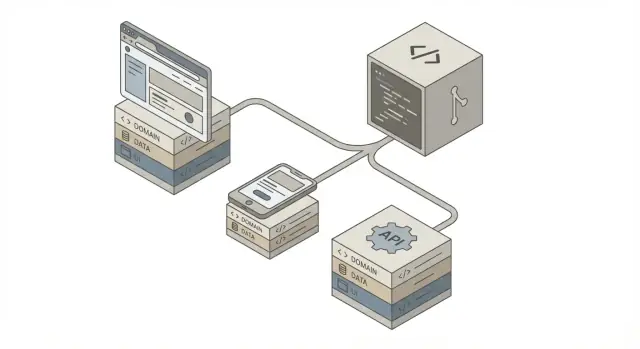
Что значит одна ИИ‑сгенерированная кодовая база
«Одна кодовая база» редко означает один UI, который запускается везде. На практике это обычно значит один репозиторий и единый набор правил — с отдельными «поверхностями доставки» (веб‑приложение, мобильное приложение, API), которые все опираются на одни и те же бизнес‑решения.
Общая логика vs. общий UI
Полезная модель мышления — это разделять то, что никогда не должно расходиться:
- Доменные правила: вычисления, проверки права, ценообразование, рабочие процессы, инварианты.
- Use cases: «создать заказ», «отменить подписку», «оформить возврат» и т. п.
- Контракты данных: формы запросов/ответов, правила валидации, коды ошибок.
Между тем, обычно вы не делите UI целиком. У веба и мобильных приложений разные паттерны навигации, ожидания по доступности, ограничения по производительности и возможности платформ. Совместное использование UI может быть выигрышным в некоторых случаях, но это не определение «одной кодовой базы».
Что меняет ИИ (и что остаётся прежним)
ИИ‑сгенерированный код может сильно ускорить:
- создание каркасов проектов (папки, скрипты сборки, базовые компоненты)
- генерацию CRUD‑эндпойнтов и клиентов
- создание тестов и фикстур по примерам
Но ИИ не гарантирует цельную архитектуру. Без чётких границ он склонен дублировать логику между приложениями, смешивать ответственности (UI напрямую обращается к коду БД) и создавать «почти одинаковые» валидации в нескольких местах. Выигрыш приходит от предварительного определения структуры — затем используйте ИИ, чтобы заполнить повторяющиеся части.
Желаемые результаты
Одна ИИ‑помогаемая кодовая база успешна, когда она обеспечивает:
- Согласованность: веб, мобильные и API применяют одинаковые правила.
- Скорость: новые фичи пишутся один раз и затем отображаются везде.
- Поддерживаемость: изменения локализуются, проходят ревью, тестируются и выпускаются предсказуемо.
Цели и ограничения для доставки на веб, мобильные и через API
Единая кодовая база работает только если вы понимаете, чего она должна добиваться — и чего не следует стандартизировать. Веб, мобильные и API обслуживают разные аудитории и паттерны использования, даже если они разделяют одни и те же бизнес‑правила.
Кому вы служите (и как)
Большинство продуктов имеют как минимум три «входные двери»:
- Пользователи веб‑приложения (клиенты, админы, служба поддержки), которые ожидают быстрой навигации, доступности и простых обновлений.
- Мобильные пользователи, которые ожидают нативного поведения, поддержки периодического подключения и экономного использования батареи/сети.
- Сторонние интеграции (партнёры, внутренние системы, инструменты автоматизации), которые зависят от стабильных API, ясных контрактов и предсказуемой обработки ошибок.
Цель — согласованность в поведении (правила, разрешения, вычисления), а не идентичный UX.
Нон‑цели: не заставляйте одинаковый UX
Распространённая ошибка — воспринимать «одна кодовая база» как «один UI». Это обычно порождает веб‑подобное мобильное приложение или мобильное‑подобный веб — оба варианта раздражают.
Вместо этого стремитесь к:
- Общей доменной логике и валидации
- Общим моделям данных и контрактам API
- Платформо‑специфическому presentation и interaction design
Ключевые ограничения, которые важно заложить рано
Офлайн‑режим: мобильные приложения часто требуют чтения (а иногда и записи) без сети. Это подразумевает локальное хранилище, стратегии синхронизации, обработку конфликтов и чёткие правила «источника правды».
