26 июл. 2025 г.·8 мин
Как создать веб‑приложение для отслеживания исключений в бизнес‑процессах
Узнайте шаги по проектированию, созданию и запуску веб‑приложения, фиксирующего, маршрутизирующего и разрешающего исключения в бизнес‑процессах с понятными workflow и отчётностью.
Что такое исключения в бизнес‑процессах (и зачем их отслеживать)
Исключение в бизнес‑процессе — это любое событие, которое выбивает процесс из «счастливого пути» стандартного сценария: ситуация, требующая вмешательства человека, потому что обычные правила не применимы или что‑то пошло не так.
Думайте об исключениях как об операционном эквиваленте «пограничных случаев», но в повседневной работе.
Примеры, с которыми легко сопоставиться
Исключения появляются почти в каждом отделе:
- Несоответствие по счёту: сумма по счёту не совпадает с заказом, отличаются количества или отсутствует строка.
- Отсутствие утверждения: контракт подписан без нужного согласования, или расход превышает лимит без одобрения.
- Поздняя отгрузка: доставка не успела к обещанной дате, пришла частичная поставка или отправили неверный SKU.
Это не редкие случаи — они частые и создают задержки, переделки и раздражение, если нет простого способа их фиксировать и разрешать.
Почему таблицы и письма в почте не годятся
Многие команды начинают с общей таблицы и писем/чатов. Это работает — пока не перестаёт.
Строка в таблице может сказать что случилось, но часто теряет всё остальное:
- Потерянный контекст: ключевые детали живут во входящих (скриншоты, ответы поставщиков, подтверждения), а не прикреплены к записи.
- Нет ясной ответственности: люди предполагают, что кто‑то другой этим занимается, особенно когда исключение пересекает команды.
- Слабая история: трудно понять, кто и почему что‑то менял — а это важно при последующих проверках.
Со временем таблица превращается в набор частичных обновлений, дубликатов и полей «статус», которым никто не доверяет.
Что вы получаете, когда правильно отслеживаете исключения
Простое приложение для отслеживания исключений (журнал инцидентов/проблем, настроенный под ваш процесс) даёт немедленную операционную ценность:
- Более быстрое разрешение: нужного человека уведомляют, сопроводительная информация остаётся с записью, и статус виден всем.
- Меньше повторов: появляются паттерны (тот же поставщик, тот же шаг, та же брешь в согласовании), и вы можете устранять корневые причины.
- Чёткая отчётность: у каждого исключения есть владелец, сроки (SLA/цели) и задокументированный результат.
Установите ожидания: начните просто и итеративно
Вам не нужен идеальный рабочий процесс в первый день. Начните с базового набора — что случилось, кто ответственный, текущий статус и следующий шаг — а затем развивайте поля, маршрутизацию и отчётность по мере того, как поймёте, какие исключения повторяются и какие данные реально важны для принятия решений.
Определите пользователей, объём и метрики успеха
Прежде чем рисовать экраны или выбирать инструменты, чётко пропишите кому служит приложение, что оно покроет в версии 1 и как вы поймёте, что оно работает. Это убережёт от превращения «приложения для отслеживания исключений» в общий тикет‑трекер.
Идентифицируйте ключевые роли
Большинству рабочих процессов с исключениями нужны несколько понятных акторов:
- Инициатор (Requester): регистрирует исключение и даёт контекст (что случилось, когда, какой эффект).
- Утверждающий (Approver): решает, допустимо ли исключение и на каких условиях.
- Исполнитель (Resolver): устраняет проблему, выполняет обходное решение или обновляет данные.
- Владелец процесса (Process owner): отвечает за сам процесс и превентивные меры.
- Аудитор/наблюдатель (Auditor/viewer): доступ только для чтения для контроля и соответствия.
Для каждой роли опишите 2–3 ключевых права (создавать, утверждать, переназначать, закрывать, экспортировать) и решения, за которые они отвечают.
Проясните цели
Держите цели практичными и наблюдаемыми. Частые цели:
- Последовательный захват исключений (тот же минимальный набор данных каждый раз).
