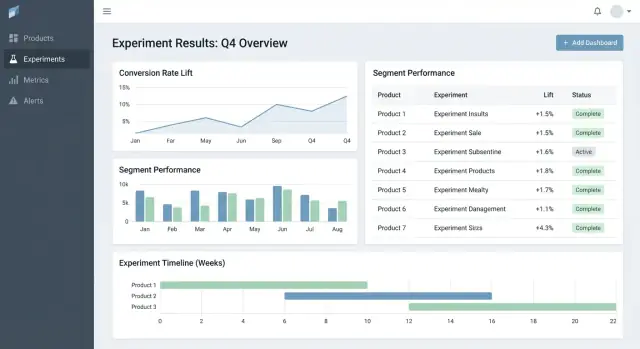
Что должно решать это веб‑приложение
Большинство команд не терпят неудач из‑за отсутствия идей — они терпят их из‑за того, что результаты разбросаны. В одном продукте есть графики в аналитическом инструменте, в другом — таблица, в третьем — слайды со скриншотами. Через несколько месяцев никто не может ответить на простые вопросы вроде «Уже тестировали это?» или «Какая версия победила и по какому определению метрики?».
Ключевая проблема: фрагментированные результаты и неединственная правда
Трекер экспериментов должен централизовать что тестировали, зачем, как измеряли и что произошло — для разных продуктов и команд. Без этого команды тратят время на восстановление отчётов, споры о цифрах и повторные запуски старых тестов, потому что выводы нельзя найти по поиску.
Для кого это и что нужно каждой группе
Это не просто инструмент для аналитиков.
- Product‑менеджерам нужен быстрый доступ к исходам, уровню доверия и статусу решения.
- Аналитикам нужно надёжное место для документирования допущений, определений метрик и оговорок.
- Инженерам нужна ясность по фич‑флагам, вариантам и условиям развёртывания.
- Руководству нужен согласованный взгляд на влияние по продуктам без специальных презентаций.
Результаты, которые стоит оптимизировать
Хороший трекер приносит бизнес‑ценность, делая возможным:
- Более быстрые решения (меньше времени на поиск ссылок и согласований)
- Меньше ошибок в отчётах (единый источник «итоговых чисел»)
- Совместное накопление знаний (поиск по истории побед, поражений и нейтральных тестов)
Чёткие границы ответственности
Явно укажите: это приложение главным образом для отслеживания и отчётности результатов, а не для полного исполнения экспериментов. Оно может ссылаться на существующие инструменты (фич‑флаги, аналитику, хранилище данных), при этом владеть структурированной записью эксперимента и его окончательной интерпретацией.
Требования: минимально жизнеспособный трекер экспериментов
MVP трекера должен отвечать на два вопроса без рытья по документам и таблицам: что мы тестируем и что мы узнали. Начните с небольшого набора сущностей и полей, которые работают для всех продуктов, и расширяйте только тогда, когда команды действительно почувствуют боль.
Базовые сущности, которые нужно поддержать
Держите модель данных простой, чтобы каждая команда использовала её одинаково:
- Product: поверхность (приложение/сайт/API), куда вносится изменение.
- Experiment: одна гипотеза и одно решение.
- Variant: контроль и один или несколько тестовых вариантов.
- Metric: именованное измерение с владельцем и определением.
- Segment: опциональные срезы аудитории (новые пользователи, платящие пользователи, регион) для отчётности.
Типы экспериментов (начните с простого, оставайтесь гибкими)
Поддерживайте самые распространённые шаблоны с первого дня:
- A/B tests (контроль vs вариант)
- Multivariate tests (несколько вариантов)
- Feature flag rollouts (распространение по проценту)
Даже если rollouts вначале не используют формальную статистику, их отслеживание рядом с экспериментами помогает не повторять «тесты» без записи.
