Почему CAP стал основным инструментом мышления
Когда вы храните одни и те же данные на нескольких машинах, вы выигрываете в скорости и отказоустойчивости — но сталкиваетесь с новой проблемой: расхождением. Два сервера могут получить разные обновления, сообщения приходят с опозданием или вовсе теряются, и пользователи будут получать разные ответы в зависимости от того, к какой реплике попали. CAP стал популярным, потому что даёт инженерам понятный язык для описания этой запутанной реальности без витания в облаках.
Эрик Брюэр, учёный в области информатики и сооснователь Inktomi, сформулировал основную идею в 2000 году как практическое утверждение о реплицированных системах при отказах. Концепция быстро распространилась, потому что соответствовала тому, что команды уже видели в продакшне: распределённые системы ломаются не только просто «упав», они ломаются, «разделяясь».
CAP — это взгляд на поведение при сбоях, а не чеклист функций
CAP наиболее полезен, когда что-то идёт не так — особенно когда сеть ведёт себя плохо. В обычный день многие системы могут выглядеть и достаточно согласованными, и достаточно доступными. Испытание наступает, когда машины не могут надёжно общаться, и вам нужно решать, что делать с чтениями и записями, пока система разделена.
Именно такое представление сделало CAP популярным: он не спорит о лучших практиках; он задаёт конкретный вопрос — что мы готовы пожертвовать во время разрыва?
Что вы сможете решить после прочтения
К концу этой статьи вы должны уметь:
- Определять, когда вы имеете дело с настоящей CAP‑ситуацией (репликация + возможные разрывы связи).
- Осознанно выбирать, отдавать ли приоритет согласованности (все видят одну правду) или доступности (система продолжает отвечать), когда реплики не могут договориться.
- Связывать этот выбор с продуктовым эффектом: что увидит пользователь, какие ошибки вы покажете и какие правки придётся сделать после восстановления связи.
CAP остаётся актуальной потому, что превращает расплывчатую фразу «распределённые системы — это сложно» в выбор, который можно аргументированно принять и защитить.
Установка: репликация и проблема расхождений
Распределённая система — попросту говоря, это много компьютеров, пытающихся работать как один. У вас могут быть серверы в разных стойках, регионах или зонах облака, но для пользователя это «приложение» или «база данных».
Зачем мы реплицируем данные
Чтобы система работала в реальном масштабе, обычно используют репликацию: держат несколько копий одних и тех же данных на разных машинах.
Репликация популярна по трём практическим причинам:
- Масштабирование: больше машин — больше трафика.
- Производительность: пользователи обслуживаются ближайшей копией, меньше задержка.
- Надёжность: если одна машина умирает, другая копия поддержит работу сервиса.
На первый взгляд — одни плюсы. Загвоздка в том, что репликация порождает новую задачу: поддерживать согласие всех копий.
Основное напряжение: копии могут расходиться
Если бы каждая реплика могла мгновенно и безошибочно общаться со всеми остальными, они могли бы согласовывать обновления и сохранять согласованность. Но реальные сети не идеальны. Сообщения задерживаются, теряются или маршрутизируются вокруг отказов.
Когда связь здоровая, реплики обычно обмениваются обновлениями и сходятся к одному состоянию. Но когда связь нарушается (пусть временно), вы можете получить две «валидно выглядящие» версии истины.
Например: пользователь меняет адрес доставки. Реплика A получает обновление, реплика B — нет. Теперь система должна ответить на простой вопрос: какой текущий адрес?
Нормальная работа vs работа при сбое
Это разница между:
- Нормальной работой: реплики координируются; расхождение — в основном вопрос времени.
- Работой при сбое: часть реплик не может общаться; расхождение становится неизбежным.
Именно здесь начинается CAP‑мышление: при наличии репликации расхождение из‑за проблем связи — это не редкость, а центральная задача проектирования.
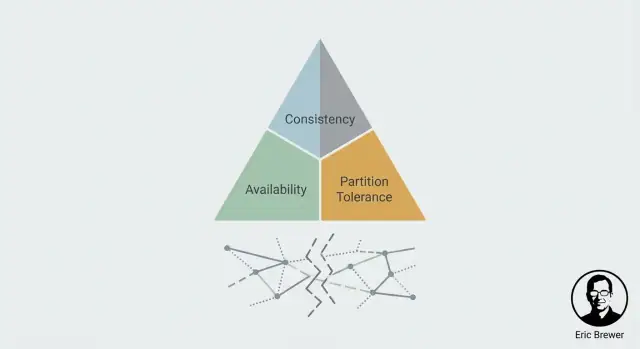
CAP простыми словами: C, A и P
CAP — модель для того, что пользователи реально ощущают, когда система разнесена по нескольким машинам (часто в разных локациях). Он не описывает «хорошие» или «плохие» системы — только напряжение, которое нужно управлять.
