29 авг. 2025 г.·8 мин
Как создать веб‑приложение для отслеживания зависимостей между отделами
Практическое руководство по проектированию веб‑приложения для фиксации, визуализации и управления зависимостями между отделами с понятными рабочими процессами, ролями и отчётностью.
Уточните проблему и масштаб
Прежде чем набрасывать экраны или выбирать стек технологий, определите, что вы отслеживаете и зачем. «Зависимость» звучит универсально, но у разных команд это обычно значит разное — и именно это несоответствие приводит к пропущенным передачам и внезапным блокерам.
Определите, что для вас значит «зависимость»
Начните с простого определения на понятном языке, с которым все согласны. В большинстве организаций зависимости попадают в несколько практических категорий:
- Артефакт/результат: команда A не может начать/завершить, пока команда B не предоставит файл, функцию или документ.
- Согласование/утверждение: требуется подпись или одобрение Legal, Finance, Security или руководства.
- Данные: другая команда должна предоставить доступ к данным, отчёт, экспорт или изменить схему.
- Ресурсы/штат: другая группа должна выделить время (ревью дизайна, QA, поддержка операций).
Будьте явными в том, что не является зависимостью. Например, «приятно поработать вместе» или «информационные обновления» могут иметь место в другом инструменте.
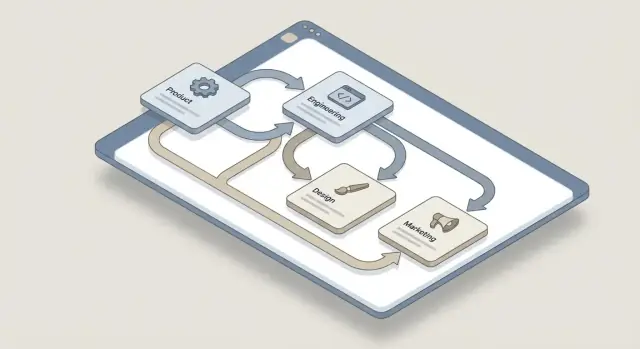
Сопоставьте отделы и типичные виды зависимостей
Перечислите отделы, которые регулярно блокируют или разблокируют работу (Product, Engineering, Design, Marketing, Sales, Support, Legal, Security, Finance, Data, IT). Затем зафиксируйте повторяющиеся шаблоны между ними. Примеры: «Маркетингу нужны даты запуска от Product», «Security требует threat model перед ревью», «Команде Data нужно две недели на внесение изменений в трекинг».
Этот шаг помогает приложению фокусироваться на реальных межкомандных передачах, а не превращаться в универсальный таск‑трекер.
Определите болевые точки, которые хотите устранить
Запишите текущие режимы сбоев:
- Передачи пропускаются, потому что неясен владелец.
- Зависимость обнаруживается слишком поздно (прямо перед запуском).
- Обновления живут в разбросанных местах (email, чаты, таблицы).
- Эскалации происходят, потому что нет общего представления о статусе и сроках.
Установите критерии успеха (чтобы «готово» было измеримо)
Определите несколько ожидаемых результатов, которые можно измерить после внедрения, например:
- Меньше эскалаций, связанных с межкомандными блокерами.
- Быстрее оборот по утверждениям (медиана дней от запроса до решения).
- Больше ясности по владельцам (например, % зависимостей с назначенным ответственным).
- Меньше «сюрпризных» блокеров, обнаруженных в последнюю неделю перед вехой.
С согласованным масштабом и метриками каждая продуктовая решение становится проще: если фича не снижает неясность вокруг ответственности, сроков или передач, вероятно, ей не место в первой версии.
Сопоставьте пользователей и основные рабочие процессы
Прежде чем проектировать экраны или таблицы, ясно определите, кто будет пользоваться приложением и чего они хотят добиться. Трекер зависимостей терпит неудачу, когда его строят «для всех», поэтому начните с небольшого набора первичных персон и оптимизируйте опыт для них.