Минимальные поля для каждого эксперимента
При создании требуйте только то, что нужно, чтобы потом интерпретировать тест:
- Hypothesis (что меняется, для кого и почему)
- Owner (один ответственный)
- Start/end dates (плановые и фактические)
- Targeting (правила попадания) и allocation (распределение трафика)
- Links на флаг/тикет/спецификацию (относительные URL вроде /projects/123)
Критерии успеха и статус решения
Сделайте результаты сопоставимыми, заставив структуру:
- Primary metric (главная метрика успеха)
- Guardrails (метрики, которые не должны ухудшаться)
- Decision status: proposed → running → analyzed → shipped/rolled back → archived
Если реализовать хотя бы это, команды смогут находить эксперименты, понимать настройки и фиксировать исходы — даже до добавления продвинутой аналитики или автоматизации.
Модель данных, работающая между продуктами
Кросс‑продуктовый трекер выигрывает или проигрывает на своей модели данных. Если ID конфликтуют, метрики расходятся, или сегменты непоследовательны, дашборд может выглядеть «правильно», но рассказывать неверную историю.
Выберите стабильные идентификаторы (и придерживайтесь их)
Начните с ясной стратегии идентификаторов:
- product_id: стабилен при переименовании (не используйте отображаемые имена как ключи)
- experiment_key: читабельный слаг (например,
checkout_free_shipping_banner) плюс неизменяемый experiment_id
- variant_key: стабильные ярлыки вроде
control, treatment_a
Это позволит сравнивать результаты между продуктами без угадывания, одинаковы ли «Web Checkout» и «Checkout Web».
Основные коллекции/таблицы
Держите ядро сущностей небольшим и явным:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (или anonymous_id), variant_key, assigned_at
- metric_defs: имя метрики, логика числителя/знаменателя, unit (user/session/order), owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Даже если расчёты выполняются в другом месте, хранение выходных данных (results) обеспечивает быстрые дашборды и надёжную историю.
Временные окна и версионирование
Метрики и эксперименты не статичны. Смоделируйте:
- time windows (например, «первые 7 дней после назначения», «календарные недели»)
- versioned metric definitions: когда меняется вычисление метрики, создавайте версию вместо правки старой
Это предотвращает ситуацию, когда результаты прошлых экспериментов меняются после обновления логики KPI.
Сегменты и аудит‑трейл
Планируйте согласованные сегменты между продуктами: страна, устройство, уровень тарифа, новые против возвращающихся.
Наконец, добавьте audit trail, фиксирующий, кто и когда что изменил (статусы, распределение трафика, обновления определений метрик). Это важно для доверия, ревью и управления.
Определения метрик и согласованные вычисления
Если трекер неправильно считает метрики (или делает это по‑разному для разных продуктов), результат — просто мнение с графиком. Самый быстрый способ избежать этого — относиться к метрикам как к разделяемым активам продукта, а не как к одноразовым SQL‑сниппетам.
Постройте канонический каталог метрик
Создайте каталог метрик — единый источник правды для определений, логики вычисления и владельцев. Каждая запись должна включать:
- Определение на понятном языке (какое решение поддерживает)
- Владельца (ответственного за изменения)
- Точную формулу и требуемые события/поля
- Правила включения/исключения (внутренние пользователи, боты, возвраты)
- Допустимые уровни агрегации и поддерживаемые продукты
Держите каталог рядом с рабочими процессами (например, ссылкой из формы создания эксперимента) и версионируйте его, чтобы можно было объяснить исторические результаты.
Стандартизируйте уровни агрегации
Решите заранее, какая «единица анализа» у каждой метрики: per user, per session, per account или per order. Конверсия «на пользователя» может отличаться от «на сессию» даже если оба расчёта корректны.
Чтобы снизить путаницу, храните выбор уровня агрегации в определении метрики и требуйте его при создании эксперимента. Не разрешайте командам выбирать единицу произвольно.
Обработка отложенных конверсий и атрибуции
Многие продукты имеют окна конверсии (например, регистрация сегодня, покупка в течение 14 дней). Определите правила атрибуции последовательно:
- Когда начинается отсчёт (время экспозиции, первый визит, время назначения)?
- Что считать конверсией, если пользователь подвергался экспозиции несколько раз?
- Как учитывать кросс‑девайсные или кросс‑продуктовые пути?
Делайте эти правила видимыми на дашборде, чтобы читатель понимал, что он видит.
