Уточните проблему зависимостей, которую вы решаете
Прежде чем проектировать экраны или выбирать стек, чётко пропишите, что в вашей организации означает «зависимость». Если люди используют это слово для всего подряд, ваше приложение в итоге не будет хорошо отслеживать ничего.
Дайте простое определение «зависимости»
Напишите одно предложение, которое все смогут повторить, затем перечислите, что подходит. Обычные категории:
- Рабочая задача: другая команда должна сделать фичу, исправить баг или выполнить тикет.
- Артефакт/Deliverable: документ, набор данных, дизайн или ресурс, необходимый для продолжения работы.
- Решение: соглашение или подпись, которые разблокируют внедрение.
- Окружение/доступ: учётные данные, инфраструктура, тестовые окружения или разрешения.
Также определите, что не является зависимостью (например, «приятные к внедрению улучшения», общие риски или внутренние задачи, которые не блокируют другую команду). Это сохраняет систему в чистоте.
Определите, для кого приложение
Отслеживание зависимостей проваливается, если его делают только для PM-ов или только для инженеров. Назовите основных пользователей и что каждый должен получить за 30 секунд:
- Руководители команд / engineering managers: что блокирует доставку и кто отвечает за следующий шаг.
- PM-ы / програм-менеджеры: даты передачи, обязательства и пути эскалации.
- Инженеры: точный запрос, контекст и критерии приёмки.
- Руководство / операции: предсказуемая доставка, меньше сюрпризов и отчёты по трендам.
Выберите измеримые метрики успеха
Выберите небольшой набор результатов, например:
- Меньше «сюрпризных блокеров», обнаруженных поздно в спринте или релизе
- Более короткое время от создания зависимости → до принятия владельца
- Больше своевременных передач по согласованным датам
- Ясная ответственность (меньше элементов со статусом «TBD» у ответственных)
Перечислите боли, которые вы устраните
Зафиксируйте проблемы, которые приложение должно решить с первого дня: устаревшие таблицы, неясные владельцы, пропущенные даты, скрытые риски и обновления статуса, разбросанные по чатам.
Смоделируйте зависимости, состояния и определения
Когда вы согласовали, что трекаете и для кого, закрепите терминологию и жизненный цикл. Общие определения превращают «список тикетов» в систему, которая уменьшает блокеры.
Начните с типов зависимостей, которые поддерживаете
Выберите небольшой набор типов, покрывающих большинство реальных ситуаций, и сделайте каждый тип легко узнаваемым:
- Blocked-by: Команда A не может доставить, пока команда B не выполнит что-то.
- Provides-to: Команда B поставляет артефакт/сервис, который потребляет команда A.
- Waiting-on: Похоже на blocked-by, но часто ограничено по времени (одобрение, доступ, решение).
- Shared resource: Команды конкурируют за одних и тех же людей, окружение, бюджет или поставщика.
- Sequence constraint: Работа должна идти в определённом порядке, даже если никто «не заблокирован».
Цель — согласованность: два человека должны классифицировать одну и ту же зависимость одинаково.
Определите минимальные атрибуты (и принуждайте их)
Запись зависимости должна быть небольшой, но достаточной для управления:
- Команда-владелец (ответственна за доставку)
- Команда-запросчик (нуждается в результате)
- Дата (когда запросчик это ожидает)
- Статус (см. жизненный цикл ниже)
- Уровень риска (например: Low/Medium/High)
- Заметки (контекст, предположения)
- Ссылки на исходную работу (Jira issue, документ, PR, инцидент и т. п.)
Если позволить создавать запись зависимости без команды-владельца или даты, вы строите «трекер забот», а не инструмент координации.
Согласуйте состояния жизненного цикла и триггеры переходов
Используйте простую модель состояний, которая соответствует реальной работе команд:
Proposed → Accepted → In progress → Ready → Delivered/Closed, плюс Rejected.
Опишите правила смены состояний. Например: «Accepted требует команду-владельца и начальную целевую дату», или «Ready требует доказательства».