Производительность: веб волнует размер бандла и time‑to‑interactive; мобильные — время старта и эффективность сети; API — задержки и пропускная способность. Совместный код не должен означать отправку ненужных модулей каждому клиенту.
Безопасность и соответствие требованиям: аутентификация, авторизация, аудиторские треки, шифрование и хранение данных должны быть последовательны на всех поверхностях. Если вы работаете в регулируемых областях, заложите требования (логирование, согласие, принцип наименьших прав) с самого начала — не как латание дыр.
Эталонная архитектура: слои и ответственности
Единая кодовая база лучше работает, когда организована в чёткие слои с жёсткими обязанностями. Такая структура облегчает проверку, тестирование и замену ИИ‑сгенерированного кода без нарушения несвязанных частей.
Высокоуровневый поток
Вот базовая форма, к которой сходятся большинство команд:
Clients (Web / Mobile / Partners)
↓
API Layer
↓
Domain Layer
↓
Data Sources (DB / Cache / External APIs)
Ключевая идея: пользовательские интерфейсы и транспортные детали находятся на краях, а бизнес‑правила — в центре.
Что стоит разделять
«Делящийся ядро» — это всё, что должно вести себя одинаково везде:
- Домен (бизнес‑логика): правила ценообразования, проверки прав, переходы состояний заказов и т. п.
- Валидация: правила ввода и сообщения об ошибках, сопоставленные с едиными кодами ошибок.
- Сети + схемы: типы запросов/ответов, сериализация и контрактные тесты.
Когда ИИ генерирует новые фичи, лучший результат — это обновить доменные правила один раз, и все клиенты автоматически получают обновление.
Что должно оставаться разным
Некоторый код дорого или рискованно принуждать к общей абстракции:
- UI‑компоненты: веб‑дизайн‑системы против нативных контролов.
- Навигация и пользовательские потоки: маршрутизация браузера против стеков мобильной навигации.
- Возможности устройства: push‑уведомления, биометрия, камера, офлайн‑хранилище.
Практическое правило: если пользователь это видит или ОС может это сломать, держите это специфичным для приложения. Если это бизнес‑решение — держите в домене.
Ответственности по слоям
- API‑слой: аутентификация, rate limiting, маппинг HTTP/GraphQL в доменные команды.
- Доменный слой: чистые правила и use cases, минимум зависимостей.
- Источники данных: базы данных и внешние сервисы за интерфейсами, чтобы реализации можно было менять без переписывания бизнес‑логики.
Общий доменный слой (бизнес‑логика)
Общий доменный слой должен быть «скучным» в лучшем смысле слова: предсказуемым, тестируемым и переиспользуемым везде. Если ИИ помогает строить систему, именно этот слой задаёт смысл проекта — веб‑экраны, мобильные потоки и эндпойнты API отражают одни и те же правила.
Начните с существительных и глаголов
Определите ключевые концепции продукта как сущности (вещи с идентичностью во времени, например Account, Order, Subscription) и value objects (вещи, определяемые своим значением, например Money, EmailAddress, DateRange). Затем выразите поведение как use cases (иногда их называют application services): «Create order», «Cancel subscription», «Change email».
Такая структура делает домен понятным для неспециалистов: существительные описывают, что есть, глаголы — что система делает.
Держите бизнес‑правила независимыми от UI
Доменная логика не должна знать, была ли она вызвана нажатием кнопки, отправкой формы на вебе или API‑запросом. На практике это значит:
- Никаких импортов фреймворков (нет веб‑контроллеров, мобильных view или аннотаций ORM в доменном коде)
- Никаких строк UI (лучше коды ошибок или ключи, чем хардкодные сообщения)
- Никаких сетевых предположений (домен не должен «звонить в API», он должен выражать правила)
Когда ИИ генерирует код, это разделение легко потерять — модели заполняются деталями UI. Рассматривайте это как триггер для рефактора, а не как норму.
Одна валидация для всех
Валидация — место, где продукты часто расходятся: веб позволяет то, что API отклоняет, или мобильная валидация отличается. Положите согласованную валидацию в доменный слой (или общий модуль валидации), чтобы все поверхности применяли одни и те же правила.
