26 нояб. 2025 г.·8 мин
Как создать веб‑приложение для отслеживания операционных узких мест
Пошаговое руководство по планированию, дизайну и запуску веб‑приложения, которое собирает данные о рабочих процессах, выявляет узкие места и помогает командам устранять задержки.
Начните с проблемы и решений
Веб‑приложение для отслеживания процессов полезно только если оно отвечает на конкретный вопрос: «Где мы застреваем и что с этим делать?» Прежде чем рисовать экраны или выбирать архитектуру веб‑приложения, определите, что значит «узкое место» в вашей операции.
Определите, что считается узким местом
Узкое место может быть шагом (например, «проверка QA»), командой (например, «комплектация»), системой (например, «платежный шлюз») или даже поставщиком (например, «забор у перевозчика»). Выберите определения, которыми вы действительно будете управлять. Например:
- Шаг считается узким местом, когда среднее время ожидания в очереди превышает 24 часа.
- Команда считается узким местом, когда незавершённая работа (WIP) остаётся выше заданного порога в течение 3 дней.
- Система считается узким местом, когда инциденты вызывают резкий рост времени цикла за пределы согласованного диапазона.
Перечислите решения, которые должно поддерживать приложение
Ваша панель операций должна приводить к действиям, а не только к отчётам. Выпишите решения, которые вы хотите принимать быстрее и с большей уверенностью, например:
- Распределение персонала: «Перенести ли на этой неделе одного человека из команды A в команду B?»
- Приоритизация: «Какие заказы/заявки должны прыгнуть в очередь, чтобы защитить SLA?»
- Автоматизация: «Какой шаг достаточно стабилен (и достаточно дорог), чтобы автоматизировать его первым?»
Определите основных пользователей и их потребности
Разным пользователям нужны разные представления:
- Менеджеры операций нуждаются в ясном виде «куда вмешаться сегодня».
- Лиды команд нуждаются в подробностях по очередям, блокирующим факторам и переделам.
- Аналитики нуждаются в согласованных определениях и выгрузках для аналитики рабочих процессов.
Установите метрики успеха для самого приложения
Решите, как вы поймёте, что приложение работает. Хорошими метриками являются использование (еженедельные активные пользователи), сэкономленное время на отчётности и более быстрое разрешение проблем (сокращение времени на обнаружение и исправление узких мест). Эти метрики помогут вам сосредоточиться на результатах, а не на фичах.
Выберите рабочий процесс и напишите простую карту процесса
Прежде чем проектировать таблицы, панели или оповещения, выберите рабочий процесс, который можно описать в одном предложении. Цель — отслеживать, где работа ждёт, — поэтому начните с малого и выберите один‑два процесса, которые важны и дают стабильный объём, например выполнение заказов, обработка тикетов поддержки или адаптация сотрудников.
Тесный охват держит определение готовности ясным и предотвращает застой проекта из‑за разногласий между командами о том, как процесс должен работать.
Начните с 1–2 процессов с высоким сигналом
Выбирайте рабочие процессы, которые:
- Происходят часто (достаточно данных, чтобы заметить закономерности)
- Пересекают как минимум один момент передачи (где формируются очереди)
- Имеют ясное влияние на клиента (время, стоимость, удовлетворённость)
Например, «тикеты поддержки» чаще лучше, чем «customer success», потому что у него очевидная единица работы и отметки времени.
Отобразите шаги и передачи простым языком
Напишите рабочий процесс простым списком шагов, используя слова, которыми уже пользуется команда. Вы не документируете политику — вы идентифицируете состояния, через которые проходит элемент работы.
Лёгкая карта процесса может выглядеть так:
- Ticket created → triaged → assigned → agent working → waiting on customer → resolved
На этом этапе явно указывайте передачи (triage → assigned, agent → specialist и т. п.). Именно на передачах обычно скрывается время в очереди, и именно эти моменты вы захотите измерять позже.
Определите старт/финиш и «готово» для каждого шага
Для каждого шага запишите два пункта:
- Событие начала (что доказывает, что шаг начат?)
- Событие окончания (что доказывает, что шаг завершён?)
