27 июл. 2025 г.·6 мин
Как язык программирования, база данных и фреймворк работают как одна система
Узнайте, как язык программирования, база данных и фреймворк образуют единую систему. Сравните компромиссы, точки интеграции и практические способы выбрать согласованный стек.
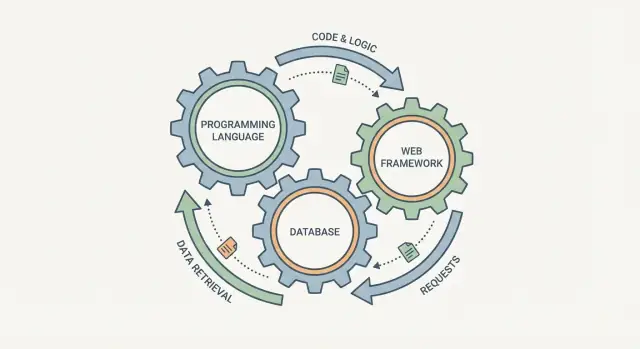
Почему это не отдельные решения
Соблазнительно выбирать язык программирования, базу данных и веб‑фреймворк как три независимых чекбокса. На практике они скорее похожи на сцепленные шестерёнки: измените одну, и остальные это почувствуют.
Веб‑фреймворк определяет, как обрабатываются запросы, как валидируются данные и как проявляются ошибки. База данных определяет, что значит «легко хранить», как вы запрашиваете информацию и какие гарантии получаете при одновременных действиях нескольких пользователей. Язык программирования находится посередине: он определяет, насколько безопасно вы можете выражать правила, как вы управляете конкурентностью и какие библиотеки и инструменты доступны.
Что значит «одна система»
Рассматривать стек как единый механизм означает не оптимизировать каждую часть по‑отдельности. Вы выбираете комбинацию, которая:
- Естественно представляет ваши данные (чтобы не бороться с конверсиями)
- Поддерживает требования к согласованности (чтобы баги не прятались в краевых случаях)
- Соответствует рабочему процессу команды (чтобы релизы и поддержка были предсказуемы)
Эта статья остаётся практичной и намеренно не перегруженной низкоуровневыми деталями. Вам не нужно зубрить теорию баз данных или внутренности рантайма — просто увидьте, как выборы отражаются на всем приложении.
Короткий пример: использование схемо‑свободной базы для сильно структурированных, отчётно‑ориентированных бизнес‑данных часто ведёт к рассыпанным «правилам» в коде приложения и запутанной аналитике позже. Лучше сочетание: реляционная база и фреймворк, поощряющий консистентную валидацию и миграции, — тогда данные остаются когерентными по мере роста продукта.
Когда вы планируете стек вместе, вы проектируете один набор компромиссов, а не три отдельных пари ставок.
Простая ментальная модель: запрос зашёл — данные вышли
Полезно думать о «стеке» как об одной конвейерной линии: пользовательский запрос входит в систему, и выходит ответ (плюс сохранённые данные). Язык программирования, веб‑фреймворк и база данных — это не отдельные выборы, а три части одного пути.
Путешествие одного запроса
Представьте, что клиент обновляет адрес доставки.
- Запрос входит: фреймворк получает HTTP‑запрос. Роутинг решает, какой обработчик исполнить (например,
/account/address). Валидация проверяет, что ввод полный и корректный. - Выполняется работа: ваш прикладной код (на выбранном языке программирования) выполняет бизнес‑правила: «залогинен ли пользователь?», «подходит ли формат адреса?», «нужно ли пометить заказ для повторной проверки?»
- Данные выходят: слой доступа к данным читает/пишет записи — часто в пределах транзакции — чтобы обновление либо применилось полностью, либо не применилось вовсе.
- Ответ выходит: фреймворк форматирует результат (HTML/JSON), устанавливает статусные коды и возвращает ответ пользователю.
- После этого: фоновые задания могут отправить подтверждение по почте, обновить индекс поиска или уведомить склад.
