Ноам Шазеер и архитектура трансформера, стоящая за LLM
Узнайте, как Ноам Шазеер и соавторы сформулировали идею трансформера: само‑внимание, многоголовое внимание и почему эта архитектура стала основой современных LLM.
Почему трансформер до сих пор важен
Трансформер — способ помочь компьютерам понимать последовательности — объекты, где важен порядок и контекст, например предложения, программный код или серия поисковых запросов. Вместо того чтобы обрабатывать токены по одному и полагаться на хрупкую память, трансформеры смотрят на всю последовательность и решают, чему уделить внимание при интерпретации каждой части.
Это простое изменение оказалось большим событием. Именно оно во многом объясняет, почему современные большие языковые модели (LLM) умеют держать контекст, следовать инструкциям, писать связные абзацы и генерировать код, который ссылается на ранее объявленные функции и переменные.
Почему вы постоянно встречаете трансформеры
Если вы использовали чат-бот, функцию «сократить/подвести итог», семантический поиск или помощника по программированию, вы взаимодействовали с системами на базе трансформеров. Одна и та же базовая схема поддерживает:
- Чат и инструменты поддержки клиентов, которые отслеживают, что вы говорили раньше
- Системы поиска и рекомендаций, которые сопоставляют смысл, а не только ключевые слова
- Сжатие текста, которое умеет взвешивать главное и второстепенное
- Инструменты для кода, которые связывают определения, использование и намерения через файлы
Что вы узнаете в этой статье
Мы разберём ключевые части — само-внимание, многоголовое внимание, позиционную кодировку и базовый блок трансформера — и объясним, почему эта архитектура так хорошо масштабируется по мере увеличения размеров моделей.
Также кратко коснёмся современных вариантов, которые сохраняют ту же идею, но подгоняют её под скорость, стоимость или большие окна контекста.
Чего ожидать (и чего не ожидать)
Это обзор высокого уровня с понятными объяснениями и минимальной математикой. Цель — дать интуицию: что делают части, почему они работают вместе и как это переводится в реальные продуктовые возможности.
Роль Ноама Шазеера в истории трансформера
Noam Shazeer — исследователь и инженер в области ИИ, наиболее известный как один из соавторов статьи 2017 года “Attention Is All You Need.” Эта статья представила архитектуру трансформера, которая впоследствии стала основой многих современных больших языковых моделей (LLM). Работа Шазеера была частью командного усилия: трансформер создали исследователи в Google, и важно отдавать этому должное.
Что изменил документ 2017 года
До трансформера многие NLP-системы опирались на рекуррентные модели, которые обрабатывали текст шаг за шагом. Предложение трансформера показало, что можно эффективно моделировать последовательности без рекуррентности, используя внимание как основной механизм для объединения информации по всему предложению.
Это изменение было важно, потому что упростило параллелизацию обучения (можно обрабатывать многие токены одновременно) и открыло путь к масштабированию моделей и наборов данных, что быстро стало практичным для реальных продуктов.
От научной идеи к элементу продуктовой инженерии
Вклад Шазеера — наряду с другими авторами — не остался только в академических бенчмарках. Трансформер стал переиспользуемым модулем, который команды могли адаптировать: менять компоненты, размер, настраивать под задачи и затем предобучать в масштабе.
Именно так многие прорывы переходят в практику: статья предлагает чистый рецепт; инженеры его уточняют; компании приводят в продакшн; и в итоге это становится стандартным выбором для языковых функций.
Точность в распределении заслуг
Правильно говорить, что Шазеер был ключевым соавтором статьи о трансформере. Неправильно представлять его как единственного изобретателя. Эффект возник из коллективного дизайна и множества последующих улучшений, которые сообщество построило поверх оригинальной схемы.
Что было до: RNN, LSTM и их ограничения
До трансформеров большинство задач с последовательностями (перевод, речь, генерация текста) были в руках рекуррентных нейросетей (RNN) и затем LSTM (Long Short-Term Memory). Идея была проста: читать текст по одному токену, хранить «память» (hidden state) и использовать её для предсказания следующего шага.
