Цели, пользователи и определения уровней аккаунтов
Прежде чем строить дашборды или инструментировать события, чётко определите, для чего служит приложение, кто им будет пользоваться и как определяются уровни аккаунтов. Большинство проектов по «отслеживанию принятия» терпят неудачу, потому что начинают с данных и в итоге расходятся во мнениях.
Практическое правило: если две команды не могут в одной фразе согласовать определение «принятия», они позже не будут доверять дашборду.
Кто будет пользоваться этим приложением?
Назовите основные аудитории и чего каждая должна добиться после просмотра данных:
- Product: понять, обнаруживаются ли новые функции, используются ли повторно и сохраняются ли пользователи.\
- Customer Success (CS): выявлять пробелы в онбординге, риски принятия и аккаунты, которым нужна помощь.\
- Sales / Account Management: определять сигналы расширения (высокое использование, широта функций) и риск продления.\
- Executives: отслеживать общее здоровье принятия и действительно ли стратегические инициативы двигают показатели.
Полезный литмус: каждая аудитория должна уметь ответить на «и что?» менее чем за минуту.
Определите «принятие» для вашего продукта
Принятие — это не одна метрика. Запишите определение, с которым команда сможет согласиться — обычно это последовательность:
- Активация: первое значимое достижение (например, приглашены коллеги, создан первый проект, завершена настройка).\
- Использование функции: повторное использование ключевых функций, коррелирующих с ценностью (не ради кликов).\
- Удержание: использование продолжается неделя за неделей / месяц за месяцем.
Держите определение, ориентированное на ценность клиента: какие действия сигнализируют о том, что они получают результат, а не просто изучают продукт.
Уровни аккаунтов и правила присвоения
Перечислите уровни и сделайте присвоение детерминированным. Частые уровни: SMB / Mid-Market / Enterprise, Free / Trial / Paid, или Bronze / Silver / Gold.
Документируйте правила простым языком (а позднее — в коде):
- Какой источник правды решает уровень (система биллинга, CRM, внутренняя таблица)?\
- На чём основан уровень: ARR, количество мест, план, отрасль или уровень поддержки?\
- Что делать при конфликте данных (например, CRM говорит Enterprise, биллинг говорит Pro)?\
- Когда изменение уровня вступает в силу и нужен ли вам исторический журнал уровней для отчётности?
Решения, которые вы хотите поддерживать
Запишите решения, которые приложение должно позволять принимать. Например:
- Onboarding: кто не активировался в течение 7 дней?\
- Risk: какие высокоценные аккаунты показывают снижение использования?\
- Expansion: какие аккаунты достигают лимитов или применяют несколько продвинутых функций?
3–5 ключевых вопросов для дашборда
Используйте их как критерии приёмки:
- Какие уровни улучшают или ухудшают принятие в этом месяце?\
- Для каждого уровня, какой процент аккаунтов активирован и какой процент удержан?\
- Какие функции дают наибольшую разницу между здоровыми и рискованными аккаунтами по уровням?\
- Каким топ-аккаунтам в каждом уровне нужно вмешательство и почему (пробел в активации, малая широта, падение частоты)?\
- После релиза или изменения онбординга, повысилось ли принятие для целевого уровня?
Метрики принятия, которые имеют смысл по уровням
Уровни аккаунтов ведут себя по-разному, поэтому единая метрика «принятие» либо накажет маленьких клиентов, либо скроет риск у крупных. Начните с определения, что считается успехом для каждого уровня, затем выберите метрики, отражающие эту реальность.
1) Выберите north-star исходы для каждого уровня
Выберите один основной результат, который представляет реальную доставленную ценность:
- Starter/SMB: «активированные аккаунты» (быстро достигли первой ценности).\
- Mid-market: «еженедельно активные аккаунты с использованием ключевых функций».\
- Enterprise: «аккаунты с мультикомандным внедрением» или «аккаунты, достигшие контрольных точек раскатывания».
Ваш north star должен быть счётным, сегментированным по уровням и сложным для искажения.
2) Определите стадии воронки с чёткой квалификацией
Запишите воронку принятия как набор стадий с явными правилами — чтобы ответ в дашборде не зависел от интерпретаций.
Пример стадий:
- Invited → Signed up: создан хотя бы один пользователь.\
- Activated: чек-лист настройки завершён и выполнено первое ключевое действие.\
- Integrated: подключена хотя бы одна ключевая интеграция.\
- Adopting: повторяющиеся ключевые действия в разные дни/недели.
Различия по уровням важны: для Enterprise «Activated» может требовать действия администратора и хотя бы одного действия конечного пользователя.
3) Выберите лидирующие и отстающие индикаторы
Используйте лидирующие индикаторы, чтобы заметить раннюю динамику:
- Завершение настройки\
- Подключение ключевой интеграции\
- Публикация/расшаривание первого рабочего процесса
Используйте отстающие индикаторы, чтобы подтвердить устойчивое принятие:
- Удержание по уровням (например, 4‑недельный active rate)\
- Глубина использования (действия на активного пользователя, созданные проекты, активные места)\
- Прокси продлений (сигналы здоровья контракта, события расширения)
4) Установите реалистичные цели по уровням
Цели должны учитывать ожидаемое время до ценности и организационную сложность. Например, SMB может целиться в активацию в течение 7 дней; Enterprise — в интеграцию за 30–60 дней.
Записывайте цели, чтобы оповещения и счётчики оставались согласованными между командами.
Модель данных для аккаунтов, пользователей и истории уровней
Чёткая модель данных предотвращает «загадочную математику» позже. Вы должны уметь ответить на простые вопросы: кто что использовал, в каком аккаунте, под каким уровнем, в этот момент времени — без встраивания ad-hoc логики в каждый дашборд.
Основные сущности для моделирования
Начните с малого набора сущностей, которые соответствуют тому, как клиенты покупают и используют продукт:
- Account: запись клиента, которой вы продаёте (компания или организация). Храните идентификаторы (
account_id), имя, статус и поля жизненного цикла (created_at, churned_at).\
- User: отдельный человек. Включите
user_id, домен электронной почты (полезно для сопоставления), created_at, last_seen_at.\
- Workspace / Project (опционально): если в продукте есть несколько пространств под одним аккаунтом, моделируйте их явно с
workspace_id и внешним ключом на account_id.\
- Subscription: объект биллинга. Храните план, период биллинга, места, MRR и временные метки.\
- Tier: нормализованная таблица (например, Free, Team, Business, Enterprise), чтобы названия оставались консистентными.
Решите, на каком уровне вести трекинг
Будьте явны насчёт аналитического «зерна»:
- События на уровне пользователя отвечают: какие персоны приняли фичу X?\
- Агрегации на уровне аккаунта отвечают: здоров ли этот клиент?
Практический дефолт — трекать события на уровне пользователя (с привязкой account_id), затем агрегировать до аккаунта. Избегайте событий только на уровне аккаунта, если только не существует сценариев без пользователей (например, системный импорт).
Моделируйте время: события vs снимки
События говорят, что произошло; снимки — что было истинно в момент времени.
- Держите таблицу событий как источник правды.\
- Добавьте ежедневные снимки аккаунтов (по одной строке на аккаунт в день) для быстрых дашбордов: активные пользователи, счётчики ключевых функций, входные компоненты adoption score и уровень на этот день.
Фиксация истории уровней (уровни меняются)
Не перезаписывайте «текущий уровень» и не теряйте контекст. Создайте таблицу account_tier_history:
account_id, tier_id\valid_from, valid_to (nullable для текущего)\source (billing, sales override)
Это позволит вычислять принятие когда аккаунт был Team, даже если он позднее апгрейдился.
