13 авг. 2025 г.·5 мин
Понятия распределённых систем: идеи Kleppmann для масштабирования SaaS
Понятия распределённых систем через реальные выборы при превращении прототипа в надёжный SaaS: поток данных, согласованность и контроль нагрузки.
Понятия распределённых систем через реальные выборы при превращении прототипа в надёжный SaaS: поток данных, согласованность и контроль нагрузки.
Прототип доказывает идею. SaaS должен пережить реальное использование: пиковый трафик, грязные данные, ретраи и клиентов, которые заметят каждую помеху. Вот тут всё и усложняется: вопрос меняется с «работает ли это?» на «будет ли это продолжать работать?»
С реальными пользователями «вчера работало» перестаёт быть ответом по скучным причинам. Фоновая задача выполняется позже обычного. Один клиент загружает файл в 10 раз больше, чем в тестах. Провайдер платежей подвисает на 30 секунд. Ничего экзотического, но эффекты домино становятся громкими, когда части системы зависят друг от друга.
Большая часть сложности проявляется в четырёх местах: данные (тот же факт хранится в нескольких местах и рассинхронизируется), задержки (50 мс вызовы иногда занимают 5 секунд), сбои (таймауты, частичные обновления, ретраи) и команды (разные люди выпускают разные сервисы по разному графику).
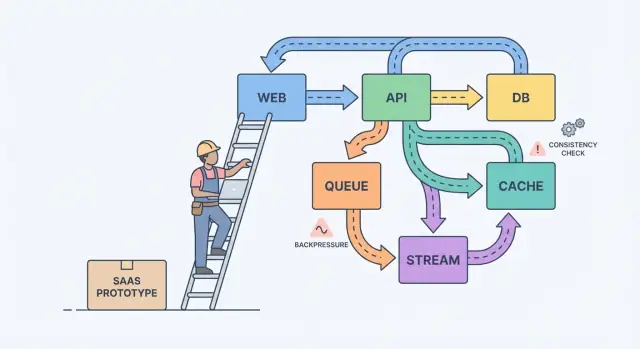
Полезная модель для мышления: компоненты, сообщения и состояние.
Компоненты выполняют работу (веб-приложение, API, воркер, база). Сообщения передают работу между компонентами (запросы, события, задания). Состояние — это то, что вы помните (заказы, настройки пользователя, статус биллинга). Боль при масштабировании обычно возникает от несоответствия: вы шлёте сообщения быстрее, чем компонент успевает их обработать, или обновляете состояние в двух местах без явного источника правды.
Классический пример — биллинг. В прототипе вы могли создать счёт, отправить письмо и обновить тариф пользователя в одном запросе. При нагрузке почта замедляется, запрос таймаутится, клиент повторяет запрос, и у вас появляются два счёта и одно изменение плана. Работа по надёжности в основном о том, чтобы эти повседневные сбои не становились багами, видимыми пользователю.
Системы усложняются, потому что они растут без соглашения о том, что должно быть правильным всегда, что должно быть просто быстрым, и что делать при сбое.
Начните с того, чтобы очертить границу того, что вы обещаете пользователям. Внутри этой границы назовите действия, которые должны быть корректны каждый раз (перемещение денег, контроль доступа, владение аккаунтом). Затем укажите области, где «в итоге корректно» достаточно (счётчики аналитики, индексы поиска, рекомендации). Это разделение превращает туманную теорию в конкретные приоритеты.
Далее запишите источник истины. Это место, где факты фиксируются единожды, надёжно и по чётким правилам. Всё остальное — производные данные, созданные для скорости или удобства. Если производный вид испорчен, его должны уметь перестроить из источника истины.
Когда команды застревают, обычно помогают эти вопросы:
Если пользователь меняет тариф, дашборд может отставать. Но нельзя допустить рассинхронизацию между статусом оплаты и реальным доступом.
Если пользователь нажимает кнопку и должен сразу увидеть результат (сохранить профиль, загрузить дашборд, проверить права), обычный request-response API обычно достаточен. Держите путь прямым.
