18 авг. 2025 г.·8 мин
LLVM Криса Латтнера: тихий двигатель современных инструментальных цепочек
Узнайте, как LLVM Криса Латтнера стал модульной платформой компилятора за кулисами — обеспечивая оптимизации, улучшённые диагностики и быстрые сборки для множества языков и инструментов.
Что такое LLVM простыми словами
LLVM лучше всего представлять как «машинное отделение», которым пользуются многие компиляторы и инструменты для разработчиков.
Когда вы пишете код на таких языках, как C, Swift или Rust, нужно как-то превратить этот код в инструкции для процессора. Традиционный компилятор обычно строил весь этот конвейер целиком сам. LLVM идёт другим путём: он предоставляет качественную, повторно используемую «сердцевину», которая занимается сложной и дорогостоящей работой — оптимизациями, анализом и генерацией машинного кода для множества архитектур.
Общая платформа для многих языков
LLVM не всегда является «компилятором, которым вы пользуетесь напрямую». Это инфраструктура компилятора — набор строительных блоков, которые команды языков могут собирать в свой toolchain. Одна команда может сосредоточиться на синтаксисе, семантике и удобстве для разработчика, а затем передать тяжёлую работу LLVM.
Эта общая основа — одна из причин, почему современные языки могут быстро выпускать безопасные и производительные toolchain’ы, не переизобретая десятилетия работы по компиляторам.
Почему это важно, даже если вы не специалист по компиляторам
LLVM проявляется в повседневном опыте разработки:
- Скорость: он умеет превращать код высокого уровня в эффективный машинный код на разных платформах.
- Лучшие ошибки и отладка: экосистема вокруг LLVM обеспечивает более богатые диагностики и улучшенные инструменты.
- Больше, чем «просто компиляция»: статический анализ, санитайзеры, покрытие кода и другие инструменты часто строятся на той же внутренней представлении и библиотеках.
О чём (и о чём не) эта статья
Это обзор идей, которые запустил Крис Латтнер: как устроен LLVM, почему важен средний слой и как он позволяет выполнять оптимизации и поддерживать множество платформ. Это не учебник — акцент на интуиции и реальном влиянии, а не на формальной теории.
Изначальная идея Криса Латтнера
Крис Латтнер — учёный и инженер, который в начале 2000-х, будучи аспирантом, начал работу над LLVM из практического неудовлетворения: технология компиляторов была мощной, но плохо переиспользуемой. Если вы хотели новый язык, лучшие оптимизации или поддержку нового CPU, приходилось дорабатывать плотносвязанную «всё-в-одном» систему, где любое изменение имело побочные эффекты.
Проблема, которую он хотел решить
В те времена многие компиляторы строились как единый громоздкий механизм: часть, понимающая язык, часть, делающая оптимизации, и часть, генерирующая машинный код, были тесно переплетены. Это делало их эффективными для исходной задачи, но дорогими в адаптации.
Цель Латтнера была не «компилятор для одного языка». Это была общая основа, которая могла бы питать множество языков и инструментов — без необходимости всем опять и опять переписывать одни и те же сложные части. Ставка была в том, что стандартизовав «середину» конвейера, можно ускорить инновации на краях.
Почему идея «модульной инфраструктуры» была новой
Ключевой сдвиг — рассматривать компиляцию как набор отдельных блоков с чёткими границами. В модульном мире:
- команда языка сосредотачивается на разборе и фичах для разработчика,
- команда оптимизаций улучшает производительность один раз и делится результатом,
- поддержку аппаратуры можно добавлять без переработки всего остального.
Это сейчас кажется очевидным, но тогда шло вразрез с эволюцией многих производственных компиляторов.
Открытый код и ориентированность на внешних пользователей
LLVM был выпущен как open source довольно рано, и это имело значение: общая инфраструктура работает только если разные группы могут доверять ей, изучать её и расширять её. Со временем университеты, компании и независимые участники вносили вклад: добавляли таргеты, исправляли граничные случаи, улучшали производительность и строили новые инструменты поверх неё.
Этот общественный аспект был не просто доброй волей — он был частью дизайна: сделай ядро полезным для многих, и за ним будет проще ухаживать вместе.