- Ясная собственность, чтобы ничего не простаивало.
- Документирование решений (почему исключение утверждено/отклонено и кем).
- Снижение повторов через отслеживание корневых причин и превентивных мер.
Решите, что войдёт в объём версии 1
Выберите 1–2 высокообъёмных сценария, где исключения случаются часто и стоимость задержки ощутима (например, несоответствия по счётам, удержания заказов, отсутствие документов при онбординге). Не начинайте со «всех бизнес‑процессов» сразу. Узкая область позволяет быстрее стандартизировать категории, статусы и правила утверждения.
Пропишите 3–5 метрик успеха
Определите метрики, которые можно измерять с первого дня:
- Время до разрешения (медиана и % в пределах SLA)
- Процент повторного открытия (качество закрытия)
- Объём исключений по типам (главные драйверы)
- Время цикла утверждения (запрос → решение)
- Повторы, связанные с одной и той же корневой причиной
Эти метрики станут отправной точкой для итераций и оправдают дальнейшую автоматизацию.
Пропишите жизненный цикл исключения и статусы
Ясный жизненный цикл показывает, где находится исключение, кто за него отвечает и что должно происходить дальше. Держите статусы небольшими, недвусмысленными и привязанными к реальным действиям.
Практичный базовый жизненный цикл
Created → Triage → Review → Decision → Resolution → Closed
- Created (Создано): зарегистрировано исключение с минимальным набором данных.
- Triage (Оценка/Триаж): проверка, назначение владельца и выставление срочности.
- Review (Рассмотрение): команда собирает доказательства и оценивает варианты.
- Decision (Решение): исключение утверждается/отклоняется (или запрашиваются изменения) с зафиксированной мотивацией.
- Resolution (Устранение): выполнены корректирующие действия и проведена валидация результата.
- Closed (Закрыто): запись финализирована для отчётности и аудита.
Определите критерии входа/выхода для статусов
Запишите, что должно быть истинно для перехода в каждый этап и из него:
- Created (выход): заполнены обязательные поля; выбрана категория; указан инициатор.
- Triage (выход): назначен владелец; определён влияние и срок; проверены дубликаты.
- Review (выход): приложены доказательства; опрошены заинтересованные стороны; есть рекомендация.
- Decision (выход): записано решение; указан утверждающий; зафиксированы условия (если есть).
- Resolution (выход): действия завершены; результат верифицирован; либо SLA соблюдён, либо записана причина нарушения.
- Closed (выход): добавлены финальные заметки; нет открытых задач; аудит‑трейл завершён.
Правила эскалации, чтобы исключения не застаивались
Добавьте автоматические эскалации для случаев, когда исключение просрочено (превышен срок/SLA), заблокировано (зависит от внешней стороны слишком долго) или высокоимпактно (превышен порог серьёзности). Эскалация может означать: уведомление менеджера, перенаправление на более высокий уровень утверждения или повышение приоритета.
Обработка повторного открытия и дубликатов
- Повторное открытие: если та же проблема проявилась снова (например, исправление не сработало). Требуется причина и возврат в Triage или Review.
- Дубликат: когда две записи описывают одну и ту же проблему. Обозначьте одну как «основную», свяжите дубликаты и закройте их с пометкой «Объединено», чтобы отчётность оставалась точной.
Спроектируйте модель данных и необходимые поля
Хорошее приложение для отслеживания исключений держится на корректной модели данных. Если структура слишком вольная — отчёты ненадёжны; если слишком жёсткая — пользователи не будут вводить данные. Стремитесь к небольшому набору обязательных полей и более широкому набору опциональных, но чётко определённых полей.
Основные сущности
Начните с парочки сущностей, покрывающих большинство сценариев:
- Exception (Исключение): основная запись (что случилось, где и что нужно сделать).
- Comment (Комментарий): обсуждение, уточнения и обновления прогресса.
- Attachment (Вложение): скриншоты, PDF, письма, выгрузки.
- Task (Задача): отдельные действия с назначенными исполнителями.
- Decision (Решение): утверждения/отказы, исключения из политики или решения по закрытию.
- Category (Категория): контролируемый список для чистоты отчётности.
