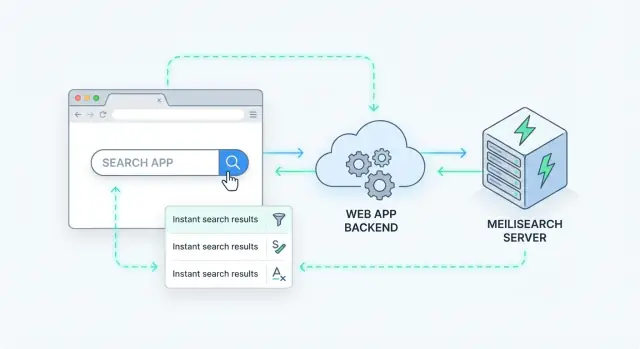
Что должен обеспечивать мгновенный серверный поиск
Серверный поиск означает, что запрос обрабатывается на вашем сервере (или в выделённом сервисе поиска), а не в браузере. Ваше приложение отправляет запрос на поиск, сервер выполняет его по индексу и возвращает ранжированные результаты.
Это важно, когда ваш набор данных слишком велик, чтобы отправлять его клиенту, когда нужна согласованная релевантность на разных платформах или когда контроль доступа обязателен (например, внутренние инструменты, где пользователи должны видеть только разрешённые записи). Это также стандартный выбор, если вы хотите собирать аналитику, логировать события и иметь предсказуемую производительность.
Что пользователи ожидают (и замечают сразу)
Люди не думают о движке поиска — они оценивают опыт. Хороший «мгновенный» поиск обычно означает:
- Быстрая обратная связь: результаты обновляются быстро по мере ввода, без неловких пауз.
- Опечатки не ломают поиск: орфографические ошибки, переставленные буквы и частичные слова всё ещё находят нужные элементы.
- Полезные элементы управления: фильтры (категория, статус, диапазон цен), сортировка (новизна, цена) и фасеты (количество по фильтру) работают естественно.
- Релевантное ранжирование: «лучшие» результаты вверху, а не просто самые новые или наиболее «нашпигованные» ключевыми словами.
Если чего‑то не хватает, пользователи будут пробовать другие запросы, больше скроллить или вообще бросить поиск.
Чему поможет это руководство
Эта статья — практическое руководство по созданию такого опыта с Meilisearch. Мы пройдём через безопасную установку, структуру и синхронизацию индексируемых данных, настройку релевантности и правил ранжирования, добавление фильтров/сортировки/фасетов и рассмотрим безопасность и масштабирование, чтобы поиск оставался быстрым по мере роста приложения.
Где серверный поиск особенно хорош
Meilisearch хорошо подходит для:
- Документации и баз знаний (быстро находить страницы, терпимо к опечаткам)
- Каталогов товаров и маркетплейсов (фильтры и сортировка критичны)
- Внутренних инструментов (поиск с учётом прав доступа)
- Контентных сайтов (поиск по статьям, руководствам, FAQ)
Цель: результаты, которые кажутся мгновенными, точными и заслуживающими доверия — без превращения поиска в большой инженерный проект.
Обзор Meilisearch простыми словами
Meilisearch — это поисковый движок, который вы запускаете рядом с приложением. Вы отправляете ему документы (товары, статьи, пользователей или заявки в поддержку), и он строит индекс, оптимизированный для быстрого поиска. Ваш бэкенд (или фронтенд) затем запрашивает Meilisearch через простой HTTP API и получает ранжированные результаты за миллисекунды.
Что вы получаете «из коробки»
Meilisearch фокусируется на функциях, которые ожидают от современного поиска:
- Толерантность к опечаткам, чтобы «iphnoe» всё ещё находил «iPhone».
- Контроль релевантности (правила ранжирования), чтобы вы могли определить, что значит «лучшее совпадение» для вашего бизнеса.
- Фильтры, сортировка и фасеты, чтобы пользователи могли сужать результаты по атрибутам: категория, ценовой диапазон, доступность, теги.
