03 нояб. 2025 г.·8 мин
Паттерны мультиарендного SaaS: изоляция, масштаб и дизайн для ИИ
Узнайте распространённые паттерны мультиарендного SaaS, компромиссы изоляции арендаторов и стратегии масштабирования. Посмотрите, как архитектуры, сгенерированные ИИ, ускоряют проектирование и ревью.
Что значит мультиарендность (без жаргона)
Мультиарендность означает, что один продукт обслуживает несколько клиентов (арендаторов) на одной и той же запущенной системе. Каждый арендатор чувствует, что у него «свое приложение», но за кулисами они разделяют части инфраструктуры — например, одни и те же веб‑серверы, один и тот же код и часто одну и ту же базу данных.
Полезная модель для восприятия — многоквартирный дом. У каждого своя запертая квартира (их данные и настройки), но вы пользуетесь общим лифтом, сантехникой и службой обслуживания (вычисления приложения, хранилище и операции).
Почему команды выбирают мультиарендность
Большинство команд не выбирают мультиарендный SaaS потому, что так модно — они выбирают его, потому что это эффективно:
- Ниже стоимость на клиента: общая инфраструктура обычно дешевле, чем разворачивать полный стек для каждого клиента.
- Проще операции: одна платформа для мониторинга, патчей и безопасности (вместо сотен мелких развёртываний).
- Быстрее выпускать: улучшения достаются всем сразу, и вы избегаете «дрейфа версий» между клиентами.
Где это может пойти не так
Два классических режима отказа — безопасность и производительность.
По безопасности: если границы арендаторов не защищены повсеместно, ошибка может привести к утечке данных между клиентами. Такие утечки редко бывают драматичными «взломами» — чаще это обычные ошибки: забытый фильтр, неправильно настроенная проверка прав или фоновая задача, работающая без контекста арендатора.
По производительности: общие ресурсы означают, что один активный арендатор может замедлить других. Эффект «шумного соседа» проявляется в медленных запросах, всплесках нагрузки или когда один клиент потребляет непропорционально много API‑ресурсов.
Краткий обзор рассматриваемых паттернов
В этой статье разбираются строительные блоки, которыми команды управляют этими рисками: изоляция данных (база данных, схема или строки), управление идентичностью и правами с учётом арендатора, контролируемое поведение при шумных соседях и операционные практики для масштабирования и управления изменениями.
Основная дилемма: изоляция против эффективности
Мультиарендность — это выбор позиции на спектре: сколько вы разделяете между арендаторами и сколько выделяете им отдельно. Каждый архитектурный паттерн ниже — просто другая точка на этой линии.
Общие vs выделенные ресурсы: главный спектр
С одной стороны, арендаторы почти всё разделяют: одни и те же инстансы приложения, базы данных, очереди, кэши — логически отделённые по tenant_id и правилам доступа. Это обычно самый дешёвый и простой вариант в эксплуатации, потому что вы объединяете ёмкость.
С другой стороны, арендаторам выделяют «срез» системы: отдельные базы данных, вычисления, иногда отдельные развёртывания. Это увеличивает безопасность и контроль, но повышает операционные издержки и стоимость.
Почему изоляция и стоимость тянут в разные стороны
Изоляция снижает вероятность, что один арендатор сможет получить доступ к данным другого, исчерпать их производственные квоты или повлиять на них при аномальной нагрузке. Также это упрощает соответствие аудиту и требованиям безопасности.
Эффективность повышается, когда вы амортизируете простаивающую ёмкость между множеством арендаторов. Общая инфраструктура позволяет содержать меньше серверов, проще конвейеры развертывания и масштабировать по совокупному спросу, а не по наихудшему сценарию для отдельного арендатора.
Типичные драйверы решения
Ваш «правильный» выбор на спектре редко философский — он обусловлен ограничениями:
- SLA и ожидания клиентов: строгие требования по доступности или задержкам тянут в сторону большей изоляции.
- Соответствие и локализация данных: требования могут заставить выделять хранилище или окружения.
- Стадия роста: ранние продукты часто начинают с большей доли общих ресурсов, чтобы быстрее двигаться; позже вводят выделенные опции для крупных клиентов.
- Операционная зрелость: больше изоляции обычно означает больше компонентов для мониторинга, патчей и миграции.