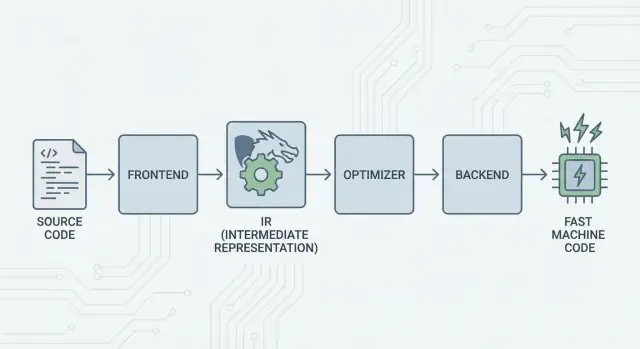
Главная идея: фронтэнды, общая «середина» и бэкенды
Основная идея LLVM проста: разделить компилятор на три больших части, чтобы многие языки могли делить самую сложную работу.
1) Фронтэнды: «Что имел в виду программист?»
Фронтэнд понимает конкретный язык программирования. Он читает исходный код, проверяет правила (синтаксис и типы) и превращает его в структурированное представление.
Главное: фронтэндам не нужно знать все детали CPU. Их задача — перевести языковые концепты (функции, циклы, переменные) в нечто более универсальное.
2) Общая середина: один общий ядро вместо N×M работы
Традиционно создание компилятора означало повторять одну и ту же работу:
- с N языками и M архитектурами у вас получается N×M комбинаций, которые нужно поддерживать.
LLVM сокращает это до:
- N фронтэндов, переводящих в общее представление,
- M бэкендов, переводящих из этого общего представления в машинный код.
Это «общее представление» — центр LLVM: общий конвейер, где живут оптимизации и анализы. Улучшения в середине (лучшие оптимизации или более качественная отладочная информация) приносят пользу многим языкам сразу, вместо того чтобы переосмыслять их в каждом компиляторе.
3) Бэкенды: «Как запустить это быстро на этом CPU?»
Бэкенд берёт общее представление и производит платформо-специфичный вывод: инструкции для x86, ARM и так далее. Здесь важны регистры, соглашения о вызовах и выбор инструкций.
Интуитивная картина конвейера
Представьте компиляцию как маршрут путешествия:
- Исходный код стартует в стране, специфичной для языка (фронтэнд).
- Он переходит границу в обобщённый «средний язык» (IR и проходы LLVM).
- Затем отправляется по локальной железной дороге в целевой город (бэкенд для вашей архитектуры).
Результат — модульный toolchain: языки могут сосредоточиться на выразительности, а общая середина LLVM — на эффективном исполнении на многих платформах.
LLVM IR: средний слой, который даёт повторное использование
LLVM IR (Intermediate Representation) — это «общий язык», который лежит между языком программирования и машинным кодом процессора.
Фронтэнд компилятора (например, Clang для C/C++) переводит ваш исходный код в это общее представление. Затем оптимизаторы и генераторы кода LLVM работают с IR, а бэкенд в конце превращает IR в инструкции для конкретной цели (x86, ARM и т. д.).
Общий язык между инструментами и CPU
Думайте о LLVM IR как о тщательно продуманном мосте:
- Над ним: подключаются многие языки (C, C++, Rust, Swift, Julia и др.).
- Под ним: можно таргетировать разные CPU.
- В середине: переиспользуются одни и те же инструменты анализа и оптимизации.
Именно поэтому LLVM чаще называют «инфраструктурой компилятора», а не просто «компилятором». IR — это общее соглашение, которое делает инфраструктуру повторно используемой.
Почему IR даёт повторное использование (и экономит работу)
Оказавшись в LLVM IR, большинство проходов оптимизации не заботятся о том, из чего исходно был составлен код — C++ шаблонов, Rust-итераторов или Swift-дженериков. Их интересуют универсальные идеи, например:
- «Это значение — константа.»
- «Это вычисление повторяется; можно использовать результат повторно.»
- «Эту загрузку из памяти можно безопасно переместить или убрать.»
Поэтому команды языков не обязаны строить и поддерживать собственный полный стек оптимизаций. Они фокусируются на фронтэнде — разборе, проверке типов и правилах языка — а затем передают тяжёлую работу LLVM.