За что на самом деле отвечает каждая часть
- Язык программирования: как выполняется код (рантайм/модель конкурентности), насколько легко тестировать и отлаживать, и есть ли у команды навыки и инструменты для безопасных и быстрых изменений.
- Фреймворк: «регуляция трафика» для запросов — роутинг, валидация, хуки для аутентификации, обработка ошибок и встроенные паттерны для фоновых задач.
- База данных: как хранятся и запрашиваются данные, какие ограничения предотвращают плохие данные, и как транзакции сохраняют согласованность связанных обновлений.
Когда эти три части согласованы, запрос проходит чисто. Если нет — вы получаете трение: неудобный доступ к данным, протекающую валидацию и тонкие ошибки согласованности.
Сначала модель данных: скрытый движущий фактор соответствия стека
Большинство дебатов о стеке начинаются с бренда языка или базы. Лучшее начало — модель данных, потому что именно она тихо диктует, что будет естественным (или болезненным) валидации, запросах, API, миграциях и даже в рабочем процессе команды.
Формы данных: объекты, строки, документы, события
Приложения обычно оперируют четырьмя формами одновременно:
- Объекты в коде (классы, структуры, типизированные записи)
- Строки в реляционных таблицах
- Документы в JSON‑стиле хранилищ или API
- События в логах/стримах («OrderPlaced», «EmailSent»)
Хорошее соответствие — когда вы не проводите день, переводя данные между формами. Если ваши ключевые сущности сильно связаны (пользователи ↔ заказы ↔ товары), строки и JOIN‑ы держат логику простой. Если данные — в основном «один blob на сущность» с переменным набором полей, документы снижают церемониальность — до тех пор, пока не понадобятся кросс‑сущностные отчёты.
Схема против гибкой структуры (и где живут правила)
Когда у базы жёсткая схема, много правил можно держать рядом с данными: типы, ограничения, внешние ключи, уникальность. Это часто уменьшает дублирование проверок по сервисам.
С гибкими структурами правила перемещаются в приложение: код валидации, версионированные полезные нагрузки, бэкофиллы и аккуратная логика чтения («если поле есть, тогда…»). Это подходит, когда требования меняются каждую неделю, но повышает нагрузку на фреймворк и тестирование.
Как выбор модели влияет на сложность кода
Ваша модель решает, будет ли код в основном:
- Запрашивать и объединять (реляционно‑тяжёлый)
- Трансформировать вложенный JSON (документно‑тяжёлый)
- Воспроизводить и аггрегировать события (событийно‑тяжёлый)
Это, в свою очередь, влияет на потребности в языке и фреймворке: сильная типизация может предотвратить незаметный дрейф полей JSON, а зрелые инструменты миграций важнее, когда схемы часто меняются.
Примеры: профиль пользователя, заказы, журнал аудита
- Профиль пользователя: часто похож на документ (настройки, необязательные поля), но выигрывает от реляционных ограничений для идентичности и уникальности.
- Заказы: обычно реляционные (позиции заказа, итоги, статусы), потому что важны согласованность и отчётность.
- Журнал аудита: естественно событийного типа — append‑only записи, которые редко обновляются, оптимизированные для запросов по времени, актору или сущности.
Сначала выберите модель; «правильный» фреймворк и база часто становятся очевидны после этого.
Транзакции и согласованность: где чаще всего начинаются баги
Транзакции — это гарантии «всё или ничего», от которых ваше приложение молча зависит. Когда оформление заказа проходит, вы ожидаете, что запись заказа, статус оплаты и обновление инвентаря либо все применятся, либо ни одно не применится. Без такой гарантии вы получаете самые тяжёлые баги: редкие, дорогие и трудно воспроизводимые.
Что делают транзакции
Транзакция группирует несколько операций с базой в единую единицу работы. Если что‑то падает посередине (ошибка валидации, тайм‑аут, краш процесса), база может откатиться к предыдущему безопасному состоянию.
