О чём на самом деле это сравнение
Большинство дебатов «BI vs Foundry» застревают на фичах: у какого инструмента лучше графики, быстрее запросы или симпатичнее дашборды. Это редко решающий фактор. Настоящее сравнение — о том, чего вы пытаетесь добиться.
Дашборд может сказать, что произошло (или происходит). Операционная система принятия решений создана, чтобы помочь людям решить, что делать дальше — и чтобы это решение было воспроизводимым, проверяемым и связанным с исполнением.
Инсайт не равно действию. Узнать, что запасы низки, — одно; автоматически инициировать пополнение, перенаправить поставку, обновить план и отследить, сработало ли решение, — совсем другое.
Что вы узнаете из этого руководства
В статье разобрано:
- Функциональные различия между традиционной бизнес‑аналитикой и операционными системами принятия решений
- Компромиссы: скорость развёртывания vs глубина интеграции, гибкость vs стандартизация, исследование vs исполнение
- Практические критерии выбора, чтобы вы ориентировались на модель работы, а не на маркетинговые формулировки
Охват (больше, чем один вендор)
Хотя Palantir Foundry — полезная отправная точка, идеи здесь применимы шире. Любая платформа, которая связывает данные, логику решений и рабочие процессы, будет вести себя иначе, чем инструменты, созданные прежде всего для дашбордов и отчётности.
Для кого это
Если вы руководите операциями, аналитикой или бизнес‑функцией, где решения принимаются под давлением времени (цепочки поставок, производство, клиентские операции, риск, полевые службы), это сравнение поможет выровнять инструменты с тем, как работа действительно выполняется — и где сегодня решения дают сбои.
Для чего предназначены традиционные BI‑инструменты
Традиционные инструменты бизнес‑аналитики созданы, чтобы помогать организациям видеть, что происходит, через дашборды и отчёты. Они отлично превращают данные в общие метрики, тренды и сводки, которыми руководители и команды могут пользоваться для мониторинга эффективности.
Дашборды: мониторинг и видимость показателей
Дашборды предназначены для быстрой ситуационной осведомлённости: растут ли продажи или падают? Соответствует ли уровень сервиса целям? Какие регионы отстают?
Хорошие дашборды делают ключевые метрики лёгкими для сканирования, сравнения и углубления. Они дают командам общий язык («это число, которому мы доверяем») и помогают заметить изменения на ранней стадии — особенно в сочетании с оповещениями или регулярным обновлением данных.
Отчётность: стандартизированные метрики и периодические сводки
Отчётность ориентирована на согласованность и повторяемость: итоговые отчёты за месяц, еженедельные операционные пакеты, сводки для комплаенса и исполнительные скоркард‑пакеты.
Цель — стабильные определения и предсказуемая доставка: одни и те же KPI, рассчитанные одинаково, распространяемые по расписанию. Здесь важны такие концепции, как семантический слой и сертифицированные метрики — всем нужно одинаково интерпретировать результаты.
Ad hoc‑анализ: исследование новых вопросов
BI‑инструменты также поддерживают исследования, когда возникают новые вопросы: почему упала конверсия на прошлой неделе? Какие товары дают наибольшее число возвратов? Что изменилось после обновления цен?
Аналитики могут нарезать сегменты, фильтровать, строить новые представления и тестировать гипотезы без ожидания работы инженеров. Такой низкопороговый доступ к инсайту — одна из главных причин, почему традиционная бизнес‑аналитика остаётся востребованной.
Где BI сильна (и где часто останавливается)
BI отлично подходит, когда результат — понимание: быстрое время до дашборда, привычный UX и широкое распространение среди бизнес‑пользователей.
Ограничение обычно возникает в следующем шаге. Дашборд может выделить проблему, но обычно не выполняет ответное действие: не назначает задачу, не закрепляет логику решения, не обновляет операционные системы и не отслеживает, было ли действие выполнено.
Этот пробел «и что дальше?» — ключевая причина, по которой команды ищут нечто большее, когда им нужно реально превратить аналитику в действие и встроенные рабочие процессы принятия решений.
Что такое операционная система принятия решений
Операционная система принятия решений проектируется для выбора, которые бизнес делает в процессе работы — а не задним числом. Эти решения частые, чувствительные ко времени и повторяемые: «Что нам делать дальше?» вместо «Что случилось в прошлом месяце?»