Держите формулировки наблюдаемыми. «Агент начинает расследование» субъективно; «статус изменён на In Progress» или «добавлена первая внутренняя заметка» — отслеживаемые события.
Также определите, что означает «готово», чтобы приложение не путало частичное выполнение с завершением. Например, «resolved» может означать «отправлено сообщение о решении и тикет помечен как Resolved», а не просто «внутренняя работа завершена».
Отметьте обычные исключения, которые вы будете отслеживать позже
В реальных операциях есть сложные пути: переделы, эскалации, недостающая информация и повторно открытые элементы. Не пытайтесь моделировать всё в первый день — просто запишите исключения, чтобы добавлять их осознанно позже.
Простая заметка вроде «10–15% тикетов эскалируется до Tier 2» уже достаточно. Эти заметки помогут решить, станут ли исключения отдельными шагами, метками или отдельными потоками при расширении системы.
Определите метрики, которые действительно выявляют узкие места
Узкое место — это не ощущение, а измеримое замедление на конкретном шаге. Прежде чем строить графики, решите, какие числа докажут, где работа скапливается и почему.
Выберите небольшой набор ключевых измерений
Начните с четырёх метрик, которые работают в большинстве рабочих процессов:
- Cycle time: сколько времени элемент проходит от старта до готовности.
- Wait/queue time: сколько времени элемент простаивает между шагами.
- Throughput: сколько элементов завершается за период.
- WIP (work in progress): сколько элементов в данный момент «в системе».
Они покрывают скорость (cycle), простои (queue), объём выпуска (throughput) и загрузку (WIP). Большинство «таинственных задержек» проявляются как рост времени в очереди и WIP на конкретном шаге.
Определите расчёты (включая граничные случаи)
Запишите определения, с которыми согласится вся команда, затем реализуйте именно их.
- Cycle time =
done_timestamp − start_timestamp.- Граничные случаи: повторно открытые элементы (рассматривать как новый цикл или продлить оригинал), элементы, которые никогда не начались (исключать из cycle time, но учитывать в WIP), отсутствующие метки времени (помечать как качество данных).
- Queue time = сумма промежутков между шагами, когда статус «ожидает».
- Граничные случаи: ночи/выходные (календарное время vs рабочие часы), заблокированные состояния (учитывать отдельно от обычного ожидания, если нужно яснее видеть причины).
- Throughput = количество элементов с
done_timestampв окне.- Граничные случаи: отмены (исключать или отслеживать отдельно), частичные завершения.
- WIP = количество элементов, не находящихся в терминальном состоянии в конкретный момент времени.
- Граничные случаи: элементы на паузе (всё ещё WIP, но может потребоваться отдельный «blocked WIP»).
Выберите разрезы, которые влияют на решения
Выберите срезы, которые менеджеры действительно используют: команда, канал, линия продукта, регион и приоритет. Цель — ответить на вопрос: «Где медленно, для кого и при каких условиях?»
Установите временные окна и цели
Определите ритм отчётности (обычно ежедневно и еженедельно) и задайте цели, такие как пороги SLA/SLO (например, «80% высокоприоритетных задач завершены в пределах 2 дней»). Цели делают панель действий полезной, а не декоративной.
Спланируйте источники данных и метод их сбора
Самый быстрый способ загнать проект по мониторингу узких мест в тупик — предположить, что данные «просто будут». Прежде чем проектировать таблицы или графики, запишите, откуда будет приходить каждое событие и метка времени — и как вы будете поддерживать согласованность со временем.
Перечислите существующие источники
Большинство команд операций уже ведут учёт в нескольких местах. Частые отправные пункты:
- Таблицы (спreadsheets) для передач, ежедневных журналов или производственных учётов
- ERP/CRM системы (заказы, клиенты, шаги выполнения)
- Тикет‑системы (очереди поддержки, заявки на изменения, задачи по обслуживанию)
- Внутренние базы данных (сканы на складе, таблицы планирования работ, данные MES)
Для каждого источника отметьте, что он способен предоставить: стабильный идентификатор записи, историю статусов (не только текущий статус) и как минимум две метки времени (вход в шаг, выход из шага). Без этого мониторинг времени в очереди и отслеживание времени цикла будут гаданием.
