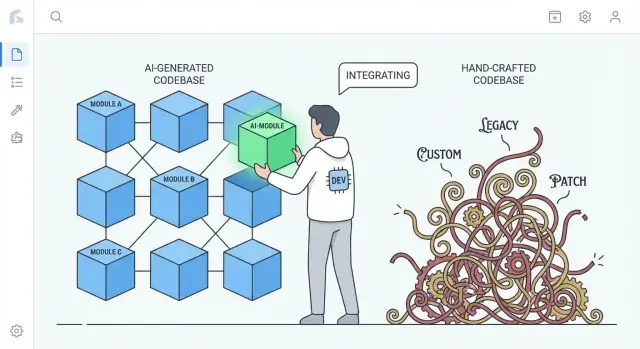
Что в реальных проектах означает «проще заменить»
«Проще заменить» редко значит удалить всё приложение и начать с нуля. В реальных командах замена происходит на разных масштабах, и «переписка» зависит от того, что именно вы меняете.
Замена vs. переписка: что реально обсуждается
Заменой может быть:
- Модуль (правила биллинга, генерация PDF, шаблоны писем)
- Сервис (API рекомендаций, фоновые воркеры)
- Фронтенд-поверхность (страница, область фичи или весь UI)
- Полная переписка приложения (редко, дорого, иногда необходимо)
Когда говорят, что кодовую базу «проще переписать», обычно подразумевают, что можно перезапустить один кусок, не распутав всё остальное, держать бизнес в работе и мигрировать постепенно.
Реальное сравнение: ИИ-сгенерированный vs. сильно кастомный код
Речь не о том, что «код ИИ лучше». Речь о типичных тенденциях.
- Сильно кастомный, вручную сделанный код может накапливать уникальные паттерны, хитрые абстракции и одноразовые «фреймворки внутри приложения». Это может быть отличной инженерией, но также создаёт приватную экосистему, понятную лишь немногим.
- ИИ-сгенерированный код чаще опирается на знакомые по умолчанию решения: мейнстрим-библиотеки, обычную слоистую архитектуру и паттерны, похожие на примеры из референс-проектов.
Эта разница важна при переписке: код, идущий по общепринятым конвенциям, обычно легче заменить на другую конвенциональную реализацию без долгих согласований и сюрпризов.
Установите ожидания: ИИ-код может быть грязным
ИИ-код может быть непоследовательным, повторяющимся или с недостаточным покрытием тестами. «Проще заменить» — не значит «чище». Это значит, что он часто менее «особенный». Если подсистема собрана из стандартных ингредиентов, её замена больше похожа на замену стандартной детали, чем на реверс-инжиниринг кастомного механизма.
Короткий анонс: зачем стандартизация снижает стоимость замены
Ключевая идея проста: стандартизация снижает стоимость переключения. Когда код состоит из узнаваемых паттернов и явных швов, вы можете регенерировать, рефакторить или переписать части без страха нарушить скрытые зависимости. Ниже объяснено, как это проявляется в структуре, владении, тестировании и повседневной скорости разработки.
Стандартные паттерны снижают стоимость старта заново
Практическое преимущество ИИ-кода в том, что он часто по умолчанию использует знакомые паттерны: прогнозируемые структуры папок, предсказуемые имена, привычные фреймворковые конвенции и «учебный» подход к маршрутизации, валидации, обработке ошибок и доступу к данным. Даже если код не идеален, он обычно читаем так же, как многие туториалы и стартер-проекты.
Знакомство важнее оригинальности при переписке
Переписка дорога в основном потому, что людям сначала нужно понять, что есть. Код, следующий известным конвенциям, сокращает время «декодирования». Новые инженеры соотносят увиденное с уже знакомыми ментальными моделями: где конфигурация, как течёт запрос, как подключаются зависимости и где находиться тесты.
Это ускоряет:
- выявление швов для замены (модули, сервисы, эндпоинты)
- воспроизведение поведения в новой реализации
- сравнение старого и нового бок о бок без перевода между стилями
В отличие от этого, сильно ручная база часто отражает персональный стиль: уникальные абстракции, самописные мини-фреймворки, «склейки», которые понятны лишь в историческом контексте. Такие решения могут быть элегантны — но увеличивают стоимость старта заново, потому что переписка должна сперва освоить мировоззрение автора.
