30 авг. 2025 г.·8 мин
Nginx против HAProxy: как выбрать обратный прокси
Сравнение Nginx и HAProxy как обратных прокси: производительность, балансировка нагрузки, TLS, наблюдаемость, безопасность и распространённые схемы развёртывания, чтобы выбрать лучшее решение.
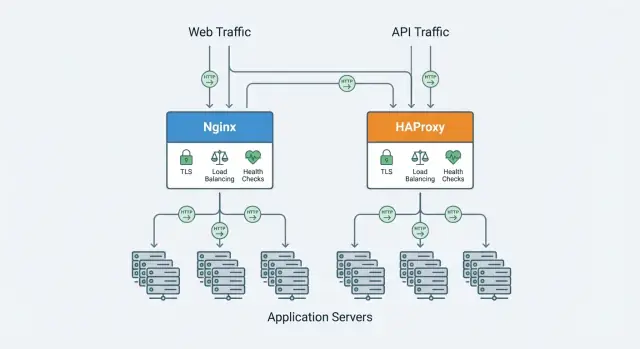
Что делает обратный прокси для ваших приложений
Обратный прокси — это сервер, который стоит перед вашими приложениями и первым принимает запросы от клиентов. Он перенаправляет каждый запрос к нужному бэкенд-сервису (вашим серверам приложений) и возвращает ответ клиенту. Пользователи общаются с прокси; прокси общается с приложениями.
Прямой прокси работает наоборот: он располагается перед клиентами (например, в корпоративной сети) и пересылает их исходящие запросы в интернет. Это в основном про контроль, фильтрацию или сокрытие клиентского трафика.
Балансировщик нагрузки часто реализуется как обратный прокси, но с явным фокусом на распределение трафика между несколькими бэкендами. Многие продукты (включая Nginx и HAProxy) делают и обратное проксирование, и балансировку, поэтому термины иногда используются взаимозаменяемо.
Типичные цели, для которых команды используют обратный прокси
Большинство развёртываний начинается по одной или нескольким из этих причин:
- TLS/SSL-терминация: обрабатывать HTTPS в одном месте, централизованно управлять сертификатами и при необходимости пересылать HTTP внутри сети.
- Маршрутизация: направлять трафик к разным сервисам по hostname, path, заголовкам или другим правилам (например,
/apiк API-сервису,/к веб-приложению). - Буферизация и обработка соединений: сглаживать поведение медленных клиентов или медленных апстримов, снижать накладные расходы на соединения для приложений и улучшать воспринимаемую надёжность.
- Механизмы защиты: вводить ограничения по запросам, базовую фильтрацию и безопасные дефолты прежде, чем запросы попадут в приложение.
Где он располагается перед вашими приложениями
Обратные прокси обычно стоят перед веб-сайтами, API и микросервисами — либо на краю (публичный интернет), либо внутри системы между сервисами. В современных стэках их также используют как компоненты ingress-шлюзов, для blue/green-развёртываний и для построения высокодоступных конфигураций.
Что поможет решить это руководство
Nginx и HAProxy пересекаются по функциональности, но отличаются акцентами. В следующих разделах мы сравним факторы принятия решения: производительность при большом числе соединений, балансировка нагрузки и health checks, поддержка протоколов (HTTP/2, TCP), функции TLS, наблюдаемость и повседневная конфигурация и эксплуатация.
Обзор Nginx: сильные стороны и типичные сценарии использования
Nginx широко используется как веб-сервер и как обратный прокси. Многие команды начинают с него для обслуживания публичного сайта, затем расширяют роль до проксирования приложений — обработки TLS, маршрутизации трафика и сглаживания всплесков.
Почему Nginx нравится на краю
Nginx хорош, когда трафик в основном HTTP(S) и нужен единый «вход», который может делать всё понемногу. Особенно сильны его возможности в:
- Эффективной отдаче статических ресурсов (изображения, CSS/JS).
- Роли HTTP reverse proxy с простыми правилами по path и host.
- Кешировании ответов, чтобы снизить нагрузку на апстримы.
- Добавлении или нормализации заголовков (например,
X-Forwarded-For, security-заголовки).
Поскольку он может и отдавать контент, и проксировать запросы, Nginx часто выбирают в небольших и средних окружениях, где хотят меньше движущихся частей.
