Определите цели и сигналы принятия
Прежде чем строить оценку здоровья принятия продукта, решите, что эта оценка должна делать для бизнеса. Оценка, предназначенная для триггеров оповещений о риске оттока, будет отличаться от той, что служит для руководства по онбордингу, обучения клиентов или улучшений продукта.
Определите, что значит «принятие» для вашего продукта
Принятие — это не просто «недавний вход». Запишите несколько поведения, которые действительно показывают, что клиенты получают ценность:
- Активация: первый момент, когда пользователь достигает значимого результата (например, «пригласил коллегу», «подключил источник данных», «опубликовал отчёт»).
- Ключевые действия: повторяемые, высокосигнальные действия, коррелирующие с успешными аккаунтами (например, еженедельные экспорты, запуски автоматизаций, дашборды, просматриваемые несколькими пользователями).
- Удержание: продолжительное использование в нужном ритме для вашего продукта (ежедневно, еженедельно, ежемесячно), желательно несколькими пользователями в аккаунте.
Они становятся вашими первоначальными сигналами принятия для аналитики использования функций и последующего анализа когорт.
Перечислите решения, которые должно обеспечивать приложение
Будьте конкретны относительно того, что происходит при изменении оценки:
- Кто получает уведомление, когда аккаунт опускается ниже порога?
- Какие плейбуки должны запускаться (аутрич, обучение, проверка поддержки)?
- Какие инсайты должны подпитывать мониторинг принятия продукта (точки трения, недоиспользуемые функции, time-to-value)?
Если вы не можете назвать решение — не отслеживайте метрику пока.
Определите пользователей, роли и временные окна
Уточните, кто будет пользоваться панелью customer success:
- Менеджеры CS нуждаются в приоритизации и контексте аккаунта.
- Продукт нужен для поиска паттернов, когорт и движения на уровне функций.
- Поддержка интересуется недавней активностью в привязке к тикетам и инцидентам.
- Руководство требует понятной агрегации и тренда.
Выберите стандартные окна — последние 7/30/90 дней — и учитывайте стадии жизненного цикла (trial, onboarding, steady‑state, renewal). Это предотвратит сравнение нового аккаунта с зрелым.
Установите критерии успеха
Определите «готово» для модели health score:
- Точность: предсказывает ли модель риск/сигналы экспансии лучше текущего подхода?
- Объяснимость: может ли CSM объяснить почему оценка высокая/низкая за одну минуту?
- Удобство: экономит ли она время и приводит ли к последовательным действиям?
Эти цели формируют всё: трекинг событий, логику скоринга и рабочие процессы вокруг оценки.
Выберите метрики для вашей оценки здоровья
Выбор метрик — момент, когда оценка становится полезным сигналом или шумной цифрой. Стремитесь к небольшому набору индикаторов, отражающих реальное принятие — не просто активность.
Начните с продуктовых сигналов принятия
Выберите метрики, показывающие, получают ли пользователи ценность регулярно:
- Логины / активные пользователи: например, weekly active users (WAU) и тренд за последние 4–8 недель.
- Active days: число уникальных дней активности аккаунта за неделю/месяц (помогает избежать ложных положительных «одна большая сессия»).
- Глубина использования функций: использование ваших «ценностных функций», а не каждого клика по кнопке.
- Подключённые интеграции: особенно если интеграции повышают барьер переключения или открывают ключевые сценарии.
- Использование мест: процент приобретённых мест, которые приглашены, активированы и действительно активны.
Держите список сфокусированным. Если вы не можете объяснить значение метрики в одном предложении — вероятно, это не основной вход.
Добавьте бизнес‑контекст (чтобы оценки были справедливы)
Принятие нужно интерпретировать в контексте. Команда из 3 мест будет вести себя иначе, чем развёртывание на 500 мест.
Распространённые сигналы контекста:
- Тарифный план и доступные функции
- Размер контракта / диапазон ARR
- Стадия жизненного цикла: trial vs недавно оплачено vs окно продления
Они не обязаны «добавлять очки», но помогают задавать реалистичные ожидания и пороги по сегментам.