Выберите метод захвата, соответствующий источнику
Обычно есть три варианта, и многие приложения используют их в комбинации:
- API pull: периодический синхрон с ERP/CRM/тикетами. Просто в рассуждении, но нужно обрабатывать пагинацию, лимиты скорости и инкрементные обновления.
- Webhooks: пуш‑обновления при изменениях работы. Отлично для почти реального времени, но нужно проектировать повторы и события вне порядка.
- Ручной ввод / загрузка CSV: полезно для команд, начинающих с таблиц или для пограничных случаев. Делайте безопасным через шаблоны, валидацию и понятные сообщения об ошибках.
Спланируйте качество данных (оно случится)
Ожидайте отсутствующих меток времени, дубликатов и несогласованных статусов («In Progress» vs «Working»). Постройте правила заранее:
- Предпочитайте неизменяемый журнал событий вместо перезаписи записей
- Дедуплицируйте по source ID + event time + status
- Нормализуйте статусы в канонические шаги вашего приложения
- Помечайте записи, которые не позволяют надёжно вычислять cycle time
Решите частоту обновления
Не каждый процесс требует обновления в реальном времени. Выбирайте исходя из принимаемых решений:
- Реальное время: диспетчирование, триаж поддержки, риск SLA
- Почасово: пропускная способность склада, мониторинг времени в очереди
- Ежедневно: еженедельные отчёты, сессии непрерывного улучшения
Запишите это сейчас; от этого зависят стратегия синхронизации, затраты и ожидания по панели операций.
Спроектируйте модель данных, ориентированную на анализ по времени
В приложение для отслеживания узких мест выживёт или погибнет в зависимости от того, насколько хорошо оно отвечает на вопросы о времени: «Сколько это заняло?», «Где оно ждало?» и «Что изменилось прямо перед замедлением?» Проще всего поддержать эти вопросы позже, моделируя данные вокруг событий и меток времени с самого начала.
Начните с основных сущностей
Держите модель маленькой и очевидной:
- Process: общий рабочий поток (например, «Выполнение заказа»).
- Step: этап внутри процесса (например, «Pick», «Pack», «Ship»).
- Work item: единица, которая перемещается через шаги (тикет, заказ, рекламация).
- Event: зафиксированное изменение состояния (вход на шаг, назначение, блокировка, завершение).
- User/Team и Assignment: кто владел работой в конкретный момент.
Такая структура позволяет измерять время цикла по шагам, время ожидания между шагами и пропускную способность по всему процессу без изобретения частных случаев.
Предпочитайте журнал событий полям «текущий статус»
Регистрируйте каждое изменение статуса как неизменяемую запись события. Вместо перезаписи current_step и потери истории, добавляйте событие вроде:
- work_item_id
- from_step → to_step (или «entered_step»)
- event_type (assigned, started, blocked, completed)
- event_time
Можно хранить снимок «текущего состояния» для быстродействия, но аналитика должна опираться на журнал событий.
Сделайте время и отслеживаемость обязательными
Храните метки времени последовательно в UTC. Также сохраняйте оригинальные идентификаторы источника (например, ключ задачи Jira, ID заказа в ERP) в записях work_items и events, чтобы любой график можно было проследить до реальной записи.
Фиксируйте исключения без лишней рутины
Запланируйте лёгкие поля для моментов, объясняющих задержки:
- reason_code (стандартные варианты вроде «Waiting on customer»)
- comment (опциональный текст)
- blocked_flag или severity
Делайте их опциональными и простыми для заполнения, чтобы учиться на исключениях, не превращая приложение в упражнение по заполнению форм.
Выберите архитектуру, подходящую вашей команде
Настройте ранние оповещения
Создайте простые пороговые правила, чтобы узкие места замечались между еженедельными обзорами.
«Лучшая» архитектура — это та, которую ваша команда может построить, понимать и эксплуатировать годами. Начните с выбора стека, соответствующего рынку труда и существующим навыкам — распространённые, хорошо поддерживаемые варианты: React + Node.js, Django или Rails. Последовательность лучше новизны, когда вы запускаете панель операций, от которой люди зависят ежедневно.
