21 сент. 2025 г.·8 мин
Почему C и C++ всё ещё двигают ОС, базы данных и игровые движки
Узнайте, как C и C++ по‑прежнему лежат в основе ОС, движков баз данных и игровых движков — через контроль памяти, скорость и низкоуровневый доступ.
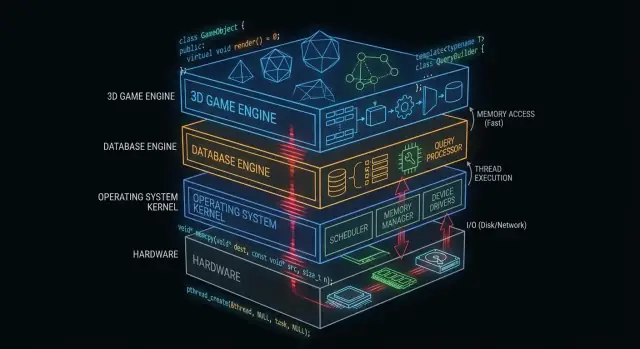
Почему C и C++ всё ещё важны «за кулисами»
«Под капотом» — это всё то, от чего зависит ваше приложение, но к чему оно редко обращается напрямую: ядра ОС, драйверы устройств, движки хранения баз данных, сетевые стеки, рантаймы и производительные библиотеки.
Напротив, с чем многие разработчики приложений сталкиваются ежедневно, — это внешние слои: фреймворки, API, управляемые рантаймы, менеджеры пакетов и облачные сервисы. Эти слои созданы ради безопасности и высокой продуктивности — даже если они сознательно скрывают сложность.
Почему некоторые слои должны быть ближе к железу
Некоторым компонентам нужна степень контроля, которую трудно обеспечить иначе:
- Предсказуемая производительность и задержки (например, планирование CPU, обработка прерываний, стриминг ассетов)
- Точный контроль памяти (расположение, выравнивание, поведение кэша, избегание пауз)
- Прямой доступ к железу (регистры, DMA, драйверы, файловые и блочные устройства)
- Небольшие, переносимые бинарники, которые могут выполняться на ранних стадиях загрузки или в ограниченных средах
C и C++ по-прежнему распространены здесь, потому что компилируются в нативный код с минимальными накладными расходами и дают инженерам тонкий контроль над памятью и системными вызовами.
Где сегодня чаще всего применяются C и C++
В широком смысле вы увидите C и C++ в:
- Ядрах операционных систем и низкоуровневых библиотеках
- Драйверах и встроенной прошивке
- Движках баз данных (выполнение запросов, хранение, индексация)
- Игровых движках и подсистемах реального времени (рендеринг, физика, аудио)
- Компиляторах, инструментальных цепочках и рантаймах языков, от которых зависят другие языки
Что охватывает (и что не охватывает) эта статья
Эта статья сосредоточена на механике: что делают эти «за кулисами» компоненты, почему им выгоден нативный код и какие компромиссы приходят вместе с этой силой.
Она не будет утверждать, что C/C++ — лучший выбор для каждого проекта, и не превратится в языковую вражду. Цель — практическое понимание того, где эти языки по‑прежнему оправдывают своё существование и почему современные стек‑технологии продолжают на них опираться.
Почему C и C++ подходят для системного ПО
C и C++ широко используются для системного программного обеспечения, потому что позволяют писать программы «близко к металлу»: маленькие, быстрые и плотно интегрированные с ОС и железом.
Компиляция в нативный код (простыми словами)
Когда код на C/C++ компилируется, он превращается в машинные инструкции, которые CPU исполняет напрямую. Нет обязательного рантайма, который переводил бы инструкции во время выполнения.
Это важно для инфраструктурных компонентов — ядер, движков баз данных, игровых движков — где даже небольшие накладные расходы накапливаются под нагрузкой.
Предсказуемая производительность для ключевой инфраструктуры
Системное ПО часто требует устойчивого времени отклика, а не только хорошей средней скорости. Например:
- Планировщик ОС должен быстро реагировать под нагрузкой.
- База данных должна сохранять стабильную задержку при большом числе параллельных запросов.
- Игровой движок должен укладываться в бюджет кадра (например, ~16 ms для 60 FPS).
C/C++ дают контроль над использованием CPU, расположением памяти и структурами данных, что помогает добиться предсказуемой производительности.