Выберите первичные персоны (и что им важно)
Большинство межотделочных зависимостей укладываются в четыре роли:
- Запрашивающий (Requester): нуждается в чём‑то от другой команды; ему важны ясность, сроки и понимание «что дальше».
- Исполнитель/владелец (Owner): команда/человек, который должен доставить; важны объём работы, усилия и переговоры по срокам.
- Утверждающий (Approver): подтверждает приоритет или ресурсы; заботится о риске, компромиссах и подотчётности.
- Программный менеджер (Program manager): нужен общий обзор; следит за узкими местами, устаревшими элементами и путями эскалации.
Напишите по одной краткой job‑story для каждой персоны (что заставляет открыть приложение, какое решение надо принять, что считается успехом).
Документируйте основные рабочие процессы полностью
Зафиксируйте ключевые рабочие процессы как простые последовательности, включая места передач:
- Создать зависимость (requester) → заполнить детали, прикрепить контекст, предложить needed‑by дату.
- Принять / отклонить / запросить изменения (owner/approver) → подтвердить ответственность и ожидания.
- Завершить зависимость (owner) → пометить как выполнено, добавить доказательства/заметки, уведомить запрашивающего.
- Эскалировать (program manager) → инициировать ревью, когда элемент заблокирован, просрочен или оспаривается.
Делайте рабочий процесс аргументированным. Если пользователи могут перемещать зависимость в любой статус в любой момент, качество данных быстро деградирует.
Предотвращайте перегрузку форм: обязательные и опциональные поля
Определите минимум, необходимый для старта: заголовок, запрашивающий, команда/человек, предоставляющий, needed‑by дата и краткое описание. Всё остальное сделайте опциональным (влияние, ссылки, вложения, теги).
Решите, что нужно отслеживать во времени
Зависимости — про изменения. Планируйте сохранять аудит‑трейл для изменений статуса, комментариев, правок даты, переназначений владельцев и решений по принятию/отклонению. Эта история необходима для обучения и справедливой эскалации позже.
Спроектируйте запись зависимости
Запись зависимости — это «единица правды», которой управляет приложение. Если она неконсистентна или расплывчата, команды будут спорить о том, что означает зависимость, вместо того чтобы её решать. Стремитесь к записи, которую можно создать меньше чем за минуту, но она должна быть структурированной настолько, чтобы позже можно было её фильтровать, сортировать и отчётить.
Начните с единообразного шаблона
Используйте одни и те же ключевые поля везде, чтобы люди не изобретали собственные форматы:
- Заголовок: короткий, ориентированный на действие (например, «Security‑ревью для новой billing‑логики»)
- Описание: что нужно, как выглядит «готово», ограничения
- Запрашивающая команда (кто нуждается в результате)
- Предоставляющая команда (кто будет доставлять)
- Владелец (ответственный за следующий шаг)
- Needed‑by дата
- Статус: держите просто (например, Draft → Proposed → Accepted → In Progress → Blocked → Done)
Добавьте пару опциональных полей, которые убирают неясность, не превращая приложение в систему оценок:
- Влияние: что будет отложено или какой риск увеличится при недоставке (Low/Medium/High достаточно)
- Срочность: насколько это чувствительно ко времени (Normal/Soon/ASAP)
Связывайте запись с реальной работой
Зависимости редко живут сами по себе. Разрешите привязывать несколько связанных элементов — тикеты, документы, заметки встречи, PRD — чтобы люди могли быстро проверить контекст. Храните и URL, и короткую метку (например, «Jira: PAY‑1842»), чтобы списки оставались читабельными.
Проектируйте на частичную информацию (это нормально)
Не каждая зависимость начинается с идеальной ясности по владельцу. Поддержите опцию «Владелец неизвестен» и направляйте такие записи в очередь триажа, где координатор (или дежурный) может назначить правильную команду. Это не даст зависимостям оставаться вне системы из‑за одного незаполненного поля.
Хорошая запись зависимости делает ответственность ясной, приоритизацию — возможной, а дальнейшие действия — бесшовными, не требуя лишней работы от пользователей.