Это важно не только для финансовых потоков: создание аккаунта (строка пользователя + строка профиля), публикация контента (пост + теги + указатели для поиска) или любой рабочий процесс, затрагивающий более одной таблицы.
Согласованность против скорости (простыми словами)
Согласованность означает «чтения совпадают с реальностью». Скорость — «вернуть результат быстро». Многие системы делают компромиссы:
- Сильная согласованность: пользователи видят последние зафиксированные данные, меньше сюрпризов, часто дороже по координации.
- Наконец‑согласованность: обновления распространяются со временем, обычно проще масштабируется, но приложение должно уметь обрабатывать временные рассогласования.
Распространённая ошибка — выбрать систему с конечной согласованностью, а код писать так, как будто она сильная.
Как фреймворки и ORM влияют на результат
Фреймворки и ORM не создают транзакцию автоматически только потому, что вы вызвали несколько «save». Некоторые требуют явных блоков транзакций; другие открывают транзакцию на каждый запрос, что может скрывать проблемы с производительностью.
Ретраи тоже сложны: ORM могут повторять операции при дедлоках или временных ошибках, но ваш код должен быть безопасен при повторном выполнении.
Обычные подводные камни
Частичные записи появляются, когда вы обновили A, а затем упали до того, как обновить B. Дублирующиеся действия происходят, когда запрос повторяется после тайм‑аута — особенно если вы списали карту или отправили письмо до коммита транзакции.
Простое правило: выполняйте побочные эффекты (письма, вебхуки) после коммита базы и делайте действия идемпотентными с помощью уникальных ограничений или ключей идемпотентности.
Слой доступа к базе: ORM, запросы и миграции
Упростите ревью
Поделитесь реальным приложением с командой и заинтересованными лицами через собственный домен.
Это «переводческий» слой между вашим приложением и базой. Выборы здесь часто важнее по повседневной работе, чем бренд базы.
ORM vs query builder vs raw SQL (простыми словами)
ORM (Object‑Relational Mapper) позволяет обращаться с таблицами как с объектами: создать User, обновить Post, а ORM сгенерирует SQL. Это продуктивно, потому что стандартизирует рутинные задачи и прячет повторяющуюся возню.
Query builder более явный: вы строите SQL‑подобный запрос через цепочки или функции. Всё ещё думаете в терминах JOIN, фильтров и группировок, но получаете безопасность параметров и композицию.
Raw SQL — это писать SQL вручную. Это самый прямой и часто самый ясный путь для сложной отчётности — плата за это: больше ручной работы и соглашений.
Как особенности языка формируют паттерны доступа
Языки со строгой типизацией (TypeScript, Kotlin, Rust) склоняют вас к инструментам, которые могут валидировать запросы и формы результатов заранее. Это уменьшает сюрпризы в рантайме, но способствует централизации доступа к данным, чтобы типы не расслаивались.
Языки с гибким метапрограммированием (Ruby, Python) часто делают ORM естественным и быстрым для итераций — до тех пор, пока скрытые запросы или неявное поведение не станут трудными для понимания.
Миграции: держать код и схему в синхронизации
Миграции — это версионированные скрипты изменения схемы: добавить колонку, создать индекс, заполнить данные. Цель проста: любой может задеплоить приложение и получить ту же структуру базы. Обращайтесь с миграциями как с кодом: ревью, тесты и возможность отката.
Когда «простые» абстракции вредят
ORM могут тихо породить N+1‑запросы, вытаскивать огромные строки, которые вам не нужны, или делать JOINы неудобными. Query builderы могут превратиться в нечитаемые «цепочки». Raw SQL может размножаться и становиться несогласованным.
Хорошее правило: используйте самый простой инструмент, который сохраняет намерение очевидным — а для критичных путей инспектируйте фактический SQL.
Производительность — свойство системы, а не только базы
Компенсируйте время разработки
Получайте кредиты, делясь созданным с Koder.ai или приглашая других попробовать.
Люди часто винят «базу данных», когда страница медлит. Но большая часть видимой задержки — сумма множества маленьких ожиданий по всему пути запроса.
Откуда на самом деле берётся латентность
Один запрос обычно платит за:
- Сетевое время (клиент → балансировщик → приложение → база и обратно)
- Время запроса (медленный SQL, отсутствующие индексы, слишком много раундтрипов)
- Сериализация/десериализация (кодирование JSON, маппинг ORM, сжатие)
- Логика приложения (валидация, разрешения, рендеринг, внешние API‑вызовы)
Даже если ваша база отвечает за 5 мс, приложение, выполняющее 20 запросов на один пользовательский запрос, блокирующее I/O и тратящее 30 мс на сериализацию большого ответа, будет казаться медленным.
Пул соединений: тихий множитель производительности
Открытие нового соединения дорого и может переполнить базу под нагрузкой. Пул соединений переиспользует существующие соединения, чтобы запросы не платили за установку каждый раз.
Но «правильный» размер пула зависит от модели рантайма. Высоко-конкурентный async‑сервер может создавать огромный одновременный спрос; без ограничений пула вы получите очереди, тайм‑ауты и шумные ошибки. С слишком строгими лимитами приложение станет узким местом.
Кэширование: что оно исправляет — и что нет
Кэширование может быть в браузере, CDN, локальном кэше в процессе или в общем кэше (Redis). Оно помогает, когда многие запросы требуют одних и тех же результатов.
Но кэш не спасёт:
- Нееффективные пути записи
- Сильно персонализированные ответы
- Медленные эндпойнты, доминируемые внешними API‑вызовами
Рантайм важен: потоки против async
Рантайм языка формирует пропускную способность. Модель «поток на запрос» может тратить ресурсы, ожидая I/O; async‑модели повышают конкуренцию, но требуют управления обратным давлением (например, лимиты пула). Поэтому тонкая настройка производительности — это решение по всему стеку, а не только по базе.
Безопасность и надёжность: общая ответственность стека
Безопасность — не та вещь, которую «подключают» плагином фреймворка или настройкой базы. Это договорённость между языком/рантаймом, веб‑фреймворком и базой о том, что должно оставаться верным даже при ошибках разработчиков или добавлении новых эндпойнтов.
Аутентификация vs авторизация: разные уровни, одна цель
Аутентификация (кто это?) обычно на краю фреймворка: сессии, JWT, OAuth‑колбэки, middleware. Авторизация (что ему разрешено?) должна обеспечиваться согласованно и в логике приложения, и в правилах данных.
Распространённый паттерн: приложение решает намерение («пользователь может редактировать этот проект»), а база усиливает границы (tenant_id, ограничения владения или, где уместно, политики на уровне строк). Если авторизация есть только в контроллерах, фоновые задачи и internal‑скрипты могут её обойти.
Валидация: фреймворк, база или оба?
Фреймворк даёт быстрый фидбэк и дружелюбные ошибки. Ограничения базы — это последний рубеж защиты.
Используйте оба, когда это важно:
- Фреймворк: обязательные поля, формат, пользовательские сообщения.
- База данных: уникальность, внешние ключи,
CHECK,NOT NULL.
Это уменьшает «невозможные состояния», возникающие при гонках или при записи данных из разных сервисов.
Секреты, шифрование и аудит
Секреты должны управляться рантаймом и пайплайном деплоймента (env vars, secret manager), а не хардкодиться в коде или миграциях. Шифрование может быть приложенческим (шифрование полей) и/или на стороне БД (шифрование на диске, управляемый KMS), но нужно чётко понимать, кто вращает ключи и как осуществляется восстановление.
Аудит тоже распределён: приложение должно эмитировать понятные события; БД — хранить неизменяемые логи там, где нужно (например, append‑only таблицы аудита с ограниченным доступом).
Типичные режимы отказа
Классическая ошибка — доверять только логике приложения: отсутствующие ограничения, тихие NULL‑ы, флаги «admin» без проверок. Решение простое: предполагайте, что баги произойдут, и проектируйте стек так, чтобы база могла отказать небезопасным писаниям — даже от вашего собственного кода.