Краткая картинка их работы
RNN обрабатывает предложение как цепочку. На каждом шаге обновляется скрытое состояние на основе текущего слова и предыдущего состояния. LSTM улучшили это, добавив ворота, которые решают, что сохранить, что забыть и что вывести — это помогает дольше хранить полезные сигналы.
Почему дальние зависимости даются с трудом
На практике последовательная память имеет бутылочное горлышко: много информации нужно уместить в одно состояние по мере роста длины предложения. Даже в LSTM сигналы от далёких слов могут ослабевать или перезаписываться.
Это затрудняло обучение некоторых взаимоотношений — например связать местоимение с нужным существительным много слов назад или отслеживать тему через сложные предложения.
Проблемы обучения и масштабирования
RNN и LSTM также медленные в обучении, потому что их нельзя полностью параллелить по времени. Можно батчить разные предложения, но внутри предложения шаг 50 зависит от шага 49, который зависит от шага 48, и так далее.
Такая пошаговая вычислительная зависимость становится серьёзным ограничением при желании увеличить модели, данные и скорость экспериментов.
Мотивация для более параллельного подхода
Исследователям нужен был дизайн, который мог бы соотносить слова друг с другом без строгого лево‑‑право порядка во время обучения — способ моделировать дальние зависимости напрямую и лучше использовать современное железо. Это подготовило почву для подхода «внимание в первую очередь», представленного в Attention Is All You Need.
Внимание, объяснённое без математики
Внимание — это способ модели спросить: «На какие другие слова мне посмотреть прямо сейчас, чтобы понять это слово?» Вместо того чтобы читать предложение строго слева направо и надеяться, что память всё удержит, внимание позволяет модели заглядывать в наиболее релевантные части предложения тогда, когда это нужно.
Идея «поиска и извлечения»
Полезная мысленная модель — крошечный поисковый движок, работающий внутри предложения.
- Запрос (Query): что ищет текущее слово (вопрос)
- Ключи (Keys): что каждое другое слово предлагает (метки)
- Значения (Values): фактическая информация, которую извлекают при совпадении (содержимое)
Модель формирует запрос для текущей позиции, сравнивает его с ключами всех позиций и затем извлекает смесь значений.
Оценки релевантности → веса внимания
Сравнения дают оценки релевантности: грубые «насколько это связано» сигналы. Модель превращает их в веса внимания, которые суммируются до 1.
Если одно слово очень релевантно, ему достаётся большая доля внимания. Если важны несколько слов, внимание распределяется между ними.
Простой пример (местоимения и грамматика)
Возьмём: “Мария сказала Дженне, что она позвонит позже.”
Чтобы понять она, модель должна оглянуться на кандидатов вроде «Мария» и «Дженна». Внимание присвоит больший вес имени, которое лучше вписывается в контекст.
Или: “Ключи от шкафа пропали.” Внимание помогает связать глагол с правильным подлежащим, даже если ближайшее существительное — «шкаф», а не «ключи». Вот в чём основная польза: внимание связывает смысл на расстоянии по требованию.
Само-внимание: основной механизм
Само-внимание — идея в том, что каждый токен последовательности может смотреть на другие токены в той же последовательности, чтобы решить, что важно прямо сейчас. Вместо пошаговой обработки слева направо (как в старых рекуррентных моделях) трансформер позволяет каждому токену собирать подсказки откуда угодно во входе.
Токены смотрят на токены
Представьте предложение: «Я налил воду в чашку, потому что она была пустой.» Слово «она» должно связаться с «чашкой», а не с «водой». С само-вниманием токен «она» даёт больший вес тем токенам, которые помогают разрешить его значение («чашка», «пустой») и меньший — несущественным.
Как строится контекст
После само-внимания каждый токен уже не является просто самим собой. Он становится контекстно-зависимой версией — взвешенной смесью информации от других токенов. Можно представить, что каждый токен создаёт персонализированное резюме всего предложения, настроенное под свои потребности.
На практике представление «чашки» может нести сигналы от «налил», «вода» и «пустой», а «пустой» — тянуть то, что он описывает.
