09 авг. 2025 г.·6 мин
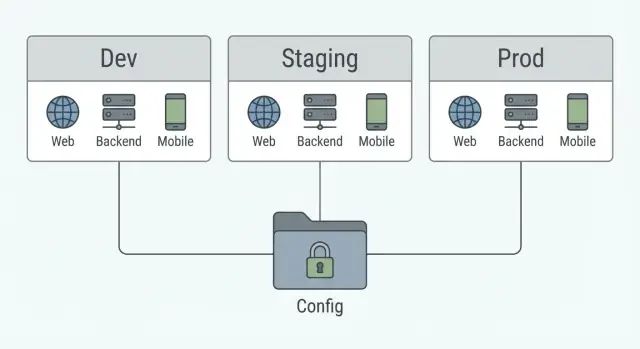
Шаблоны конфигурации окружений для dev, staging и prod
Шаблоны настройки окружений, которые держат URL, ключи и флаги фич вне исходного кода для веба, бэкенда и мобильных приложений в dev, staging и prod.
Почему хардкод в конфигурации постоянно создаёт проблемы
Хардкод в конфигурации кажется приемлемым в первый день. Но потом нужен staging, второй API или быстрый переключатель фич — и «просто изменить» превращается в риск релиза. Решение простое: не храните окружные значения в исходниках, а держите их в предсказуемой структуре конфигурации.
Обычно источники проблем очевидны:
- Базовые URL API вшиты в приложение (запуск против prod во время теста или обращение к dev после релиза)
- API‑ключи закоммичены в репозиторий (утечки, неожиданные счета, экстренная ротация)
- Переключатели фич прописаны как константы (чтобы выключить — нужно шипнуть код)
- Идентификаторы аналитики и отчётности об ошибках захардкожены (данные попадают не туда)
«Просто поменять для продакшена» формирует привычку правок в последний момент. Такие правки часто проходят без ревью, тестов и воспроизводимости. Один человек меняет URL, другой — ключ, и теперь вы не можете ответить на простой вопрос: какая точная конфигурация была в этой сборке?
Типичный сценарий: вы собираете новую мобильную версию против staging, но кто‑то переключает URL на prod прямо перед выпуском. Бэкенд через день меняется снова, и нужно откатываться. Если URL захардкожен, откат требует ещё одной обновлённой версии приложения. Пользователи ждут, а тикеты поддержки растут.
Цель — простая схема, работающая для веба, Go‑бэкенда и Flutter‑мобильного приложения:
- чёткие правила, что должно быть в коде, а что — в конфиге
- безопасные значения по умолчанию для dev, staging и prod
- переключатели фич, которые можно менять без полной пересборки
- секреты вне кодовой базы с возможностью их ротации
Что действительно меняется между dev, staging и prod
Dev, staging и prod должны ощущаться как одно и то же приложение, запущенное в трёх разных местах. Смысл — менять значения, а не поведение.
Меняться должно всё, что связано с местом запуска или тем, кто пользуется приложением: базовые URL и хосты, учётные данные, песочницы против реальных интеграций и меры безопасности вроде уровня логирования или более строгих настроек в проде.
Оставаться одинаковым должно логика и контракт между частями: маршруты API, формы запросов и ответов, имена фич и основные бизнес‑правила не должны различаться по окружениям. Если staging ведёт себя иначе, он перестаёт быть надёжной репетицией для production.
Практическое правило для «нового окружения» против «нового значения конфига»: создавайте новое окружение только тогда, когда нужен изолированный система (отдельные данные, доступ и риски). Если просто нужны разные эндпоинты или числа — добавьте значение конфигурации.
Пример: вы хотите протестировать нового провайдера поиска. Если безопасно включить его для небольшой группы, оставьте одно staging‑окружение и добавьте флаг фичи. Если же нужен отдельный БД и строгие права доступа, тогда имеет смысл отдельное окружение.
Практичная модель конфигурации, которую можно переиспользовать
Хорошая настройка делает одну вещь хорошо: усложняет случайную отправку dev‑URL, тестового ключа или незавершённой фичи в прод.
Используйте три одинаковых слоя для каждого приложения (веб, бэкенд, мобильное):
- Значения по умолчанию: безопасные значения, которые работают в большинстве случаев.
- Перекрытия по окружениям: что меняется для dev, staging, prod.
- Секреты: чувствительные значения, которые никогда не живут в репо.