Он сделан так, чтобы быть отзывчивым и «прощать» ошибки, даже когда запрос короткий, слегка неверный или неоднозначный.
Чем Meilisearch не является
Meilisearch не заменяет вашу основную базу данных. База данных остаётся источником правды для записей, транзакций и ограничений. Meilisearch хранит копию тех полей, которые вы выбрали сделать доступными для поиска, фильтрации или отображения.
Хорошая ментальная модель: база данных — для хранения и обновления данных, Meilisearch — чтобы быстро их находить.
Ожидания по производительности (что влияет на скорость)
Meilisearch может быть очень быстрым, но это зависит от нескольких практических факторов:
- Размер и структура данных (количество документов, число полей и сколько текста вы индексируете)
- Аппаратное обеспечение (CPU, RAM, диск)
- Конфигурация (какие атрибуты делаются searchable/filterable/sortable и как часто вы переиндексируете)
Для небольших и средних наборов данных часто хватает одной машины. По мере роста индекса вам нужно будет продуманно выбирать, что индексировать и как поддерживать синхронизацию — темы для следующих разделов.
Планирование индексов и модели данных
Прежде чем что‑то устанавливать, решите, что именно вы собираетесь искать. Meilisearch будет казаться «мгновенным» только если ваши индексы и документы соответствуют тому, как люди просматривают ваше приложение.
Отображение сущностей в индексы
Сначала перечислите сущности, по которым будут искать: обычно products, articles, users, help docs, locations и т.д. Во многих приложениях самый простой подход — один индекс на тип сущности (например, products, articles). Это делает правила ранжирования и фильтры предсказуемыми.
Если ваш UX подразумевает поиск по разным типам в одном поле («искать всё»), вы всё ещё можете держать отдельные индексы и объединять результаты на бэкенде или создать отдельный «глобальный» индекс позже. Не сваливайте всё в один индекс, если поля и фильтры не согласованы.
Выбор первичного ключа и формы документа
Каждый документ нуждается в стабильном идентификаторе (primary key). Выберите такое поле, которое:
- никогда не меняется (или меняется крайне редко)
- уникально в пределах индекса
- уже есть в вашей базе данных (например,
id, sku, slug)
По форме документа предпочитайте плоские поля, когда это возможно. Плоская структура проще для фильтрации и сортировки. Вложенные объекты допустимы, когда они представляют тесно связанное неизменяемое сочетание (например, объект author), но избегайте глубокой иерархии, копирующей всю реляционную схему — документы для поиска должны быть оптимизированы для чтения, а не повторять структуру БД.
Классифицируйте поля: searchable, filterable, displayed
Практичный способ проектирования документов — присвоить каждому полю роль:
- Searchable: текст, который вводят люди (title, name, description)
- Filterable: атрибуты для ограничений (category, price range, status, tags)
- Displayed: что вы возвращаете UI (title, URL миниатюры, краткий фрагмент)
Это предотвращает распространённую ошибку — индексировать поле «на всякий случай» и потом удивляться, почему результаты шумные или фильтры медленные.
Планирование мультиязычного контента
«Язык» в ваших данных может означать разные вещи:
- язык документа (например,
lang: "en")
- локаль пользователя (язык интерфейса)
- смешанные языковые поля (названия товаров на нескольких языках)
Решите заранее, будете ли вы использовать отдельные индексы для каждого языка (просто и предсказуемо) или один индекс с полями языка (меньше индексов, больше логики). Подход зависит от того, ищут ли пользователи в одном языке за раз и как вы храните переводы.
Установка и запуск Meilisearch безопасно
Запустить Meilisearch просто, но «безопасно по умолчанию» требует нескольких решений: где его деплоить, как хранить данные и как обращаться с master key.
Варианты деплоя (выберите то, чем вы умеете управлять)
- Docker (самый распространённый): быстро стартовать, легко обновлять, одинаково в разных средах. Используйте при этом постоянный том для данных.
- VM или bare metal: хорошо, если у вас уже есть стандартная Linux‑практика деплоя (systemd, ротация логов, бэкапы).
- Управляемый хостинг: если команда не хочет поддерживать сервера, посмотрите на управляемые провайдеры Meilisearch или платформы с аддоном. Вы отдадите гибкость, но упростите операции.
Базовые требования окружения: хранилище, память, бэкапы, мониторинг
Хранилище: Meilisearch записывает индекс на диск. Разместите директорию данных на надёжном постоянном носителе (не на эфемерном контейнерном хранилище). Планируйте ёмкость под рост: индексы могут быстро увеличиваться при больших текстовых полях и множестве атрибутов.
Память: выделите достаточно RAM, чтобы поддерживать отзывчивость при нагрузке. При свопинге производительность падает.
Бэкапы: бэкапьте директорию данных Meilisearch (или снимки на уровне хранилища). Обязательно протестируйте восстановление; бэкап, который нельзя восстановить, — просто файл.
Мониторинг: отслеживайте CPU, RAM, диск и I/O. Логи и ошибки тоже должны попадать в систему мониторинга. Минимум — алерт при падении процесса или нехватке места на диске.
Установка и хранение master key безопасно
Всегда запускайте Meilisearch с master key вне локальной разработки. Храните его в секретном менеджере или в зашифрованном хранилище переменных окружения (не в Git, не в открытом .env).
Пример (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
Также подумайте о сетевых правилах: привязывать к приватному интерфейсу или ограничить входящие подключения так, чтобы только ваш бэкенд мог обращаться к Meilisearch.
Список перед первым запуском
curl -s http://localhost:7700/version
Индексирование документов и поддержание синхронизации
Настраивайте релевантность с уверенностью
Тестируйте изменения ранжирования и быстро откатывайтесь с помощью снимков и отката.
Индексирование в Meilisearch асинхронно: вы отправляете документы, Meilisearch ставит задачу в очередь, и только после успешного выполнения задачи эти документы становятся доступными для поиска. Обращайтесь с индексированием как с системой задач, а не как с одиночным запросом.
Простой поток индексирования (добавить → ждать → проверить)
- Добавьте документы (каждый документ с устойчивым уникальным id, обычно
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
- Дождитесь выполнения задачи. Ответ API содержит
taskUid. Ожидайте, пока его статус не станет succeeded (или failed).
curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Проверьте количество и базовый поиск. Подтвердите, что в индексе ожидаемое число документов и что простой запрос возвращает результаты.
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Если количество не совпадает, не делайте догадок — сначала проверьте детали ошибки задачи.
Группировка (batching), которая не удивит вас позже
Группировка нужна, чтобы задачи были предсказуемы и восстанавливались после ошибок.
- Начните с 1 000–10 000 документов на пакет, или ограничивайте по размеру полезной нагрузки (для многих приложений диапазон 5–15 МБ на запрос комфортен).
- Предпочитайте много небольших пакетов одному огромному; их легче повторить и локализовать проблемные данные.
- Если у вас частые изменения, индексируйте постоянно пакетами (например, каждую минуту), а не перестраивайте всё целиком.
Обновления против полной переиндексации
addDocuments работает как upsert: документы с тем же первичным ключом обновляются, новые — вставляются. Используйте это для обычных обновлений.
Делайте полную переиндексацию, когда:
- существенно изменилась форма документов,
- нужно пересчитать выводные поля,
- синхронизация сбилась и нужен чистый сброс.
Для удаления явно вызывайте deleteDocument(s), иначе старые записи могут остаться.
Идемпотентность: безопасные повторные попытки
Индексирование должно быть повторяемым. Ключ — стабильные id.
- Если загрузка пакета тайм‑аутится, можно отправить тот же пакет повторно: upsert + стабильные id предотвратят дубли.
- Сохраняйте возвращаемый
taskUid вместе с id пакета/задачи и повторяйте попытки, ориентируясь на статус задачи.
- В очередях делайте обработчик «at‑least‑once» безопасным: дубликаты не должны навредить.
Тестовые данные для быстрой предпрод тестовой проверки
Перед продуктивными данными индексируйте небольшой набор (200–500 элементов), соответствующий реальным полям. Пример: набор products с id, name, description, category, brand, price, inStock, createdAt. Это достаточно, чтобы проверить поток задач, количество и поведение обновления/удаления — без ожиданий при большом импорте.
Релевантность и правила ранжирования, которые вы можете контролировать
«Релевантность» — это просто: что показывается первым и почему. Meilisearch делает это настраиваемым без необходимости строить собственную систему скоринга.
Начните с правильных атрибутов
Две настройки определяют, как Meilisearch использует ваше содержимое:
searchableAttributes: поля, в которых Meilisearch ищет при вводе запроса (например: title, summary, tags). Порядок важен: ранние поля считаются более значимыми.displayedAttributes: поля, возвращаемые в ответе. Это важно для приватности и размера полезной нагрузки — если поле не отображается, оно не отправляется назад.
Практическая отправная точка — сделать поисковыми несколько полей с высоким сигналом (title, ключевой текст) и показывать только те поля, которые нужны UI.
Как правила ранжирования влияют на порядок результатов
Meilisearch сортирует подходящие документы, используя ranking rules — конвейер «тай‑брейкеров». Концептуально он предпочитает:
- результаты, хорошо соответствующие запросу (включая толерантность к опечаткам), затем
- результаты, где совпадения сильнее (ближе слова, матч в более важном атрибуте), затем
- результаты, соответствующие вашей бизнес‑логике (кастомная сортировка — новизна или популярность).
Вам не нужно знать все внутренности, чтобы эффективно настраивать: достаточно решить, какие поля важны и когда применять кастомную сортировку.
Частые цели настройки (с примерами)
Цель: «Совпадения в title должны побеждать.» Поместите title первым:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Цель: «Новые материалы должны быть выше.» Добавьте сортируемое поле и сортируйте при запросе (или задайте кастомное ранжирование):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Затем запросите:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Цель: «Продвигать популярные товары.» Сделайте popularity сортируемым и сортируйте по нему при необходимости.
Оценка изменений простым тестом до/после
Выберите 5–10 реальных запросов. Сохраните верхние результаты до изменений, затем сравните после.
Пример:
- До: запрос
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- После (title-first + exactness): запрос
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
Если «после» лучше соответствует пользовательскому намерению — оставьте настройки. Если возникают боковые эффекты, меняйте по одной вещи за раз (сначала порядок атрибутов, затем правила сортировки), чтобы понять причину улучшения.
Фильтры, сортировка и фасеты для реального поиска
Хороший поиск — это не только «вводи слова, получай совпадения». Люди также хотят сузить результаты («только в наличии») и отсортировать их («сначала дешёвые»). В Meilisearch это делается через фильтры, сортировку и фасеты.
Фильтры и фасеты (одна идея, разные UI)
Фильтр — правило, которое применяется к набору результатов. Фасет — то, что вы показываете в UI, чтобы помочь пользователям конструировать эти правила (обычно чекбоксы или счётчики).
Примеры:
- Категория: “Shoes”, “Jackets”, “Accessories”
- Цена: “До $50”, “$50–$100”
- Статус: “В наличии”, “Под заказ”, “Архив”
Пользователь может искать «running», затем отфильтровать category = Shoes и status = in_stock. Фасеты показывают счётчики, например “Shoes (128)”, чтобы пользователь понял доступность.
Настройка filterable и sortable полей (иначе они не будут работать)
Meilisearch требует явного разрешения полей для фильтрации и сортировки.
- Отмечайте поля как filterable:
category, status, brand, price, created_at, tenant_id.
- Отмечайте поля как sortable:
price, rating, created_at, popularity.
Держите этот список компактным. Делать всё filterable/sortable увеличит размер индекса и замедлит обновления.
Пaginация и лимиты, чтобы держать поиск быстрым
Даже при 50 000 совпадений пользователь видит только первую страницу. Используйте маленькие страницы (обычно 20–50 результатов), задавайте sensible limit и реализуйте пагинацию через offset (или новые механизмы пагинации). Также ограничьте максимальную глубину страниц в приложении, чтобы предотвратить дорогие запросы на «странице 400».
Синонимы и стоп‑слова (используйте аккуратно)
- Синонимы помогают, когда разные слова значат одно и то же (например, “hoodie” ↔ “sweatshirt”). Добавляйте постепенно и анализируйте логи поиска — слишком много синонимов могут дать неожиданные совпадения.
- Стоп‑слова убирают распространённые слова («the», «and»). Они могут снизить шум, но также повредить точечные запросы вроде названий («The Who», «A Team»). Меняйте стоп‑слова только при явной проблеме.
Интеграция Meilisearch в бэкенд вашего приложения
Переведите проект из локального режима в продакшн
Разверните и разместите приложение, затем корректируйте релевантность без рискованных ручных изменений.
Чистый способ добавить серверный поиск — делать Meilisearch специальным сервисом за вашим API. Ваше приложение получает запрос поиска, вызывает Meilisearch, затем возвращает клиенту отфильтрованный ответ.
Простой шаблон бэкенда
Обычно команды используют такой поток:
- Клиент вызывает ваш endpoint (например,
GET /api/search?q=wireless+headphones&limit=20).
- Бэкенд валидирует вход, применяет бизнес‑правила и решает, какой индекс запрашивать.
- Бэкенд вызывает Search API Meilisearch с пользовательским запросом и фильтрами/сортировкой.
- Бэкенд пост‑обрабатывает результаты (скрывает приватные поля, объединяет с данными БД, применяет права доступа).
- Бэкенд возвращает клиенту стабильную форму ответа.
Этот шаблон делает Meilisearch заменяемым и предотвращает зависимость фронтенда от внутренней структуры индекса.
Если вы строите новое приложение и хотите быстро реализовать этот шаблон, платформы‑вещи вроде Koder.ai могут помочь заскелетить полный поток — React UI, Go‑бэкенд и PostgreSQL — и интегрировать Meilisearch за одним /api/search endpoint, чтобы клиент оставался простым, а права — на стороне сервера.
Запросы с фронтенда против бэкенда (и почему бэкенд безопаснее)
Meilisearch поддерживает клиентские запросы, но обычно безопаснее делать запросы через бэкенд, потому что:
- Секреты остаются приватными: вы не раскрываете привилегированные ключи.
- Авторизация последовательная: бэкенд может применить «что пользователь может видеть» перед возвратом результатов.
- Вы контролируете сложность запросов: лимитируете фильтры, опции сортировки и пагинацию для защиты производительности.
Клиентские запросы подходят для публичных данных с ограниченными ключами, но если есть правила видимости для пользователей — делайте запросы через сервер.
Кэширование популярных запросов без нарушения релевантности
Трафик поиска часто повторяется («iphone case», «return policy»). Кешируйте на уровне API:
- Кешируйте полный ответ на короткий период (10–60 секунд) для анонимного трафика.
- Нормализуйте ключи кеша (обрезайте пробелы, приводите к нижнему регистру, включайте фильтры/сортировку).
- Инвалидация по‑уму: для быстро меняющихся индексов держите TTL коротким вместо агрессивной чистки.
Ограничение скорости и защита от злоупотреблений
Относитесь к поиску как к публичному endpoint:
- Применяйте лимиты по IP или по пользователю.
- Устанавливайте максимальный
limit и максимальную длину запроса.
- Рассмотрите мягкие блокировки для ботов, но не мешайте реальным пользователям.
Основы безопасности: ключи, контроль доступа и мультитенантность
Meilisearch часто ставят «за» вашим приложением, потому что он быстро возвращает бизнес‑данные. Обращайтесь с ним как с базой: закрывайте доступ и выдавайте только то, что должен видеть вызывающий.
API ключи: master против ограниченных (принцип наименьших привилегий)
Meilisearch имеет master key, который может всё: создавать/удалять индексы, обновлять настройки и читать/писать документы. Держите его только на сервере.
Для приложений генерируйте ключи с ограниченными правами и индексами. Обычная схема:
- Jobs на бэкенде: ключ, который может записывать документы и обновлять настройки, но только для определённых индексов.
- Сервер приложения: ключ только для чтения (search).
- Клиент (если нужно): тесно ограниченный search‑only ключ с жёсткими фильтрами.
Принцип наименьших привилегий означает, что скомпрометированный ключ не сможет удалить данные или читать чужие индексы.
Мультитенантность: отдельные индексы или фильтр по tenantId
Если вы обслуживаете нескольких клиентов (тенантов), есть два основных подхода:
1) Один индекс на тенанта.
Просто моделируется и уменьшает риск доступа между тенантами. Минусы: больше индексов управлять и нужно поддерживать консистентность настроек.
2) Общий индекс + фильтр tenantId.
Храните поле tenantId в каждом документе и требуйте фильтр tenantId = "t_123" для всех поисков. Это может масштабироваться, но вы должны гарантировать, что каждый запрос всегда применяет фильтр (идеально через скоуп‑ключ, чтобы клиент не мог удалить фильтр).
Предотвращение утечек данных: контроль возвращаемых полей
Даже если поиск корректен, результаты могут случайно выдавать приватные поля (email, внутренние заметки, себестоимость). Настройте, что можно возвращать:
- Ограничьте displayed/retrievable attributes безопасным allowlist.
- Индексируйте чувствительные поля только при необходимости и не возвращайте их в результатах.
Сделайте «worst‑case» тест: выполните поиск по общему слову и проверьте, что приватные поля не появляются.
Операционная безопасность
- Ограничьте сетевой доступ: привяжите к localhost или приватной сети, разрешите подключение только с ваших серверов.
- Поставьте Meilisearch за reverse proxy, если нужен TLS и rate limiting.
- Храните ключи в секретном менеджере (не в репозитории или в бандлах фронтенда) и регулярно их ротируйте.
Если сомневаетесь, нужен ли ключ на стороне клиента — ответ чаще всего «нет»; держите поиск на сервере.
Производительность и масштабирование без догадок
Сохраняйте полный контроль над кодом
Владейте кодовой базой — экспортируйте исходники, когда будете готовы развить проект.
Meilisearch быстр, когда вы учитываете два рабочих потока: индексирование (запись) и запросы поиска (чтение). Большая часть «непонятной» медлительности — это конкуренция за CPU, RAM или диск между этими нагрузками.
Где обычно возникают узкие места
Нагрузка индексирования может всплывать при больших пакетных импортов, частых обновлениях или при индексации множества полей. Индексирование — фоновая работа, но оно всё равно потребляет CPU и диск. Если очередь задач растёт, поиски начнут медлеть, даже если трафик запросов не изменился.
Нагрузка запросов растёт с трафиком, а также с функционалом: больше фильтров, фасетов, больших наборов результатов и более агрессивной толерантностью к опечаткам увеличивают работу на запрос.
Disk I/O — тихий виновник. Медленные диски (или «шумные соседи» на шаред‑томе) могут превратить «мгновенно» в «в конце концов». NVMe/SSD — типичный минимум для продакшна.
Практические шаги масштабирования
Начните с простого: выделите Meilisearch достаточно RAM, чтобы держать индексы в памяти, и достаточно CPU для пиков QPS. Затем разделите обязанности:
- Если индексирование мешает чтениям, планируйте массовые импорты вне пиков и предпочитайте большие пакеты вместо множества мелких обновлений.
- Добавьте реплики для высокой доступности и увеличения чтения (балансируйте запросы между репликами).
- Шардинг: Meilisearch не делает автоматический шардинг. Если вы выросли из одной ноды, вы можете партицировать данные на уровне приложения (по тенанту, региону или интервалу времени) в несколько индексов или кластеров.
Что мониторить (чтобы не гадать)
Отслеживайте небольшой набор метрик:
- Задержка поиска (p50/p95) и пропускная способность
- Длина очереди задач / время обработки задач (рост очереди = индексирование не успевает)
- CPU, RAM, диск и ожидание I/O
- Ошибки (таймауты, 4xx/5xx, неуспешные задачи)
Резервное копирование и планирование обновлений
Бэкапы должны быть рутинными. Используйте функцию snapshot Meilisearch по расписанию, храните снапшоты вне машины и периодически тестируйте восстановление. Для апгрейдов читайте релиз‑ноты, прогоняйте апгрейд в stage‑среде и планируйте время на переиндексацию, если версия меняет способ индексирования.
Если вы уже используете снапшоты окружения и rollback в платформе (например, через рабочие процессы снапшотов/отката в Koder.ai), приведите rollout поиска к той же дисциплине: снимайте снапшот перед изменениями, проверяйте health‑чек и держите быстрый путь отката.
Устранение неполадок и практический чеклист для развёртывания
Даже при аккуратной интеграции проблемы с поиском обычно укладываются в несколько повторяющихся категорий. Хорошая новость: Meilisearch даёт достаточно видимости (задачи, логи, детерминированные настройки), чтобы быстро дебажить, если действовать системно.
Частые проблемы (и что они обычно означают)
- «Мои фильтры не работают»: поле не добавлено в
filterableAttributes, или документы хранят его в неожиданной форме (строка vs массив vs вложенный объект).
- «Результаты ранжируются странно»: правила ранжирования, синонимы, стоп‑слова или отсутствие
sortableAttributes/rankingRules меняют порядок.
- «Поиск показывает старые данные»: задачи индексирования ещё выполняются, вы пишете в другой индекс, чем читаете, или в пайплайне синхронизации пропущены обновления/удаления.
Рабочий порядок отладки, который не сводит с ума
Начните с проверки, успешно ли Meilisearch применил последнее изменение.
- Проверьте статус задачи: каждое изменение настроек и обновление документов создаёт асинхронную задачу. Если задача упала — сначала исправьте это (некорректная полезная нагрузка, неверные типы полей, слишком большие документы).
- Смотрите логи с одной целью: «Принял ли сервер мой запрос?» затем «Закончил ли он обработку?» Не пытайтесь читать всё сразу.
- Создайте минимально воспроизводимый запрос:
- Выберите один индекс.
- Используйте запрос, возвращающий небольшой и стабильный набор.
- Добавляйте ограничения по одному:
filter, затем sort, затем facets.
Если не можете объяснить результат, временно упростите конфигурацию: отключите синонимы, уменьшите правки ранжирования и протестируйте на маленьком наборе данных. Сложные проблемы релевантности легче заметить на 50 документах, чем на 5 миллионах.
Стратегия развёртывания: уменьшение радиуса поражения
- Тестовый индекс сначала: соберите
your_index_v2 параллельно, примените настройки и проиграйте выборку продовых запросов.
- Канарейка: направьте небольшую долю трафика на новый индекс или настройки, сравнивайте CTR и частоту «нет результатов».
- Fallback: определите, что видит пользователь, если поиск медленный или недоступен — кешированные результаты, упрощённый запрос или дружелюбное сообщение «повторите попытку». Не допускайте, чтобы проблемы поиска ломали всю страницу.
Чеклист следующих шагов
- Убедитесь, что
filterableAttributes и sortableAttributes соответствуют UI.
- Подтвердите, что задачи индексирования завершаются успешно после каждого деплоя.
- Добавьте простой «health» монитор для поиска (латентность + ошибки задач).
- Попрактикуйтесь в откате: переключите трафик обратно на предыдущий индекс.
Related guides: /blog (search reliability, indexing patterns, and production rollout tips).