Уточните цель и область приложения
Прежде чем проектировать экраны или выбирать стек технологий, чётко пропишите, что под «операционным риском» понимает ваша организация. Для одних команд это сбои процессов и человеческие ошибки; другие включают сбои ИТ, проблемы с поставщиками, мошенничество или внешние события. Если определение размыто, приложение превратится в свалку — и отчёты будут ненадёжны.
Определите, что вы будете отслеживать
Напишите ясное заявление о том, что считается операционным риском и что нет. Можно разбить по четырём корзинам (процессы, люди, системы, внешние события) и привести по 3–5 примеров для каждой. Это уменьшит споры в дальнейшем и обеспечит согласованность данных.
Согласуйте ожидаемые результаты
Конкретизируйте, чего приложение должно достичь. Общие цели включают:
- Видимость: единое место для рисков, контролей, инцидентов и действий
- Ответственность: у каждого элемента есть именованный владелец и дата выполнения
- Отслеживание устранения: действия переходят от «открыто» к «проверено» с доказательствами
- Отчётность и готовность к аудиту: можно объяснить, что изменилось, когда и почему
Если вы не можете описать результат, это, вероятно, запрос на фичу, а не требование.
Определите основных пользователей
Перечислите роли, которые будут использовать приложение, и что им нужно в первую очередь:
- Владелцы рисков (идентифицируют и обновляют риски)
- Владельцы контролей (подтверждают контроли, прикладывают доказательства)
- Рецензенты (утверждают изменения, просят обновления)
- Аудиторы (только чтение, прослеживаемость)
- Администраторы (доступ пользователей, конфигурация)
Это предотвращает проектирование «для всех» и неудовлетворение ни одного типа пользователей.
Задайте реалистичный объём для v1
Практичный v1 обычно фокусируется на: реестре рисков, базовой оценке рисков, отслеживании действий и простых отчётах. Глубокие возможности (сложные интеграции, управление таксономией, конструкторы рабочих процессов) оставьте для следующих этапов.
Определите метрики успеха
Выберите измеримые сигналы, например: процент рисков с назначенными владельцами, полнота реестра, время закрытия действий, доля просроченных действий и своевременное завершение пересмотров. Эти метрики помогут понять, работает ли приложение и что улучшать.
Сбор требований у заинтересованных сторон
Веб‑приложение реестра рисков работает только в том случае, если оно соответствует тому, как люди реально идентифицируют, оценивают и сопровождают операционный риск. Прежде чем обсуждать фичи, поговорите с теми, кто будет пользоваться результатами (или по ним оцениваться).
Кого привлекать (и зачем)
Начните с небольшой репрезентативной группы:
- Владельцы бизнес‑единиц, которые ежедневно создают и управляю рисками
- Риск/Комплаенс, которые определяют терминологию, ожидания по оценкам и требования к отчётности
- Внутренний аудит, которому важны доказательства, утверждения и полнота аудита‑трейла
- IT/Безопасность, которые просмотрят доступы, хранение данных и интеграции
- Руководство/совет, которое потребляет сводки и трендовые отчёты
Смоделируйте текущий процесс от начала до конца
На воркшопах пройдите реальный рабочий поток шаг за шагом: идентификация риска → оценка → лечение → мониторинг → пересмотр. Фиксируйте, где принимаются решения (кто что утверждает), что считается «сделано» и что запускает пересмотр (по времени, по инциденту или по порогу).
Зафиксируйте болевые точки, которые нужно решить
Попросите заинтересованных показать текущую таблицу или цепочку писем. Документируйте конкретные проблемы, например:
- Отсутствие владельца (неясно, кто владеет риском, контролем или действием)
- Неконсистентная оценка (команды по‑разному трактуют вероятность/влияние)
- Слабые аудиторские следы (нет записи о том, кто и почему что‑то изменил)
- Путаница версий (несколько копий «последней» версии реестра)
Задокументируйте необходимые рабочие процессы и события
Пропишите минимальные рабочие процессы, которые приложение должно поддерживать:
- Создать новый риск (с обязательными полями и правилами утверждения)
- Обновить риск (переоценка, смена статуса, добавление заметок)
- Зарегистрировать инцидент и связать его с рисками/контролями
- Зафиксировать результаты тестирования контроля и доказательства
- Создать и отслеживать план действий (сроки, напоминания, эскалация)
Определите отчёты, от которых зависят люди
Согласуйте выходные отчёты заранее, чтобы избежать переделок. Частые запросы: сводка для совета, виды по бизнес‑единицам, просроченные действия, топ‑риски по оценке или тренду.