Модули и возможности, на которые опираются команды
Популярные возможности включают:
- TLS-терминация и рабочие процессы управления сертификатами (часто с автоматикой для reload).
- Сжатие (gzip/brotli в зависимости от сборки) для экономии трафика.
- Ограничение скорости и базовые механизмы защиты от шумных клиентов.
- Перезаписи и редиректы для очистки URL и поддержки legacy.
- Опциональные возможности, такие как проксирование WebSocket для realtime-приложений.
Типичные сценарии «входной двери»
Nginx часто выбирают, когда нужен единый вход для:
- Маркетингового сайта и API (статическое + прокси).
- Простой балансировки между несколькими инстансами приложения.
- Кеширования перед медленными бэкендами (например, CMS или REST-сервисы).
- Шлюза для множества сервисов под разными host-имёнами.
Если приоритет — богатая обработка HTTP и возможность совмещать веб-сервер и прокси, Nginx часто является дефолтным выбором.
Обзор HAProxy: сильные стороны и типичные сценарии использования
HAProxy (High Availability Proxy) чаще всего используют как обратный прокси и балансировщик нагрузки, стоящий перед одним или несколькими серверами приложений. Он принимает входящий трафик, применяет правила маршрутизации и пересылает запросы на здоровые бэкенды — часто при этом поддерживая стабильное время ответа при высокой конкуренции.
Для чего обычно используют HAProxy
Команды обычно разворачивают HAProxy для управления трафиком: распределения запросов по серверам, обеспечения доступности при сбоях и сглаживания всплесков. Его часто ставят на «краю» системы (north–south трафик) и внутри сети между сервисами (east–west), особенно когда нужны предсказуемое поведение и строгий контроль над соединениями.
Ядро сильных сторон: соединения, балансировка, health checks
HAProxy известен эффективной обработкой большого числа конкурентных соединений. Это важно при большом числе одновременно подключённых клиентов (нагруженные API, долгоживущие соединения, болтливые микросервисы), когда прокси должен оставаться отзывчивым.
Его возможности балансировки — ключевая причина выбора. Помимо round-robin, он поддерживает несколько алгоритмов и стратегий маршрутизации, которые помогают:
- Не допускать перегрузки «горячих» серверов.
- Плавно перераспределять трафик при релизах.
- Предпочитать быстрые или менее загруженные инстансы при необходимости.
Health checks — ещё один сильный аспект. HAProxy может активно проверять здоровье бэкендов и автоматически исключать нездоровые инстансы из ротации, затем возвращать их, когда они восстанавливаются. На практике это уменьшает простои и предотвращает влияние «полусломанных» развёртываний на всех пользователей.
Уровень 4 vs уровень 7: что это означает на практике
HAProxy может работать на Layer 4 (TCP) и Layer 7 (HTTP).
- Layer 4 (TCP) режим фокусируется на сыром пересылании соединений. Он идеален для протоколов, где не нужно разбираться в деталях HTTP — базы данных, SMTP, Redis или когда важен минимальный оверхед.
- Layer 7 (HTTP) понимает семантику HTTP, что включает маршрутизацию по заголовкам, path и более тонкое управление трафиком.
Практическая разница: L4 проще и очень быстр для пересылки TCP, а L7 даёт богатую логику маршрутизации, когда это требуется.
Когда выбирают HAProxy
HAProxy выбирают, когда приоритет — надёжная, высокопроизводительная балансировка с мощными health-checks — например, распределение API-трафика по множеству серверов, управление фейловером между зонами доступности или фронт для сервисов, где объём соединений и предсказуемость поведения важнее, чем web-серверные удобства.
Основы производительности: задержка, пропускная способность и соединения
Сравнения производительности часто бывают некорректными, потому что люди смотрят на одно число (например, «максимум RPS») и игнорируют восприятие пользователями.
Пропускная способность vs задержка vs tail latency
- Пропускная способность — сколько работы можно прогнать (запросов/сек или байт/сек).
- Задержка — сколько времени занимает запрос.
- Tail latency (p95/p99) — где проявляются реальные проблемы: даже если среднее ок, самые медленные 1–5% могут вызывать таймауты, ретраи и плохой UX.
Прокси может увеличить пропускную способность, но при этом ухудшить tail latency, если при высокой нагрузке накапливает очередь.