Простой ментальный фильтр для выбора паттерна
Задайте два вопроса:
-
Каков радиус поражения, если один арендатор ведёт себя неправильно или скомпрометирован?
-
Каова бизнес‑стоимость уменьшения этого радиуса?
Если радиус поражения должен быть минимален — выбирайте более выделенные компоненты. Если важнее стоимость и скорость — делайте больше общего и инвестируйте в строгие контролли доступа, лимиты по скорости и мониторинг по арендаторам.
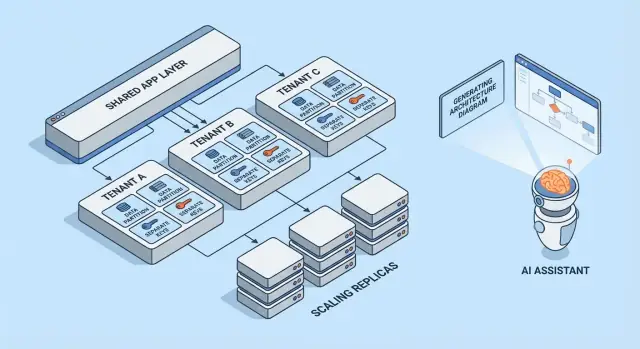
Модели мультиарендности в целом
Мультиарендность — это не одна архитектура, а набор подходов к совместному использованию (или неиспользованию) инфраструктуры между клиентами. Лучший модель зависит от требуемой изоляции, ожидаемого числа арендаторов и операционных возможностей команды.
1) Single‑tenant (выделенный) — базовая опция
Каждому клиенту выделяется собственный стек приложения (или, по крайней мере, изолированный runtime и база данных). Это проще всего для рассуждений о безопасности и производительности, но обычно дороже на клиента и усложняет масштабирование операций.
2) Общее приложение + общая БД — самая низкая стоимость, требует аккуратности
Все арендаторы используют одно приложение и одну базу данных. Стоимость обычно минимальна, потому что вы максимально переиспользуете ресурсы, но необходимо педантично обеспечивать контекст арендатора повсюду (запросы, кэши, фоновые задачи, экспорт аналитики). Одна ошибка может привести к утечке данных между арендаторами.
3) Общее приложение + отдельные БД — более высокая изоляция, больше операций
Приложение общее, но у каждого арендатора своя база данных (или экземпляр БД). Это уменьшает радиус поражения при инцидентах, упрощает бэкапы/восстановления на уровне арендатора и может облегчить разговоры о комплаенсе. Компромисс — операционный: больше баз для provisioning, мониторинга, миграций и безопасности.
4) Гибридные модели для «крупных» арендаторов
Многие SaaS‑продукты смешивают подходы: большинство клиентов живут в общей инфраструктуре, а крупные или регулируемые клиенты получают выделенные базы или выделенный compute. Гибрид часто оказывается практичным финалом, но требует чётких правил: кто попадает в выделенный режим, сколько это стоит и как проходят обновления.
Если нужен более подробный разбор техник изоляции внутри каждой модели, см. /blog/data-isolation-patterns.
Паттерны изоляции данных (БД, схема, строка)
Изоляция данных отвечает на простой вопрос: «Может ли один клиент когда‑нибудь увидеть или повлиять на данные другого?» Существует три распространённых паттерна с разной безопасностью и операционными последствиями.
Изоляция на уровне строк (общие таблицы + tenant_id)
Все арендаторы разделяют одни и те же таблицы, и каждая строка включает колонку tenant_id. Это наиболее эффективная модель для маленьких и средних арендаторов, потому что минимизирует инфраструктуру и упрощает отчётность и аналитику.
Риск очевиден: если какой‑то запрос забывает отфильтровать по tenant_id, данные могут утечь. Даже один «админский» эндпоинт или фоновая задача могут стать слабым звеном. Меры смягчения включают:
- Принудительное применение фильтрации по арендатору в общем слое доступа к данным (чтобы разработчики не писали фильтры вручную)
- Использование возможностей БД, таких как row‑level security (RLS), где это доступно
- Автотесты, которые намеренно пробуют кросс‑арендаторский доступ
- Индексация по распространённым путям доступа (часто
(tenant_id, created_at)или(tenant_id, id)), чтобы запросы в рамках арендатора оставались быстрыми
Схема на арендатора (одна БД, отдельные схемы)
Каждому арендатору выделяется своя схема (пространства имён вроде tenant_123.users, tenant_456.users). Это даёт лучшую изоляцию по сравнению с общими строками и облегчает экспорт арендатора или тонкую настройку под конкретного клиента.