Учитывайте ограничения по соответствию (не обещая сертификатов)
Перечислите правила, которые влияют на требования — например: сроки хранения данных, ограничения конфиденциальности для данных инцидентов, разделение обязанностей, доказательства утверждений и ограничения доступа по региону/юридическому лицу. Фиксируйте это как ограничения, а не как автоматическое соответствие стандартам.
Спроектируйте рамки оценки риска и терминологию
Прежде чем строить экраны или рабочие процессы, договоритесь о словаре, который будет использовать приложение. Ясная терминология предотвращает ситуации «один и тот же риск разными словами» и делает отчёты надёжными.
Начните с практичной таксономии рисков
Определите, как группировать и фильтровать риски в реестре. Делайте таксономию полезной как для повседневной работы, так и для дашбордов и отчётов.
Типичные уровни: категория → подкатегория, с привязкой к бизнес‑единицам и (по необходимости) процессам, продуктам или локациям. Избегайте чрезмерной детализации, при которой пользователи теряются; таксономию можно уточнять позже по мере накопления паттернов.
Стандартизируйте формулировку риска и обязательные поля
Договоритесь о едином формате описания риска (например: «Из‑за причины, событие может произойти, что приведёт к влиянию»). Решите, какие поля обязательны:
- причина, событие, влияние (для полезного анализа)
- владелец риска и команда (для ответственности)
- статус (черновик, активен, на пересмотре, снят с учёта)
- даты (выявлен, последняя оценка, следующий пересмотр)
Такая структура связывает контроли и инциденты с единым повествованием, а не с разбросанными заметками.
Определите измерения оценки и шкалу
Выберите измерения, которые будут в модели оценки. Минимум — вероятность и влияние; скорость распространения и детектируемость добавляют ценности, если команды смогут оценивать их согласованно.
Решите, как учитывать «наврожденный» и «остаточный» риск. Общий подход: сначала оцениваем наврожденный риск (до контролей), затем остаточный — после существующих контролей, причём контролы явно связаны с расчётом, чтобы логику можно было объяснить при проверках.
Наконец, согласуйте простую шкалу (обычно 1–5) и дайте определения в обычном языке для каждого уровня. Если «3 = средний» означает разное для разных команд, оценки будут генерировать шум вместо инсайтов.
Создайте модель данных (реестр рисков, контроли, действия)
Чёткая модель данных превращает регистр в систему, которой можно доверять. Стремитесь к небольшому набору основных сущностей, чистым связям и согласованным справочникам, чтобы отчётность оставалась надёжной по мере роста использования.
Основные сущности (минимальная рабочая схема)
Начните с таблиц, которые напрямую отражают работу людей:
- Пользователи и Роли: кто в системе и что может делать
- Риски: запись реестра (заголовок, описание, владелец, бизнес‑область, наврожденные/остаточные оценки, статус)
- Оценки: точечные оценки (дата, оценщик, входные параметры, заметки). Отдельная сущность защищает от перезаписи «текущего вида».
- Контроли: меры, связанные с рисками (эффективность дизайна/операций, периодичность тестирования, владелец контроля)
- Инциденты/События: что произошло (дата, влияние, первопричина, связанные риски, связанные отказы контролей)
- Действия: задачи по устранению, привязанные к риску, контролю или инциденту
- Комментарии: обсуждения и решения, желательно с упоминаниями @ и метками времени
Связи, важные для прослеживаемости
Моделируйте ключевые связи многие‑ко‑многим явно:
- Risk ↔ Controls (через таблицу связки) — показывает, какие контроли снижают какие риски
- Risk ↔ Incidents — связывает реальные потери/околопроисшествия с реестром
- Actions → Risk/Control/Incident (полиморфная ссылка или три nullable внешних ключа) — чтобы задачи всегда были привязаны
Эта структура отвечает на вопросы вроде «Какие контроли снижают наши топ‑риски?» или «Какие инциденты вызвали изменение оценки риска?»