Разделяйте ответственности, чтобы система оставалась правкой
Приложение для отслеживания узких мест обычно лучше работает, когда вы разбиваете его на очевидные слои:
- Ingestion: приём событий (изменения статусов, метки времени, передачи) из форм, интеграций или импортов.
- Storage: транзакционная база данных для надёжных записей и аудита.
- Analytics queries: оптимизированные чтения или представления для вычисления cycle time, queue time и throughput.
- UI/API: эндпоинты и экраны, которые делают панели быстрыми и предсказуемыми.
Это разделение позволяет менять одну часть (например, добавить новый источник данных) без переписывания всего остального.
Решите, где должны выполняться вычисления
Некоторые метрики достаточно просты для вычисления в запросах к базе (например, «среднее время в очереди по шагу за последние 7 дней»). Другие тяжёлые или требуют предобработки (например, перцентильные оценки, обнаружение аномалий, еженедельные когорты). Практическое правило:
- Выполняйте фильтры и разрезы в реальном времени в базе данных.
- Используйте фоновые задания для предвычисления тяжёлых агрегатов и сохраняйте их для быстрой загрузки дашборда.
- Добавляйте слой аналитики только если команда уверенно его поддерживает.
Планируйте производительность заранее
Операционные панели терпят неудачу, когда работают медленно. Индексируйте по временным меткам, ID шагов и tenant/team ID. Добавьте пагинацию для журналов событий. Кешируйте общие представления панели (например, «сегодня» и «последние 7 дней») и инвалидируйте кеш при поступлении новых событий.
Если нужно обсуждение компромиссов глубже, оставьте короткую запись решения в репозитории, чтобы будущие изменения не уводили проект в сторону.
Быстрый путь для команд, которые хотят быстро запустить
Если цель — проверить аналитику рабочего процесса и оповещения до полной сборки, платформа vibe-coding, например Koder.ai, может помочь быстрее поднять первую версию: вы описываете в чате рабочий процесс, сущности и панели, затем итеративно правите сгенерированный React UI и бэкенд на Go + PostgreSQL по мере уточнения инструментирования KPI.
Практическое преимущество для приложения по отслеживанию узких мест — скорость обратной связи: вы можете пилотно подключить сбор (API pull, webhooks или импорт CSV), добавить экраны с drill‑down и корректировать определения метрик без недель создания инфраструктуры. Когда будете готовы, Koder.ai также поддерживает экспорт исходного кода и деплой/хостинг, что облегчает путь от прототипа к поддерживаемому internal‑инструменту.
Спроектируйте панель и опыт drill‑down
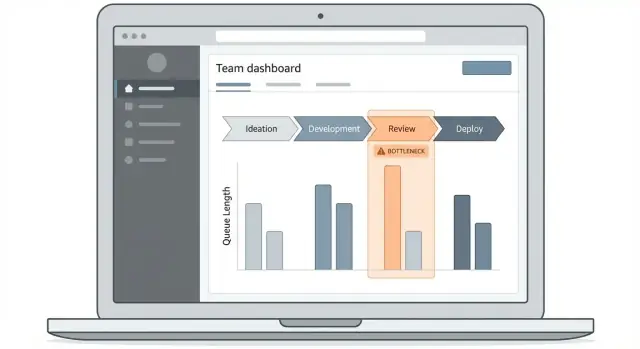
Успех приложения для отслеживания узких мест зависит от того, может ли человек быстро ответить на вопрос: «Где сейчас застряла работа и какие элементы её вызывают?» Ваша панель должна делать этот путь очевидным, даже для того, кто заходит раз в неделю.
Начните с 2–3 основных экранов
Задержите первый релиз коротким:
- Обзорная панель: «доска состояния» для cycle time, queue time и топ‑шагов с блокировками.
- Список элементов работы: таблица с поиском и фильтрами элементов, затронутых задержками.
- Детали рабочего процесса: покроковый вид времени на каждом этапе и точек передачи.
Эти экраны создают естественный путь drill‑down без сложности в использовании интерфейса.