Решите, какие индикаторы ведущие, а какие — запаздывающие
Полезная оценка смешивает:
- Ведущие индикаторы (предсказывают будущий успех): рост активных дней, завершение онбординга, первая подключённая интеграция.
- Запаздывающие индикаторы (подтверждают исходы): продление, экспансия, долгосрочное удержание.
Избегайте переувески запаздывающих метрик — они рассказывают о том, что уже произошло.
Опционально: качественные входы (используйте осторожно)
Если у вас есть данные, NPS/CSAT, объём тикетов поддержки и заметки CSM могут добавить нюанс. Используйте их как модификаторы или флаги — не как основу, потому что качественные данные могут быть редкими и субъективными.
Создайте простой словарь данных
Перед построением графиков согласуйте названия и определения. Легковесный data dictionary должен включать:
- Название метрики (например,
active_days_28d)
- Чёткое определение (что считается, что нет)
- Временное окно и частоту обновления
- Систему‑источник (product events, CRM, support)
Это предотвратит путаницу «та же метрика — разный смысл» при реализации дашбордов и оповещений.
Спроектируйте объяснимую модель оценки
Оценка принятия работает только тогда, когда команда ей доверяет. Стремитесь к модели, которую можно объяснить за одну минуту CSM и за пять минут заказчику.
Начните просто: взвешенные очки (до ML)
Начните с прозрачной правиловой модели. Выберите небольшой набор сигналов принятия (например, активные пользователи, использование ключевых функций, включённые интеграции) и назначьте веса, отражающие «aha»-моменты продукта.
Пример весов:
- Weekly active users per seat: 0–40 баллов
- Частота использования ключевых функций: 0–35 баллов
- Ширина используемых функций: 0–15 баллов
- Время с последней значимой активности: 0–10 баллов
Держите веса легко защищаемыми. Их можно пересматривать позже — не ждите идеальной модели.
Нормализуйте, чтобы уменьшить смещение
Сырые счётчики наказывают маленькие аккаунты и сглаживают большие. Нормализуйте, где это важно:
- На место (usage / licensed seats)
- По возрасту аккаунта (новые vs зрелые аккаунты)
- По тарифу (доступность функций)
Это помогает оценке отражать поведение, а не размер.
Определите зоны Зеленый/Жёлтый/Красный с понятной логикой
Задайте пороги (например, Зелёный ≥ 75, Жёлтый 50–74, Красный < 50) и задокументируйте, почему каждый порог существует. Свяжите пороги с ожидаемыми исходами (риск продления, завершение онбординга, готовность к экспансии) и храните примечания в внутренних доках или на /blog/health-score-playbook.
Сделайте модель объяснимой: драйверы и тренд
Каждая оценка должна показывать:
- Топ‑3 вкладчика (что помогло/повредило)
- Изменение во времени (последние 7/30 дней)
- Понятное резюме («Использование Feature X упало на 35% неделя к неделе»)
Планируйте итерации: версионируйте модель
Относитесь к скорингу как к продукту. Версионируйте (v1, v2) и отслеживайте эффект: стали ли оповещения о риске точнее? Действуют ли CSM быстрее? Храните версию модели с каждым расчётом, чтобы можно было сравнить результаты во времени.
Инструментируйте продуктовые события и источники данных
Оценка полезна ровно настолько, насколько надёжны данные активности под ней. Перед реализацией логики скоринга убедитесь, что нужные сигналы попадают в систему последовательно.
Выберите источники событий
Большинство программ принятия используют смесь:
- Frontend events (просмотры страниц, клики, взаимодействия с функцией)
- Backend actions (API‑вызовы, выполненные задания, созданные записи)
- Биллинг (план, продления, статус оплаты, число мест)
- Инструменты поддержки и успеха (тикеты, CSAT, этапы онбординга)
Практическое правило: критические действия трекать сервер‑сайд (труднее подделать, меньше зависит от блокировщиков рекламы), фронтенд‑события — для вовлечения UI и discovery.
Определите единый схематичный формат событий
Держите контракт событий единообразным, чтобы их было просто объединять, запрашивать и объяснять заинтересованным сторонам. Базовый набор:
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id и т. п.)
Используйте контролируемую номенклатуру для event_name (например, project_created, report_exported) и документируйте это в простом tracking plan.
Выбор SDK vs сервер‑сайд (или оба)
- SDK‑трекинг быстро запускается и хорош для UI‑событий.
- Сервер‑сайд трекинг лучше для system‑of‑record действий.
Многие команды делают и то, и другое, но следите, чтобы одно и то же реальное действие не учитывалось дважды.
Правильно обрабатывайте идентификацию
Оценки обычно агрегируются на уровне аккаунта, поэтому нужна надёжная связка user→account. Планируйте для:
- Пользователей, принадлежащих нескольким аккаунтам
- Слияний аккаунтов (поглощения, консолидация рабочих пространств)
- Анонимизированных ID для поведения до логина (с безопасным мерджем после регистрации)
Встраивайте проверки качества данных
Минимум — мониторьте пропущенные события, всплески дубликатов и согласованность часовых поясов (храните UTC; конвертируйте для отображения). Флагируйте аномалии рано, чтобы оповещения о риске не срабатывали из‑за поломки трекинга.
Смоделируйте данные и хранилище
Веб‑приложение оценки здоровья принятия выживает или умирает по тому, насколько хорошо вы моделируете «кто что сделал и когда». Цель — чтобы типичные вопросы быстро отвечались: «Как этот аккаунт ведёт себя на этой неделе? Какие функции идут вверх или вниз?» Хорошая модель данных упрощает скоринг, дашборды и оповещения.
Основные сущности для модели
Начните с небольшого набора "источников правды":
- Accounts: account_id, plan, segment, lifecycle_stage, CSM owner
- Users: user_id, account_id, role/persona, created_at, status
- Subscriptions (или контракты): account_id, start/end, seats, MRR, renewal_date
- Features: feature_id, name, category (activation, collaboration, admin и т. п.)
- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores: account_id, score_date (или computed_at), overall_score, component_scores, explanation_fields
Держите сущности консистентными через стабильные ID (account_id, user_id) везде.
Разделение хранилища: реляционное + аналитика
Используйте реляционную БД (например, Postgres) для accounts/users/subscriptions/scores — объектов, которые вы обновляете и часто джоините.
Храните высокообъёмные события в хранилище/веархе (например, BigQuery/Snowflake/ClickHouse). Это держит дашборды и анализ когорт отзывчивыми без перегрузки транзакционной БД.
Храните агрегаты для скорости
Вместо пересчёта всего с сырых событий поддерживайте:
- Ежедневные сводки по аккаунту (одна строка на аккаунт на день): активные пользователи, ключевые счётчики событий, последняя активность, этапы принятия
- Счётчики по функциям: по аккаунту/дню/функции — количество использований, уникальные пользователи, время (если доступно)
Эти таблицы питают тренд‑чарты, инсайты «что изменилось» и компоненты health score.
Ретеншн, партиционирование и производительность запросов
Для больших таблиц событий планируйте ретеншн (например, 13 месяцев сырых данных, дольше для агрегатов) и партиционируйте по дате. Кластеризуйте/индексируйте по account_id и timestamp/date для ускорения запросов «аккаунт во времени».
В реляционных таблицах индексируйте частые фильтры и джои: account_id, (account_id, date) в сводках, и используйте внешние ключи для чистоты данных.
Спланируйте архитектуру веб‑приложения
Чётко спланируйте модель
Отобразите события, метрики и пороги до кодирования, затем реализуйте всё по единому плану.
Архитектура должна позволять быстро выпустить надёжный v1, а затем расти без полного переписывания. Начните с минимально нужного количества компонентов.
Монолит vs сервисы (сделайте v1 простым)
Для большинства команд модульный монолит — самый быстрый путь: один код‑бейс с чёткими границами (ингест, скоринг, API, UI), один деплой и меньше операционных сюрпризов.
Переходите к сервисам только при явной необходимости — независимое масштабирование, строгая изоляция данных или отдельные команды. Ранний распад на сервисы увеличивает точки отказа и замедляет итерацию.