Таблицы истории и «почему это изменилось?»
Операционное отслеживание рисков часто требует защищённой истории изменений. Добавьте таблицы истории/аудита для Risks, Controls, Assessments, Incidents и Actions с:
- кто изменил, когда и какие поля изменились
- опциональная причина изменения (текст или набор кодов)
Избегайте хранения только «последнего обновления», если ожидаются проверки и утверждения.
Справочники для согласованности
Используйте справочники (а не строковые константы) для таксономии, статусов, шкал вероятности/серьёзности, типов контролей и состояний действий. Это предотвращает поломку отчётов из‑за опечаток («High» vs «HIGH»).
Вложения (доказательства) с учётом хранения
Рассматривайте доказательства как первичную сущность: таблица Attachments с метаданными файла (имя, тип, размер, загрузивший, связанная запись, дата загрузки) и полями для даты удаления/удаления и классификации доступа. Файлы храните в объектном хранилище, а правила управления — в базе данных.
Спланируйте рабочие процессы, утверждения и ответственность
Приложение быстро проваливается, когда «кто что делает» неясно. Прежде чем строить экраны, определите состояния рабочего процесса, кто может переводить элементы между состояниями и что должно фиксироваться на каждом шаге.
Роли и права (держите их простыми)
Начните с небольшого набора ролей и расширяйте по мере необходимости:
- Создатель: может черновать новые риски, контроли, инциденты и действия
- Владелец риска: отвечает за точность записи и регулярные пересмотры
- Утверждающий: подтверждает записи и может пометить их как «официальные»
- Аудитор / только для чтения: может просматривать, экспортировать и (опционально) комментировать, но не редактировать
- Админ: управляет конфигурацией, пользователями и разрешениями
Делайте права явными по типу объекта (риск, контроль, действие) и по возможностям (создавать, редактировать, утверждать, закрывать, открывать).
Поток утверждения: draft → review → approved → re‑review
Используйте понятный жизненный цикл с предсказуемыми воротами:
- Черновик: редактируемый; допускаются неполные поля
- На рассмотрении: изменения ограничены; требуются комментарии рецензента
- Утверждён: ключевые поля блокируются; изменения требуют формального запроса на обновление
- Периодический пересмотр: плановые контрольные точки (например, ежеквартально)
SLA, напоминания и логика просрочки
Привяжите SLA к циклам пересмотра, тестированию контролей и срокам действий. Отправляйте напоминания до срока, эскалируйте после пропуска SLA и явно показывайте просроченные элементы (для владельцев и их менеджеров).
Делегирование, переназначение и ответственность
У каждого элемента должен быть один ответственный владелец плюс опциональные соавторы. Поддерживайте делегирование и переназначение, но требуйте причину (и опционально дату вступления в силу), чтобы читатели понимали, почему и когда сменился ответственный.
Проектирование UX и ключевых экранов
Соберите заинтересованные стороны в одном месте
Объедините владельцев рисков, рецензентов и аудиторов в одной рабочей области, чтобы протестировать права доступа и рабочие процессы.
Приложение по рискам успешно, когда люди им реально пользуются. Для нетехнических пользователей лучший UX — предсказуемый, с минимальным трением и понятными метками: минимум жаргона и достаточно подсказок, чтобы избежать размытых «прочих» записей.
1) Приём риска: сделайте правильные данные значением по умолчанию
Форма ввода должна ощущаться как управляемая беседа. Добавьте короткие подсказки под полями (не длинные инструкции) и помечайте действительно обязательные поля.
Включите обязательные поля: заголовок, категория, процесс/область, владелец, текущий статус, начальная оценка и «почему это важно» (нарратив последствий). Если вы используете оценивание, встраивайте тултипы рядом с факторами, чтобы пользователи могли сразу видеть определения.