Шаблоны соединений имеют значение
Подумайте о «форме» вашего приложения:
- Много коротких соединений (типичный веб-трафик): важны эффективность принятия соединений, TLS-handshake и парсинга запросов.
- Меньше долгоживущих соединений (WebSockets, стриминг, gRPC, TCP-подобные): важна стабильность и предсказуемое потребление ресурсов на соединение, а не чистый RPS.
Если вы бенчмаркуете один сценарий, а прод запускаете другой, результаты не перенесутся.
Буферизация: друг и враг
Буферизация может помогать, когда клиенты медленные или трафик всплесковый: прокси может прочитать весь запрос (или ответ) и кормить приложение более ровно.
Буферизация может вредить, когда приложение выигрывает от стриминга (SSE, большие скачивания, real-time API). Дополнительная буферизация добавляет нагрузку на память и ухудшает tail latency.
Практические советы для бенчмарков
Измеряйте не только «максимальный RPS»:
- RPS/throughput, p50/p95/p99 latency и rate ошибок (таймауты, 502/503).
- Тестируйте устойчивую нагрузку и всплески (короткие бурсты часто выявляют очереди).
- Используйте реалистичные keep-alive/TLS-настройки и фиксируйте CPU, память и открытые соединения.
Если p95 резко растёт до появления ошибок — это ранний признак насыщения, а не «свободный ресурс».
Сравнение балансировки нагрузки и проверок состояния
Оба решения — Nginx и HAProxy — могут стоять перед множеством инстансов и распределять трафик, но они отличаются глубиной встроенных возможностей балансировки.
Алгоритмы балансировки
Round-robin — дефолтный «достаточно хороший» выбор, когда бэкенды похожи. Простой и предсказуемый, хорошо работает для stateless-приложений.
Least connections полезен, когда длительность запросов варьируется (загрузки файлов, долгие API-вызовы, WebSocket-подобные нагрузки). Он склонен избегать перегрузки медленных серверов, отдавая предпочтение тем, у кого меньше активных запросов.
Взвешенная балансировка (round-robin с весами, или weighted least connections) пригодна, когда серверы не одинаковы — смешанные старые/новые ноды, разные размеры инстансов или постепенное смещение трафика во время миграции.
В целом, HAProxy предлагает больше выбора алгоритмов и более тонкий контроль на L4/7, тогда как Nginx покрывает распространённые кейсы чисто (и может быть расширен в зависимости от издания/модулей).
Сохранение сессии (stickiness)
Stickiness держит пользователя на одном бэкенде между запросами.
- Cookie-based persistence обычно лучше для веб-приложений: явна, работает через NAT и допускает контролируемый failover при недоступности бэкенда.
- Source IP persistence просто включить, но это может быть несправедливо (много пользователей за одним NAT окажутся на одном бэкенде) и ломается при изменении видимости IP (CDN, прокси).
Используйте persistency только при крайней необходимости (устаревшие серверные сессии). Stateless-приложения лучше масштабируются и восстанавливаются без нее.
Health checks: активные vs пассивные
Активные проверки периодически опрашивают бэкенды (HTTP endpoint, TCP connect, ожидаемый статус). Они ловят отказы даже при низком трафике.
Пассивные проверки реагируют на реальный трафик: таймауты, ошибки соединения или плохие ответы помечают сервер как нездоровый. Они лёгкие по ресурсам, но обнаруживают проблемы медленнее.
HAProxy широко известен своими богатыми health-check'ами и управлением отказами (пороги, rise/fall, детальные проверки). Nginx также поддерживает надёжные проверки, возможности зависят от сборки и издания.
Бесшовные релизы: дренирование и повторы
Для rolling deploys обратите внимание на:
- Draining: перестать отправлять новые запросы на бэкенд, но дать завершиться текущим.
- Retries и redispatch: если бэкенд упал во время запроса, безопасно повторить (только для идемпотентных запросов) или переслать запрос на другой здоровый сервер.
В паре с дренированием используйте короткие, определённые таймауты и четкий endpoint «ready/unready», чтобы трафик плавно переключался при деплоях.
Протоколы и TLS: HTTP, HTTP/2 и TCP-прокcирование
Создать приложение-прокси
Создайте React-фронтенд и Go-API, которые можно разместить за Nginx или HAProxy.
Прокси стоят на границе системы, поэтому выбор протоколов и TLS влияет на всё — от производительности в браузере до безопасного общения между сервисами.