Чтобы избежать путаницы, выберите один источник правды для каждого приложения и придерживайтесь его. Например, бэкенд читает переменные окружения при старте, веб‑приложение читает build‑time переменные или небольшой runtime‑файл, а мобильное приложение читает маленький файл окружения, выбранный при сборке. Последовательность внутри каждого приложения важнее, чем одинаковый механизм везде.
Простая, переиспользуемая схема выглядит так:
- Значения по умолчанию живут в коде как несекретные константы (таймауты, размер страницы, количество повторов).
- Перекрытия хранятся в файлах для конкретного окружения или в переменных окружения (API_BASE_URL, включение аналитики).
- Секреты хранятся в хранилище секретов и внедряются при деплое/сборке (JWT‑секрет, пароль БД, ключи сторонних сервисов).
Именование, понятное людям
Давайте каждому элементу конфигурации понятное имя, которое отвечает на три вопроса: что это, где применяется и какого типа.
Практическая конвенция:
- Префикс по приложению: WEB_, API_, MOBILE_
- Используйте ВСЕ_ЗАГЛАВНЫЕ_БУКВЫ с подчёркиваниями
- Группируйте по назначению: API_BASE_URL, AUTH_JWT_SECRET, FEATURES_NEW_CHECKOUT
- Для булевых значений делайте их явными: FEATURES_SEARCH_ENABLED=true
Так никто не будет гадать, предназначен ли BASE_URL для React, Go‑сервиса или Flutter‑приложения.
Шаг за шагом: конфигурация веб‑приложения (React) без хардкода
Код React выполняется в браузере пользователя, поэтому всё, что вы шлёте, можно прочитать. Цель проста: держать секреты на сервере, а браузеру отдавать только «безопасные» настройки вроде базового URL API, названия приложения или небезопасного флага фичи.
1) Решите, что делается при сборке, а что — во время выполнения
Конфиг времени сборки внедряется при создании бандла. Это подходит для значений, которые редко меняются и безопасно видны. Конфиг времени выполнения загружается при старте приложения (например, из небольшого JSON‑файла, который сервируется вместе с приложением, или через глобальную переменную). Он лучше подходит для значений, которые вы хотите менять после деплоя, например переключение базового API между окружениями.
Простое правило: если смена значения не должна требовать пересборки UI — делайте его runtime.
2) Храните базовый URL API без коммита
Держите локальный файл для разработчиков (не в git) и ставьте реальные значения в пайплайне деплоя.
- Локальная разработка: используйте
.env.local(в .gitignore) сVITE_API_BASE_URL=http://localhost:8080 - CI/CD: задавайте
VITE_API_BASE_URLкак переменную окружения в job‑е сборки или помещайте его в runtime‑файл, создаваемый при деплое
Пример runtime (файл рядом с вашим приложением):
{ "apiBaseUrl": "https://api.staging.example.com", "features": { "newCheckout": false } }
Затем загрузите его один раз при старте и держите в одном месте:
export async function loadConfig() {
const res = await fetch('/config.json', { cache: 'no-store' });
return res.json();
}
3) Открывайте в браузере только безопасные значения
Считайте, что любые переменные окружения React — публичны. Не кладите туда пароли, приватные API‑ключи или строки подключения к базе. Безопасные примеры: базовый URL API, Sentry DSN (публичный), версия сборки и простые флаги фич.
Шаг за шагом: конфигурация бэкенда (Go), которую можно валидировать
Бэкенд безопаснее, когда конфигурация типизирована, загружается из переменных окружения и валидируется до того, как сервер начнёт принимать трафик.
Начните с определения минимального набора значений, необходимых для запуска бэкенда. Типичные "must have":
APP_ENV(dev, staging, prod)HTTP_ADDR(например:8080)DATABASE_URL(DSN Postgres)PUBLIC_BASE_URL(используется для колбэков и ссылок)API_KEY(для стороннего сервиса)
Загрузите их в структуру и падайте сразу, если что‑то отсутствует или неправильно. Так вы находите проблемы за секунды, а не после частичного деплоя.