Используйте визуализации, объясняющие время и поток
Выбирайте типы диаграмм, соответствующие операционным вопросам:
- Фильтр по этапу (stage funnel): показывает, где накапливается объём (полезно для нахождения очередей).
- Гистограммы времени на этапе: сравнивают шаги по медиане и перцентилям, а не только по среднему.
- Линии тренда: отвечают на вопрос «становится ли лучше или хуже?» за недели.
- Тепловые карты: показывают закономерности вроде «понедельники в Review» или «передачи ночной смены».
Держите подписи простыми: «Время ожидания» вместо «Queue latency».
Сделайте фильтры последовательными и заметными
Используйте одну общую панель фильтров на всех экранах (одно и то же расположение, одни и те же значения по умолчанию): интервал дат, команда, приоритет, шаг. Показывайте активные фильтры как чипсы, чтобы люди не перепутали цифры.
Проектируйте чёткие пути drill‑down
Каждый KPI‑тайл должен быть кликабельным и вести к полезному месту:
KPI → шаг → список затронутых элементов
Пример: клик по «Самое длинное время ожидания» открывает детали шага, затем один клик показывает конкретные элементы, ожидающие там — отсортированные по возрасту, приоритету и ответственному. Это превращает любопытство в конкретный список дел, что делает панель востребованной, а не игнорируемой.
Добавьте оповещения и ранние сигналы
Сделайте задержки управляемыми
Генерируйте детализированные экраны от KPI-плиток до конкретных зависших задач.
Панели хороши для обзоров, но узкие места чаще всего наносят вред между встречи. Оповещения превращают приложение в систему раннего предупреждения: вы находите проблемы, когда они только формируются, а не когда неделя уже потеряна.
Начните с ясных, тривиальных правил
Начните с малого набора типов оповещений, которые команда уже считает «плохими»:
- Превышение порога: cycle time или queue time выше известного лимита (например, «этап Review > 24 часов»).
- Аномальное увеличение: медиана cycle time сегодня выросла на 30% по сравнению с прошлой неделей.
- Застрявшие элементы: отсутствие изменения статуса N часов/дней или элементы, превысившие максимальный возраст.
Делайте первую версию простой. Пара детерминированных правил ловит большинство проблем и вызывает больше доверия, чем сложные модели.
Добавьте лёгкие проверки аномалий
Когда пороги устаканятся, добавьте базовые сигналы «это странно?»:
- Процентное изменение vs прошлой недели (сравнивать с тем же днём недели помогает уменьшить ложные срабатывания).
- Скользящая трендовая дрейф‑метрика (например, 7‑дневное среднее стабильно растёт).
- Несоответствие объёмов (входы растут быстрее выхода на шаге).
Делайте аномалии подсказками, а не тревогой: помечайте их как «Внимание», пока пользователи не подтвердят их полезность.
Доставляйте оповещения туда, где люди работают
Поддерживайте несколько каналов, чтобы команды выбирали удобный:
- Email для менеджеров и ежедневных сводок
- Slack/Microsoft Teams для оперативного триажа
- Встроенные уведомления для владельцев внутри инструмента
Каждое оповещение должно быть действующим
Оповещение должно отвечать на «что, где и что дальше»:
- Какой шаг затронут и за какой период
- Главные драйверы (например, команда, категория, приоритет)
- Прямая ссылка для расследования, например:
/dashboard?step=review&range=7d&filter=stuck
Если оповещения не ведут к конкретным действиям, люди будут их отключать — относитесь к качеству оповещений как к продуктовой фиче, а не как к дополнению.
Учитывайте права доступа, безопасность и аудируемость
Приложение быстро становится «источником правды». Это хорошо — пока неверный человек не изменит определение, не экспортирует чувствительные данные или не поделится панелью вне команды. Права доступа и аудит‑трейл защищают доверие к цифрам.
Определите роли и правила доступа
Начните с небольшой, понятной модели ролей и расширяйте только при необходимости:
- Viewer: только чтение панелей и отчётов.
- Manager: может фильтровать по команде, создавать сохранённые виды, подтверждать оповещения и добавлять заметки (но не изменять глобальные настройки).
- Admin: управляет определениями процессов, формулами KPI, интеграциями и доступом пользователей.
Ясно опишите для каждой роли, что ей доступно: просмотр сырых событий vs агрегированных метрик, экспорт данных, редактирование порогов и управление интеграциями.
Разделяйте данные по командам или бизнес‑единицам
Если приложение используется несколькими командами, обеспечьте разграничение на уровне данных, а не только в UI. Общие варианты:
- Мульти‑тенант: каждая запись имеет
tenant_id, и каждый запрос ограничен им. - Партиции/проекты: отдельные «рабочие пространства» для каждой бизнес‑единицы с независимыми настройками и панелями.
Решите заранее, могут ли менеджеры смотреть данные других команд. Делайте межкомандную видимость осознанным разрешением, а не дефолтом.
Безопасная аутентификация (SSO или готовность к MFA)
Если в организации есть SSO (SAML/OIDC), используйте его, чтобы оффбординг и контроль доступа были централизованы. Если SSO нет, реализуйте логин, готовый к MFA (TOTP или passkeys), поддерживающий безопасный сброс пароля и принудительное истечение сессий.
Делайте изменения аудируемыми
Логируйте действия, которые могут изменить результаты или раскрыть данные: экспорты, изменения порогов, правки процессов, обновления прав и настройки интеграций. Фиксируйте, кто, когда, что изменил (до/после) и где (рабочее пространство/tenant). Предоставьте вид «Журнал аудита», чтобы быстро расследовать проблемы.
Превращайте инсайты в действия и улучшения процессов
Панель узких мест важна только если она изменяет поведение людей. Цель этого раздела — превратить «интересные графики» в повторяемый рабочий ритм: решить, сделать, измерить и сохранить то, что работает.
Создайте лёгкий обзор узких мест
Установите простой еженедельный ритм (30–45 минут) с чёткими владельцами. Начните с топ‑1–3 узких мест по влиянию (например, самое большое время в очереди или крупнейшее падение throughput), затем согласуйте одно действие на каждое узкое место.
Держите процесс маленьким:
- Владелец: один ответственный за действие
- Срок: следующий обзор по умолчанию
- Критерий готовности: измеримое изменение (не «ещё разобраться»)
Фиксируйте решения прямо в приложении, чтобы панель и журнал действий были связаны.
Отслеживайте улучшения как эксперименты
Рассматривайте исправления как эксперименты, чтобы быстро учиться и избегать «случайных оптимизаций». Для каждого изменения записывайте:
- Гипотеза (что замедляет и почему)
- Изменение (что будете делать)
- Ожидаемый эффект (какая метрика должна измениться и на сколько)
- Результат (что произошло на самом деле)
Со временем это станет плейбуком того, что уменьшает время цикла, что сокращает переделы и что не работает.
Добавляйте контекст аннотациями
Графики могут вводить в заблуждение без контекста. Добавляйте простые аннотации на временной шкале (например, набран новый персонал, сбой системы, обновление политики), чтобы зрители могли правильно интерпретировать сдвиги в queue time или throughput.
Облегчите совместный доступ
Давайте возможность экспортов для анализа и отчётности — CSV‑выгрузки и плановые отчёты — чтобы команды могли включать результаты в операционные отчёты и обзоры руководства. Если у вас уже есть страница отчётов, ссылайтесь на неё из панели (например, /reports).
Развёртывание, мониторинг и поддержание актуальности данных
Постройте по простой карте процесса
Преобразуйте карту процесса в шаги, события и дашборды без недельной настройки.
Приложение для отслеживания узких мест полезно только при стабильной доступности и доверии к цифрам. Относитесь к развёртыванию и свежести данных как к части продукта, а не к праздничной детали.
Используйте отдельные окружения и повторяемые деплои
Настройте dev / staging / prod рано. Staging должна имитировать прод (тот же движок БД, похожий объём данных, те же фоновые задания), чтобы ловить медленные запросы и сломанные миграции до пользователей.