TLS-терминация и управление сертификатами
Оба — Nginx и HAProxy — могут «терминировать» TLS: принимать зашифрованные соединения от клиентов, расшифровывать и пересылать запросы к приложениям по HTTP или по повторно зашифрованному TLS.
Операционно важно управление сертификатами. Понадобится план для:
- Получения и обновления сертификатов (обычно через ACME/Let’s Encrypt).
- Безопасного хранения приватных ключей и ограничения доступа к ним.
- Перезагрузок конфигурации без разрыва соединений.
Nginx часто выбирают, когда TLS-терминация сочетается с веб-функциями (статические файлы, редиректы). HAProxy выбирают, когда TLS — часть слоя управления трафиком (балансировка, обработка соединений).
HTTP/2: производительность и совместимость
HTTP/2 может уменьшить время загрузки страниц у браузеров за счёт мультиплексирования запросов по одному соединению. Оба инструмента поддерживают HTTP/2 на клиентской стороне.
Ключевые моменты:
- Совместимость клиентов: большинство современных браузеров поддерживают HTTP/2, но старые клиенты и некоторые автоматизированные инструменты могут не поддерживать.
- Поддержка бэкендов: часто HTTP/2 терминируют на прокси и говорят с upstream по HTTP/1.1, что проще и распространено.
Когда важен TCP-прокси
Если нужно маршрутизировать не-HTTP трафик (базы данных, SMTP, Redis, кастомные протоколы), нужен TCP-прокси, а не HTTP-маршрутизация. HAProxy широко используется для высокопроизводительной TCP-балансировки с тонким контролем соединений. Nginx тоже может проксировать TCP (через stream), что подходит для простых pass-through сценариев.
Взаимная TLS (mTLS)
mTLS проверяет обе стороны: клиенты представляют сертификаты не только серверы. Это хорошо подходит для сервис-ту-сервис коммуникации, интеграций с партнёрами или zero-trust-дизайна. Любой из прокси может валидировать клиентские сертификаты на краю, многие команды также используют mTLS внутри сети между прокси и upstream для уменьшения доверия к «внутренней сети».
Наблюдаемость: логирование, метрики и отладка
Прокси проходят через каждое обращение, поэтому они — отличное место, чтобы ответить на вопрос «что произошло?». Хорошая наблюдаемость значит: консистентные логи, небольшой набор высокосигнальных метрик и повторяемый способ отладки таймаутов и gateway-ошибок.
Обязательные логи: access, error и тайминги upstream
Минимум — включите access logs и error logs в продакшне. Для access-логов включайте тайминги upstream, чтобы отличать, где было торможение: в прокси или в приложении.
В Nginx полезны поля вроде $request_time, $upstream_response_time, $upstream_status. В HAProxy включите режим HTTP-логирования и захватывайте поля таймингов (queue/connect/response), чтобы отделить «ожидание слота у бэкенда» от «медленного бэкенда».
Держите логи структурированными (JSON, если возможно) и добавляйте request ID (из входящего заголовка или сгенерированный), чтобы связывать логи прокси и приложения.
Метрики, которые стоит экспортировать
Будь то Prometheus или другая система, экспортируйте устойчивый набор метрик:
- Количество запросов и коды ответов (2xx/4xx/5xx).
- Счётчики ошибок (повторы, неудачные health checks, 502/504).
- Latency (p50/p95/p99; желательно разделять proxy vs upstream).
- Соединения (active, queued, rejected).
Nginx часто использует stub status или Prometheus-exporter; HAProxy имеет встроенную stats-страницу, с которой многие экспортеры считывают метрики.
Health endpoints и readiness checks
Экспонируйте лёгкие /health (процесс запущен) и /ready (достигнуты зависимости) endpoint’ы. Используйте оба в автоматизации: health checks балансировщика, деплои и автоскейлинг.
Отладка таймаутов, ресетов, 502/504
- 502: бэкенд отказал/закрыл соединение, проблемы с DNS или несоответствие протокола.
- 504: прокси вышел по таймауту в ожидании бэкенда.
- Resets/timeouts: проверьте keep-alive, насыщение бэкенда и длину очередей.
При отладке сравнивайте тайминги прокси (queue/connect) и upstream response. Если queue/connect велики — добавьте capacity или поменяйте логику балансировки; если upstream велико — фокусируйтесь на приложении и БД.