Согласованность (C): увижу ли я последнюю запись?
Согласованность — про согласие. Если вы обновили что‑то, покажет ли следующее чтение (откуда угодно) это обновление?
С точки зрения пользователя — это разница между «я только что поменял, и все видят новое значение» и «некоторые ещё некоторое время видят старое значение».
Доступность (A): получу ли я вообще ответ?
Доступность значит, что система отвечает на запросы — чтения и записи — успешным результатом. Не обязательно «самым быстрым», но «не отказывает в обслуживании».
Во время проблем (сервер упал, сеть шатается) доступная система продолжает принимать запросы, даже если отвечает данными, которые могут быть слегка устаревшими.
Устойчивость к разрывам (P): что происходит, когда узлы не могут общаться?
Разрыв — это когда сеть разделяется: машины работают, но сообщения между частями не проходят (или приходят слишком поздно). В распределённых системах это нельзя считать невозможным — нужно заранее определить поведение на такой случай.
Простая история: два магазина и один инвентарь
Представьте два магазина, продающие один и тот же товар и разделяющие «1 в наличии». Клиент покупает последний товар в магазине A — A записывает inventory = 0. Одновременно сетевой разрыв мешает магазину B узнать это.
Если магазин B остаётся доступным, он может продать товар, которого у него уже нет (принять продажу во время разрыва). Если магазин B принудительно требует согласованности, он может отказать в продаже до подтверждения актуального инвентаря (отказать в обслуживании во время разрыва).
Что такое на самом деле разрывы (и почему их нельзя игнорировать)
«Разрыв» — это не только «интернет упал». Это любая ситуация, когда части вашей системы не могут надёжно общаться, хотя каждая часть может оставаться работоспособной.
В реплицированной системе узлы постоянно обмениваются сообщениями: записи, подтверждения, heartbeat‑ы, выборы лидера, запросы чтения. Разрыв — это когда эти сообщения перестают приходить (или приходят слишком поздно), создавая разногласия о реальности: «Прошла ли запись?» «Кто сейчас лидер?» «Жив ли узел B?»
Разрывы — это сбои связи
Связь может ломаться по‑разному:
- потеря пакетов, вызывающая повторы и таймауты
- проблемы маршрутизации, когда трафик уходит в большой крюк или проваливается
- перегруженные каналы (или сетевые карты), вызывающие большие задержки
- неправильные настройки фаерволов / security groups, блокирующие части трафика
- сбои DNS или discovery, мешающие узлам найти друг друга
Важно: разрывы часто — это деградация, а не чистый «вкл/выкл». Для приложения «достаточно медленно» зачастую не отличается от «вниз».
Почему разрывы неизбежны в масштабе
Чем больше машин, сетей, регионов и движущихся частей, тем больше возможностей для временного нарушения связи. Даже если отдельные компоненты надёжны, общая система испытывает сбои из‑за большого числа зависимостей и межузловой координации.
Не нужно задавать точную вероятность отказов, чтобы признать реальность: если ваша система работает долго и охватывает достаточно инфраструктуры, разрывы произойдут.
Что на практике означает «терпеть разрывы»
Устойчивость к разрывам значит, что система спроектирована так, чтобы продолжать работать во время разделения — даже если узлы не могут согласовать или подтвердить, что видели друг друга. Это заставляет сделать выбор: продолжать обслуживать запросы (с риском расхождений) или останавливать/отклонять часть запросов (сохраняя согласованность).
Ключевой момент: выбор согласованности или доступности во время разрыва
С появлением репликации разрыв — это просто сбой связи: две части системы не могут надёжно общаться какое‑то время. Реплики всё ещё запущены, пользователи кликают, сервис получает запросы — но реплики не могут согласовать актуальную правду.
Это напряжение CAP в одной фразе: во время разрыва вы должны выбрать, что приоритетнее — Согласованность (C) или Доступность (A). Одновременно иметь и то, и другое нельзя.