Автоматизируйте деплой через единую конвейерную цепочку: запускайте тесты, применяйте миграции, деплойте, затем прогоняйте smoke‑проверку (вход, загрузка панели, проверка инжеста). Держите деплои мелкими и частыми — это уменьшает риск и делает откат реалистичным.
Мониторьте приложение и пайплайн
Нужно мониторить два направления:
- Здоровье приложения: уровень ошибок, латентность, медленные эндпоинты и медленные запросы.
- Здоровье данных: сбои инжеста, размер бэклога и «время с последнего события».
Оповещайте о симптомах, которые чувствуют пользователи (панели зависают), и о ранних сигналах (очередь растёт 30 минут). Также отслеживайте ошибки вычисления метрик — отсутствие cycle time может выглядеть как «улучшение».
Поддерживайте актуальность данных: поздние события, правки и бэкфиллы
Операционные данные приходят с задержкой, вне порядка или корректируются. Планируйте:
- Идемпотентный инжест (повторная обработка одного и того же события не даёт двойного учёта).
- Бэкфиллы для периодов, когда источник был недоступен.
- Перерасчёты при изменении справочных данных (например, календаря смен).
Определите, что значит «свежо» (например, 95% событий в течение 5 минут) и показывайте свежесть в UI.
Пишите runbook‑ы, чтобы исправления не были гаданием
Документируйте пошаговые инструкции: как перезапустить синхронизацию, проверить KPI за вчера, и убедиться, что бэкфилл не изменил исторические числа неожиданно. Храните их в проекте и ссылайтесь через /docs, чтобы команда могла быстро реагировать.
Итерация с пользователями и расширение охвата
Приложение преуспевает, когда люди ему доверяют и реально им пользуются. Это происходит только когда вы наблюдаете, как реальные пользователи задают реальные вопросы («Почему утверждения медленные на этой неделе?») и затем дорабатываете продукт вокруг этих рабочих потоков.
Начните с пилота и посмотрите, что ломается
Стартуйте с одной пилотной команды и небольшого числа рабочих процессов. Держите объём узким, чтобы можно было наблюдать использование и быстро реагировать.
В первые неделю‑две сосредоточьтесь на том, что вызывает путаницу или ломается:
- Какие графики пользователи неправильно читают?
- Где они застревают при drill‑down?
- Какие данные они ожидают увидеть, но не находят?
- Какие узкие места кажутся им «очевидными», но в приложении не отражены?
Собирайте обратную связь внутри инструмента (простая кнопка «Было ли это полезно?» на ключевых экранах хорошо работает), чтобы не полагаться на устные отчёты.
Валидируйте метрики, чтобы избежать «споров по дашборду»
Прежде чем расширяться на другие команды, закрепите определения с людьми, которые будут нести ответственность. Многие внедрения проваливаются, потому что команды не договорились, что означает метрика.
Для каждого KPI (cycle time, queue time, rate переделов, нарушения SLA) задокументируйте:
- Точные события старта и окончания
- Обработку пауз, выходных и отсутствующих меток времени
- Как считаются исключения (отмены, эскалации, повторы)
Затем согласуйте эти определения с пользователями и добавьте короткие подсказки в UI. Если вы меняете определение, показывайте явный changelog, чтобы люди понимали, почему числа сдвинулись.
Расширяйте охват осторожно, чтобы не превратить приложение в хаос
Добавляйте функции аккуратно, только когда аналитика рабочего процесса пилотной команды стабильна. Частые расширения: настраиваемые шаги (разные команды по‑разному называют стадии), дополнительные источники (тикеты + CRM + таблицы) и расширенная сегментация (по линии продукта, региону, приоритету, уровню клиента).
Правило: добавляйте одно новое измерение за раз и проверяйте, улучшает ли оно принятие решений, а не только отчётность.
Сделайте онбординг лёгким и воспроизводимым
При расширении на другие команды вам понадобится последовательность. Создайте краткое руководство по подключению данных, интерпретации панели и действиям по оповещениям об узких местах.
Связывайте людей с релевантными страницами продукта и контентом, такими как /pricing и /blog, чтобы новые пользователи могли получать ответы самостоятельно, а не ждать тренингов.