Сделайте «выполнено» однозначным
Для закрытия требуйте всё следующее:
- Критерии приёмки: что считается выполненным
- Подпись: кто подтверждает (имя/команда)
- Доказательства/ссылка: PR, релиз-нота, скриншот, документ или тикет
- Отметка времени: когда это было принято/закрыто
Эти определения станут основой фильтров, напоминаний и обзоров статуса позже.
Спроектируйте простую модель данных, которая масштабируется
Трекер зависимостей выигрывает или проигрывает по тому, могут ли люди описать реальность, не борясь с инструментом. Начните с небольшого набора объектов, который соответствует тому, как команды уже разговаривают, затем добавляйте структуру там, где это предотвращает путаницу.
Основные объекты (делайте их простыми)
Используйте несколько первичных записей:
- Team: группа, которая владеет работой или предоставляет зависимость.
- Project/Initiative: контейнер работы с понятным результатом.
- Work item: единица исполнения (фича, задача, epic, ссылка на тикет).
- Dependency: обещание между заказчиком и поставщиком.
- Milestone/Release: контрольная точка с датой, которую зависимости могут блокировать.
Избегайте создания отдельных типов для каждой пограничной ситуации. Лучше добавить пару полей (например, “type: data/API/approval”), чем дробить модель слишком рано.
Отношения, которые отражают реальную координацию
Зависимости часто вовлекают несколько групп и несколько задач. Моделируйте это явно:
- Teams ↔ Dependencies: многие-ко-многим (зависимость может иметь несколько команд-поставщиков; команда может участвовать во многих зависимостях).
- Dependencies ↔ Work items: многие-ко-многим (одна зависимость может блокировать несколько work items; одна work item может зависеть от нескольких зависимостей).
Это предотвращает хрупкое мышление «одна зависимость = один тикет» и делает возможными сводные отчёты.
Аудитируемость: делайте изменения надёжными
Каждый основной объект должен включать поля аудита:
- Created by / created at, updated by / updated at
- История изменений (что и когда изменилось)
- Комментарии (решения и контекст)
- Вложения/ссылки (спеки, документы, Jira-тикеты, заметки по встречам)
Лёгкая поддержка внешних зависимостей
Не каждая зависимость имеет команду в вашей орг-структуре. Добавьте запись Owner/Contact (имя, организация, email/Slack, заметки) и разрешите ссылаться на неё из зависимостей. Это держит в поле зрения блокеры с вендорами или «другими отделами», не заставляя их становиться частью вашей внутренней структуры команд.
Определите роли, владение и права доступа
Если роли неявны, отслеживание зависимостей превращается в поток комментариев: все думают, что кто-то другой ответственный, и даты «корректируются» без контекста. Ясная модель ролей делает приложение надёжным и предсказуемым для эскалаций.
Основные роли (делайте просто)
Начните с четырёх повседневных ролей и одной административной:
- Requester: создаёт запрос и указывает «почему», требуемую дату и критерии приёмки.
- Owner: единственный ответственный за доставку (или формальное отклонение) зависимости.
- Approver: подтверждает обязательство, когда зависимость влияет на ёмкость, объём или план релиза.
- Viewer: может отслеживать прогресс и комментировать, но не менять обязательства.
- Admin: управляет конфигурацией (команды, права, шаблоны), не занимается операционными решениями.
Правила владения, предотвращающие неясность
Сделайте Owner обязательным и единичным: одна зависимость — один ответственный. Поддерживайте соавторов (contributors) из других команд, но они не заменяют ответственность.
Добавьте путь эскалации, если Owner не отвечает: сначала пингуйте Owner, затем их менеджера (или лидера команды), затем программу/релиз-овнера — в зависимости от структуры вашей организации.
Права доступа: защищайте обязательства, а не видимость
Разделяйте «редактирование деталей» и «изменение обязательств». Практический дефолт:
- Requester может создавать, добавлять контекст и предлагать даты; не может пометить как «Committed» без подтверждения.
- Owner может обновлять статус, добавлять заметки по доставке и предлагать новые даты; закрывать можно только при выполнении критериев приёмки.
- Approver может ставить состояния обязательств (Committed/Rejected) и утверждать изменения дат.
- Viewer может смотреть и комментировать; не имеет прав на редактирование.
Если вы поддерживаете приватные инициативы, определите, кто их видит (например, только вовлечённые команды + Admin). Избегайте «секретных зависимостей», которые удивляют команды доставки.
RACI подсказки в UI
Не прячьте ответственность в политике. Показывайте её в каждой записи:
- Accountable (A): Owner
- Responsible (R): Collaborators (опционально)
- Consulted (C): Approver и затронутые команды
- Informed (I): Viewers/watchers
Явное обозначение «Accountable vs Consulted» в форме уменьшает перенаправления и ускоряет обзоры статуса.
План UX: представления, которыми команды действительно будут пользоваться
Трекер зависимостей работает только если люди находят свои элементы за секунды и обновляют их без раздумий. Проектируйте вокруг частых вопросов: «Что я блокирую?», «Что блокирует меня?» и «Что может сдвинуться?»
Основные экраны для раннего релиза
Начните с небольшого набора видов, которые соответствуют разговорному стилю команд:
- Список зависимостей: фильтруемая таблица для «всех открытых зависимостей» с быстрыми действиями.
- Детали зависимости: одно место, где видны запрос, статус, владельцы, даты и история.
- Просмотр команды: всё, что команда должна сделать и что ждёт её, с явными приоритетами.
- Просмотр инициативы: зависимости сгруппированы по проекту/релизу, чтобы лиды видели риски.
- Таймлайн: лёгкий обзор дат исполнения и передач (не пытайтесь делать полноценный Gantt).
Сделайте создание и обновления минимально затратными
Большинство инструментов проваливается на «ежедневных обновлениях». Оптимизируйте скорость:
- Шаблоны и поля по умолчанию (частые типы зависимостей, правила SLA/даты)
- Inline-редактирование в списке и на странице деталей (без модалей для простых изменений)
- Клавиатурные сочетания для power users (порядок tab, быстрые сохранения, предсказуемые шорткаты)
Сделайте статус невозможным для неправильного прочтения
Используйте цвет + текстовые метки (никогда цвет в одиночку) и держите словарь согласованным. Добавьте видимую метку «Last updated» на каждой зависимости и предупреждение об устаревании, если запись не трогали заданное время (например, 7–14 дней). Это подтолкнёт к обновлениям без необходимости созыва встреч.
Снижайте количество встреч, фиксируя контекст
Каждая зависимость должна иметь единую ветку, содержащую:
- Комментарии и апдейты прогресса
- Принятые решения (с датой и участником)
- Ссылки на сопроводительную работу (тикеты, документы)
Когда страница деталей рассказывает полную историю, обзоры статуса проходят быстрее — многие «быстрые синки» исчезают, потому что ответ уже в записи.
Постройте workflows для запросов, обновлений и закрытия
Изменяйте модель безопасно
Экспериментируйте с состояниями и правами доступа безопасно с помощью снимков и отката.
Трекер зависимостей выигрывает или проигрывает по повседневным действиям, которые он поддерживает. Если команды не смогут быстро запросить работу, ответить ясным обязательством и закрыть петлю с доказательством, ваш инструмент превратится в «доску FYI», а не в рабочий инструмент.
Основной workflow: запрос → решение → обязательство
Начните с единого потока «Create request», который фиксирует, что команда-поставщик должна сделать, зачем это важно и когда это нужно. Держите структуру: запрошенная дата, критерии приёмки и ссылка на эпик/спеку.
Далее требуйте явного ответа в состоянии:
- Accept (обязуются на дату)
- Decline (с обязательной причиной)
- Propose new date (контрпредложение с пояснением)
Это избегает самой частой ошибки: молчаливые «может быть», которые выглядят нормально до момента провала.
Ожидания в стиле SLA, предотвращающие устаревание
Определите лёгкие ожидания прямо в workflow. Примеры:
- Ответ в течение X рабочих дней после создания запроса
- Частота обновлений (например, раз в неделю или при изменении статуса)
- Пометка как stale, если нет обновления в Y дней и дата приближается на Z дней
Цель не в контроле, а в том, чтобы обязательства оставались актуальными и планирование было честным.
Обновления с контролем изменений (без бюрократии)
Позвольте командам пометить зависимость как At risk с короткой заметкой и следующими шагами. При изменении даты или статуса требуйте причину (выпадающий список + текст). Это простое правило создаёт историю изменений, которая делает ретроспективы и эскалации фактами, а не эмоциями.
Закрытие, подтверждающее реальную выполненность
«Закрыть» — значит зависимость удовлетворена. Требуйте доказательство: ссылку на слитый PR, релизный тикет, документ или заметку об одобрении. Если закрытие неясно, команды будут «зеленить» элементы преждевременно, чтобы снизить шум.
Массовые действия для еженедельного планирования
Поддержите массовые операции на матч-ревью: выберите несколько зависимостей и поставьте одинаковый статус, добавьте общую заметку (например, «перепланировано после сброса квартала»), или запросите обновления. Это делает приложение достаточно быстрым для использования на встречах, а не только после них.
Добавьте оповещения и нотификации, не создавая шума
Уведомления должны защищать доставку, а не отвлекать. Самый простой способ создать шум — оповещать всех обо всём. Вместо этого проектируйте оповещения вокруг точек решения и сигналов риска.
Начните с небольшого набора полезных триггеров
Сосредоточьтесь на событиях, которые меняют план или требуют явного ответа:
- Создан новый запрос (уведомление команде-владельцу)
- Нужна подтверждение (назначена зависимость и ждёт подтверждения)
- Изменена дата (любая сторона меняет обещанную/нужную дату)
- Статус «at risk» / blocked (поднят флаг риска или добавлен блокер)
- Устаревание (нет обновлений X дней для активной зависимости)
Каждый триггер должен соответствовать явному следующему шагу: принять/отклонить, предложить новую дату, добавить контекст или эскалировать.
Доставляйте уведомления там, где команды уже проверяют сообщения
По умолчанию используйте in-app notifications (чтобы оповещения были привязаны к записи) плюс email для срочных случаев.
Предложите опциональные чат-интеграции — Slack или Microsoft Teams — но рассматривайте их как механизмы доставки, а не систему учёта. Сообщения в чате должны вести на конкретный элемент (например, /dependencies/123) и содержать минимум контекста: кто должен действовать, что изменилось и к какому сроку.
Уменьшайте шум с помощью настроек и дайджестов
Дайте возможность управлять на уровне команды и пользователя:
- Мгновенные оповещения для acceptance, blocked, overdue
- Режим дайджеста (ежедневно/еженедельно) для низкой срочности
- Группировка и дедупликация (одна сводка по зависимости за окно времени)
Здесь же важны «watchers»: уведомляйте requestor, owning team и явных заинтересованных — избегайте широких рассылок.
Эскалация только при сигналах системного риска
Эскалация должна быть автоматической, но консервативной: оповещайте, когда зависимость просрочена, когда дата многократно переносилась, или когда заблокированный статус не обновлялся заданный период.
Направляйте эскалации на нужный уровень (team lead, program manager) и включайте историю, чтобы получатель мог быстро действовать без поисков контекста.
Выберите интеграции, которые убирают дублирование работы
Подключите другие команды
Пригласите другую команду опробовать Koder.ai и получите кредиты за рефералы.
Интеграции должны исключать повторный ввод, а не добавлять настройку. Самый безопасный путь — начать с систем, которым команды уже доверяют (трекеры задач, календари, идентификация), держать первую версию read-only или однонаправленной, затем расширять.
Начните с одного трекера задач
Выберите первичный трекер (Jira, Linear или Azure DevOps) и поддерживайте простой «link-first» поток:
- Запись зависимости хранит URL и ключ трекера (например,
PROJ-123).