- User (Пользователь): репортеры, исполнители, утверждающие и наблюдатели.
Обязательные поля (держите их короткими)
Сделайте обязательными для каждой записи Exception:
- Заголовок и описание (простым языком: что случилось и почему это важно)
- Категория
- Влияние (например: финансовое, клиентское, комплаенс, операционное)
- Область процесса (например: выставление счётов, исполнение, возвраты)
- Срок (Due date) или целевая дата решения
Структурированные значения, которые нужно стандартизировать
Используйте контролируемые значения вместо свободного текста для:
- Статус (Created, Triage, Review, Decision, Resolution, Closed)
- Приоритет (Низкий/Средний/Высокий/Срочный)
- Корневая причина (Человеческая ошибка, дефект системы, отсутствие данных, проблема поставщика, неясная политика)
- Тип решения (Данные скорректированы, возвращён платёж, временное решение, процесс обновлён, обучение, без действий)
Связи и трассируемость
Планируйте поля для привязки исключений к реальным бизнес‑объектам:
- Ссылки на затронутые записи (ID заказа, ID счёта, ID клиента)
- Внешние идентификаторы (тикет в ERP, дело в CRM)
- Связанные исключения (дубликаты, повторяющиеся, parent/child)
Эти связи помогут выявлять повторяющиеся проблемы и строить корректную отчётность.
Спланируйте UX и ключевые экраны
Хорошее приложение по ощущению похоже на общий почтовый ящик: все быстро видят, что требует внимания, что заблокировано и что просрочено. Начните с небольшого набора экранов, покрывающих 90% повседневной работы, а потом добавляйте мощные функции (продвинутые отчёты, интеграции).
Основные экраны для первой версии
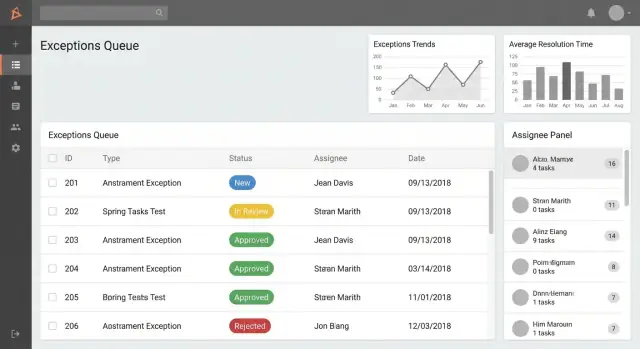
1) Список исключений / очередь (главный экран)
Здесь проводят время пользователи. Сделайте его быстрым, легко просматриваемым и ориентированным на действие.
Создайте очереди по ролям, например:
- Мои исключения (созданные мной или назначенные мне)
- Требует моего утверждения (ожидающие решения)
- Просроченные (просрочены по SLA или целевой дате)
Добавьте поиск и фильтры, которые соответствуют способу, как люди говорят о работе:
- Статус, категория, область процесса
- Диапазон дат (создано, срок, закрыто)
- Исполнитель / команда
2) Форма создания исключения
Сделайте первый шаг лёгким: несколько обязательных полей и опциональные детали под «Ещё». Подумайте о сохранении черновиков и возможности установить «исполнитель неизвестен», чтобы избежать обходных путей.
3) Страница деталей исключения
Она должна отвечать на вопросы «Что случилось? Что дальше? Кто за это отвечает?» Включите:
- Сводку, статус, владельца/исполнителя, срок/SLA
- Явные основные действия (Назначить, Запросить утверждение, Закрыть)
- Боковую панель с ключевыми метаданными
Основы совместной работы (без превращения в чат)
Добавьте:
- Комментарии с @упоминаниями для привлечения нужных людей
- Вложения для доказательств (скриншоты, PDF)
- Хронологию активности, фиксирующую изменения (обновления статуса, переназначения, утверждения), чтобы не приходилось уточнять «кто это изменил»
Админ‑настройки (минимум, но необходимо)
Дайте небольшой раздел админки для управления категориями, областями процесса, целями SLA и правилами уведомлений — чтобы операционная команда могла эволюционировать приложение без деплоя.
Выберите технологический подход и архитектуру
Настройте эскалации SLA
Прототипируйте правила просрочки и уведомления, затем уточняйте их по мере выявления паттернов исключений.
Здесь вы балансируете скорость, гибкость и долгосрочную поддерживаемость. «Правильный» выбор зависит от сложности жизненного цикла исключений, числа команд‑пользователей и требований к аудиту.
Три практичных подхода к сборке
1) Полностью кастомная разработка (полный контроль). Вы реализуете UI, API, базу данных и интеграции самостоятельно. Подходит, когда нужны настроенные рабочие процессы, строгие SLA, аудиторский след и интеграции с ERP/тикетингом. Минус — большие первичные затраты и потребность в поддержке.
2) Low‑code (быстрый запуск). В internal app‑builders можно быстро собрать формы, таблицы и базовые утверждения. Идеально для пилота или деплоймента в одном отделе. Ограничения: кастомные права, отчётность, масштабируемость и переносимость данных могут стать проблемой.
3) Vibe‑coding / агент‑помощник (быстрая итерация с реальным кодом). Если хотите скорость без потери поддерживаемой кодовой базы, платформы вроде Koder.ai помогают генерировать рабочее веб‑приложение по спецификации в диалоге — затем экспортировать исходники при необходимости. Часто команды генерируют начальный React UI и бэкенд на Go + PostgreSQL, итеративно стабилизируют workflow и используют снимки/откат при изменениях.
Простая масштабируемая архитектура
Стремитесь к разделению ответственности:
- Web UI — интерфейс для подачи, просмотра и решения исключений
- API — валидация, права и правила workflow
- База данных — хранит исключения, комментарии, метаданные вложений, решения, задачи и аудит‑события
- Фоновые задачи — уведомления, эскалации, таймеры SLA и плановые отчёты
Такая структура остаётся понятной по мере роста и упрощает добавление интеграций.
Хостинг и окружения
Планируйте минимум dev → staging → prod. Staging должен быть максимально похож на прод (особенно по аутентификации и почте), чтобы безопасно тестировать маршрутизацию, SLA и отчёты перед релизом.
Если хотите снизить управление инфраструктурой на старте — рассмотрите платформу с готовой деплоймент/хостинг поддержкой (Koder.ai, например, предлагает деплой, кастомные домены и регионы AWS) — затем можно перейти на собственное размещение после подтверждения процесса.
Трейд‑оффы стоимости и сложности
Low‑code снижает время до первой версии, но потребности в кастомизации и соответствия могут повысить затраты позже. Кастомная разработка дороже сначала, но может быть дешевле в долгосрочной перспективе, если обработка исключений критична. Часто лучший путь — быстро выпустить, валидировать процесс и иметь ясный план миграции (например, экспорт кода).
Настройте аутентификацию, роли и контроль доступа
Записи исключений часто содержат чувствительные данные (имена клиентов, финансовые корректировки, нарушения политики). Если доступ слишком свободен, риски приватности и «теневых правок» подорвут доверие к системе.
Вход и безопасные сессии
Не изобретайте пароли заново. Если в организации есть провайдер идентичности — используйте SSO (SAML/OIDC), чтобы наследовать MFA и управление доступом. Вне зависимости от механизма, уделите внимание сессиям: короткоживущие сессии, безопасные cookies, CSRF‑защита и автоматический выход для ролей высокого риска. Логируйте события аутентификации (вход, выход, неудачные попытки).
Роли и права
Определяйте роли понятным бизнес‑языком и привязывайте их к действиям в приложении. Стартовый набор:
- Reporter (Инициатор): создавать исключения, добавлять заметки/вложения, смотреть свои записи
- Assignee/Resolver (Исполнитель): редактировать поля, предлагать решение, обновлять статус
- Approver/Manager (Утверждающий/Менеджер): утверждать/отклонять, запрашивать доп. информацию, закрывать записи
- Admin (Администратор): настраивать систему (не ежедневная операционная работа)
Будьте явны по поводу удаления: многие команды блокируют жёсткое удаление и разрешают лишь архивирование администраторами для сохранения истории.
Доступ на уровне записи
Кроме ролей, добавьте правила видимости по департаменту, команде, локации или области процесса. Шаблоны:
- Пользователи видят созданные ими и назначенные их команде записи
- Менеджеры видят всё в пределах их организационной единицы
- Роли аудита видят записи по всему предприятию в режиме read‑only
Это предотвращает «свободный просмотр», сохраняя коллаборацию.
Необходимые админ‑возможности
Админы должны управлять категориями, SLA (сроки, пороги эскалации), шаблонами уведомлений и назначениями ролей. Требуйте повышения подтверждения для изменений с сильным влиянием (например, редактирование SLA), так как это влияет на отчётность и ответственность.
Постройте рабочие процессы, маршрутизацию и уведомления
Стандартизируйте категории для отчетности
Настройте категории, причины и типы решений, чтобы отчёты были надёжными.
Именно рабочие процессы превращают простой журнал в инструмент, на который можно опереться. Цель — предсказуемое движение: у каждого исключения должен быть ясный владелец, следующий шаг и срок.
Правила маршрутизации: кто что получает и когда
Начните с небольшого набора простых и объяснимых правил. Маршрутировать можно по:
- Категории (качество данных, отклонение от политики, сбой системы)
- Влиянию (финансовая сумма, число затронутых клиентов, уровень серьёзности)
- Области процесса (AP/AR, онбординг, исполнение)
- Порогам (например, «Сумма > $10,000» или «Высокая серьёзность»)
Держите правила детерминированными: если несколько правил совпадают, задайте порядок приоритета и безопасный фолбэк (например, очередь «Triage»), чтобы ничего не оставалось без владельца.
Утверждения: простые, многошаговые и оверрайды
Многие исключения требуют утверждения перед принятием решения или закрытием.
Продумайте два распространённых паттерна:
- Один утверждающий: один человек утверждает/отклоняет (самый быстрый вариант).
- Многошаговое утверждение: последовательность, например Менеджер → Комплаенс → Финансы.
Будьте явны по поводу того, кто может переопределить (и при каких условиях). Если переопределение разрешено — требуйте причину и записывайте её в аудит‑трейл (например, «Одобрено через оверрайд из‑за риска нарушения SLA»).
Уведомления, которые не раздражают
Добавьте email и in‑app уведомления для ключевых событий, меняющих владельца или срочность:
- Назначение и переназначение
- Новые комментарии или упоминания
- Запрос на утверждение / утверждение / отказ
- Просроченные и напоминания «скоро срок»
Пусть пользователи настраивают необязательные уведомления, но держите критичные (назначение, просрочка) включёнными по умолчанию.
Делайте работу по разрешению видимой через задачи/чек‑листы
Исключения часто проваливаются, когда работа происходит «в стороне». Добавьте лёгкие задачи или чек‑листы, привязанные к исключению: у каждой задачи есть владелец, срок и статус. Это делает прогресс отслеживаемым, улучшает передачи и даёт менеджерам представление о блокерах.
Добавьте отчётность и операционные дашборды
Отчёты — это то место, где журнал исключений перестаёт быть просто списком и становится операционным инструментом. Цель — помогать лидерам раннее выявлять паттерны и помогать командам решать, над чем работать дальше — без открытия каждой записи по отдельности.
Стандартные отчёты
Начните с небольшого набора отчётов, которые уверенно отвечают на частые вопросы:
- Объём во времени (дневной/недельный/месячный): растут ли исключения, есть ли сезонность?
- По категориям/причинам: какие типы создают наибольшие проблемы?
- По командам/владельцам: где концентрируется нагрузка?
- По статусу: сколько в каждой стадии (Created, Triage, Review, Decision, Resolution, Closed)?
Держите визуализацию простой (линия для трендов, столбцы для распределений). Главное — согласованность: пользователи должны доверять, что отчёт соответствует списку исключений.