Почему обучение может быть параллельным
Потому что каждый токен может одновременно посчитать своё внимание по всей последовательности, обучение не обязано ждать пошаговой обработки предыдущих токенов. Эта параллельная обработка — одна из главных причин, почему трансформеры эффективно обучаются на больших датасетах и масштабируются до огромных моделей.
Почему это хорошо для дальних зависимостей
Само-внимание облегчает связь удалённых частей текста. Токен может напрямую сфокусироваться на релевантном слове далеко — без передачи информации через длинную цепочку промежуточных шагов.
Такой прямой путь помогает в задачах вроде кореференции («она», «оно», «они»), отслеживания тем через абзацы и обработки инструкций, зависящих от ранних деталей.
Многоголовое внимание: много взглядов на одно предложение
Один механизм внимания мощный, но всё равно похоже на попытку понять разговор, глядя только с одной камеры. В предложении одновременно сосуществуют несколько отношений: кто что сделал, на что ссылается «оно», какие слова задают тон и какова тема.
Почему одного взгляда может быть недостаточно
Когда вы читаете «Трофей не поместился в чемодан, потому что он был слишком мал», вам может понадобиться одновременно отслеживать грамматику, смысл и здравый смысл. Одна голова внимания может зацепиться за ближайшее существительное; другая — использовать глагол, чтобы решить, на что ссылается «он».
Что делают множественные головы
Многоголовое внимание выполняет несколько расчётов внимания параллельно. Каждая «голова» смотрит на предложение через свою линзу — часто описываемую как разные подпространства. На практике головы могут специализироваться на таких паттернах, как:
- Локальный синтаксис (например прилагательное → существительное)
- Дальние связи (например субъект ↔ сказуемое через придаточное)
- Кореференция (например местоимение → сущность)
- Тематические сигналы (слова, задающие тему или тон)
Как комбинируются головы
После того как каждая голова сформировала свои выводы, модель не выбирает одну из них. Она конкатенирует выходы голов (складывает их по ширине) и затем проецирует обратно в рабочее пространство модели линейным слоем. Можно представить это как объединение нескольких частичных заметок в одно чистое резюме, которое следующий слой может использовать.
Результат — представление, способное одновременно захватывать множество отношений; это одна из причин, почему трансформеры так хорошо работают в масштабе.
Позиционная кодировка: обучение порядку слов
Само-внимание отлично находит связи, но по сути не знает, кто был раньше. Если переставить слова в предложении, простой слой само-внимания может посчитать перестановку равнозначной, потому что сравнивает токены без встроенной информации о позиции.
Позиционная кодировка решает это, вводя в представления токенов сигнал «где я в последовательности». После добавления позиции внимание может выучить паттерны вроде «слово сразу после не важно» или «подлежащее обычно стоит перед сказуемым» без необходимости выводить порядок из нуля.
Как позиционные сигналы вводят порядок
Идея простая: эмбеддинг каждого токена комбинируется с позиционным сигналом перед тем, как попасть в блок трансформера. Этот позиционный сигнал можно рассматривать как дополнительные признаки, помечающие токен как 1-й, 2-й, 3-й… во входе.
Есть несколько популярных подходов:
- Абсолютные (фиксированные) позиции: классические трансформеры использовали детерминированные синусоидальные паттерны. Они не добавляют новых параметров и могут частично обобщаться на длины больше тех, что были в обучении.
- Обучаемые абсолютные позиции: модель учит вектор для «позиции 1», «позиции 2» и т. д. Это работает хорошо, но часто привязывает модель к максимальному окну контекста, с которым она была обучена.
- Относительные позиции: вместо кодирования «это токен 57» модель фокусируется на расстояниях вроде «этот токен на 3 шага раньше того». Современные варианты (включая ротационные методы) часто относятся к этой категории.
Почему это важно для задач с большим контекстом
Выбор позиции заметно влияет на моделирование длинного контекста — например, суммирование длинного отчёта, отслеживание сущностей через много абзацев или извлечение детали, упомянутой тысячи токенов назад.
