Что на самом деле делает индексация базы данных
Индекс базы данных — это отдельная структура поиска, которая помогает базе данных находить строки быстрее. Это не вторая копия таблицы. Думайте об этом как о страницах-индексе в книге: вы используете индекс, чтобы быстро перейти ближе к нужному месту, а затем читаете конкретную страницу (строку).
Без индекса у базы часто остаётся только один безопасный вариант: прочитать много строк и проверить, какие из них соответствуют запросу. Это может быть нормально для таблицы с несколькими тысячами строк. По мере роста таблицы до миллионов строк «проверять больше строк» превращается в больше дисковых чтений, большую нагрузку на память и CPU — и та же операция, которая раньше казалась мгновенной, начинает тормозить.
Что меняет индекс (и чего не меняет)
Индексы уменьшают объём данных, который базе нужно просмотреть, чтобы ответить на вопросы вроде «найти заказ с ID 123» или «получить пользователя с этим email». Вместо сканирования всего таблица сначала обращается к компактной структуре, которая быстро сужает поиск.
Но индексация — не универсальное решение. Некоторые запросы всё равно должны обработать много строк (широкие отчёты, фильтры с низкой селективностью, тяжёлые агрегации). А у индексов есть реальные издержки: дополнительное место на диске и замедление операций записи, потому что вставки и обновления тоже должны обновлять индекс.
Что вы узнаете из этого руководства
Вы увидите:
- почему уклонение от полного сканирования таблицы даёт главный прирост скорости
- как распространённые структуры индексов (например, B-tree) ускоряют поиск
- какие запросы выигрывают больше всего и когда индексы не помогают
- как выбирать составные/покрывающие индексы и проверять их через EXPLAIN
- как поддерживать индексы со временем, чтобы производительность не деградировала незаметно
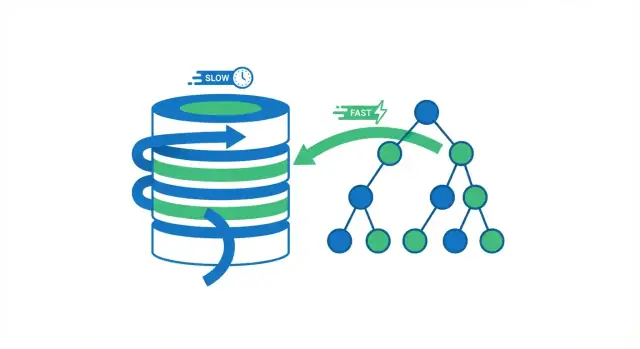
Основной выигрыш в скорости: избегание полного сканирования
Когда база выполняет запрос, у неё есть два общих варианта: просканировать всю таблицу построчно или прыгнуть прямо к подходящим строкам. Большинство выигрышей от индексов получаетcя за счёт избежания ненужных чтений.
Полное сканирование vs. поиск по индексу
Полное сканирование таблицы — это ровно то, о чём речь: база читает каждую строку, проверяет, соответствует ли она условию WHERE, и только затем возвращает результаты. Для маленьких таблиц это приемлемо, но по мере роста таблицы скорость падает предсказуемо — больше строк = больше работы.
При использовании индекса база часто может избежать чтения большинства строк. Вместо этого она сначала обращается к индексу (компактной структуре, предназначенной для поиска), чтобы узнать, где лежат подходящие строки, а затем читает только эти конкретные строки.
Простая аналогия
Представьте книгу. Если вы хотите найти каждую страницу с упоминанием «фотосинтеза», вы можете прочитать книгу целиком (полный скан). Или можете воспользоваться оглавлением/индексом книги, перейти на перечисленные страницы и читать только эти разделы (поиск по индексу). Второй подход быстрее, потому что вы пропускаете почти все страницы.
Почему меньше чтений обычно означает более быстрые запросы
Базы много времени проводят в ожидании чтения — особенно когда данные ещё не в памяти. Сокращение числа строк (и страниц), к которым нужно обратиться, обычно уменьшает:
- обращения к диску/SSD
- CPU на проверку фильтров
- нагрузку на память из-за подтягивания лишних данных в кэш
Когда виден выигрыш в скорости
Индексация помогает главным образом, когда данных много, а шаблон запроса селективен (например, получить 20 совпадающих строк из 10 миллионов). Если ваш запрос и так возвращает большую часть строк или таблица достаточно мала, чтобы влезть в память, полное сканирование может быть столь же быстрым — или даже быстрее.
Как структуры индексов делают поиск быстрым
Индексы работают потому, что упорядочивают значения так, чтобы база могла перейти прямо к нужному месту, а не проверять каждую строку.
Индексы B-tree: стандартный рабочий инструмент
Самая распространённая структура индексов в SQL-движках — B-tree (иногда пишут «B-tree» или «B+tree»). Концептуально:
- значения хранятся в отсортированном виде
- индекс разделён на страницы (чанки), которые указывают на другие страницы и, в конечном счёте, на строки таблицы
Поскольку значения отсортированы, B-tree отлично подходит и для точных поисков (WHERE email = ...), и для диапазонных запросов (WHERE created_at >= ... AND created_at < ...). База может перейти в нужную «окрестность» значений и затем просканировать вперёд по порядку.
Что означает «логарифмический» (без математики)
Говорят, что поиск в B-tree «логарифмический». Практически это значит: по мере роста таблицы с тысяч до миллионов строк число шагов для поиска растёт медленно, а не пропорционально. Вместо «вдвое больше данных = вдвое больше работы» это скорее «много больше данных = лишь несколько дополнительных шагов», потому что база следует указателям через небольшое число уровней дерева.
Хеш-индексы: быстро для точных совпадений (с ограничениями)
Некоторые движки предлагают хеш-индексы. Они могут быть очень быстры для точных проверок равенства, потому что значение хешируется и по хешу сразу находится запись.
Компромисс: хеш-индексы обычно не помогают для диапазонов или упорядоченных обходов, и поддержка/поведение различаются между СУБД.
Детали реализации различаются, идея остаётся прежней
PostgreSQL, MySQL/InnoDB, SQL Server и другие по-разному хранят и используют индексы (размер страницы, кластеризация, включённые столбцы, проверки видимости). Но базовая идея общая: индекс создаёт компактную, проходимую структуру, которая позволяет базе находить строки с меньшей затратой, чем полный скан таблицы.
Запросы, которые получают наибольшую выгоду от индексов
Индексы не ускоряют «SQL» вообще — они ускоряют конкретные модели доступа. Когда индекс совпадает с тем, как ваш запрос фильтрует, объединяет или сортирует данные, база может перейти напрямую к релевантным строкам вместо чтения всей таблицы.
Наиболее «индекс-дружественные» шаблоны запросов
1) Фильтры WHERE (особенно по селективным столбцам)
Если запрос часто сужает большую таблицу до небольшого набора строк, индекс — первое, куда стоит взглянуть. Классический пример — поиск пользователя по идентификатору.
Без индекса на users.email база может просканировать все строки:
SELECT * FROM users WHERE email = '[email protected]';
С индексом на email она найдёт совпадающие строки быстро и остановится.
2) Ключи JOIN (внешние ключи и референсируемые ключи)
JOIN — место, где «маленькие неэффективности» превращаются в большие расходы. Если вы соединяете orders.user_id с users.id, индексация столбцов для соединения (обычно orders.user_id и первичный ключ users.id) помогает базе сопоставлять строки без постоянного сканирования.
3) ORDER BY (когда вам нужен уже отсортированный результат)
Сортировка дорогая, если базе нужно собрать много строк и отсортировать их. Если вы часто выполняете:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
индекс, согласованный с user_id и колонкой сортировки, может позволить движку читать строки в нужном порядке вместо сортировки большого промежуточного результата.
4) GROUP BY (когда группировка согласуется с индексом)
Группировка может выигрывать, когда база читает данные в сгруппированном порядке. Это не гарантировано, но если вы часто группируете по столбцу, который также используется в фильтре (или естественно сгруппирован в индексе), движок может выполнить меньше работы.
Диапазонные фильтры: типичная победа B-tree
B-tree особенно хорош для диапазонных условий — подумайте о датах, ценах и запросах «между»:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Для панелей мониторинга, отчётов и экранов «недавней активности» этот шаблон встречается повсеместно, и индекс по колонке диапазона часто даёт заметное ускорение.
Тема проста: индексы помогают, когда они отражают то, как вы ищете и сортируете. Если ваши запросы совпадают с этими моделями доступа, база может выполнить целенаправленные чтения вместо широких сканирований.
Селективность: почему некоторые индексы не помогают
Индекс полезен, когда он сильно сужает число строк, к которым нужно обратиться. Это свойство называется селективностью.
Что означает «селективность» на практике
Селективность — это по сути: сколько строк совпадает для данного значения? Высокая селективность означает много уникальных значений, поэтому каждый поиск возвращает мало строк.
- Высокая селективность:
email, user_id, order_number (часто уникальные или близкие к уникальным)
- Низкая селективность:
is_active, is_deleted, status с несколькими распространёнными значениями
При высокой селективности индекс может перейти к небольшому набору строк. При низкой селективности индекс указывает на большой кусок таблицы — и базе всё равно придётся прочитать и отфильтровать много строк.
Почему булевые и похожие индексы разочаровывают
Возьмём таблицу с 10 миллионами строк и колонкой is_deleted, где 98% — false. Индекс по is_deleted мало помогает для:
SELECT * FROM orders WHERE is_deleted = false;
Набор совпадающих строк всё ещё почти вся таблица. Использование индекса может быть медленнее последовательного сканирования, потому что движку приходится прыгать между индексными записями и страницами таблицы.
Почему база может проигнорировать ваш индекс
Планировщик оценивает затраты. Если индекс не снижает работы достаточно — потому что совпадает слишком много строк или запрос требует большинство столбцов — он может выбрать полный скан.
Селективность меняется со временем
Распределение данных не постоянно. Столбец status может сначала быть равномерно распределён, а со временем один статус станет доминирующим. Если статистика не обновлена, планировщик сделает плохие оценки, и индекс, который раньше помогал, перестанет окупаться.
Составные и покрывающие индексы (и порядок колонок)
Одноколоночные индексы — хороший старт, но многие реальные запросы фильтруют по одному столбцу и сортируют или фильтруют по другому. Здесь на помощь приходят составные (многоколоночные) индексы: один индекс может обслуживать сразу несколько частей запроса.
Порядок колонок: правило «слева-направо»
Большинство СУБД (особенно с B-tree) эффективно использует составной индекс, начиная с левых колонок. Думайте об индексе как об отсортированном сначала по колонке A, затем по B и т.д.
Это значит:
- индекс (account_id, created_at) отлично подходит для запросов по
account_id с последующей сортировкой или фильтрацией по created_at
- тот же индекс обычно не полезен для запроса, который фильтрует только по
created_at (потому что это не левый столбец)
Практический шаблон: таймлайн по аккаунту
Обычная нагрузка — «показать самые свежие события для аккаунта». Запрос:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
часто сильно выигрывает от:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
База может сразу перейти к части индекса, относящейся к конкретному аккаунту, и читать строки в порядке времени, вместо сканирования и сортировки большого набора.
Покрывающие индексы: когда индекс — это весь ответ
Покрывающий индекс содержит все столбцы, которые нужны запросу, поэтому база может вернуть результат прямо из индекса, не обращаясь к строкам таблицы (меньше чтений, меньше случайного ввода-вывода).
Осторожно: добавление дополнительных колонок делает индекс больше и дороже в обслуживании.
Не создавайте широкие составные индексы «на всякий случай»
Широкие составные индексы замедляют записи и занимают много места. Добавляйте их только для конкретных высокоценностных запросов и проверяйте через EXPLAIN и реальные измерения до и после.
Компромиссы: замедление записей и дополнительное место
Индексы часто представляют как «бесплатное ускорение», но это не так. Структуры индексов нужно поддерживать при изменении таблицы, и они потребляют ресурсы.
Медленнее INSERT/UPDATE/DELETE (каждый индекс нужно обновлять)
Когда вы INSERT-ите новую строку, база не только записывает саму строку — она также добавляет соответствующие записи во все индексы этой таблицы. То же самое для DELETE и для многих UPDATE.
Поэтому «больше индексов» заметно замедляет рабочие нагрузки с большим количеством записей. UPDATE, затрагивающий индексный столбец, особенно дорог: базе может понадобиться удалить старую запись из индекса и добавить новую (в некоторых движках это вызывает разбиение страниц или перестройку).
Если приложение интенсивно пишет — события заказов, данные сенсоров, журналы — индексация всего подряд может сделать базу медленной, даже если чтения быстрые.
Дополнительное место и нагрузка на память
Каждый индекс занимает место на диске. На больших таблицах индексы могут сравняться по размеру с таблицей или даже превысить её, особенно если есть пересекающиеся индексы.
Это также влияет на память. Базы сильно зависят от кэширования; если рабочий набор включает несколько больших индексов, кэшу нужно хранить больше страниц, чтобы оставаться быстрым. Иначе вы увидите больше дискового ввода-вывода и менее предсказуемую производительность.
Практический баланс
Индексация — это выбор того, что ускорять. Если нагрузка в основном чтения, больше индексов может быть оправдано. Если нагрузка на запись высокая, приоритизируйте индексы для самых важных запросов и избегайте дублирования. Полезное правило: добавляйте индекс только если можете назвать запрос, которому он помогает, и подтвердить, что выигрыш по чтению перевешивает стоимость при записи и обслуживании.
Как доказать, что индекс помогает: EXPLAIN и измерения
Добавление индекса кажется полезным, но вы должны это проверить. Два инструмента, которые делают это конкретным — план запроса (EXPLAIN) и реальные измерения до/после.
Читайте план: используется ли индекс на самом деле?
Запустите EXPLAIN (или EXPLAIN ANALYZE) на том самом запросе, который вам важен.
- Тип сканирования: Seq Scan / Full Table Scan означает чтение всей таблицы. Index Scan / Index Seek (или Index Range Scan) указывает, что используется индекс для сужения набора.
- Оценочные vs фактические строки (особенно в
EXPLAIN ANALYZE): если план оценил 100 строк, а на самом деле затронул 100 000, оптимизатор ошибся — часто из‑за устаревшей статистики или менее селективного фильтра.
- Шаги сортировки: если вы видите явный Sort, база упорядочивает результаты после выборки. Если новый индекс соответствует
ORDER BY, сортировка может исчезнуть — это большой выигрыш.
Правильные измерения: до/после, в одинаковых условиях
Бенчмаркните запрос с тем же набором параметров, на репрезентативном объёме данных, фиксируя как латентность, так и сканируемые строки.
Осторожно с кэшированием: первый прогон может быть медленнее, потому что данные ещё не в памяти; повторные прогоны могут выглядеть «фиксированными» даже без индекса. Чтобы не вводить себя в заблуждение, сравнивайте несколько запусков и смотрите, меняется ли план (используется ли индекс, меньше ли прочитанных строк), а не только сырое время.
Если EXPLAIN ANALYZE показывает, что затронуто меньше строк и пропали дорогие шаги (например, сортировка), вы доказали, что индекс помогает, а не надеетесь на это.
Типичные ошибки, которые нивелируют выгоду индекса
Можно добавить «правильный» индекс и всё равно не увидеть ускорения, если сам запрос написан так, что база не может его использовать. Эти проблемы часто тонкие: запрос по‑прежнему возвращает корректный результат, но выполняется медленно.
Антипаттерны, блокирующие использование индекса
1) Лидирующие подстановки
Когда пишут:
WHERE name LIKE '%term'
обычный B-tree не может помочь, потому что база не знает, где в отсортированном порядке начинается «%term». Часто придётся сканировать много строк.
Альтернативы:
- если можно, используйте поиск по префиксу:
WHERE name LIKE 'term%'.
- если нужен поиск по вхождению, рассмотрите специализированный индекс (например, полнотекстовый или триграммный), а не стандартный B-tree.
2) Функции над индексированными колонками
Выглядит безобидно:
WHERE LOWER(email) = '[email protected]'
Но LOWER(email) меняет выражение, и индекс на email не может быть использован напрямую.
Альтернативы:
- храните нормализованные данные (например, email в нижнем регистре) и сравнивайте
WHERE email = ....
- или создайте выражение/функциональный индекс (зависит от СУБД) специально для
LOWER(email).
Скрытые факторы, которые блокируют индекс
Неявные приведения типов: сравнение разных типов может заставить базу приводить одну сторону, что отключит индекс. Например, сравнение целочисленного столбца со строковым литералом.
Несовпадающие колlation/кодировки: если сравнение использует другую сортировку, чем индекс, оптимизатор может избегать индекса.
Быстрый чек-лист: «Почему мой индекс не используется?»
- Условие начинается со спецсимвола (
LIKE '%x')?
- Применяете функцию к индексированному столбцу (
LOWER(col), DATE(col), CAST(col))?
- Типы одинаковы по обе стороны (нет неявного приведения)?
- Коллация/локаль согласованы для сравнения?
- Предикат достаточно селективен (не совпадает ли большая часть таблицы)?
- Фильтрация/сортировка по левому префиксу составного индекса?
- Проверяли план через
EXPLAIN, чтобы подтвердить выбор движка?