15 мая 2025 г.·8 мин
Как создать веб‑приложение для обогащения данных клиентов
Научитесь строить веб‑приложение для обогащения клиентских записей: архитектура, интеграции, сопоставление, валидация, приватность, мониторинг и советы по запуску.
Определите цели, пользователей и объём обогащения
Прежде чем выбирать инструменты или рисовать архитектуру, точно сформулируйте, что именно означает «обогащение» для вашей организации. Команды часто смешивают несколько типов обогащения и потом не могут измерить прогресс — или спорят о том, что считать «сделано».
Что считается обогащением?
Начните с перечисления категорий полей, которые вы хотите улучшить, и причин для этого:
- Фирмографические: размер компании, отрасль, местоположение штаб‑квартиры, стадия финансирования
- Контактные: должность, верифицированный email/телефон, уровень (seniority), роль
- Поведенческие: сигналы использования продукта, намерения, показатели вовлечённости
- Пользовательские поля: внутренняя территория, уровень аккаунта, оценка соответствия ICP
Запишите, какие поля обязательны, какие желательны, а какие ни в коем случае не должны обогащаться (например, чувствительные атрибуты).
Кто будет пользоваться приложением — и зачем?
Определите основных пользователей и их основные задачи:
- Sales ops: уменьшить дубликаты, стандартизировать аккаунты, улучшить маршрутизацию
- Marketing ops: обогащать лиды для сегментации и таргетинга
- Support: показывать контекст аккаунта при работе с тикетами
- Аналитики: получать доверенные наборы данных для отчётов
У каждой группы свои потребности (пакетная обработка против ручной проверки одной записи), поэтому зафиксируйте эти требования на раннем этапе.
Определите результаты, границы объёма и метрики успеха
Перечислите результаты в измеримых показателях: более высокий процент совпадений, меньше дубликатов, быстрее маршрутизация лидов/аккаунтов или улучшение качества сегментации.
Задайте чёткие границы: какие системы входят в область (CRM, биллинг, продуктовая аналитика, служба поддержки) и какие — нет, по крайней мере для первого релиза.
Наконец, согласуйте метрики успеха и допустимые ошибки (например, покрытие обогащения, процент верификации, уровень дубликатов и правила «безопасного отказа», когда обогащение неопределённо). Это станет вашим компасом на этапе разработки.
Смоделируйте данные о клиентах и выявите пробелы
Прежде чем что‑то обогащать, уточните, что в вашей системе означает «клиент», и что вы уже знаете о нём. Это предотвратит плату за обогащение, которое вы не сможете сохранить, и исключит путаницу при последующих слияниях.
Инвентаризация текущих полей и источников
Начните с простого каталога полей (например: имя, email, компания, домен, телефон, адрес, должность, отрасль). Для каждого поля укажите, откуда оно берётся: ввод пользователя, импорт в CRM, биллинг, инструмент поддержки, форма регистрации в продукте или поставщик обогащения.
Также зафиксируйте как оно собирается (обязательно/необязательно) и как часто меняется. Например, должность и размер компании со временем дрейфуют, тогда как внутренний идентификатор клиента никогда не должен меняться.
Определите модель идентичности: человек, компания, аккаунт
Большинство рабочих процессов обогащения включают по крайней мере две сущности:
- Человек (контакт/лид): индивидуум с email, телефонами, ролями
- Компания (организация): бизнес с доменом, местоположением, фирмографикой
Решите, нужен ли вам также Аккаунт (коммерческое отношение), который связывает несколько людей с одной компанией и содержит атрибуты вроде плана, дат контракта и статуса.
Опишите поддерживаемые отношения (например, много людей → одна компания; один человек → несколько компаний с течением времени).
Документируйте типичные проблемы с данными
Перечислите повторяющиеся проблемы: отсутствующие значения, несовместимые форматы ("US" vs "United States"), дубликаты после импортов, устаревшие записи и конфликтующие источники (биллинг‑адрес vs адрес в CRM).
Выберите ключи идентификации и установите уровни доверия
Выберите идентификаторы для сопоставления и обновлений — обычно email, домен, телефон и внутренний customer ID.
Назначьте каждому уровень доверия: какие ключи авторитетны, какие — «попытка наилучшего совпадения», а какие никогда не перезаписывать.
Уточните владение и права редактирования
Согласуйте, кто владеет какими полями (Sales ops, Support, Marketing, Customer Success) и определите правила редактирования: что может менять человек, что — автоматизация, а что требует утверждения.
Эта модель управления экономит время, когда результаты обогащения конфликтуют с существующими данными.
Выберите источники обогащения и договорённости по данным
Прежде чем писать интеграционный код, решите, откуда будет поступать обогащение и что вам разрешено с этими данными делать. Это предотвращает распространённую проблему: функционал работает технически, но рушит бюджет, надёжность или правила соответствия.
Типичные источники обогащения
Обычно вы комбинируете несколько входов:
- Внутренние системы: CRM, биллинг, тикеты поддержки, продуктовая аналитика, почтовая платформа, хранилище данных
- Сторонние API: фирмографика компаний, валидация контактов, коды отраслей, технологические сигналы, рисковые индикаторы
- Загруженные списки: CSV от продаж, мероприятий, партнёров или провайдеров данных
- Вебхуки: события в реальном времени от инструментов, которые уже отслеживают изменения (например, верификация email, провайдеры идентичности)
Как оценивать источники
Оценивайте каждый источник по покрытию (как часто возвращает полезные данные), свежести (как быстро обновляется), стоимости (за запрос/запись), лимитам запросов и условиям использования (что можно хранить, как долго и с какой целью).
Проверьте, возвращает ли поставщик оценки уверенности и явную происхождение (provenance) — это важно для доверия.
Определите контракт данных
Рассматривайте каждый источник как контракт, который определяет имена и форматы полей, обязательные и опциональные поля, частоту обновлений, ожидаемую задержку, коды ошибок и семантику уверенности.
Включите явное отображение («поле поставщика → ваше каноническое поле») и правила для null‑значений и конфликтов.
План резервных вариантов и решения по хранению
Пропишите, что делать, если источник недоступен или возвращает данные с низкой уверенностью: повторить с экспоненциальной задержкой, поставить в очередь на позже или переключиться на вторичный источник.
Решите, что вы храните (стабильные атрибуты, нужные для поиска/отчётов), а что вычисляете на лету (дорогие или чувствительные lookup’и).
Наконец, документируйте ограничения на хранение чувствительных атрибутов (личные идентификаторы, выводимые демографические данные) и правила хранения/удаления.
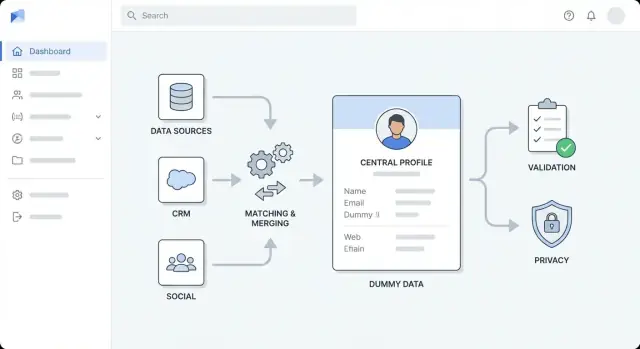
Проектирование высокоуровневой архитектуры
Прежде чем выбирать инструменты, решите форму приложения. Чёткая архитектура делает работу предсказуемой, предотвращает превращение «быстрых фиксов» в постоянный мусор и помогает команде оценить усилия.
Выберите стиль архитектуры, подходящий команде
Для большинства команд начните с модульного монолита: одно деплойное приложение, внутренне разбитое на модули (ингест, матчинг, обогащение, UI). Так проще строить, тестировать и отлаживать.
Переходите к отдельным сервисам, когда есть веская причина — например, высокий throughput обогащения, необходимость независимого масштабирования или разные команды владеют частями. Обычное разделение:
- API‑сервис (синхронные запросы, аутентификация, CRUD записей)
- Worker‑сервис (асинхронное обогащение, ретраи)
- UI (просмотр, утверждения, пакетные действия)
Разделяйте обязанности по слоям
Держите границы явными, чтобы изменения не распространялись повсеместно:
- Слой поглощения (ingestion): импорты из CRM/файлов и нормализация входных данных
- Слой обогащения: вызовы провайдеров/внутренних источников и сохранение результатов
- Слой валидации: правила качества данных и флаги исключений
- Слой хранения: профили клиентов, сырые полезные нагрузки источников, история аудита
- Слой представления: UI‑виды, очереди на проверку, утверждения
Проектируйте асинхронное обогащение с первого дня
Обогащение медленное и ненадёжное (лимиты запросов, таймауты, неполные данные). Рассматривайте обогащение как джобы:
- API создаёт задачу и возвращает управление быстро
- Worker’ы обрабатывают задачи через очередь (с ретраями и backoff)
- UI показывает статус задач и позволяет перезапускать при необходимости
Планируйте окружения и конфигурацию
Заведите dev/staging/prod рано. Храните ключи поставщиков, пороги и feature‑флаги в конфигурации (не в коде) и делайте простым переключение провайдеров по окружению.
Схема на одной странице
Нарисуйте простую диаграмму: UI → API → база данных, плюс очередь → воркеры → провайдеры обогащения. Используйте её на ревью, чтобы все согласовали зоны ответственности до реализации.
Быстрый прототип (опционально)
Если цель — проверить рабочие процессы и экраны, прежде чем вбухивать инженерные ресурсы, платформа для быстрого кодинга вроде Koder.ai может помочь быстро прототипировать ядро приложения: React‑UI для ревью/утверждений, Go API‑слой и хранение на PostgreSQL.
Это полезно для проверки модели задач (асинхронное обогащение с ретраями), истории аудита и ролей доступа; затем можно экспортировать исходники при готовности к продакшену.
Настройка хранилищ, очередей и вспомогательных сервисов
Прежде чем подключать провайдеров обогащения, настройте «трубы». Решения по хранению и фоновой обработке тяжело менять, и они напрямую влияют на надёжность, стоимость и аудитируемость.
Основная база данных: профили + история
Выберите основную БД для профилей клиентов, которая поддерживает структурированные данные и гибкие атрибуты. Postgres — частый выбор: хранит основные поля (имя, домен, отрасль) рядом с полями обогащения в JSON.
Не менее важно: хранить историю изменений. Вместо тихого перезаписывания значений фиксируйте, кто/что изменил поле, когда и почему (например, «vendor_refresh», «manual_approval»). Это упрощает утверждения и помогает при откатах.
Очередь: обогащение и ретраи
Обогащение по природе асинхронно: API‑поставщики лимитируют запросы, сеть падает, некоторые ответы медленные. Добавьте очередь задач для фоновой работы:
- Запросы на обогащение (одиночная запись и пакетные)
- Ретраи с backoff
- Плановые обновления (например, каждые 30/90 дней)
- Dead‑letter для задач, которые постоянно падают
Это держит UI отзывчивым и не даёт проблемам провайдеров ломать приложение.
Кэш: быстрые lookup’ы и отслеживание лимитов
Небольшой кэш (часто Redis) помогает частым запросам (например, «компания по домену») и отслеживанию лимитов провайдеров и окон охлаждения. Он также полезен для idempotency‑ключей, чтобы повторные импорты не запускали дублирующее обогащение.
Хранение файлов и правила хранения
Спланируйте объектное хранилище для CSV импортов/экспортов, отчетов об ошибках и файлов‑diff для проверок.
Задайте правила хранения: держите сырые полезные нагрузки провайдеров только столько, сколько нужно для отладки и аудитов, и очищайте логи по расписанию согласно политике соответствия.
Постройте пайплайны поглощения и нормализации
От схемы к интерфейсу
Превратите модель данных и контракты в рабочие CRUD-экраны и API для итераций.
Ваше приложение полезно ровно настолько, насколько качественные данные в него попадают. Поглощение — это место, где вы решаете, как информация входит в систему, а нормализация делает её достаточно согласованной для сопоставления, обогащения и отчётности.
Решите, как данные будут поступать
Большинству команд нужен микс точек входа:
- API‑эндпоинты для продукта или внутренних инструментов для отправки новых/обновлённых клиентов
- Вебхуки из CRM или биллинга для near‑real‑time изменений
- Плановые выгрузки (ночные синки) для систем без push
- Импорт CSV для бекфиллов и разовых загрузок
Что бы вы ни поддерживали, держите шаг «сырое поглощение» лёгким: примите данные, аутентифицируйте, залогируйте метаданные и поставьте в очередь для обработки.