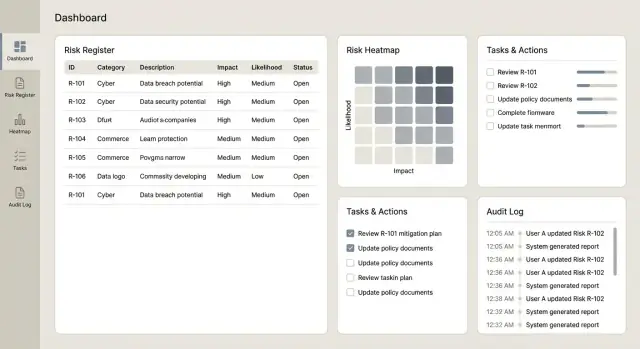
2) Список рисков: триаж и дальнейшие действия в одном месте
Большинство пользователей будут жить в виде списка, поэтому сделайте его быстрым в ответах на вопрос «что требует внимания?»
Добавьте фильтры и сортировку по статусу, владельцу, категории, оценке, дате последнего пересмотра и просроченным действиям. Подчёркивайте исключения (просрочки, истёкшие пересмотры) аккуратными бейджами — не везде кричащие цвета — чтобы внимание шло к действительно важным элементам.
3) Страница детали риска: одна история, связанные записи
Экран детали должен сначала давать сводку, затем подробности. Верхняя часть — описание, текущая оценка, дата последнего пересмотра, дата следующего пересмотра и владелец.
Ниже отображайте связанные контроли, инциденты и действия отдельными секциями. Добавьте комментарии для контекста («почему мы изменили оценку») и вложения как доказательства.
4) Трекер действий: превращайте решения в закрытие
Действия нуждаются в назначении, сроках, прогрессе, загрузке доказательств и чётких критериях закрытия. Сделайте закрытие явным: кто утверждает закрытие и какие доказательства требуются.
Если нужен эталонный макет, держите навигацию простой и согласованной (например: /risks, /risks/new, /risks/{id}, /actions).
Реализация логики оценки и пересмотров
Оценка — то место, где приложение становится практически полезным. Цель не «оценивать» команды, а стандартизировать сравнение рисков, приоритизацию и предотвращение устаревания записей.
Выберите (и задокументируйте) модель оценки
Начните с простой объяснимой модели, которая работает в большинстве команд. Частый дефолт — шкала 1–5 для Вероятности и Влияния, с расчётом:
- Оценка = Вероятность × Влияние
Дайте чёткие определения для каждого значения (что означает «3», не только число). Разместите эту документацию рядом с полями в UI (тултипы или «Как работает оценка»), чтобы пользователям не приходилось её искать.
Сделайте пороги значимыми и свяжите их с действиями
Числа сами по себе не меняют поведения — пороги это делают. Определите границы для Низкий / Средний / Высокий (и опционально Критический) и решите, что каждый уровень инициирует.
Примеры:
- Высокий: требует владельца, целевой даты и утверждения руководства перед закрытием
- Средний: требует плана смягчения, но не всегда утверждения
- Низкий: отслеживать и пересматривать; немедленных действий не требует
Держите пороги настраиваемыми — «Высокий» для одной бизнес‑единицы может отличаться от другой.
Отслеживайте наврожденный и остаточный риск
Часто обсуждения заходят в тупик, когда стороны говорят о разных понятиях. Разделите:
- Наврожденный риск: до учёта контролей
- Остаточный риск: после учёта контролей
В UI показывайте оба значения рядом и показывайте, как контролы влияют на остаточный риск (например, контроль уменьшает вероятность или влияние на 1). Не прячьте логику за автоматическими корректировками, которые пользователи не могут объяснить.
Постройте настраиваемые правила пересмотра
Добавьте правила пересмотра по времени, чтобы риски не устаревали. Практический базовый подход:
- Высокие риски: пересмотр ежеквартально
- Средние риски: пересмотр полугодно
- Низкие риски: пересмотр ежегодно
Сделайте частоту пересмотра настраиваемой для бизнес‑единиц и позвольте переопределение для отдельного риска. Автоматизируйте напоминания и статус «пересмотр просрочен» на основе даты последнего пересмотра.
Избегайте «чёрного ящика» в расчётах
Отображайте расчёт: Вероятность, Влияние, любые корректировки контролей и итоговую остаточную оценку. Пользователь должен уметь ответить «почему это Высокий?» одним взглядом.