package config
import (
"errors"
"net/url"
"os"
"strings"
)
type Config struct {
Env string
HTTPAddr string
DatabaseURL string
PublicBaseURL string
APIKey string
}
func Load() (Config, error) {
c := Config{
Env: mustGet("APP_ENV"),
HTTPAddr: getDefault("HTTP_ADDR", ":8080"),
DatabaseURL: mustGet("DATABASE_URL"),
PublicBaseURL: mustGet("PUBLIC_BASE_URL"),
APIKey: mustGet("API_KEY"),
}
return c, c.Validate()
}
func (c Config) Validate() error {
if c.Env != "dev" && c.Env != "staging" && c.Env != "prod" {
return errors.New("APP_ENV must be dev, staging, or prod")
}
if _, err := url.ParseRequestURI(c.PublicBaseURL); err != nil {
return errors.New("PUBLIC_BASE_URL must be a valid URL")
}
if !strings.HasPrefix(c.DatabaseURL, "postgres://") {
return errors.New("DATABASE_URL must start with postgres://")
}
return nil
}
func mustGet(k string) string {
v, ok := os.LookupEnv(k)
if !ok || strings.TrimSpace(v) == "" {
panic("missing env var: " + k)
}
return v
}
func getDefault(k, def string) string {
if v, ok := os.LookupEnv(k); ok && strings.TrimSpace(v) != "" {
return v
}
return def
}
Это держит DSN баз данных, API‑ключи и callback URL вне кода и git. В размещённых окружениях вы внедряете эти env‑переменные per‑environment, чтобы dev, staging и prod могли отличаться без изменения строк кода.
Шаг за шагом: мобильная конфигурация (Flutter), остающаяся гибкой
Сделайте релизы более предсказуемыми
Используйте одно место, чтобы проверить, какая конфигурация попадёт в сборку перед деплоем.
Flutter‑приложения обычно требуют двух уровней конфигурации: flavor‑ы при сборке (что вы шлёте) и runtime‑настройки (что приложение может изменить без нового релиза). Разделение предотвращает ситуацию, когда «ещё одно быстрое изменение URL» превращается в экстренную пересборку.
1) Используйте flavor‑ы для идентичности, а не эндпоинтов
Создайте три flavor‑а: dev, staging, prod. Flavor‑ы контролируют то, что должно быть зафиксировано при сборке: имя приложения, bundle id, подпись, проект аналитики и включение инструментов отладки.
Передавайте только небезопасные значения через --dart-define (или CI), чтобы ничего не хардкодить в коде:
ENV=stagingDEFAULT_API_BASE=https://api-staging.example.comCONFIG_URL=https://config.example.com/mobile.json
В Dart читайте их через String.fromEnvironment и стройте простой AppConfig один раз при старте.
2) Кладите URL и переключатели в загружаемый конфиг
Чтобы избежать пересборки для маленьких изменений эндпоинтов, не делайте базовый URL API константой. Загружайте небольшой конфиг при запуске приложения (и кешируйте). Flavor задаёт только, откуда скачивать конфиг.
Практическое разделение:
- Flavor (build‑time): идентичность приложения, URL дефолтного конфига, проект для отчётов о падениях
- Удалённый конфиг (runtime): базовый URL API, флаги фич, проценты rollout, режим техобслуживания
- Секреты: никогда не идут в приложение (мобильные бинарники можно проинспектировать)
Если вы переносите бэкенд, обновите удалённый конфиг с новым базовым URL — пользователи получат его при следующем запуске, с безопасным fall‑back на последний кешированный вариант.
Фич‑флаги и переключатели, которые не превращаются в хаос
Флаги фич полезны для постепенных релизов, A/B‑тестов, быстрых аварийных выключателей и тестирования рискованных изменений в staging перед включением в прод. Они не заменяют контролей безопасности. Если флаг защищает то, что нужно защищать, это не флаг — это правило авторизации.
Относитесь к каждому флагу как к API: понятное имя, владелец и дата удаления.
Именование, отражающее намерение
Используйте имена, которые показывают, что происходит, когда флаг ВКЛ и какую часть продукта он затрагивает. Примеры:
feature.checkout_new_ui_enabled(для клиентов)ops.payments_kill_switch(аварийный выключатель)exp.search_rerank_v2(эксперимент)release.api_v3_rollout_pct(постепенный rollout)debug.show_network_logs(диагностика)
Предпочитайте положительные булевы имена (..._enabled) и стабильные префиксы для поиска и аудита.
Дефолты, оградительные меры и уборка
Начинайте с безопасных дефолтов: если сервис флагов недоступен, приложение должно вести себя как стабильная версия.
Реалистичный паттерн: внедрите новый эндпоинт в бэкенд, держите старый работающим и используйте release.api_v3_rollout_pct для постепенного переключения трафика. Если ошибки растут — откатьте без хотфикса.
Чтобы флаги не накапливались:
- У каждого флага есть владелец и дата удаления
- Удаляйте флаги в течение 1–2 релизов после полного включения
- Логируйте значения флагов в ключевых потоках для отладки
- Проводите ежемесячный обзор флагов
Секреты: хранение, доступ и основы ротации
Владейте сгенерированным исходным кодом
Сохраняйте контроль над стеком, экспортируя исходники после генерации и деплоя.