Примеры:
EmailAddress проверяет формат один раз и переиспользуется на вебе/мобиле/APIMoney не допускает отрицательных итогов вне зависимости от источника- Use cases налагают межполевая валидация (например, «дата окончания должна быть позже даты начала»)
Если вы это сделаете хорошо, API‑слой станет транслятором, а веб/мобайл — представителями, в то время как домен остаётся единственным источником правды.
API‑слой: контракты, которые задают всё остальное
Планируйте архитектуру в чате
Определите границы, контракты и сценарии использования до кода, чтобы вывод ИИ оставался согласованным.
API‑слой — это «публичное лицо» вашей системы — и в единой ИИ‑помогаемой кодовой базе он должен быть тем, что увязывает всё остальное. Если контракт ясен, веб‑приложение, мобильное приложение и внутренние сервисы можно генерировать и проверять по одному источнику правды.
Начните с API‑контракта
Определите контракт до генерации хэндлеров или привязки UI:
- Эндпойнты и ресурсы: согласованные существительные (например,
/users, /orders/{id}), предсказуемая фильтрация и сортировка.
- Ошибки: стабильная форма ошибки (code, message, details) с документированным использованием HTTP‑статусов.
- Пагинация: выберите подход (курсорная часто легче для эволюции) и стандартизируйте поля ответа.
- Версионирование: решите рано (путь
/v1/... или через заголовки) и задокументируйте правила депрекации.
Генерируйте типы и клиенты из одной схемы
Используйте OpenAPI (или схему вроде GraphQL SDL) как канонический артефакт. Из него генерируйте:
- серверные заготовки (маршруты, каркас валидации)
- типизированные клиенты для веба и мобильных приложений
- общие модели запросов/ответов, которые уменьшают дрейф
Это важно для ИИ‑генерируемого кода: модель может быстро создавать много кода, но схема удерживает его в рамках.
Правила согласованности, которые предотвращают тонкие поломки
Установите несколько безкомпромиссных правил:
- Именование:
snake_case или camelCase, но не оба; совпадение между JSON и сгенерированными типами.
- Коды статусов: 200/201/204 для успеха, 400 для валидации, 401/403 для auth, 409 для конфликтов.
- Идемпотентность: требуйте
Idempotency‑Key для рискованных операций (платежи, создание заказа) и определяйте поведение при повторных запросах.
Относитесь к API‑контракту как к продукту. Когда он стабилен, остальное проще генерировать, тестировать и выпускать.
Веб‑приложение: интеграция общей логики без жёсткой связки
Веб‑приложение выигрывает от общей бизнес‑логики и страдает, когда эта логика перепутана с UI‑вопросами. Ключ — считать общий домен «безголовым» движком: он знает правила, валидации и рабочие процессы, но ничего не знает о компонентах, роутинге или браузерных API.
Выбор рендеринга: SSR vs CSR (и почему это важно)
Если вы используете SSR (server‑side rendering), общий код должен быть безопасен для запуска на сервере: никаких прямых window, document или обращений к браузерному хранилищу. Это хорошая принудительная мера: браузерозависимое поведение держите в тонком адаптере веб‑слоя.
С CSR (client‑side rendering) свободы больше, но та же дисциплина окупается. В проектах только CSR часто «по‑случаю» импортируют UI‑код в доменные модули, потому что всё выполняется в браузере — до тех пор, пока вы не добавите SSR, edge‑рендеринг или тесты в Node.
Практическое правило: общие модули должны быть детерминированными и независимыми от окружения; всё, что трогает cookies, localStorage или URL, — в веб‑слое.
Границы состояния: доменное состояние vs UI‑состояние
Общая логика может предоставлять доменное состояние (например, итог заказа, права, вычисляемые флаги) через простые объекты и чистые функции. Веб‑приложение владеет UI‑состоянием: спиннерами загрузки, фокусом форм, оптимистичными анимациями, видимостью модалей.
Это позволяет менять библиотеки состояния React/Vue без переписывания бизнес‑правил.
Веб‑специфичные вопросы, которые следует изолировать
Веб‑слой должен обрабатывать:
- Доступность (семантическая разметка, навигация с клавиатуры, ARIA)
- Роутинг (структура URL, deep links, серверные редиректы)
- Браузерное хранилище (cookies/session,
localStorage, кеширование)
Думайте о веб‑приложении как об адаптере, который переводит взаимодействия пользователя в доменные команды и доменные результаты — в доступные экраны.
Мобильное приложение: общая логика с нативными возможностями
Мобильное приложение выигрывает от общего доменного слоя: правила ценообразования, права, валидация и рабочие процессы должны работать так же, как в вебе и API. Мобильный UI — это «оболочка» вокруг этой общей логики, оптимизированная под касания, периодическое подключение и возможности устройства.
Паттерны платформ, которые нужно предусмотреть
Даже с общей бизнес‑логикой у мобильных есть паттерны, которые редко мапятся 1:1 на веб:
- Навигация: моделируйте навигационное состояние в слое приложения (экраны, вкладки, модальные окна), при этом держите доменные решения (например, «пользователь должен подтвердить почту перед оплатой») в общем коде.
- Фоновые задачи: относитесь к синхронизации и загрузкам как к явным заданиям с лимитами времени и возможностью возобновления.
- Push‑уведомления: парсюйте payload в слое приложения, затем передавайте в общую логику для принятия решения о действии.
- Deep links: маршрутизируйте ссылки в слое приложения, но используйте общую логику для проверки прав доступа и загрузки данных.
Offline‑first: кэширование, синхронизация и стратегия конфликтов
Если вы ожидаете реального мобильного использования, предполагайте офлайн:
- Кэшируйте модели чтения локально (key‑value или SQLite) с ясной политикой устаревания.
- Помещайте записи для записи как намерения/события (например, «создать черновик заказа»), затем синхронизируйте при подключении.
- Задайте правила конфликтов заранее (last‑write‑wins, сервер‑авторитетное слияние или разрешение пользователем).
- Реализуйте ретраи с backoff и идемпотентные ключи, чтобы API мог безопасно принимать дубликаты.
Мобильные специфичные заботы
- Размер приложения: делайте общий слой модульным, чтобы отдавать приложению только нужное.
- Батарея/трафик: группируйте сетевые запросы и избегайте агрессивного опроса.
- Разрешения: запрашивайте только по необходимости (камера, геолокация, контакты) и держите проверки разрешений вне доменного кода, чтобы политики могли отличаться на платформах.
Модели данных, аутентификация и права доступа на всех поверхностях
Сначала сгенерируйте правильные слои
Используйте чат для создания каркаса React-веба, Go API и Flutter-мобильного приложения без смешения UI и доменной логики.
Единая кодовая база быстро разваливается, если веб, мобильное приложение и API придумывают свои формы данных и правила безопасности. Исправление — рассматривать модели, аутентификацию и авторизацию как общие продуктовые решения и кодировать их один раз.
Источник правды для моделей данных
Выберите одно место, где живут модели, и пусть всё остальное выводится из него. Распространённые варианты:
- Schema‑first: определяйте сущности и правила валидации в схемах (OpenAPI/JSON Schema), затем генерируйте типы для API, веба и мобильных.
- Общие модули: держите типы моделей и валидаторы в общем пакете (обычно пакет «domain»), который импортируют все приложения.
- Гибрид: схемы для внешних контрактов, общие модули — для внутренних доменных правил.
Ключ не в инструменте, а в согласованности. Если у OrderStatus пять значений в одном клиенте и шесть в другом, ИИ‑сгенерированный код с радостью скомпилируется и всё равно доставит баги.
Аутентификация: сессии, токены и безопасное хранение
Аутентификация должна ощущаться одинаково для пользователя, но механика отличается по поверхностям:
- Веб часто предпочитает cookie‑сессии (хорошая защита от CSRF, простое браузерное хранение).
- Мобильные и сторонние клиенты обычно нуждаются в токенах (access + refresh).
Спроектируйте единый поток: логин → короткоживущий access → обновление при необходимости → логаут, инвалидирующий серверное состояние. На мобильных устройствах храните секреты в защищённом хранилище (Keychain/Keystore), не в простых настройках. В вебе отдавайте предпочтение httpOnly cookie, чтобы токены не были доступны JS.
Авторизация: централизованные правила, применяемые на API
Права доступа должны быть определены один раз — желательно близко к бизнес‑правилам — затем применяться везде:
- Централизуйте проверки в домене (например,
canApproveInvoice(user, invoice)).
- Применяйте их на API для реальной безопасности.
- Отражайте их в UI лишь для скрытия/деактивации действий, а не для защиты данных.
Это предотвращает расхождения «работает на мобайле, но не на вебе» и даёт ИИ чёткие тестируемые контракты о том, кто что может делать.
Стратегия сборки, релизов и деплоя
Единая кодовая база остаётся единой только если сборки и релизы предсказуемы. Цель — позволить командам выпускать API, веб и мобильные приложения независимо, не форкая логику и не вводя «специальные случаи» для окружений.
Монорепозиторий vs мульти‑репо
Монорепо (один репозиторий, несколько пакетов/приложений) обычно лучше для единой кодовой базы, потому что общая доменная логика, контракты API и клиенты эволюционируют вместе. Вы получаете атомарные изменения (один PR обновляет контракт и всех потребителей) и проще рефакторить.
Мульти‑репо тоже может быть объединённым, но вы заплатите в плане координации: версионирование общих пакетов, публикация артефактов и синхронизация несовместимых изменений. Выбирайте мульти‑репо только если организационные границы, требования безопасности или масштаб делают монорепо непрактичным.
Цели сборки и артефакты
Рассматривайте каждую поверхность как отдельную сборочную цель, потребляющую общие пакеты:
- API‑артефакт: образ контейнера или сборка для serverless, собранная из пакета API.
- Веб‑бандл: статические ассеты + runtime SSR (если нужно) из пакета веб‑приложения.
- Мобильные сборки: Android (AAB/APK) и iOS (IPA), создаваемые нативными пайплайнами, но подтягивающие общий код.
Держите выходы сборки явными и воспроизводимыми (lockfiles, фиксированные toolchain‑ы, детерминированные сборки).
CI/CD и разделение окружений
Типичный пайплайн: lint → typecheck → unit tests → contract tests → build → security scan → deploy.
Отделяйте конфиг от кода: переменные окружения и секреты хранятся в CI/CD и менеджере секретов, а не в репозитории. Используйте оверлеи окружений (dev/stage/prod), чтобы один и тот же артефакт можно было продвигать между окружениями без пересборки — особенно для API и веб‑рантайма.
Тестирование и контроли качества для общего кода
Получите экспортируемый исходный код
Сохраняйте полный контроль с реальным исходным кодом, который можно просматривать, тестировать и переносить куда угодно.
Когда веб, мобильные и API выходят из одной кодовой базы, тестирование перестаёт быть «ещё одной галочкой» и становится механизмом, который не даёт маленькой правке сломать три продукта одновременно. Цель — обнаруживать проблемы там, где их дешевле исправлять, и блокировать рискованные изменения до попадания к пользователям.
Практическая тестовая пирамида для единой кодовой базы
Начинайте с общего домена (бизнес‑логики), потому что он наиболее переиспользуем и его проще тестировать без медленной инфраструктуры.
- Unit‑тесты (домен): проверяют правила вроде ценообразования, прав, переходов состояний и крайних случаев. Они должны запускаться быстро и составлять основу набора тестов.
- Интеграционные тесты (API‑слой): доказывают, что API работает end‑to‑end с реальной сериализацией, валидацией, аутентификацией и доступом к данным. Держите их сфокусированными на критичных сценариях, а не на каждой граничной ситуации.
- UI‑тесты (по клиенту): небольшое число проверок для веба и мобильных, подтверждающих ключевые пути (вход, checkout, отправка формы). Они медленнее, поэтому рассматривайте их как «дымовые сигнализации», а не как исчерпывающее доказательство.
Такая структура удерживает большую часть уверенности в общем коде, и при этом ловит ошибки интеграции между слоями.
Контрактное тестирование, чтобы держать клиентов и API в соответствии
Даже в монорепо легко изменить API так, что код скомпилируется, но UX сломается. Контрактные тесты предотвращают тихой дрейф.
- Контракты API→клиенты: фиксируют формы запросов/ответов, формат ошибок и коды статусов. Если API добавляет новое обязательное поле или меняет enum, контрактные тесты падают до слияния.