Конфигурация и повседневная эксплуатация
Спланируйте работу прокси
Пропишите маршруты, таймауты и шаги релиза в Режиме планирования до развёртывания.
Запуск обратного прокси — это не только про пиковую пропускную способность, но и про то, как быстро команда может внести безопасное изменение в 14:00 (или в 2:00 ночи).
Стиль конфигурации и онбординг
Конфигурация Nginx директивно-ориентированная и иерархичная. Она читается как «блоки в блоках» (http → server → location), что нравится многим, кто мыслит в терминах сайтов и маршрутов.
Конфигурация HAProxy более «конвейерная»: вы определяете frontends (что принимаете), backends (куда шлёте) и прикрепляете правила (ACL) для связи. Это кажется более явным и предсказуемым, когда вы освоите модель, особенно для логики маршрутизации трафика.
Reloads и управление изменениями
Nginx обычно перезагружает конфигурацию, создавая новые workers и аккуратно завершая старые. Это удобно для частых обновлений маршрутов и ротации сертификатов.
HAProxy тоже умеет seamless reload, но команды зачастую относятся к нему как к «appliance»: строгий контроль изменений, версионирование конфигов и аккуратная координация команд reload.
Валидация, шаблоны и DRY-принцип
Оба поддерживают тест конфигурации перед reload (обязательно для CI/CD). На практике вы будете держать конфиги DRY, генерируя их:
- Используйте шаблоны (Helm, Ansible, Terraform или внутренние инструменты).
- Храните общие фрагменты для логирования, заголовков, таймаутов и security-дефолтов.
Операционная привычка: относитесь к конфигу прокси как к коду — review, тесты и deploy как приложение.
Эксплуатация в масштабе: много приложений, маршрутов и сертификатов
Когда число сервисов растёт, настоящий боль — это разрастание сертификатов и маршрутов. Планируйте:
- Стандартные соглашения по именам и ответственностям (кто владеет каким hostname).
- Автоматическую выдачу/ротацию сертификатов.
- Ясные конвенции по таймаутам и retries для каждого сервиса.
Если ожидаете сотни хостов, централизуйте паттерны и генерируйте конфигурации из метаданных сервисов, а не правьте файлы вручную.
Где Koder.ai вписывается в этот рабочий процесс
Если вы быстро создаёте и итеративно развиваете множество сервисов, обратный прокси — лишь часть конвейера доставки: нужны повторяемые шаблоны приложений, параллельность окружений и безопасные релизы.
Koder.ai помогает командам быстрее перейти от идеи к работающему сервису, генерируя React веб-приложения, Go + PostgreSQL бэкенды и Flutter мобильные приложения через чат-интерфейс, затем поддерживая экспорт исходников, развёртывание/хостинг, пользовательские домены и снэпшоты с откатом. Фактически, вы можете прототипировать API + веб-фронтенд, развернуть их и выбирать между Nginx и HAProxy как входной дверью, опираясь на реальные паттерны трафика, а не на догадки.
Безопасность и жесткая защита
Безопасность редко сводится к одной «волшебной» фиче — это уменьшение площади поражения и ужесточение дефолтов вокруг трафика, который вы не полностью контролируете.
Базовое ужесточение (наименьшие привилегии, права, сетевые правила)
Запускайте прокси с минимальными привилегиями: привязку к привилегированным портам делегируйте через capabilities (Linux) или внешний сервис, держите рабочие процессы непривилегированными. Заблокируйте доступ к конфигам и ключам (TLS-приватные ключи, DH-параметры) для чтения только сервисным аккаунтом.
На сетевом уровне разрешайте входящие соединения только от ожидаемых источников (internet → proxy; proxy → backends). По возможности запрещайте прямой доступ к бэкендам, чтобы прокси оставался единой точкой для аутентификации, лимитов и логирования.
Ограничение скорости и защита от злоупотреблений
Nginx имеет первоклассные примитивы вроде limit_req / limit_conn. HAProxy обычно использует stick tables для отслеживания скоростей запросов, конкурентных соединений или паттернов ошибок, а затем блокирует, замедляет или тарпит злоумышленников.
Выбирайте подход под вашу модель угроз:
- Контроль всплесков для логинов/API.
- Ограничение соединений, чтобы защитить от медленных клиентов.
- Баны на основе повторяющихся 4xx/5xx паттернов (используйте осторожно, чтобы не вызвать самоинфраструктурный outage).
Подводные камни с заголовками (X-Forwarded-For, Host)
Будьте явны в том, каким заголовкам вы доверяете. Принимайте X-Forwarded-For (и подобные) только от известных upstream; иначе атакующие могут подделать IP клиента и обойти IP-ориентированные механизмы контроля. Аналогично, валидируйте или устанавливайте заголовок Host, чтобы предотвратить host-header атаки и отравление кеша.
Правило простое: прокси должен устанавливать forwarding-заголовки, а не слепо их пробрасывать.
Безопасные дефолты против request smuggling и плохих входных данных
Request smuggling эксплуатирует неоднозначный парсинг (Content-Length / Transfer-Encoding, странные пробелы или некорректный формат заголовков). Предпочитайте строгие режимы парсинга HTTP, отвергайте испорченные заголовки и задавайте консервативные лимиты:
- Максимальный размер/число заголовков.
- Разумные таймауты для заголовков/тела (защита от slowloris).
- Ясная обработка
Connection,Upgradeи hop-by-hop заголовков.
Синтаксис этих настроек отличается в Nginx и HAProxy, но итог должен быть один: закрываться при неясностях и держать лимиты явными.
Распространённые паттерны развёртывания (и когда их применять)
Обратные прокси обычно вводят в одном из двух способов: как выделённая входная точка для одного приложения или как общий шлюз для множества сервисов. Оба инструмента умеют и то, и другое — важно только, сколько логики маршрутизации вам нужно на краю и как вы хотите это эксплуатировать.
1) Одно приложение — один прокси (просто и предсказуемо)
Паттерн ставит прокси прямо перед одним веб-приложением (или небольшим набором тесно связанных сервисов). Подходит, когда основное нужно — TLS-терминация, HTTP/2, сжатие, кеширование (если Nginx) или чёткое разделение публичной и приватной зон.
Используйте, когда:
- Есть один домен приложения и ясный бэкенд.
- Нужны простые откаты и минимальные правила маршрутизации.
- Предпочитаете конфиг, привязанный к приложению.
2) Общий шлюз для многих приложений (централизованная маршрутизация)
Один (или кластер) прокси маршрутизирует трафик к множеству приложений по hostname, path, заголовкам или другим свойствам запроса. Это сокращает публичные входные точки, но усиливает важность управления конфигурацией и контроля изменений.
Используйте, когда:
- Хостите множество приложений (
app1.example.com,app2.example.com) и хотите единый ingress. - Нужны согласованные политики (TLS, редиректы, rate limiting) для всех сервисов.
- Хотите централизовать сертификаты и логирование доступа.
3) Blue/green и canary-релизы на уровне прокси
Прокси может разделять трафик между «старой» и «новой» версиями без изменений DNS или кода. Частый подход — задать две upstream-пулы (blue и green) или два бэкенда (v1 и v2) и плавно перераспределять трафик.
Обычные сценарии:
- Blue/green: переключить 100% трафика с blue на green после валидации.
- Canary: отправлять 1–10% на новую версию (взвешенно, по cookie, заголовку или отдельному canary-hostname) и постепенно увеличивать.
Это удобно, когда deployment-инструменты не умеют weighted rollouts, или когда нужна единая механика rollout для разных команд.
4) Высокая доступность: active/passive, VRRP и далее
Один прокси — точка отказа. Распространённые HA-паттерны:
- Active/passive с VRRP: два узла делят виртуальный IP; один — primary, другой — резервный.
- Active/active за балансировщиком: несколько прокси принимают трафик через облачный или аппаратный балансировщик.
- Anycast (продвинутый): один и тот же IP анонсируется из разных локаций; маршрутизация направляет пользователей к ближайшему здоровому сайту.
Выбирайте в зависимости от окружения: VRRP популярен на VM/bare-metal; управляемые балансировщики чаще проще в облаке.
5) Где CDN и WAF
Типичная цепочка: CDN (опционально) → WAF (опционально) → reverse proxy → приложение.
- CDN снижает нагрузку на origin и улучшает латентность для статического и кешируемого контента.
- WAF фильтрует вредоносные запросы до попадания на прокси/приложение.