Постройте аудит‑трейл, версионность и обработку доказательств
Проверьте UX на реальном интерфейсе
Разверните страницы ввода, списка и деталей, чтобы пользователи могли протестировать рабочий процесс вместо обсуждений.
Инструмент по операциям ценен настолько, насколько верна его история. Если оценка меняется, контроль помечен как «проверен», или инцидент переклассифицирован — нужно ответить: кто, что, когда и почему.
Решите, что аудировать (и сделайте это явно)
Начните со списка событий, чтобы не пропустить важное и не засорить журнал шумом. Частые события:
- создание/обновление/удаление основных объектов (риски, контроли, инциденты, действия)
- решения по утверждениям (отправлено, утверждено, отклонено) и смены владельцев
- экспорты (CSV/PDF) — особенно для регулируемых команд
- события аутентификации (входы, сбросы паролей) и изменения прав
Фиксируйте «кто/когда/что» плюс контекст
Минимум: актор, отметка времени, тип/ID объекта и изменённые поля (старое значение → новое). Добавьте опциональную «причину изменения» — это предотвращает путаницу («изменили остаточную оценку после квартального пересмотра»).
Держите журнал append‑only. Не позволяйте редактировать записи, даже администраторам; если нужен исправительный шаг — создавайте новое событие с ссылкой на предыдущее.
Предоставьте вид журнала только для чтения
Аудиторы и админы обычно нуждаются в отдельном фильтруемом представлении: по диапазону дат, по объекту, по пользователю и по типу события. Сделайте экспорт удобным, при этом логируя сам факт экспорта. Если есть админская область, дайте ссылку из /admin/audit-log.
Версионируйте доказательства и предотвращайте тихие перезаписи
Вложения (скриншоты, результаты тестов, политики) должны версионироваться. Каждый загруз — новая версия с отметкой времени и автором; предыдущие файлы сохраняются. Если замена разрешена, требуйте заметку с причиной и сохраняйте обе версии.
Определите правила хранения и доступа к чувствительным доказательствам
Установите правила хранения (например, хранить события аудита X лет; удалять доказательства через Y, если нет юридического удержания). Ограничьте доступ к доказательствам строже, чем к записи риска, если там есть персональные данные или детали безопасности.
Учтите безопасность, приватность и контроль доступа
Безопасность и приватность — не «опция» для приложения по рискам; они определяют, насколько комфортно людям регистрировать инциденты, прикладывать доказательства и назначать владельцев. Начните с карты того, кто должен видеть что и что нужно ограничить.
Аутентификация: SSO vs email/password
Если в вашей организации уже есть провайдер идентификации (Okta, Azure AD, Google Workspace), отдайте приоритет SSO через SAML или OIDC. Это снижает риск паролей, упрощает on/offboarding и согласуется с корпоративной политикой.
Для небольших команд или внешних пользователей email/password подойдёт, но сочетайте с жёсткими требованиями к паролям, безопасным восстановлением аккаунта и (по возможности) MFA.
RBAC, соответствующий реальному процессу работы
Определите роли, отражающие реальные обязанности: админ, владелец риска, рецензент/утверждающий, участник, только для чтения, аудитор.
Операционные риски часто требуют более строгих границ, чем обычный внутренний инструмент. Рассмотрите RBAC с ограничениями:
- по бизнес‑единице/департаменту (например, Финансы не видит HR‑инциденты)
- по записям (например, только команда расследования видит чувствительный инцидент)
Делайте права понятными — пользователи должны быстро понимать, почему они видят или не видят запись.
Базовые меры защиты данных, обязательные для исполнения
Используйте шифрование в транзите (HTTPS/TLS) повсеместно и принцип наименьших привилегий для сервисов и баз данных. Сессии защищайте secure cookies, короткими таймаутами простоя и серверной инвалидизацией при выходе.
Чувствительные поля и редактирование
Не каждое поле равно по риску. Текст инцидента, данные о клиентах или сотрудниках могут требовать более строгого контроля. Поддерживайте поле‑уровневую видимость или хотя бы редактирование/редакцию, чтобы пользователи могли сотрудничать, не раскрывая чувствительные данные.