Нормализуйте и стандартизируйте как можно раньше
Сделайте слой нормализации, который превращает грязные входы в единый внутренний формат:
- Имена: обрезать пробелы, по возможности разбивать полное имя, корректно обрабатывать регистр
- Телефоны: приводить к E.164 и явно хранить предположение о стране
- Адреса: стандартизировать поля (улица, населённый пункт, регион, почтовый индекс) и сохранять оригинальный текст
- Домены/емейлы: переводить в lowercase, убирать UTM‑параметры из URL, валидировать синтаксис
Валидация, карантин и идемпотентность
Определите обязательные поля для каждого типа записи и отклоняйте или отправляйте на карантин записи, которые не проходят проверки (например, отсутствие email/домена для сопоставления компаний). Карантинные элементы должны быть доступны и исправляемы в UI.
Добавьте идемпотентные ключи, чтобы предотвратить повторную обработку при ретраях (часто с вебхуками и ненадёжными сетями). Простой подход — хешировать (source_system, external_id, event_type, event_timestamp).
Отслеживайте происхождение по каждому полю
Храните provenance для каждой записи и, по возможности, для каждого поля: источник, время поглощения, версия трансформации. Это отвечает на вопросы типа «Почему изменился этот телефон?» или «Какой импорт дал это значение?»
Реализуйте сопоставление, удаление дубликатов и слияние
Правильное обогащение зависит от надёжного определения «кто есть кто». Ваше приложение должно иметь понятные правила сопоставления, предсказуемое поведение при слиянии и страховку, когда система не уверена.
Определите правила сопоставления (и пороги уверенности)
Начните с детерминистических идентификаторов:
- Точные ключи: email (нормализованный в lowercase), customer ID, налоговый/VAT ID или верифицированный домен
Затем добавьте вероятностное сопоставление для случаев без точных ключей:
- Фаззи‑совпадения: имя + домен компании, имя + местоположение, сходство телефонов
Назначьте оценку совпадения и задайте пороги, например:
- Автослияние только выше высокого порога
- Поставить на ручную проверку в «возможном» диапазоне
- Отклонять ниже нижнего порога
Планируйте логику дедупликации и слияний
Когда две записи представляют одного и того же клиента, решите, как выбираются поля:
- Приоритет полей: «верифицированный email важнее неверифицированного», «новая отметка побеждает», «CRM переопределяет обогащение для владельца контакта»
- Оценки доверия источников: ранжируйте источники (CRM, биллинг, провайдеры обогащения) для разрешения конфликтов
- Обработка конфликтов: сохранять оба значения, где возможно (например, несколько телефонов), или переносить проигравшее значение в историю
Журнал аудита и рабочий процесс проверки
Каждое слияние должно создавать событие аудита: кто/что инициировал слияние, до/после значения, когда, оценка совпадения и ID вовлечённых записей.
Для неоднозначных совпадений предоставьте экран проверки с рядом‑в‑ряд сравнением и вариантами «слияние / не сливать / запросить дополнительные данные».
Защита от массовых ошибочных слияний
Требуйте дополнительного подтверждения для пакетных слияний, ставьте лимиты на число слияний в задаче и поддерживайте режим «прогон без выполнения» (dry run).
Также добавьте путь для «отката» (undo) через историю аудита, чтобы ошибки не были необратимыми.
Интегрируйте API обогащения и обеспечьте надёжность
Обогащение — это момент встречи вашего приложения с внешним миром: несколько провайдеров, непоследовательные ответы и непредсказуемая доступность.
Рассматривайте каждого провайдера как подключаемый «коннектор», чтобы можно было добавлять, менять или отключать источники без изменений в остальном пайплайне.
Постройте коннекторы провайдеров (аутентификация, ретраи, маппинг ошибок)
Создайте отдельный коннектор для каждого поставщика с единым интерфейсом (например, enrichPerson(), enrichCompany()). Держите специфичную логику внутри коннектора:
- Аутентификация (API‑ключи, OAuth‑токены, обновление токенов)
- Стандартизованные ретраи для временных ошибок
- Маппинг ошибок (перевод ошибок провайдера в ваши категории:
invalid_request,not_found,rate_limited,provider_down)
Это упрощает обработку ошибок ниже по стеку: они работают с вашими типами ошибок, а не со множеством вариаций каждого провайдера.