Прямой доступ к памяти и указателям
Указатели позволяют работать с адресами памяти напрямую. Эта мощь может пугать, но она открывает возможности, которые многие языки более высокого уровня абстрагируют:
- Кастомные аллокаторы, настроенные под конкретные нагрузки
- Компактные форматы в памяти (важно для баз данных и кэшей)
- Шаблоны нулевого копирования (zero-copy I/O), когда данные не копируются повторно
При аккуратном использовании такой контроль даёт значительные выигрыши в эффективности.
Компромиссы: безопасность, сложность и время развития
Та же свобода — и риск. Типичные компромиссы:
- Безопасность: ошибки могут привести к крахам, порче данных или уязвимостям.
- Сложность: ручное управление памятью и неопределённое поведение требуют дисциплины.
- Время разработки: тестирование, ревью и инструменты становятся обязательными для надёжности.
Распространённый подход — держать производительно критическое ядро в C/C++, а окружать его более безопасными языками для фич и UX.
C/C++ в ядрах операционных систем
Ядро операционной системы находится ближе всего к железу. Когда ваш ноутбук просыпается, открывается браузер или программа запрашивает память, именно ядро координирует эти запросы и принимает решение.
Что на самом деле делает ядро
Практически ядра занимаются несколькими ключевыми задачами:
- Планирование: решение, какой программе (и какому потоку) выделить время CPU и на какой срок.
- Управление памятью: выделение памяти процессам, изоляция и безопасное освобождение.
- Управление устройствами: общение с железом через драйверы (диск, сеть, клавиатура, GPU и т. д.).
- Границы безопасности: соблюдение прав доступа, чтобы одна программа не читала и не портила данные другой.
Поскольку эти обязанности в центре системы, код ядра одновременно чувствителен к производительности и к корректности.
Почему строгий контроль благоприятствует C (а иногда и C++)
Разработчикам ядра нужен точный контроль над:
- Расположением памяти: структуры фиксированного размера, выравнивание и предсказуемое поведение при выделении.
- Инструкциями CPU и соглашениями о вызовах: взаимодействие с прерываниями, переключениями контекстов и низкоуровневой синхронизацией.
- Аппаратными регистрами: чтение/запись по конкретным адресам и работа в специальных режимах CPU.
C остаётся типичным «языком ядра», потому что он хорошо отображается на машинные понятия, оставаясь читаемым и переносимым между архитектурами. Многие ядра также используют ассемблер для самых маленьких и аппаратно‑специфичных частей, в то время как большая часть логики пишется на C.
C++ может появляться в ядрах, но обычно в ограничённом стиле (ограниченные возможности рантайма, осторожные политики обработки исключений и строгие правила выделения). Где он используется, чаще всего это улучшение абстракции без потери контроля.
Код, смежный с ядром, часто пишут на C/C++
Даже если само ядро консервативно, многие близкие компоненты пишутся на C/C++:
- Драйверы устройств (особенно производительные)
- Стандартные библиотеки и рантаймы (части libc, низкоуровневая работа с потоками)
- Загрузчики и код раннего старта
- Системные службы, которым нужна нативная скорость (например, сетевые или хранилищные помощники)
Для большего о том, как драйверы связывают ПО и железо, см. /blog/device-drivers-and-hardware-access.
Драйверы устройств и доступ к железу
Драйверы переводят команды между ОС и физическим оборудованием — сетевые карты, GPU, контроллеры SSD, аудиоустройства и т. д. Когда вы нажимаете «плей», копируете файл или подключаетесь к Wi‑Fi, драйвер часто должен первым отреагировать.
Поскольку драйверы находятся на «горячем пути» ввода/вывода, они крайне чувствительны к производительности. Дополнительные микросекунды на пакет или на запрос к диску быстро суммируются при высокой загрузке. C и C++ по‑прежнему распространены, потому что могут вызывать API ядра ОС напрямую, контролировать расположение памяти точно и работать с минимальными накладными расходами.
Прерывания, DMA и почему важны низкоуровневые API
Устройства не «ожидают своей очереди». Они сигнализируют CPU через прерывания — срочные уведомления о событии (пакет пришёл, перенос завершён). Код драйвера должен быстро и корректно обрабатывать такие события, часто в условиях жёстких требований по времени и по потокам.