Компромисс — операционный: миграции нужно запускать по множеству схем, и неудачи становятся сложнее: вы можете успешно мигрировать 9,900 арендаторов и «зависнуть» на 100. Важны мониторинг и инструменты — процесс миграции должен иметь понятные ретраи и отчётность.
База данных на арендатора (отдельные БД)
Каждому арендатору выделяется отдельная база данных. Изоляция сильная: границы доступа яснее, шумные запросы одного арендатора реже повлияют на других, и восстановление одного арендатора из бэкапа становится чище.
Основные минусы — стоимость и масштабирование: больше баз для управления, больше пулов соединений и потенциально больше работы по апгрейдам/миграциям. Многие команды резервируют этот подход для крупных или регулируемых клиентов, а мелкие остаются в общей инфраструктуре.
Шардинг и стратегии размещения по мере роста арендаторов
Реальные системы часто смешивают эти паттерны. Частый путь: изоляция на уровне строк на ранних этапах, затем «перевод» крупных арендаторов в отдельные схемы или БД.
Шардинг добавляет слой размещения: решение, в каком кластере БД живёт арендатор (по региону, по размерному уровню или по хешу). Ключ — делать размещение арендатора явным и меняемым, чтобы можно было переместить арендатора без переписывания приложения и масштабировать добавлением шардов вместо полной переработки.
Идентичность, доступ и контекст арендатора
Мультиарендность ломается по удивительно простым причинам: забытый фильтр, кэш, разделяемый между арендаторами, или админ‑функция, которая «забывает», для кого выполняется запрос. Решение — не одна большая фича безопасности, а последовательный контекст арендатора от первого байта запроса до последнего запроса в базу.
Идентификация арендатора (как понять «кто»)
Большинство SaaS‑продуктов выбирают один первичный источник идентификатора и трактуют всё остальное как удобство:
- Субдомен:
acme.yourapp.comудобно для пользователей и хорошо подходит для брендинга арендатора. - Заголовок: полезно для API‑клиентов и внутренних сервисов (но должен быть аутентифицирован).
- Клейм в токене: подписанный JWT (или сессия) содержит
tenant_id, что затрудняет подделку.
Выберите один источник истины и логируйте его повсеместно. Если поддерживаете несколько сигналов (субдомен + токен), определите приоритет и отвергайте неоднозначные запросы.
Скоуп запроса (как каждый запрос остаётся в контексте арендатора)
Хорошее правило: как только вы разрешили tenant_id, всё downstream должно читать его из одного места (контекста запроса), а не пересчитывать.
Распространённые меры предосторожности:
- Middleware, прикрепляющий
tenant_idв контекст запроса - Хелперы доступа к данным, требующие
tenant_idкак параметр - Принудения на уровне БД (например, политики на уровне строк), чтобы ошибки приводили к отказу, а не к утечке
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Базовые принципы авторизации (роли внутри арендатора)
Разделяйте аутентификацию (кто пользователь) и авторизацию (что он может делать).
Типичные роли SaaS — Owner / Admin / Member / Read‑only, но ключ в области действия: пользователь может быть Admin в Тenant A и Member в Тenant B. Храните права на уровне арендатора, а не глобально.
Предотвращение утечек между арендаторами (тесты и барьеры)
Относитесь к доступу между арендаторами как к инциденту высшего уровня и предотвращайте его проактивно:
- Добавьте автоматические тесты, пытающиеся прочитать данные Тenant B, будучи аутентифицированными как Тenant A
- Сделайте ошибки с отсутствующим фильтром сложнее для попадания в релиз (линтеры, билдеры запросов, обязательные параметры арендатора)
- Логируйте и тревожьте по подозрительным паттернам (напр., несовпадение tenant в токене и субдомене)
Если нужен более глубокий операционный чек‑лист, свяжите эти правила с вашими инженерными рукописями в /security и держите их версионно вместе с кодом.
Изоляция помимо базы данных
Проверьте риски безопасности арендаторов
Получите чеклист для моделирования угроз по утечкам между арендаторами, фоновых задач и кэшей.
Изоляция БД — только половина истории. Многие реальные инциденты мультиарендности происходят в общей «обвязке» вокруг приложения: кэши, очереди и сторедж. Эти слои быстры и удобны, и их легко случайно сделать глобальными.