Конвенции можно обеспечить и вручную
Это не волшебство, доступное только ИИ. Команды могут и должны навязывать структуру и стиль с помощью шаблонов, линтеров, форматтеров и скелетных инструментов. Разница в том, что ИИ склонен по умолчанию быть «универсальным», тогда как человекописные системы со временем дрейфуют в сторону кастомизации, если конвенции не поддерживать активно.
Меньше кастомного «клея» = меньше скрытых зависимостей
Много боли при переписке возникает не из-за «основной» бизнес-логики, а из-за bespoke glue — самописных хелперов, домашних мини-фреймворков, метапрограммирования и одноразовых конвенций, которые тихо связывают всё вместе.
Что считается «bespoke glue»
Это то, что не является продуктом, но без чего продукт не работает: кастомный контейнер DI, самописный роутер, магический базовый класс, автоматически регистрирующий модели, или хелперы, мутирующие глобальное состояние «для удобства». Обычно это начинается как экономия времени и становится требованием для любых изменений.
Почему уникальный клей увеличивает связность (и риск переписки)
Проблема не в существовании клея, а в том, что он превращается в невидимую связку. Если клей уникален для вашей команды, он часто:
- создаёт неявные зависимости (всё работает только потому, что хелперы вызываются в определённом порядке)
- распространяет допущения по файлам (правила именования становятся поведением)
- делает «простые» рефакторы рискованными (изменил клей — сломал всё)
При переписке этот клей трудно корректно восстановить, потому что правила редко записаны. Вы открываете их, ломая продакшн.
Почему ИИ-код склонен избегать экстремальной хитрости
ИИ-выводы часто тяготеют к стандартным библиотекам, общим паттернам и явным связкам. Модель вряд ли придумает микрофреймворк, когда подойдёт понятный модуль или сервисный объект. Такая сдержанность — фича: меньше магических хуков — меньше скрытых зависимостей, а значит проще вырезать подсистему и заменить её.
Компромисс: многословность вместо хитрости
Минус в том, что «простой» код может быть более многословным — больше параметров, явная проводка, меньше сокращений. Но многословность обычно дешевле тайны. При решении переписать вы хотите код, который легко понять, легко удалить и сложно неверно истолковать.
Предсказуемая структура поддерживает инкрементные переписки
«Предсказуемая структура» — это не про красоту, а про последовательность: одинаковые папки, правила именования и потоки запросов встречаются повсюду. ИИ-проекты часто склонны к привычным дефолтам — controllers/, services/, repositories/, models/ — с повторяющимися CRUD-эндпоинтами и похожими паттернами валидации.
Эта единообразность превращает переписку из обрыва в лестницу.
Как выглядит предсказуемость
Вы видите повторяемые паттерны:
- Чёткие границы папок (API → service → data access)
- Последовательные имена (
UserService, UserRepository, UserController)
- Похожий CRUD-поток (list → get → create → update → delete)
- Стандартная «форма» ошибок, логирования и объектов запроса/ответа
Когда каждая фича построена одинаково, вы можете заменять одну часть без постоянного переобучения.
Меняем по частям
Инкрементные переписки работают лучше, когда можно изолировать границу и реконструировать за ней. Предсказуемые структуры естественно создают такие швы: каждый слой имеет узкую роль, и большинство вызовов проходит через небольшой набор интерфейсов.
Практический подход — стиль «strangler»: сохраняйте публичный API стабильным и постепенно заменяйте внутренности.
Пример: заменить слой доступа к данным, не трогая API
Предположим, контроллеры вызывают сервисы, а сервисы — репозитории:
OrdersController → OrdersService → OrdersRepository
Хотите перейти от прямых SQL-запросов к ORM или от одной БД к другой. В предсказуемой кодовой базе изменение можно содержать:
- Создать
OrdersRepositoryV2 (новая реализация)
- Сохранить сигнатуры методов (
getOrder(id), listOrders(filters))
- Переключить проводку в одном месте (DI или фабрика)
- Запустить тесты и выкатывать фича за фичей
Контроллер и сервис останутся почти нетронутыми.
Контраст: ручные архитектуры
Высоко ручные системы могут быть отличными — но часто они кодируют уникальные идеи: абстракции, метапрограммирование или сквозное поведение в базовых классах. Это делает каждое изменение требующим глубокого исторического контекста. С предсказуемой структурой вопрос «куда менять?» обычно очевиден, и небольшие переписки возможны шаг за шагом.
Меньшая «привязанность автора» делает удаление приемлемее
Тихим препятствием в переписях часто является не технический аспект, а социальный. В командах появляется риск владения, когда лишь один человек реально понимает, как всё работает. Если этот человек писал большие части кода вручную, код может стать его личным артефактом: «мой дизайн», «мое хитрое решение», «моя лазейка, спасшая релиз». Такая привязанность делает удаление эмоционально дорогим даже при экономической целесообразности.
ИИ-сгенерированный код уменьшает этот эффект. Поскольку первоначальный черновик мог быть сгенерирован инструментом (и часто следует знакомым шаблонам), код воспринимается не как подпись, а как взаимозаменяемая реализация. Люди охотнее говорят: «Заменим этот модуль», когда это не выглядит как стирание чьего-то мастерства или вызов их статусу в команде.
Почему это меняет поведение при переписке
Когда привязанность автора ниже, команды чаще:
- свободно ставят под вопрос существующий код («Это всё ещё лучший подход?»)
- удаляют большие секции без переговоров о гордости или политике
- выбирают регенерацию или замену раньше, вместо месяцев осторожного латания
- быстрее распространяют знания, потому что никто не считает внутренности «своими владениями»
Практическое замечание
Решения о переписке всё ещё должны основываться на стоимости и результатах: сроки доставки, риск, поддерживаемость и влияние на пользователей. «Легко удалить» — полезное свойство, но не стратегия само по себе.
Промпты и следы генерации как документация
Начните со стандартных паттернов
Создайте слои для React, Go и PostgreSQL с предсказуемыми стыками для поэтапных переписок.
Одно недооценённое преимущество ИИ-кода — что входы генерации могут служить живой спецификацией. Промпт, шаблон и конфигурация генератора описывают намерение простым языком: что должна делать фича, какие ограничения важны (безопасность, производительность, стиль) и что считается «готово».
Промпты как живые спецификации
Когда команды используют повторяемые промпты (или библиотеки промптов) и стабильные шаблоны, они создают трассировку решений, которые иначе были бы неявными. Хороший промпт может явно указать то, что будущему поддерживающему обычно придётся угадывать:
- ожидаемый пользовательский поток и крайние случаи
- соглашения по именам и структуре папок
- как обрабатывать и логировать ошибки
- что должно тестироваться (и что можно мокать)
Это принципиально отличается от многих ручных кодовых баз, где ключевые архитектурные решения разбросаны по коммитам, племенной памяти и мелким, неоформленным конвенциям.
Следы генерации помогают воспроизвести поведение
Если хранить следы генерации (промпт + модель/версия + входные данные + постобработка), переписка не стартует с чистого листа. Вы можете переиспользовать тот же чеклист, чтобы воссоздать поведение в более чистой структуре, а затем сравнить выходы.
На практике это превращает переписку в: «сгенерировать фичу X под новыми конвенциями и проверить паритет», а не в «реверс-инжиниринг того, что фича X должна делать».
Важное предупреждение: относитесь к промптам как к коду
Это работает только если промпты и конфиги управляются с той же дисциплиной, что и исходники:
- версионируйте их в репозитории (не в чьих-то заметках)
- требуйте ревью изменений
- фиксируйте, какой промпт/конфиг породил какие модули
Без этого промпты станут ещё одной недокументированной зависимостью. С дисциплиной они могут стать той документацией, которой многим ручным системам не хватает.
Сильные тесты превращают переписку в рутину
«Проще заменить» — это не про то, кто писал код, а про то, можно ли изменять его с уверенностью. Переписка становится рутинной инженерной задачей, когда тесты быстро и надёжно говорят, что поведение осталось тем же.
ИИ-код может помочь в этом — если вы просите. Многие команды просят у модели генерировать шаблонные тесты вместе с фичей (простые unit-тесты, базовые интеграционные тесты, простые моки). Эти тесты не идеальны, но дают первоначальную страховку, которой часто не хватает в ручных системах, где тесты откладывали «на потом».
Ставьте контрактные тесты на границах
Если хотите заменяемости, фокусируйтесь на тестировании швов, где части встречаются:
- Внешние API: запросы, ответы, коды ошибок, повторные попытки, пагинация
- Адаптеры: платёжные провайдеры, email, файловое хранилище, очереди
- Модели данных: миграции, сериализация, правила валидации
Контрактные тесты фиксируют то, что обязательно должно оставаться верным, даже если вы меняете внутренности. Значит, можно переписать модуль за API или заменить адаптер, не споря о бизнес-логике.
Используйте покрытие как компас, не как трофей
Показатели покрытия помогают понять зону риска, но погоня за 100% часто рождает хрупкие тесты, блокирующие рефакторы. Вместо этого:
- добавляйте тесты там, где ошибки дорого обходятся (деньги, потеря данных, доверие пользователей)
- предпочитайте несколько тестов с высоким сигналом множеству поверхностных
- при переписке сравнивайте старую и новую реализации через одни и те же контрактные тесты
С сильными тестами переписки перестают быть героическими проектами и превращаются в серию безопасных, обратимых шагов.
Общие недостатки ИИ-кода чаще всего легко заметить и изолировать
Поделитесь новым срезом
Разместите пилот под кастомным доменом, чтобы поделиться им и собрать обратную связь на раннем этапе.
ИИ-код склонен к предсказуемым ошибкам. Часто встречаются дублирование логики (тот же хелпер реализован трижды), «почти одинаковые» ветки с разной обработкой краевых случаев или функции, растущие путём добавления фиксов. Это не идеально — но у этого есть преимущество: проблемы обычно видны.
Очевидные косяки лучше, чем тонкие хитрые баги
Ручные системы могут скрывать сложность за хитрыми абстракциями, микрооптимизациями или тесно связанным «как надо» поведением. Такие баги болезненны, потому что выглядят правильно и проходят поверхностный ревью.
ИИ-код скорее будет являться непоследовательным: где-то параметр игнорируется, где-то валидация есть только в одном файле, где-то стиль обработки ошибок меняется каждые несколько функций. Эти несоответствия заметны при ревью и статическом анализе и их легче изолировать, потому что они редко опираются на глубокие, намеренные инварианты.
Кандидаты на переписку проявляются через повторение
Повторение — признак. Когда вы видите один и тот же набор шагов снова и снова — parse input → normalize → validate → map → return — вы нашли естественный шов для замены. ИИ часто «решает» новую задачу, перепечатывая предыдущее решение с правками, что создаёт кластеры почти-дубликатов.
Практический подход — помечать любой повторяющийся кусок как кандидата на извлечение или замену, особенно если:
- он встречается 3+ раз с незначительными отличиями
- отличия в основном про обработку краевых случаев или тексты ошибок
- у кода нет явного владельца и он постоянно патчится
Правило: консолидация повторов в один протестированный модуль
Если вы можете описать повторяющееся поведение в одном предложении, оно, вероятно, должно стать единым модулем.
Замените повторяющиеся фрагменты одним хорошо протестированным компонентом (утилита, общий сервис или библиотечная функция), напишите тесты, фиксирующие ожидаемые краевые случаи, и удалите копии. Вы превратите множество хрупких копий в одно место для улучшений — и в одно место для будущей переписки.
Читаемость и согласованность могут перевесить ручную оптимизацию
ИИ-код часто лучше, когда вы просите оптимизировать ясность, а не хитрость. При правильных промптах и линтинге модель обычно выбирает знакомый контроль потока, привычные имена и «скучные» модули вместо новизны. Это может быть более ценной инвестицией в долгосрочной перспективе, чем несколько процентов скорости, выжатыми из ручных тонкостей.
Почему читаемый код легче переписать
Переписки успешны, когда новые люди быстро собирают корректную ментальную модель системы. Читаемый, согласованный код снижает время ответа на базовые вопросы: «куда попадает запрос?» и «какая здесь форма данных?». Если каждый сервис следует схожим паттернам (структура, обработка ошибок, логирование, конфиг), новая команда может заменять кусок за куском, не переучиваясь постоянно.
Согласованность также снижает страх. Когда код предсказуем, инженеры могут удалять и перестраивать части с уверенностью: поверхность проще понять и радиус поражения кажется меньше.
Компромисс с ручными хаковыми оптимизациями
Сильно оптимизированный вручную код трудно переписать, потому что приёмы производительности часто протекают повсюду: кастомные кэширования, микрооптимизации, самописные паттерны конкурентности или плотная связка с определёнными структурами данных. Эти решения могут быть оправданы, но часто скрывают тонкие ограничения, которые не очевидны, пока что-то не сломается.
Оговорка: производительность всё ещё важна — измеряйте её
Читаемость — не оправдание медлительности. Заслуживайте производительность доказательствами. До переписки снимите базовую метрику (перцентили задержки, CPU, память, стоимость). После замены измерьте снова. Если производительность упала, оптимизируйте конкретный горячий путь — не превращая кодовую базу в головоломку.
Регенерация vs. рефакторинг vs. перепись: как выбрать правильный сброс
Когда код с поддержкой ИИ начинает казаться «не тем», не всегда нужна полная переписка. Лучший сброс зависит от того, что именно неверно: плоха ли архитектура или просто грязная реализация.
Три варианта сброса
Регенерировать значит воссоздать часть кода из спецификации или промпта — часто начиная со шаблона или известного паттерна — и снова подсоединить точки интеграции (маршруты, контракты, тесты). Это не «удалить всё», а «построить этот срез заново по понятной спецификации».
Рефакторить — менять внутреннюю структуру без изменения поведения: переименования, разбиение модулей, упрощение условий, удаление дубликатов, улучшение тестов.
Переписать — заменить компонент или систему новой реализацией, обычно потому что текущий дизайн нельзя привести в порядок без изменения поведения, границ или потоков данных.
Когда регенерация подходит идеально
Регенерация хороша, когда код — в основном шаблонный, а ценность живёт в интерфейсах, а не в хитрой внутренней логике:
- CRUD-экраны и административные панели
- API-адаптеры и тонкие интеграционные слои
- скелет: маршрутизация, сериализаторы, DTO, простая валидация, общая обработка ошибок
Если спецификация ясна и граница чиста, регенерация часто быстрее, чем распутывание множества правок.
Когда регенерация рискована (или проваливается)
Будьте осторожны, когда код кодирует накопленные доменные знания или тонкие корректности:
- насыщенные доменные правила с множеством краевых случаев
- сложная конкурентность (очереди, блокировки, retries, идемпотентность)
- комплаенс-логика (аудит-трейлы, хранение, правила приватности)
В таких областях «довольно близко» может оказаться дорого. Регенерация всё ещё полезна, но только когда вы можете доказать эквивалентность с помощью сильных тестов и ревью.
Ворота ревью и мелкие выкаты
Относитесь к регенерированному коду как к новой зависимости: требуйте ревью человеком, запускайте полный набор тестов и добавляйте целевые тесты для известных ошибок. Выкатывайте небольшими кусками — один эндпоинт, один экран, один адаптер — за флагом или с постепенным релизом, если возможно.
Полезный дефолт: регенерируйте оболочку, рефакторьте швы, переписывайте только участки, где предположения постоянно ломаются.
Риски и ограждения для «заменяемого по дизайну» кода
Владейте генерируемым кодом
Сохраняйте полное владение — экспортируйте исходники, когда нужно перенести или проверить офлайн.
«Легко заменить» остаётся преимуществом только если команды рассматривают замену как инженерию, а не как кнопку сброса. ИИ-модули можно менять быстрее — но их и легче сломать, если доверять им больше, чем проверять.
Ключевые риски
ИИ-код часто выглядит завершённым даже когда это не так. Это создаёт ложную уверенность, особенно когда счастливые пути работают.
Второй риск — пропущенные крайние случаи: необычные входы, таймауты, конкурентность и обработка ошибок, которые не были в промпте или образцах.
Наконец, есть неопределённость по лицензиям/IP. Хотя риск низок в многих сценариях, командам нужна политика по допустимым источникам и инструментам и способ отслеживания происхождения.
Ограждения, которые держат переписки в безопасности
Ставьте замену за те же ворота, что и любые другие изменения:
- Код-ревью с явной линзой «сгенерированный код»: читаемость, режимы отказа, валидация входов и логирование
- Проверки безопасности (SAST, сканирование зависимостей, поиск секретов) и правило: сгенерированный код не может их обходить
- Политики зависимостей: предпочитайте немного, но известные библиотеки; фиксируйте версии; избегайте подтягивания нового фреймворка только потому, что промпт его предложил
- Аудит-трейсы: храните промпты, версии модели/инструмента и заметки о генерации в репозитории, чтобы изменения были объяснимы позже
Документируйте границы до замены модулей
Перед заменой компонента опишите его границы и инварианты: какие входы принимает, что гарантирует, чего никогда не должен делать (напр., «никогда не удалять данные клиента») и ожидания по производительности/латентности. Этот «контракт» — то, против чего вы тестируете — независимо от того, кто (или что) пишет код.
Лёгкий чек-лист
- Определите контракт модуля (входы/выходы, инварианты).
- Добавьте/подтвердите тесты на краевые случаи.
- Прогоните сканы безопасности и зависимостей.
- Проведите ревью на читаемость и обработку ошибок.
- Запишите метаданные промпта/инструмента.
- Выпускайте за флагом и мониторьте.
Практические выводы и простой план следующих шагов
ИИ-сгенерированный код часто легче переписать, потому что он стремится к знакомым паттернам, избегает глубокой персонализации и быстрее регенерируется при изменениях требований. Эта предсказуемость снижает социальную и техническую стоимость удаления и замены частей системы.
Цель — не «выбрасывать код», а сделать замену нормальной, малозатратной опцией, подкреплённой контрактами и тестами.
Шаги, которые можно сделать уже на этой неделе
Начните со стандартизации соглашений, чтобы любой регенерированный или переписанный код укладывался в одну форму:
- Закрепите конвенции: форматирование, структура папок, именование, обработка ошибок и форма API. Запишите это кратко в CONTRIBUTING.md.
- Добавьте контрактные тесты на границах: сфокусируйтесь на входах/выходах модулей и сервисов (HTTP-эндпоинты, сообщения в очереди, слои доступа к БД). Эти тесты должны проходить независимо от реализации.
- Храните промпты и спецификации: сохраняйте промпты, заметки требований и следы генерации рядом с кодом, чтобы будущие переписки могли воспроизвести намерение, а не только текст.
Если вы используете рабочий процесс с «vibe-coding», ищите инструменты, которые упрощают эти практики: сохранение «planning mode» спецификаций рядом с репо, захват следов генерации и поддержку безопасного отката. Например, Koder.ai спроектирован вокруг чатно-ориентированной генерации со снимками и откатом — это хорошо ложится на подход «replaceable by design»: регенерировать срез, держать контракт стабильным и быстро откатываться, если паритетные тесты падают.
Проведите небольшой пилот «заменяемого модуля»
Выберите один модуль, важный, но безопасно изолируемый — генерация отчётов, отправка уведомлений или один CRUD-участок. Определите публичный интерфейс, добавьте контрактные тесты, затем позволяйте регенерировать/рефакторить/переписывать внутренности, пока всё не станет скучным. Измеряйте время цикла, количество дефектов и усилия на ревью; используйте результаты для формулирования командных правил.
Чтобы это оформить, держите чек-лист в внутреннем playbook (или поделитесь им через /blog) и сделайте «контракты + конвенции + следы» триадой обязательной для новой работы. Если вы оцениваете поддержку инструментов, документируйте требования к решению до изучения /pricing.