Спланируйте модель данных (просто, но с запасом на будущее)
Приложение для отслеживания зависимостей живёт и умирает вместе со своей моделью данных. Стремитесь к структуре, которую легко запросить и объяснить, при этом оставляя место для роста (новые команды, проекты, правила) без полной переработки.
Начните с небольшого набора сущностей
Большинству организаций хватит 80% потребностей пяти таблиц/коллекций:
- Department/Team: имя, cost center (опционально), parent team (опционально)
- Person: имя, email, team_id, роль/должность (опционально)
- Project/Initiative: имя, owner_team_id, даты начала/окончания (опционально)
- Milestone: project_id, due date, заметки о «definition of done»
- Dependency: запись, которую все обсуждают — что нужно, кем и к какому сроку
Держите Dependency компактной: title, description, requesting_team_id, providing_team_id, owner_person_id, needed_by_date, status, priority, и ссылки на связанное рабочее.
Моделируйте связи явно
Две связи важнее всего:
- Dependency → Project/Initiative: зависимость должна прикрепляться к проекту (и опционально к вехе). Это даёт видимость по проекту и позволяет отчётить.
- Dependency → Dependency (blocked by): иногда зависимость не может начаться, пока другая не завершится. Храните это в таблице‑соединении (например,
dependency_edges) сblocking_dependency_idиblocked_dependency_id, чтобы позже строить граф зависимостей.
Определите статусы и переходы
Используйте простой, общий жизненный цикл, например:
Draft → Proposed → Accepted → In Progress → Blocked → Done
Задайте небольшой набор разрешённых переходов (например, Done не возвращается назад без действия администратора). Это предотвратит «статус‑рулетку» и сделает уведомления предсказуемыми.
Храните историю без оверинжиниринга
Вам захочется ответить на вопрос: «Кто что поменял и когда?» Два распространённых варианта:
- Таблица аудита: хранить
entity_type,entity_id,changed_by,changed_atи JSON‑diff. Просто реализовать и удобно запрашивать. - Поток событий: append‑only события (например,
DependencyAccepted,DueDateChanged). Мощно, но сложнее в реализации.
Для большинства команд начните с таблицы аудита; при потребности в продвинутой аналитике или воспроизведении состояния можно перейти на событийную модель позже.
Выберите подходящие UI‑паттерны
Трекер зависимостей успешен тогда, когда люди могут ответить на два вопроса за секунды: что я владею и на что я жду. UI должен снижать когнитивную нагрузку, делать статус очевидным и держать частые действия в один клик.
Начните с фильтруемого списка (вид по умолчанию)
Сделайте вид по умолчанию простым: таблица или карточки с мощными фильтрами — здесь будут жить большинство пользователей. Вынесите два «стартерных» фильтра в центр:
- Моя команда — поставщик (зависимости, которые должна доставить ваша команда)
- Моя команда — запрашивающий (зависимости, которые блокируют вашу команду)
Держите список сканируемым: заголовок, запрашивающая команда, предоставляющая команда, срок, статус и последнее обновление. Избегайте уместывания всех полей; подробности доступны в детальном виде.
Используйте понятные визуальные подсказки, соответствующие реальным решениям
Люди визуально триажат работу. Используйте согласованные сигналы (цвет + текстовая метка, не только цвет) для:
- Просрочено
- На грани риска (напр., скоро срок и есть вопросы)
- Ожидает утверждения
- Заблокировано
Добавьте маленькие читаемые индикаторы вроде «Просрочено на 3 дня» или «Требуется ответ владельца», чтобы пользователи знали, что делать дальше, а не просто видели проблему.
Предложите граф зависимостей — но делайте его опциональным
Граф зависимостей полезен для больших программ, планёрок и поиска циркулярных или скрытых блокеров. Но графы могут перегружать казуальных пользователей, поэтому предлагайте их как вторичный вид («Switch to graph»), а не по умолчанию. Разрешите пользователям фокусироваться на одной инициативе или срезе по команде, вместо того чтобы показывать организационную паутину.