Традиционная BI‑система отлично подходит для дашбордов и отчётности. Операционная система идёт дальше, упаковывая данные + логику + рабочий процесс + ответственность, чтобы аналитика надёжно превращалась в действие внутри реального процесса.
Какие решения она поддерживает
Операционные решения обычно имеют несколько общих признаков:
- Происходят много раз в день (или в час)
- «Правильный» ответ зависит от самых свежих данных
- Важна последовательность: две команды должны принять похожее решение при одинаковых фактах
- Нужна объяснимость и аудит, почему было принято то или иное решение
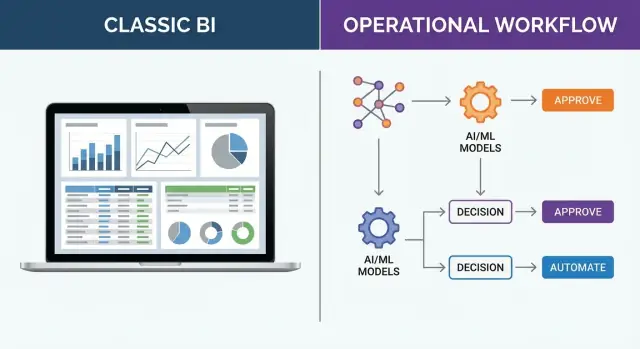
Как выглядит результат (это не график)
Вместо плитки на дашборде система выдаёт практические результаты, встроенные в работу:
- Рекомендованные действия (с обоснованием)
- Исключения, требующие внимания
- Шаги утверждения и подписи
- Очереди задач и назначения
Например, вместо демонстрации трендов по запасам операционная система может сгенерировать предложения по пополнению с порогами, ограничениями поставщиков и шагом ручного утверждения. Вместо дашборда для службы поддержки она может сформировать приоритизацию обращений с правилами, скорингом риска и следом аудита. В полевых операциях — предложить корректировки расписания с учётом загрузки и новых ограничений.
Как измерять успех
Успех — это не «больше просмотров отчётов». Это улучшение результатов в бизнес‑процессе: меньше пустых мест на складе, быстреее время решения инцидентов, снижение затрат, повышение соблюдения SLA и ясная ответственность.
От инсайта к действию: открытый цикл против закрытого цикла
Самое важное отличие в сравнении Palantir Foundry vs BI — не тип графика и не оформление дашборда. Важно, останавливается ли система на инсайте (открытый цикл) или продолжает до исполнения и обучения (закрытый цикл).
Открытый цикл: BI превращает данные в представления
Традиционная BI‑система оптимизирована под дашборды и отчётность. Общая последовательность выглядит так:
- BI‑поток: ingest → model → visualize → human interprets
Последний шаг важен: «решение» происходит в голове человека, на совещании или в переписке. Это хорошо для исследования, квартальных обзоров и вопросов, где дальнейшее действие не очевидно.
Где возникают задержки в BI‑подходах: между «я вижу проблему» и «мы что‑то сделали»:
- нужный человек не смотрит дашборд
- определения метрик обсуждаются (несовпадения семантического слоя)
- действия требуют координации между командами и системами
- нет способа последовательно подтвердить, сработало ли действие
Закрытый цикл: системы решений продуктируют действие
Операционная система принятия решений расширяет конвейер дальше чем инсайт:
- Поток системы решений: ingest → model → decide → execute → learn
Разница в том, что «decide» и «execute» являются частью продукта, а не ручной передачей. Когда решения повторяемы (утверждать/отклонять, приоритизировать, распределять, маршрутизировать, планировать), кодирование их как рабочих процессов плюс логики снижает задержки и несогласованность.
Почему обратная связь в закрытом цикле меняет результаты
Закрытый цикл означает, что каждое решение прослеживается до входных данных, логики и исходов. Вы можете измерить: Что мы выбрали? Что случилось дальше? Нужно ли менять правило, модель или порог?
Со временем это создаёт непрерывное улучшение: система учится на реальных операциях, а не только на том, что люди успевают обсудить позже. Это практический мост от аналитики к действию.