Как это выглядит концептуально
LLVM IR достаточно низкоуровнев, чтобы его было легко сопоставить с машинным кодом, но при этом достаточно структурирован, чтобы проводить анализ. Концептуально он состоит из простых инструкций (add, compare, load/store), явного управления потоком (ветвления) и строго типизированных значений — ближе к аккуратному ассемблероподобному языку, предназначенному для компиляторов, чем к тому, что обычно пишут люди.
Как работают оптимизации (без математики)
Когда слышат «оптимизации компилятора», многие представляют себе таинственные трюки. В LLVM большинство оптимизаций — это скорее безопасные, механические переписывания программы: преобразования, сохраняющие поведение, но стремящиеся сделать его быстрее (или меньше).
Думайте об этом как о редактировании, а не изобретении
LLVM берёт код в IR и многократно применяет мелкие улучшения, словно доводя черновик до ума:
- Убирает дублирующуюся работу: если значение вычисляется дважды и между вычислениями ничего не меняется, LLVM может вычислить его один раз и переиспользовать.
- Упрощает очевидную логику: константные выражения складываются заранее (например,
3 * 4превращается в12), чтобы CPU сделал меньше работы во время исполнения. - Оптимизирует циклы: проходы, связанные с циклами, могут уменьшать повторяющиеся проверки, выносить инвариантную работу из цикла или распознавать паттерны для более эффективного выполнения.
Эти изменения намеренно консервативны. Проход выполняет переписание только тогда, когда можно доказать, что смысл программы не изменится.
Понятные примеры
Если ваша программа концептуально делает следующее:
- читает одно и то же конфигурационное значение на каждой итерации цикла;
- выполняет одно и то же вычисление на одинаковых входных данных в нескольких местах;
- проверяет условие, которое в данном контексте всегда истинно/ложно;
…то LLVM попытается превратить это в «выполнить установку один раз», «переиспользовать результат» и «удалить мёртвые ветки». Это менее волшебно и больше похоже на регулярную уборку.
Реальный компромисс: время компиляции против времени выполнения
Оптимизация не бесплатна: больше анализа и больше проходов обычно означают медленную компиляцию, даже если итоговая программа работает быстрее. Поэтому toolchain’ы предлагают уровни: «немного оптимизировать» против «агрессивно оптимизировать».
Профили помогают здесь. С оптимизацией, управляемой профилем (PGO), вы запускаете программу, собираете реальные данные использования, а затем перекомпилируете, чтобы LLVM сосредоточил усилия на действительно важных путях — это делает компромисс более предсказуемым.
Бэкенды: достижение многих CPU без переписывания всего
От разработки к запуску
Выпустите хостинг-версию, не собирая шаги сборки вручную.
У компилятора есть две очень разные задачи. Сначала он должен понять исходный код. Затем он должен произвести машинный код, который сможет выполнить конкретный CPU. Бэкенды LLVM фокусируются на второй задаче.
Что конкретно делает бэкенд
Думайте о LLVM IR как о «универсальном рецепте» того, что программа должна делать. Бэкенд превращает этот рецепт в точные инструкции для определённого семейства процессоров — x86-64 для десктопов и серверов, ARM64 для многих телефонов и новых ноутбуков, или специализированные цели вроде WebAssembly.
Конкретно бэкенд отвечает за:
- Выбор инструкций: сопоставление операций IR с реальными инструкциями CPU;
- Распределение регистров: выбор, какие значения держать в быстрых регистрах CPU, а какие — в памяти;
- Планирование: упорядочивание инструкций так, чтобы CPU мог выполнять их эффективно;
- Вывод ассемблера/объектного файла: генерация кода, понятного линкеру и ОС.
Почему общая инфраструктура облегчает поддержку нового железа
Без общей середины каждый язык должен был бы заново реализовать всё это для каждой архитектуры — колоссальная работа и постоянная нагрузка по поддержке.
LLVM меняет подход: фронтэнды (например, Clang) один раз генерируют IR, а бэкенды занимаются «последней милей» для каждой цели. Добавление поддержки нового CPU обычно означает написание одного бэкенда (или расширение существующего), а не переписывание каждого компилятора.
Портабельность для команд, выпускающих продукты на многих платформах
Для проектов, которые должны работать на Windows/macOS/Linux, на x86 и ARM или даже в браузере, модель бэкендов LLVM — практическое преимущество. Можно держать один код и в основном один пайплайн сборки, а затем перенаправлять таргетированием на другой бэкенд (или кросс-компиляцией).