Разместите быстрые действия там, где они нужны
Поддержите быструю координацию инлайн‑действиями в списке и на странице детали:
- Принять / подтвердить владение
- Запросить информацию
- Изменить дату (с указанием причины)
- Комментировать (с @mentions)
Делайте эти действия так, чтобы они создавали явный аудит‑трейл и запускали нужные уведомления, чтобы обновления не терялись в потоках чата.
Установите права, владение и доступ
Проведите целевой пилот
Запустите трекер зависимостей для одной программы и соберите отзывы перед масштабированием.
Права доступа — это то место, где трекер зависимостей либо приживается, либо нет. Слишком свободно — люди перестанут доверять данным. Слишком жёстко — обновления остановятся.
Держите роли небольшими (и запоминающимися)
Начните с четырёх ролей, соответствующих повседневному поведению:
- Viewer: может просматривать зависимости и подписываться на обновления.
- Contributor: может добавлять новые зависимости и комментировать, но не менять владельца.
- Owner: отвечает за запись зависимости; может обновлять статус, даты и заметки о решении.
- Admin: управляет командами, назначениями ролей и глобальными настройками.
Это делает понятным «кто что может», без превращения приложения в свод политик.
Определите правила редактирования
Сделайте саму запись единицей ответственности:
- Владельцы обновляют статус, даты и обязательства по доставке.
- Contributors предлагают изменения (предложенные правки или комментарии), когда находят ошибки или новые риски.
- Admins управляют командами и могут переназначать владельцев при изменении ролей.
Чтобы избежать тихого дрейфа данных, логируйте правки (кто что и когда поменял). Простой аудит‑трейл повышает доверие и снижает споры.
Работа с чувствительными зависимостями
Некоторые межотделочные зависимости касаются найма, security, юридических ревью или эскалаций клиентов. Поддержите ограниченную видимость на уровне зависимости (или проекта):
- Приватно для указанного набора команд
- Приватно для рабочего пространства проекта
- Видимо для всех аутентифицированных пользователей
Убедитесь, что ограниченные элементы всё ещё могут появляться в агрегированных отчётах как счётчики (без деталей), если нужна высокоуровневая видимость проектов.
Аутентификация: выбирайте вариант с наименьшим трением
Если в компании есть — используйте SSO, чтобы люди не создавали новые пароли и админы не управляли аккаунтами. Если нет — поддержите email/password с базовыми защитами (верификация email, сброс пароля, опционально MFA позже). Сохраните процесс входа простым, чтобы обновления происходили вовремя.
Реализуйте уведомления и эскалации
Уведомления превращают трекер зависимостей из статичной таблицы в активный инструмент координации. Цель проста: нужные люди получают нужное напоминание вовремя — без необходимости постоянно обновлять дашборд.
Выберите каналы, которые соответствуют рабочим привычкам
Начните с двух базовых каналов:
- Встроенные (in‑app) уведомления для лёгких обновлений и видимого журнала активности.
- Email для всего, что чувствительно по времени или требует действия.
Делайте интеграции с чатами (Slack/Microsoft Teams) опциональными для тех команд, которые живут в каналах. Рассматривайте чат как удобный слой, а не единственный метод доставки — иначе вы потеряете заинтересованных лиц, которые этим инструментом не пользуются.
Триггерьте оповещения по значимым событиям
Формируйте список событий вокруг решений и риска:
- Назначение (новая зависимость назначена владельцу)
- Принятие/подтверждение (владелец подтвердил, что доставит)
- Изменение даты (особенно если её перенесли на более ранний срок)
- Просрочка (срок прошёл, а задача не завершена)
Каждое оповещение должно содержать, что изменилось, кто владеет следующим шагом, дату выполнения и прямую ссылку на запись.