Храните сырые счётчики и вычисленные статистики
Для быстрых дашбордов и аудита храните оба уровня:
- Сырые счётчики (exposures, converters, суммы revenue, входы для дисперсии)
- Вычисленные статистики (lift, доверительные интервалы, p‑values)
Это даёт быстрый рендер и позволяет пересчитать при изменении определений.
Правила именования предотвращают разрастание метрик
Примите стандарт именования, кодирующий смысл (например, activation_rate_user_7d, revenue_per_account_30d). Требуйте уникальных ID, поддерживайте алиасы и помечайте почти‑дубликаты при создании метрик, чтобы каталог оставался чистым.
Сбор данных: события, пайплайны и проверки качества
Трекер экспериментов лишь так же надёжен, как данные, которые он получает. Цель — надёжно ответить на два вопроса для каждого продукта: кто был подвергнут какому варианту, и что этот человек сделал потом? Всё остальное (метрики, статистика, графики) опирается на это.
Выберите подход к приёму данных
Команды обычно выбирают один из шаблонов:
- Event stream (near real-time): хорошо для быстрого отображения и дебага. Требует большей инженерной зрелости для стабильности.
- Daily batch: проще в эксплуатации и дешевле. Подходит, когда решения не нужны в почасовом режиме.
- Hybrid: стриминг экспозиций и критичных событий (чтобы быстро валидировать назначения), пакетная загрузка остального для полноты и контроля затрат.
Какой бы подход вы ни выбрали, стандартизируйте минимальный набор событий: exposure/assignment, ключевые conversion events и контекст для объединения (user ID/device ID, timestamp, experiment ID, variant).
Соотнесение продуктовых событий с метриками (и валидировать полноту)
Определите чёткое соответствие от сырых событий к метрикам, которые трекер будет отчётывать (например, purchase_completed → Revenue, signup_completed → Activation). Поддерживайте это соответствие для каждого продукта, но сохраняйте единые имена по продуктам, чтобы дашборд корректно сравнивал одно с другим.
Валидируйте полноту рано:
- Убедитесь, что каждая экспозиция содержит experiment ID и variant.
- Проверьте, что события конверсии включают те же идентификационные поля, что и экспозиции для джоина.
- Следите за потерями событий между клиентом, сервером и хранилищем (мобильные SDK часто виновники).
Проверки качества данных, которые стоит автоматизировать
Создайте проверки, работающие при каждой загрузке и громко сигналящие о проблемах:
- Отсутствующие события экспозиции: конверсии без прежней экспозиции (часто инструментальные баги или несоответствие идентичностей).
- Смещение распределения: варианты получают 70/30 вместо ожидаемых 50/50 (возможные баги таргетинга).
- Проверка временных меток: экспозиции позже конверсий или большие задержки, указывающие на проблемы с часами.
Показывайте эти предупреждения в приложении как предупреждения, привязанные к эксперименту, а не прячьте в логах.
Бэкфиллы и перерасчёты
Пайплайны меняются. Когда вы исправляете баг инструментирования или логику дедупа, придётся пересчитать исторические данные, чтобы метрики и KPI оставались согласованными.
Планируйте:
- версионированные трансформации (чтобы знать, какая логика произвела результат)
- безопасные бэкфиллы (ограничение по дате/продукту/эксперименту)
- аудит‑записи о перерасчёте
Документируйте интеграции
Рассматривайте интеграции как фичи продукта: задокументируйте поддерживаемые SDK, схемы событий и шаги по устранению неполадок. Если у вас есть раздел с документацией, ссылку делайте относительной, например /docs/integrations.
Статистика и вычисления результатов, которым можно доверять
Сохраняйте полный контроль над кодом
Экспортируйте исходный код в любой момент и продолжайте разработку в своём репозитории.
Если люди не доверяют цифрам, они не будут пользоваться трекером. Цель — не впечатлить математикой, а сделать решения повторимыми и защищаемыми в разных продуктах.
Выберите один статистический «диалект» и придерживайтесь его
Решите заранее, будете ли вы показывать frequentist результаты (p‑values, confidence intervals) или bayesian (вероятность улучшения, credible intervals). Оба подхода работают, но смешивание их между продуктами вводит путаницу («Почему этот тест показывает 97% шанс победы, а тот — p=0.08?»).