Управление лимитами: троттлинг и backoff
Большинство API имеют квоты. Добавьте троттлинг на уровне провайдера (и иногда на уровне эндпоинта), чтобы держать запросы в рамках лимитов.
При достижении лимита используйте экспоненциальный backoff с джиттером и уважайте заголовки Retry‑After.
Планируйте также «медленный отказ»: таймауты и частичные ответы должны считаться ретрай‑событиями, а не тихим пропаданием данных.
Храните уверенность и доказательства (в рамках правил)
Результаты обогащения редко абсолютны. Сохраняйте оценки уверенности от провайдера, когда они есть, и собственную оценку на основе качества совпадения и полноты полей.
Там, где это разрешено контрактом и политикой приватности, храните сырые доказательства (URL источников, идентификаторы, временные метки) для аудита и доверия пользователей.
Стратегия нескольких провайдеров: выбор «лучшего доступного» результата
Поддерживайте несколько провайдеров, задав правила выбора: сначала самый дешёвый, сначала с наибольшей уверенностью или поле‑по‑полю «лучшее доступное».
Записывайте, какой провайдер дал каждое поле, чтобы можно было объяснить изменения и откатить их при необходимости.
Правила плановой переобработки
Обогащение стареет. Внедрите политики обновления: «переобогащать каждые 90 дней», «обновлять при изменении ключевого поля» или «обновлять только если упала уверенность».
Делайте расписания настраиваемыми по клиенту и по типу данных, чтобы контролировать затраты и шум.
Добавьте правила качества данных и валидацию
Выпустите чистый пайплайн
Проектируйте потоки приёма, нормализации и валидации в одном проекте и развивайте их шаг за шагом.
Обогащение полезно только если новые значения заслуживают доверия. Рассматривайте валидацию как фичу: она защищает пользователей от проблем при импортах, ненадёжных сторонних ответов и случайных повреждений при слияниях.
Определите правила валидации на уровне поля
Начните с простого каталога правил по полю, общего для UI‑форм, пайплайнов поглощения и публичных API.
Обычные правила: проверки формата (email, телефон, почтовый индекс), допустимые значения (коды стран, списки отраслей), диапазоны (количество сотрудников, диапазоны выручки) и зависимости (если country = US, тогда state обязателен).
Ведите версии правил, чтобы безопасно их менять со временем.
Добавьте проверки качества, отражающие бизнес‑использование
Кроме базовой валидации, запускайте проверки качества, которые отвечают на практические вопросы:
- Полнота: есть ли минимальный набор полей для использования записи?
- Уникальность: не дублируются ли «уникальные» идентификаторы (домен, налоговый ID)?
- Согласованность: согласуются ли родственные поля (страна vs префикс телефона)?
- Актуальность: насколько старо значение и нужно ли его обновить?
Оценивайте записи и источники
Превратите проверки в скоринг: по записи (общая «здоровье» записи) и по источнику (как часто он даёт валидные, актуальные значения).
Используйте этот скор для автоматизации — например, применять обогащения автоматически только выше порога.
Предсказуемая маршрутизация при ошибках
Когда запись не проходит валидацию, не теряйте её.
Отправляйте в «очередь качества данных» для ретраев (при временных проблемах) или на ручную проверку (плохой ввод). Храните полезную нагрузку, правила нарушения и предложенные исправления.
Делайте ошибки понятными
Возвращайте ясные, практичные сообщения для импортов и клиентов API: какое поле упало, почему и пример валидного значения.
Это сокращает нагрузку саппорта и ускоряет очистку данных.
Создайте UI для ревью, утверждений и пакетной работы
Пайплайн обогащения полезен только тогда, когда люди могут увидеть, что изменилось, и с уверенностью применить обновления в системах‑потребителях.
UI должен отвечать на вопрос «что случилось, почему и что мне с этим делать?» очевидно.
Основные экраны
Профиль клиента — это центральная точка. Показывайте ключевые идентификаторы (email, домен, название компании), текущие значения полей и бейдж состояния обогащения (например: Not enriched, In progress, Needs review, Approved, Rejected).
Добавьте таймлайн истории изменений, который описывает обновления простым языком: «Размер компании обновлён с 11–50 до 51–200». Каждая запись должна быть кликабельной для детализации.
Показывайте предложения на слияние при детекции дубликатов. Выводите два (или более) кандидата рядом с рекомендуемым «выжившим» и превью результата слияния.
Пакетная работа, соответствующая реальным операциям
Большая часть работы выполняется пачками. Включите пакетные действия:
- Обогащать выбранные записи (или ставить в очередь на ночную обработку)
- Утверждать/отклонять предложенные слияния
- Экспортировать результаты (CSV) для аудита или офлайн‑проверки
Делайте явный шаг подтверждения для деструктивных действий (слияние, перезапись) и показывайте окно для отката, если возможно.
Быстрый поиск, фильтры и происхождение на уровне поля
Добавьте глобальный поиск и фильтры по email, домену, компании, статусу и скору качества.
Пусть пользователи сохраняют представления вроде «Needs review» или «Low confidence updates».
Для каждого обогащённого поля показывайте происхождение: источник, временная метка и уверенность.
Панель «Почему это значение?» повышает доверие и снижает количество запросов.
Направляющие рабочие процессы для нетехнических пользователей
Сделайте решения бинарными и направленными: «Принять предложенное значение», «Оставить текущее» или «Редактировать вручную». Если нужен более глубокий контроль — спрячьте его за «Advanced».
Безопасность, приватность и соответствие требованиям
Компенсируйте расходы на разработку
Получайте кредиты, делясь тем, что вы создали с Koder.ai, или приглашая коллег.
Приложения обогащения затрагивают чувствительные идентификаторы (email, телефоны, данные компаний) и часто тянут данные из сторонних источников. Рассматривайте безопасность и приватность как основные функции, а не как «потом».
Ролевой доступ (RBAC)
Начните с чётких ролей и принципа наименьших привилегий:
- Admin: управление пользователями, ролями, коннекторами, политиками хранения
- Ops: запуск задач обогащения, решение конфликтов, утверждение слияний
- Viewer: только чтение для отчётности и поддержки
Делайте права детализированными (например, «экспорт данных», «просмотр PII», «утвердить слияния») и отделяйте окружения, чтобы продовые данные не были в dev.
Защита чувствительных данных
Используйте TLS для всего трафика и шифрование на хранении для баз и объектного хранилища.
Ключи API храните в менеджере секретов (не в env‑файлах в репозитории), регулярно ротируйте и ограничивайте область применения ключей по окружению.
Если показываете PII в UI — задайте безопасные дефолты: маска полей (например, показать последние 2–4 цифры) и требование явного разрешения для раскрытия полных значений.
Согласие и ограничения использования данных
Если обогащение зависит от согласия или контрактов, закодируйте эти ограничения в рабочем процессе:
- Отслеживайте источник данных, цель и разрешённые использования по полю
- Документируйте, что вы храните и зачем (короткая внутренняя страница вроде /privacy или /docs/data-handling помогает)
- Не собирайте поля, которые вам не нужны — меньше данных = меньше рисков
Аудит, хранение и удаление
Создайте журнал аудита для доступа и изменений:
- Логируйте кто просматривал/экспортировал записи
- Логируйте кто изменил что и когда (до/после значения, ID задачи, провайдер)
Поддерживайте запросы о приватности: политики хранения, удаление записей и процессы «забыть» с очисткой копий в логах, кэше и бэкапах там, где возможно (или помечайте для истечения).
Мониторинг, аналитика и операционные интерфейсы
Мониторинг — это не только про аптайм; это способ следить за доверием к обогащению по мере роста объёмов, смены провайдеров и правил.
Рассматривайте каждый прогон обогащения как измеримую задачу с сигналами, по которым можно строить тренды.
Метрики, которые действительно помогают
Начните с небольшого набора операционных метрик, связанных с результатами:
- Пропускная способность задач (записей/мин) и время выполнения на прогон
- Процент успешных vs ошибочных, разбитый по типам ошибок (валидация, матчинг, провайдер)
- Латентность провайдеров (p50/p95) и таймауты по источникам
- Процент совпадений (как часто вы уверенно прикрепляете обогащение)
- Предотвращённые дубликаты (сколько слияний бы произошло без защит)
Эти метрики быстро отвечают на вопрос: «Улучшаем ли мы данные, или просто их двигаем?»
Триггеры и ограничители
Добавьте алерты, которые реагируют на изменения, а не на шум:
- Всплески ошибок или карантинных записей
- Застои в очередях или медленные потребители (сигнал о застрявшем пайплайне)
- Всплески ошибок провайдеров (429/5xx), рост латентности или таймаутов
Привяжите аlerты к действиям: приостановить провайдера, снизить конкурентность или переключиться на кэш/устаревшие данные.
Админ‑дашборд для операторов
Дайте оператору обзор недавних прогонов: статус, счётчики, ретраи и список карантинных записей с причинами.
Включите контролы «повтора» и безопасные пакетные действия (retry всех таймаутов провайдера, перезапуск только matching’а).
Трассировка с логами
Используйте структурированные логи и correlation ID, который проходит с одной записи по всей цепочке (ingest → match → enrich → merge).
Это значительно ускоряет поддержку клиентов и отладку инцидентов.
План действий при инциденте и откат
Опишите краткие плейбуки: что делать при деградации провайдера, падении процента совпадений или пробое дубликатов.
Должен быть вариант отката (например, отмена слияний за определённый временной промежуток) и документация на /runbooks.
Тестирование, деплой и план итераций
Тестирование и выкатывание — это то, где приложение обогащения становится безопасным для доверия. Цель — не «больше тестов», а уверенность, что сопоставления, слияния и валидации предсказуемы при реальных грязных данных.
Тестируйте наиболее рискованные части в первую очередь
Сосредоточьтесь на логике, которая может незаметно повредить записи:
- Правила сопоставления: unit‑тесты для точных, фраззи и комбинированных совпадений (например, email + домен). Включите почти‑дубликаты и переставленные поля.
- Результаты слияний: тесты приоритетов полей (приоритет источников), обработка конфликтов и правила «не перезаписывать».
- Пограничные случаи валидации: некорректные email, международные форматы телефонов, отсутствие страны, дублирующиеся идентификаторы и «неизвестные» значения.
Используйте синтетические наборы данных (генерированные имена, домены, адреса) для проверки точности без использования реальных клиентских данных.
Храните версионированный «golden set» с ожидаемыми выходами для очевидных регрессий.
Пошаговый rollout, чтобы уменьшить масштаб проблем
Начинайте с малого и расширяйтесь:
- Пилот: одна команда или сегмент (например, только SMB‑лиды)
- Ограниченные действия: сначала «предложенные обновления», требующие подтверждения перед записью в CRM
- Рамп‑ап: увеличьте объём записей, затем включите автоматические записи для низкорисковых полей
Определите метрики успеха заранее (точность совпадений, процент утверждений, снижение ручных правок и время обогащения).
Документируйте рабочие процессы и чек‑лист интеграции
Создайте короткие руководства для пользователей и интеграторов (ссылку разместите в продуктовой зоне или /pricing, если фича платная). Включите чек‑лист интеграции:
- Метод аутентификации API, лимиты и поведение при ретраях
- Обязательные поля для запросов обогащения
- Вебхук/структура событий (и версионирование)
- Коды ошибок и правила «частичного обогащения»
- Ожидания по журналам и хранению
Для непрерывного улучшения заведите лёгкий цикл обзоров: анализируйте провалившиеся валидации, частые ручные переопределения и рассогласования, потом обновляйте правила и добавляйте тесты.
Практическая ссылка для ужесточения правил: /blog/data-quality-checklist.
Строить или ускорять: практическая заметка
Если вы уже знаете рабочие процессы, но хотите сократить время от спецификации до рабочего приложения, рассмотрите использование Koder.ai для генерации начальной реализации (React UI, Go‑сервисы, PostgreSQL).
Команды часто используют такой подход чтобы быстро поднять UI для ревью, обработку задач и историю аудита — затем итеративно дорабатывать. При необходимости можно экспортировать исходники и продолжить развитие в существующем пайплайне. Koder.ai предлагает тарифы free, pro, business и enterprise, что помогает балансировать экспериментирование и продакшен‑требования.