Эта портативность — причина, почему LLVM встречается повсеместно: дело не только в производительности, но и в сокращении повторной платформо-специфичной работы, которая замедляет команды.
Clang: где многие разработчики впервые встречают LLVM
Clang — это фронтэнд для C, C++ и Objective-C, который подключается к LLVM. Если LLVM — общий двигатель, способный оптимизировать и генерировать машинный код, то Clang — часть, читающая ваши исходные файлы, понимающая правила языка и превращающая то, что вы написали, в форму, с которой LLVM может работать.
Почему Clang привлёк внимание
Многие разработчики не узнали бы о LLVM, читая статьи по компиляторам — они столкнулись с ним, когда заменили компилятор и получили гораздо более понятные сообщения об ошибках.
Диагностика Clang известна своей читаемостью и конкретностью. Вместо расплывчатых ошибок он часто указывает на точный токен, показвает релевантную строку и объясняет, чего ожидал. Это важно в повседневной работе: цикл «компилируй — исправляй — повторяй» становится менее раздражающим.
Clang также предоставляет чистые, документированные интерфейсы (включая libclang и экосистему Clang tooling). Это облегчило интеграцию редакторов, IDE и других инструментов, которые получили глубокое понимание языка C/C++, не переписывая парсер с нуля.
Как это проявляется в повседневной работе
Как только инструмент надёжно парсит и анализирует ваш код, начинают появляться фичи, которые воспринимаются скорее как работа с структурной программой, чем простая правка текста:
- Точная навигация по коду («перейти к определению», «найти ссылки»), даже в больших проектах с макросами;
- Поддержка рефакторинга, понимающая символы и области видимости, а не просто поиск и замену;
- Всплывающие подсказки и быстрые исправления, основанные на реальном синтаксисе и типах.
Поэтому Clang часто является первой «точкой соприкосновения» с LLVM: именно здесь зарождаются практические улучшения опыта разработчика. Даже не думая о LLVM IR или бэкендах, вы выигрываете от более умного автодополнения, точных статических проверок и понятных ошибок сборки.
Почему многие современные языки строятся на LLVM
LLVM привлекателен для команд языков по простой причине: он позволяет им сосредоточиться на самом языке, а не тратить годы на то, чтобы заново создавать оптимизирующий компилятор.
Быстрейший выход на рынок
Создание нового языка уже включает разбор, проверку типов, диагностику, пакеты, документацию и работу с сообществом. Если к этому добавить создание продвинутого оптимизатора, генератора кода и поддержки платформ с нуля, выпуск будет отложен на годы.
LLVM даёт готовое ядро компиляции: распределение регистров, выбор инструкций, зрелые проходы оптимизации и таргеты для распространённых CPU. Команды подключают фронтэнд, переводят язык в LLVM IR, и получают нативный код для macOS, Linux и Windows.
Высокая производительность (без «геройских подвигов»)
Оптимизатор и бэкенды LLVM — результат длительной инженерной работы и постоянного тестирования в реальных условиях. Это даёт хорошую базовую производительность для языков, использующих LLVM — достаточно высокую сразу и с потенциалом улучшения по мере развития LLVM.
Поэтому несколько известных языков строятся вокруг LLVM:
- Swift использует LLVM для генерации оптимизированных нативных бинарников на платформах Apple.
- Rust полагается на LLVM для генерации кода и поддержки множества архитектур.
- Julia использует LLVM для быстрой численной работы, включая компиляцию во время выполнения для специализированных задач.
Не каждому языку нужен LLVM
Выбор LLVM — это компромисс, а не обязательное требование. Некоторые языки ставят в приоритет маленькие бинарники, сверхбыструю компиляцию или полный контроль над собственным toolchain. Другие уже опираются на существующие компиляторы (например, экосистемы на базе GCC) или предпочитают простые бэкенды.
LLVM популярен потому, что это сильный дефолт — но не единственный путь.
JIT и компиляция во время выполнения: быстрые циклы обратной связи
Масштабируйтесь в своём темпе
Выберите Free, Pro, Business или Enterprise в зависимости от того, насколько далеко вы хотите зайти.