Практическое правило: выбирайте подход, понятный вашей организации, затем стандартизируйте терминологию, значения по умолчанию и пороги.
Точно определите, что показывать в UI
Минимум для представления результатов:
- Lift (абсолютный и/или относительный) относительно контроля
- Интервал (confidence/credible interval) как диапазон, а не только точечная оценка
- Сила доказательств (p‑value для frequentist или вероятность опередить контроль для Bayesian)
Также показывайте analysis window, units counted (users, sessions, orders) и версию определения метрики, использованную в анализе. Эти «детали» отделяют согласованную отчётность от бесконечных дебатов.
Множественные сравнения и политика «peeking»
Если команды тестируют много вариантов, много метрик или проверяют результаты ежедневно, вероятность ложных находок увеличивается. Приложение должно кодировать политику, а не оставлять выбор за каждой командой:
- Multiple comparisons: решите, корректировать ли (например, контролировать false discovery rate) или помечать результаты как «неоткорректированные, exploratory».
- Repeated peeking: либо (1) отговаривайте от этого фиксированной конечной датой и статусом «finalized», либо (2) поддерживайте последовательные методы и показывайте подсказки «safe‑to‑stop».
Guardrails, ловящие распространённые ошибки
Добавьте автоматические флаги рядом с результатами, а не в логах:
- Sample Ratio Mismatch (SRM): предупреждение, когда распределение трафика отклоняется от ожидаемого
- Anomaly detection: пометка резких провалов/всплесков в трафике, конверсиях или доходе, что может указывать на слом трекинга, даунтайм или ботов
Простые объяснения на понятном языке
Рядом с цифрами давайте краткое объяснение для нетехнического читателя, например: “Лучшая оценка +2.1% lift, но истинный эффект может быть в диапазоне от −0.4% до +4.6%. У нас недостаточно доказательств для объявления победителя.”
UX и дашборды для быстрых решений
Хорошие инструменты для экспериментов помогают ответить на два вопроса быстро: Что смотреть дальше? и Что нам с этим делать? Интерфейс должен минимизировать поиск контекста и делать «состояние решения» явным.
Ключевые страницы для рабочего процесса
Начните с трёх страниц, покрывающих большую часть сценариев:
- Experiments list: сортируемая очередь для всей организации (или по продукту).
- Experiment detail: единый источник правды для настроек, результатов и решения.
- Product overview: сводка активных тестов, недавних решений и состояния метрик для продукта.
На списке и странице продукта сделайте фильтры быстрыми и «липкими»: product, owner, date range, status, primary metric, segment. Люди должны за секунды сужать выдачу до «эксперименты Checkout, ответственная Maya, в этом месяце, primary metric = conversion, segment = new users».
Состояния решения, которым можно доверять
Обращайтесь со статусом как с контролируемым словарём, а не свободным текстом:
Draft → Running → Stopped → Shipped / Rolled back
Показывайте статус везде (строки списка, заголовок детальной страницы, ссылки) и записывайте, кто его поменял и почему. Это предотвращает «тихие запуски» и неясные исходы.
Таблица результатов, которая делает решение очевидным
На странице эксперимента выведите компактную таблицу результатов по метрикам:
- Baseline
- Variant
- Lift
- Uncertainty (confidence/credible interval)
- Notes (например, оговорки по инструментированию, особенности сегмента)
Держите подробные графики в секции «More details», чтобы не перегружать принимающих решения.
Шеринг и экспорт без потери контроля
Добавьте CSV export для аналитиков и shareable links для стейкхолдеров, но соблюдайте права доступа: ссылки должны уважать роли и продуктовые разрешения. Простая кнопка «Copy link» плюс «Export CSV» покрывает большинство потребностей в совместной работе.
Разрешения, приватность и управление
Вносите изменения безопасно
Экспериментируйте с изменениями схемы и рабочих процессов и откатывайтесь, если что‑то ломается.
Если трекер покрывает несколько продуктов, управление доступом и аудируемость — не опция. Это то, что делает инструмент безопасным для корпоративного использования и надёжным при ревью.
Ролевой доступ (RBAC)
Начните с простого набора ролей и держите их согласованными по всему приложению:
- Viewer: только чтение экспериментов, результатов и дашбордов.
- Editor: создание/редактирование экспериментов, загрузка сопроводительных материалов, изменение статуса (draft → running → concluded).
- Admin: управление пользователями, разрешениями, определениями метрик, правилами хранения и интеграциями.
Делайте решения RBAC централизованными (один уровень политики), чтобы UI и API применяли одинаковые правила.
Разрешения на уровне продукта и строк
Многим организациям нужен доступ в рамках продукта: команда A видит эксперименты Product A, но не Product B. Смоделируйте это явно (например, user ↔ product memberships) и фильтруйте все запросы по продукту.
Для чувствительных случаев (партнёры, регулируемые сегменты) добавляйте row‑level ограничения поверх продуктовой фильтрации. Практичный подход — тегировать эксперименты/срезы по уровню чувствительности и требовать дополнительного права для просмотра.
Аудит‑трейл: изменения и доступ
Логируйте два потока отдельно:
- Change logs: кто редактировал эксперимент, определение метрики или решение — что и когда изменено.
- Access logs: кто просматривал или экспортировал результаты (особенно важны для чувствительных экспериментов).
Показывайте историю изменений в UI для прозрачности и держите более глубокие логи для расследований.
Правила хранения и удаления
Определите правила хранения для:
- Метаданных эксперимента (гипотеза, владельцы, даты, заметки по решению)
- Вычисленных результатов (эффекты, интервалы, флаги значимости)
Делайте хранение настраиваемым по продукту и чувствительности. Когда надо удалить данные, сохраняйте минимальную «тombstone»‑запись (ID, время удаления, причина), чтобы не нарушать целостность отчётности, но не держать чувствительный контент.
Фичи рабочего процесса: от идеи до библиотеки знаний
Трекер становится действительно полезным, когда покрывает полный цикл эксперимента, а не только итоговый p‑value. Workflow‑фичи превращают разбросанные документы, тикеты и графики в повторяемый процесс, улучшающий качество и делающий выводы легко повторно используемыми.
Цикл жизни: идея → ревью → запуск → пост‑мортем
Моделируйте эксперименты как последовательность состояний (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Каждое состояние должно иметь чёткие «exit criteria», чтобы эксперименты не выходили в прод без обязательных элементов: гипотеза, primary metric и guardrails.
Согласования не обязаны быть тяжёлыми. Простой шаг reviewer (например, продукт + дата) и аудит‑трейл, кто и что утвердил, помогают избежать лишних ошибок. По завершении требуйте короткого post‑mortem перед пометкой «Published», чтобы контекст и интерпретация были зафиксированы.
Шаблоны, стандартизирующие мышление
Добавьте шаблоны для:
- Experiment brief (цель, гипотеза, аудитория, метрики успеха, guardrails, план rollout)
- Analysis notes (источники данных, исключения, sanity checks, интерпретация, риски)
Шаблоны снижают трение «чистого листа» и ускоряют ревью, потому что все знают, где искать нужную информацию. Делайте их редактируемыми по продукту, сохраняя общий каркас.
Выводы: связывайте всё и делайте поиск удобным
Эксперименты редко живут изолированно — людям нужен окружающий контекст. Позвольте прикреплять ссылки на тикеты/спеки и связанные отчёты (например: /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Храните структурированные поля «Learning», например:
- Что изменили (решение)
- Что узнали (insight)
- Что делать дальше (follow‑up)
Оповещения по guardrails и изменяющимся результатам
Поддерживайте нотификации, когда guardrails ухудшаются (например, error rate, отмены) или когда результаты существенно меняются после поздних данных или перерасчёта метрик. Делайте оповещения действенными: показывайте метрику, порог, временной промежуток и владельца для подтверждения или эскалации.
Библиотека для повторного использования прошлых результатов
Предоставьте библиотеку, фильтруемую по продукту, области фичи, аудитории, метрике, исходу и тегам (например, “pricing”, “onboarding”, “mobile”). Добавьте подсказки «similar experiments» на основе общих тегов/метрик, чтобы команды не запускали повторно то же самое, а строили на предыдущем опыте.
Архитектура и варианты стека технологий
Вам не нужен «идеальный» стек, чтобы построить трекер экспериментов — но нужны чёткие границы: где хранятся данные, где выполняются вычисления и как команды получают доступ к результатам.
Практический базовый стек
Для многих команд простая и масштабируемая связка выглядит так:
- Frontend: React (или Vue) для дашбордов и воркфлоу
- Backend API: Node.js/Express, Python/FastAPI или Java/Spring — выбирайте то, что команда поддерживает
- Database: Postgres для данных приложения (эксперименты, определения метрик, разрешения)
- Analytics warehouse: BigQuery/Snowflake/Redshift для событий и тяжёлых агрегаций
Такое разделение держит транзакционные сценарии быстрыми и даёт склададанным решать объёмы вычислений.
Если хотите быстро прототипировать UI воркфлоу (experiments list → detail → readout) до полной инженерной реализации, платформа для быстрой генерации кода вроде Koder.ai может помочь с рабочей основой React + backend по спецификации чата. Это удобно для получения сущностей, форм, RBAC‑каркаса и CRUD, а затем для итерации с аналитикой.
Где должны выполняться вычисления метрик?
Обычно есть три варианта:
- Warehouse‑first: SQL‑модели вычисляют метрики и таблицы с результатами. Приложение в основном читает их.
- Backend jobs: воркер вычисляет результаты по расписанию или при изменениях эксперимента.
- Hybrid: канонические агрегации в хранилище, с бэкенд‑пост‑обработкой (форматирование, guardrails, кэширование).
Warehouse‑first часто проще, если команда данных уже владеет доверенным SQL. Backend‑heavy оправдан, когда нужны низкая задержка обновлений или кастомная логика, но это повышает сложность приложения.
Производительность: кеш и предвычисления
Дашборды по экспериментам часто повторяют одни и те же запросы. Планируйте:
- Precompute rollups (ежедневные агрегаты метрик per experiment/variant/segment)
- Кэширование тяжёлых запросов на уровне API (например, Redis) с понятными правилами инвалидизации
- Используйте materialized views или запланированные таблицы в хранилище для общих дашбордов
Мульти‑тенантность vs single‑tenant
Если вы поддерживаете много продуктов/бизнес‑единиц, решите рано:
- Single‑tenant (shared schema): проще в эксплуатации, но требует строгой фильтрации прав доступа
- Multi‑tenant: отдельные схемы/проекты на продукт/команду для лучшей изоляции, но дороже в администрировании
Компромисс: общая инфраструктура с сильной моделью tenant_id и принудительным row‑level доступом.
Определите базовые API
Держите API‑поверхность маленькой и явной. Большинству систем нужны эндпоинты для experiments, metrics, results, segments и permissions (и read‑операции, пригодные для аудита). Это упрощает добавление новых продуктов без переделки инфраструктуры.
Тестирование, мониторинг и надёжная эксплуатация
Быстро смоделируйте ключевые сущности
Быстро превратите продукты, эксперименты, варианты, метрики и результаты в рабочие экраны.
Трекер полезен только пока ему доверяют. Доверие приходит от дисциплинированного тестирования, понятного мониторинга и предсказуемой эксплуатации — особенно когда многие продукты и пайплайны кормят одни и те же дашборды.
Обсервабилити, соответствующая использованию
Начните со структурированного логирования для каждого критичного шага: приём событий, назначение, агрегации метрик и вычисление результатов. Включайте идентификаторы вроде product, experiment_id, metric_id, pipeline run_id, чтобы техподдержка могла проследить значение до входных данных.
Добавьте метрики системы (latency API, время джобов, глубина очереди) и метрики данных (обработано событий, % поздних событий, % отфильтрованных по валидации). Дополните трассировкой между сервисами, чтобы отвечать на вопросы вроде «почему у этого эксперимента нет данных за вчерашний день?».
Проверки свежести данных — самый быстрый способ предотвратить молчаливые падения. Если SLA — «ежедневно до 9:00», мониторьте свежесть по продукту и источнику и сигнализируйте, когда:
- отсутствует последняя партиция
- объём событий резко отклоняется от эталона
- rollup‑джобы завершились, но выдали нулевые строки
Автоматизированные тесты: защищаем данные и математику
Создавайте тесты на трёх уровнях:
- Схема и ограничения: обязательные поля, уникальность (например, одно назначение на пользователя на эксперимент), внешние ключи и валидные диапазоны дат
- Разрешения: тесты RBAC (viewer/editor/admin) и фильтрация по продукту, чтобы команды видели только своё
- Математика результатов: unit‑тесты для lift, доверительных интервалов, флагов значимости и крайних случаев (малые выборки, нулевой знаменатель, множественные варианты)
Держите небольшой «golden dataset» с известными выходами, чтобы ловить регрессии до релиза.
Деплой, миграции и историческая безопасность
Относитесь к миграциям как к операционной части: версионируйте определения метрик и логику вычислений результатов, избегайте переписывания исторических экспериментов без явной просьбы. Когда изменения необходимы, предоставляйте контролируемый путь бэкфилла и документируйте, что именно поменялось в аудит‑трейле.
Админ‑инструменты для инцидентов и перерасчётов
Дайте админам возможность перезапустить пайплайн для определённого эксперимента/диапазона дат, посмотреть ошибки валидации и пометить инциденты со статусом. Связывайте заметки об инцидентах прямо с затронутыми экспериментами, чтобы пользователи понимали задержки и не принимали решения на основе неполных данных.
План развёртывания и частые ошибки, которых стоит избегать
Развёртывание трекера — это не столько «день запуска», сколько постепенное сокращение неясностей: что отслеживается, кто за это отвечает и совпадают ли числа с реальностью.
Практическая последовательность развёртывания
Начните с одного продукта и небольшого набора метрик (напр., conversion, activation, revenue). Цель — проверить сквозной рабочий процесс: создание эксперимента, захват экспозиций и исходов, вычисления результатов и запись решения — прежде чем увеличивать сложность.
Когда первый продукт стабилен, расширяйтесь продукт за продуктом с предсказуемым онбордингом. Каждый новый продукт должен быть повторяемой настройкой, а не кастомным проектом.
Если организация склонна к долгим «платформенным» циклам, рассмотрите двухтрековый подход: параллельно стройте прочные датаконtrakты (события, ID, определения метрик) и тонкий слой приложения. Команды иногда используют Koder.ai для быстрого запуска тонкого слоя — формы, дашборды, разрешения и экспорт — затем постепенно укрепляют его по мере роста использования.
Чек‑лист онбординга для каждого нового продукта
Используйте лёгкий чек‑лист для последовательного онбординга и схем событий:
- Подтвердить таксономию событий и соглашения по именам (и кто может их менять)
- Проверить, что есть событие exposure и оно однозначно атрибутируется
- Смэпить метрики на схему событий продукта (включая кейсы возврата/аннулирования)
- Провести бэкфилл или параллельный прогон для сравнения с существующей аналитикой
- Назначить владельцев для настройки эксперимента, валидации данных и заметок по решению
Где помогает принятие, делайте из результатов ссылки на релевантные участки продукта (напр., эксперименты по ценообразованию могут ссылаться на /pricing). Держите ссылки информативными и нейтральными — без намёка на исход.
Измеряйте принятие, чтобы быстро устранять трения
Отслеживайте, становится ли инструмент местом принятия решений:
- Weekly active users по ролям (PM, аналитик, инженер)
- Созданные и завершённые эксперименты
- Процент с заполненными заметками решения (не только просмотр результатов)
- Время от завершения эксперимента до фиксации решения
Частые ошибки, которых стоит избегать
- Несогласованные определения метрик между продуктами (одно имя — разная математика)
- Отсутствие или неверный трекинг экспозиций, приводящий к смещённым результатам
- Неопределённая ответственность за валидацию и подпись, из‑за чего появляются «zombie experiments»
- Тихие изменения схем, ломающие тренды без уведомления
- Поспешное масштабирование числа метрик до того, как базовый workflow заслужит доверие