- Приложение подтягивает статус (Open/In Progress/Done), исполнителя и дату по расписанию.
- Обновления остаются в трекере; ваше приложение отображает их.
Это избегает двух источников правды, одновременно давая видимость зависимостей. Позже добавьте опциональную двустороннюю синхронизацию для ограниченного набора полей (статус, дата) с понятными правилами конфликтов.
Добавьте календарные вехи (сначала read-only)
Вехи и дедлайны часто хранятся в Google Calendar или Microsoft Outlook. Начните с чтения событий в ваш таймлайн зависимостей (например, «Release Cutoff», «UAT Window») без обратной записи.
Read-only синк календаря позволяет командам планить там, где им удобно, а вашему приложению показывать влияние и приближающиеся даты в одном месте.
Сделайте доступ простым с SSO
Single sign-on снижает трение при подключении и контроле прав. Выбирайте в зависимости от реальности заказчика:
- Google Workspace (часто для небольших организаций)
- Microsoft Entra ID (часто для корпоративных клиентов)
- Okta (для смешанных сред)
Если вы на ранней стадии, выпустите одну реализацию и задокументируйте, как запросить другие.
Предложите небольшой, хорошо задокументированный API + вебхуки
Даже нетехнические команды выигрывают, когда internal ops могут автоматизировать передачи. Предоставьте несколько эндпоинтов и event-хуков с примерами «копи-вставь».
curl -X POST /api/dependencies \\
-H "Authorization: Bearer $TOKEN" \\
-d '{"title":"API contract from Payments","trackerUrl":"https://jira/.../PAY-77"}'
Вебхуки вроде dependency.created и dependency.status_changed позволяют интегрировать ваши внутренние инструменты без ожидания roadmap. Для подробностей ведите на /docs/integrations.
Создайте дашборды и отчёты для обзоров статуса
Дашборды — это место, где трекер зависимостей оправдывает себя: они превращают «думаю, мы заблокированы» в общее ясное представление того, что требует внимания до следующей проверки.
Дашборды для разных аудиторий
Один универсальный дашборд обычно не работает. Вместо этого сделайте несколько видов под формат встреч:
- Просмотр руководителя команды: показывает, что ваша команда должна и что блокирует её, с фокусом на даты, статус и следующий шаг.
- Просмотр программы: группирует зависимости по инициативам/релизам и выделяет межкомандные узкие места (когда несколько пунктов ждут одну команду или веху).
- Исполнительный срез: компактный агрегат: всего открытых зависимостей, сколько в риске, что недавно просрочено и топ-3 блокера. Держите его легко просматриваемым.
Отчёты, которые ведут к решениям (а не к работе ради отчётов)
Сделайте небольшой набор отчётов, которые реально будут использовать в обзорах:
- Просроченные зависимости: сортировка по дням просрочки и по серьёзности/риску.
- Топ блокирующих команд: кто имеет больше всего зависимостей на себе (и тренды во времени).
- Приближающиеся вехи под риском: вехи на 2–4 недели с открытыми или помеченными «at risk» зависимостями.
Каждый отчёт должен отвечать: «Кто должен что сделать дальше?» — указывайте владельца, ожидаемую дату и последнее обновление.
Фильтры, которые действительно важны
Сделайте фильтрацию быстрой и очевидной, потому что большинство встреч начинается с «покажи только…»
Поддерживайте фильтры: team, initiative, status, диапазон дат, risk level и теги (например, «security review», «data contract», «release train»). Сохраняйте часто используемые наборы фильтров как именованные представления (например, «Release A — next 14 days").
Экспорт и шаринг
Не все живут в вашем приложении. Предложите:
- CSV export для простого анализа и одноразового шаринга.
- Shareable links на отфильтрованный дашборд или отчёт (например, /reports/overdue?team=payments). Ссылки держите внутренними и стабильными.
Если у вас платный план, оставьте административные настройки шаринга и ссылку на /pricing.