Для высокой пропускной способности драйверы также полагаются на DMA (Direct Memory Access), когда устройство читает/записывает системную память без копирования каждым байтом CPU. Настройка DMA обычно включает:
- Подготовку буферов в нужном формате и выравнивании
- Передачу устройству физических адресов или отображённых дескрипторов
- Синхронизацию владения памятью между устройством и CPU
Эти задачи требуют низкоуровневых интерфейсов: отображаемых в память регистров, битовых флагов и аккуратного порядка операций чтения/записи. C/C++ позволяют практично выражать такую «близкую к металлу» логику и при этом оставаться переносимыми между компиляторами и платформами.
Стабильность — обязательна
В отличие от обычного приложения, ошибка в драйвере может повесить всю систему, повредить данные или открыть уязвимость. Этот риск формирует подход к написанию и ревью драйверного кода.
Команды снижают опасность строгими стандартами кодирования, защитными проверками и многоуровневыми ревью. Распространённые практики включают ограничение опасного использования указателей, валидацию входов от железа/прошивок и запуск статического анализа в CI.
Управление памятью: возможности и ловушки
Владейте кодовой базой
Экспортируйте исходный код, когда вам нужен полный контроль или собственные инструменты.
Управление памятью — одна из главных причин, по которой C и C++ всё ещё доминируют в частях ОС, баз данных и игровых движков. Это также одно из самых легких мест для возникновения тонких ошибок.
Что значит «управление памятью»
На практике управление памятью включает:
- Выделение памяти (получение куска для хранения данных)
- Освобождение её (возврат, когда она больше не нужна)
- Обработку фрагментации (остаточные «дыры», которые усложняют будущие выделения)
В C это часто явно (malloc/free). В C++ это может быть явно (new/delete) или обёрнуто в безопасные шаблоны.
Почему ручной контроль бывает преимуществом
В компонентах с критичными требованиями к производительности ручной контроль — это преимущество:
- Можно избежать непредсказуемых пауз сборщика мусора.
- Можно выбирать где и как выделяется память (пулы, ареновские аллокаторы), улучшая устойчивость.
- Можно адаптировать паттерны выделения к реальным нагрузкам (множество мелких объектов против больших смежных буферов).
Это важно, когда база данных должна поддерживать стабильную задержку или движок игры — укладываться в бюджет кадра.
Частые режимы отказа (и почему они серьёзны)
Та же свобода создаёт классические проблемы:
- Утечки памяти: забыли освободить — потребление растёт, пока не наступит деградация или крах процесса.
- Переполнение буфера: запись за пределы массива, повреждение данных или открытие векторов атак.
- Использование после освобождения: обращение к указателю после
free, приводящее к крахам, которые трудно воспроизвести.
Эти баги часто тонки: программа может «работать нормально», пока конкретная нагрузка не вызовет ошибку.
Как помогают современные практики
Современный C++ снижает риски, не жертвуя контролем:
- RAII (Resource Acquisition Is Initialization) связывает время жизни ресурсов со скоупом, обеспечивая автоматический клин‑ап.
- Умные указатели (
std::unique_ptr,std::shared_ptr) делают владение явным и предотвращают многие утечки. - Sanitizers (AddressSanitizer, UndefinedBehaviorSanitizer) и статический анализ ловят проблемы рано, часто в CI.
При грамотном использовании эти инструменты сохраняют скорость C/C++, делая потенциальные ошибки памяти менее вероятными в продакшене.
Конкуренция и производительность на многопоточном железе
Современные CPU не получают существенно большей скорости на одно ядро — они получают больше ядер. Это меняет вопрос производительности с «насколько быстрый мой код?» на «насколько хорошо код работает параллельно, не мешая самому себе?» C и C++ популярны здесь, потому что дают низкоуровневый контроль над потоками, синхронизацией и поведением памяти с минимальными накладными расходами.
Потоки, ядра и планирование
Поток — это единица работы в программе; ядро CPU — место, где эта работа выполняется. Планировщик ОС сопоставляет runnable‑потоки с доступными ядрами, постоянно делая компромиссы.
Небольшие детали планирования важны в производительном коде: приостановка потока в неправильный момент может заблокировать конвейер, создать очереди или вызвать неплавность. Для CPU‑интенсивной работы согласование числа активных потоков с числом ядер помогает уменьшить thrashing.
Основы блокировок: мьютексы, атомарные операции и конкуренция
- Мьютексы просты для рассуждений, но при сильном шарировании создают контенцию — время ожидания вместо работы.
- Атомарные операции могут быть быстрее для небольших глобальных обновлений, но требуют аккуратного дизайна, чтобы избежать тонких багов корректности.
Практическая цель не в «никогда не блокироваться», а в: блокироваться меньше, но умнее — держать критические секции короткими, избегать глобальных блокировок и уменьшать разделяемое изменяемое состояние.
Почему всплески задержек важны
Базы данных и игровые движки заботятся не только о средней скорости — им важны худшие паузы. Конвой мьютексов, page fault или застывший рабочий поток могут вызвать заметные подвисания или медленный запрос, нарушающий SLA.
Распространённые шаблоны в C/C++
Многие высокопроизводительные системы полагаются на:
- Пулы потоков для повторного использования рабочих и предсказуемого планирования.
- Очереди с work‑stealing для балансировки нагрузки между ядрами.
- Безблоковые очереди (в горячих путях) для уменьшения блокировок — но их корректность сложнее доказать.
Эти шаблоны ориентированы на стабильную пропускную способность и предсказуемую задержку при высокой нагрузке.
Движки баз данных: где C/C++ приносят скорость
Движок базы данных — это не просто «хранение строк». Это плотный цикл CPU и I/O, который выполняется миллионы раз в секунду, где мелкие неэффективности быстро растут. Именно поэтому многие движки и их критические компоненты всё ещё активно пишутся на C или C++.
Основная задача движка: парсинг, планирование, исполнение
Когда вы отправляете SQL, движок:
- Парсит запрос (преобразует текст в структурированное представление)
- Планирует (выбирает эффективный способ выполнения)
- Выполняет (сканирование, поиск по индексам, соединения, сортировки, агрегирование и возврат рядов)
Каждый этап выигрывает от тщательного контроля над памятью и временем CPU. C/C++ дают быстрые парсеры, меньше аллокаций при построении планов и экономный горячий путь исполнения — часто с кастомными структурами данных под нагрузку.
Движки хранения: страницы, индексы, буферизация
Под уровнем SQL движок хранения решает базовые задачи:
- Страницы: данные читаются и записываются фиксированными блоками, а не по одной строке.
- Индексы: B‑деревья, LSM‑деревья и родственные структуры нужно эффективно обновлять.
- Буферизация: пул буферов решает, что держать в памяти, что выкидывать и как батчить чтения/записи.
C/C++ подходят для этого потому, что эти компоненты зависят от предсказуемого расположения в памяти и контроля границ ввода/вывода.
Кэш‑дружественные структуры данных (почему это важно)
Современная производительность часто зависит больше от CPU‑кешей, чем от сырой скорости CPU. С помощью C/C++ разработчики могут упаковывать часто используемые поля рядом, хранить колонки в смежных массивах и минимизировать следование по указателям — паттерны, которые держат данные ближе к CPU и уменьшают простои.
Где всё ещё появляются языки высокого уровня
Даже в базах, где ядро сильно на C/C++, языки высокого уровня часто используются для инструментов администрирования, бэкапов, мониторинга, миграций и оркестрации. Производительное ядро остаётся нативным; окружающая экосистема выбирает скорость итерации и удобство.
Хранение, кэширование и ввод/вывод в базах данных
Изолируйте нативный код
Прототипируйте границу FFI и подключайте приложение к существующему коду на C или C++.
Базы данных кажутся мгновенными, потому что они стараются избегать диска. Даже на быстрых SSD чтение со стораджа на порядки медленнее, чем чтение из RAM. Движок на C/C++ может контролировать каждый шаг ожидания — и часто избегать его.
Пул буферов и кэш страниц простыми словами
Представьте данные на диске как коробки в складе. Доставать коробку (чтение с диска) занимает время, поэтому наиболее используемые предметы держат на столе (RAM).
- Пул буферов: «стол» базы данных, хранящий недавно использованные страницы (фиксированные куски таблиц и индексов).
- Кэш страниц: «стол» ОС, кэширующий недавно прочитанные данные файлов.
Многие базы управляют собственным пулом буферов, чтобы прогнозировать, что должно оставаться горячим, и не бороться с ОС за память.
Почему диск медлен и как кэш это скрывает
Хранилище не только медленное, но и непредсказуемое. Всплески задержек, очереди и случайный доступ добавляют задержку. Кэширование смягчает это:
- Читает из RAM чаще всего
- Батчит записи в большие I/O‑операции
- Предзагружает страницы, которые могут понадобиться далее (например, при сканировании индекса)
Решения, выигрывающие от низкоуровневого контроля
C/C++ позволяют движкам тонко настраивать важные детали при высокой пропускной способности: выровненные чтения, прямой I/O против буферизованного, кастомные политики вытеснения и продуманную организацию в памяти для индексов и лог‑буферов. Эти решения уменьшают копирования, избегают контенций и держат кеши CPU насыщенными.
Сжатие и контрольные суммы могут быть узким местом по CPU
Кэширование уменьшает I/O, но увеличивает нагрузку на CPU. Распаковка страниц, вычисление контрольных сумм, шифрование логов и валидация записей могут стать бутылочными горлышками. Поскольку C и C++ дают контроль над шаблонами доступа к памяти и облегчают векторизацию SIMD‑циклов, их часто используют, чтобы выжать больше работы из каждого ядра.
Игровые движки: ограничения реального времени
Игровые движки работают при строгих ожиданиях реального времени: игрок поворачивает камеру или нажимает кнопку, и мир должен откликнуться мгновенно. Это измеряется временем кадра, а не средней пропускной способностью.
Бюджеты кадров: почему миллисекунды важны
При 60 FPS на кадр даётся примерно 16.7 ms: симуляция, анимация, физика, сведение аудио, отбор объектов, отправка команд рендереру и часто стриминг ассетов. При 120 FPS бюджет падает до 8.3 ms. Превышение бюджета проявляется в виде просадок, задержки ввода или непоследовательного темпа.
Именно поэтому программирование на C и программирование на C++ остаются распространёнными в ядрах движков: предсказуемая производительность, низкие накладные расходы и точный контроль над памятью и CPU.
Основные подсистемы обычно на C/C++
Большинство движков использует нативный код для тяжёлых операций:
- Рендеринг (обход сцены, формирование draw‑вызовов, управление ресурсами GPU)
- Физика (детекция коллизий, ограничения, жёсткие тела)
- Анимация (skeletal blending, IK, вычисление поз)
- Аудио (реальное‑временное смешивание, пространственное звучание)
Эти системы запускаются каждый кадр, поэтому мелкие неэффективности быстро накапливаются.
Плотные циклы и расположение данных
Много производительности в играх — это плотные циклы: итерация по сущностям, обновление трансформов, проверка столкновений, скиннинг вершин. C/C++ упрощают организацию памяти для эффективности кэша (контiguous arrays, меньше аллокаций, меньше виртуальных переходов). Расположение данных может быть так же важно, как выбор алгоритма.
Где уместен скриптинг (а где нет)
Многие студии используют скриптовые языки для логики геймплея — квестов, правил UI, триггеров — потому что важна скорость итерации. Ядро движка обычно остаётся нативным, а скрипты вызывают C/C++‑системы через биндинги. Типичный паттерн: скрипты оркестрируют; C/C++ выполняет тяжёлые операции.
Компиляторы, инструментальные цепочки и межъязыковое взаимодействие
Быстро выпустите первую версию
Превратите идею в рабочее веб‑приложение без предварительной настройки полного набора инструментов.
C и C++ не просто «запускаются» — их собирают в нативные бинарники, соответствующие конкретному CPU и ОС. Этот пайплайн сборки — одна из причин, почему языки остаются центральными для ОС, баз данных и игровых движков.
Что происходит при сборке
Типичная сборка проходит несколько этапов:
- Компилятор: превращает исходники C/C++ в объектные файлы для конкретной машины.
- Линкер: связывает объекты и библиотеки в исполняемый файл или разделяемую библиотеку.
- Бинарный результат: финальный артефакт, который ОС может загрузить (часто отдельно с отладочными символами).
На этапе линковки часто проявляются реальные проблемы: пропавшие символы, несовместимые версии библиотек или разные флаги сборки.
Почему инструментальные цепочки и поддержка платформ важны
«Toolchain» — это весь набор: компилятор, линкер, стандартная библиотека и утилиты сборки. Для системного ПО покрытие платформ зачастую решающе:
- SDK консолей и мобильных платформ могут требовать специфические компиляторы и линкеры.
- Базы и серверное ПО нуждаются в стабильных сборках по разным дистрибутивам Linux и типам CPU.
- Работа с ОС и драйверами может требовать кросс‑компиляторов, строгих флагов и дисциплины ABI.
Команды выбирают C/C++ во многом потому, что инструментальные цепочки зрелы и доступны везде — от встраиваемых устройств до серверов.
Взаимодействие с другими языками (FFI)
C часто рассматривают как «универсальный адаптер». Многие языки могут вызывать C‑функции через FFI, поэтому команды нередко помещают критическую логику в библиотеку на C/C++ и экспонируют маленький API кода более высокого уровня. Именно поэтому Python, Rust, Java и другие часто оборачивают существующие C/C++‑компоненты, а не переписывают их.
Отладка и профилирование: что измеряют команды
Команды на C/C++ обычно измеряют:
- Время CPU (горячие функции, стеки вызовов)
- Использование памяти (аллокации, утечки, фрагментация)
- Задержки (время кадра в играх, время ответа запроса в базах)
- Поведение I/O (промахи кэша, чтения с диска, системные вызовы)
Рабочий цикл стандартный: найти бутылочное горлышко, подтвердить данные, оптимизировать самую маленькую важную часть.
Выбор C/C++ сегодня: практическое руководство
C и C++ остаются отличными инструментами — когда вы строите ПО, где важны миллисекунды, байты или конкретная инструкция CPU. Они не являются универсальным выбором для каждой фичи или команды.
Когда выбирать C/C++
Выбирайте C/C++, когда компонент критичен по производительности, требует строгого контроля памяти или должен тесно интегрироваться с ОС или железом.
Типичные сценарии:
- Горячие пути, где видна латентность (парсинг, сжатие, рендеринг, выполнение запросов)
- Низкоуровневые модули, которые должны быть предсказуемыми (аллокаторы, планировщики, сетевые примитивы)
- Кроссплатформенные библиотеки, где нативный код — продукт сам по себе (SDK, движки, embedded)
- Ситуации, где требуются переносимость между компиляторами/инструментальными цепочками
Когда предпочесть другие языки
Выбирайте язык более высокого уровня, когда приоритеты — безопасность, скорость итерации или поддерживаемость в масштабе.
Часто разумнее использовать Rust, Go, Java, C#, Python или TypeScript, когда:
- Команда большая и ожидается текучка (меньше «лазеек» — это важно)
- Фича часто меняется и корректность важнее выжимания циклов
- Нужны сильные гарантии безопасности памяти
- Производительность команды и рынок найма важнее сырой скорости
На практике большинство продуктов смешанные: нативные библиотеки для критического пути и языки высокого уровня для остального.
Практическая заметка для команд приложений (где полезен Koder.ai)
Если вы в основном строите веб, бэкенд или мобильные фичи, вам часто не нужно писать C/C++, чтобы пользоваться его преимуществами — вы потребляете его через ОС, базу данных, рантайм и зависимости. Платформы вроде Koder.ai используют такое разделение: вы быстро создаёте React‑вебприложения, Go + PostgreSQL бэкенды или Flutter‑мобильные приложения через чат‑ориентированный рабочий процесс, одновременно интегрируя нативные компоненты при необходимости (например, вызов существующей библиотеки на C/C++ через FFI). Так большая часть продукта остаётся в быстро итерабельном коде, но при этом не игнорируются случаи, где нативный код — правильный инструмент.
Практический чек‑лист (по компонентам)
Задайте себе эти вопросы перед решением:
- На критическом ли это пути? Сначала измеряйте; не догадывайтесь.
- Какие режимы отказа? Коррупция памяти в C/C++ может быть катастрофичной.
- Какой интерфейс на границе? Можно ли изолировать нативный код за маленьким API?
- Есть ли у вас экспертиза? Ревью, тестирование и профилирование — обязательно.
- Какая целевая платформа? Консоли, embedded, ядра и драйверы часто предпочитают C/C++.
- Как будете тестировать и профилировать? Планируйте инструменты и CI с самого начала.
Рекомендуемые следующие чтения
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing