04 июн. 2025 г.·7 мин
Почему горизонтальное масштабирование сложнее, чем вертикальное
Вертикальное масштабирование — это обычно добавление CPU/RAM. Горизонтальное требует координации, разбиения данных, поддержания согласованности и больше операций — поэтому это сложнее.
Масштабирование простыми словами
Масштабирование означает «обрабатывать больше, не падая». Это «больше» может быть:
- Больше пользователей, использующих продукт одновременно
- Больше API‑запросов в секунду
- Больше данных для хранения и запросов
- Больше фоновой работы (письма, обработка видео, отчёты), выполняемой за сценой
Когда говорят о масштабировании, обычно цель — улучшить одно или несколько из этих свойств:
- Вместимость: сколько трафика или данных система может выдержать.\n- Скорость: как быстро она отвечает под нагрузкой.\n- Надёжность: насколько хорошо она продолжает работать при сбоях.
Большая часть сводится к одной теме: масштабирование вверх сохраняет ощущение «одной системы», в то время как масштабирование вширь превращает систему в координируемую группу независимых машин — и именно в этой координации сложность взрывается.
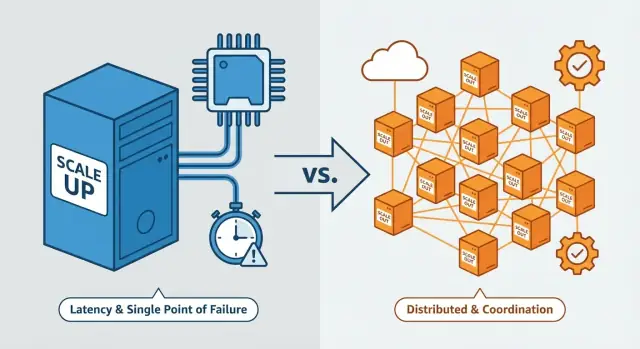
Вертикальное vs горизонтальное масштабирование (короткие определения)
Вертикальное масштабирование (scale up)
Вертикальное масштабирование означает сделать одну машину мощнее. Архитектура остаётся та же, но сервер (или VM) апгрейдится: больше CPU‑ядер, больше RAM, быстрые диски, выше пропускная способность сети.
Думайте об этом как о покупке большего грузовика: всё тот же водитель и один автомобиль, просто он вмещает больше.
Горизонтальное масштабирование (scale out)
Горизонтальное масштабирование означает добавить больше машин или инстансов и разделить работу между ними — часто за балансировщиком нагрузки. Вместо одной мощной машины у вас несколько серверов, работающих вместе.
Это похоже на использование большего числа грузовиков: перевозить можно больше, но теперь нужно планирование, маршрутизация и координация.
Что обычно заставляет задуматься?
Частые триггеры:
- Всплески трафика (маркетинговые кампании, сезонность, вирусный рост)
- Постоянный рост продукта в течение месяцев или лет
- Увеличение объёмов данных (больше клиентов, событий, истории для хранения)
Важный нюанс: большинство реальных систем используют оба подхода
Команды часто сначала масштабируются вверх — это быстро (апгрейд сервера), затем переходят к масштабированию вширь, когда одна машина достигает пределов или нужна более высокая доступность. Зрелые архитектуры обычно комбинируют оба подхода: более мощные узлы и больше узлов, в зависимости от узкого места.
Почему вертикальное масштабирование кажется проще
Вертикальное масштабирование привлекательно, потому что оставляет систему в одном месте. На одном узле обычно есть единый источник правды для памяти и локального состояния. Один процесс владеет in‑memory кешем, очередью задач, хранилищем сессий (если сессии в памяти) и временными файлами.
Меньше движущихся частей
На одном сервере большинство операций просты, потому что почти нет межузловой координации:
- Отладка легче: логи и метрики в одном месте.\n- Отказы понятнее: либо машина здорова, либо нет.\n- Многие узкие места локальны и измеримы.
Настройка производительности остаётся «локальной»
При масштабировании вверх вы тянете знакомые рычаги: добавляете CPU/RAM, используете более быстрое хранилище, улучшаете индексы, настраиваете запросы и конфигурации. Не нужно переделывать распределение данных или то, как несколько узлов согласуют «что будет дальше».\n
Принятые компромиссы
Вертикальное масштабирование не бесплатно — оно просто держит сложность в одном месте.
Рано или поздно вы столкнётесь с лимитами: наибольший доступный инстанс, убывающая отдача или крутая кривая стоимости в верхнем сегменте. Также растёт риск простоя: если одна большая машина падает или требует обслуживания, большая часть системы пострадает, если вы не добавили резервирование.
Накладные расходы координации: больше узлов — больше правил
При масштабировании вширь вы получаете не просто «больше серверов». Вы получаете больше независимых акторов, которые должны договориться, кто отвечает за какую работу, в какой момент и с какими данными.
На одном сервере координация часто неявная: одна область памяти, один процесс, одно место для состояния. С множеством машин координация становится фичей, которую нужно проектировать.
Как координация выглядит на практике
Распространённые инструменты и паттерны:
- Выбор лидера: выбрать узел, принимающий решения (например, какой воркер возьмёт следующую задачу). Если лидер умирает, все должны договориться о замене.\n- Локи/аренды: гарантировать, что только один узел выполняет задачу одновременно. Аренды истекают, часы дрейфуют — спор «кому принадлежит лок» усложняется.\n- Системы консенсуса: небольшая группа узлов поддерживает согласованное представление критического состояния (конфигурация, состав кластера, лидерство). Мощно, но операционно требовательно.
Симптомы при провалах координации
Ошибки координации редко выглядят как чистые падения. Чаще вы увидите:
- Состояния гонки: два узла действуют над одними данными в неправильном порядке.\n- Дублирующаяся работа: одна и та же задача выполняется дважды, потому что два воркера считали её незанятой.\n- Split‑brain: сетевой сбой создаёт двух «лидеров», каждый из которых уверенно принимает противоречивые решения.
Эти проблемы часто проявляются только под реальной нагрузкой, во время деплоев или при частичных сбоях (узел тормозит, коммутатор теряет пакеты, зона на мгновение недоступна). Система выглядит нормально — пока не будет стресс‑сценария.
Разбиение данных и шардинг — сложно сделать правильно
При масштабировании вширь вы часто не можете хранить все данные в одном месте. Их разбивают по машинам (шарды), чтобы несколько узлов могли хранить и обслуживать запросы параллельно. В этом разбиении начинается сложность: каждое чтение и запись зависит от вопроса «в каком шарде хранится эта запись?».
Распространённые стратегии: range vs hash
Range‑partitioning группирует данные по упорядоченному ключу (например, пользователи A–F на шарде 1, G–M на шарде 2). Интуитивно понятно и хорошо для диапазонных запросов («показать заказы за прошлую неделю»). Минус — неравномерная нагрузка: если один диапазон внезапно популярен, его шардер становится узким местом.
Hash‑partitioning пропускает ключ через хеш‑функцию и распределяет результаты по шардом. Это равномернее распределяет трафик, но усложняет диапазонные запросы, потому что связанные записи разбросаны.
Ребалансировка — не бесплатно
Добавили узел и хотите его использовать — часть данных нужно переместить. Удалили узел (по плану или из‑за сбоя) — остальные шарды должны подхватить нагрузку. Ребалансировка может вызвать большие переносы, прогрев кешей и временные падения производительности. Во время перемещения нужно также предотвращать старые чтения и неправильную маршрутизацию записей.
Горячие партиции и ски́н
Даже при хеше реальный трафик неравномерен. Звёздный аккаунт, популярный товар или временные паттерны доступа могут сконцентрировать операции на одном шарде. Один «горячий» шард может ограничить общую пропускную способность системы.
Операционная работа, которую нельзя игнорировать
Шардинг вводит постоянные обязанности: поддержка правил маршрутизации, запуск миграций, выполнение бэкофиллов после изменений схемы и планирование разделения/слияния шардов без нарушения клиентов.
Состояние: сессии, кеши и фоновая работа
Планируйте шаги масштабирования
Набросайте план вертикального и горизонтального масштабирования в Koder.ai перед переписыванием архитектуры.
При масштабировании вширь вы не просто добавляете серверы — вы добавляете копии приложения. Сложность в том, что такое «состояние»: всё, что приложение «помнит» между запросами или во время работы.
Сессии: где хранится информация о логине?
Если пользователь залогинился на сервере A, а следующий запрос попадает на сервер B, знает ли B, кто это?
- Sticky sessions отправляют пользователя на тот же сервер. Просто, но хрупко: перезапуски и неравномерная нагрузка становятся видимыми пользователю.\n- Общее хранилище сессий (Redis или БД) позволяет любому серверу обработать любой запрос. Более надёжно, но добавляет зависимость; если стор сессий тормозит, всё приложение замедляется.
Кеши: быстро, пока они не разошлись
Кеши ускоряют работу, но несколько серверов значит несколько кешей. Теперь возникают вопросы:
- Инвалидация: как предотвратить, чтобы каждый кеш отдавал устаревшее значение?\n- Коэрентность: узлы могут не соглашаться о «правде» в короткие окна времени.\n- Неравномерные hit‑rate: один сервер «тёплый», другой «холодный» — производительность будет различной.
Фоновая работа: как избежать двойной обработки
С множеством воркеров фоновые задачи могут выполняться дважды, если не продумать защиту. Обычно нужны очередь, аренды/локи или идемпотентная логика задач, чтобы «отправить счёт» или «списать карту» не произошло дважды — особенно при ретраях и рестартах.
Проблемы согласованности и конкурентности умножаются
С одним узлом (или одной основной БД) обычно есть ясный «источник правды». При масштабировании вширь данные и запросы распределяются по машинам, и поддержание синхронности становится постоянной заботой.
Сильная vs итоговая согласованность (простыми словами)
- Сильная согласованность: после записи все читатели сразу видят последнее значение.\n- Итоговая согласованность: обновления распространяются, но некоторое время часть читателей может видеть старые данные.
Итоговая согласованность часто быстрее и дешевле в масштабах, но приносит неожиданные краевые случаи.
Что ломается в реальных системах
Типичные проблемы:
- Старые чтения: пользователь обновил адрес, сделал рефреш и всё ещё видит старое.\n- Конфликты записей: два обновления почти одновременно затирают друг друга.\n- Потерянные изменения: «последняя запись побеждает» скрытно теряет изменение, которое надо было слить.
Паттерны для уменьшения вреда
Нельзя полностью устранить отказы, но можно проектировать систему так, чтобы они причиняли меньше вреда:
- Ключи идемпотентности: повторы «создать платёж» не приведут к двойному списанию.\n- Ретраи с бэкофом: повтор через 200ms, потом 400ms, потом 800ms (с джиттером), чтобы избежать штампа запросов.\n- Дедупликация: при приходе одного и того же сообщения дважды — обработать один раз.
Почему распределённые транзакции сложны
Транзакция через сервисы (заказ + инвентарь + платёж) требует, чтобы несколько систем согласились. Если один шаг падает посередине, нужны компенсирующие действия и аккуратный учёт. Классическое поведение «всё или ничего» трудно обеспечить, когда сеть и узлы могут падать независимо.
Где важна сильная согласованность
Сильную согласованность применяйте для того, что должно быть корректным: платежи, балансы, учёт товара, бронирование мест. Для менее критичных данных (аналитика, рекомендации) часто достаточна итоговая согласованность.
Сеть: задержки, таймауты и повторные попытки
При масштабировании вверх многие вызовы — это вызовы функций в одном процессе: быстро и предсказуемо. При масштабировании вширь те же взаимодействия становятся сетевыми вызовами — с добавлением задержки, джиттера и новых режимов отказа, которые код должен обрабатывать.
Задержка — это не просто «немного медленнее»
Сетевые вызовы имеют фиксированную накладную (сериализация, очереди, хопы) и переменную (конгестия, маршрутизация, «шумные соседи»). Даже если средняя задержка в порядке, хвосты (slowest 1–5%) могут доминировать в пользовательском опыте, потому что один медленный зависимый сервис тормозит весь запрос.
Пропускная способность и потеря пакетов тоже становятся ограничениями: при больших скоростях «маленькие» полезные нагрузки суммируются, и повторы тихо увеличивают нагрузку.
Таймауты, ретраи и штормы повторов
Без таймаутов медленные вызовы накапливаются и потоки блокируются. С таймаутами и ретраями можно восстанавливаться — пока ретраи не усилят нагрузку.
Обычная ошибка: backend замедляется, клиенты таймаутят и повторяют, повторы увеличивают нагрузку, backend ещё больше замедляется.
Более безопасные ретраи обычно требуют:
- консервативных таймаутов, основанных на реальных данных о задержках\n- ограниченного числа попыток (часто 0–1) с экспоненциальным бэкофом и джиттером\n- ясных правил, что безопасно ретраить (идемпотентные операции)
Балансировщики и discovery сервисы
С множеством инстансов клиентам нужно знать, куда слать запросы — через балансировщик или через discovery + client‑side балансировку. В любом случае добавляются элементы: health checks, connection draining, неравномерное распределение трафика и риск маршрутизации на частично сломанный инстанс.
Обратное давление и ограничение скорости
Чтобы не дать перегрузиться всей системе, нужны механизмы обратного давления: ограниченные очереди, circuit breakers и rate limiting. Цель — быстро и предсказуемо отказывать вместо того, чтобы позволить небольшой замедлению перерасти в инцидент на всю систему.
Режимы отказов меняются: частичный отказ становится нормой
Превратите обучение в кредиты
Получайте кредиты, делясь контентом о Koder.ai или приглашая коллег.
Вертикальное масштабирование обычно ломается предсказуемо: одна большая машина — единая точка отказа. Если она тормозит или падает, эффект очевиден.
Горизонтальное масштабирование меняет математику. С множеством узлов нормально, что некоторые машины нездоровы, а другие в порядке. Система «в сети», но пользователи видят ошибки, медленные страницы или несогласованное поведение. Это — частичный отказ, и на него нужно ориентироваться при проектировании.
Как частичные отказы превращаются в каскады
В распределённой системе сервисы зависят друг от друга: БД, кеши, очереди, сторонние API. Небольшая проблема может распространиться:
- Один узел не может достучаться до БД → он агрессивно ретраит\n- Ретраи увеличивают нагрузку на БД → задержки растут для всех\n- Бóльшая задержка вызывает таймауты → ещё больше ретраев → ещё большая нагрузка\n- Очереди накапливаются, кеши промахиваются, downstream API получают шторм трафика
Резервирование помогает, но вводит правила
Чтобы пережить частичные отказы, системы добавляют резервирование:
- Репликация: несколько копий данных/сервисов\n- Кворумы: успешно, если N из M реплик согласны\n- Развёртывание по зонам: чтобы выход одной зоны не повлек за собой полный отказ
Это повышает доступность, но добавляет краевые случаи: split‑brain, устаревшие реплики и решения о поведении при отсутствии кворума.
Инструменты устойчивости, которые вам пригодятся
Типичные паттерны:
- Circuit breakers для остановки вызовов к падающей зависимости\n- Bulkheads для изоляции сбоев, чтобы один шумный компонент не утопил всё\n- Graceful degradation — отдавать упрощённый опыт вместо жёсткой ошибки
Наблюдаемость и отладка по множеству машин
На одном сервере «история системы» в одном месте: логи, графики CPU, процесс для инспекции. При горизонтальном масштабировании история рассеяна.
Больше машин — больше потерянного контекста
Каждый дополнительный узел добавляет поток логов, метрик и трасс. Сложность не в сборе данных — в их корреляции. Ошибка при оформлении заказа может начаться на веб‑ноды, вызвать два сервиса, попасть в кеш и прочитать с конкретного шарда — подсказки окажутся в разных местах и временах.
Проблемы также становятся селективными: один узел с неправильной конфигурацией, один горячий шард, одна зона с повышенной задержкой. Отладка кажется случайной, потому что в большинстве случаев всё работает.
Трейсинг и correlation ID (по‑простому)
Распределённый трейсинг похож на присвоение номерка отслеживания запросу. Correlation ID — этот номер. Передавайте его между сервисами и включайте в логи, чтобы можно было взять один ID и увидеть полный путь запроса энд‑ту‑энд.
Оповещения, которые помогают, а не заглушают
Больше компонентов — больше оповещений. Без настройки команды горят от алертов. Стремитесь к действенным оповещениям, которые дают понять:
- что сломалось\n- кого это затрагивает\n- что проверять в первую очередь
Наблюдайте насыщение, а не только ошибки
Проблемы с ёмкостью часто проявляются прежде, чем произойдёт отказ. Следите за сигналами насыщения: CPU, память, глубина очередей, использование пулов соединений. Если насыщение видно только на части узлов, подозревайте балансировку, шардирование или дрейф конфигурации — а не просто «больше трафика».
Деплой, апгрейды и откаты становятся рискованнее
При масштабировании вширь деплой уже не «замена одной коробки». Это координация изменений по множеству машин при сохранении доступности сервиса.
Rolling updates, canary и blue/green
Горизонтальные деплои часто используют rolling updates (замена узлов постепенно), canary (направление небольшой доли трафика на новую версию) или blue/green (переключение трафика между двумя окружениями). Они уменьшают blast radius, но требуют: управления трафиком, health checks, дренажа соединений и определения «достаточно хорошо, чтобы двигаться дальше».\n
Версионный скошенность — это норма
Во время постепенного деплоя старые и новые версии работают вместе. Версионный скошенность означает, что система должна выдерживать смешанное поведение:
- новые узлы вызывают старые (и наоборот)\n- старые клиенты попадают на новые серверы\n- разные форматы кеша или полезной нагрузки задач могут быть в полёте
Совместимость — требование
API должны быть обратно/вперёд совместимы, не только корректны. Изменения схемы БД по возможности должны быть аддитивными (сначала добавить nullable‑поле, потом сделать обязательным). Форматы сообщений стоит версионировать, чтобы потребители умели читать и старые, и новые события.
Откаты усложняются при миграциях данных
Откат кода прост; откат данных — нет. Если миграция удаляет или перезаписывает поля, старый код может падать или неверно обрабатывать записи. Подход «expand/contract» помогает: сначала выкладываете код, поддерживающий обе схемы, мигрируете данные, затем удаляете старые пути.
Конфиги и секреты должны быть консистентны
С множеством узлов управление конфигурацией становится частью деплоя. Один узел с устаревшим конфигом, неправильными флагами или просроченными кредами может давать непостоянные, трудно воспроизводимые сбои.
Стоимость и сложность команды часто растут при масштабировании вширь
Прототипируйте следующую версию
Разверните приложение на React с бэкендом на Go и PostgreSQL из простого чата.
Горизонтальное масштабирование может казаться дешевле в расчёте на единицу: много мелких инстансов, у каждого низкая почасовая цена. Но общая стоимость — не только вычисления. Добавление узлов означает больше сетевого трафика, мониторинга, координации и времени на поддержание согласованности.
Меньше больших машин vs много мелких инстансов
Вертикальное масштабирование концентрирует расходы в меньшем числе машин — часто меньше хостов для патчей, меньше агентов, меньше логов для отправки, меньше метрик для скрапинга.
При масштабировании вширь цена за единицу может быть ниже, но вы часто платите за:
- балансировщики, discovery и дополнительную пропускную способность\n- больше реплик для достижения целей производительности и доступности\n- более высокий резерв, потому что нужно держать запас не на одной машине, а на многих уровнях
Использование и перепрофилирование
Чтобы безопасно пережить всплески, в распределённых системах часто работают с недозагруженностью. Нужно держать запас на нескольких слоях (веб, воркеры, БД, кеши), что может означать оплату простаивающей мощности на десятках или сотнях инстансов.
Операционная стоимость: скрывающий множитель
Масштабирование вширь увеличивает нагрузку дежурных и требует зрелых инструментов: тонкая настройка алертов, руководы по инцидентам, тренировки и учения. Команды тратят время на определение зон ответственности и координацию при инцидентах.
В итоге: «дешевле за единицу» может оказаться дороже в сумме, учитывая труд людей, операционные риски и работу по сдерживанию множества машин в единой системе.
Как выбрать путь: масштабироваться вверх или вширь
Выбор между scale up и scale out — не только о цене. Важно, какова нагрузка и сколько операционной сложности команда готова принять.
Критерии, которые действительно важны
Начните с характера нагрузки:
- Тип нагрузки: CPU‑Bound задачи часто выигрывают от scale up; веб‑трафик с большим числом запросов выигрывает от scale out за балансировкой.\n- Состояния: если запросы зависят от локального состояния (сессии, кеши, незавершённая работа), scale out заставит вас переработать место хранения состояния.\n- Требования согласованности: если корректность критична (платежи, инвентарь), scale out вводит более жёсткие компромиссы по конкуренции и согласованности.\n- Темп роста и всплески: предсказуемый рост можно закрыть масштабированием вверх по шагам; непредсказуемые всплески чаще подталкивают к горизонтальной ёмкости.
Практическая последовательность (которая экономит время)
Распространённый разумный путь:
- Оптимизируйте очевидные узкие места (медленные запросы, пропущенные индексы, неэффективные эндпоинты).\n2) Масштабируйте вверх сначала (больше VM/БД), потому что это меняет меньше предположений.\n3) Масштабируйте вширь когда одна нода действительно становится лимитом — или когда нужна доступность, которую одна машина дать не может.
Гибридные паттерны — норма
Многие команды вертикально масштабируют базу (или держат её слегка кластеризованной), а горизонтально масштабируют статлесс‑слой. Это снижает боль шардинга, позволяя быстро добавлять веб‑ёмкость.
Сигналы, что вы готовы к масштабированию вширь
Вы ближе к этому, когда есть надёжный мониторинг и алерты, протестированный failover, нагрузочные тесты и повторяемые деплои с безопасными откатами.
Вопросы перед решением
- Можно ли достигнуть целей оптимизацией или scale‑up на 6–12 месяцев?\n- Где будут храниться сессии, кеши и фоновые задачи?\n- Нужна ли сильная согласованность и какие отказы допустимы?\n- Каков план по партиционированию данных и ребалансировке?\n- Есть ли инструменты для отладки проблем по множеству узлов?
Где вписывается Koder.ai (практическая помощь без изобретения велосипеда)
Много боли масштабирования — это не только архитектура, но и операционный цикл: безопасно итерации, надёжные деплои и быстрый откат, когда реальность не совпадает с планом.
Если вы строите веб‑, бэкэнд‑ или мобильные системы и хотите двигаться быстро, не теряя контроля, Koder.ai может помочь прототипировать и выпускать быстрее, пока вы принимаете решения о масштабировании. Это платформа на базе «vibe‑coding», где приложения строятся через чат с агентной архитектурой под капотом. На практике это даёт возможность:
- Быстро поднять React веб‑приложение, бэкэнд на Go + PostgreSQL или Flutter мобильное приложение и итеративно выявлять узкие места.\n- Использовать planning mode, чтобы продумать изменения «scale up vs. scale out» перед реализацией.\n- Снизить риск деплоев с помощью snapshots и rollback, что важно по мере роста числа узлов и появления версионной скошенности.\n- Экспортировать исходники, когда будете готовы перейти на собственный пайплайн, и деплоить/хостить с кастомными доменами.
Поскольку Koder.ai разворачивается глобально на AWS, платформа может поддерживать деплой в разных регионах для соблюдения требований по задержке и трафику — полезно, когда в историю масштабирования входит мультирегиональная доступность.
FAQ
В чём разница между вертикальным и горизонтальным масштабированием?
Вертикальное масштабирование — это увеличение мощности одной машины (больше CPU/RAM/быстрее диск). Горизонтальное масштабирование — это добавление машин и распределение работы между ними.
Вертикальное чаще кажется проще, потому что приложение продолжает вести себя как «одна система», тогда как при горизонтальном нужно, чтобы несколько систем координировались и сохраняли согласованность.
Почему горизонтальное масштабирование добавляет сложности по сравнению с вертикальным?
Потому что как только у вас появляется несколько узлов, требуется явная координация:
- решение, кто обрабатывает какую работу
- предотвращение дублей в обработке
- обработка сетевых задержек и частичных сбоев
Один сервер по умолчанию избегает многих проблем распределённых систем.
Что такое «координационные издержки» в распределённой системе?
Это время и логика, затрачиваемые на то, чтобы несколько машин вели себя как одна:
- выбор лидера и правила переключения при сбое
- локи/аренда и проблемы со сдвигом часов
- предотвращение split‑brain
Даже если каждый узел прост, поведение системы становится труднее прогнозировать под нагрузкой и при ошибках.
Почему шардинг и разбиение данных так трудно реализовать правильно?
Шардинг (разбиение) распределяет данные по узлам, чтобы ни одна машина не хранила и не обслуживала всё. Это сложно, потому что нужно:
- направлять каждое чтение/запись к нужному шарду
- переназначать данные при добавлении/удалении узлов
- справляться с горячими партициями, когда нагрузка концентрируется на одном шарде
Это также увеличивает операционную работу (миграции, бэкофиллы, карты шардов).
Что значит «состояние» и почему оно важно при масштабировании вширь?
Состояние — это всё, что приложение «помнит» между запросами или пока выполняется работа (сессии, in‑memory кеши, временные файлы, прогресс задач).
При горизонтальном масштабировании запросы могут попасть на разные сервера, поэтому обычно требуется общий стор (например, Redis/БД) или приходится смириться с компромиссами вроде sticky sessions.
Как предотвратить двойную обработку фоновых задач при масштабировании вширь?
Если несколько воркеров могут взять одну и ту же задачу (или задача ретраится), можно дважды списать платёж или отправить дублирующее письмо.
Распространённые меры:
- идемпотентные обработчики задач
- локи/аренды при захвате задач
- дедупликация по уникальным ID задач
- аккуратные политики повторных попыток с бэкофом
В чём практическая разница между сильной и итоговой согласованностью?
Сильная согласованность означает, что после успешной записи все читатели сразу видят новое значение. Итоговая (eventual) согласованность означает, что обновления распространяются со временем, и некоторое время читатели могут видеть старые данные.
Сильную согласованность применяют для критичных данных (платежи, балансы, инвентарь). Для менее критичных данных (аналитика, рекомендации) часто допустима итоговая согласованность.
Почему таймауты и ретраи становятся критичными при горизонтальном масштабировании?
В распределённой системе вызовы становятся сетевыми — появляются задержки, джиттер и дополнительные режимы отказов.
Базовые принципы:
- устанавливайте таймауты, чтобы запросы не вешали потоки
- ограничьте число повторных попыток и используйте экспоненциальный бэкоф с джиттером
- повторяйте только безопасные (идемпотентные) операции, чтобы не создать дублирующих эффектов
Что такое «частичный отказ» и почему он становится нормой в масштабируемых системах?
Частичный отказ — это когда некоторые компоненты медленные или упали, а другие работают. Система может быть «в сети», но показывать ошибки, таймауты или несогласованное поведение.
Реакции на частичные отказы: репликация, кворумы, развёртывание по зонам, circuit breakers и graceful degradation, чтобы не давать проблеме разрастаться.
Как отлаживать проблемы, когда приложение работает на множестве серверов?
Доказательства рассредоточены: логи, метрики и трассы на разных узлах.
Практические шаги:
- пользоваться correlation ID для каждого запроса
- внедрять распределённый трейсинг, чтобы увидеть путь запроса
- следить за признаками насыщения (CPU, глубина очередей, пул соединений), а не только за ошибками