Документируйте определения метрик
Запишите определения один раз и относитесь к ним как к продуктовым требованиям: что считается «активным пользователем», как вы приписываете события аккаунтам и как обрабатываете смену уровня в середине месяца. Это предотвратит ситуацию, когда два дашборда показывают разные истины.
План трекинга событий и основы инструментирования
Аналитика принятия будет такой же хорошей, как события, которые вы собираете. Начните с отображения небольшого набора «критических» действий, которые сигнализируют о реальном прогрессе для каждого уровня аккаунта, затем инструментируйте их последовательно на вебе, мобильных и бекенде.
Критические события для отслеживания
Сфокусируйтесь на событиях, которые отражают значимые шаги — а не на каждом клике. Практический стартовый набор:
signup_completed (создание аккаунта)\user_invited и invite_accepted (рост команды)\first_value_received (ваше «аха»-момент; определите явно)\key_feature_used (повторяемое действие, приносящее ценность; может быть несколько событий на фичу)\integration_connected (если интеграции увеличивают удержание)
Свойства событий (сделайте их удобными для запросов)
Каждое событие должно нести контекст для срезов по уровню и роли:
account_id (обязательно)\user_id (обязательно, когда вовлечён человек)\tier (фиксируйте на момент события)\plan (SKU биллинга, если релевантно)\role (например, owner/admin/member)\- Опционально, но полезно:
workspace_id, feature_name, source (web/mobile/api), timestamp
Конвенции именований, которые стоит соблюдать
Используйте предсказуемую схему, чтобы дашборды не превратились в словарь:
- События: строчные
snake_case глаголы, прошедшее время (report_exported, dashboard_shared)\
- Свойства: согласованные имена (
account_id, а не acctId)\
- События фич: либо отдельные события (
invoice_sent), либо единое событие с feature_name; выберите подход и придерживайтесь его.
Идентификация: кросс-девайс и мульти-воркспейс
Поддерживайте как анонимную, так и аутентифицированную активность:
- Назначьте
anonymous_id при первом визите, затем свяжите с user_id при логине.\
- В продуктах с несколькими рабочими пространствами всегда включайте
workspace_id и мапьте его на account_id сервер-сайдом, чтобы избежать клиентских багов.
Серверные события для надёжности
Инструментируйте системные действия на бекенде, чтобы ключевые метрики не зависели от браузеров или блокировщиков рекламы. Примеры: subscription_started, payment_failed, seat_limit_reached, audit_log_exported.
Эти серверные события также идеальны как триггеры для оповещений и рабочих процессов.
Пайплайн: приём, хранение и агрегация
Здесь трекинг превращается в систему: события приходят из приложения, очищаются, надёжно хранятся и превращаются в метрики, которые команда действительно может использовать.
Выберите путь приёма, подходящий продукту
Большинство команд используют смесь:
- SDK (клиент/сервер): лучше для согласованного, структурированного трекинга продуктовых событий.\
- HTTP API: хорошо для бэкенд-сервисов, партнёров или импорта событий из других систем.\
- Логи приложения: полезно, если у вас уже есть богатые логи; потребуется парсинг и жёсткие схемы.\
- Очередь сообщений (Kafka/SQS/PubSub): идеальна при большом объёме или когда нужна устойчивость и возможность повторного проигрыша.
Что бы вы ни выбрали, относитесь к приёму как к контракту: если событие непонятно — помещайте его в карантин, а не принимайте молча.
Нормализуйте рано: временные метки, идентификаторы и свойства
При приёме стандартируйте несколько полей, которые делают отчётность предсказуемой:
- Приводите все временные метки к UTC и храните оригинальную временную метку источника, когда это важно.\
- Мапьте идентификаторы к каноничной форме:
account_id, user_id, и (если нужно) workspace_id.\
- Валидируйте обязательные свойства (например,
event_name, tier, plan, feature_key) и добавляйте значения по умолчанию только когда это явно оправдано.
