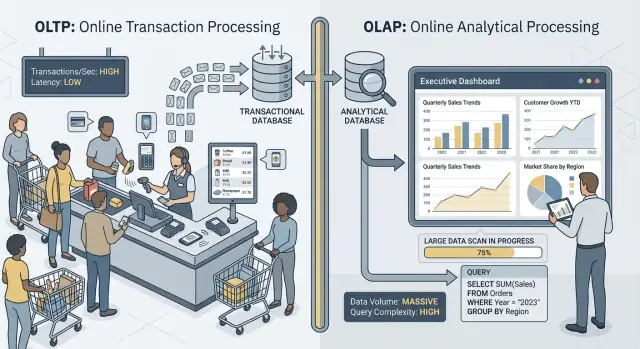
OLTP vs OLAP: что это такое (без жаргона)
Когда говорят «OLTP» и «OLAP», имеют в виду два очень разных способа использования базы данных.
OLTP: база, которая «ведёт» бизнес
OLTP (Online Transaction Processing) — это нагрузка за повседневные действия, которые должны быть быстрыми и корректными каждый раз. Подумайте: «сохранить изменение прямо сейчас».
Типичные OLTP‑задачи: создание заказа, обновление остатка, запись платежа или смена адреса клиента. Операции обычно небольшие (несколько строк), частые и должны отвечать за миллисекунды, потому что за ними ждёт пользователь или другая система.
OLAP: база, которая объясняет бизнес
OLAP (Online Analytical Processing) — это нагрузка для понимания, что произошло и почему. Подумайте: «просканировать много данных и суммировать результат».
Типичные OLAP‑задачи: дашборды, отчёты по трендам, когортный анализ, прогнозы и «slice‑and‑dice» вопросы вроде: «Как изменился доход по региону и категории продукта за последние 18 месяцев?» Такие запросы читают много строк, делают тяжёлые агрегирования и могут выполняться секунды (или минуты), при этом небольшая задержка не считается «ошибкой».
Одни и те же данные — разные цели и разные требования
Главная мысль проста: OLTP оптимизирован для быстрых, согласованных записей и небольших чтений, тогда как OLAP оптимизирован для больших чтений и сложных вычислений. Из‑за разных целей отличаются и оптимальные настройки базы, индексы, расположение хранения и подход к масштабированию.
Отметьте слово: редко, не никогда. Небольшие команды некоторое время могут делить одну базу, особенно при скромных объёмах данных и аккуратной дисциплине запросов. В следующих разделах — что ломается первым, типичные паттерны разделения и как безопасно перенести отчётность с продакшена.
Быстрые примеры
- Оформление покупки (OLTP): клиент нажимает «Оплатить», и приложение записывает заказ, статус платежа и обновления остатков.
- Дашборд отчётности (OLAP): менеджер открывает панель, агрегирующую тысячи (или миллионы) заказов, чтобы показать конверсию, средний чек и недельные тренды.
Разные цели — разные метрики успеха
OLTP и OLAP оба могут «использовать SQL», но оптимизированы под разные задачи — это видно по тому, что каждое считает успехом.
OLTP: скорость, конкуренция и корректность
Транзакционные системы обслуживают повседневные операции: оформления покупок, обновления аккаунтов, брони, инструменты поддержки. Приоритеты просты:
- Быстрый отклик для мелких чтений/записей (миллисекунды)
- Много одновременных пользователей без деградации
- Корректность и согласованность, потому что неверный баланс или дублированный заказ — реальная проблема для бизнеса
Успех часто измеряют метриками задержек вроде p95/p99, процентом ошибок и тем, как система держится под пиками нагрузки.
OLAP: сканирование, агрегирование и гибкость
Аналитические системы отвечают на вопросы вроде «Что изменилось в квартале?» или «Какой сегмент оттек после нового прайсинга?» Эти запросы обычно:
- Сканируют большие объёмы данных по множеству строк
- Делаю агрегирования (SUM, COUNT, перцентили) и джойны
- Часто меняются по мере исследования аналитиком
Успех здесь — это пропускная способность запросов, время до получения инсайта и возможность запускать сложные запросы без ручной донастройки каждого отчёта.
Почему «всё в одной системе» — это компромисс
Если принудительно класть обе нагрузки в одну базу, вы просите её одновременно быть отличной в мелких, объёмных транзакциях и в больших, исследовательских сканах. Результат — компромисс: у OLTP непредсказуемая задержка, OLAP throttled ради защиты продакшена, и команды спорят, чей запрос «разрешён». Разные цели требуют разных метрик успеха — и обычно разных систем.
Конфликт за ресурсы: когда аналитика крадёт ресурсы у транзакций
Когда OLTP (операции приложения) и OLAP (отчёты/анализ) работают в одной базе, они борются за одни и те же ограниченные ресурсы. Результат — не просто «медленнее отчёты», а замедленные покупки, зависшие логины и непредсказуемые глюки в приложении.
CPU и память: длинные запросы против коротких
Аналитические запросы часто долгие и тяжёлые: джойны по большим таблицам, агрегирования, сортировки. Они могут монополизировать CPU и, не менее важно, память для hash‑join’ов и буферов сортировки.
Транзакционные запросы, наоборот, малы и очень чувствительны к задержке. Если CPU загружен или давление по памяти вызывает частые вытеснения, эти маленькие запросы начинают ждать больших — даже если сами по себе они требуют миллисекунд работы.
Диск I/O: большие сканы против множества мелких чтений/записей
Аналитика вызывает большие последовательные чтения страниц, OLTP — наоборот, много мелких случайных чтений плюс постоянные записи в индексы и логи.
Вместе они заставляют подсистему хранения лавировать между несовместимыми паттернами доступа. Кэши, которые помогали OLTP, «смываются» аналитическими сканами, и задержка записей может вырасти, когда диск занят стримингом данных для отчёта.
Давление на пул соединений и очередь запросов
Пара аналитиков, запустивших широкие запросы, может занять соединения на минуты. Если приложение использует фиксированный пул, запросы начнут ставиться в очередь в ожидании свободного соединения. Это может сделать систему кажущейся «сломавшейся»: средняя задержка может быть нормальной, а хвостовые (p95/p99) — болезненными.
Что видят пользователи
Снаружи это выглядит как таймауты, медленные оформления заказов, задержки в поиске и нестабильное поведение — обычно «только при отчётах» или «в конце месяца». Команда приложения видит ошибки; аналитики — медленные запросы; настоящая проблема — общая конкуренция ресурсов под капотом.
Требования к макету данных и индексам тянут в разные стороны
OLTP и OLAP не просто «по‑разному используют базу» — они поощряют противоположную физическую организацию. Пытаясь угодить обоим, вы чаще всего получаете дорогостоящий компромисс с плохой производительностью.
OLTP: оптимизация под быстрые селективные запросы
Транзакционная нагрузка доминируется короткими запросами, которые касаются маленькой доли данных: получить один заказ, обновить одну строку остатка, показать последние 20 событий для пользователя.
Это ведёт к строко‑ориентированным схемам и индексам для точечных выборок и небольших диапазонных сканов (первичные ключи, внешние ключи, несколько ценных вторичных индексов). Цель — предсказуемая низкая задержка, особенно для записей.
OLAP: оптимизация под сканирование, группировку и суммирование
Аналитика часто читает много строк, но только несколько колонок: «доход по неделям и регионам», «конверсия по кампании», «топ товаров по марже».
OLAP‑системы выигрывают от колоночного хранения (чтобы читать только нужные колонки), партиционирования (чтобы быстро отбрасывать старые данные) и предагрегаций (материализованные представления, rollup), чтобы отчёты не пересчитывали одни и те же итоги снова и снова.
Почему «индексировать всё» — плохая идея
Пошлина в сторону: добавить индексы на всё, чтобы ускорить дашборды, а затем жаловаться, что записи стали медленнее. Каждый дополнительный индекс увеличивает стоимость записи, объём хранения и усложняет операции обслуживания — и вы всё равно можете не покрыть все аналитические запросы.
Планировщик запросов и дрейф статистик (проще говоря)
Базы строят планы на основе статистик — оценок, сколько строк пройдёт по фильтру, насколько селективен индекс и т. д. OLTP постоянно меняет данные. По мере смещения распределений статистики дрейфуют, и планировщик может выбрать план, который был хорош вчера, но медлен сегодня.
Добавьте тяжёлые OLAP‑запросы, и вариативность растёт: «лучший план» сложнее предсказать, а тюнинг под одну нагрузку часто ухудшает другую.
Блокировки, MVCC и побочные эффекты обслуживания
Даже если ваша база «поддерживает конкуренцию», смешение тяжёлой аналитики с живыми транзакциями создаёт тонкие замедления, которые трудно предсказать — и ещё труднее объяснить клиенту, смотрящему на крутящийся индикатор оформления заказа.
Долгие запросы всё ещё создают блокировки
OLAP‑запросы часто сканируют много строк, джойнят несколько таблиц и выполняются секунды или минуты. За это время они могут держать блокировки (например, на объекты схемы или при сортировке/агрегации во временных структурах) и косвенно увеличивать конкуренцию блокировок, удерживая многие строки «в игре».
Даже с MVCC база должна отслеживать версии строк, чтобы читатели и писатели не блокали друг друга. Это помогает, но не устраняет конкуренцию — особенно на «горячих» таблицах, которые транзакции постоянно обновляют.
У MVCC есть скрытая цена: очистка становится сложнее
MVCC означает, что старые версии строк остаются, пока база не сможет их безопасно удалить. Долгий отчёт может держать старый снимок открытым, что мешает очистке пространства.
Это влияет на:
- Vacuum/garbage collection: очистка не может быстро удалить «мертвые» кортежи/версии.
- Bloat/фрагментацию: растёт объём хранения, индексы становятся менее эффективны, кэш хуже работает.
- Давление на компактирование: некоторые движки начинают делать более тяжёлую фон‑работу, отбирая I/O и CPU у транзакций.
Результат — двойной удар: отчётность заставляет базу работать сильнее и постепенно замедляет её.
Уровни изоляции увеличивают вариативность задержек
Инструменты отчётности часто запрашивают более строгую изоляцию (или случайно выполняют длинную транзакцию). Более высокая изоляция может увеличить ожидания блокировок и объём версионирования. С точки зрения OLTP это проявляется как непредсказуемые пики: большинство заказов быстро, а некоторые внезапно «застревают».
Практический пример: месячный отчёт тормозит заказы
В конце месяца бухгалтерия запускает запрос «доход по продукту», сканируя заказы и строки заказов за весь месяц. Пока он выполняется, новые записи всё ещё принимаются, но vacuum не может освободить старые версии, индексы начинают фрагментироваться. API заказов начинает получать случайные таймауты — не потому что система «упала», а потому что конкуренция и накладные расходы на очистку тихо толкают задержки за допустимый порог.
Взрывной характер нагрузки и непредсказуемая задержка
OLTP живёт и умирает предсказуемостью. Оформление заказа, тикет поддержки или обновление баланса — это не «в основном нормально», если в 5% случаев всё медленно; пользователи замечают медленные моменты. OLAP, напротив, часто всплескова: несколько тяжёлых запросов могут молчать часами, а затем внезапно захватить много CPU, памяти и I/O.
Всплески случаются по нормальным причинам
Аналитическая активность сгруппирована вокруг рутин:
- Утренние «стенд‑ап» дашборды, когда многие обновляют одни и те же графики
- Плановые отчёты, стартующие в начале часа
- Закрытие месяца/квартала, запускающее тяжёлые сканы и джойны
Тем временем OLTP трафик обычно более равномерный. Когда оба делят базу, аналитические всплески превращаются в непредсказуемую задержку транзакций — таймауты, медленные страницы и повторы, которые создают ещё большую нагрузку.
Почему лимиты и расписание помогают, но не решают проблему
Можно смягчить эффект тактиками: запускать отчёты ночью, ограничивать конкуренцию, вводить таймауты запросов или лимиты стоимости. Это полезные защитные меры, особенно для «отчётов на продакшене».
Но они не убирают фундаментального противоречия: OLAP‑запросы предназначены для потребления больших ресурсов, а OLTP нуждается в маленьких кусочках ресурсов весь день. Как только неожиданный рефреш дашборда, ad‑hoc запрос или восстановление данных проскальзывает, проблема возвращается.
Проблема шумного соседа
На общей инфраструктуре один «шумный» аналитик или джоб может монополизировать кэш, загрузить диск или вызвать давление на CPU — не делая ничего «неправильного». OLTP становится коллатеральным ущербом, и сложность в том, что сбои выглядят как случайные: пики задержек вместо чётких воспроизводимых ошибок.
Операционная сложность: бэкапы, безопасность и планирование ёмкости
Смешивание OLTP и OLAP усложняет не только производительность — оно делает рутину эксплуатации сложнее. База становится «ящиком на всё», и каждая операция наследует риски обеих нагрузок.
Бэкапы, восстановление и DR медленнее
Аналитические таблицы растут быстро и широко (больше истории, колонок, агрегатов). Это меняет сценарий восстановления.
Полный бэкап занимает больше времени, требует больше хранилища и повышает шанс пропустить окно бэкапа. Восстановления — хуже: при аварии вы восстанавливаете не только транзакционные данные, нужные приложению, но и большие аналитические объёмы, которые не требуются для быстрого запуска бизнеса. Тесты DR также занимают больше времени и проводятся реже — прямо противоположно тому, что нужно.
Планирование ёмкости превращается в гадание
Транзакционный рост обычно предсказуем: больше клиентов, больше заказов. Рост аналитики — часто скачкообразный: новая панель, изменение политики хранения или решение команды держать «ещё год» сырых событий.
Когда всё вместе, сложно понять:
- Растём мы из‑за успеха продукта или из‑за того, что отчёты хранят больше истории?
- Нужен ли нам быстрый диск для транзакций или большое «дешёвое» хранилище для аналитики?
Непонятность ведёт к переплатам (избыточные ресурсы) или недоплатам (неожиданные простои).
Правила труднее справедливо применять
В общей базе «невинный» запрос может стать инцидентом. Вводятся guardrails: таймауты, квоты, расписания отчётов, правила управления нагрузкой. Они помогают, но хрупки: приложение и аналитики конкурируют за одни и те же лимиты, и изменение политики для одной группы может сломать другую.
Безопасность и доступы усложняются
Приложения обычно требуют узких, целевых прав. Аналитики часто хотят широкий доступ на чтение для изучения и валидации. Помещение обоих в одну базу усиливает давление выдавать более широкие привилегии «чтобы отчёт работал», увеличивая blast radius ошибок и расширяя круг людей, видящих чувствительные данные.
Масштабирование и стоимость: в итоге вы платите дважды (или хуже)
Попытки держать OLTP и OLAP в одной базе кажутся дешевле — пока не начнёте масштабировать. Проблема не только в производительности: «правильный» способ масштабирования каждой нагрузки ведёт к разной инфраструктуре, а совмещение заставляет делать дорогие компромиссы.
Масштабирование OLTP ориентировано на записи (обычно болезненно)
Транзакционные системы ограничены записями: много мелких обновлений, жёсткая задержка и всплески, которые надо принять немедленно. Масштаб OLTP зачастую достигается вертикальным масштабированием (мощнее CPU, быстрее диски, больше памяти), потому что write‑heavy нагрузку трудно растянуть.
Когда вертикальные пределы исчерпаны, начинается шардирование или другие паттерны масштабирования записи. Это добавляет инженерную сложность и часто требует изменений в приложении.
Масштабирование OLAP ориентировано на вычисления (и часто эластично)
Аналитика масштабируется иначе: большие сканы, тяжёлые агрегирования, высокий read‑throughput. OLAP‑системы обычно масштабируют путём добавления распределённого compute и часто отделяют compute от storage, чтобы масштабировать мощность запросов независимо.
Если OLAP делит базу с OLTP, вы не можете масштабировать аналитику отдельно — вам приходится масштабировать всю базу, даже если транзакциям это не нужно.
Скрытый счёт: платить OLTP‑цену за аналитику
Чтобы сохранить скорость транзакций при выполнении отчётов, команды перепрокладывают продакшн: лишний CPU, высокопроизводительные диски, большие инстансы «на всякий случай». То есть вы платите OLTP‑цену за поддержку OLAP‑поведения.
Разделение позволяет каждую систему подбирать под задачу: OLTP — под предсказуемые низкие задержки записей, OLAP — под всплесковое чтение. В итоге часто выходит дешевле в сумме — даже несмотря на то, что это «две системы».