Определите ключевые компоненты
Минимально запланируйте следующие ответственности (даже если они живут в одном приложении):
- Ingestion: принимает продуктовые события (SDK, Segment, webhook, пакетный импорт).
- Aggregation: превращает сырые события в ежедневные/недельные факты по аккаунту/пользователю.
- Scoring: вычисляет оценку здоровья принятия и объяснения.
- API: отдаёт оценки, тренды и «почему» в UI и интеграциям.
- UI: дашборд customer success с аккаунт‑вью, когортами и детализацией.
Если нужно быстро прототипировать, подход vibe‑coding поможет получить работающий дашборд без больших усилий. Например, Koder.ai может сгенерировать React UI и бэкенд на Go + PostgreSQL по простому описанию сущностей (accounts, events, scores), эндпоинтов и экранов — полезно для поднятия v1, чтобы CS команда ранжировала фидбек.
Плановые задания vs стриминг
Батч‑скоринг (например, ежечасно/ежедневно) обычно достаточно для мониторинга принятия и гораздо проще в эксплуатации. Стриминг оправдан, если нужны near‑real‑time оповещения (внезапный провал активности) или очень большой объём событий.
Практический гибрид: инжест событий непрерывен, агрегирование/скоринг по расписанию, а стриминг оставьте для ограниченного набора срочных сигналов.
Среды, секреты и нефункциональные требования
Разверните dev/stage/prod заранее, с примерными аккаунтами в stage для проверки дашбордов. Используйте управляемое хранилище секретов и ротацию ключей.
Задокументируйте ожидаемый объём событий, свежесть оценки (SLA), целевые задержки API, доступность, ретеншн и ограничения конфиденциальности (обращение с PII и контроль доступа). Это предотвращает принятие архитектурных решений в последний момент под давлением.
Постройте data pipeline и задания скоринга
Оценка полезна ровно настолько, насколько надёжна последовательность, её производящая. Обращайтесь с скорингом как с продакшен‑системой: воспроизводимая, наблюдаемая и понятная, когда спрашивают «Почему сегодня упал счёт этого аккаунта?"
Простой пайплайн: raw → validated → aggregates
Начните со стадии, которая сужает данные до того, что можно безопасно скорить:
- Raw events: append‑only инжест из приложения, мобильных клиентов, интеграций и экспортов биллинга/CRM.
- Validated events: события, прошедшие схемные проверки (обязательные поля, типы), проверки идентичности (user→account) и дедупликацию.
- Daily aggregates: сводки по аккаунту (и, при необходимости, workspace/team) — активные пользователи, ключевые счётчики, milestones time‑to‑value, дельты трендов.
Такая структура делает задания скоринга быстрыми и стабильными, потому что они работают с чистыми компактными таблицами, а не с миллиардами сырых строк.
Расписания перерасчёта и бэкофилы
Решите, насколько «свежая» должна быть оценка:
- Часовой скоринг подходит для высокочастотных действий CSM.
- Дневной чаще всего достаточен для SMB/self‑serve и экономит ресурсы.
Сделайте планировщик с поддержкой backfill (перепроработка последних 30/90 дней), когда вы фиксируете трекинг, меняете веса или добавляете сигнал. Backfill должен быть first‑class возможностью, а не аварийным скриптом.
Идемпотентность: избегайте двойного счёта
Задания будут ретрайниться. Импорты — переисполняться. Вебхуки — доставляться дважды. Проектируйте под это.
Используйте idempotency key для событий (event_id или стабильный хеш от timestamp + user_id + event_name + properties) и обеспечьте уникальность на validated‑слое. Для агрегатов делайте upsert по (account_id, date), чтобы при перерасчёте старые результаты заменялись, а не суммировались.
Мониторинг и проверки аномалий
Добавьте операционный мониторинг для:
- Успех/провал заданий и счётчики ретраев
- Задержки данных (насколько отстают последние агрегаты от «сейчас»)
- Аномалии объёма (внезапные провалы/пики в событиях, активных пользователях, ключевых действиях)
Даже простые пороги (например, «событий упало на 40% vs 7‑дневного среднего») предотвращают молчаливые поломки, которые исказят дашборд customer success.