- Reverse proxy остаётся точкой контроля для маршрутизации, TLS-политики и поведения при проблемах с upstream.
Если у вас уже есть CDN/WAF, держите прокси сосредоточенным на доставке приложений и маршрутизации, а не пытайтесь сделать его единственным уровнем защиты.
Kubernetes и современные стэки приложений
Тестируйте мобильное приложение и API
Добавьте клиент на Flutter к API и проверьте долгие соединения и повторные попытки.
Kubernetes меняет представление о «входе» в приложения: сервисы эфемерны, IP меняются, а маршрутизация часто выполняется на краю кластера через Ingress controller. И Nginx, и HAProxy подходят, но выделяются в разных ролях.
Kubernetes: опции Ingress controller и компромиссы
- Nginx — распространённый выбор для Ingress: большая экосистема и модель конфигурации естественно соответствует HTTP-маршрутизации (hosts, paths, redirects, rewrites). Многие команды выбирают его, когда им нужна гибкая L7-логика.
- HAProxy часто выбирают, когда важна балансировка, управление соединениями и предсказуемая производительность при высокой конкуренции.
На практике решение редко «кто лучше», скорее «что соответствует паттернам трафика и сколько HTTP-манипуляций нужно на краю».
Использование прокси вместе с service mesh
Если у вас service mesh (mTLS и политики трафика внутри), вы всё ещё можете держать Nginx/HAProxy на периметре для north–south трафика (интернет → кластер). Mesh обрабатывает east–west. Такое разделение сохраняет пограничные задачи (TLS-терминация, WAF/rate limiting, базовая маршрутизация) отдельно от внутренних политик (retries, circuit breaking).
Обработка gRPC и долгоживущих соединений (WebSockets, SSE)
gRPC и долгоживущие соединения предъявляют иные требования:
- Поддержка и настройка HTTP/2 для gRPC (таймауты, max concurrent streams).
- Таймауты соединений и keepalives для WebSockets и SSE.
- Поведение балансировки, которое не разрушает важную «липкую» разговорную сессию.
Тестируйте с реалистичными длительностями (минуты/часы), а не только быстрыми smoke-тестами.
Хранение конфигураций в Git и деплой через CI/CD
Относитесь к конфигу прокси как к коду: храните в Git, валидируйте в CI (lint, тест конфигурации) и разворачивайте через CD контролируемо (canary или blue/green). Это делает апгрейды безопаснее и даёт audit trail на изменения, повлиявшие на прод.
Чек-лист принятия решения: кого выбрать?
Самый быстрый путь — исходить из того, что вы хотите, чтобы прокси делал ежедневно: отдавать контент, формировать HTTP-трафик или строго управлять соединениями и балансировкой.
Выбирайте Nginx, когда вам нужно…
Если прокси — это веб-вход, Nginx часто удобнее по умолчанию:
- Кеширование для снижения нагрузки (API-ответы, ресурсы).
- Отдача статических файлов эффективно.
- Простая HTTP-маршрутизация (host/path, редиректы, нормализация заголовков).
- Удобная HTTP-ориентированная конфигурация и TLS-терминация.
Выбирайте HAProxy, когда вам нужно…
Если приоритет — точное распределение трафика и контроль под нагрузкой, HAProxy чаще выигрывает:
- Продвинутые опции балансировки и тонкая настройка поведения по backend.
- Жёсткий контроль соединений (лимиты, очереди, таймауты для высокой конкуренции).
- Глубокие health checks и устойчивый фейловер для сложных пулов.
- Layer 4 (TCP) проксирование как основной кейс.
Когда имеет смысл использовать оба
Комбинация распространена, когда нужны удобства веб-сервера и специализированная балансировка:
- Nginx на краю для статических файлов, кеширования и HTTP-маршрутизации.
- HAProxy за ним для распределения трафика между большим количеством инстансов с жёсткой политикой соединений.
Разделение помогает разграничить ответственность: веб-вопросы vs traffic engineering.
Быстрый чек-лист
Задайте себе вопросы:
- Нужны ли нам кеширование или отдача статических файлов на прокси? → Nginx
- Нужен ли строгий контроль балансировки/соединений, чтобы защитить бэкенды? → HAProxy
- Большая часть трафика — HTTP с простой маршрутизацией? → Nginx
- Балансируем ли мы смешанный TCP и HTTP трафик? → HAProxy
- Хотим один инструмент или двухуровневую схему (edge + balancer)? → выбирайте соответственно
FAQ
В чём разница между обратным (reverse) прокси и прямым (forward) прокси?