Если вы выбираете Согласованность (C)
Вы говорите: «лучше быть правильным, чем отзывчивым». Когда система не может подтвердить, что запрос сохранит согласие всех реплик, она должна отказаться или подождать.
Практический эффект: часть пользователей увидит ошибки, таймауты или «попробуйте позже» — особенно для операций, изменяющих данные. Это типично, когда вы предпочитаете отклонить платеж, чем рискнуть списать дважды, или блокировать бронирование места, чтобы не перепродать.
Если вы выбираете Доступность (A)
Вы говорите: «лучше ответить, чем блокировать». Каждая сторона разрыва продолжит принимать запросы, даже без координации.
Практический эффект: пользователи получают успешные ответы, но данные могут быть устаревшими, а параллельные обновления — в конфликте. Тогда вы полагаетесь на последующую реконсиляцию (правила слияния, last‑write‑wins, ручная проверка и т. п.).
Выбор может отличаться для разных операций
Это не всегда глобальная настройка. Многие продукты смешивают стратегии:
- Чтения vs записи: оставить чтения доступными, а записи сделать строже.
- Критичные vs некритичные действия: требовать согласованности для денег, идентификации и инвентаря; позволять доступность для лент, аналитики, «лайков» или кэшированных профилей.
Ключевой момент — решать для каждой операции, что хуже: заблокировать пользователя сейчас или исправлять конфликтную правду позже.
Распространённые заблуждения: дальше слогана «выбери два»
Тестируйте предположения CAP на раннем этапе
Создайте небольшую систему и проверьте задержки, имитирующие разделение сети, с реалистичным поведением клиентов.
Слоган «выбери два» запоминается, но часто вводит в заблуждение, заставляя думать, что CAP — это меню из трёх особенностей, где навсегда можно сохранить только две. CAP про то, что происходит когда сеть перестаёт сотрудничать: во время разрыва распределённая система должна выбирать между возвращением согласованных ответов и сохранением доступности на каждый запрос.
Заблуждение 1: «Я просто выберу C и A и отключу разрывы»
В реальных распределённых системах разрывы нельзя выключить. Если система охватывает машины, стойки, зоны или регионы, сообщения могут задерживаться, теряться или приходить в другом порядке. Это разрыв с точки зрения софта: узлы не могут договориться.
Даже если физическая сеть в порядке, другие сбои даёт тот же эффект — перегруженные узлы, паузы GC, «шумные соседи», проблемы с DNS, ненадёжные балансировщики. Результат тот же: части системы не могут координироваться достаточно хорошо.
Заблуждение 2: «Разрывы — редкие крайние случаи»
Приложения редко видят «разрыв» как аккуратное бинарное событие. Они видят скачки задержек и таймауты. Если запрос тайм‑аутится через 200 мс, неважно, пришёл ли пакет через 201 мс или не пришёл вовсе: приложению нужно решить, что делать дальше. С точки зрения приложения «медленно» часто невозможно отличить от «сломано».
Заблуждение 3: «Системы либо CP, либо AP»
Многие системы на деле более‑менее согласованы или более‑менее доступны, в зависимости от конфигурации и условий. Таймауты, политики повторов, размеры кворумов и опции «читать свои записи» смещают поведение.
При нормальной работе БД может выглядеть сильно согласованной; под нагрузкой или при межрегиональных проблемах она начнёт либо отказываться (в пользу согласованности), либо возвращать старые данные (в пользу доступности).
CAP — не про ярлыки продуктов, а про понимание компромисса, который вы делаете при расхождении — особенно когда причиной расхождения выступает обычная задержка.
Варианты согласованности, которые реально можно выбрать
CAP‑обсуждения часто рисуют согласованность как бинарную: либо «идеальная», либо «что попало». На практике есть набор гарантий, каждая из которых даёт разный пользовательский опыт при расхождении реплик или разрыве сети.
Сильная согласованность (и её цена при сбое)
Сильная согласованность (часто «линеаризуемость») значит: как только запись подтверждена, любое последующее чтение — с любого узла — вернёт эту запись.
Что это стоит: во время разрыва или при недоступности части реплик система может задерживать или отклонять чтения/записи, чтобы не показать конфликтующие состояния. Пользователи заметят таймауты, «попробуйте позже» или временный режим только для чтения.
В конечном счёте согласованность (и что чувствует пользователь)
В конечном счёте согласованность обещает: если новые обновления прекратятся, все реплики со временем сольются. Она не обещает, что два пользователя, читающие прямо сейчас, увидят одно и то же.
Что заметит пользователь: недавно обновлённая фотография профиля может «откатиться», счётчики отставать, или сообщение, отправленное с одного устройства, пока не видно на другом.
Полезные промежуточные гарантии
Часто можно получить лучшую работу не требуя полной сильной согласованности:
- Read‑your‑writes: после вашего обновления вы не увидите старую версию своих данных.
- Monotonic reads: увидев версию N, вы не вернётесь к N‑1.
- Causal consistency: если событие B зависит от A (ответ после прочтения сообщения), все увидят A прежде чем B.
Эти гарантии соответствуют пользовательскому восприятию («не показывайте мои собственные изменения как исчезнувшие») и легче поддерживаются при частичных сбоях.
Выбор уровня согласованности по ожиданиям
Исходите из обещаний пользователю, а не из жаргона:
- Если некорректные чтения наносят необратимый вред (переводы денег, резерв товара, изменение прав) — склоняйтесь к более сильной согласованности и соглашайтесь на временную недоступность.
- Если фича терпит кратковременное расхождение (лайки, счётчики, ранжирование ленты) — подойдёт в конечном счёте или каузальная согласованность.
- Если основная боль — личная путаница («я сохранил — почему я не вижу?»), — приоритет read‑your‑writes и monotonic reads.
Согласованность — продуктовый выбор: опишите, что для пользователя будет «неправильным», и выберите самую слабую гарантию, которая не допустит этой ошибки.
Доступность как продуктовое решение, а не просто число аптайма
Планируйте согласованность по эндпоинтам
Набросайте эндпоинты, типы данных и требования к согласованности в режиме планирования перед кодированием.
Доступность в CAP — это не хвастовство «пять девяток» — это обещание пользователю о том, что произойдёт, когда система не уверена.
Быстрый успех против корректного успеха
Когда реплики не могут согласиться, часто выбор стоит между:
- Быстрым успехом: вернуть что‑то быстро (даже если это устарело).
- Корректным успехом: вернуть ответ только когда можно доказать, что он актуален.
Пользователь ощущает это как «приложение работает» vs «приложение правильно». Ни то, ни другое не всегда лучше; правильный выбор зависит от того, что значит «ошибка» для вашего продукта. Немного устаревшая лента раздражает; устаревший баланс счёта может быть опасен.
«Закрываться» vs «Открываться» при сбое
Два распространённых поведения при неопределённости:
- Fail closed: отклонить запрос (ошибки, таймауты, режим только для чтения). Вы защищаете корректность, но блокируете пользователей.
- Fail open: отдать лучший возможный ответ (кэш, локальная реплика, поставленная в очередь запись). Вы защищаете поток, но допускаете несогласованность.
Это не только техническое решение — это политическое. Продукт должен определить, что допустимо показывать, а что ни в коем случае не должно быть «угадывано».
Частичная доступность — всё ещё доступность
Доступность редко «всё или ничего». Во время разрыва вы можете увидеть частичную доступность: некоторые регионы, сети или группы пользователей получают ответы, другие — нет. Это может быть сознательным дизайном (обслуживать локально здоровые реплики) или случайностью (неравномерный роутинг, недостижимость кворума).
Режим деградации: сохранить ядро, ограничить риск
Практический компромисс — режим деградации: продолжать обслуживать безопасные действия и ограничивать рискованные. Например, разрешить просмотр и поиск, но временно отключить «перевести средства», «сменить пароль» или другие операции, где корректность и уникальность критичны.
Конкретные примеры: сопоставление CAP‑выбора с кейсами
CAP абстрактен, пока вы не свяжете его с тем, что видит пользователь при разрыве: предпочитаете ли вы, чтобы система продолжала отвечать, или чтобы остановилась и не принимала конфликтных данных?
Инвентарь и заказ: риск перепродажи vs простои корзины
Представьте два дата‑центра, принимающих заказы и не получающих сообщения друг от друга.
Если вы сохраняете доступность оформления заказа, каждая сторона может продать «последний» товар — получится перепродажа. Это приемлемо для дешёвых товаров (вы оформите бэк‑ордер или извинитесь), но болезненно для лимитированных релизов.
Если вы выбираете согласованность, вы можете блокировать новые заказы, пока не подтвердите глобальный запас. Пользователь увидит «попробуйте позже», но вы избежите невозможных к исполнению заказов.
Платежи и балансы: паттерны «корректность прежде всего»
Деньги — классическая область, где ошибка дорого стоит. Если две реплики независимо примут снятие во время разрыва, счёт может уйти в минус.
Системы часто предпочитают согласованность для критичных записей: отклонять или задерживать операции, если нельзя подтвердить актуальный баланс. Вы платите в виде недоступности платежей, но получаете корректность, аудит и доверие.
Чаты, ленты, аналитика: допустима небольшая устарелость
В чатах и социальных лентах пользователи обычно терпимы к кратковременным несоответствиям: сообщение приходит с задержкой, счётчик лайков неточен, метрика просмотра обновится позже.
Здесь дизайн в пользу доступности — хорошее продуктовое решение, если вы ясно обозначили, какие элементы «в конечном счёте корректны», и умеете аккуратно сливать обновления.
Суть: ваш компромисс — бизнес‑решение
Правильный выбор CAP зависит от цены ошибки: возвраты, юридические риски, потеря доверия пользователей или операционный хаос. Решите, где вы готовы терпеть временную устарелость, а где нужно «закрываться».
Паттерны проектирования, реализующие ваш выбор
После того как вы решили, как вести себя при разрыве, нужны механизмы, которые воплотят это решение. Эти паттерны встречаются в базах данных, системах сообщений и API — даже если продукт никогда прямо не упоминает «CAP».
Кворумы: согласие большинства
Кворум — это просто «большинство реплик согласны». Если у вас 5 копий, большинство — 3.
Требуя подтверждения записи/чтения от большинства, вы снижаете шанс вернуть устаревшие или конфликтующие данные. Например, если запись должна подтвердиться 3 репликами, труднее получить две изолированные группы, принявшие разные «истины».
Цена — скорость и достижимость: если вы не можете достучаться до большинства (из‑за разрыва), операция может быть отклонена — вы отдаёте приоритет согласованности над доступностью.
Таймауты, повторы и backoff формируют восприятие доступности
Многие вопросы доступности — это не «жёсткие падения», а медленные ответы. Короткий таймаут делает систему отзывчивой, но увеличивает шанс считать медленный успех ошибкой.
Повторы могут помочь восстановиться после кратковременных сбоев, но агрессивные повторы перегружают уже испытывающие трудности сервисы. Backoff (увеличение пауз между повторами) и jitter (рандомизация) помогают не превратить повторы в всплеск трафика.
Подбирайте эти параметры в соответствии с вашими обещаниями: «всегда отвечать» обычно требует больше повторов и fallback‑ов; «никогда не лгать» — жёстких лимитов и понятных ошибок.
Разрешение конфликтов, если вы допускаете расхождение
Если вы остаётесь доступными во время разрывов, реплики могут принять разные обновления, и их нужно будет примирять позже. Популярные подходы:
- Last‑write‑wins (LWW): берётся обновление с последним временным штампом. Просто, но может потерять важные изменения при рассинхронизации часов.
- Векторные версии (version vectors): прикрепляют небольшую «историю», помогающую понять, были ли обновления конкурентными или одно заменяет другое.
- Правила слияния: определяйте, как комбинировать изменения (например, объединение корзин; суммирование счётчиков; предпочтение непустых полей в профиле). Лучше всего подобные правила проектировать в модели данных заранее.
Идемпотентность: как сделать повторы безопасными
Повторы могут порождать дубликаты: двойное списание с карты или повторная отправка заказа. Идемпотентность решает это.
Частый паттерн — idempotency key (ключ запроса), который клиент шлёт вместе с запросом. Сервер сохраняет первый результат и возвращает тот же результат для повторных запросов — так повторы повышают доступность, не портя данные.
Как валидировать предположения CAP в реальной жизни
Сохраняйте исходники за собой
Генерируйте, просматривайте и экспортируйте исходный код, чтобы полностью контролировать архитектуру.
Большинство команд «выбирает» поведение CAP на бумаге — и затем в продакшне обнаруживает, что система ведёт себя иначе. Валидация — это намеренное создание условий, где компромиссы CAP становятся видимыми, и проверка, что система реагирует ожидаемо.
Тестируйте разрывы намеренно (безопасно)
Не нужен настоящий отрезанный кабель, чтобы чему‑то научиться. Используйте управляемую инъекцию отказов в staging (и аккуратно в production), чтобы симулировать разрывы:
- Чёрноте трафик между сервисами или узлами (отбрасывайте пакеты, не закрывая соединения), имитируя тихое разделение.
- Блокируйте каналы, изменяя правила фаерволов или security groups между репликами/регіонами.
- Добавляйте экстремальные задержки и потери так, чтобы таймауты и повторы вели себя как при разрыве.
- Изолируйте лидера (например, отделите primary от кворума), чтобы увидеть, упадёт ли система в режим «согласованности» или «доступности».
Цель — получить конкретные ответы: отклоняются ли записи или принимаются? читаются ли устаревшие данные? как быстро происходит восстановление и реконсиляция?
Если хотите валидировать поведение на ранней стадии (до больших затрат на интеграцию), полезно быстро поднять реалистичный прототип. Например, команды часто начинают с простого набора сервисов и отрабатывают retry‑политики, idempotency ключи и сценарии «деградированного режима» в песочнице.
Мониторьте сигналы, которые раскрывают CAP‑проблемы
Обычные uptime‑чеки не поймают «доступно, но неправильно». Отслеживайте:
- Уровень ошибок по типам операций (чтение vs запись vs условные обновления)
- Индикаторы устаревших чтений (нарушения read‑your‑writes, несоответствие версий/ETag)
- Расхождение реплик (лаг репликации, количество неудачных апплаев, частота конфликтов)
- Таймауты и повторы (часто первый сигнал надвигающегося разрыва)
Рукомписи и коммуникация с пользователями
Операторам нужны заранее принятые действия при разрыве: когда заморозить записи, когда переключаться, когда переходить в деградированный режим, и как проверять безопасность слияния.
Также продумайте, что видит пользователь. Если вы выбираете согласованность, сообщение может звучать: «Мы не можем подтвердить ваше обновление — попробуйте позже». Если вы выбираете доступность, будьте откровенны: «Ваше обновление может появиться не сразу во всех местах». Ясные формулировки снижают нагрузку на саппорт и сохраняют доверие.
Практический чеклист CAP для повседневных решений
Когда вы принимаете решение по системе, CAP полезен как быстрый аудит «что ломается при разрыве?» — не как теоретическая дискуссия. Используйте этот чеклист перед выбором фичи базы данных, стратегии кеширования или режима репликации.
1) Короткий CAP‑чеклист
Задавайте вопросы в таком порядке:
- Что должно быть правильным? (например: «баланс счёта никогда не должен уйти в минус», «инвентарь нельзя перепродать», «права доступа должны быть точными»)
- Что должно оставаться доступным? (например: страница оформления, вход, только‑чтение каталог)
- Что может временно деградировать? (например: аналитика, рекомендации, аватары, статус «последний раз в сети»)
Если случится разрыв, вы решаете, что защищать в первую очередь.
2) Решайте по типу данных и по endpoint'ам
Избегайте глобальной настройки вроде «мы AP». Решайте для:
- Типа данных: деньги vs лайки vs логи
- Endpoint'а: «создать заказ» vs «посмотреть заказ» vs «отслеживать доставку»
Пример: во время разрыва вы можете блокировать записи в payments (приоритет согласованности), но оставлять чтения product_catalog доступными из кеша.
3) Опишите допустимую несогласованность конкретно
Пропишите, что вы готовы терпеть, с примерами:
- По времени: «счётчики могут отставать 5–10 минут»
- По величине: «инвентарь может отличаться на ±1 для малопопулярных товаров»
- По полю: «ETA доставки может быть устаревшим; итог заказа — нет»
- Формулировка для пользователя: «показывайте «в обработке» вместо окончательного статуса»
Если вы не можете описать несоответствие простыми примерами, вам будет сложно тестировать и объяснять инциденты.
4) Выводы + что читать дальше
- Разрывы превращают «приятные» гарантий в вынужденный выбор.
- Делайте эти выборы явными по endpoint'ам и документируйте допустимую несогласованность.
Темы, которые логично изучать дальше: consensus (/blog/consensus-vs-cap), модели согласованности (/blog/consistency-models-explained) и SLO/бюджеты ошибок (/blog/sre-slos-error-budgets).