- Схема как шлюз: если вы публикуете OpenAPI/GraphQL схемы, рассматривайте изменения схемы как артефакты, требующие ревью. Ломающие изменения должны требовать явного одобрения и плана миграции.
Контролирующие ворота качества
Тесты важны, но важны и правила вокруг них.
- PR‑ворота: требуйте прохождения unit + integration тестов, lint/format и минимального покрытия для домена.
- Фичер‑флаги: деплойте код безопасно, скрывая незавершённое поведение за флагами, управляемыми по окружению или группе пользователей.
- Пошаговые релизы: сначала внутренним пользователям, затем небольшой части production‑трафика, затем всем.
- План отката: делайте откат первоклассной возможностью — версионированные релизы, обратимые миграции (или безопасное продвижение вперёд) и чёткие критерии «остановить конвейер».
С такими воротами ИИ‑помогаемые изменения могут быть частыми, не становясь хрупкими.
Как использовать ИИ, не потеряв контроль над архитектурой
ИИ может ускорить единую кодовую базу, но лишь если вы относитесь к нему как к быстрому младшему инженеру: он отлично делает черновики, но небезопасен для прямого мерджа. Цель — использовать ИИ для скорости, а людям оставить ответственность за архитектуру, контракты и долгосрочную когерентность.
Где ИИ помогает больше всего (и где риск низок)
Используйте ИИ для генерации «первых версий», которые вы бы писали рутинно:
- Скелеты проектов (папки, boilerplate модули, каркасы фич)
- Документация API и примеры по существующим контрактам
- Наборы тестов (unit‑тесты домена, контрактные тесты для эндпойнтов)
- Миграции и скрипты seed‑данных
- Повторяющиеся рефакторы (переименования полей, разделение модулей) — после того как вы определили план
Хорошее правило: пусть ИИ генерирует код, который легко верифицировать чтением или прогоном тестов, а не код, который молча меняет смысл бизнеса.
Ограждения, которые защищают архитектуру
Выход ИИ должен быть ограничен явными правилами, а не интуицией. Поместите эти правила туда, где код живёт:
- Стандарты кодирования: линтеры/форматтеры, правила именования и запрет прямого доступа к БД из UI.
- Архитектурные правила: границы зависимостей (например, домен не может импортировать API/web/mobile), которые можно принудить инструментами или простыми сборочными проверками.
- Чек‑лист PR: «Контракт изменился? Обновите OpenAPI + клиентские типы + тесты.» «Новоe доменное правило? Добавьте unit‑тесты домена.»
Если ИИ предлагает обход, нарушающий границы, ответ — «нет», даже если это компилируется.
Управление: делайте работу ИИ аудируемой
Риск — это не только плохой код, но и непрозрачные решения. Ведите аудиторский след:
- Сохраняйте ключевые подсказки и ответы ИИ рядом с задачами (ID тикетов, ссылки на PR).
- Фиксируйте архитектурные решения (ADR) для изменений контракта, модели авторизации или новых доменных понятий.
- Требуйте, чтобы изменения API были явными: версионированными, документированными и покрытыми контрактными тестами.
ИИ наиболее полезен, когда его результаты повторяемы: команда видит почему что‑то было сгенерировано, может это проверить и безопасно пересоздать при изменении требований.
Примечание по инструментам: ИИ, который уважает границы
Если вы внедряете ИИ‑помощь на уровне системы (веб + API + мобайл), самая важная «фича» — не скорость генерации, а способность держать выходы в рамках ваших контрактов и слоёв.
Например, Koder.ai — это платформа типа vibe‑coding, которая помогает командам строить веб, сервер и мобильные приложения через чат‑интерфейс, при этом генерируя реальный, экспортируемый исходный код. На практике это удобно для описанного в статье рабочего процесса: вы определяете API‑контракт и доменные правила, затем быстро итеративно делаете React‑веб‑поверхности, Go + PostgreSQL бэкенды и Flutter‑мобайл‑приложения, не теряя возможности ревью, тестирования и принудительного соблюдения архитектурных границ. Фичи как planning mode, snapshots и rollback соотносятся с дисциплиной «generate → verify → promote» в единой кодовой базе.