Предотвращайте спам с помощью управляемых настроек
Если приложение шумит, пользователи его отключат. Добавьте:
- Ежедневные/еженедельные дайджесты для не‑срочных обновлений
- Тихие часы (настройка пользователя, по часовому поясу)
- Пользовательские предпочтения по типам событий и каналам
Также избегайте уведомления человека о действии, которое он сам совершил.
Добавьте правила эскалации для застрявшей работы
Эскалации — это страховочная сетка, а не наказание. Обычное правило: «Просрочено на 7 дней — уведомить группу менеджеров» (или спонсора зависимости). Делайте шаги эскалации видимыми в записи, чтобы ожидания были ясны, и позвольте админам настраивать пороги по мере обучения команд.
Добавьте поиск, фильтры и отчётность
Сохраняйте полный контроль над кодом
Когда будете готовы, экспортируйте кодовую базу и продолжайте разработку внутри компании.
Когда зависимостей становится много, успех приложения зависит от того, насколько быстро люди могут найти «ту самую вещь, которая нас блокирует». Хороший поиск и отчёты превращают трекер в рабочий инструмент для еженедельных сессий.
Сделайте поиск немедленным
Проектируйте поиск вокруг реальных вопросов пользователей:
- Поиск по ключевым словам в заголовке, описании, связанных проектах и комментариях (включая общие аббревиатуры).
- Фильтры по команде/владельцу, проекту, статусу и диапазону дат (создано, обновлено, срок).
Держите результаты читабельными: показывайте заголовок, текущий статус, срок, предоставляющую команду и самую релевантную ссылку (например, «Заблокировано Security‑ревью»).
Сохранённые фильтры для повторяющихся рутин
Большинство заинтересованных лиц возвращаются к одним и тем же видам каждую неделю. Добавьте сохранённые фильтры (личные и общие) для типичных сценариев:
- Еженедельный обзор зависимостей (только «Blocked» + «Due in 14 days»)
- Предстоящие сроки по команде
- «Ждём от нас» vs «Ждём от них»
Делайте сохранённые виды доступными по ссылке (стабильный URL), чтобы их можно было вставлять в заметки к встречам или в вики, например /operations/dependency-review.
Теги и лёгкие отчёты
Используйте теги или категории для быстрой группировки (например, Legal, Security, Finance). Теги должны дополнять — а не заменять — структурированные поля вроде статуса и владельца.
Для отчётности начните с простых диаграмм и таблиц: количества по статусам, стареющие зависимости и предстоящие дедлайны по командам. Фокусируйтесь на действии, а не на красивой статистике.
Экспорт с учётом правил доступа
Экспорт — топливо для митингов, но он может протекать данные. Поддержите CSV/PDF‑экспорт, который:
- Включает только строки и поля, доступные пользователю
- Явно отмечает «ограниченные» элементы (или полностью исключает их)
- Включает критерии фильтра и отметку времени, чтобы отчёты не интерпретировались неверно
Выберите поддерживаемый стек технологий
Приложение для отслеживания зависимостей преуспевает, когда его легко менять. Выбирайте инструменты, которые ваша команда уже знает (или может поддерживать в долгосрочной перспективе), и оптимизируйте под ясные связи данных, надёжные уведомления и простую отчётность.
Начните со стандартного веб‑стека
Никакой излишней экзотики не требуется. Обычный набор упрощает найм, адаптацию и реагирование на инциденты.
- Фронтенд: любая популярная библиотека (React, Vue или аналог) — важны единообразные компоненты для форм, таблиц и страниц деталей.
- Бэкенд: широко используемый серверный фреймворк (Node, Python, Ruby, Java, .NET), соответствующий силе вашей команды.
Если вы хотите проверить UX и рабочие процессы перед серьёзной разработкой, платформа для быстрой прототипировки в стиле «vibe‑coding», например Koder.ai, может помочь быстро прототипировать и итерировать через чат — а затем экспортировать исходники, когда будете готовы взять проект в свои руки. Koder.ai обычно таргетирует React на фронтенде и Go + PostgreSQL на бэкенде, что хорошо ложится на реляционные данные зависимостей.