При длинных входах модель учится не просто языку, но и где искать. Относительные и ротационные схемы часто облегчают сравнение удалённых токенов и сохранение паттернов при росте контекста, тогда как некоторые абсолютные схемы могут деградировать за пределами окна обучения.
На практике позиционная кодировка — тихое архитектурное решение, которое может определить, будет ли LLM оставаться чётким и согласованным на 2000 токенов — и ещё более долгом контексте.
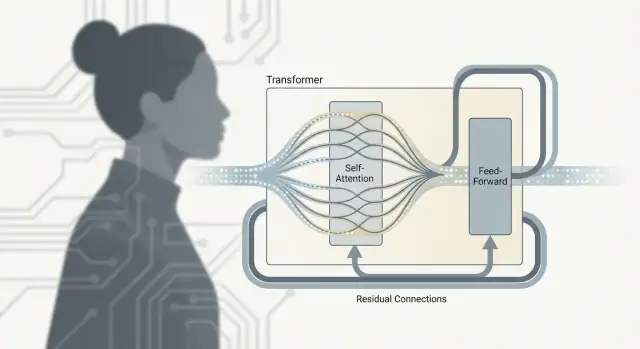
Блок трансформера: внимание + MLP + стабилизаторы
Трансформер — это не только «внимание». Реальная работа происходит внутри повторяющейся единицы — блока трансформера — который смешивает информацию между токенами и затем её уточняет. Если сложить много таких блоков, получится глубина, делающая большие языковые модели настолько мощными.
После внимания: что делает FFN/MLP
Само-внимание — это шаг коммуникации: каждый токен собирает контекст от других токенов.
Feed-forward сеть (FFN), также называемая MLP, — это шаг обработки: она берёт обновлённое представление каждого токена и запускает одну и ту же небольшую нейросеть для каждой позиции независимо.
Проще говоря, FFN преобразует и переформатирует то, что теперь знает токен, помогая модели строить более богатые признаки (синтаксические структуры, факты, стилистические маркеры) после того, как он собрал релевантный контекст.
Почему блоки чередуют внимание и FFN
Чередование важно, потому что две части делают разную работу:
- Внимание перемещает информацию между токенами (кто на кого влияет)
- FFN обрабатывает информацию внутри каждого токена (как превратить контекст в полезные признаки)
Повторение этого паттерна позволяет модели постепенно строить более высокоуровневое понимание: общаться, вычислять, снова общаться, снова вычислять.
Резидуальные связи: «полосы-обходы»
Каждый субслой (внимание или FFN) окружён резидуальной связью: вход прибавляется к выходу. Это помогает при обучении глубоких сетей, потому что градиенты могут течь через «обходную полосу», даже если конкретный слой ещё учится. Также это позволяет слою вносить небольшие коррективы вместо того, чтобы переучивать всё с нуля.
Нормализация слоёв: удержание сигналов в пределах
Нормализация слоёв стабилизирует активации, чтобы они не росли и не падали слишком сильно при прохождении через десятки или сотни слоёв. Представьте это как поддержание постоянного уровня громкости, чтобы последующие слои не перегружались и не оставались без сигнала — это делает обучение более плавным и надёжным, особенно в масштабах LLM.
Энкодер–декодер против декодерного подхода: что питает LLM?
Оригинальный трансформер в Attention Is All You Need был создан для машинного перевода, где нужно преобразовать одну последовательность (напр., французский) в другую (английский). Эта задача естественно делится на две роли: прочитать вход и сгенерировать выход.
Энкодер–декодер: «сначала читать, затем писать»
В энкодер–декодер трансформере энкодер обрабатывает весь вход сразу и выдаёт богатые представления. Декодер затем генерирует выход по одному токену. Ключевое: декодер помимо своих прошлых токенов использует кросс-внимание к выходам энкодера, чтобы оставаться привязанным к исходному тексту.
Эта схема отлично работает, когда нужно сильно обусловливать генерацию входом — перевод, суммирование или вопрос-ответ с конкретным отрывком.
Декодерный подход: одна модель, которая просто продолжает предсказывать
Большинство современных LLM — только декодеры. Их обучают простой и мощной задаче: предсказывать следующий токен.
Для этого используют маскированное само-внимание (каузальное). Каждая позиция может смотреть только на предыдущие токены, а не на будущие, поэтому при генерации модель расширяет последовательность слева направо.
Это доминирующий подход для LLM, потому что он прост для обучения на огромных текстовых корпусах, соответствует задаче генерации и эффективно масштабируется с данными и вычислениями.
Где применяются энкодерные модели
Только энкодер модели (в стиле BERT) не генерируют текст; они читают вход двунаправленно. Они отлично подходят для классификации, поиска и эмбеддингов — задач, где важно понять фрагмент текста больше, чем продолжить его.
Почему трансформеры масштабируются до больших языковых моделей
Трансформеры оказались необычно дружелюбными к масштабированию: если дать им больше текста, вычислений и большие модели, они, как правило, продолжают улучшаться предсказуемым образом.
Одна большая причина — структурная простота. Трансформер строится из повторяющихся блоков (само-внимание + небольшая FFN плюс нормализация), и эти блоки себя ведут схожим образом, будь вы обучаете модель на миллионах слов или на триллионах.
Параллельное обучение — скрытая суперсила
Ранние последовательные модели (RNN) были вынуждены обрабатывать токены по одному, что ограничивает параллелизм. Трансформеры же могут во время обучения обработать все токены в последовательности параллельно.
Это делает их отличной парой для GPU/TPU и распределённых систем — как раз то, что нужно при обучении современных LLM.
«Окно контекста» и почему это важно
Окно контекста — это кусок текста, который модель «видит» одновременно: ваш промпт плюс недавняя история разговора или документ. Большое окно позволяет модели связывать идеи через предложения или страницы, отслеживать ограничения и отвечать на вопросы, зависящие от ранних деталей.
Но контекст не бесплатен.
Ключевое ограничение: стоимость внимания растёт с длиной
Само-внимание сравнивает токены друг с другом. По мере удлинения последовательности число сравнений быстро растёт (примерно пропорционально квадрату длины). Поэтому очень длинные окна контекста требовательны к памяти и вычислениям, и многие современные усилия направлены на то, чтобы сделать внимание эффективнее.
Масштабирование открыло универсальное поведение
Когда трансформеры обучают в масштабе, они перестают становиться лучше только в одной узкой задаче. Они показывают широкие, гибкие способности — суммирование, перевод, написание, кодинг и рассуждение — потому что одна и та же общая обучающая машина применяется к массивным и разнообразным данным.
Современные варианты, построенные на той же основе
Оригинальный дизайн трансформера остаётся отправной точкой, но большинство production LLM — это «трансформеры плюс»: небольшие практические изменения, которые сохраняют основной блок (внимание + MLP), но улучшают скорость, стабильность или длину контекста.
Частые улучшения, которые вы встретите
Многие апгрейды больше про то, как модель обучать и запускать, чем про изменение её сути:
- Лучшие позиционные методы: альтернативы классическим синусоидальным позициям (часто ротационные или относительные подходы) могут сделать обработку длинных текстов более устойчивой.
- Оптимизации внимания: реализации, которые снижают использование памяти и увеличивают пропускную способность (например, объединённые ядра или более эффективные вычисления внимания).
- Хитрости нормализации: вариации в том, где и как применяется нормализация, могут улучшить стабильность обучения и снизить чувствительность к гиперпараметрам.
Эти изменения обычно не меняют фундаментальную «трансформерность» модели — они её уточняют.
Подходы к длинному контексту (в общих чертах)
Расширение контекста от нескольких тысяч токенов до десятков или сотен тысяч часто опирается на разреженное внимание (аттенд только к отобранным токенам) или эффективные варианты внимания (приближения или реструктуризация внимания, чтобы сократить вычисления).
Компромисс обычно между точностью, использованием памяти и инженерной сложностью.
Mixture-of-Experts (MoE): больше ёмкости без линейного роста стоимости
MoE добавляет несколько «экспертных» подсетей и маршрутизирует каждый токен только через часть из них. Концептуально: вы получаете больший «мозг», но не активируете его полностью каждый раз.