Защитные меры для администраторов
Добавьте практичные ограничения:
- логи активности админов (кто сменил права, сделал экспорт, конфигурацию)
- опциональные IP‑белые списки для особо рисковых сред
- MFA для админов (даже если другие пользователи его не используют)
Такие меры защищают данные, сохраняя рабочие процессы и отчётность удобными.
Доставьте дашборды, отчёты и экспорт
Дашборды и отчёты — это место, где приложение доказывает ценность: они превращают длинный реестр в понятные решения для владельцев, менеджеров и комитетов. Главное — чтобы числа можно было проследить до расчёта и исходных записей.
Дашборды, которыми будут пользоваться люди
Начните с небольшого набора высокосигнальных представлений, которые быстро отвечают на частые вопросы:
- Топ‑риски по остаточной оценке (с возможностью переключиться на наврожденную)
- Тренды во времени (остаточная оценка по месяцам/кварталам)
- Распределение остаточной vs. наврожденной оценки, включая «до/после контролей»
- Тепловая карта рисков (вероятность × влияние) с ссылкой на риски из ячейки
Делайте плитки кликабельными, чтобы пользователь мог перейти к списку рисков, контролей, инцидентов и действий, стоящих за графиком.
Операционные представления для повседневного управления
Дашборды для принятия решений отличаются от оперативных видов. Добавьте экраны, ориентированные на задачи на неделю:
- Просроченные действия (по владельцу/команде, с количеством дней просрочки)
- Предстоящие пересмотры (риски или контроли, у которых срок приближается)
- Неуспешные тесты контролей (последние провалы, серьёзность, открытые корректировки)
- Частота инцидентов (количества и ставки по времени, с фильтрами по процессам/категориям)
Эти виды хорошо сочетаются с напоминаниями и ответственностью, чтобы приложение ощущалось как рабочий инструмент, а не просто база данных.
Экспорт для комитетов и аудита
Спланируйте экспорт заранее, потому что комитеты часто полагаются на офлайн‑пакеты. Поддерживайте CSV для анализа и PDF для распространения, с:
- фильтрами (бизнес‑единица, категория, владелец, статус)
- диапазонами дат (инциденты за период, действия созданные/закрытые в период)
- понятными метками (наврожденный vs остаточный, даты версий и применённые фильтры)
Если у вас уже есть шаблон governance‑пака, воспроизведите его структуру, чтобы упростить принятие.
Согласованность и производительность в масштабе
Убедитесь, что определение отчёта совпадает с вашими расчётами. Например, если дашборд ранжирует «топ‑риски» по остаточной оценке — это должно совпадать с расчётом на карточке риска и в экспорте.
Для больших реестров проектируйте на производительность: постраничная загрузка списков, кэширование для распространённых агрегатов и асинхронная генерация отчётов (генерировать в фоне и уведомлять, когда готово). Сохраняйте конфигурации отчётов внутренними ссылками (например, /reports), если будете добавлять плановые отчёты.
План интеграций и миграции данных
Безопасно запустите пилот
Выпустите внутреннюю бета-версию с встроенным хостингом и развёртыванием, затем улучшайте продукт по обратной связи.
Интеграции и миграция определяют, станет ли приложение системой учёта — или ещё одним местом, которое забывают обновлять. Планируйте их заранее, реализуйте постепенно, чтобы ядро оставалось стабильным.
Начните с рабочих процессов, которыми уже пользуются люди
Большинству команд не нужен «ещё один список задач». Они хотят, чтобы приложение соединялось с инструментами исполнения:
- Jira или ServiceNow для создания и отслеживания задач‑действий (и синхронизации статуса обратно)
- Slack или Microsoft Teams для оповещений о эскалациях, сроках пересмотров или запросах доказательств
- Email для напоминаний по периодическим пересмотрам и утверждениям (полезно для редких пользователей)
Практичный подход — сохранить риск‑приложение как источник истины по данным о рисках, а внешние инструменты использовать для исполнения и возвращать прогресс обратно.