Используйте реляционную базу для данных зависимостей
Межотделочные зависимости по своей природе реляционные: команды, владельцы, проекты, сроки, статусы и связи «зависит от». Реляционная БД (Postgres/MySQL) упрощает:
- принудительную целостность данных (обязательные поля, допустимые статусы)
- запросы типа «кто кого блокирует и с каких пор?»
- генерацию отчётов без сложных ухищрений
Если позже понадобятся графовые представления, можно моделировать рёбра в реляционных таблицах и визуализировать их в UI.
Спланируйте API‑слой для будущих интеграций
Даже если вы стартуете с одного веб‑интерфейса, проектируйте бэкенд как API, чтобы другие инструменты могли интегрироваться позже.
- REST подходит для CRUD и отчётов.
- GraphQL полезен, если много экранов требуют гибких вложенных данных.
В любом случае версионируйте API и стандартизируйте идентификаторы, чтобы интеграции не ломались.
Добавьте фоновые задачи для уведомлений и дайджестов
Уведомления не должны зависеть от обновления страницы. Используйте фоновые джобы для:
- запланированных дайджестов (ежедневных/еженедельных)
- правил эскалации (просроченные зависимости)
- повторных попыток доставки вебхуков и пакетной отправки почты
Такое разделение сохраняет приложение отзывчивым и делает уведомления надёжными при росте нагрузки.
Спланируйте интеграции с существующими инструментами
Интеграции — то, что заставляет трекер зависимостей прижиться. Если людям придётся покидать свою систему тикетов, документы или календарь, чтобы обновить зависимость, обновления отстанут и ваше приложение станет «ещё одним местом для проверки». Стремитесь встретить команды там, где они уже работают, сохраняя ваше приложение источником правды.
Начните с систем, которые люди трогают ежедневно
Приоритизируйте небольшой набор популярных инструментов — обычно это тикет‑системы (Jira/ServiceNow), документы (Confluence/Google Docs) и календари (Google/Microsoft). Цель не в зеркалировании всех полей. Цель — упростить:
- привязку зависимости к задаче, которая её реализует
- переход из вашего приложения к каноничному артефакту
- подтягивание минимальных сигналов статуса (например, «Done», срок, владелец)
Предпочитайте двунаправленные ссылки вместо полного синка
Полная синхронизация привлекательна, но порождает сложную логику разрешения конфликтов и хрупкие кейсы. Лучший паттерн — двунаправленная привязка:
- Ваше приложение хранит внешний референс (инструмент, ID, URL).
- Внешний инструмент хранит обратную ссылку на зависимость (комментарий, кастомное поле или просто URL).
Это сохраняет контекст связанным без требования идентичной модели данных.
Запланируйте импорт для первичного релиза
У большинства организаций уже есть таблица или бэклог зависимостей. Поддержите путь «быстрого старта»:
- Загрузка CSV с понятными шаблонами
- API‑импорт для продвинутых пользователей и админов
Сопровождайте импорт лёгким отчётом валидации, чтобы команды могли исправить пропущенные владельцы или даты перед публикацией.
Документируйте ограничения и обработку ошибок
Опишите, что происходит при ошибках: недостаток прав, удалённые/архивированные элементы, переименованные проекты или лимиты запросов. Показывайте действенные ошибки («Мы не можем получить доступ к этой задаче в Jira — запросите доступ или переставьте ссылку») и держите страницу состояния интеграций (например, /settings/integrations), чтобы админы могли быстро диагностировать проблемы.
Пошаговый выпуск с управлением
Внедряйте и улучшайте безопасно
Размещайте приложение на Koder.ai и используйте снимки и откат при итерациях.
Трекер зависимостей работает только если люди ему доверяют и поддерживают актуальность. Самый безопасный путь — выпустить минимальный рабочий вариант, протестировать на небольшой группе и затем ввести лёгкие правила управления, чтобы приложение не превратилось в кладбище старых записей.
Начните с минимально жизнеспособной версии (MVP)
Для первого релиза держите область узкой и очевидной:
- Записи зависимостей с понятным заголовком и коротким описанием
- Владелец (человек) и запрашивающая/предоставляющая команды
- Статусы (Draft → Proposed → Accepted → In Progress → Blocked → Done)
- Needed‑by дата (опционально, но настоятельно рекомендуется)
- Простой флаг риска/влияния
- Уведомления о назначении, изменениях статуса и приближении сроков
Если вы не можете ответить на вопросы «кто владеет этим?» и «что дальше?» из представления списка, модель слишком сложна.
Проведите пилот перед запуском во всю компанию
Выберите 1–2 кросс‑функциональные программы, где зависимости уже болезненны (запуск продукта, проект соответствия, крупная интеграция). Проведите короткий пилот 2–4 недели.
Проводите еженедельную 30‑минутную сессию обратной связи с представителями каждого отдела. Спрашивайте:
- Какие поля вы игнорируете?
- Какие обновления кажутся повторяющимися?
- Какие уведомления полезны, а какие — шум?
Используйте обратную связь пилота чтобы доработать форму, статусы и виды перед масштабированием.
Введите лёгкое управление (чтобы работа оставалась актуальной)
Управление — это не комитет, а несколько понятных правил:
- Триаж‑владелец: рол rotating duty (или небольшая ops‑команда), которая назначает нераспределённые зависимости в течение 24–48 часов.
- Политика устаревания: после X дней без активности приложение пингует владельца; после Y дней — эскалирует к программному лидеру.
- Критерии закрытия: определите, когда зависимость можно пометить Done и кто может её закрывать/переоткрывать.
Опубликуйте короткое руководство по использованию
Выпустите одностраничное руководство, объясняющее статусы, ожидания по владению и правила уведомлений. Ссылка на него должна быть внутри приложения (например, /help/dependencies).
Измеряйте успех и итеративно улучшайте
Релиз — это лишь середина пути. Трекер зависимости успешен, когда команды действительно им пользуются для упрощения передач и ускорения работы — и когда лидеры доверяют ему как источнику правды.
Отслеживайте принятие (используется ли?)
Начните с небольшого набора метрик использования, которые можно просматривать еженедельно:
- Активные пользователи по отделам (и % возвращающихся)
- Зависимости, создаваемые в неделю/месяц
- Полнота данных, особенно % с владельцем и needed‑by датой
Проблемы с принятием обычно выглядят так: люди создают записи, но их не обновляют; только одна команда логирует зависимости; записи без владельцев/дат — ничего не движется.
Отслеживайте результаты (улучшается ли доставка?)
Измеряйте, действительно ли трекер снижает трения, а не просто генерирует активность:
- Среднее время до принятия (от создания до подтверждения)
- Доля просроченных зависимостей
- Число повторно открытых элементов (закрытые, но позже восстановленные)
Если время до принятия велико — возможно, запрос неясен или процесс требует слишком много шагов. Если часто переоткрывают элементы — определение «готово» вероятно нечеткое.
Собирайте качественную обратную связь там, где происходит работа
Используйте существующие перекрёстные встречи (еженедельное планирование, release syncs) для быстрого сбора отзывов.
Спросите, какой информации не хватает при получении зависимости, какие статусы вызывают путаницу и какие обновления люди забывают делать. Ведите общий документ с повторяющимися жалобами — это лучшие кандидаты для итераций.
Планируйте небольшие циклы итераций
Фиксируйте ритм (например, каждые 2–4 недели) для улучшения:
- Поля (убирайте редко используемые; уточняйте названия; добавляйте только по частому запросу)
- Виды (страница «Мои зависимости», вид «Просроченные», простой дашборд по отделу)
- Уведомления (уменьшайте шум; фокусируйтесь на изменениях владельцев, риске по сроку и просроченных)
Трактуйте каждое изменение как продуктовую работу: опишите ожидаемое улучшение, выпустите и затем проверьте те же метрики, чтобы убедиться, что это действительно помогло.