Пути масштабирования: что каждый выбор открывает или закрывает
Тестируйте изменения без страха
Экспериментируйте со схемой и функциями, а затем безопасно откатывайте изменения, если что-то пойдет не так.
Масштабирование редко проваливается из‑за того, что «база не выдержала». Обычно провал происходит потому, что весь стек плохо реагирует на изменение формы нагрузки: один эндпойнт стал популярным, один запрос нагрелся, один рабочий процесс начал ретриться.
При росте трафика боль проявляется в конкретных местах
Большинство команд сталкиваются с одними и теми же ранними узкими местами:
- Горячие запросы: один «главный» запрос или дашборд постоянно грузит CPU/IO.
- Контенция блокировок: обновления встают за несколькими строками (счётчики инвентаря,
last_seen, таблицы очередей), замедляя всё. - Давление на соединения: воркеры приложения открывают слишком много соединений; база тратит ресурсы на управление сессиями, а не на работу.
Возможность быстро отреагировать зависит от того, насколько хорошо фреймворк и инструменты базы показывают планы выполнения запросов, миграции, пул соединений и безопасные паттерны кэширования.
Реплики для чтения, шардинг и очереди: когда они появляются
Типичные шаги масштабирования появляются в порядке:
- Реплики для чтения, когда чтений значительно больше, чем записей, и вы можете позволить себе слегка устаревшие данные. ORM/фреймворк должен поддерживать разделение чтение/запись или облегчать маршрутизацию запросов.
- Очереди/фоновые задачи, когда «делать прямо сейчас» начинает портить латентность запросов (письма, экспорты, биллинговые вызовы). Здесь ретраи и дедупликация становятся необходимыми.
- Шардинг/партиционирование, когда единичный первичный узел не справляется с пропускной способностью записей или ростом хранения. Это требует продуманного моделирования данных: ключи шарда, кросс‑шардовые запросы и границы транзакций.
Фоновые задачи и идемпотентность — это функции фреймворка, а не мысли в последнюю очередь
Масштабируемый стек нуждается в поддержке фоновых задач, планирования и безопасных повторов. Если система задач не может обеспечить идемпотентность (одна и та же задача выполняется дважды без двойного списания), вы «масштабируетесь» в порчу данных.
Ранние выборы — например, опираясь на неявные транзакции, слабую уникальность или непрозрачное поведение ORM — могут заблокировать чистое введение очередей, паттерна outbox или почти‑точно‑один‑раз процедур позже.
Ранняя синхронизация окупается: выберите базу, соответствующую требованиям согласованности, и экосистему фреймворка, которая делает следующий шаг масштабирования (реплики, очереди, партиционирование) поддерживаемым, а не приводящим к рефакторингу.
FAQ
Почему нельзя выбирать язык, фреймворк и базу данных как отдельные чекбоксы?
Рассматривайте их как единую конвейерную цепочку для каждого запроса: фреймворк → код (язык) → база данных → ответ. Если одна часть поощряет паттерны, с которыми другие части конфликтуют (например, схемо‑свободное хранилище + интенсивная аналитика), вы потратите время на «склеивание», дублирующие правила и трудноподдающиеся отладке проблемы с согласованностью.
С чего лучше начать выбор согласованного стека?
Начните с вашего ключевого моделирования данных и операций, которые вы будете выполнять чаще всего:
- Сильно связанные данные + отчётность → реляционные таблицы и JOIN-ы
- «Один blob на сущность» с переменным набором полей → документы (пока не выросла потребность в отчётах)
- Append-only история и прослеживаемость → событийные/аудитные паттерны
Когда модель ясна, естественные требования к базе и фреймворку обычно становятся очевидными.
Где должны храниться правила данных: в схеме базы или в коде приложения?