Аудит‑трейсы для каждой оценки
Храните аудит‑запись на аккаунт для каждого прогона скоринга: входные метрики, производные признаки (например, изменение неделя‑к‑неделе), версия модели и итоговый счёт. Когда CSM нажимает «Почему?», вы сможете показать точно, что изменилось и когда — без обратного инженеринга по логам.
Создайте безопасный API для здоровья и инсайтов
Построить пайплайн скоринга
Быстро прототипируйте аккаунты, события, агрегаты и задания скоринга, чтобы команда могла раньше приступить к итерациям.
Веб‑приложение живёт или умирает по своему API. Это контракт между заданиями скоринга, UI и сторонними инструментами (CS платформы, BI, экспорт данных). Стремитесь к быстрому, предсказуемому API, безопасному по умолчанию.
Ключевые эндпоинты для рабочих процессов
Проектируйте эндпоинты вокруг того, как Customer Success изучает принятие:
- Account health:
GET /api/accounts/{id}/health возвращает последнюю оценку, статусную банду (Зеленый/Жёлтый/Красный) и время последнего расчёта.
- Trends:
GET /api/accounts/{id}/health/trends?from=&to= для серии оценок во времени и ключевых дельт метрик.
- Drivers («почему»):
GET /api/accounts/{id}/health/drivers чтобы показать топ положительных/отрицательных факторов (например, «weekly active seats упали на 35%»).
- Cohorts:
GET /api/cohorts/health?definition= для анализа когорт и бенчмарков по сверстникам.
- Exports:
POST /api/exports/health для генерации CSV/Parquet с согласованными схемами.
Фильтры, пагинация и кэширование
Сделайте список‑эндпоинты удобными для срезов:
- Фильтры:
plan, segment, csm_owner, lifecycle_stage, date_range — базовые нужны.
- Пагинация: используйте курсорную пагинацию (
cursor, limit) для стабильности при изменении данных.
- Кэширование: кешируйте тяжёлые запросы (когорт‑роллапы, тренды) и возвращайте
ETag/If-None-Match, чтобы снизить повторные нагрузки. Учитывайте фильтры и права в ключах кеша.
Безопасность с RBAC
Защитите данные на уровне аккаунта. Реализуйте RBAC (например, Admin, CSM, Read‑only) и проверяйте его сервер‑сайд на каждом эндпоинте. CSM должен видеть только свои аккаунты; финансовые роли — агрегаты по планам, но не уровни пользователей.
Всегда возвращайте объяснимость
Вместе с числовой оценкой здоровья возвращайте поля «почему»: топ‑драйверы, затронутые метрики и базовую линию сравнения (предыдущий период, медиана когорты). Это превращает мониторинг принятия продукта в действия, а не отчётность, и делает вашу панель customer success надёжной.
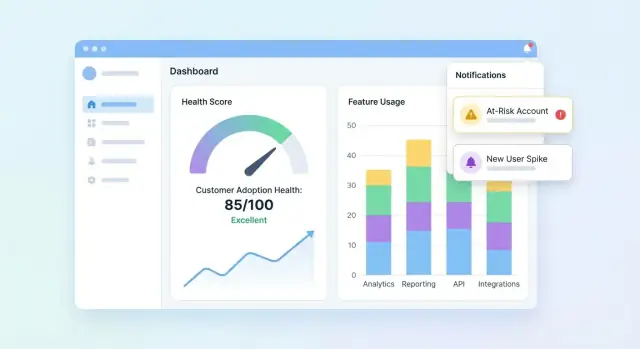
Спроектируйте дашборды и вью аккаунта
UI должен быстро отвечать на три вопроса: Кто здоров? Кто скользит вниз? Почему? Начните с панели, суммирующей портфель, и позвольте пользователям углубляться в аккаунт, чтобы понять историю за оценкой.
Необходимое на портфельной панели
Включите компактный набор тайлов и графиков, которые команда CS сканирует за секунды:
- Распределение оценок (гистограмма или бакеты Здоров / На контроле / Риск)
- Список в зоне риска с полями для действий (аккаунт, владелец, оценка, последняя активность, топ‑драйвер)
- Тренд оценок во времени (линейный график) с фильтрами по сегментам
Сделайте список кликабельным, чтобы пользователи могли открыть аккаунт и сразу увидеть, что изменилось.
Просмотр аккаунта: объясните оценку
Страница аккаунта должна читаться как таймлайн принятия:
- Таймлайн ключевых событий (завершение онбординга, подключение интеграций, изменения админов, первое использование важных функций)
- Ключевые метрики (активные пользователи, ключевые действия, время с последней значимой активности)
- Разбивка по функциям: какие функции усвоены, игнорируются или регрессируют
Добавьте панель «Почему такая оценка?»: клик по оценке раскрывает вкладчики (положительные и отрицательные) с объяснениями на простом языке.
Когортные и сегментные представления
Дайте фильтры когорт, которые соответствуют управлению аккаунтами: когорты онбординга, тарифные уровни, отрасли. Пара проветров с линиями трендов и небольшой таблицей топ‑муверов помогает сравнивать исходы и замечать паттерны.
Доступные и надёжные визуалы
Используйте понятные подписи и единицы, избегайте неоднозначных иконок и предлагайте цветобезопасные индикаторы (например, текст + формы). Отмечайте пики, показывайте диапазоны дат и делайте поведение drill‑down последовательным.
Добавьте оповещения, задачи и рабочие процессы
Оценка полезна только если приводит к действию. Оповещения и рабочие процессы превращают «интересные данные» в своевременные обращения, исправления онбординга или product nudges — без необходимости постоянно смотреть в дашборды.
Определите правила оповещений, связанные с реальным риском
Начните с небольшого набора высокосигнальных триггеров:
- Падение оценки (например, минус 15 баллов неделя к неделе)
- Красный статус (пересечение критического порога)
- Внезапный спад использования (ключевая функция упала ниже базовой линии)
- Неудачный шаг онбординга (застрявший чеклист, интеграция не завершена)
Делайте каждое правило явным и объяснимым. Вместо «Плохое здоровье» оповещайте «Нет активности в Feature X в течение 7 дней + онбординг не завершён».
Выберите каналы и сделайте их настраиваемыми
Разные команды работают по‑разному — обеспечьте поддержку каналов и настройки:
- Email для владельцев аккаунтов и менеджеров
- Slack для командной видимости и быстрого реагирования
- In‑app tasks в панели customer success, чтобы работа не терялась
Позвольте настраивать: кто получает уведомления, какие правила включены и что значит «срочно».
Снижайте шум при помощи правил безопасности
Усталость от оповещений убивает мониторинг. Добавьте контролы, например:
- Окна кулдауна (не оповещать повторно по тому же аккаунту N часов/дней)
- Минимальные пороги данных (пропуск оповещений, если у аккаунта слишком мало данных)
- Группировка/дайджесты для несрочных сигналов (ежедневные/еженедельные)
Добавляйте контекст и следующие шаги
Каждое оповещение должно отвечать: что изменилось, почему это важно и что делать дальше. Включайте недавние драйверы оценки, короткий таймлайн (например, последние 14 дней) и предложенные задачи вроде «Запланировать онбординг‑звонок» или «Отправить гайд по интеграции». Ссылка на аккаунт: /accounts/{id}.
Отслеживайте результаты, чтобы замкнуть цикл
Относитесь к оповещениям как к рабочим элементам со статусами: подтверждено, связан(ось с клиентом), восстановлено, отток. Отчётность по исходам помогает шлифовать правила, улучшать плейбуки и доказывать, что оценка влияет на удержание.
Обеспечьте качество данных, приватность и управление
Подготовьте для команды
Разместите дашборд CS на собственном домене для удобного внутреннего доступа.
Если оценка построена на ненадёжных данных, команда перестанет ей доверять и перестанет действовать. Рассматривайте качество, приватность и governance как элементы продукта, а не как дописанные позже.
Настройте автоматические проверки данных
Начните с лёгкой валидации на каждом этапе (ingest → warehouse → scoring output). Пара тестов с высоким сигналом ловят большинство проблем рано:
- Проверки схемы: ожидаемые колонки есть, типы не поменялись, enum‑значения валидны.
- Проверки диапазонов: невозможные значения (отрицательные сессии, будущие timestamps) проваливают проверку.
- Проверки null: обязательные поля (account_id, event_name, occurred_at) не могут быть пустыми.
При провале тестов — блокируйте скоринг (или помечайте результаты как «устаревшие»), чтобы сломанный пайплайн не генерировал вводящие в заблуждение оповещения.
Обрабатывайте распространённые краевые случаи явно
Скоринг ломается на «странных, но нормальных» сценариях. Опишите правила для:
- Новых аккаунтов с мало данных: показывайте «недостаточно данных» или используйте рampp‑baseline вместо низкой оценки.
- Сезонного использования: сравнивайте с прошлым периодом аккаунта или когорты, а не с универсальным порогом.
- Аутейджей и пропусков трекинга: помечайте пострадавшие окна и не штрафуйте клиентов за простой вашей системы.
Добавьте права и приватность
Ограничьте PII по умолчанию: храните только то, что нужно для мониторинга принятия. Применяйте RBAC в веб‑приложении, логируйте, кто просматривал/экспортировал данные, и редактируйте экспорты, когда поля не нужны (например, скрывайте email в CSV).
Создайте руководы и практики управления
Напишите короткие runbook‑ы для инцидентов: как приостановить скоринг, сделать backfill и перезапустить исторические задания. Регулярно пересматривайте метрики customer success и веса оценки — ежемесячно или ежеквартально — чтобы предотвратить дрейф по мере развития продукта. Для согласования процессов свяжите внутренний чеклист с /blog/health-score-governance.
Валидируйте, итерайте и масштабируйте оценку
Валидация — то место, где оценка перестаёт быть «красивым графиком» и становится достаточно доверенной, чтобы управлять действием. Относитесь к первой версии как к гипотезе.
Проведите пилот и откалибруйте против человеческого суждения
Начните с пилотной группы аккаунтов (например, 20–50 по сегментам). Для каждого аккаунта сравните оценку и причины риска с оценкой CSM.
Ищите паттерны:
- Оценки систематически выше/ниже суждения CSM (калибровка)
- «Ложные срабатывания» (высокий риск, но аккаунт в порядке) vs «пропуски» (здоровая оценка, но аккаунт уходит)
- Причины, не соответствующие реальности (пробелы объяснимости)
Измеряйте полезность
Точность полезна, но полезность — то, что окупается. Отслеживайте операционные исходы:
- Время обнаружения риска (насколько рано вы флагируете проблему)
- Успешность аутрича (доля рискованных аккаунтов, которые улучшились после вмешательства)
- Прокси‑метрики снижения оттока (движение к вероятности продления, сигналы экспансии, изменение нагрузки на поддержку)
Тестируйте изменения безопасно с версионированием
Когда корректируете пороги, веса или добавляете сигналы, относитесь к ним как к новой версии модели. Проводите A/B тесты версий на сопоставимых когортных сегментах и храните исторические версии, чтобы объяснить, почему оценки поменялись.
Собирайте фидбек в UI
Добавьте лёгкий контрол вроде «Оценка кажется неверной» с указанием причины (например, «недавнее завершение онбординга не отражено», «использование сезонное», «неверная привязка аккаунта»). Маршрутизируйте этот фидбек в бэклог и привязывайте к аккаунту и версии модели для быстрого дебага.
Масштабируйте с дорожной картой
Когда пилот стабилен, планируйте масштабирование: более глубокие интеграции (CRM, биллинг, поддержка), сегментация (по тарифу, отрасли, стадии), автоматизация (таски и плейбуки) и self‑serve настройки, чтобы команды могли кастомизировать представления без инженеров.
По мере масштабирования держите цикл build/iterate коротким. Часто команды используют Koder.ai для быстрого создания новых страниц дашборда, доработки API или добавления рабочих функций (таски, экспорты, откаты), особенно когда версионируют модель и нужно быстро выпустить UI + backend изменения без замедления обратной связи CS.