Отслеживание производительности и SLA
Добавьте операционные метрики, отражающие здоровье обслуживания:
- Среднее время решения (и медиана, если возможно)
- Процент нарушений SLA (доля исключений, превысивших целевой срок)
- Размер бэклога (открытые исключения) и старение (сколько открыто уже)
Если вы храните метки времени вроде created_at, assigned_at и resolved_at, эти метрики становятся простыми и понятными.
Детализация, экспорт и плановые сводки
Любой график должен поддерживать детализацию: клик по столбцу переводит пользователя на отфильтрованный список (например, «Категория = Доставка, Статус = Open»). Это делает дашборды применимыми.
Для обмена и оффлайн‑анализа предоставьте CSV‑экспорт как из списка, так и из ключевых отчётов. Для заинтересованных сторон добавьте плановые сводки (еженедельная почта или in‑app дайджест) с изменениями трендов, топ‑категориями и нарушениями SLA, со ссылками на отфильтрованные представления (/exceptions?status=open&category=shipping).
Обеспечьте аудируемость и базовые требования соответствия
Если приложение влияет на утверждения, платежи, результаты для клиентов или регуляторные отчёты, вам придётся отвечать на вопрос: «Кто что сделал, когда и почему?» Построение аудита с самого начала предотвращает поздние переделки и даёт уверенность, что запись заслуживает доверия.
Ведите неоспоримый журнал активности
Создайте полный журнал активности для каждой записи исключения. Логируйте актёра (пользователь или система), временную метку (с таймзоной), тип действия (создано, поле изменено, переход статуса) и значения до/после.
Делайте журнал добавляемым (append‑only). Правки должны добавлять события, а не перезаписывать историю. Если нужно исправить ошибку, фиксируйте событие «коррекция» с объяснением.
Храните решения с причинами и доказательствами
Утверждения и отказы должны быть полноценными событиями, а не просто сменой статуса. Захватывайте:
- Решение (утверждено/отклонено/возвращено)
- Код причины + текстовое объяснение (обязательно для ключевых решений)
- Вложения (скриншоты, PDF, письма) и кто их загрузил
Это ускоряет ревью и сокращает переписку, когда кто‑то спрашивает, почему исключение было принято.
Политики хранения и удаления (определяйте их сознательно)
Определите, как долго хранятся записи, вложения и логи. Для многих организаций безопасный диапазон:
- Хранить записи и события аудита фиксированный период (например, 3–7 лет)
- Ограничить удаление небольшой группой админов с обязательной мотивацией
- Предпочитать «мягкое удаление» (скрытие из обычных представлений) при сохранении аудита
Согласуйте политику с внутренним управлением и юридическими требованиями.
Проектируйте для ревью и аудита
Аудиторы и проверяющие ценят скорость и ясность. Добавьте фильтры специально для ревью: по диапазону дат, владельцу/команде, статусу, кодам причин, нарушению SLA и результатам утверждений.
Предоставьте печатные сводки и экспортируемые отчёты, включающие неизмениюемую историю (хронология событий, заметки по решениям и список вложений). Правило: если вы не можете восстановить полную историю из записи и её лога — система ещё не готова для аудита.
Тестируйте, пилотируйте и разворачивайте
Генерируйте дашборды из метрик
Преобразуйте метрики успеха в дашборды с возможностью углубления по статусу, владельцу и категории.
Тестирование и запуск — это момент, когда идея превращается в надёжный инструмент. Сосредоточьтесь на нескольких потоках, которые происходят каждый день, затем расширяйте.
Протестируйте ключевые сценарии end‑to‑end
Составьте простой тест‑скрипт (например, в таблице), проходящий по полному жизненному циклу:
- Создать исключение, прикрепить файл и убедиться, что обязательные поля требуются.
- Назначить на правильного человека/команду и проверить видимость у них.
- Пути утверждения/отказа: каждая операция фиксирует причину и временную метку.
- Закрыть исключение и убедиться, что оно становится доступно только для чтения (или с ограничениями на редактирование).
- Повторно открыть и проверить, что история чётко показывает, что изменилось.
Добавьте «реальные» вариации: изменение приоритета, переназначения и просрочки, чтобы проверить расчёты SLA и времени решения.