Храните сырые события отдельно от агрегатов
Решите, где будут жить сырые события в зависимости от стоимости и паттернов запросов:
- Warehouse (Snowflake/BigQuery/Redshift): проще для аналитики и ad-hoc запросов.\
- Object storage (S3/GCS) + query engine: дешевле при масштабировании, но потребует больше настройки.\
- Операционная БД: только для меньших объёмов; следите за производительностью.
Роллапы: запланированные джобы, соответствующие решениям
Постройте ежедневные/почасовые агрегирующие джобы, которые генерируют таблицы вроде:
- Ежедневные активные аккаунты по уровням\
- Счётчики принятия функций по уровням\
- Входные данные для adoption score на уровне аккаунта
Держите роллапы детерминированными, чтобы их можно было перезапустить при изменении определений уровней или при бэфилле.
Правила хранения (ретеншн)
Установите ясные правила хранения для:
- Сырье событий: дольше (например, 12–36 месяцев) для аудита и перерасчётов\
- Агрегатов: дольше или бессрочно, так как они компактны и питают дашборды и оповещения
Оценка принятия и агрегаты по уровням
Избегайте привязки с первого дня
Сохраняйте полный контроль: экспортируйте исходный код при передаче инженерам.
Adoption score даёт занятым командам одну цифру для мониторинга, но он работает лишь при простоте и объяснимости. Цель — 0–100, отражающий значимое поведение (не ванити), и разложимый по причинам изменения.
Простой объяснимый счёт 0–100
Начните с взвешенного чеклиста поведений, с ограничением в 100 очков. Держите веса стабильными хотя бы квартал, чтобы тренды были сопоставимы.
Пример весов (подстройте под продукт):
- Активация (40 pts): завершённые шаги онбординга, создан первый проект, приглашён коллега.\
- Основное использование (40 pts): использована основная функция на 3+ разных дня за последние 14 дней.\
- Расширение (20 pts): принята вспомогательная функция (например, интеграции, экспорт, утверждения).
Каждое поведение должно соответствовать явному правилу событий (например, «использовал основную функцию» = core_action в 3 отдельных дня). Когда счёт меняется, храните факторы вклада, чтобы можно было показать: «+15 потому что приглашено 2 пользователя» или «-10 потому что основное использование упало ниже 3 дней».
Роллапы по аккаунту и по уровню
Вычисляйте счёт на уровне аккаунта (ежедневный или еженедельный снимок), затем агрегируйте по уровням, используя распределения, а не только средние:
- Медианный счёт по уровню\
- 25й/75й перцентили (и опционально 10й/90й)\
- % аккаунтов выше порогов (например, 60+ = «здоровое принятие»)
Тренды без вводящих в заблуждение сравнений
Отслеживайте недельное изменение и 30‑дневное изменение по уровням, но избегайте смешения размеров уровней:
- Показывайте счётчики (например, 38 аккаунтов улучшились) вместе с процентами (например, 12% улучшились).
Это делает небольшие уровни читаемыми и не позволяет большим уровням доминировать в нарративе.
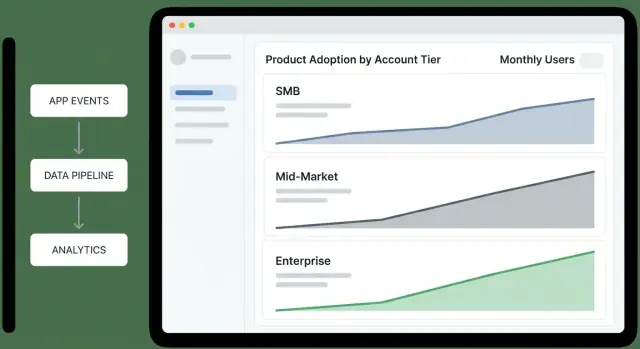
Дашборды: обзор по уровням и сводка для руководства
Дашборд обзора уровней должен позволять руководителю ответить за минуту: «Какие уровни улучшаются, какие скатываются и почему?» Рассматривайте его как экран для принятия решений, а не как музей отчётов.
Что показывать (и какой вопрос отвечает каждый график)
Воронка по уровням (Awareness → Activation → Habit): «Где аккаунты застревают по уровням?» Держите шаги согласованными с вашим продуктом (например, «приглашены пользователи» → «выполнено первое ключевое действие» → «еженедельно активны»).
Rate активации по уровням: «Достигают ли новые или реактивированные аккаунты первой ценности?» Сопровождайте ставку знаменателем (сколько аккаунтов имели право), чтобы лидеры могли отличать сигнал от шума малой выборки.
Удержание по уровням (например, 7/28/90 дней): «Остаются ли аккаунты активными после первого выигрыша?» Покажите простую линию для каждого уровня; избегайте чрезмерной сегментации на обзорной странице.
Глубина использования (широта функций): «Внедряют ли они несколько областей продукта или остаются поверхностными?» Стековая диаграмма по уровням хорошо работает: % использующих 1 область, 2–3 области, 4+ областей.
Сравнения, подталкивающие к действию
Добавьте два сравнения везде:
- Эта неделя vs прошлый период (или последние 7 дней vs предыдущие 7) для быстрого фидбэка.\
- Уровень vs уровень, чтобы заметить несоответствия (например, SMB лучше Enterprise по активации).
Используйте одинаковые делты (абсолютное изменение в процентах), чтобы руководители могли быстро просматривать.
Фильтры, которые не ломают историю
Ограничьте фильтры, делайте их глобальными и «липкими»:
- Диапазон времени (предустановленные окна плюс кастом)\
- Область продукта (для контекста глубины использования)\
- Регион (чтобы выявить эффекты релиза или рынка)\
- Владелец аккаунта (для ответственности GTM)
Если фильтр меняет определения метрик, не предлагайте его здесь — отправляйте в drill-down представления.
«Топ драйверов» по уровню
Включите небольшую панель для каждого уровня: «Что было связано с высоким принятием в этот период?» Примеры:
- Топ-3 функции/события, коррелирующие с высоким adoption score\
- Самая большая ступень вылета в воронке\
- Аккаунты с наибольшими недельными изменениями (положительными и отрицательными)
Держите объяснимость: предпочтительнее «Аккаунты, настроившие X в первые 3 дня, удерживаются на 18 п.п. лучше», чем непрозрачные модельные выводы.
Полезная компоновка
Поместите KPI-карты по уровням вверху (активация, удержание, глубина), один экран трендовых графиков в середине и драйверы + следующие шаги внизу. Каждый виджет должен отвечать на один вопрос — иначе ему не место в сводке руководства.
Drill-down: от уровня до конкретных аккаунтов
Обзор по уровню полезен для приоритизации, но реальная работа происходит, когда можно кликнуть и понять почему уровень изменился и кому нужно внимание. Проектируйте drill-down как направленный путь: уровень → сегмент → аккаунт → пользователь.
Уровень → Сегмент: сузьте вопрос
Начните с таблицы обзора уровня, затем позвольте пользователям нарезать её по смысловым сегментам без создания кастомных отчётов. Частые фильтры:
- Статус онбординга (не начат / в процессе / завершён)\
- Отрасль, план, регион, стадия жизненного цикла\
- «В риске» vs «здоров» по вашему adoption score
Каждая страница сегмента должна ответить: «Какие аккаунты двигают счёт этого уровня вверх или вниз?» Включайте ранжированный список аккаунтов с изменением счёта во времени и топовыми факторами вклада.
Профиль аккаунта: таймлайн, счёт, вехи
Профиль аккаунта должен ощущаться как «дело»:
- Таймлайн использования (последние 30/90 дней): ключевые события, активные дни, важные точки взаимодействия с функциями\
- Adoption score с простым разбором (например, активация, широта, глубина)\
- Вехи: первое ключевое действие, принятие фичи X, приглашение коллег, достижение порога Y
Держите представление сканируемым: показывайте дельты («+12 за неделю») и аннотируйте всплески функцией/событием, их вызвавшим.
Drill-down по пользователю и когортные представления
Со страницы аккаунта перечислите пользователей по недавней активности и роли. Клик по пользователю показывает его использование функций и последнее время онлайна.
Добавьте когортные представления, чтобы объяснять паттерны: месяц регистрации, программа онбординга и уровень при регистрации. Это помогает CS сравнивать похожие группы, а не смешивать новые и зрелые аккаунты.
Принятие функций по уровням + экспорт для рабочих процессов
Включите представление «Кто что использует» по уровню: доля внедрения, частота и тренды по фичам, с кликабельным списком аккаунтов, использующих (или не использующих) каждую фичу.
Для CS и Sales добавьте опции экспорта/шаринга: экспорт CSV, сохранённые представления и sharable внутренние ссылки (например, /accounts/{id}), которые открываются с применёнными фильтрами.
Оповещения и действенные рабочие процессы по уровням
Вносите изменения, не подрывая доверие
Экспериментируйте безопасно с помощью снимков и отката при изменении правил метрик.
Дашборды хороши для понимания принятия, но команды действуют, когда их подталкивают в нужный момент. Оповещения должны быть привязаны к уровню аккаунта, чтобы CS и Sales не засорялись шумом низкой ценности — или, что хуже, не пропустили критические проблемы у самых ценных аккаунтов.
Определите сигналы риска, зависящие от уровня
Начните с небольшого набора сигналов «что-то не так»:
- Падение использования: значимое снижение weekly active users, ключевых событий или сессий относительно базового уровня аккаунта.\
- Застой онбординга: отсутствие прогресса за контрольные точки (например, нет созданных проектов, не подключена интеграция) в ожидаемый интервал.\
- Низкая активация: аккаунт не достигает минимального порога «аха»-использования после регистрации или покупки.
Сделайте эти сигналы чувствительными к уровню. Например, для Enterprise alert может срабатывать при 15% недельного падения в ключовом workflow, а для SMB — при 40%, чтобы избежать шума из спорадического использования.
Определите сигналы расширения по уровням
Оповещения расширения должны выделять аккаунты, набирающие ценность:
- Появление power users: несколько пользователей регулярно выполняют высокоценные рабочие процессы.\
- Широта фич: принятие в нескольких ключевых областях (не одна фича).\
- Сильный рост: увеличение числа мест, отправленных приглашений или стабильный рост активных пользователей.
Опять же, пороги зависят от уровня: один power user может значить для SMB, а Enterprise требует мульти‑командного охвата.
Уведомления, которые побуждают к действию
Маршрутизируйте оповещения туда, где выполняется работа:
- Slack/email для реальных сигналов (например, застой онбординга у топ-аккаунта).\
- Недельный дайджест для менее срочных инсайтов (например, аккаунты, растущие по широте фич).
Делайте payload действительным: имя аккаунта, уровень, что изменилось, окно сравнения и ссылка на drill-down (например, /accounts/{account_id}).
Плейбуки: что делать при срабатывании оповещения
Каждое оповещение нуждается в владельце и коротком плейбуке: кто отвечает, первые 2–3 проверки (свежесть данных, недавние релизы, изменения прав администратора) и рекомендованные шаги по аутричу или in-app подсказкам.
Документируйте плейбуки рядом с определениями метрик, чтобы ответы оставались согласованными, а оповещения — заслуживали доверия.
Качество данных, мониторинг и управление метриками
Если метрики принятия влияют на решения по уровням (аутрич CS, ценовые разговоры, продуктовые ставки), данные, которые их питают, должны иметь страховочные механизмы. Набор проверок и практик управления предотвратит «загадочные провалы» в дашбордах и сохранит единое понимание метрик.