«Just-in-time» (JIT) компиляция проще всего воспринимать как «компиляцию по ходу выполнения». Вместо трансляции всего кода заранее в окончательный исполняемый файл, JIT ждёт, когда кусок кода понадобится, и компилирует только его — зачастую используя реальные данные выполнения (например, точные типы и размеры данных) для более выгодных решений.
Почему JIT кажется быстрым
Поскольку не нужно компилировать всё заранее, JIT-системы дают быстрый отклик в интерактивных сценариях. Вы пишете или генерируете фрагмент кода, сразу его запускаете, и система компилирует только необходимое сейчас. Если тот же код выполняется часто, JIT может кэшировать скомпилированный результат или перекомпилировать «горячие» участки более агрессивно.
Где компиляция во время выполнения реально помогает
JIT хорош там, где рабочие нагрузки динамичны или интерактивны:
- REPL и ноутбуки: мгновенная оценка фрагментов с нативной скоростью для тяжёлых циклов;
- Плагины и расширения: приложения могут загружать код пользователей и компилировать его под целевой CPU во время выполнения;
- Динамические нагрузки: при сильно варьируемых входах профилирование во время работы помогает понять, какие пути стоит оптимизировать;
- Научные вычисления: генерируемые ядра (для конкретного размера матрицы, формы модели или фичи железа) можно компилировать по требованию.
Роль LLVM (без хайпа)
LLVM не делает программу магически быстрее и сам по себе не является полным JIT-движком. Он предоставляет набор инструментов: определённый IR, большое количество проходов оптимизации и генерацию кода для многих CPU. Проекты строят JIT-движки поверх этих компонентов, решая компромисс между временем запуска, пиком производительности и сложностью.
Производительность, предсказуемость и реальные компромиссы
Инструменты на базе LLVM могут генерировать очень быстрый код — но «быстрый» не является единым и постоянным свойством. Всё зависит от версии компилятора, целевого CPU, настроек оптимизации и даже предположений, которые вы делаете о программе.
Почему «один и тот же исходник — разные результаты» происходит
Два компилятора могут прочитать один и тот же исходник на C/C++ (или Rust, Swift и т. п.) и всё равно сгенерировать заметно разный машинный код. Часть причин — преднамеренные: у каждого компилятора свой набор проходов оптимизации, эвристик и настроек по умолчанию. Даже внутри LLVM Clang 15 и Clang 18 могут по‑разному решать, что инлайнить, какие циклы векторизировать или как планировать инструкции.
Также это может быть вызвано неопределённым поведением и неуточнённым поведением в языке. Если программа случайно опирается на то, чего стандарт не гарантирует (например, переполнение со знаком в C), разные компиляторы или разные флаги могут «оптимизировать» так, что результаты изменятся.
Детерминированность, debug-сборки и релизные сборки
Люди часто ожидают детерминированности: те же входы — те же выходы. На практике вы будете близки, но не всегда получите идентичные бинарники в разных средах. Пути сборки, метки времени, порядок линковки, данные профильных запусков и опции LTO могут повлиять на итоговый артефакт.
Более практичное различие — debug vs release. В debug-сборках обычно отключено много оптимизаций, чтобы сохранить читаемость шага отладки и понятность стека. Релизные сборки включают агрессивные преобразования: перестановку кода, инлайнинг функций и удаление переменных — это хорошо для производительности, но сложнее для отладки.
Практический совет: измеряйте, не догадывайтесь
Рассматривайте производительность как проблему измерения:
- Бенчмарьте на репрезентативном железе с реальными данными;
- Прогревайте кэши и запускайте несколько итераций;
- Сравнивайте сборки с явными флагами (например,
-O2vs-O3, включение/отключение LTO, выбор-march).
Небольшие изменения флагов могут изменить производительность в любую сторону. Самый надёжный рабочий процесс: сформулировать гипотезу, измерить её и держать бенчмарки близко к реальным сценариям пользователей.
Инструменты вокруг компиляции: анализ, отладка и безопасность
Кроссплатформенная разработка
Создайте мобильное приложение на Flutter вместе с веб- и серверной частями.
LLVM часто называют инструментарием компилятора, но многие разработчики ощущают его влияние через инструменты, которые «сидят» вокруг процесса компиляции: анализаторы, отладчики и проверки безопасности, которые включают во время сборок и тестов.