Общие кэши: предотвращайте коллизии ключей и утечки данных
Если несколько арендаторов делят Redis или Memcached, главное правило простое: никогда не храните ключи без префикса арендатора.
Практический паттерн — префиксовать каждый ключ стабильным идентификатором арендатора (не домен электронной почты, не отображаемое имя). Например: t:{tenant_id}:user:{user_id}. Это дает две вещи:
- Предотвращает коллизии, когда у двух арендаторов одинаковые внутренние идентификаторы
- Делает массовую инвалидизацию возможной (удаление по префиксу) при инцидентах поддержки или миграциях
Также решите, что допускается как глобальное (например, публичные флаги фич) и документируйте это — случайные глобальные данные часто становятся источником межарендаторских утечек.
Лимиты скорости и квоты с учётом арендатора
Даже если данные изолированы, арендаторы всё ещё могут влиять друг на друга через общий compute. Добавьте лимиты по арендаторам на краях:
- Ограничения API на арендатора (и часто на пользователя внутри арендатора)
- Квоты на дорогие операции (экспорты, генерация отчётов, вызовы ИИ)
Делайте лимиты видимыми (заголовки, уведомления в UI), чтобы клиенты понимали, что троттлинг — это политика, а не ошибка.
Фоновые задачи: разнесите очереди по арендаторам
Одна общая очередь может позволить одному активному арендатору захватить всё время воркеров.
Распространённые решения:
- Отдельные очереди по уровню подписки (например,
free,pro,enterprise) - Разделённые очереди по бакетам арендаторов (хеш tenant_id в N очередей)
- Планирование с учётом арендатора, чтобы каждый арендатор получал справедливую долю
Всегда передавайте контекст арендатора в полезной нагрузке задач и в логах, чтобы избежать побочных эффектов для неправильного арендатора.
Файловое/объектное хранилище: отдельные пути, политики и ключи
Для S3/GCS‑подобных хранилищ изоляция обычно базируется на путях и политиках:
- Bucket на арендатора для строгой сегрегации (сильные границы, больше операций)
- Общий bucket с префиксами арендаторов (проще, требует аккуратных IAM и подписанных URL)
Что бы вы ни выбрали, проверяйте владение при загрузках/скачивании на каждом запросе, а не только в UI.
Бороться с шумными соседями и обеспечивать справедливость в использовании ресурсов
Мультиарендные системы разделяют инфраструктуру, значит один арендатор может случайно (или намеренно) потреблять больше, чем положено. Это проблема шумного соседа: одна громкая рабочая нагрузка ухудшает условия для всех.
Как выглядит «шумный сосед»
Представьте функцию экспорта отчёта на год в CSV. Арендатор A запускает 20 экспортов в 9:00 утра. Эти экспорты насыщают CPU и диск базы данных, и у арендатора B начинают таймаутиться обычные экраны — хотя B ничего необычного не делает.
Контроль ресурсов: лимиты, квоты и формирование нагрузки
Предотвращение начинается с явных границ ресурсов:
- Rate limits (запросы в секунду) на арендатора и на эндпоинт, чтобы дорогие API нельзя было спамить
- Квоты (суточные/месячные) для экспортов, почтовых рассылок, вызовов ИИ или фоновых задач
- Формирование нагрузки: отправляйте тяжёлые задачи (экспорт, импорт, реиндексация) в очереди с ограничением конкурентности и приоритетными правилами
Практический паттерн — разделять интерактивный трафик и пакетную работу: держите пользовательские запросы на «быстрой полосе», а всё остальное — в контролируемых очередях.
Цепные предохранители и «bulkheads» на арендатора
Добавьте предохранители, которые срабатывают, когда арендатор превышает порог:
- Circuit breakers: временно отклонять или отложить дорогие операции при повышении ошибок, задержек или глубины очереди у арендатора
- Bulkheads: изолировать общие пулы (соединения к БД, потоки воркеров, кэш) так, чтобы один арендатор не мог исчерпать общую ёмкость
При правильном подходе, арендатор A будет мешать только себе (например, его экспорту), а не арендаторам B и C.
