Почему идеи Роя Филдинга по REST до сих пор важны
Рой Филдинг — не просто имя, приклеенное к API-термину. Он был одним из ключевых авторов спецификаций HTTP и URI и в своей докторской диссертации описал архитектурный стиль под названием REST (Representational State Transfer), чтобы объяснить, почему Веб работает так хорошо.
Это происхождение важно потому, что REST не был придуман ради «красивых эндпойнтов». Это способ описать ограничения, которые позволяют глобальной, хаотичной сети масштабироваться: много клиентов, много серверов, промежуточные звенья, кеширование, частичные отказы и постоянные изменения.
Что вы получите из этой статьи
Если вы когда-либо задумывались, почему два «REST API» кажутся совсем разными — или почему небольшое решение впоследствии превращается в проблемы с пагинацией, путаницу в кешировании или в ломание клиентов — этот материал поможет снизить такие сюрпризы.
Вы уйдёте с:
- ясностью при принятии решений при проектировании или оценке API
- лучшим словарём для обсуждения компромиссов с командой
- практическим ощущением того, какие идеи REST действительно важны в реальных проектах
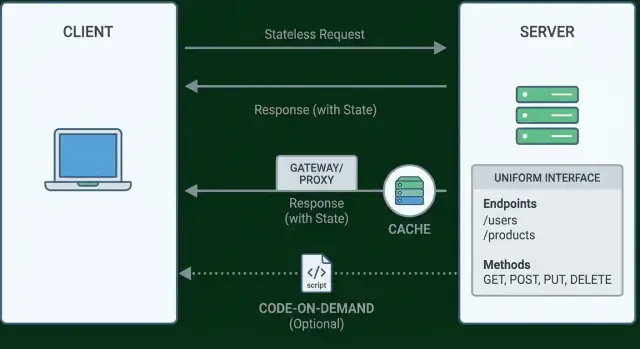
REST в одной странице: стиль, а не стандарт
REST — не чеклист, не протокол и не сертификат. Филдинг описал его как архитектурный стиль: набор ограничений, которые, применённые вместе, дают системы, масштабирующиеся как Веб — простые в использовании, способные эволюционировать и дружелюбные к промежуточным звеньям (прокси, кеши, шлюзы) без постоянной координации.
Проблема, которую решал REST
Раннему Вебу нужно было работать через множество организаций, серверов, сетей и типов клиентов. Он должен был расти без централизованного контроля, переживать частичные отказы и позволять появляться новым фичам без ломки старых. REST решает это, отдавая приоритет небольшому набору широко разделяемых концептов (идентификаторы, представления, стандартные операции) вместо кастомных, жёстко связанных контрактов.
«Архитектурные ограничения» простыми словами
Ограничение — это правило, которое ограничивает свободу проектирования в обмен на преимущества. Например, вы можете отказаться от серверных сессий, чтобы любой узел мог обработать запрос — это повышает надёжность и масштабируемость. Каждое ограничение REST делает похожий обмен: меньше произвольной гибкости, больше предсказуемости и способности к эволюции.
REST vs «похожий на REST» API
Многие HTTP API заимствуют идеи REST (JSON по HTTP, URL-эндпойнты, возможно коды статусов), но не применяют полный набор ограничений. Это не «неправильно» — часто это отражает сроки продукта или внутренние нужды. Полезно различать: API может быть ресурсно-ориентированным, не будучи полностью REST.
Короткая ментальная модель
Думайте о REST-системе как о ресурсах (вещи, которые можно назвать URL) и клиентах, взаимодействующих с ними через представления (текущее представление ресурса — JSON, HTML), ориентируясь по ссылкам (следующие действия и связанные ресурсы). Клиенту не нужны секретные внеполосные правила; он следует стандартной семантике и перемещается по ссылкам, как браузер по Вебу.
Ресурсы и представления: базовый словарь
Прежде чем заблудиться в ограничениях и HTTP-деталях, REST начинается с простого сдвига в мышлении: думайте о ресурсах, а не о действиях.
Ресурс = существительное, которое можно идентифицировать
Ресурс — это адресуемая «вещь» в вашей системе: пользователь, счёт, категория товаров, корзина. Важно, что это существительное с идентичностью.
Вот почему /users/123 читается естественно: он идентифицирует пользователя с ID 123. Сравните с URL, оформленными как действия: /getUser или /updateUserPassword. Они описывают глаголы — операции, а не предмет, над которым оперируют.
REST не говорит, что действия запрещены. Он говорит, что действия следует выражать через единый интерфейс (для HTTP-API это обычно методы GET/POST/PUT/PATCH/DELETE), действующие на идентификаторы ресурсов.
Представление = взгляд на ресурс
Представление — это то, что вы отправляете по сети как снимок ресурса в конкретный момент. Один и тот же ресурс может иметь несколько представлений.
Например, ресурс /users/123 может быть представлен JSON для приложения или HTML для браузера.
GET /users/123
Accept: application/json
Может вернуть:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
В то же время:
GET /users/123
Accept: text/html
Может вернуть HTML-страницу с теми же деталями пользователя.
Ключевая мысль: ресурс — это не JSON и не HTML. Это просто форматы для представления.
Почему такое мышление меняет дизайн API
Когда вы моделируете API вокруг ресурсов и представлений, несколько практических решений становятся проще:
- Именование остаётся стабильным.
/users/123 остаётся валидным даже если UI, рабочие процессы или модель данных эволюционируют.
- Эндпойнты становятся проще. Вместо создания нового URL для каждой операции вы переиспользуете URL ресурса и меняете метод или представление.
- Код клиента менее связан. Клиенты фокусируются на «получить пользователя» или «обновить поля пользователя», а не на запоминании каталога action-эндпойнтов.
Этот ресурсно-ориентированный подход — фундамент, на котором строятся ограничения REST. Без него «REST» часто распадается в «JSON по HTTP с приятными URL».
Ограничение 1: Разделение клиент–сервер
Разделение клиент–сервер — это способ REST навязать чистое разделение обязанностей. Клиент отвечает за пользовательский опыт (что люди видят и делают), сервер отвечает за данные, правила и персистентность (что верно и что разрешено). Когда вы держите эти заботы раздельно, каждая сторона может меняться без необходимости переписывать другую.
Что живёт на клиенте, а что на сервере?
В повседневных терминах клиент — это «слой представления»: экраны, навигация, локальная валидация для быстрого отклика и оптимистичный UI (показ нового комментария немедленно). Сервер — это «источник правды»: аутентификация, авторизация, бизнес-правила, хранение данных, аудит и всё, что должно быть согласованным между устройствами.
Практическое правило: если решение влияет на безопасность, деньги, права или согласованность общих данных — оно на сервере. Если решает только то, как выглядит опыт (расположение, локальные подсказки ввода, состояния загрузки) — оно на клиенте.
Почему это подходит для современных приложений
Ограничение напрямую ложится на распространённые архитектуры:
- SPA + API: веб-приложение (React/Vue и т. п.) быстро итератирует над UI, пока API продолжает обслуживать ресурсы.
- Мобильные приложения: iOS и Android клиенты могут разделять одни и те же серверные правила и эндпойнты.
- Партнёрские интеграции: партнёры потребляют те же серверные возможности без необходимости вашего UI.
Разделение client–server делает реалистичным сценарий «один бэкенд — много фронтов».
Частая ошибка: утечка состояния UI в сессии на сервере
Частая ошибка — хранить состояние рабочего процесса UI на сервере (например: «на каком шаге оформления заказа находится пользователь») в серверной сессии. Это связывает бэкенд с конкретным экранным потоком и усложняет масштабирование.
Предпочитайте отправлять необходимый контекст с каждым запросом (или выводить его из хранимых ресурсов), чтобы сервер был сосредоточен на ресурсах и правилах, а не на запоминании прогресса конкретного UI.
Ограничение 2: Без состояния (Stateless)
Без состояния означает, что сервер не обязан помнить ничего о клиенте между запросами. Каждый запрос несёт всю информацию, необходимую для его понимания и корректного ответа — кто вызывает, чего хочет и какой контекст нужен для обработки.
Почему это важно
Когда запросы независимы, вы можете добавлять или убирать серверы за балансировщиком нагрузки без заботы о «какой сервер знает мою сессию». Это улучшает масштабируемость и надёжность: любой экземпляр может обработать любой запрос.
Это также упрощает эксплуатацию. Отладка часто проще, потому что полный контекст виден в запросе (и логах), а не скрыт в памяти серверной сессии.
Компромиссы, которые вы почувствуете в реальных API
Stateless API обычно посылают чуть больше данных за вызов. Вместо опоры на сохранённую серверную сессию клиенты включают учётные данные и контекст каждый раз.
Также нужно явно обрабатывать «состояния» пользовательских потоков (пагинация, многошаговые оформления). REST не запрещает многошаговые сценарии — он просто переносит состояние на клиента или на серверные ресурсы с идентификаторами и возможностью получения.
Практические паттерны (и что они решают)
- Auth-токены (например, Bearer JWT): каждый запрос включает заголовок
Authorization: Bearer …, чтобы любой сервер мог аутентифицировать его.
- Idempotency-ключи: для операций вроде «создать платёж» клиенты посылают
Idempotency-Key, чтобы повторы не дублировали работу.
- Correlation IDs: заголовок вроде
X-Correlation-Id даёт возможность трассировать одно действие пользователя через сервисы и логи в распределённой системе.
Для пагинации избегайте «сервер помнит страницу 3». Предпочитайте явные параметры ?cursor=abc или ссылку next, которую клиент может просто пройти, сохраняя состояние навигации в ответах, а не в памяти сервера.
Ограничение 3: Кешируемые ответы
Приложение на Flutter для вашего API
Создайте приложение на Flutter, которое использует ваш API и обрабатывает пагинацию и повторы запросов.
Кеширование — это повторное использование предыдущего ответа безопасно, чтобы клиент (или что-то между клиентом и сервером) не запрашивал у вашего сервера ту же работу снова. При грамотном применении это снижает задержки для пользователей и уменьшает нагрузку на вас — не меняя смысла API.
Что означает «кешируемый» на практике
Ответ кешируем, когда безопасно, чтобы другой запрос получил ту же полезную нагрузку в течение некоторого времени. В HTTP вы сигнализируете об этом через заголовки кеширования:
Cache-Control: главный переключатель (на сколько хранить, можно ли в общих кешах и т. п.)ETag и Last-Modified: валидаторы, позволяющие клиентам спросить «изменилось ли это?» и получить дешёвый ответ «не изменилось»Expires: старый способ выразить свежесть, всё ещё встречается
Это шире чем «кеш браузера». Прокси, CDN, шлюзы API и мобильные приложения могут переиспользовать ответы, когда правила ясны.
Что обычно безопасно кешировать (а что нет)
Хорошие кандидаты:
- Публичные, одинаковые для всех данные (каталоги товаров, документация, флаги фич, не зависящие от пользователя)
- Только для чтения ресурсы, которые редко меняются (статическая конфигурация, справочные данные)
- GET-ответы, которые не зависят от cookies или авторизации
Обычно плохие кандидаты:
- Личные данные, привязанные к аккаунту (профили, заказы, сообщения)
- Ответы, связанные с авторизацией (обмен токенов, состояние сессии)
- Всё, что варьируется на пользователя, если вы явно не обрабатываете это (например, через
private правила)
Практические эффекты
- Быстрее страницы и отзывчивее приложения (меньше ожидания сети)
- Ниже серверные и базовые затраты (меньше повторных вычислений)
- Меньше инцидентов с лимитами (кешированные чтения снижают объём запросов)
Ключевая идея: кеширование — не побочный эффект. Это ограничение REST, которое вознаграждает API, ясно передающие свежесть и правила валидации.
Ограничение 4: Единый интерфейс (что это действительно значит)
Единый интерфейс часто путают с «используйте GET для чтения и POST для создания». Это лишь малая часть. Идея Филдинга шире: API должны быть достаточно последовательными, чтобы клиентам не требовалось знание каждого эндпойнта в отдельности.
Четыре части единого интерфейса
-
Идентификация ресурсов: вы называете вещи (ресурсы) стабильными идентификаторами (обычно URL), а не действиями. Думайте /orders/123, а не /createOrder.
-
Манипуляция через представления: клиенты изменяют ресурс, посылая представление (JSON, HTML и т. п.). Сервер управляет ресурсом; клиент обменивается его представлениями.
-
Самоописываемые сообщения: каждый запрос/ответ должен нести достаточно информации, чтобы понять, как его обработать — метод, код статуса, заголовки, медиатип и ясное тело. Если смысл спрятан в внешней документации, клиенты сильно связаны с сервером.
-
Гипермедиа (HATEOAS): ответы должны включать ссылки и допустимые действия, чтобы клиенты могли следовать рабочему процессу без жёстко закодированных шаблонов URL.
Почему это уменьшает связанность
Согласованный интерфейс делает клиентов менее зависимыми от внутренних деталей сервера. Со временем это означает меньше ломки, меньше «спецслучаев» и меньше переработок при эволюции команд и эндпойнтов.
Практические эвристики
- Используйте коды статуса последовательно: например
200 для успешного чтения, 201 для созданного ресурса (с Location), 400 для валидации, 401/403 для аутентификации/авторизации, 404 когда ресурс не найден.
- Стандартизируйте формат ошибок по всему API. Пример полей:
code, message, details, requestId.
- Держите медиатипы и заголовки значимыми (
Content-Type, заголовки кеширования), чтобы сообщения объясняли себя.
Единый интерфейс — про предсказуемость и способность к эволюции, а не про «правильные глаголы».
Самоописываемые сообщения: проектирование для понимания
Клиент на React с API
Создайте фронтенд на React, который обращается к REST-ресурсам предсказуемыми запросами.
«Самоописываемое» сообщение — это такое, которое подсказывает получателю, как его интерпретировать, без внеполосного tribal-knowledge. Если клиент (или промежуточный узел) не может понять, что означает ответ, глядя на HTTP-заголовки и тело, вы создали приватный протокол поверх HTTP.
Используйте медиатипы, чтобы объяснять полезную нагрузку
Самая простая победа — быть явным с Content-Type (что вы посылаете) и часто с Accept (что хотите получить). Ответ с Content-Type: application/json сообщает клиенту базовые правила парсинга, но можно пойти дальше с vendor- или profile-ориентированными медиатипами, когда смысл важен.
Подходы:
- Обычный медиатип + стабильные поля:
application/json с аккуратно поддерживаемой схемой. Самый простой вариант для большинства команд.
- Vendor-медиатипы:
application/vnd.acme.invoice+json для указания специфического представления.
- Профили: держите
application/json, добавьте параметр profile или ссылку на профиль, который определяет семантику.
Версионирование и совместимость (без ломки клиентов)
Версионирование должно защищать существующих клиентов. Популярные варианты:
- Версионирование в URL (
/v1/orders): очевидно, но может поощрять «форк» представлений вместо их эволюции.
- Версионирование в заголовках или медиатипе (через
Accept): держит URL стабильными и делает «что это значит» частью сообщения.
- Аддитивная эволюция: предпочитайте добавлять новые поля и сохранять старые; помечайте устаревшие постепенно.
Что бы вы ни выбрали, стремитесь к обратной совместимости по умолчанию: не переименовывайте поля легкомысленно, не меняйте смысл молча и относитесь к удалению как к ломаюшей изменению.
Согласованные ошибки и понятные имена
Клиенты учатся быстрее, когда ошибки везде выглядят одинаково. Выберите одну форму ошибки (например, code, message, details, traceId) и используйте её по всем эндпойнтам. Используйте понятные, предсказуемые имена полей (createdAt vs created_at) и придерживайтесь одного стиля.
Документация помогает — но ясность должна жить в сообщении
Хорошая документация ускоряет принятие, но она не может быть единственным местом смысла. Если клиент должен читать вики, чтобы понять, означает ли status: 2 «оплачено» или «в ожидании», сообщение не самоописываемое. Хорошие заголовки, медиатипы и читаемые полезные нагрузки уменьшают эту зависимость и делают системы легче для эволюции.
Гипермедиа (HATEOAS): самая пропускаемая идея REST
Гипермедиа (HATEOAS) означает, что клиенту не нужно заранее «знать» следующие URL API. Вместо этого каждый ответ включает обнаруживаемые следующие шаги как ссылки: куда идти дальше, какие действия возможны и иногда какой HTTP-метод использовать.
Как это выглядит на практике
Вместо жестко закодированных путей вроде /orders/{id}/cancel клиент следует ссылкам, которые даёт сервер. Сервер, по сути, говорит: «Учитывая текущее состояние этого ресурса, вот допустимые ходы.»
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
Если заказ потом станет paid, сервер может перестать включать cancel и добавить refund — без ломки корректно написанного клиента.
Когда гипермедиа особенно полезна
Гипермедиа особенно хороша, когда потоки эволюционируют: шаги онбординга, оформление заказа, утверждения, подписки или любые процессы, где «что разрешено дальше» меняется в зависимости от состояния, прав или бизнес-логики.
Она также уменьшает жёстко закодированные URL и хрупкие предположения клиента. Вы можете реорганизовать маршруты, ввести новые действия или пометить старые устаревшими, сохраняя клиентов работоспособными, если вы поддерживаете смысл отношений ссылок.
Почему команды пропускают это (и что теряют)
Команды часто пропускают HATEOAS, потому что он кажется дополнительной работой: нужно определить форматы ссылок, согласовать имена отношений и научить разработчиков клиентов следовать ссылкам вместо конструирования URL-ов.
Чего вы теряете — ключевое преимущество REST: слабую связанность. Без гипермедиа многие API становятся «RPC поверх HTTP» — они используют HTTP, но клиенты всё ещё зависят от внешней документации и фиксированных шаблонов URL.
Ограничение 5: Многослойная система
Многослойная система означает, что клиент не обязан знать (и часто не может определить), общается ли он с «настоящим» origin-сервером или с промежуточными звеньями. Эти слои могут включать API-шлюзы, обратные прокси, CDN, сервисы аутентификации, WAF и внутренние маршрутизации между микросервисами.
Зачем нужны слои
Слои создают чистые границы. Команды безопасности могут настраивать TLS, лимиты скорости, аутентификацию и валидацию запросов на краю сети, не меняя каждый бэкенд. Операционные команды могут масштабировать горизонтально за шлюзом, добавлять кеширование в CDN или перераспределять трафик во время инцидентов. Для клиентов это упрощение: одна стабильная точка входа, согласованные заголовки и предсказуемые форматы ошибок.
Компромиссы
Промежуточные звенья могут добавлять скрытую латентность (дополнительные прыжки, дополнительные рукопожатия) и усложнять отладку: баг может быть в правилах шлюза, в кеше CDN или в коде origin. Кеширование может запутать, когда различные слои кешируют по-разному или когда шлюз переписывает заголовки, влияющие на ключи кеша.
Практические советы
- Используйте end-to-end tracing ID: принимайте ID запроса (или генерируйте) и пропагируйте его через все хопы; включайте его в ответы и логи.
- Явно передавайте ошибки: стандартизируйте тело ошибок и чётко отображайте upstream-ошибки (не превращайте всё в универсальный 500).
- Устанавливайте таймауты на каждом хопе: таймауты шлюзов, апстрима и клиента должны быть согласованы, чтобы избежать «тайных» разрывов.
- Документируйте поведение кеширования: ясно укажите, какие ответы кешируются и какие заголовки промежуточные звенья должны сохранять.
Слои — сила, когда система остаётся наблюдаемой и предсказуемой.
Ограничение 6 (опционально): Отправка кода на клиент
Шаблон API без состояния
Генерируйте аутентификацию на основе токенов и шаблоны запросов, которые хорошо работают за балансировщиком нагрузки.
Отправка кода на клиент — единственное ограничение REST, которое явно опционально. Это означает, что сервер может расширять клиента, пересылая выполняемый код, который запускается на стороне клиента. Вместо того, чтобы заранее паковать всё поведение в клиент, клиент может скачивать новую логику по мере необходимости.
Пример из веба: JavaScript
Если вы когда-либо загружали страницу, которая потом становится интерактивной — валидация формы, отрисовка графика, фильтрация таблицы — вы уже использовали отправку кода. Сервер доставляет HTML и данные плюс JavaScript, который выполняется в браузере, чтобы обеспечить поведение.
Это одна из причин, почему веб может быстро эволюционировать: браузер остаётся универсальным клиентом, а сайты доставляют новую функциональность без установки полного приложения.
Почему это опционально (и почему многие API этого избегают)
REST прекрасно работает и без отправки кода, потому что остальные ограничения уже дают масштабируемость, простоту и совместимость. API может быть чисто ресурсно-ориентированным — возвращать представления вроде JSON — а клиенты реализуют своё поведение сами.
Многие современные Web API сознательно избегают отправки исполняемого кода, потому что это усложняет:
- Безопасность: исполняемый код увеличивает поверхность атаки (инъекции, проблемы цепочек поставок, вредоносные скрипты).
- Политики контента: браузеры налагают ограничения вроде CSP; организации могут блокировать inline-скрипты или неизвестные источники.
- Аудит и соответствие: сложнее доказать, какой код выполнился на клиенте в конкретный момент, особенно при динамической загрузке.
Когда отправка кода имеет смысл
Отправка кода полезна, когда вы контролируете среду клиента и нужно быстро выкатывать поведение UI, или когда хотите тонкий клиент, скачивающий «плагины» или правила с сервера. Но относитесь к этому как к дополнительному инструменту, а не как к требованию.
Главный вывод: вы можете полностью следовать REST без отправки кода — и многие боевые API так и делают, потому что это ограничение про опциональную расширяемость, а не про основу взаимодействия с ресурсами.
Применение REST сегодня: практические выборы и распространённые ошибки
Большинство команд не отказываются от REST — они принимают «REST-похожий» стиль, который держит HTTP как транспорт и при этом незаметно отбрасывает ключевые ограничения. Это нормально, если это сознательный компромисс, а не случайность, которая проявится позже в виде хрупких клиентов и дорогих переработок.
Распространённые REST-подобные сокращения (и почему они появляются)
Часто встречаются паттерны:
- RPC-эндпойнты:
/doThing, /runReport, /users/activate — просто назвать и подключить.
- URL, перегруженные глаголами:
/createOrder, /updateProfile, /deleteItem — HTTP-методы отходят на второй план.
- Скрытые сессии: «stateless» API, которые всё ещё полагаются на sticky-сессии, память сервера или неявное состояние рабочего процесса.
Эти решения кажутся эффективными на ранних этапах, потому что они отражают внутренние имена функций и операции.
Последствия, которые вы заметите позже
- Хрупкие клиенты: если клиенты зависят от конкретных форм эндпойнтов и ad-hoc поведения, небольшие рефакторы сервера станут ломать клиентов.
- Сложное версионирование: если URL кодируют поведение, вам придётся версионировать поведение вместо эволюции представлений.
- Промахи кеша (и большая задержка): использование POST для всего или игнорирование заголовков кеширования мешает промежуточным звеньям помогать.
- Проблемы масштабирования: скрытое серверное состояние осложняет горизонтальное масштабирование и восстановление после отказов.
Прагматический чек-лист соответствия REST
Используйте это как ревью «насколько мы действительно REST»:
- Называйте ресурсы, а не действия: предпочитайте
/orders/{id} вместо /createOrder.
- Используйте HTTP-методы осмысленно: GET для чтения, POST для создания, PUT/PATCH для обновлений, DELETE для удаления.
- Делайте запросы независимыми: никакой памяти сервера, необходимой для понимания шага клиента.
- Используйте кеширование там, где безопасно: задавайте
Cache-Control, ETag, Vary для GET-ответов.
- Стандартизируйте ошибки и медиатипы: согласованные коды статуса и формы ответов уменьшают спецслучаи.
Как это проявляется при реальной разработке
Ограничения REST — не только теория, это рельсы, которые вы чувствуете во время релиза. Когда вы быстро генерируете API (например, scaffold-ите React-фронтенд с бэкендом на Go + PostgreSQL), самая лёгкая ошибка — позволить «что быстрее подключить» диктовать интерфейс.
Если вы используете платформу для кодинга вроде Koder.ai, чтобы собрать веб‑приложение из чата, поможет вынести ограничения REST в раннюю часть обсуждения — сначала назвать ресурсы, оставаться stateless, определить единый формат ошибок и решить, где кеширование безопасно. Так быстрые итерации всё ещё дадут предсказуемые API, которые проще эволюционировать. (И поскольку Koder.ai поддерживает экспорт исходного кода, вы можете продолжать улучшать контракт API и реализацию по мере роста требований.)
Выводы для команд API и веб‑приложений
Определите ключевые ресурсы сначала, затем сознательно выбирайте ограничения: если вы отказываетесь от кеширования или гипермедиа, документируйте почему и чем заменяете. Цель не в чистоте — а в ясности: стабильные идентификаторы ресурсов, предсказуемая семантика и явные компромиссы, которые сохраняют клиентов устойчивыми по мере эволюции системы.