Заселите реестр из таблиц — безопасно
Многие начинают с Excel. Предложите импорт, который принимает распространённые форматы, но добавьте защиту:
- Правила валидации (обязательные поля, форматы дат, числовые диапазоны)
- Обнаружение дубликатов (напр., одинаковый заголовок + процесс + владелец) с опцией «merge/skip»
- Принуждение таксономии (бизнес‑единица, процесс, категория)
Покажите предварительный просмотр того, что будет создано/отвергнуто и почему. Один экран превью может сэкономить часы переписок.
API‑основы, чтобы уменьшить будущие проблемы
Даже если у вас одна интеграция, проектируйте API так, будто их будет несколько:
- консистентные эндпоинты и наименования (например, /risks, /controls, /actions)
- логирование на записи (кто, когда и откуда менял)
- rate limiting и понятные коды ошибок, чтобы интеграции падали аккуратно
Обрабатывайте ошибки с ретраями и видимым статусом
Интеграции терпят ошибки: истёкшие токены, таймауты сети, удалённые тикеты. Подготовьтесь:
- очередь исходящих запросов с ретраями и backoff
- статус синхронизации на каждом связанном объекте («Synced», «Pending», «Failed»)
- понятные сообщения действий («Токен ServiceNow истёк — переподключите») и кнопка «Повторить сейчас»
Это сохраняет доверие и предотвращает тихой рассинхронизации реестра и инструментов исполнения.
Тестируйте, запускайте и улучшайте со временем
Ценность приложения растёт, когда люди ему доверяют и используют регулярно. Рассматривайте тестирование и запуск как часть продукта, а не финальный чек‑лист.
Постройте практичную стратегию тестирования
Начните с автоматических тестов для критичных частей — особенно оценок и прав доступа:
- Unit‑тесты для расчётов: проверьте вычисления вероятность/влияние, пороговые значения, округления и пограничные случаи (NA, отсутствующие поля, переопределения)
- Тесты рабочих процессов: проверьте переходы состояний (draft → submitted → approved), включая переназначение и отклонения
- Тесты прав доступа: убедитесь, что зрители не редактируют, владельцы не могут утверждать свои записи (если это политика), и админы могут аудитить без нарушения принципов разделения обязанностей
Проведите UAT с реальными сценариями
UAT эффективен, когда он повторяет реальную работу. Попросите каждую бизнес‑единицу подготовить примеры рисков, контролей, инцидентов и действий и прогнать типичные сценарии:
- создать риск, связать контроли и отправить на утверждение
- обновить после инцидента и приложить доказательства
- завершить действие и проверить изменение отчётов
Фиксируйте не только баги, но и непонятные метки, отсутствующие статусы и поля, которые не соответствуют речи команд.
Пилотный запуск перед общекомандным
Запустите для одной команды или региона на 2–4 недели. Ограничьте набор: один рабочий поток, небольшое число полей и чёткая метрика успеха (например, % рисков, пересмотренных вовремя). Используйте обратную связь для корректировок:
- названия полей и обязательность
- шаги утверждения и правила ответственности
- тайминги напоминаний и эскалаций
Обучение, документация и внедрение
Дайте короткие инструкции и одностраничный глоссарий: что означает каждая оценка, когда использовать статусы и как прикладывать доказательства. 30‑минутный живой тренинг плюс записи часто эффективнее длинного руководства.
Ускорьте разработку с Koder.ai (опционально)
Если нужно быстро дойти до рабочего v1, платформа типа Koder.ai может помочь прототипировать и итеративно улучшать рабочие процессы без долгой подготовки. Вы описываете экраны и правила (приём риска, утверждения, оценки, напоминания, виды аудита) в чате и дорабатываете с учётом отзывов.
Koder.ai поддерживает end‑to‑end доставку: веб‑приложения (обычно React), бэкенд‑сервисы (Go + PostgreSQL), экспорт исходников, деплой/хостинг, кастомные домены и снимки с откатом — это полезно, когда меняются таксономии, шкалы или правила утверждений и нужна безопасная итерация. Команды могут начать с бесплатного уровня и переходить на pro, business или enterprise по мере роста требований к управлению и масштабу.
Поддерживайте приложение после запуска
Спланируйте эксплуатацию заранее: автоматические бэкапы, мониторинг времени работы/ошибок и лёгкий процесс изменений для таксономии и шкал оценки, чтобы обновления оставались консистентными и аудируемыми.