Когда переводить арендатора на выделённые ресурсы
Переводите арендатора на выделённые ресурсы, когда он постоянно превышает допущения общего режима: устойчивый высокий throughput, непредсказуемые всплески, критичные для бизнеса события, строгие требования соответствия или когда их нагрузка требует кастомной настройки. Простое правило: если ради защиты других клиентов нужно постоянно троттлить платящего клиента, пора переводить его на выделенные ресурсы (или предлагать более высокий тариф), а не постоянно решать проблему временными мерами.
Паттерны масштабирования в мультиарендном SaaS
Более безопасные миграции на практике
Экспериментируйте с изменениями схемы и быстро откатывайте миграции при ошибках.
Масштабирование мультиарендности — это не просто «больше серверов», а умение не позволять росту одного арендатора удивлять всех остальных. Лучшие паттерны делают рост предсказуемым, измеримым и обратимым.
Горизонтальное масштабирование для stateless сервисов
Начните с того, чтобы сделать веб/API‑слой stateless: храните сессии в общем кэше (или используйте токены), сохраняйте загрузки в объектном хранилище и выносите долгие задачи в фоновые процессы. Когда запросы не зависят от локальной памяти или диска, можно добавлять инстансы за балансировщиком и быстро масштабироваться.
Практический совет: держите контекст арендатора на краю (извлечённый из субдомена или заголовков) и передавайте его в обработчики запросов. Stateless не значит «не знающий арендатора» — это значит «знающий арендатора без привязки к конкретному серверу».
Горячие точки по арендаторам: как их обнаружить и сглаживать
Большинство проблем масштабирования — это «один арендатор отличается». Следите за горячими точками:
- Один арендатор генерирует непропорционально много трафика
- Небольшая группа арендаторов с очень большими данными
- Пакетное использование (отчёты в конце месяца, ночные импорты)
Способы сглаживания: лимиты на арендатора, инжест через очереди, кэширование путей чтения для конкретных арендаторов и шардирование тяжёлых арендаторов в отдельные воркер‑пулы.
Реплики для чтения, партиционирование и асинхронная работа
Используйте read‑реплики для нагрузок чтения (дашборды, поиск, аналитика), а записи держите на primary. Партиционирование (по арендатору, по времени или по обоим) помогает держать индексы малыми и запросы быстрыми. Для дорогих задач — экспортов, ML‑скоринга, вебхуков — предпочитайте асинхронные джобы с идемпотентностью, чтобы повторные попытки не увеличивали нагрузку.
Сигналы планирования ёмкости и простые пороги
Держите сигналы простыми и с учётом арендатора: p95‑латентность, уровень ошибок, глубина очередей, CPU базы данных и запросы по арендаторам. Устанавливайте простые пороги (например, “queue depth > N в течение 10 минут” или “p95 > X ms”), которые триггерят автоскейл или временные ограничения по арендаторам — до того, как другие арендаторы это почувствуют.
Наблюдаемость и операции по арендаторам
Мультиарендные системы обычно сначала отваливаются для одного арендатора или плана. Если ваши логи и дашборды не дают ответа на вопрос «какой арендатор пострадал?» за секунды, время он‑кола превратится в догадки.
Логи, метрики и трассы с контекстом арендатора
Начните с единого контекста арендатора в телеметрии:
- Логи: добавляйте
tenant_id,request_idи стабильныйactor_id(пользователь/сервис) в каждый запрос и фоновую задачу - Метрики: эмитируйте счётчики и гистограммы задержек с разбиением по уровню подписки арендатора (напр.,
tier=basic|premium) и по ключевым эндпоинтам - Трейсы: прокидывайте контекст арендатора в атрибуты трассы, чтобы отфильтровать медленный трейс по конкретному арендатору и увидеть, где тратится время (БД, кэш, сторонние вызовы)
Контролируйте кардинальность: метрики на арендатора для всех арендаторов могут быть дорогими. Частая компромисс‑стратегия — метрики по уровням подписки по умолчанию и детальный анализ по арендаторам по требованию (например, семплинг трасс для «топ‑20 арендаторов по трафику» или для арендаторов, нарушающих SLO).
Избегайте утечек секретов в телеметрии
Телеметрия — это канал экспорта данных. Обращайтесь с ней как с продакшен‑данными.
Отдавайте предпочтение ID вместо содержимого: логируйте customer_id=123 вместо имён, email, токенов или полезной нагрузки запросов. Делайте редактирование/редакцию на уровне логгера/SDK и добавьте блок‑лист для секретов (Authorization header, API keys). Для саппорт‑воркфлоу храните отладочные полезные нагрузки в отдельной, контролируемой системе, а не в общих логах.