Выберите практичный стек технологий и архитектуру
Вам не нужна сложная платформа, чтобы выпустить трекер зависимостей. MVP — это простая трёхчастная система: веб-UI для людей, API для правил и интеграций и база данных как источник правды. Оптимизируйте под «легко менять», а не «идеально спроектировано». Вы узнаете больше от реального использования, чем от месяцев предварительной архитектуры.
Простой стек для MVP
Практичная стартовая связка может выглядеть так:
- Web UI: React, Vue или server-rendered страницы (Rails/Django) для быстрого CRUD.
- API: Node (Express/Nest), Python (FastAPI/Django) или Rails — выбирайте то, что команда уже поддерживает.
- База данных: Postgres обычно лучший выбор для реляционных данных: зависимости, владельцы, статусы и отметки времени.
Если ожидаются интеграции со Slack/Jira, держите интеграционные модули отдельными и обращающимися к API, а не позволяющими внешним системам писать прямо в БД.
Если нужно получить рабочий продукт быстро, можно использовать быстрые workflow-решения: например, инструменты генерации кода по спецификации. Это сокращает путь от требований до пилота, при этом вы сохраняете экспорт кода и контроль архитектуры.
Технические базовые штуки, которые пригодятся
- Аутентификация: SSO (SAML/OIDC), если доступно; иначе надёжный логин по email.
- Логирование: структурированные логи запросов и трекинг ошибок, чтобы разбираться «почему это изменили?»
- Rate limits: защита API от шумных интеграций и циклов обновлений.
- Бэкапы: ежедневные автоматические бэкапы и протестированные восстановления.
Производительность и чистота данных
Большинство экранов — это списки: открытые зависимости, блокеры по командам, изменения за неделю. Проектируйте под это:
- Добавьте индексы для частых фильтров (status, owning team, due date, updated_at).
- Используйте пагинацию везде.
- Обеспечьте поиск (стандартный full-text в Postgres зачастую достаточен).
Конфиденциальность и доверие
Данные зависимостей могут содержать чувствительную информацию. Используйте принцип минимально необходимого доступа (видимость на уровне команды там, где нужно) и ведите аудит-логи правок — кто что и когда изменил. Аудит снижает споры на обзорах статуса и делает инструмент надёжным.
План выката: пилот, миграция и внедрение
Запустите живой пилот
Разверните и хостьте приложение для отслеживания зависимостей без лишней настройки.
Выкат трекера зависимостей — это не столько про фичи, сколько про изменение привычек. Относитесь к выкатыванию как к продукт-ланчу: начните с малого, докажите ценность, затем масштабируйте с ясным ритмом операций.
1) Начните с фокусированного пилота
Выберите 2–4 команды, работающие над одной общей инициативой (например, релизом или заказным проектом). Определите критерии успеха, измеримые за несколько недель:
- Меньше «неизвестных» блокеров на обзорах статуса
- Короткое время от «зависимость поднята» до «назначен владелец»
- Больше своевременных передач для пилотной инициативы
Держите конфигурацию пилота минимальной: только поля и виды, нужные чтобы ответить «что блокирует, кем и когда?».
2) Миграция из таблиц без хаоса
Большинство команд уже ведут зависимости в таблицах. Импортируйте их, но осознанно:
- Сопоставьте столбцы с полями (описание зависимости, команда-запросчик, команда-владелец, дата, статус, причина блокера)
- Очистите дубликаты и нормализуйте имена команд перед импортом
- Решите, что делать с «историческими» строками (обычно лучше архивировать, а не мигрировать)
Проведите короткий QA данных с пилотными пользователями, чтобы подтвердить определения и исправить неоднозначные записи.
3) Стимулируйте принятие через лёгкий плейбук
Принятие закрепляется, когда приложение поддерживает существующий ритм. Предложите:
- 15–20 минутное обучение с 2–3 реальными примерами зависимостей
- Еженедельную рутину обновлений (например, вторник перед кросс-командным синком)
- Чёткое правило: записи без владельца или даты не считаются валидными
Если вы быстро итеративно развиваетесь, используйте окружения/снимки, чтобы тестировать изменения полей, состояний и дашбордов с пилотными командами — затем откатывайте или продвигайте, не ломая всех пользователей.
4) Постройте цикл обратной связи и итерации
Отслеживайте места, где пользователи застревают: запутанные поля, отсутствующие статусы или виды, не отвечающие на вопросы обзора. Просматривайте фидбек еженедельно в пилоте и корректируйте поля и дефолтные виды перед приглашением новых команд. Простой «Report an issue» ссылка на /support поможет держать цикл коротким.
Избегайте подводных камней и планируйте следующие итерации
Когда трекер запущен, главные риски не технические, а поведенческие. Большинство команд не бросают инструменты потому что они «не работают», а потому что обновление кажется необязательным, запутанным или шумным.
Частые причины провала (и как их избежать)
Слишком много полей. Если создание зависимости похоже на заполнение анкеты, люди будут откладывать или пропускать это. Начните с минимального набора обязательных полей: заголовок, команда-запросчик, команда-владелец, «следующее действие», дата и статус.
Неясная ответственность. Если не видно, кто должен действовать, зависимости превращаются в поток статусов. Сделайте «owner» и «next action owner» явными и хорошо видимыми.
Нет привычки обновлять. Даже отличный UI терпит неудачу, если элементы устаревают. Добавьте мягкие напоминания: подсветка устаревших элементов в списках, напоминания только когда дата близка или последнее обновление старое, и лёгкие обновления (одно-кликовое изменение статуса + короткая заметка).
Перегрузка уведомлений. Если каждый комментарий пингуется всем, пользователи заглушат систему. По умолчанию используйте «watchers» по выбору и отправляйте сводки (ежедневно/еженедельно) для низкой срочности.
Ограждения, которые сохраняют систему здоровой
Сделайте «next action» полем первого класса: каждая открытая зависимость всегда должна иметь понятный следующий шаг и одного ответственного. Если этого нет, элемент не должен выглядеть «полным» в ключевых видах.
Определите, что значит «done» (например: решено, не требуется, перенесено в другой трекер) и требуйте короткой причины закрытия, чтобы избежать «зомби»-элементов.
Управление таксономией, чтобы она не дрейфовала
Назначьте владельца списка тегов, команд и категорий — обычно это program manager или ops с лёгким контролем изменений. Установите политику устаревания: автоматически архивируйте старые инициативы через X дней после закрытия и пересматривайте неиспользуемые теги ежеквартально.
Идеи дорожной карты для следующей итерации
После стабилизации принятия рассмотрите улучшения, добавляющие ценность без трения:
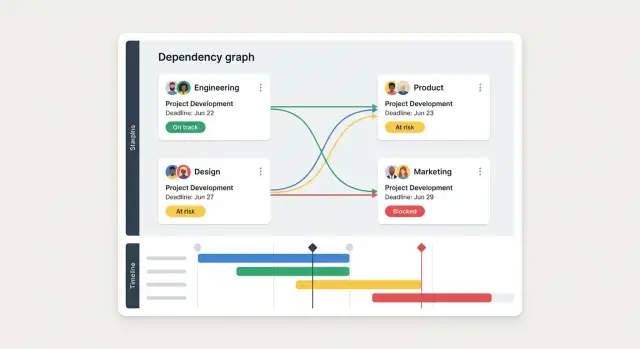
- Граф зависимостей для сложных релизов и многокомандных работ
- Оценка риска (например: старение, пропущенные даты, высокоимпактные теги)
- Аналитика SLA для выявления хронических узких мест и установки ожиданий
- Шаблоны по отделам чтобы типовые зависимости создавались в один клик
Если нужно структурированное приоритизирование улучшений, привязывайте идею к ритуалу обзора (еженедельная встреча, планирование релиза, ретроспектива инцидента), чтобы изменения шли из реального использования, а не из догадок.