12 нояб. 2025 г.·4 мин
От некоммерческой лаборатории к лидеру ИИ: история OpenAI
Изучите историю OpenAI — от некоммерческой лаборатории и ключевых исследований до запуска ChatGPT, GPT‑4 и эволюции её миссии.
Изучите историю OpenAI — от некоммерческой лаборатории и ключевых исследований до запуска ChatGPT, GPT‑4 и эволюции её миссии.
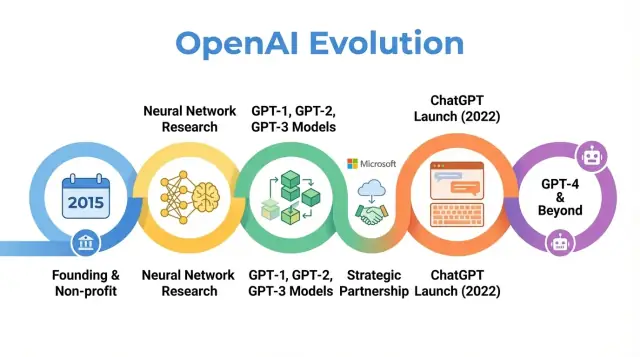
OpenAI — компания по исследованию и развёртыванию ИИ, чья работа сформировала представления о том, как люди думают об искусственном интеллекте: от ранних научных статей до продуктов вроде ChatGPT. Понимание того, как OpenAI эволюционировала — от небольшой некоммерческой лаборатории в 2015 году до центрального игрока в сфере ИИ — помогает объяснить, почему современный ИИ выглядит так, как он выглядит сегодня.
История OpenAI — это не просто последовательность выпусков моделей. Это пример того, как миссия, стимулы, технические прорывы и общественное давление взаимодействуют. Организация начинала с сильным акцентом на открытые исследования и широкую пользу, затем реструктурировалась, чтобы привлечь капитал, сформировала глубокое партнёрство с Microsoft и запустила продукты, которыми пользуются сотни миллионов людей.
Прослеживание истории OpenAI освещает несколько более широких тенденций в ИИ:
Миссия и ценности: OpenAI была основана с заявленной целью обеспечить, чтобы AGI приносил пользу всему человечеству. То, как эта миссия интерпретировалась и пересматривалась со временем, показывает напряжение между идеалистическими целями и коммерческими реалиями.
Исследовательские прорывы: Переход от ранних проектов к системам вроде GPT‑3, GPT‑4, DALL·E и Codex отражает более широкое смещение в сторону крупномасштабных foundation‑моделей, которые сегодня лежат в основе многих приложений ИИ.
Управление и структура: Переход от чисто некоммерческой структуры к организации с ограниченной прибылью и создание сложных механизмов управления подчёркивают, какие новые организационные формы испытываются для управления мощными технологиями.
Общественное влияние и контроль: С выпуском ChatGPT и других продуктов OpenAI превратилась из лаборатории, известной в узких AI‑кругах, в общеизвестный бренд, что привлекло внимание к вопросам безопасности, согласования и регулирования, формирующим нынешние политические дискуссии.
Эта статья прослеживает путь OpenAI с 2015 года до её последних событий, показывая, как каждый этап отражает более широкие сдвиги в исследованиях, экономике и управлении ИИ — и что это может значить для будущего отрасли.
OpenAI была основана в декабре 2015 года, в момент, когда машинное обучение — особенно глубокое обучение — быстро развивалось, но всё ещё было далеко от общей интеллекта. Падали рекорды в задачах распознавания изображений, улучшались речевые системы, и компании вроде Google, Facebook и Baidu активно инвестировали в ИИ.
У многих исследователей и лидеров отрасли росла обеспокоенность, что продвинутый ИИ может оказаться в руках нескольких крупных корпораций или государств. OpenAI задумывалась как противовес: исследовательская организация, ориентированная на долгосрочную безопасность и широкое распределение выгод ИИ, а не на узкое коммерческое преимущество.
С первого дня OpenAI определяла свою миссию в терминах искусственного общего интеллекта (AGI), а не только поэтапного прогресса в машинном обучении. Основное утверждение заключалось в том, что OpenAI будет работать над тем, чтобы AGI, если он будет создан, «приносил пользу всему человечеству».
Эта миссия влекла за собой несколько конкретных последствий:
Ранние публичные блоги и учредительная хартия подчёркивали одновременно открытость и осторожность: OpenAI публиковала многое из своей работы, но также учитывала общественные последствия выпуска мощных возможностей.
OpenAI стартовала как некоммерческая исследовательская лаборатория. Первоначальные финансовые обязательства оценивались примерно в $1 млрд в виде обещанных инвестиций, хотя это были долгосрочные обещания, а не единовременные выплаты. Ключевые ранние спонсоры включали Илона Маска, Сэма Олтмана, Рейда Хоффмана, Питера Тиля, Джессику Ливингстон и YC Research, а также поддержку со стороны компаний вроде Amazon Web Services и Infosys.
Ранняя руководящая команда сочетала опыт стартапов, исследований и операционной деятельности:
Это сочетание предпринимательского духа Кремниевой долины и ведущих исследовательских кадров сформировало раннюю культуру OpenAI: амбициозность в продвижении границ возможностей ИИ при сохранении миссии не ради немедленной коммерциализации, а ради долгосрочного глобального влияния.
Когда OpenAI стартовала в 2015 году как некоммерческая лаборатория, её публичное обещание было простым, но амбициозным: развивать искусственный интеллект, максимально делясь результатами с научным сообществом.
Ранние годы характеризовались философией «открытость по умолчанию». Научные статьи публиковались оперативно, код обычно выкладывался в открытый доступ, а внутренние инструменты перерабатывались в публичные проекты. Идея заключалась в том, что ускорение общего научного прогресса — вместе с общественной проверкой — будет безопаснее и полезнее, чем концентрация возможностей в одной компании.
В то же время вопросы безопасности уже присутствовали в обсуждении. Команда рассуждала о том, когда открытость может повысить риск злоупотреблений, и начала формировать идеи для поэтапного выпуска и политических обзоров, пусть эти механизмы были ещё более неформальными по сравнению с последующими процессами управления.
Ранние научные направления OpenAI охватывали несколько ключевых областей:
Эти проекты были направлены не на готовые продукты, а на проверку возможного с помощью глубокого обучения, вычислений и продуманных режимов обучения.
Два самых влиятельных результата этой эпохи — OpenAI Gym и Universe.
Оба проекта отражали приверженность к совместной инфраструктуре, а не к проприетарному преимуществу.
В этот некоммерческий период OpenAI часто изображали как организацию, движимую миссией, и как противовес крупным технологическим лабораториям. Коллеги ценили качество исследований, доступность кода и сред, а также готовность обсуждать вопросы безопасности.
Медиа подчёркивали необычное сочетание известных финансистов, некоммерческой структуры и обещания публиковать материалы открыто. Эта репутация — влиятельной открытой лаборатории, озабоченной долгосрочными последствиями — сформировала ожидания, которые позже повлияли на реакцию на каждое стратегическое изменение внутри организации.
Поворотный момент в истории OpenAI — решение сосредоточиться на крупных трансформер‑моделях для обработки языка. Этот сдвиг превратил OpenAI из в первую очередь исследовательской лаборатории в компанию, известную foundation‑моделями, на которых строят другие.
GPT‑1 был скромным по современным меркам — 117 миллионов параметров, обучен на BookCorpus — но он дал важное доказательство концепции.
Вместо обучения отдельных моделей для каждой NLP‑задачи GPT‑1 показал, что единая трансформер‑модель, обученная задаче предсказания следующего слова, может с минимальной донастройкой решать задачи вроде вопросно‑ответных систем, анализа тональности и дедукции текста.
Для внутренней дорожной карты OpenAI GPT‑1 подтвердил три идеи:
GPT‑2 значительно расширил ту же идею: 1.5 миллиарда параметров и гораздо больший набор данных, собранный из интернета. Его тексты часто были поразительно связными: многоабзацные статьи, художественные рассказы и сводки, похожие на человеческую авторскую работу.
Такие возможности вызвали тревогу по поводу потенциальных злоупотреблений: автоматизированная пропаганда, спам, домогательства и фальшивые новости в масштабе. Вместо немедленного полного выпуска OpenAI приняла стратегию поэтапного релиза:
Это был один из первых заметных примеров того, как OpenAI явно связывала решения о развертывании с вопросами безопасности и социального воздействия.
GPT‑3 снова увеличил масштаб — до 175 миллиардов параметров. Вместо активного использования донастройки для каждой задачи GPT‑3 продемонстрировал способность «few‑shot» и даже «zero‑shot» обучения: модель часто могла выполнять новую задачу просто по инструкциям и нескольким примерам в подсказке.
Такая универсальность изменила представления OpenAI и всей отрасли о системах ИИ. Вместо множества узких моделей одна большая модель могла служить общим движком для:
Ключевым решением было не публиковать GPT‑3 в открытом доступе. Доступ предоставлялся через коммерческое API. Это означало стратегический поворот:
GPT‑1, GPT‑2 и GPT‑3 демонстрируют явную траекторию в истории OpenAI: масштабирование трансформеров, обнаружение неожиданных способностей, борьба за безопасность и злоупотребления и создание коммерческой базы, которая позже поддержит продукты вроде ChatGPT и развитие GPT‑4.
OpenAI была основана в 2015 году как некоммерческая исследовательская лаборатория с миссией обеспечить, чтобы искусственный общий интеллект (AGI), если он будет создан, приносил пользу всему человечеству.
На формирование её создания повлияли несколько факторов:
Эта история основания продолжает влиять на структуру OpenAI, её партнёрства и публичные обязательства по сей день.
AGI (artificial general intelligence) — это термин для систем ИИ, способных выполнять широкий набор когнитивных задач на уровне человека или выше, а не узкие инструменты, оптимизированные для одной задачи.
Миссия OpenAI заключается в том, чтобы:
Эта миссия формализована в и влияет на ключевые решения о направлениях исследований и развертывании.
OpenAI перешла от чисто некоммерческой организации к структуре "capped‑profit" (ограниченная прибыль), OpenAI LP, чтобы привлечь большие капиталы, необходимые для передовых исследований в ИИ, не теряя формально приоритет миссии.
Ключевые моменты:
Это эксперимент в области управления — его эффективность остаётся предметом обсуждения.
Microsoft предоставила OpenAI масштабные облачные мощности через Azure и вложила миллиарды долларов.
Партнёрство включает:
В обмен OpenAI получает ресурсы, необходимые для обучения и развертывания передовых моделей в глобальном масштабе, а Microsoft — дифференцированные ИИ‑возможности для своей экосистемы.
Серия GPT изменила траекторию OpenAI по масштабу, возможностям и стратегии развертывания:
OpenAI начинала с принципа «открытость по умолчанию»: публикация статей, кода и инструментов вроде OpenAI Gym. По мере роста возможностей моделей компания смещалась в сторону:
OpenAI объясняет это необходимостью снижать риски злоупотреблений и повышать безопасность. Критики считают, что это подрывает первоначальные обещания, заложенные в названии «OpenAI», и концентрирует власть в одной компании.
OpenAI применяет сочетание организационных и технических мер для управления безопасностью и согласованием:
Эти меры снижают риски, но не устраняют такие проблемы, как галлюцинации, смещения и потенциальное злоупотребление — это остаётся активной областью исследований и управления.
Запуск ChatGPT в конце 2022 года стал поворотным моментом, потому что сделал крупные языковые модели доступными широкой публике через простой чат‑интерфейс.
Это изменило принятие ИИ следующим образом:
Публичная видимость усилила внимание к управлению, бизнес‑модели и практикам безопасности OpenAI.
Технологии OpenAI, особенно Codex и GPT‑4, уже меняют части знаний и творческой работы:
Потенциальные выгоды:
Риски и опасения:
Вы можете взаимодействовать с экосистемой OpenAI несколькими способами:
Во всех случаях полезно оставаться информированным о том, как обучаются модели и как они управляются, а также добиваться прозрачности, подотчётности и справедливого доступа к этим системам.
Переход к OpenAI LP в 2019 году был ответом на потребность в крупном финансировании и талантах для обучения масштабных моделей. Обучение передовым моделям требует десятков и сотен миллионов долларов на вычисления и инфраструктуру, а также конкурентных условий для найма исследователей.
Модель с ограниченной прибылью позволяла:
Эта структура — компромисс, стремящийся сочетать доступ к капиталу и защиту миссии, но её долгосрочная эффективность остаётся предметом дебатов.
OpenAI в ранние годы публиковала исследования, открывала код и предоставляла инструменты вроде OpenAI Gym. По мере того как модели становились мощнее, компания ввела более осторожный подход к раскрытию:
OpenAI объясняет это стремлением снизить риски злоупотреблений и обеспечить безопасность. Критики считают, что это расходится с первоначальными обещаниями открытости и концентрирует влияние.
Главные направления ранних исследований OpenAI включали:
Эти направления были направлены не на коммерческие продукты, а на исследование пределов возможного с глубинным обучением и вычислительными ресурсами.
CLIP, DALL·E и Codex показали, что подход OpenAI можно применить не только к тексту:
Эти разработки расширили влияние OpenAI на дизайн, творчество и разработку ПО.
Партнёрство с Microsoft привело к созданию крупной вычислительной инфраструктуры на Azure, специально оптимизированной под обучение больших моделей:
Это сделало Azure де‑факто базовой платформой для обучения и развёртывания моделей OpenAI.
ChatGPT первоначально запустили как бесплатный «исследовательский превью» 30 ноября 2022 года, чтобы снизить трение и собрать отзывы о провалах, злоупотреблениях и недостатках.
Первые недели показали взрывной рост использования: миллионы пользователей попробовали сервис в краткие сроки. Это быстро привело к:
В феврале 2023 года появился платный план ChatGPT Plus для обеспечения приоритетного доступа и средств на поддержку сервиса, а позже — корпоративные и API‑решения.
Среди вызовов и критики OpenAI часто упоминают вопросы власти, данных и коммерциализации:
Руководство OpenAI отстаивает доходы как необходимое условие для финансирования дорогостоящих исследований, одновременно сохраняя формальные механизмы контроля для защиты миссии.
Каждый шаг расширял технические границы и одновременно требовал новых решений по безопасности, доступу и коммерциализации.
Чистое влияние будет зависеть от политики, организационных решений и того, как люди и фирмы будут интегрировать ИИ в рабочие процессы.