SLO по уровням подписки (без пустых обещаний)
Определяйте SLO, которые реально можете обеспечить. Премиум‑клиенты могут получить более жёсткие бюджеты по задержкам/ошибкам, но только если у вас есть механизмы контроля (лимиты, изоляция нагрузок, приоритетные очереди). Публикуйте SLO как цели и отслеживайте их по уровням подписки и для выбранных ключевых клиентов.
Руководства on‑call: распространённые инциденты в мультиарендном SaaS
Ваши рукописи для on‑call должны начинаться с «выявить затронутых арендаторов» и затем — быстрой изолирующей меры:
- Шумный сосед: троттлить арендатора, приостановить тяжёлые джобы или переместить их в очередь с более низким приоритетом.
- DB hotspots/runaway queries: включить таймауты запросов, посмотреть топ‑запросов по арендатору, применить индекс или ограничить эндпоинт.
- Баги контекста арендатора (перепутанные данные): немедленно отключить флаг фичи или эндпоинт и проверить scoping в проверках доступа.
- Накопление фоновых задач: опорожнить очереди по арендаторам, ограничить конкурентность и воспроизвести с идемпотентностью.
Операционная цель проста: обнаруживать по арендатору, содержать по арендатору и восстанавливаться, не затрагивая всех остальных.
Развёртывания, миграции и релизы по арендаторам
Мультиарендный SaaS меняет ритм релизов. Вы не просто выкатываете «приложение»; вы выкатываете общую среду и общие пути данных, от которых зависят многие клиенты. Цель — доставлять новые фичи без принуждения к синхронному апгрейду всех арендаторов.
Поэтапные релизы и миграции с низким даунтаймом
Отдавайте предпочтение шаблонам развертывания, допускающим смешанные версии недолго (blue/green, canary, rolling). Это работает, только если изменения в базе данных тоже поэтапны.
Практическое правило — расширяй → мигрируй → сужай:
- Расширяй: добавляйте новые колонки/таблицы/индексы, не ломая старый код.
- Мигрируй: бэкфилляйте данные батчами (часто по арендаторам) и верифицируйте.
- Сужай: удаляйте старые поля только после того, как все инстансы приложения перестали от них зависеть.
Для «горячих» таблиц делайте бэкфиллы инкрементально и с троттлингом, иначе вы устроите собственный инцидент «шумного соседа» во время миграции.
Флажки фичей на уровне арендатора для безопасных релизов
Флаги фичей на уровне арендатора позволяют выкатывать код глобально, включая поведение выборочно.
Это даёт:
- Программы раннего доступа для нескольких арендаторов
- Быстрый откат, отключив фичу только для затронутых арендаторов
- A/B‑эксперименты без форка релизов
Держите систему флагов аудируемой: кто включил что, для какого арендатора и когда.
Версионирование и ожидания по обратной совместимости
Предполагается, что некоторые арендаторы могут отставать в конфигурации, интеграциях или шаблонах использования. Проектируйте API и события с явным версионированием, чтобы новые продьюсеры не ломали старых консьюмеров.
Типичные ожидания внутри команды:
- Новые релизы должны уметь читать и старую, и новую форму данных в окне миграции.
- Депрекации требуют опубликованного графика (пусть даже внутреннего плюс шаблон письма клиенту).
Управление конфигурацией для конкретного арендатора
Рассматривайте конфигурацию арендатора как поверхность продукта: она нуждается в валидации, значениях по умолчанию и истории изменений.
Храните конфиг отдельно от кода (и, желательно, отдельно от секретов рантайма) и поддерживайте fallback‑режим при неверной конфигурации. Лёгкая внутренняя страница вроде /settings/tenants может сэкономить часы при инцидентах и поэтапных релизах.
Как архитектуры, сгенерированные ИИ, помогают (и их ограничения)
Контролируйте шумных соседей
Реализуйте лимиты на арендатора и очереди задач, чтобы шумные соседи оставались изолированы.
ИИ может ускорить раннее архитектурное мышление для мультиарендного SaaS, но не заменяет инженерное суждение, тестирование и security‑ревью. Рассматривайте его как качественного партнёра по брейншторму, который генерирует черновики — затем проверьте каждое предположение.
