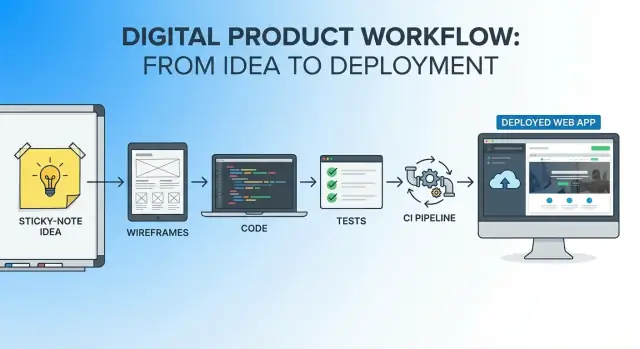
Цель: один непрерывный путь от идеи до живого приложения
Представьте простую полезную идею для приложения: «Queue Buddy», который позволяет сотруднику кафе нажать одну кнопку, чтобы добавить клиента в список ожидания и автоматически отправить ему SMS, когда столик готов. Метрика успеха простая и измеримая: снизить количество звонков из‑за путаницы во время ожидания в среднем на 50% за две недели, при этом обучаемость персонала не превышает 10 минут.
Это дух этой статьи: выберите ясную, ограниченную идею, определите, что значит «хорошо», и пройдите путь от концепта до живого деплоя, не переключая постоянно инструменты, документы и модель мышления.
Что значит «единый рабочий процесс»
Единый рабочий процесс — это одна непрерывная нить от первой строки идеи до первого релиза в продакшн:
- Одно место, где фиксируются решения (что мы строим и зачем)
- Один развивающийся набор артефактов (требования → экраны → задачи → код → тесты → заметки по деплою)
- Один цикл обратной связи (каждое изменение можно проследить до цели и метрики)
Вы всё ещё будете использовать несколько инструментов (редактор, репозиторий, CI, хостинг), но проект не будет «перезапускаться» на каждом этапе. Одна и та же история и ограничения идут дальше.
Роль ИИ: помощник, а не автопилот
ИИ особенно полезен, когда он:
- быстро генерирует варианты (формулировки требований, пользовательские потоки, формы API)
- создаёт стартовый код и тесты, которые вы можете просмотреть малыми порциями
- указывает на пограничные случаи, которые вы можете пропустить (валидация, права, логирование)
Но он не принимает продуктовые решения. Вы принимаете решения. Рабочий процесс устроен так, чтобы вы всегда проверяли: движет ли это метрику? Безопасно ли это выпускать?
Сквозной путь, который мы пройдём
В следующих разделах вы пройдёте шаг за шагом:
- Прояснить проблему, пользователей и «малую победу», которую можно выпустить.
- Превратить идею в лёгкий документ требований.
- Набросать пользовательское путешествие и ключевые экраны.
- Выбрать разумную архитектуру версии 1.
- Забутстрэпить скелет репозитория.
- Построить ключевые фичи тонкими, обозримыми срезами.
- Добавить базовые меры безопасности: валидация, права, логирование.
- Написать тесты, которые защищают happy path и рискованные части.
- Настроить сборки, CI и quality gates.
- Развернуть с понятным, обратимым процессом.
- Мониторить, учиться и итеративно улучшать — не теряя нити.
К концу у вас будет повторяемый способ перехода от «идеи» к «живому приложению», сохраняя объём, качество и обучение плотно связанными.
Начните с ясности: проблема, пользователи и малая победа
Прежде чем просить ИИ сгенерировать экраны, API или таблицы БД, нужно чёткое целевое представление. Немного ясности здесь сэкономит часы на правках «почти правильно» позже.
Однопараграфное описание проблемы
Вы строите приложение, потому что определённая группа людей регулярно сталкивается с одной и той же фрустрацией: они не могут быстро, надёжно или с уверенностью выполнить важную задачу существующими инструментами. Цель версии 1 — убрать один болезненный шаг в этом потоке, не пытаясь автоматизировать всё, — чтобы пользователи могли перейти от «надо сделать X» к «X сделано» за минуты, с понятной записью произошедшего.
Целевые пользователи и их топ‑3 задач
Выберите одного основного пользователя. Второстепенные можно отложить.
- Основной пользователь: занятые операторы/владельцы, которые управляют процессом целиком (не специалисты).
- Главные задачи:
- Быстро зафиксировать запрос (ввод) без потери ключевых деталей.
- Видеть статус одним взглядом и знать следующее действие.
- Поделиться результатом (подтверждение, сводка, экспорт), которому можно доверять.
Предположения (что должно быть правдой)
Хорошие идеи тихо терпят неудачу именно в предположениях — сделайте их явными.
- Пользователи готовы потратить немного времени на настройку ради повторяемого workflow.
- Необходимые данные существуют (или могут быть введены) с приемлемой точностью.
- Лёгкого аудита достаточно; полноценные функции соответствия не нужны для v1.
- «Помощь ИИ» ускоряет, но пользователи сохраняют окончательный контроль.
Критерии готовности для первого релиза
Версия 1 должна быть маленькой победой, которую можно выпустить.
- Пользователь завершает основной сценарий менее чем за 3 минуты.
- Данные валидируются и сохраняются, с базовыми правами и журналом действий.
- Есть один шарируемый результат (email, PDF или ссылка) и он консистентен.
- Вы можете развернуть, откатить и ответить на вопрос: «Это работает?»
Превратите идею в лёгкий документ требований
Лёгкий документ (страница) — мост между «крутой идеей» и «планом для разработки». Он помогает сохранять фокус, даёт контекст ИИ и не позволяет v1 разрастись до месячного проекта.
Черновой одностраничный PRD (важные части)
Держите документ коротким и удобочитаемым. Простой шаблон:
- Проблема: в одно предложение
- Целевые пользователи: кто испытывает боль чаще всего
- Объём (версия 1): что будем строить сейчас
- Non-goals: что явно не будем делать
- Ограничения: бюджет, сроки, технические ограничения, соответствие, устройства, источники данных
- Метрика успеха: как понять, что «сработало» (подойдёт простая прокси‑метрика)
Определите и ранжируйте 5–10 ключевых фич
Напишите 5–10 фич максимально, сформулированных как исходы. Затем ранжируйте:
- Must-have (без этого приложение не работает)
- Should-have (высокая ценность, но можно отложить)
- Nice-to-have (паркуем)
Это ранжирование поможет направлять планы и код, генерируемые ИИ: «Сначала реализуй только must‑have.»
Добавьте критерии приёмки для топ‑фич
Для 3–5 ключевых фич добавьте по 2–4 тестируемых критерия. Пишите простым языком.
Пример:
- Фича: Создать аккаунт
- Пользователь может зарегистрироваться по email и паролю
- Пароль должен быть не короче 12 символов
- После регистрации пользователь попадает на дашборд
- При дублировании email показывается понятная ошибка
Список открытых вопросов для быстрой валидации
Завершите коротким списком «Открытых вопросов» — вещей, которые можно закрыть одним чатом, звонком с клиентом или быстрым поиском.
Примеры: «Нужен ли вход через Google?» «Какие минимальные данные нужно сохранить?» «Нужна ли админская модерация?»
Этот документ не бюрократия; это общий источник правды, который вы будете обновлять по мере развития разработки.
Набросайте пользовательское путешествие и ключевые экраны
Прежде чем просить ИИ сгенерировать экраны или код, выстройте историю продукта. Быстрый набросок путешествия выравнивает ожидания: чего хочет пользователь, что считается успехом и где могут быть ошибки.
Смоделируйте основные потоки (happy path + ключевые пограничные случаи)
Начните с happy path: самая простая последовательность, которая даёт основную ценность.
Пример потока (обобщённый):
- Пользователь регистрируется / входит
- Создаёт новый Проект
- Добавляет Задачи
- Отмечает задачу как выполненную
- Видит прогресс / подтверждение
Добавьте несколько пограничных случаев, которые вероятны и дорогостоящи при ошибке:
- Пользователь бросает регистрацию (что происходит с частичными данными?)
- Пользователь теряет доступ (просроченная сессия, отозванное разрешение)
- Пустое состояние (проектов ещё нет)
- Неудачное сохранение (сбой сети) и поведение повторной попытки
Не нужен большой диаграмм; нумерованный список и примечания достаточно для прототипирования и генерации кода.
Перечислите ключевые экраны/страницы и их цели
Опишите кратко «работу, которую должен выполнить» каждый экран. Сосредоточьтесь на исходе, а не на UI.
- Логин / Регистрация: быстро попасть в приложение; ясно показывать ошибки; восстановление пароля
- Дашборд: показать текущие элементы и следующее действие; аккуратно обработать пустое состояние
- Детали проекта: показать информацию о проекте; позволить добавлять/редактировать задачи; показывать статус
- Редактор задачи (модал/страница): создать/обновить задачу; валидировать обязательные поля
- Настройки / Профиль: управлять профилем; выйти; при необходимости — удаление аккаунта
Если вы работаете с ИИ, этот список — отличный материал для подсказок: «Сгенерируй Дашборд, который поддерживает X, Y, Z и включает состояния empty/loading/error.»
Определите данные‑сущности на высоком уровне
Останьтесь на уровне «наброска базы» — достаточно для экранов и потоков.
- User: id, email, name, role
- Project: id, ownerId, title, createdAt
- Task: id, projectId, title, status, dueDate
Отметьте связи (User → Projects → Tasks) и всё, что влияет на права доступа.
Где важны доверие и безопасность
Отметьте точки, где ошибки подрывают доверие:
- Аутентификация и сессии
- Права доступа (кто может смотреть/редактировать проект?)
- Деструктивные действия (удаление проекта/задачи) и подтверждения
- Аудит (журнал правок и удалений)
Речь не о сверхзащите — а о предотвращении сюрпризов, которые превращают «рабочее демо» в головную боль поддержки после релиза.
Выберите разумную архитектуру для версии 1
Архитектура v1 должна уметь главное: позволять выпустить минимально полезный продукт, не загнав себя в угол. Хорошее правило: «один репозиторий, один бэкенд для деплоя, один фронтенд для деплоя, одна база данных» — и добавляйте компоненты только при явной необходимости.
Выберите самый простой стек, который подойдёт
Для типичного веб‑приложения разумные дефолты:
- Фронтенд: React (или Next.js для маршрутизации + базовой серверной отрисовки)
- Бэкенд: Node.js + лёгкий фреймворк (Express/Fastify) или API‑роуты Next.js, если API небольшой
- База данных: Postgres (надёжна, гибка и поддерживается везде)
Держите число сервисов низким. Для v1 «модульный монолит» (хорошо организованный код в одном бэкенде) обычно легче, чем микросервисная архитектура.
Если вы предпочитаете среду, ориентированную на ИИ, где архитектура, задачи и генерируемый код остаются тесно связанными, платформы вроде Koder.ai могут подойти: опишите объём v1 в чате, итеративно планируйте и затем генерируйте фронтенд на React и бэкенд на Go + PostgreSQL — при этом сохраняя контроль и ревью.
Обрисуйте API как контракт
Перед генерацией кода напишите маленькую таблицу API, чтобы вы и ИИ имели одну цель. Пример формы:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }
Добавьте заметки про коды статусов, формат ошибок (например, { error: { code, message } }) и пагинацию при необходимости.
Решите, нужна ли аутентификация (или можно обойтись)
Если v1 можно сделать публичным или для одного пользователя — пропустите auth и выпуститесь быстрее. Если нужны учётные записи, используйте управляемого провайдера (email magic link или OAuth) и держите права простыми: «пользователь владеет своими записями». Избегайте сложных ролей, пока реальные пользователи не потребуют их.
Установите цели по производительности и надёжности для первого запуска
Задокументируйте несколько практических ограничений:
- Ожидаемый трафик (даже приблизительно)
- Цель по времени отклика (например, «большинство запросов < 300ms»)
- Минимальное логирование (запросы, ошибки и ключевые бизнес‑события)
- Резервное копирование и план отката
Эти заметки направят генерацию кода ИИ в сторону deployable‑решения, а не только функционального демо.
Забутстрэпьте репозиторий: от пустой папки до рабочего скелета
План v1 без смены инструментов
Преобразуйте ваш v1 PRD в задачи и архитектуру в режиме планирования Koder.ai.
Самый быстрый способ убить импульс — неделями спорить о инструментах и не иметь запускаемого кода. Цель: получить «hello app», который стартует локально, показывает экран и принимает запрос — оставаясь достаточно маленьким, чтобы каждый коммит было легко ревьюить.
Попросите ИИ сгенерировать практичный скелет (не готовый продукт)
Дайте ИИ сжатую подсказку: выбранный фреймворк, базовые страницы, заглушечный API и ожидаемые файлы. Вы хотите предсказуемые соглашения, а не хакерские трюки.
Хорошая первая структура:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Если вы в одном репозитории, попросите про базовые роуты (например, / и /settings) и одну API‑точку (например, GET /health или GET /api/status). Этого достаточно, чтобы проверить, что plumbing работает.
Если вы используете Koder.ai, это тоже естественная точка старта: попросите минимальный «web + api + database-ready» скелет, затем экспортируйте исходники, когда будете довольны структурой.
Сгенерируйте минимальный UI, привязанный к заглушечному бэкенду
Держите UI специально скучным: одна страница, одна кнопка, один вызов.
Пример поведения:
- домашняя страница рендерит «App is running.»
- кнопка вызывает бэкенд‑эндпоинт
- ответ отображается на странице
Это даёт непосредственную обратную связь: если UI загружается, но вызов падает, вы знаете, где смотреть (CORS, порт, маршрутизация, сетевая ошибка). Удерживайте от добавления auth, БД или сложного стейта — этим займётесь после стабилизации скелета.
Добавьте переменные окружения и инструкции для локальной разработки
Создайте .env.example в первый день. Это предотвращает «работает у меня» и упрощает онбординг.
Пример:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Сделайте README запускаемым менее чем за минуту:
- установить зависимости
- скопировать
.env.example в .env
- запустить web + api
- открыть URL в браузере
Делайте маленькие коммиты и фиксируйте прогресс
Относитесь к этой фазе как к закладыванию чистого фундамента. Коммитьте после каждого малого достижения: «init repo», «add web shell», «add api health endpoint», «wire web to api». Маленькие коммиты облегчают итерации с ИИ: если сгенерированное изменение пошло не так, вы можете вернуть его без потери дня работы.
Стройте ключевые фичи тонкими, обозримыми срезами
Когда скелет работает сквозь, сопротивляйтесь желанию «сделать всё сразу». Вместо этого стройте узкие вертикальные срезы, которые касаются БД, API и UI (если нужно), затем повторяйте. Тонкие срезы ускоряют ревью, уменьшают баги и упрощают работу ИИ.
Начните с основной модели данных (и миграций)
Выберите одну модель, без которой приложение не функционирует — чаще всего «сущность», которую создают пользователи. Опишите её просто (поля, обязательные/необязательные, значения по умолчанию), затем добавьте миграции для реляционной БД. Первая версия должна быть скучной: избегайте хитрых нормализаций и преждевременной гибкости.
Если вы просите ИИ сгенерировать модель, попросите его объяснить каждое поле и значение по умолчанию одной фразой. Всё, что он не сможет обосновать, скорее всего, не нужно в v1.
Постройте первичные эндпоинты с правилами валидации
Сделайте только те endpoint’ы, которые нужны для первого пользовательского сценария: обычно create, read и минимальный update. Размещайте валидацию близко к границе (DTO/схемы запросов) и делайте правила явными:
- обязательные поля, форматы и допустимые диапазоны
- проверки владения/прав («может ли пользователь получить доступ к этой записи?»)
- единообразные формы ответов (успех и ошибка)
Валидация — это часть фичи, а не полировка: она предотвращает грязные данные, которые тормозят вас позже.
Обработка ошибок, которая помогает людям
Рассматривайте сообщения об ошибках как UX для отладки и поддержки. Возвращайте понятные, действующие сообщения (что не так и как исправить), при этом не раскрывая чувствительных деталей клиенту. Сервер‑логи должны содержать технический контекст с request ID, чтобы можно было трассировать инциденты.
Используйте предложения ИИ — затем ревьюьте каждое изменение
Просите ИИ предлагать небольшие изменения размером с PR: одна миграция + один endpoint + один тест. Просматривайте diff’ы как у коллеги: проверяйте нейминг, пограничные случаи, допущения безопасности и соответствие целевой «малой победе». Если генерируется лишняя функциональность — вычёркивайте её и идите дальше.
Сделайте это достаточно безопасно: валидация, права и логирование
Запуститесь на собственном домене
Добавьте собственный домен, чтобы ваш v1 выглядел настоящим с момента запуска.
V1 не требует уровня enterprise, но должна избегать предсказуемых провалов, превращающих перспективное приложение в головную боль поддержки. Цель — «достаточно безопасно»: предотвращать некорректный ввод, по умолчанию ограничивать доступ и оставлять след полезных доказательств при ошибках.
Валидация входа + базовая защита от злоупотреблений
Рассматривайте каждую границу как ненадёжную: формы, payload API, query‑параметры и даже внутренние вебхуки. Валидируйте типы, длины и допустимые значения; нормализуйте данные (trim строк, унификация регистра) перед сохранением.
Практические дефолты:
- Серверная валидация (всегда), даже если есть валидация на UI
- Ограничения по частоте для логина, сброса пароля и дорогих эндпоинтов
- Проверки при загрузке файлов: лимит размера, разрешённые MIME‑типы, сканирование на вирусы для публичных загрузок
- Безопасные сообщения об ошибках: говорите, что нужно исправить, но не раскрывайте стек‑трейсы или внутренние идентификаторы
Если вы просите ИИ генерировать обработчики, потребуйте явных правил валидации (например, «макс 140 символов» или «должно быть одним из: …»), а не просто «проверить ввод».
Права доступа: начинайте с малого, deny by default
Простая модель прав обычно достаточна для v1:
- Аноним: доступ только к публичным страницам.
- Зарегистрированный пользователь: может создавать и просматривать свои данные.
- Владелец/редактор (опционально): может редактировать общие записи.
Сделайте проверки владения централизованными и переиспользуемыми (middleware/политики), чтобы не раскидывать if userId == … по всему коду.
Логи, которые помогают быстро отлаживать
Хорошие логи отвечают: что произошло, с кем и где? Включайте:
- request ID (пропагируйте между сервисами)
- user ID (если авторизован)
- действие + ресурс (например,
update_project, project_id)
- время (длительность медленных запросов)
Логируйте события, а не секреты: никогда не записывайте пароли, токены или полные платёжные данные.
Быстрый чеклист типичных ошибок
Перед тем как считать приложение «достаточно безопасным», проверьте:
- auth требуется для всех не‑публичных маршрутов
- есть проверки авторизации (не только аутентификации)
- лимиты частоты на auth и write‑эндоинты
- валидация на сервере для всех входов
- секреты хранятся в env/secret manager (не в репозитории)
- консистентное, безчувственное логирование с request ID
Добавьте тесты, которые защищают happy path и риски
Тестирование — не гнаться за идеальным покрытием, а предотвращать провалы, которые вредят пользователям, подрывают доверие или ведут к дорогостоящим разборкам. В рабочем процессе с ИИ тесты также служат «контрактом», который держит сгенерированный код в русле задуманного.
Начните с самой рискованной логики
Прежде чем покрывать всё, определите, где ошибки дорогие. Часто это платежи/кредиты, права доступа, преобразования данных и пограничная валидация. Пишите юнит‑тесты для таких частей первыми. Дерзайте короткими, специфическими тестами: для входа X ожидается выход Y или ошибка. Если функция имеет слишком много ветвлений — это сигнал, что её нужно упростить.
Добавьте 1–2 интеграционных теста для основного потока
Юнит‑тесты ловят ошибки логики; интеграционные — ошибки «связки»: маршруты, вызовы БД, проверки auth и совместную работу UI. Выберите основной сценарий и автоматизируйте end‑to‑end:
- создать аккаунт / войти
- выполнить ключевое действие приложения
- подтвердить, что результат отображается там, где пользователь ждёт (экран, email, дашборд)
Пара хороших интеграционных тестов часто предотвращает больше инцидентов, чем десятки мелких тестов.
Попросите ИИ черновые тесты — затем сделайте их значимыми
ИИ хорош в создании шаблонов тестов и перечислении пограничных случаев. Попросите его сгенерировать:
- граничные случаи (пустые значения, максимальные длины, часовые пояса)
- негативные сценарии (неавторизованный доступ, недопустимые состояния)
- реалистичные примеры данных (не просто «foo/bar")
Затем проверьте каждое утверждение: тесты должны проверять поведение, а не детали реализации. Если тест пройдёт, несмотря на баг — это не тест.
Поставьте аккуратную цель покрытия и оптимизируйтесь на надёжность
Выберите скромную цель (например, 60–70% по основным модулям) и используйте её как ограничитель, а не трофей. Сосредоточьтесь на стабильных тестах, которые быстро выполняются в CI и падают по понятным причинам. Флаки тесты подрывают доверие к suite — и когда команда перестаёт верить тестам, они перестают защищать вас.
Подготовьте автоматизацию: сборки, CI и quality gates
Автоматизация — это то, где ИИ‑рабочий процесс перестаёт быть «проектом, работающим на моей машине» и становится чем‑то, чем можно безопасно выпускать. Цель не в навороченных инструментах, а в повторяемости.
Начните с одной повторяемой команды сборки
Выберите одну команду, которая даёт одинаковый результат локально и в CI. Для Node это может быть npm run build; для Python — make build; для мобильной сборки — конкретный Gradle/Xcode шаг.
Разделите конфигурации dev и prod уже рано. Простое правило: dev — удобно, prod — безопасно.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Добавьте линтинг и форматирование как quality gates
Линтер ловит рискованные паттерны (неиспользуемые переменные, небезопасные async‑вызовы). Форматтер убирает споры о стиле. Держите правила умеренными для v1, но применяйте последовательно.
Практичный порядок проверок:
- format → 2) lint → 3) tests → 4) build
Настройте базовый CI: тесты на каждый push
Первый CI‑воркфлоу может быть прост: установить зависимости, запустить гейты и фэйлнуть быстро. Это уже предотвращает тихую поломку главной ветки.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Управление секретами (и сделать это сложно испортить)
Решите, где хранятся секреты: store CI, менеджер паролей или переменные деплой‑платформы. Никогда не коммите их в git — добавьте .env в .gitignore и включите .env.example с безопасными плейсхолдерами.
Если хотите чистый следующий шаг, привяжите эти проверки к процессу деплоя так, чтобы «зелёный CI» был единственным путём в продакшн.
Деплой в продакшн с понятным и обратимым процессом
Быстро создайте рабочий репозиторий
Сгенерируйте минимальный каркас веб‑приложения и API из одного чата в Koder.ai.
Релиз — это не одно нажатие, а повторяемая рутина. Цель v1: выбрать цель деплоя, соответствующую стеку, деплоить малыми инкрементами и всегда иметь путь назад.
Выберите подходящую платформу (не переплачивайте)
Платформы по назначению:
- Статический сайт + serverless API: Vercel / Netlify
- Docker‑приложение: Render / Fly.io
- Нужны VM: небольшой VPS (только если действительно требуется)
Оптимизация под «удобный повторный деплой» обычно важнее, чем «максимальный контроль» на этом этапе.
Если приоритет — минимальное переключение инструментов, рассмотрите платформы, которые объединяют сборку + хостинг + откат. Например, Koder.ai поддерживает деплой и хостинг вместе со «снэпшотами» и откатом, так что релизы — обратимые шаги.
Используйте чеклист деплоя каждый раз
Напишите чеклист один раз и используйте при каждом релизе. Держите его коротким, чтобы им действительно пользовались:
- Подтвердить переменные окружения и секреты
- Запустить миграции БД (или подтвердить, что не нужны)
- Собрать и стартовать приложение в прод‑конфигурации
- Прогнать smoke‑тест основного потока
- Убедиться, что логи идут и видны ошибки
Храните чеклист в репозитории (например, /docs/deploy.md), чтобы он был близко к коду.
Добавьте
Добавьте health checks и статус‑эндпоинт
Сделайте лёгкую точку, отвечающую на вопрос: «Приложение запущено и может достучаться до зависимостей?» Распространённые паттерны:
GET /health для аптайм‑мониторовGET /status с версией приложения + чеками зависимостей
Делайте ответы быстрыми, без кешей и безопасными (без секретов).
План отката до того, как он понадобится
План отката должен быть явным:
- Как задеплоить предыдущую версию (тег, релиз, образ)
- Что делать с миграциями (сначала обратно‑совместимые; обратимые — только при необходимости)
- Кто принимает решение об откате и какие сигналы его триггерят (уровень ошибок, падение health checks)
Когда деплой обратим, релизы становятся рутинными, и выпускать можно чаще без стресса.
Закройте цикл: мониторьте, учитесь и итеративно улучшайте тем же рабочим процессом
Запуск — начало самой полезной фазы: вы узнаёте, что делают реальные пользователи, где приложение ломается и какие мелкие изменения двигают метрику успеха. Цель — сохранить тот же AI‑помогающий рабочий процесс, но теперь направленный на доказательства, а не на предположения.
Настройте базовый мониторинг (аптайм, ошибки, производительность)
Начните с минимального стека мониторинга, который отвечает на три вопроса: Он запущен? Он падает? Он медленный?
Аптайм‑чеки могут быть простыми (периодический вызов health‑эндпоинта). Трекер ошибок должен захватывать stack trace и контекст запроса (без чувствительных данных). Мониторинг производительности: время ответа для ключевых эндпоинтов и метрики загрузки фронта.
Попросите ИИ помочь с:
- форматом логов и корреляционными ID, чтобы одно действие пользователя можно было проследить насквозь
- порогами alert’ов (по умолчанию консервативными) и кратким чеклистом на on‑call
Добавьте продуктовую аналитику, привязанную к метрике успеха
Не собирайте всё подряд — отслеживайте то, что доказывает, что приложение работает. Определите одну основную метрику успеха (например: «завершённый checkout», «создан первый проект», «приглашён коллега»). Затем инструментируйте небольшой воронкой: вход → ключевое действие → успех.
Попросите ИИ предложить имена событий и свойства, а затем проверьте их с точки зрения приватности и ясности. Держите имена стабильными; менять их каждую неделю делает тренды бесполезными.
Превратите обратную связь пользователей в план итерации
Сделайте простой канал: кнопка обратной связи в приложении, короткий email‑алиас и лёгкий шаблон для багов. Триаж — еженедельно: группируйте фидбек по темам, связывайте темы с аналитикой и решайте 1–2 улучшения на итерацию.
Сохраняйте рабочий процесс непрерывным и после релиза
Обрабатывайте алерты мониторинга, спад аналитики и темы обратной связи как новые «требования». Подавайте их в тот же процесс: обновляйте документ, генерируйте маленькое предложение по изменению, реализуйте тонким срезом, добавьте целевой тест и задеплойте через тот же обратимый процесс. Для команд полезна общая «Журнал обучения» (ссылка из /blog или внутренних доков) — он делает решения видимыми и повторяемыми.