Анализ и инструментирование как «надстройки»
Поскольку LLVM предоставляет чёткое IR и конвейер проходов, естественно добавлять шаги, которые инспектируют или переписывают код не ради производительности, а для других целей. Проход может вставлять счётчики для профилирования, помечать сомнительные операции с памятью или собирать данные покрытия кода.
Главная мысль: эти функции можно интегрировать без того, чтобы каждой команде языка приходилось заново реализовывать одну и ту же инфраструктуру.
Санитайзеры: ловя баги близко к исходнику
Clang и LLVM популяризировали семейство рантайм‑«санитайзеров», которые инструментируют программы для обнаружения распространённых ошибок во время тестирования — выход за границы массива, use-after-free, гонки данных и паттерны неопределённого поведения. Это не магические щиты и они обычно замедляют программу, поэтому используются в CI и перед выпуском. Но когда санитайзер срабатывает, он часто указывает точное место в исходнике и понятное объяснение — именно то, что нужно при поиске редких падений.
Лучшие диагностики = быстрее ввод в команду
Качество инструментов — это ещё и качество коммуникации. Чёткие предупреждения, понятные сообщения об ошибках и последовательная отладочная информация уменьшают «фактор загадочности» для новичков. Когда тулчейн объясняет, что произошло и как это исправить, разработчики тратят меньше времени на запоминание особенностей компилятора и больше — на изучение кода.
LLVM не гарантирует идеальную диагностику или безопасность сам по себе, но даёт общую основу, которая делает эти инструменты практичными для создания, поддержки и совместного использования.
Когда стоит использовать LLVM (и когда нет)
LLVM лучше рассматривать как «собери‑свой‑компилятор и набор инструментов». Эта гибкость — причина, по которой он питает многие современные toolchain’ы, но она же означает, что он не всегда является правильным выбором.
Когда LLVM подходит отлично
LLVM хорош, если вы хотите переиспользовать серьёзную инженерную работу по компиляторам, не переписывая её.
Если вы создаёте новый язык программирования, LLVM даёт проверенный пайплайн оптимизаций, зрелую генерацию кода для множества CPU и путь к качественной поддержке отладки.
Если вы выпускаете кроссплатформенные приложения, экосистема бэкендов LLVM снижает объём работы по таргетированию разных архитектур. Вы фокусируетесь на логике языка или продукта, а не на написании отдельных генераторов кода.
Если ваша цель — инструментарий для разработчиков (линтеры, статический анализ, навигация по коду, рефакторинг), LLVM и экосистема вокруг него — хорошая основа, потому что компилятор уже «понимает» структуру кода и типы.
Когда это может быть избыточно
LLVM может быть тяжеловат для миниатюрных встроенных систем, где размер сборки, память и время компиляции строго ограничены.
Он также может плохо подходить для очень специализированных пайплайнов, где не нужны общие оптимизации или язык ближе к фиксированному DSL с простым прямым соответствием машинному коду.
Простой чек‑лист
Задайте три вопроса:
- Нужно ли нам таргетировать несколько платформ/CPU сейчас или скоро?
- Выгодны ли нам существующие оптимизации и отладочная информация, вместо того чтобы строить их самостоятельно?
- Нужна ли нам экосистема (инструменты, интеграции, найм) больше, чем минимальный кастомный компилятор?
Если на большинство ответ «да», LLVM обычно практическая ставка. Если вам нужен самый маленький и простой компилятор для узкой задачи, выигрывает более лёгкий подход.
Практическая заметка для продуктовых команд: преимущества LLVM без становления экспертами по компиляторам
Большинству команд не хочется «внедрять LLVM» как проект. Им нужны результаты: кроссплатформенные сборки, быстрые бинарники, хорошие диагностики и надёжный инструментарий.
Поэтому интересны платформы вроде Koder.ai: если ваш рабочий процесс всё больше опирается на автоматизацию высокого уровня (планирование, генерация шаблонов, итерации в тесном цикле), вы всё равно выигрываете от LLVM косвенно через используемые toolchain’ы — будь то React‑веб‑приложение, бэкенд на Go с PostgreSQL или мобильный клиент на Flutter. Подход Koder.ai с чат‑ориентированным «vibe‑coding» помогает быстро выпускать продукт, в то время как современная инфраструктура компиляторов (LLVM/Clang и сопутствующие инструменты, где применимо) тихо делает работу по оптимизациям, диагностике и портированию на фоне.