Что ИИ‑архитектура должна (и не должна) делать
ИИ полезен для генерации опций и подчёркивания типичных режимов отказа (где контекст арендатора может потеряться или где общие ресурсы могут создать сюрпризы). Он не должен выбирать вашу модель, гарантировать комплаенс или верифицировать производительность. ИИ не видит ваш реальный трафик, сильные стороны команды или погребённые в интеграциях крайние случаи.
Входные данные, которые важны: требования, ограничения, риски, рост
Качество вывода зависит от того, что вы ему даёте. Полезные входные данные:
- Число арендаторов сейчас и через 12–24 месяца, ожидаемый объём данных на арендатора
- Требования по изоляции (контрактные, регуляторные, ожидания клиентов)
- Бюджет и операционные возможности (on‑call, SRE‑поддержка, инструменты)
- Цели по задержке, пиковые паттерны и всплески по арендаторам
- Толерантность к риску: что происходит, если один арендатор влияет на другого?
Использование ИИ для предложений паттернов с разбором компромиссов
Попросите 2–4 варианта дизайна (например: база‑на‑арендатора vs схема‑на‑арендатора vs изоляция на уровне строк) и чёткую таблицу компромиссов: стоимость, операционная сложность, радиус поражения, усилия на миграцию и пределы масштабирования. ИИ хорош в перечислении подводных камней, которые вы можете превратить в вопросы для команды.
Если хотите перейти от «черновой архитектуры» к рабочему прототипу быстрее, платформа для кодинга вроде Koder.ai может помочь превратить эти решения в реальный каркас приложения через чат — часто с React‑фронтендом и Go + PostgreSQL на бэкенде — чтобы вы могли проверить распространение контекста арендатора, лимиты скорости и рабочие процессы миграций раньше. Фичи вроде planning mode и snapshot/rollback особенно полезны при итерации над мультиарендными моделями данных.
Использование ИИ для генерации моделей угроз и чек‑листов
ИИ может сгенерировать простой threat model: точки входа, границы доверия, пути передачи контекста арендатора и обычные ошибки (например, пропущенные проверки авторизации в фоновых задачах). Используйте его для составления чек‑листов для PR и рукописей, но верифицируйте с реальной security‑экспертизой и историей инцидентов.
Практический чек‑лист для вашей команды
Выбор мультиарендного подхода — это не про «лучшее в целом», а про соответствие: чувствительность данных, темпы роста и сколько операционной сложности вы готовы нести.
Пошаговый чек‑лист (используйте на 30‑минутном воркшопе)
-
Данные: Какие данные делятся между арендаторами (если есть)? Что никогда не должно соседствовать?
-
Идентичность: Где живёт идентичность арендатора (инвайт‑ссылки, домены, SSO‑клеймы)? Как устанавливается контекст арендатора в каждом запросе?
-
Изоляция: Решите базовый уровень изоляции (строка/схема/база) и определите исключения (например, enterprise‑клиенты, требующие сильной сегрегации).
-
Масштабирование: Определите первое давление на масштаб (хранилище, трафик чтения, фоновые джобы, аналитика) и выберите самый простой паттерн, который это решает.
Вопросы для валидации с инженерами и ревьюерами по безопасности
- Как мы предотвращаем доступ между арендаторами, если разработчик забудет фильтр?
- Какой у нас аудит‑стори по арендатору (кто что сделал и когда)?
- Как мы обрабатываем удаление и хранение данных по арендатору?
- Каков радиус поражения плохой миграции или runaway query?
- Можем ли мы троттлить, лимитировать и бюджетировать ресурсы по арендатору?
Красные флаги, требующие глубокого дизайна
- «Мы добавим проверки арендатора позже.»
- Общие админ‑инструменты, которые видят всё без строгого контроля.
- Нет плана для бэкапов/восстановлений по арендаторам или инцидент‑реакции.
- Одна очередь/пул воркеров без механизмов справедливости по арендаторам.
Пример рекомендуемого краткого плана действий
Рекомендация: Начните с изоляции на уровне строк + строгого принудительного контекста арендатора, добавьте per‑tenant троттлинги и определите путь апгрейда до схем/БД для арендаторов с высоким риском.
Следующие шаги (2 недели): составить threat‑model границ арендаторов, прототипировать enforcement в одном эндпоинте и провести репетицию миграции на staging‑копии. Для руководства по релизам см. /blog/tenant-release-strategies.