«Секрет» — всё, что может навредить при утечке: API‑токены, пароли БД, OAuth‑секреты, ключи подписи (JWT), секреты вебхуков, приватные сертификаты. Не секрет: базовые URL, номера сборок, флаги фич или публичные аналитические идентификаторы.
Отделяйте секреты от остальных настроек. Разработчики должны иметь возможность свободно менять безопасный конфиг, а секреты внедряются только при запуске и только там, где это необходимо.
Где хранить секреты (по окружениям)
В dev держите секреты локально и легко сбрасываемыми. Используйте .env или системный keychain и не коммитьте их.
В staging и prod держите секреты в выделенном хранилище секретов, а не в репо, не в чатах и не вшивайте в мобильные приложения.
- Веб (React): не кладите секреты в браузер. Если клиенту нужен токен — выдавайте краткоживущийся токен с бэкенда.
- Бэкенд (Go): загружайте секреты из переменных окружения или менеджера секретов при старте и держите их в памяти только там.
- Мобильное (Flutter): считаем приложение публичным. Любой «секрет» в приложении можно извлечь, поэтому используйте токены, выданные бэкендом, и защищённое хранилище устройства только для сессионных данных пользователя.
Основы ротации (без разрыва продакшена)
Ротация терпит поражение, когда вы меняете ключ и забываете про старых клиентов. Планируйте окно перекрытия.
- Поддерживайте два валидных секрета одновременно (активный + предыдущий) в короткое окно.
- Сначала разверните новый секрет, затем переключите указатель «active».
- Мониторьте ошибки аутентификации и удаляйте старый секрет после окна.
- Логируйте версии секретов (не их значения) для безопасной отладки.
Такой подход годится для API‑ключей, секретов вебхуков и ключей подписи — он избегает внезапных простоев.
Пример rollout: смена API URL без ущерба для пользователей
У вас есть staging API и новый production API. Цель — переложить трафик по фазам с быстрым откатом при необходимости. Это проще, когда приложение читает базовый URL API из конфига, а не из кода.
Трактуйте URL API как значение, задаваемое при деплое везде. В вебе это часто build‑time значение или runtime‑config файл. В мобильном — flavor плюс удалённый конфиг. В бэкенде — runtime‑env var. Главное — консистентность: код использует одну переменную (например API_BASE_URL) и никогда не встраивает URL в компоненты, сервисы или экраны.
Безопасный поэтапный rollout может выглядеть так:
- Разверните prod API и держите его «тёмным» (только внутренний трафик), пока staging остаётся дефолтом.
- Сначала переключите зависимости бэкенда (если бэкенд вызывает другие сервисы), используя env‑переменные и быстрый рестарт.
- Переключайте веб‑трафик небольшими долями (или только внутренние аккаунты).
- Выпустите мобильное приложение с новой настройкой, но держите серверный флаг, который контролирует окончательное переключение.
- Постепенно увеличивайте долю трафика и держите план отката.
Проверка в основном о том, чтобы ловить несоответствия рано. До того как реальные пользователи попадут в изменения, подтвердите, что /health отвечает, аутфлоу работает и тестовый аккаунт проходит ключевой путь от начала до конца.
Быстрый чек‑лист перед релизом
Большинство продакшн‑багов в конфигурации скучны: оставшийся staging‑значение, дефолт флага, или отсутствующий API‑ключ в одном регионе. Быстрый прогон ловит большинство из них.
Перед деплоем проверьте, что три вещи соответствуют целевому окружению: endpoints, секреты и дефолты.
- Базовые URL указывают в нужное место (API, auth, CDN, платежи). Проверяйте веб, бэкенд и мобильные отдельно.
- В production нет тестовых ключей, и в dev/staging нет production‑ключей. Убедитесь, что имена ключей совпадают с ожидаемыми.
- Флаги фич имеют безопасные дефолты. Рисковые функции по умолчанию выключены и включаются сознательно.
- Настройки сборки и релиза совпадают (bundle ID/package name, кастомный домен, CORS‑origins, OAuth redirect URLs).
- Наблюдаемость настроена (логи, отчёты об ошибках, трассировка) и маркирована правильным окружением.
Затем выполните быстрый smoke‑тест. Возьмите один реальный пользовательский путь и прогоните его end‑to‑end на «чистом» клиенте, без закешированных токенов.
- Откройте приложение и убедитесь, что оно загружается без ошибок в консоли.
- Войдите и сделайте один API‑вызов, требующий авторизации (профиль, настройки или список данных).
- Сымитируйте контролируемую ошибку (неверный ввод или офлайн) и убедитесь, что показывается дружелюбное сообщение, а не пустой экран.
- Проверьте логи и репорты об ошибках: тестовая ошибка должна появиться под правильным окружением в течение нескольких минут.
Практичная привычка: относитесь к staging как к production с другими значениями. Это значит та же схема конфигурации, те же правила валидации и та же форма деплоя. Только значения различаются, а не структура.
Распространённые ошибки, ведущие к инцидентам
Ранний контроль конфигурации бэкенда
Сгенерируйте Go‑бэкенд, который читает env‑переменные при старте и валидирует обязательные настройки.
Большинство инцидентов с конфигурацией — не экзотика. Это простые ошибки, которые проходят из‑за того, что конфиг разбросан по файлам, шагам сборки и дашбордам, и никто не может ответить: «Какие значения это приложение будет использовать сейчас?» Хорошая настройка делает этот вопрос простым.
Смешивание значений build‑time и runtime
Распространённая ловушка — класть runtime‑значения в места build‑time. Запекание базового URL в сборку React означает, что для каждого окружения нужна пересборка. Тогда кто‑то деплоит неверный артефакт, и production смотрит в staging.
Более безопасное правило: запекайте только то, что действительно никогда не меняется после релиза (например, версия приложения). Держите данные окружения (API URL, флаги фич, endpoints аналитики) там, где их можно менять во время выполнения, и сделайте источник правды очевидным.
Отправка dev‑эндпоинтов или тестовых ключей в прод
Это случается, когда дефолты «полезны», но небезопасны. Мобильное приложение может по умолчанию смотреть на dev API, если не может прочитать конфиг, или бэкенд может падать на локальную базу, если env‑переменная отсутствует. Это превращает мелкую ошибку конфигурации в полный outage.
Две полезные привычки:
- Fail closed: если обязательное значение отсутствует — падать сразу с понятной ошибкой.
- Сделайте прод самое сложное окружение для ошибочной настройки: никаких dev‑дефолтов, никаких тестовых ключей, никаких debug‑эндпоинтов.
Реалистичный пример: релиз уходит в пятницу вечером, и production‑сборка случайно содержит staging‑ключ для платежей. Всё «работает», пока платежи не начнут падать. Лечится это не новой библиотекой платежей, а валидацией, которая отвергает не‑production‑ключи в проде.
Позволять staging уходить от production
Если staging не совпадает с production, вы получаете ложную уверенность. Разные настройки баз данных, отсутствующие background‑job‑ы или лишние флаги делают баги видимыми только после релиза.
Держите staging близко к production: зеркалируйте схему конфига, правила валидации и форму деплоя. Различаться должны только значения, а не структура.
Следующие шаги: сделайте конфиг скучным, повторяемым и безопасным
Цель — не фановые инструменты, а скучная последовательность: одни и те же имена, типы и правила в dev, staging и prod. Когда конфиг предсказуем, релизы перестают быть рискованными.
Начните с того, что запишите короткий контракт конфигурации в одном месте. Делайте его коротким, но конкретным: каждое имя ключа, его тип (string, number, boolean), где оно может приходить (env var, remote config, build‑time) и значение по умолчанию. Добавьте заметки для значений, которые никогда не должны быть в клиентском приложении (например приватные API‑ключи). Относитесь к этому контракту как к API: изменения требуют ревью.
Затем заставьте ошибки обнаруживаться рано. Лучшее место для нахождения отсутствующего базового URL — CI, а не после деплоя. Добавьте автоматическую валидацию, которая загружает конфиг так же, как приложение, и проверяет:
- обязательные значения присутствуют (никаких пустых строк)
- типы верны (нет багов с "true" vs true)
- продовые правила выполняются (например, требование HTTPS)
- флаги фич имеют ожидаемые имена (нет опечаток)
- секреты не закоммичены в репозиторий
Наконец, делайте восстановление простым. Снимайте снапшоты текущего состояния, меняйте по одному параметру, быстро проверяйте и держите путь отката.
Если вы деплоите и собираете через платформу вроде Koder.ai (koder.ai), правила те же: рассматривайте переменные окружения как входные данные для сборки и хостинга, не держите секреты в экспортируемых исходниках и валидируйте конфиг перед отправкой. Эта последовательность делает повторные деплои и откаты рутинными.
Когда конфиг документирован, валидирован и обратим, он перестаёт быть источником аварий и становится обычной частью процесса доставки.