Это может снизить вычисления на токен при заданном числе параметров, но увеличивает системную сложность (маршрутизация, балансировка экспертов, развёртывание).
Как проверять заявления о новых вариантах
Когда модель хвастается новым вариантом трансформера, спросите про:
- Бенчмарки, релевантные вашим задачам (а не только заголовочные баллы)
- Задержку (time-to-first-token и токены/сек)
- Стоимость (обучение и инференс), включая память и требования к железу
Большинство улучшений реальны, но редко бывают бесплатными.
Что это означает для команд, строящих системы на LLM
Идеи трансформеров — само-внимание и масштабирование — впечатляют, но продуктовые команды в основном ощущают их как компромиссы: сколько текста вы можете прокинуть, как быстро получаете ответ и во сколько обходится запрос.
Выбор модели или провайдера: четыре компромисса
Длина контекста: длинный контекст позволяет включать больше документов, истории чата и инструкций, но увеличивает затраты на токены и может замедлить ответы. Если фича зависит от «прочитать эти 30 страниц и ответить», приоритезируйте окно контекста.
Задержка: пользовательские чаты и copilot‑опыт зависят от времени ответа. Потоковая выдача помогает, но выбор модели, регион и батчирование тоже влияют.
Стоимость: ценообразование обычно за токен (вход + выход). Модель, которая на 10% «лучше», может стоить в 2–5× дороже. Сравнивайте по цене и мощности, чтобы понять, какой уровень качества стоит платить.
Качество: определите его для вашей задачи: фактическая точность, следование инструкциям, тон, использование инструментов или код. Оценивайте на реальных примерах из вашей предметной области, а не на общих бенчмарках.
Когда эмбеддинги лучше генерации
Если вам в основном нужен поиск, дедупликация, кластеризация, рекомендации или «найти похожее», эмбеддинги (часто энкодерные модели) обычно дешевле, быстрее и стабильнее, чем вызов чат-модели. Используйте генерацию только для финального шага (суммирование, объяснения, черновики) после извлечения.
Для более глубокого разбора отправьте команду к техническому объяснению типа /blog/embeddings-vs-generation.
Где это проявляется в рабочих процессах
Когда вы переводите возможности трансформера в продукт, сложность чаще всего связана не с архитектурой, а с рабочим процессом вокруг неё: итерации промптов, закрепление знаний, оценка и безопасный деплой.
Один практичный путь — прототипировать и выкатывать функции на vibe-coding платформе вроде Koder.ai: вы можете описать веб‑приложение, бэкенд‑эндпоинты и модель данных в чате, итеративно планировать и затем экспортировать исходный код или развернуть с хостингом, собственными доменами и откатом через снимки. Это особенно полезно, когда вы экспериментируете с извлечением, эмбеддингами или вызовами инструментов и хотите быстрые итерации без перестройки базовой инфраструктуры.
Практический чек‑лист для внедрения
- Напишите одностраничную спецификацию: цель пользователя, режимы отказа и критерии «хорошо».
- Решите, что должно быть заякорено в ваших данных (RAG, цитаты или вызовы инструментов).
- Установите бюджеты на токены, задержку и ежемесячные расходы; измеряйте их в стейджинге.
- Добавьте предохранители: отказ, редактирование чувствительных данных и поведение «я не знаю».
- Постройте оценку на раннем этапе: золотые промпты, регрессионные тесты и человеческий ревью.
- Планируйте смену модели: держите промпты и маршрутизацию настраиваемыми.
FAQ
Что такое трансформер простыми словами?
Трансформер — это архитектура нейронной сети для последовательных данных, которая использует само-внимание чтобы соотносить каждый токен со всеми остальными токенами в одном входе.
Вместо того чтобы переносить информацию шаг за шагом (как в RNN/LSTM), он строит контекст, решая на что обращать внимание по всему фрагменту входа — это улучшает понимание дальнодействующих связей и делает обучение более параллельным.
Почему трансформеры заменили RNN и LSTM во многих задачах NLP?
RNN и LSTM обрабатывают текст по одному токену за раз, что затрудняет параллелизацию обучения и создаёт узкое место для долгосрочных зависимостей.
Трансформеры используют внимание, чтобы напрямую связывать удалённые токены, и при обучении могут одновременно вычислять множество взаимодействий между токенами — поэтому их проще масштабировать с большими данными и вычислительными ресурсами.
Что такое «внимание» и как его представлять?
Внимание — это механизм для ответа на вопрос: «Какие другие токены наиболее важны для понимания этого токена прямо сейчас?»
Можно представить его как внутренний поиск по предложению:
- запрос (query) — что нужно текущему токену
- ключи (keys) — что предлагает каждый токен
- значения (values) — информация, которую можно смешать при совпадении
На выходе получается взвешенная смесь релевантных токенов, дающая контекстно-зависимое представление для каждой позиции.
В чём разница между attention и self-attention?
Само-внимание означает, что токены в последовательности обращаются к другим токенам в той же последовательности.
Это основной инструмент, который помогает модели разрешать кореференцию (например, на что ссылается «оно»), отношения субъект–предикат через целые фразы и зависимости, находящиеся далеко друг от друга, — и всё это без «проталкивания» информации через единое рекуррентное состояние.
Зачем трансформерам многоголовое внимание?
Многоголовое внимание запускает несколько независимых расчётов внимания параллельно, и каждая голова может специализироваться на разных паттернах.
На практике разные головы часто фокусируются на разных отношениях (синтаксис, дальние связи, разрешение местоимений, тематические сигналы). Модель затем объединяет эти виды, чтобы одновременно представлять несколько типов структуры.
Если внимание смотрит на всё, как модель узнаёт порядок слов?
Само-внимание само по себе не даёт информации о порядке токенов — без позиционной информации переставленные слова могут выглядеть одинаково.
Позиционные кодировки/встраивания вводят сигнал «где я в последовательности», чтобы модель могла выучить паттерны вроде «слово сразу после не важно» или «подлежащее обычно стоит перед сказуемым».
Распространённые варианты: синусоидальные (фиксированные), обучаемые абсолютные позиции и относительные/ротационные методы.
Что ещё находится в блоке трансформера, кроме внимания?
Блок трансформера обычно сочетает в себе:
- Внимание: перемещает информацию между токенами
- FFN/MLP: обрабатывает информацию внутри каждого токена
- Резидуальные связи: помогают градиентам и позволяют слоям вносить небольшие корректировки
- Нормализация слоёв: стабилизирует активации при глубокой стэкинге
Слои чередуются, чтобы модель могла поочерёдно «общаться» и «думать» над полученным контекстом.
Энкодер–декодер или только декодер: что используют LLM?
Оригинальный трансформер — это энкодер–декодер:
- энкодер читает вход двунаправленно и создаёт представления
- декодер генерирует выход по одному токену, используя кросс-внимание к энкодеру
Большинство современных LLM — только декодеры. Их обучают предсказывать следующий токен с помощью маскированного (каузального) само-внимания, что соответствует пошаговой генерации слева направо и хорошо масштабируется при обучении на огромных корпусах.
Какую роль сыграл Ноам Шазир в создании трансформера?
Noam Shazeer был соавтором статьи 2017 года «Attention Is All You Need», которая ввела архитектуру трансформера.
Правильно считать его ключевым участником, но архитектура была создана командой в Google, и её влияние также обусловлено множеством последующих улучшений со стороны сообщества и индустрии.
Почему большие окна контекста дорогие и что с этим можно сделать?
При длинных входах стандартное само-внимание становится дорогостоящим, потому что число сравнений растёт примерно пропорционально квадрату длины последовательности, что увеличивает требования к памяти и вычислениям.
Практические подходы команд:
- выбирать модели с большим нативным окном контекста
- применять RAG (извлекать релевантные куски вместо того, чтобы класть всё во вход)
- использовать варианты с длинным контекстом (разреженное/эффективное внимание)
- измерять реальные компромиссы: задержка, стоимость токенов и точность на ваших рабочих нагрузках