Валидация на границе
Валидируйте события как можно раньше (SDK клиента, API шлюз или ingestion worker). Отклоняйте или помещайте в карантин события, которым нельзя доверять.
Реализуйте проверки типа:
- Отсутствует
account_id или user_id (или значения, которых нет в таблице аккаунтов)\
- Неверные значения
tier (вне утверждённого enum)\
- Невозможные временные метки (далёкое будущее/прошлое) и отсутствие обязательных свойств для ключевых событий
Храните таблицу карантина, чтобы можно было исследовать плохие события без загрязнения аналитики.
Мониторинг объёма и свежести
Отслеживание принятия чувствительно ко времени; поздние события искажают weekly active и роллапы уровней. Мониторьте:
- Объём событий по типу и уровню (внезапные всплески/падения)\
- Свежесть и распределение задержек (например, p95 задержки инжеста)\
- Здоровье пайплайна (упавшие джобы, работающие бэфиллы, сломанные зависимости)
Маршрутируйте мониторы в on-call канал, а не всем подряд.
Дубликаты, ретраи и идемпотентность
Ретраи случаются (мобильные сети, повторная доставка webhook, повторный проигрыш батчей). Делайте ingestion идемпотентным с помощью idempotency_key или стабильного event_id, и дедупьте в окне времени.
Ваши агрегации должны быть безопасны для повторного запуска без двойного подсчёта.
Управление метриками: одно значение — один владелец
Создайте глоссарий, который определяет каждую метрику (входы, фильтры, окно времени, правила атрибуции уровней) и рассматривайте его как единственный источник правды. Ссылайтесь из дашбордов и документации на этот глоссарий (например, /docs/metrics).
Добавьте аудиторские логи для изменений определений метрик и правил scoring — кто что изменил, когда и почему — чтобы сдвиги в трендах можно было быстро объяснить.
Приватность, безопасность и контроль доступа
Упростите оценку внедрения
Выпустите объяснимую шкалу внедрения 0–100 с сохранёнными факторами влияния.
Аналитика принятия полезна лишь при доверии. Самый безопасный подход — проектировать трекинг так, чтобы отвечать на вопросы о принятии, собирая минимально необходимый набор чувствительных данных, и делать «кто что видит» первоклассной фичей.
Минимизируйте персональные данные (по дизайну)
Начните с идентификаторов, достаточных для инсайтов принятия: account_id, user_id (или псевдоним), временная метка, фича и небольшой набор свойств поведения (план, уровень, платформа). Избегайте хранения имен, email-адресов, свободного текста или чего-либо, что может содержать секреты.
Если нужен анализ на уровне пользователя, храните идентификаторы отдельно от PII и объединяйте только при необходимости. Рассматривайте IP и device идентификаторы как чувствительные; если они не нужны для scoring — не храните их.
Роли, права и безопасные дефолты
Определите ясные роли доступа:
- Exec/Leadership: агрегаты по аккаунтам и уровням\
- CS/Sales: детали аккаунта; ограниченные пользовательские представления при необходимости\
- Product/Analytics: глубокие пользовательские исследования с аудиторским следом\
- Admin: конфигурация, правила ретеншна и удаление
По умолчанию показывайте агрегированные представления. Делайте drill-down по пользователю явным правом, и скрывайте чувствительные поля (email, полные имена, внешние id), если роль действительно не требует их видеть.
Ретеншн, удаление и согласие
Поддерживайте запросы на удаление, умея удалять историю событий пользователя (или анонимизировать её) и удалять данные аккаунта по окончании контракта.
Реализуйте правила хранения (например, сырые события N дней, агрегаты дольше) и документируйте их в политике. Фиксируйте согласия и обязанности по обработке данных там, где это применимо.
Выбор архитектуры и практическая дорожная карта
Самый быстрый путь к ценности — выбрать архитектуру, соответствующую тому, где уже живут ваши данные. Вы всегда можете эволюционировать — главное дать доверенные инсайты по уровням людям.
Два распространённых подхода к сборке
Warehouse-first analytics: события текут в хранилище (BigQuery/Snowflake/Postgres), затем вы считаете метрики и отдаёте их лёгкому веб-приложению. Идеально, если вы уже живёте в SQL, у вас есть аналитики, или вы хотите единый источник правды для других отчётов.
App-first analytics: веб-приложение пишет события в собственную БД и считает метрики в приложении. Это может быть быстрее для небольшого продукта, но его легко перерасти при увеличении объёма событий и потребности в исторической переработке.
Практический дефолт для большинства SaaS-команд — warehouse-first с небольшой операционной БД для конфигурации приложения (уровни, определения метрик, правила оповещений).
Основные компоненты (держите просто)
- Web UI: обзор по уровням + страницы drill-down по аккаунту.\
- API: отдаёт пред-агрегированные метрики, списки аккаунтов и фильтры.\
- Warehouse / analytics DB: сырые события + смоделированные таблицы для ежедневных метрик принятия.\
- Job runner: запланированные трансформации (ежедневно/ежечасно), бэфиллы и scoring.
Buy vs build решения, экономящие недели
- Графики: начните с проверенной библиотеки визуализаций (или встройте BI-инструмент на раннем этапе), вместо того чтобы строить примитивы визуализации с нуля.\
- Аутентификация: используйте установленного провайдера (SSO, роли), чтобы избежать проблем с безопасностью.\
- Сбор событий: используйте доверенный SDK или gateway; стройте кастомный сборщик только при строгих требованиях.
MVP-дорожная карта (2–4 недели)
Выпустите первую версию с:
- 3–5 метрик (например, активные аккаунты, использование ключевой фичи, adoption score, еженедельное удержание, time-to-first-value).\
- Одной обзорной страницей по уровням: adoption score по уровням + тренд во времени.\
- Одним представлением аккаунта: текущий уровень, последняя активность, топ использованных фич и простое объяснение «почему такой счёт».
План итераций без потери доверия
Добавьте каналы обратной связи рано: позвольте Sales/CS пометить «это выглядит неверно» прямо из дашборда. Версионируйте определения метрик, чтобы менять формулы, не переписывая историю молча.
Внедряйте постепенный rollout (одна команда → вся организация) и ведите changelog обновлений метрик в приложении (например, /docs/metrics), чтобы стейкхолдеры всегда знали, что смотрят.
Где вписывается Koder.ai (быстрая прототипизация без локинга)
Если вы хотите перейти от «специ» к рабочему внутреннему приложению быстро, vibe-coding-подход может помочь — особенно на этапе MVP, когда вы валидируете определения, а не совершенствуете инфраструктуру.
С Koder.ai команды могут прототипировать веб-приложение для аналитики принятия через чат-интерфейс, при этом генерируя реальный, редактируемый код. Это хорошо подходит для такого проекта, поскольку объём работ перекрёстный (React UI, API-слой, модель данных в Postgres и запланированные роллапы) и часто быстро меняется по мере согласования определений.
Типичный рабочий процесс:
- Используйте Planning Mode для сопоставления модели уровней, схемы событий и вопросов дашборда в план реализации.\
- Сгенерируйте React UI и Go бэкенд, опираясь на PostgreSQL для конфигурационных таблиц (уровни, определения метрик, правила оповещений).\
- Экспортируйте исходный код, когда будете готовы передать его инженерам, и используйте snapshots/rollback для безопасной итерации при изменении определений метрик.
Поскольку Koder.ai поддерживает деплой/хостинг, кастомные домены и экспорт кода, это практичный способ получить убедительный внутренний MVP, сохраняя при этом открытую возможность выбора долгосрочной архитектуры (warehouse-first vs app-first).