Как обычно различаются архитектуры
Традиционная BI‑схема обычно представляет собой цепочку компонентов, каждый оптимизированный под конкретный шаг: хранилище или lake для хранения, ETL/ELT‑пайплайны для перемещения и формирования данных, семантический слой для стандартизации метрик и дашборды/отчёты для визуализации.
Это хорошо работает, когда цель — стабильная отчётность и анализ, но действие часто происходит вне системы — через совещания, почту и ручные передачи.
Подход в стиле Foundry скорее похож на платформу, где данные, логика трансформаций и оперативные интерфейсы живут ближе друг к другу. Аналитику рассматривают не как конец конвейера, а как один из ингредиентов в рабочем процессе, который производит решение, запускает задачу или обновляет операционную систему.
Data products vs разовые наборы данных
Во многих BI‑окружениях команды создают наборы данных под конкретный дашборд или вопрос («продажи по регионам за Q3»). Со временем возникает много похожих таблиц, которые расходятся.
Мышление «data product» предполагает создание переиспользуемого, чётко определённого актива (входы, владельцы, режим обновления, проверки качества и ожидаемые потребители). Это облегчает создание множества приложений и рабочих процессов на одних и тех же доверенных строительных блоках.
Где выполняются вычисления (и почему это важно)
Традиционный BI часто опирается на пакетную обработку: ночные загрузки, плановые обновления моделей и периодические отчёты. Операционные решения часто требуют более свежих данных — иногда почти в реальном времени — потому что цена запоздалого действия высока (пропущенные отправки, нехватка запасов, отложенные вмешательства).
Интерфейсы, выходящие за пределы графиков
Дашборды хороши для мониторинга, но операционные системы часто нуждаются в интерфейсах для захвата и маршрутизации работы: формы, очереди задач, утверждения и лёгкие приложения. Это архитектурный сдвиг от «увидеть цифры» к «выполнить шаг».
Потребности в интеграции данных выше для операционного использования
Быстро создавайте интерфейс рабочего процесса
Создавайте легкие операционные экраны — очереди, формы и представления задач — без тяжёлой разработки.
Дашборды иногда терпят «почти правильные» данные: если две команды считают клиентов по‑разному, вы всё ещё можете построить график и объяснить рассогласование на встрече. Операционные системы такой роскоши не имеют.
Когда решение запускает работу — утвердить отправку, приоритизировать техобслуживание, заблокировать платёж — определения должны быть согласованы между командами и системами, иначе автоматизация быстро становится небезопасной.
Согласованные определения между командами
Операционные решения зависят от общих семантик: что такое «активный клиент», «выполненный заказ» или «задержанная доставка»? Без согласованных определений один шаг рабочего процесса будет трактовать запись иначе, чем следующий.
Здесь семантический слой и хорошо управляемые data products важнее красивых визуализаций.
Разрешение сущностей и выравнивание справочников
Автоматизация ломается, когда система не может надёжно ответить на простые вопросы типа «это тот же поставщик?». Операционные настройки обычно требуют:
- Разрешение сущностей (сопоставление записей из разных источников)
- Мастер‑данные (авторитетные ID и атрибуты)
- Выравнивание справочных данных (валюты, локации, коды статусов, календари)
Если этих основ нет, каждая интеграция превращается в одноразовое отображение, которое ломается при изменении исходной системы.
Проблемы качества данных, которые ломают автоматизацию
Проблемы качества многоматочных источников распространены — дубликаты ID, отсутствующие временные метки, несогласованные единицы. Дашборд может отфильтровать или аннотировать такие случаи; операционный рабочий поток требует явной обработки: правила валидации, запасные сценарии и очереди исключений, чтобы люди могли вмешаться, не останавливая весь процесс.
Моделирование для решений, а не только для отчётности
Операционные модели требуют сущностей, состояний, ограничений и правил (например, «заказ → упакован → отправлен», ограничения по ёмкости, нормативные ограничения).
Проектирование пайплайнов вокруг этих концепций и ожидание изменений помогает избежать хрупких интеграций, которые развалятся при вводе новых продуктов, выходе на новые регионы или изменении политик.
Управление, безопасность и следы аудита
Когда вы переходите от «просмотра инсайтов» к «запуску действий», управление перестаёт быть галочкой соответствия и становится операционной системой безопасности.
Автоматизация может умножить последствия ошибки: одна плохая свертка, устаревшая таблица или слишком широкие права могут распространиться на сотни решений за минуты.
Почему автоматизация повышает ставки
В традиционном BI неправильные данные часто приводят к неверной интерпретации. В операционной системе неправильные данные могут привести к неправильному исходу — перераспределению запасов, перенаправлению заказов, отказу клиентам, изменению цен.
Поэтому управление должно быть непосредственно на пути data → decision → action.
Ролевой доступ: кто может смотреть, а кто — действовать
Дашборды обычно ориентированы на «кто что видит». Операционные системы нуждаются в более тонком разделении:
- Права просмотра (инспекция данных, метрик и объяснений)
- Права действия (утверждать, выполнять или запускать downstream‑системы)
- Контекстные ограничения (действовать только в рамках региона, продуктовой линии или уровня аккаунта)
Это снижает риск того, что «право читать» случайно превратится в «право влиять», особенно при интеграции с тикетингом, ERP или управлением заказами.
Прослеживаемость и аудируемость
Хорошая прослеживаемость — это не только происхождение данных, но и происхождение решения. Команды должны уметь проследить рекомендацию или действие до:
- шагов трансформации
- входов и используемых версий
- применённой логики решений
- исходных систем
Не менее важно аудирование: запись почему была сделана рекомендация (входы, пороги, версия модели, сработавшие правила), а не только что было рекомендовано.
Разделение обязанностей и обработка исключений
Операционные решения часто требуют утверждений, переопределений и контролируемых исключений. Разделение ролей — билдера против утверждающего, рекомендующего против исполнителя — помогает предотвратить тихие ошибки и создаёт понятный ревью‑трейл при возникновении нетипичных ситуаций.
Логика решений: правила, оптимизация и ML в контексте
Избегайте привязки в будущем
Сохраняйте контроль с помощью экспорта исходного кода, когда нужно переместить или проверить реализацию.
Дашборды отвечают на «что случилось?». Логика решений отвечает на «что нам делать дальше и почему?». В операционной среде эта логика должна быть явной, тестируемой и безопасной для изменения — потому что она может запускать утверждения, перенаправления, удержания или коммуникации.
Логика на правилах: чёткие политики, предсказуемые результаты
Решения на базе правил хороши, когда политика проста: «Если запас ниже X — ускорить» или «Если в деле не хватает документов — запросить их перед рассмотрением».
Плюс — предсказуемость и аудитируемость. Минус — хрупкость: правила могут конфликтовать или устаревать при изменении бизнеса.
Оптимизация: компромиссы в условиях ограничений
Многие реальные решения — не бинарные, а задачи распределения. Оптимизация пригодится, когда ресурсы ограничены (часы персонала, транспорт, бюджет) и есть противоречивые цели (скорость vs стоимость vs справедливость).
Вместо одного порога вы задаёте ограничения и приоритеты, затем генерируете «лучший доступный» план. Важно делать эти ограничения читаемыми для владельцев бизнеса, а не только для моделлеров.
ML‑скоринг: приоритизация с человеческой проверкой
Машинное обучение часто выступает как шаг скоринга: ранжирование лидов, выявление рисков, прогноз задержек. В операционных рабочих процессах ML обычно лучше работать как рекомендация, а не как молчаливая автоматизация — особенно если решения влияют на клиентов или соответствие требованиям.
Объяснимость: заслужить доверие и соответствие
Люди должны видеть основные драйверы рекомендации: какие входы использовались, коды причин и что могло бы изменить исход. Это укрепляет доверие и помогает при аудитах.
Мониторинг дрейфа и безопасное обновление
Операционная логика должна мониториться: сдвиги входных данных, изменение эффективности и непреднамеренные смещения.
Используйте контролируемые релизы (shadow‑режим, ограниченный выпуск) и версионирование, чтобы можно было сравнивать результаты и быстро откатывать изменения.
UX: дашборды против рабочих процессов
Традиционная BI оптимизирована для просмотра: дашборд, отчёт, возможность нарезать‑фильтровать, помогающие понять, что случилось и почему.
Операционные системы оптимизированы для действия. Основные пользователи — планировщики, диспетчеры, кейс‑воркеры и супервайзеры — люди, принимающие много небольших, чувствительных ко времени решений, когда «следующий шаг» не может быть совещанием или тикетом в другом инструменте.
Дашборды: отличны для осведомлённости, слабы в исполнении
Дашборды хороши для широкой видимости и повествования, но они часто создают трение в момент, когда нужно действовать:
- Вы видите, что KPI ушёл в минус
- Копируете ID в другую систему
- Сопоставляете контекст в разных вкладках
- Документируете решение в другом месте
Это переключение контекста вызывает задержки, ошибки и несогласованность решений.
Рабочие процессы: действуй там, где видишь проблему
Операционный UX использует паттерны, которые ведут пользователя от сигнала к решению:
- Оповещения, срабатывающие при порогах, аномалиях или рисках SLA
- Очереди исключений, приоритизирующие «несколько вещей, которые требуют внимания сейчас»
- Руководимые рабочие процессы, показывающие обязательные поля, рекомендованные действия и ограничения (политика, ёмкость, допустимость)
Вместо «вот график» интерфейс отвечает: какое решение нужно, какая информация важна и какое действие можно выполнить прямо здесь?
На платформах вроде Palantir Foundry это часто означает встраивание шагов принятия решений прямо в ту же среду, где собираются исходные данные и логика.
Измерение внедрения: не только просмотры страниц
Успех BI часто измеряют использованием отчётов. Операционные системы стоит оценивать как продакшен‑инструменты:
- Процент завершения (сколько кейсов/позиций было разрешено)
- Время на решение (от оповещения до действия)
- Процент переопределений (как часто пользователи обходят рекомендации и почему)
Эти метрики показывают, действительно ли система меняет исходы, а не просто генерирует инсайты.
Сценарии, где операционные системы особенно эффективны
Операционные системы оправдывают себя, когда цель не «узнать, что произошло», а «решить, что делать дальше» — и сделать это последовательно, быстро и с прослеживаемостью.
Цепочки поставок: инвентарь, распределение и исполнение
Дашборды укажут на нехватку запасов или опоздания; операционная система поможет их устранить.
Она может рекомендовать перераспределение между DC, приоритизировать заказы по SLA и маржинальности и инициировать запросы на пополнение — фиксируя при этом, почему было принято то или иное решение (ограничения, затраты и исключения).
Производство: качество, техобслуживание и пропускная способность
При появлении проблемы качества командам нужно больше, чем график дефектов. Рабочий процесс может маршрутизировать инциденты, предлагать действия по локализации, определять затронутые партии и координировать переналадки линий.
Для планирования техобслуживания система может балансировать риск, доступность техников и производственные цели — а затем отправлять утверждённое расписание в ежедневные рабочие инструкции.
Здравоохранение и страхование: триажа дел и планирование мощности
В клиниках и при обработке претензий узким местом часто является приоритизация. Операционные системы могут триажировать дела по политике и сигналам (серьёзность, время в очереди, нехватка документов), назначать их в нужные очереди и поддерживать планирование мощности сценарием «что‑если» — без потери аудируемости.
Энергетика и коммунальные услуги: реагирование на аварии и полевые работы
Во время аварий решения должны приниматься быстро и скоординированно. Система может объединять SCADA/телеметрию, погоду, расположение бригад и историю активов, рекомендовать планы выезда, очередность восстановления и коммуникации с клиентами — а затем отслеживать исполнение по мере изменения условий.
Бэк‑офис: ревью мошенничества, кредитные операции и маршрутизация поддержки
Команды по фроду и кредиту живут в рабочих процессах: проверка, запрос данных, утвердить/отклонить, эскалация. Операционные системы стандартизируют эти шаги, применяют единообразную логику и направляют элементы к нужным ревьюерам.
В клиентской поддержке они могут направлять тикеты по намерению, ценности клиента и требуемым навыкам — улучшая исходы, а не только отчётность.
Подход к внедрению, снижающий риск
Проведите пилот одного цикла принятия решений
Выберите одно решение с высоким эффектом и реализуйте минимальный рабочий процесс от начала до конца.
Операционные системы реже терпят неудачу, если их строят как продукт, а не как «проекты с данными». Цель — доказать один цикл end‑to‑end: данные на входе, решение принято, действие выполнено и исход измерен — прежде чем расширять.
Начните с одного решения, которым можно управлять
Выберите одно решение с явной бизнес‑ценностью и реальным владельцем. Задокументируйте основы:
- Входы: какие данные нужны, откуда и как свежими они должны быть
- Владелец: кто отвечает за решение и эскалацию
- Частота: ежечасно, ежедневно, еженедельно
- SLA: как быстро решение должно быть принято и выполнено
Это сужает сферу и делает успех измеримым.
Определяйте «готово» как изменённое действие
Инсайты — не финишная линия. Определяйте «готово» через указание, какое действие меняется и где — например, обновление статуса в тикетинге, утверждение в ERP, список обзвона в CRM.
Хорошее определение включает целевую систему, точное поле/состояние и способ проверки выполнения.
Постройте минимально жизнеспособный рабочий процесс (сначала исключения)
Не пытайтесь автоматизировать всё сразу. Начните с рабочего процесса, ориентированного на исключения: система помечает элементы, требующие внимания, направляет их нужному человеку и отслеживает разрешение.
Интегрируйте только необходимое, с явными путями утверждения
Приоритезируйте несколько интеграций с высокой отдачей (ERP/CRM/тикетинг) и сделайте шаги утверждения явными. Это снижает риск «теневых решений» за пределами системы.
Планируйте управление изменениями как часть внедрения
Операционные инструменты меняют поведение. Включите обучение, стимулы и новые роли (владельцы рабочих процессов, стюарды данных) в план развёртывания, чтобы процесс действительно прижился.
Быстрое прототипирование рабочих процессов (где может помочь Koder.ai)
Практическая проблема в операционных системах — часто нужны легковесные приложения: очереди, экраны утверждений, обработка исключений и статус‑обновления — прежде чем можно доказать ценность.
Платформы вроде Koder.ai помогают быстро прототипировать такие интерфейсы с помощью чат‑управляемого, vibe‑coding подхода: опишите поток решения, сущности данных и роли, и получите начальное веб‑приложение (часто на React) и бэкенд (Go + PostgreSQL), которые можно итеративно дорабатывать.
Это не отменяет необходимости надёжной интеграции данных и управления, но сокращает цикл «от описания решения до рабочего интерфейса» — особенно если вы используете режим планирования для выравнивания заинтересованных сторон и снапшоты/откат для безопасного тестирования изменений. При необходимости экспорт исходного кода снижает риск vendor‑lock‑in.
Как выбирать: практический чек‑лист
Самый простой способ решить между Palantir Foundry vs BI — начать с решения, которое вы хотите улучшить, а не с набора желаемых функций.
1) Когда традиционный BI достаточен
Выбирайте традиционную бизнес‑аналитику (дашборды и отчётность), когда цель — видимость и обучение:
- Мониторинг KPI, трендов и исключений ("что изменилось?")
- Ad‑hoc исследование и резка‑фильтрация по новым вопросам ("почему это произошло?")
- Периодическая отчётность для руководства и комплаенса
Если главный результат — лучшее понимание (а не немедленное операционное действие), BI обычно подходит.
2) Когда нужна операционная система принятия решений
Операционная система лучше, когда решения повторяются и результат зависит от единообразного исполнения:
- Решение имеет явное действие (утвердить/отклонить, распределить, перенаправить, расписать)
- Многие люди принимают одно и то же решение в разных командах или локациях
- Важна скорость, и ждать совещания или отчёта дорого
Здесь цель — аналитика в действие: превращать данные в рабочие процессы решений, которые надёжно запускают следующий шаг.
3) Вопросы для оценки (до сравнения вендоров)
- Инвентарь решений: какие 10 самых повторяющихся решений и кто за них отвечает?
- Интеграция данных: есть ли у вас все операционные данные в одном месте или они разбросаны?
- Управление: можете ли вы объяснить «кто что и когда поменял» для ключевых выходов?
- UX: нужен ли пользователям дашборд или руководимый рабочий процесс с защитами?
- Время до ценности: можно ли пилотировать одно решение end‑to‑end за 6–10 недель?
4) Практический гибридный подход
Многие организации оставляют BI для широкой видимости и добавляют рабочие процессы решений (плюс управляемые data products и семантический слой) там, где исполнение нужно стандартизировать.
5) Следующие шаги
Создайте инвентарь решений, оцените каждое по бизнес‑влиянию и реализуемости, затем выберите одно высокоэффективное решение для пилота с понятными метриками успеха.