Обратный прокси располагается перед вашими приложениями: клиенты подключаются к прокси, а прокси пересылает запросы к нужному бэкенду и возвращает ответ.
Прямой (forward) прокси стоит перед клиентами и контролирует исходящий трафик в интернет (часто используется в корпоративных сетях).
Является ли балансировщик нагрузки тем же самым, что и обратный прокси?
Балансировщик нагрузки фокусируется на распределении трафика между несколькими инстансами бэкенда. Многие балансировщики реализованы как обратные прокси — поэтому термины часто пересекаются.
На практике вы обычно используете один инструмент (например, Nginx или HAProxy) для обеих задач: reverse proxy + load balancing.
Где должен располагаться обратный прокси в архитектуре?
Размещайте прокси там, где хотите единый контрольный пункт:
- На границе (публичный интернет → ваша система): TLS-терминация, маршрутизация, базовая защита, единое логирование.
- Внутри сети (служба → служба): управление трафиком, контроль соединений и безопасные развертывания.
Главное — не позволять клиентам напрямую обращаться к бэкендам, чтобы прокси оставался точкой контроля политики и видимости.
Что значит «TLS/SSL termination» и зачем это нужно?
TLS-терминация означает, что прокси обрабатывает HTTPS: принимает зашифрованные соединения от клиентов, расшифровывает их и пересылает трафик на бэкенды по HTTP или по повторно зашифрованному TLS.
Операционно нужно предусмотреть:
- Автоматическую выдачу/обновление сертификатов (обычно ACME/Let’s Encrypt).
- Безопасное хранение приватных ключей.
- Перезагрузки конфигурации без разрыва активных соединений.
Когда обычно стоит выбирать Nginx?
Выберите Nginx, если прокси одновременно является «входной дверью» для веб-трафика:
- Эффективная отдача статических файлов.
- Кеширование (включая микрокеширование) для снижения нагрузки на бэкенды.
- Простая маршрутизация по host/path, редиректы и нормализация заголовков.
- Удобная HTTP-ориентированная конфигурация для типичных веб-стэков.
Когда обычно стоит выбирать HAProxy?
Выберите HAProxy, когда приоритетом являются управление трафиком и предсказуемость под нагрузкой:
- Обработка большого количества конкурентных соединений.
- Расширенные опции балансировки нагрузки.
- Богатые и поведение при ошибках.
Как выбрать между round-robin, least-connections и weighted balancing?
Используйте round-robin для похожих бэкендов и однородной стоимости запросов.
Используйте least connections, когда длительность запросов варьируется (загрузки файлов, долгие API-вызовы, долгоживущие соединения), чтобы не перегружать медленные инстансы.
Применяйте взвешенные варианты, когда бэкенды не одинаковы (разные размеры инстансов, смешанные классы машин, поэтапные миграции) — так можно преднамеренно перераспределять трафик.
Нужно ли использовать session persistence (sticky sessions) и какой тип лучше?
Прилипание (stickiness) направляет пользователя на тот же бэкенд между запросами.
- Предпочтительно использовать cookie-based persistence для веб-приложений (явно и корректно работает через NAT).
- Будьте осторожны с source-IP persistence (много пользователей за одним NAT/CDN окажутся на одном бэкенде).
Если возможно — избегайте stickiness: статeless-приложения проще масштабировать и откатывать.
Как буферизация на прокси влияет на задержки и стриминговые нагрузки?
Буферизация помогает выравнивать медленных или всплесковый клиентов, чтобы приложение видело более равномерный поток.
Она вредит при необходимости стриминга (SSE, WebSockets, большие загрузки): буферизация увеличивает потребление памяти и может ухудшать tail-latency.
Если ваше приложение ориентировано на стриминг, тестируйте и настраивайте буферизацию явно, не полагаясь на значения по умолчанию.
Как отлаживать ошибки 502/504 и таймауты?
Начните с разделения задержки прокси и задержки бэкенда по логам/метрикам.
Типичные значения:
- 502: бэкенд отверг/закрыл соединение, проблемы с DNS или несоответствие протокола.
- 504: прокси вышел по таймауту, ожидая бэкенд.
Полезно смотреть: