Установите цели и объём для отслеживания надежности
Прежде чем выбирать метрики или строить дашборды, решите, за что отвечает ваше приложение надежности — и за что не отвечает. Чёткий объём предотвращает превращение инструмента в универсальный «ops‑портал», которому никто не доверяет.
Определите, что вы отслеживаете
Начните с перечисления внутренних инструментов, которые будет покрывать приложение (например, тикетинг, зарплатная система, интеграции CRM, конвейеры данных) и команд, которые ими владеют или зависят от них. Будьте конкретны в границах: «внешний сайт для клиентов» может быть вне области, в то время как «внутренний админ‑консоль» — внутри.
Согласуйте, что тут значит «надежность»
В разных организациях это слово означает разное. Запишите рабочее определение простым языком — обычно это смесь:
- Доступность: могут ли люди получить доступ, когда нужно?
- Задержка: достаточно ли быстро, чтобы быть удобным?
- Ошибки: падает ли система заметно для пользователей (тайм‑ауты, сбои задач, неправильные ответы)?
Если команды не договорятся, приложение будет сравнивать «яблоки с апельсинами».
Решите, какие результаты вы хотите
Выберите 1–3 основных результата, например:
- Более быстрое обнаружение проблем (меньше «time to notice»)
- Чёткая отчётность для менеджеров и стейкхолдеров
- Меньше повторных инцидентов благодаря лучшему сопровождению
Эти результаты будут направлять, что вы измеряете и как это показываете.
Идентифицируйте пользователей и роли
Перечислите, кто будет использовать приложение и какие решения принимает: инженеры, расследующие инциденты; саппорт, эскалирующий вопросы; менеджеры, просматривающие тренды; стейкхолдеры, которым нужны статус‑обновления. Это повлияет на терминологию, права доступа и уровень детализации на разных экранах.
Выберите метрики надежности, которые имеют значение (SLI/SLO)
Отслеживание надежности работает только если все согласны, что значит «хорошо». Начните с разделения похожих терминов.
SLI vs SLO vs SLA (простыми словами)
SLI (Service Level Indicator) — это измерение: «Какой % запросов вернулся успешно?» или «Сколько времени грузятся страницы?»
SLO (Service Level Objective) — цель для этого измерения: «99.9% успеха за 30 дней.»
SLA (Service Level Agreement) — обещание с последствиями, обычно внешнее (скидки, штрафы). Для внутренних инструментов часто ставят SLO без формальных SLA — достаточно для согласования ожиданий без превращения надежности в контракт.
Выбирайте небольшой, согласованный набор SLI для каждого инструмента
Держите набор сопоставимым между инструментами и простым для объяснения. Практический базовый набор:
- Uptime/доступность: был ли инструмент доступен?
- Время ответа: насколько быстро реагируют ключевые страницы или эндпойнты?
- Доля ошибок: какая доля проверок или запросов упала (5xx, тайм‑ауты, известные состояния ошибок)?
Не добавляйте новые метрики, пока не сможете ответить: «Какое решение будет принимать эта метрика?»
Выбирайте окна времени, которые совпадают с тем, как люди мыслят
Используйте скользящие окна, чтобы скоркард обновлялся постоянно:
- 7 дней: быстро ловит регрессии
- 30 дней: месячная отчётность и тренды
- 90 дней: стабильность за квартал
Определите инциденты с явными уровнями серьёзности
Приложение должно превращать метрики в действия. Определите уровни серьёзности (например, Sev1–Sev3) и явные триггеры, например:
- Sev1: инструмент упал или критический рабочий поток заблокирован на X минут
- Sev2: серьёзная деградация (например, доля ошибок выше Y% в течение Z минут)
- Sev3: мелкие или периодические проблемы
Такие определения делают оповещения, таймлайны инцидентов и отслеживание error budget консистентными между командами.
Запланируйте источники данных и подход к инжесту
Трекер надежности ценен ровно настолько, насколько достоверны данные. Перед тем как строить пайплайны инжеста, замапьте все сигналы, которые будете считать «истиной», и пропишите, на какой вопрос отвечает каждый из них (доступность, задержка, ошибки, влияние деплоя, ответ на инцидент).
Замапьте доступные источники данных
Большинство команд покрывают базу с помощью смеси:
- Статус‑чеки / синтетические пробы (uptime и базовая задержка)
- Метрики (перцентильные задержки, доли ошибок, насыщение)
- Логи (счётчики ошибок, топ падений по эндпойнтам)
- Трейсы (где тратится время по зависимостям)
- Системы тикетов/инцидентов (время начала/окончания, severity, владелец, ссылки на постмортем)
Будьте явны, какие системы являются авторитетными. Например, ваш «uptime SLI» может браться только из синтетических проб, а не из серверных логов.
Решите push vs pull (и частоты)
- Pull хорош для API (Prometheus, cloud monitoring, тикеты): приложение опрашивает по расписанию.
- Push лучше для высокочастотных событий (деплои, инциденты, оповещения): системы шлют вебхуки/события в приложение.
Устанавливайте частоту обновлений по кейсу: дашборды могут обновляться каждые 1–5 минут, а скоркард — ежечасно/ежедневно.
Нормализуйте идентификаторы и владение
Создайте согласованные ID для инструментов/сервисов, окружений (prod/stage) и владельцев. Согласуйте правила именования заранее, чтобы «Payments-API», «payments_api» и «payments» не стали тремя разными сущностями.
Ретенция и приватность
Решите, что хранить и как долго (например, сырые события 30–90 дней, дневные агрегаты 12–24 месяца). Избегайте инжеста чувствительных полезных нагрузок; храните только метаданные, необходимые для анализа надежности (метки времени, коды статусов, корзины задержек, теги инцидентов).
Проектирование модели данных и схемы БД
Схема должна облегчать два сценария: ежедневный ответ на «здоров ли инструмент?» и реконструкцию произошедшего в инциденте («когда начались симптомы, кто что поменял, какие оповещения сработали?»). Начните с небольшого набора сущностей и явно укажите связи.
Основные сущности (стартовый минимум)
- Tool/Service: отслеживаемый инструмент (имя, описание, окружение, критичность).
- Check: конкретная синтетическая или uptime‑проверка (тип, целевой URL, расписание, включена/выключена).
- Metric: точки временных рядов (задержка, доля успеха, счётчик ошибок) связанные с инструментом или чеком.
- SLO: цель и окно оценки (например, 99.9% за 30 дней) плюс настройки error budget.
- Incident: событие, влияющее на надежность (severity, status, start/end, краткое описание).
- Event: запись в таймлайне инцидента (смены состояний, заметки, получение оповещения, применённые меры).
- Owner: команда или человек, ответственный за инструмент.
Связи, которые упрощают запросы
Практический минимум:
- Tool имеет много Checks (и может иметь много SLO).
- Check имеет много Metrics (или потоков метрик).
- Incident принадлежит Tool, и Incident имеет много Events для таймлайна.
- Tool принадлежит Owner (или many‑to‑many, если владение разделено).
Такая структура поддерживает дашборды («tool → текущий статус → недавние инциденты») и детальный просмотр («incident → events → связанные проверки и метрики»).
Поля аудита и теги
Добавьте поля аудита там, где нужна ответственность и история:
created_by, created_at, updated_atstatus плюс отслеживание изменений статуса (в Event или отдельной history‑таблице)
Наконец, включите гибкие теги для фильтрации и отчётности (team, criticality, system, compliance). tool_tags join‑таблица (tool_id, key, value) помогает держать теги консистентными и упрощает склейки/агрегации.
Выбор стека и модели деплоя
Трекер надежности должен быть «скучным» в лучшем смысле: легко запускаться, легко менять и поддерживать. «Правильный» стек — тот, который ваша команда способна поддерживать без героизма.
Начните с того, что команда уже использует
Выберите популярный веб‑фреймворк, который команда хорошо знает — Node/Express, Django или Rails — все подойдут. Отдавайте приоритет:
- понятным конвенциям (чтобы новые контрибьюторы не терялись)
- хорошим библиотекам для аутентификации, фоновых задач и графиков
- предсказуемому пути обновлений
Если интеграция с внутренними системами (SSO, тикеты, чат) важна, выберите экосистему, где эти интеграции проще реализовать.
Если нужно ускорить первую итерацию, vibe‑coding‑платформа вроде Koder.ai может быть практичным стартом: вы описываете сущности (tools, checks, SLO, incidents), рабочие процессы (alert → incident → postmortem) и генерируете каркас веб‑приложения. Koder.ai часто целится в React на фронте и Go + PostgreSQL на бэке, что хорошо ложится на «скучный, поддерживаемый» стек — и вы можете экспортировать исходники, если позже перейдёте на полностью ручной пайплайн.
Сначала база данных, потом вспомогательные компоненты
Для большинства внутренних приложений надежности PostgreSQL — правильный выбор по умолчанию: он справляется с реляционными отчётами, временными запросами и аудитом.
Добавляйте компоненты только когда они реально решают проблему:
- Кэш (например, Redis) если дашборды медленные или вы ограничены API‑квотами upstream
- Очередь/фоновые задачи (Redis + worker, Sidekiq, Celery, BullMQ) для опроса, отправки уведомлений и генерации отчётов
Хостинг и модель деплоя
Выбирайте между:
- Внутренний облак / Kubernetes, когда нужен более плотный сетевой доступ к внутренним сервисам
- PaaS, когда хочется проще оперировать и быстро итератировать
Вне зависимости от выбора, стандартизируйте dev/staging/prod и автоматизируйте деплой (CI/CD), чтобы изменения не меняли числа надежности молча. Если используете платформу вроде Koder.ai, ищите поддержку сред, деплоя и быстрых откатов (snapshots), чтобы итерации не ломали сам трекер.
Управление конфигурацией, которому можно доверять
Документируйте конфигурацию в одном месте: переменные окружения, секреты, feature‑флаги. Держите краткий «how to run locally» и минимальный ранбук (что делать, если инжест остановился, очередь накопилась или база заполнилась). Небольшая страница в /docs обычно достаточна.
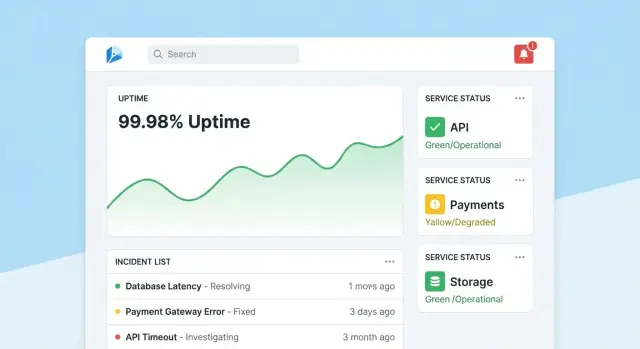
Проектирование UX: дашборды, детализация и рабочие процессы
Разверните и поделитесь внутри команды
Хостьте приложение с встроенным деплоем, затем добавьте собственный домен, когда будете готовы.
Успех трекера надежности определяется тем, насколько быстро люди могут ответить на два вопроса: «Мы в порядке?» и «Что делать дальше?» Проектируйте экраны вокруг этих решений с понятной навигацией: overview → конкретный инструмент → конкретный инцидент.
Домашняя страница: быстрый read‑out здоровья
Сделайте домашнюю страницу компактным командным центром. Начните с общего сводного статуса (напр., число инструментов, соответствующих SLO, активные инциденты, самые большие риски), затем покажите недавние инциденты и оповещения с бейджами статуса.
Держите дефолтный вид спокойным: выделяйте только то, что требует внимания. Дайте каждой карточке прямой переход к инструменту или инциденту.
Страница инструмента: от статуса к действию
Страница инструмента должна отвечать: «Достаточно ли надежен этот инструмент?» и «Почему/почему нет?» Включите:
- Текущий статус SLO с простым pass/fail и оставшимся error budget
- Графики доступности, задержки и доли ошибок за выбранные периоды
- Недавние изменения (деплои, правки конфигураций, обновления чеков), чтобы видеть закономерности
- Ранбуки и контакты: заметная секция «Что делать» с ссылками и контактами
Дизайн графиков для не‑экспертов: подписывайте единицы, отмечайте пороги SLO и добавляйте небольшие подсказки, вместо плотных технических контролов.
Страница инцидента: общий контекст и таймлайн
Страница инцидента — это живой документ. Включите таймлайн (автозахваченные события: сработал алерт, подтверждён, применена мера), обновления от людей, затронутых пользователей и предпринятые действия.
Сделайте обновления простыми: одно поле ввода, предопределённые статусы (Investigating/Identified/Monitoring/Resolved) и опциональные внутренние заметки. После закрытия инцидента кнопка «Start postmortem» должна предзаполнять факты из таймлайна.
Админские страницы: владение и консистентность
Админам нужны простые экраны для управления инструментами, чекерами, целями SLO и владельцами. Оптимизируйте на корректность: разумные дефолты, валидация и предупреждения при изменениях, влияющих на отчётность. Показывайте заметно «последнее редактирование», чтобы люди доверяли числам.
Реализуйте аутентификацию, права и аудиты
Данные надежности остаются полезными, пока им доверяют. Это значит связывать каждое изменение с сущностью, ограничивать, кто может делать критичные правки, и хранить историю изменений для последующего анализа.
Аутентификация: используйте существующий IdP
Для внутреннего приложения по умолчанию используйте SSO (SAML) или OAuth/OIDC через провайдера удостоверений (Okta, Azure AD, Google Workspace). Это уменьшает управление паролями и упрощает онбординг/оффбординг.
Практика:
- Требуйте MFA через IdP (не реализуйте заново)
- Маппируйте группы IdP в роли приложения при логине
- Устанавливайте короткие сессии и поддержку ручного выхода
Права: ролевая модель с «защищёнными действиями»
Стартуйте с простых ролей и добавляйте детализацию, только если нужно:
- Viewer: только чтение дашбордов и скоркардов
- Editor: создание/обновление чеков, инцидентов и заметок
- Admin: управление определениями SLO, порогами, интеграциями и маппингом ролей
Защитите действия, которые влияют на результаты или повествование:
- Только Admin может менять цели SLO, пороги оповещений или маппинги источников данных
- Ограничьте, кто может закрывать инциденты и требуйте краткое резюме решения
Аудит: неизменяемая история изменений
Логируйте каждое редактирование SLO, чеков и полей инцидента с:
- кто сделал (пользователь + роль)
- когда (timestamp)
- что поменялось (значения до/после)
- откуда (UI/API/автоматизация)
Сделайте логи доступными на соответствующих страницах (например, на странице инцидента показывайте всю историю изменений). Это упрощает ревью и уменьшает споры в постмортемах.
Постройте проверки мониторинга и сбор uptime
Мониторинг — это «сенсорный слой» трекера: он превращает поведение системы в данные. Для внутренних инструментов синтетические проверки часто самые быстрые, потому что вы контролируете, что значит «здорово».
Определите синтетические проверки для каждого инструмента
Начните с небольшого набора типов проверок, покрывающих большинство внутренних приложений:
- HTTP ping: проверить, что сервис отвечает (код статуса, TLS, базовые заголовки)
- Валидация эндпойнта: обратиться по известному URL и проверить что‑то значимое (ожидаемая JSON‑форма, ключевая строка в HTML или payload health endpoint)
- Smoke‑путь без логина: по возможности протестировать один read‑only флоу, отражающий опыт пользователя (например, загрузка страницы дашборда и проверка рендера)
Держите проверки детерминированными. Если валидация может падать из‑за изменяющегося контента, вы получите шум и потеряете доверие.
Собирать uptime и задержки (и хранить разумно)
Для каждого прогона проверки записывайте:
- Timestamp (start и end)
- Результат: up/down/unknown
- Задержка: общее время (и опционально DNS/connect/TTFB, если меряете)
- Причина: код ошибки, тайм‑аут, неудачная валидация или сообщение об исключении
Храните данные как события временных рядов (по одной записи на прогон проверки) или как агрегированные интервалы (например, минутные роллапы с подсчётами и p95). Сырые события хороши для дебага; роллапы — для быстрых дашбордов. Многие команды хранят оба: сырые события 7–30 дней и роллапы для долгосрочного отчёта.
Явно различайте простои и отсутствие данных
Пропущенный результат проверки не должен автоматически значить «down». Добавьте явное состояние unknown для случаев как:
- воркер проверки остановлен
- сетевой разрыв между проверяющим и целью
- конфигурация изменена во время прогона
Это предотвращает завышение времени простоя и делает «провалы мониторинга» видимыми как отдельную операционную проблему.
Запускайте проверки по расписанию через фоновые задачи
Используйте фоновые воркеры (cron‑подобные расписания, очереди) для запуска проверок с фиксированными интервалами (например, каждые 30–60 секунд для критичных инструментов). Добавьте тайм‑ауты, ретраи с backoff и лимиты параллелизма, чтобы ваш чекер не перегружал внутренние сервисы. Сохраняйте результат каждого прогона — даже неудачи — чтобы дашборд uptime показывал и текущий статус, и надёжную историю.
Создайте потоки оповещений и уведомлений
Экспортируйте код в любой момент
Сохраняйте полный контроль: экспортируйте код, когда захотите перейти на свой пайплайн.
Оповещения превращают трекинг надежности в действие. Цель проста: уведомлять нужных людей с нужным контекстом в нужное время — без флуд‑штормов.
Связывайте оповещения с SLO (а не только с порогами)
Определяйте правила оповещений, которые прямо соответствуют вашим SLIs/SLOs. Две практики:
- Burn‑rate оповещения: тревога, когда бюджет ошибок сжигается настолько быстро, что вы не успеваете держать SLO
- Пороговые нарушения: предупреждение, когда метрика пересекает явную границу (например, доступность ниже 99.5% за 15 минут)
Для каждого правила храните «почему» рядом с «что»: какой SLO затронут, окно оценки и предполагаемая серьёзность.
Делайте уведомления действенными
Шлите уведомления через каналы, в которых команды уже живут (email, Slack, Microsoft Teams). Сообщение должно включать:
- Однострочное резюме (сервис + симптом + серьёзность)
- Прямую ссылку на релевантный вид дашборда (например,
/services/payments?window=1h)
- Ссылку на страницу инцидента, если он создан (например,
/incidents/123)
Избегайте дампа сырых метрик. Дайте короткое «следующее действие»: «Проверить недавние деплои» или «Открыть логи».
Снижайте шум с помощью дедупа, группировки и quiet hours
Реализуйте:
- Дедупликация (одинаковый fingerprint → обновление существующей нити)
- Группировка (один инцидент может собирать несколько связанных алертов)
- Quiet hours и правила маршрутизации, чтобы низкосерьёзные оповещения не будили on‑call
Поддержка эскалаций и маршрутов on‑call
Даже во внутреннем инструменте людям нужен контроль. Добавьте ручную эскалацию (кнопка на странице алерта/инцидента) и интеграцию с on‑call системой, если есть (PagerDuty/Opsgenie), либо хотя бы конфигурируемый ротационный список, хранимый в приложении.
Добавьте управление инцидентами и возможности постмортема
Управление инцидентами превращает «мы получили алерт» в согласованную, отслеживаемую реакцию. Встройте это в приложение, чтобы люди могли переходить от сигнала к координации без прыжков между инструментами.
Создание инцидента в один клик
Позвольте создавать инцидент прямо из алерта, страницы сервиса или графика uptime. Предзаполняйте ключевые поля (сервис, окружение, источник алерта, время первого обнаружения) и присваивайте уникальный ID инцидента.
Лёгкий набор полей — хороший по умолчанию: severity, влияние на пользователей (внутренние команды), текущий владелец и ссылки на триггерный алерт.
Жизненный цикл статусов и совместная работа
Используйте простой жизненный цикл, соответствующий реальной работе команд:
- Open → Investigating → Mitigated → Resolved
Каждое изменение статуса фиксируйте с кем и когда. Добавьте таймлайн‑обновления (короткие timestamped заметки), а также поддержку вложений и ссылок на ранбуки и тикеты (например, /runbooks/payments-retries или /tickets/INC-1234). Это становится единой нитью «что произошло и что делали».
Постмортемы с планом действий
Постмортемы должны быть быстрыми для старта и единообразными для ревью. Дайте шаблоны с полями:
- Краткое описание, влияние, обнаружение и корневая причина
- Сопутствующие факторы (включая процессные пробелы)
- Что сработало / что нет
- follow‑up задачи с владельцами и сроками
Привязывайте action items к инциденту, отслеживайте выполнение и показывайте просроченные задачи на командных дашбордах. Для обучающих ревью поддержите «blameless» режим, фокусирующийся на системах и процессах, а не на личных ошибках.
Отчётность и скоркарды надежности
Преобразуйте SLO в дашборды
Создавайте React‑вью для карточек показателей и подробного анализа — Go и PostgreSQL генерируются для вас.
Отчёты превращают отслеживание в принятие решений. Дашборды помогают операторам; скоркарды помогают лидерам видеть, улучшается ли ситуация, где нужны инвестиции и что значит «хорошо».
Что включать в скоркард
Сделайте консистентный, повторяемый вид на инструмент (и опционально на команду), который быстро отвечает:
- Соблюдение SLO во времени: текущий период (неделя/месяц/квартал) и линия тренда против цели.
- Топ‑ненадёжных инструментов: ранжируйте по пропущенным SLO, минутам простоя или самому быстрому сжиганию error budget.
- MTTR: медиана и p90 времени восстановления, чтобы один длинный инцидент не скрывал закономерность.
- Число инцидентов: всего инцидентов и разбивка по severity, с сравнением с предыдущим периодом.
По возможности добавляйте лёгкий контекст: «SLO пропущен из‑за 2 деплоев» или «Большая часть простоя из‑за зависимости X», не превращая отчёт в полный разбор инцидента.
Фильтры, делающие отчёты удобными для руководства
Руководителям редко нужно «всё». Добавьте фильтры по команде, критичности инструмента (Tier 0–3) и времяному окну. Убедитесь, что один инструмент может появляться в нескольких агрегатах (команда‑владелец, но и команда‑потребитель).
Сводки и экспорт
Дайте еженедельные и ежемесячные сводки, которыми можно делиться вне приложения:
- Кнопка CSV export для таблиц
- Чистый PDF export для обзорных встреч
Сохраняйте единый нарратив («Что изменилось с прошлого периода?» «Где мы превысили бюджет?»). Если нужно, дайте вводную для стейкхолдеров и ссылку на /blog/sli-slo-basics.
Безопасность, качество данных и операционная устойчивость
Трекер надежности быстро становится источником правды. Относитесь к нему как к продакшену: защищён по умолчанию, устойчив к «грязным» данным и с понятным планом восстановления.
Защитите поверхность приложения
Закрывайте все эндпойнты — даже «только внутри».
- Валидируйте вход на границе (типы, диапазоны, допустимые enum'ы, max payload) и отвергайте незнакомые поля
- Добавьте rate limiting по пользователю/токену, чтобы шумные клиенты не перегружали инжест или дашборды
- Используйте параметризованные запросы и безопасные ORM‑паттерны, чтобы избежать инъекций
Секреты и контроль доступа
Держите креды вне кода и логов.
Храните секреты в секрет‑менеджере и периодически ротаируйте. Давайте веб‑приложению минимальные права к базе: отдельные read/write роли, доступ только к нужным таблицам и короткоживущие креды, где возможно. Шифруйте трафик (TLS) между браузером↔приложение и приложением↔базой.
Защитные механизмы качества данных
Метрики надежности полезны только если события достоверны.
Добавьте серверные проверки на метки времени (timezone/сдвиг часов), обязательные поля и idempotency‑ключи для дедупа ретраев. Логируйте ошибки инжеста в dead‑letter очередь или таблицу «quarantine», чтобы плохие события не портили дашборды.
Операционные базовые вещи (не пропускайте)
Автоматизируйте миграции базы и тестовые откаты. Делайте бэкапы, регулярно проверяйте восстановление и задокументируйте минимальный DR‑план (кто, что, сколько времени).
Наконец, делайте сам трекер надежным: health checks, мониторинг задержки очередей и БД, и оповещение, если инжест молча упал до нуля.
План запуска и дорожная карта итераций
Трекер надежности успешен, когда люди доверяют ему и реально пользуются. Считайте первый релиз петлёй обучения, а не «big bang» запуском.
Начните с фокусного пилота
Выберите 2–3 внутренних инструмента с ясными владельцами и большим использованием. Реализуйте небольшой набор проверок (например: доступность главной страницы, успешный логин и ключевой API‑эндпойнт) и опубликуйте один дашборд, отвечающий: «Он доступен? Если нет — что изменилось и кто за это отвечает?»
Держите пилот заметным, но ограниченным: одна команда или небольшая группа power‑пользователей достаточно, чтобы валидировать поток.
Собирайте критичный фидбек
В первые 1–2 недели активно собирайте отзывы по:
- Что сбивает с толку (имена метрик, графики, фильтры, определения)
- Что шумит (оповещения, не соотносимые с влиянием на пользователей)
- Чего не хватает (владение, ранбуки, ссылки на инциденты)
Переводите фидбек в конкретные задачи в бэклоге. Простая кнопка «Report an issue with this metric» на каждом графике часто даёт самые быстрые инсайты.
Итерации через интеграции и автоматизацию
Добавляйте ценность слоями: подключите сначала чат для уведомлений, затем систему инцидентов для автосоздания тикетов, затем CI/CD для маркеров деплоя. Каждая интеграция должна уменьшать ручную работу или сокращать time‑to‑diagnose — иначе это просто сложность.
Если прототипируете быстро, рассмотрите использование Koder.ai в режиме планирования, чтобы сначала смэпить начальный объём (сущности, роли, рабочие процессы), а потом генерировать первую сборку. Это помогает удерживать MVP компактным, и поскольку есть снапшоты/откаты, вы безопасно итератируете над дашбордами и инжестом по мере уточнения определений.
Определите метрики успеха и расширяйтесь
Прежде чем масштабировать на другие команды, определите метрики успеха: еженедельная активность по дашбордам, сокращение времени обнаружения, меньше дублирующих алертов, регулярные ревью SLO. Публикуйте лёгкую дорожную карту в /blog/reliability-tracking-roadmap и расширяйте покрытие инструмент за инструментом с явными владельцами и сессиями обучения.