Если база данных навязывает жёсткую схему, многие правила могут «жить» рядом с данными:
- Типы,
NOT NULL, уникальность - Внешние ключи и целостность связей
CHECK-ограничения для допустимых диапазонов/состояний
При гибкой структуре правила смещаются вверх в приложение (валидация, версионирование полезных нагрузок, бэкофиллы). Это ускоряет раннюю итерацию, но увеличивает нагрузку на тестирование и риск рассогласования между сервисами.
Когда транзакции особенно важны и что ломается при их игнорировании?
Транзакции нужны, когда несколько записей должны выполниться как единый атомарный набор (например, заказ + статус оплаты + изменение инвентаря). Если пренебречь транзакциями, вы получите:
- Частичные записи (A обновлено, B нет)
- Сложные гонки, которые трудно воспроизвести под нагрузкой
- Несогласованные чтения, ломающие бизнес‑логику
Также выполняйте побочные эффекты (письма, вебхуки) после коммита и делайте операции идемпотентными (безопасными при повторном выполнении).
Как выбрать между ORM, query builder и чистым SQL?
Выбирайте самый простой инструмент, который делает намерение очевидным:
- ORM: быстро для типичных CRUD‑операций; может скрывать N+1‑запросы и неявное поведение
- Query builder: явные JOIN/фильтры с безопасностью параметров и композицией
- Raw SQL: максимально ясный для сложной аналитики и критичных по производительности запросов, но требует соглашений, чтобы избежать дублирования
Для критичных эндпойнтов всегда проверяйте SQL, который реально выполняется.
Какие практики миграций предотвращают расхождение схем и рискованные деплои?
Поддерживайте схему и код в синхронизации с миграциями, которые вы рассматриваете как production‑код:
- Версионируйте миграции, ревьюьте их и запускайте в CI
- Предпочитайте обратимые или безопасно форвардные изменения
- При необходимости разделяйте «добавить колонку» и «заполнить данные»
- Тестируйте миграции на реалистичных объёмах данных
Если миграции ручные или ненадёжные, окружения разойдутся и деплои станут рискованными.
Почему производительность — это свойство системы, а не только базы данных?
Профилируйте весь путь запроса, а не только базу:
- Сетевые хопы и круглые трипы
- Число запросов на один запрос пользователя (часто именно это убивает производительность)
- Оверхед сериализации/ORM‑маппинга
- Внешние API‑вызовы и рендеринг шаблонов
База, отвечающая за 5 мс, не спасёт вас, если приложение делает 20 запросов или блокируется на I/O.
Какова роль пулов соединений и где это может пойти не так?
Пул соединений нужен, чтобы не платить за установку соединения на каждый запрос и чтобы защитить базу под нагрузкой.
Практические рекомендации:
- Установите жёсткий максимальный размер пула на процесс/контейнер
- Проследите, чтобы суммарные пулы по всем репликам не превышали возможностей БД
- Согласуйте размер пула с вашим моделью рантайма (высоко-конкурентный async может перегрузить БД без механизма обратного давления)
Неправильно настроенные пулы проявляются в тайм‑аутах и «шумных» ошибках при всплесках трафика.
Валидация: во фреймворке, в базе данных или в обоих местах?
Используйте оба уровня:
- Фреймворк: быстрая обратная связь и дружелюбные ошибки (обязательные поля, форматирование)
- База данных: контрольный механизм (уникальность, внешние ключи,
NOT NULL,CHECK)
Так вы предотвратите «невозможные состояния», возникающие при гонках запросов, фоновых задачах или забытых проверках в новых эндпойнтах.
Как быстро оценить стек без излишнего переусложнения?
Затайте небольшой proof of concept с ограничением по времени (2–5 дней), который проверит реальные швы:
- Один основной сценарий (запрос → запись → ответ)
- Одна фоновая задача с ретраями/идемпотентностью
- Один отчётный запрос
- Базовая аутентификация и проверки авторизации
Потом оформите одностраничное решение, чтобы будущие изменения были осознанными (см. связанные руководства в /docs и /blog).