Валидация и обработка ошибок, предотвращающая «плохие» данные
Большинство проблем с отчётностью происходит из‑за несогласованного ввода. Ранние защитные механизмы:
- Обязательные поля (область процесса, тип исключения, владелец, срок)
- Ограничения на размер/тип файлов с понятными сообщениями
- Детекция дубликатов (например, тот же клиент/заказ/дата) с опцией «связать с существующей»
- Безопасная обработка крайних случаев: отсутствующий исполнитель, некорректные даты, удалённые пользователи
Тестируйте также негативные сценарии: прерывание сети, истёкшая сессия и ошибки прав доступа.
Проведите пилот с одной командой
Выберите команду с достаточным объёмом, чтобы быстро учиться, но небольшую, чтобы оперативно вносить изменения. Пилот 2–4 недели, затем ревью:
- Захватывают ли поля то, что людям действительно нужно?
- Соответствуют ли статусы реальному ходу работы?
- Помогают ли уведомления — или они мешают?
Вносите изменения каждую неделю, но зафиксируйте workflow на последней неделе ради стабилизации.
Развёртывание с простым набором материалов
Сделайте запуск лёгким:
- Одностраничное «Как мы пользуемся приложением» (статусы, правила ответственности, SLA)
- Короткая сессия обучения (15–30 минут) и запись
- Чек‑лист запуска: доступы/роли, маршрутизация по умолчанию, шаблоны и контакт поддержки
После запуска наблюдайте за показателями использования и состоянием бэклога ежедневно первую неделю, затем еженедельно.
Поддержка, улучшение и масштабирование со временем
Релиз — это только начало: нужно поддерживать журнал исключений точным, быстрым и синхронизированным с тем, как бизнес реально работает.
Отслеживайте использование и узкие места
Относитесь к потоку исключений как к операционной трубе. Анализируйте, где элементы застревают (по статусу, команде, владельцу), какие категории доминируют и реалистичны ли SLA.
Простая месячная проверка часто включает:
- Медиану и 90‑й процентиль времени решения по категориям
- Счётчики «старых» задач (открыто > 7/30/60 дней)
- Процент повторного открытия и циклы «отправлено обратно»
- Топ полей, остающихся пустыми (символизирует проблемы UX)
Используйте выводы для тонкой настройки статусов, обязательных полей и правил маршрутизации — без постоянного усложнения.
Ведите бэклог итераций
Создайте лёгкий бэклог для запросов от операторов, утверждающих и комплаенса. Типичные элементы:
- Новые поля (только если они реально нужны для отчётов или решений)
- Автоматизации (автоназначение по категории, дефолтные сроки)
- Шаблоны для распространённых типов исключений
- Небольшие UI‑правки, уменьшающие ошибки классификации
Приоритизируйте то, что сокращает цикл или предотвращает повторы.
Интеграции: начните с безопасного уровня, затем углубляйтесь
Интеграции увеличивают ценность, но добавляют риски и поддержку. Начните со связей только для чтения:
- Храните внешние ID (ERP/CRM/тикетинг)
- Давайте deep‑link в исходную систему (например, заказ, клиент, счёт)
Когда процесс стабилен — переходите к выборочным обратным записям (обновления статуса, комментарии) и синхронизации на основе событий.
Назначьте ясную ответственность
Определите владельцев для самых меняющихся частей:
- Таксономия категорий (когда сливать/удалять категории)
- Определение SLA и правил эскалации
- Правила маршрутизации и уведомлений
Когда владение явное — приложение остаётся надёжным при росте объёмов и реорганизациях.
Замечание по поддержанию скорости разработки
Отслеживание исключений редко «заканчивается» — оно меняется по мере того, как команды понимают, что стоит предотвращать, автоматизировать или эскалировать. Если ожидаются частые изменения, выбирайте подход, делающий итерации безопасными (feature flags, staging, rollback) и который держит вас в контроле над кодом и данными. Платформы вроде Koder.ai часто используются для быстрой первоначальной версии (Free/Pro уровни подходят для пилотов), а затем масштабируются до Business/Enterprise по мере роста требований к управлению, доступу и деплою.