Как только работа может происходить позже, переводите её в async. Подумайте об отправке писем, списании денег, генерации отчётов, изменении размеров загрузок или синхронизации данных в поиск. Пользователь не должен ждать этого, и ваш API не должен быть заблокирован, пока они выполняются.
Очередь — это список дел: каждую задачу должен выполнить один воркер ровно один раз. Поток (или лог) — это запись: события хранятся в порядке, и несколько читателей могут перепроигрывать их, догонять состояние или строить новые функции позже, не меняя продюсера.
Практический выбор:
Пример: в вашем SaaS есть кнопка «Create invoice». API валидирует ввод и сохраняет счёт в Postgres. Затем очередь обрабатывает «send invoice email» и «charge card». Если позже вы добавите аналитику, уведомления и проверки на мошенничество, поток с событиями InvoiceCreated позволит каждой фиче подписаться, не превращая основной сервис в лабиринт.
По мере роста продукта события перестают быть «приятным дополнением» и становятся страховочной сеткой. Хорошее проектирование событий сводится к двум вопросам: какие факты вы фиксируете и как другие части продукта могут на них реагировать без домыслов?
Начните с небольшого набора бизнес-событий. Выбирайте моменты, важные для пользователей и денег: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Имена живут дольше кода. Используйте прошедшее время для завершённых фактов, делайте названия конкретными и избегайте формулировок из UI. PaymentSucceeded останется понятным, даже если позже появятся купоны, ретраи или несколько провайдеров платежей.
Относитесь к событиям как к контрактам. Избегайте универсального «UserUpdated» с мешаниной полей, которая меняется каждую итерацию. Предпочитайте наименьший факт, за который вы готовы ручаться годами.
Для безопасной эволюции отдавайте предпочтение добавлению (новые опциональные поля). Если нужен несовместимый баг-разбивающий апдейт — опубликуйте новое имя события (или явную версию) и держите оба варианта, пока старые потребители не уйдут.
Что хранить? Если вы держите только последние строки в базе, вы теряете историю того, как вы к ним пришли.
Сырые события хороши для аудита, перепроигрывания и отладки. Снимки (snapshots) хороши для быстрых чтений и быстрого восстановления. Многие SaaS используют оба подхода: хранят сырые события для ключевых рабочих процессов (биллинг, права доступа) и поддерживают снимки для экранов, видимых пользователю.
Согласованность проявляется в моментах типа: «Я поменял тариф, почему он всё ещё показывает Free?» или «Я отправил приглашение, почему мой коллега ещё не может войти?»
Сильная согласованность означает: как только вы получили сообщение об успехе, все экраны сразу должны отражать новое состояние. Eventual consistency значит, что изменение распространяется со временем, и в короткий промежуток разные части приложения могут не совпадать. Ни один подход не «лучше» — вы выбираете, исходя из ущерба от несоответствия.
Сильная согласованность обычно нужна для денег, доступа и безопасности: снятие денег, смена пароля, отзыв API-ключей, соблюдение лимитов по местам. Eventual consistency чаще подходит для лент активности, поиска, аналитики, «последнего визита» и уведомлений.
Если вы принимаете устаревание, проектируйте под это явно, а не скрывайте. Держите UI честным: показывайте «Обновляется…» после записи до получения подтверждения, предлагайте ручное обновление списков и используйте optimistic UI только там, где можно легко отменить изменения.
Ретраи — вот где согласованность подкрадывается. Сеть падает, клиенты нажимают дважды, воркеры перезапускаются. Для важных операций делайте запросы идемпотентными, чтобы повторение не создало два счёта, два приглашения или два возврата. Распространённый подход — idempotency key для действия плюс серверное правило возвращать первоначальный результат при повторах.
Backpressure — это то, что нужно, когда запросов или событий приходит больше, чем система успевает обработать. Без него работа накапливается в памяти, очереди растут, а самая медленная зависимость (часто база данных) решает, когда всё упадёт.
Проще: продюсер продолжает говорить, а потребитель тонет. Если вы продолжаете принимать работу, вы не только замедляетесь. Вы запускаете цепную реакцию таймаутов и ретраев, которая умножает нагрузку.
Предупреждающие признаки обычно видны до аварии: backlog растёт, задержки прыгают после всплесков или деплоев, ретраи увеличиваются из-за таймаутов, несвязанные эндпоинты падают при замедлении одной зависимости, а соединения с базой сидят на пределе.
Когда вы попадаете в такой момент, выберите явное правило того, что происходит при заполнении. Цель не в том, чтобы обработать всё любой ценой. Цель — остаться живыми и быстро восстановиться. Команды обычно начинают с одного-двух контролей: rate limits (на пользователя или API-ключ), ограниченные очереди с определённой политикой отброса/задержки, circuit breakers для падающих зависимостей и приоритеты, чтобы интерактивные запросы выигрывали у фоновых задач.
Защищайте базу в первую очередь. Держите пулы подключений маленькими и предсказуемыми, ставьте таймауты на запросы и накладывайте жёсткие лимиты на дорогие эндпойнты вроде ad-hoc отчётов.
Надёжность редко требует большого рефакторинга. Обычно она приходит из нескольких решений, которые делают сбои видимыми, локализованными и восстанавливаемыми.
Начните с потоков, которые зарабатывают или теряют доверие, затем добавляйте страховые ограждения перед добавлением фич:
Map critical paths. Запишите точные шаги для signup, login, сброса пароля и любых платёжных потоков. Для каждого шага перечислите зависимости (база, почтовый провайдер, фоновый воркер). Это заставит ясно понять, что должно быть мгновенным, а что можно исправить «в итоге».
Add observability basics. Дайте каждому запросу ID, который виден в логах. Отслеживайте небольшой набор метрик, совпадающих с болью пользователя: error rate, latency, глубина очереди и медленные запросы. Добавляйте трассировки только там, где запросы пересекают сервисы.
Isolate slow or flaky work. Всё, что общается с внешним сервисом или регулярно занимает больше секунды, стоит перенести в задания и воркеры.
Design for retries and partial failures. Предположите, что таймауты случаются. Делайте операции идемпотентными, используйте экспоненциальный backoff, ставьте временные лимиты и держите пользовательские действия короткими.
Practice recovery. Бэкапы важны только если вы умеете их восстановить. Делайте маленькие релизы и держите быстрый путь отката.
Если ваш тулкит поддерживает снапшоты и откат (Koder.ai это делает), встроите это в обычные практики деплоя вместо того, чтобы обращаться к ним только в авариях.
Представьте себе маленький SaaS, который помогает командам подключать новых клиентов. Поток простой: пользователь регистрируется, выбирает тариф, оплачивает и получает приветственное письмо плюс несколько шагов "getting started".
В прототипе всё происходит в одном запросе: создать аккаунт, списать платёж, переключить флаг "paid" у пользователя, отправить письмо. Это работает, пока не растёт трафик, происходят ретраи и внешние сервисы не замедляются.
Чтобы сделать систему надёжной, команда превращает ключевые действия в события и сохраняет append-only историю. Они вводят несколько событий: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Это даёт аудит, упрощает аналитику и позволяет медленным задачам выполняться в фоне, не блокируя регистрацию.
Несколько ключевых выборов решают большую часть проблем:
PaymentSucceeded с явным idempotency key, чтобы ретраи не давали двойного предоставления.Если платёж прошёл, но доступ ещё не предоставлен, пользователи почувствуют себя обманутыми. Решение не в «идеальной согласованности везде». Решение — решить, что должно быть согласовано прямо сейчас, и отобразить это в UI состоянием вроде «Активируем ваш план», пока не придёт EntitlementGranted.
В плохой дизайн день обратное давление решает всё. Если почтовый API подвиснет во время маркетинговой кампании, старый дизайн таймаутит checkouts, пользователи повторяют, и появляются дублированные списания и письма. В лучшем дизайне checkout проходит, запросы на почту накапливаются в очереди, и задача replay очищает backlog, когда провайдер восстанавливается.
Большинство инцидентов не вызывает одна героическая ошибка. Они приходят из мелких решений, которые имели смысл в прототипе и затем превратились в привычки.
Одна частая ловушка — переход на микросервисы слишком рано. В результате получают сервисы, которые в основном вызывают друг друга, неясную ответственность и изменения, требующие пяти деплоев вместо одного.
Другая ловушка — использование «eventual consistency» как свободного пропуска. Пользователям всё равно на термин. Им важно, что они нажали Сохранить, а страница позже показывает старые данные или статус счёта то появляется, то исчезает. Если принимаете задержки, всё равно нужны пользовательская обратная связь, таймауты и определение «достаточно хорошо» для каждого экрана.
Другие частые ошибки: публикация событий без плана перепроигрывания, неограниченные ретраи, которые умножают нагрузку в инцидентах, и позволение каждому сервису напрямую обращаться к одной и той же схеме базы, так что одно изменение ломает многие команды.
«Production ready» — это набор решений, на которые вы можете указать в два часа ночи. Чёткость важнее хитроумности.
Начните с указания источников истины. Для каждого ключевого типа данных (клиенты, подписки, счета, права) решите, где хранится окончательная запись. Если приложение читает «правду» из двух мест, рано или поздно вы будете показывать разный ответ разным пользователям.
Потом посмотрите на ретраи. Предположите, что важное действие выполнится дважды. Если тот же запрос попадёт в систему два раза, можно ли избежать двойного списания, двойной отправки или двойного создания?
Небольшой чеклист, который ловит большинство болезненных ошибок:
Масштабирование становится проще, если вы рассматриваете системный дизайн как короткий список решений, а не как груду теории.
Запишите 3–5 решений, с которыми вы ожидаете столкнуться в следующем месяце, простым языком: «Переносим ли отправку писем в фоновые задачи?» «Принимаем ли мы слегка устаревшую аналитику?» «Какие действия должны быть немедленно согласованы?» Используйте этот список, чтобы согласовать продукт и инженерию.
Затем выберите один рабочий поток, который сейчас синхронен, и переведите только его в async. Квитанции, уведомления, отчёты и обработка файлов — частые первые шаги. Измеряйте два показателя до и после: задержку, видимую пользователю (стало ли быстрее?), и поведение при сбоях (не вызвали ли ретраи дубликаты или путаницу?).
Если хотите быстро прототипировать такие изменения, Koder.ai (koder.ai) может помочь итерировать на стеке React + Go + PostgreSQL, удерживая снапшоты и откаты под рукой. Критерий прост: выпустите одно улучшение, изучите поведение на реальном трафике и решите, что делать дальше.
Прототип отвечает на вопрос «можем ли мы это собрать?» SaaS отвечает на вопрос «будет ли это работать, когда появятся пользователи, данные и сбои?»
Крупный сдвиг — это проектирование под:
Выделите границу вокруг того, что вы обещаете пользователям, и затем пронумеруйте действия по их влиянию.
Начните с должно быть корректно всегда:
Потом отметьте может быть в итоге корректно:
Выберите одно место, где каждый «факт» записывается один раз и считается окончательным (для небольшого SaaS это часто Postgres). Это и есть источник истины.
Всё остальное — производные данные для скорости или удобства (кэши, read-модели, индексы поиска). Хороший тест: если производный вид неверен, можно ли восстановить его из источника истины без догадок?
Используйте request-response, когда пользователь ждёт немедленного результата и работа мала.
Переводите в async, когда задача может выполняться позже или быть медленной:
Асинхронность держит API быстрым и уменьшает таймауты, которые провоцируют ретраи.
Очередь — это список дел: каждую задачу должен выполнить ровно один воркер (с ретраями).
Поток/лог — это запись событий в порядке: несколько потребителей могут перепроигрывать его, догонять состояние или строить новые фичи, не связывая продюсера с ними.
Практическое правило:
Сделайте важные операции идемпотентными: повтор одного и того же запроса должен возвращать тот же результат, а не создавать второй счёт или платёж.
Распространённый паттерн:
Также используйте уникальные ограничения, где это возможно (например, один счёт на заказ).
Публикуйте небольшой набор стабильных фактов бизнеса, названных в прошедшем времени, например PaymentSucceeded или SubscriptionStarted.
Держите события:
Признаки, что нужна обратная связь/контроль нагрузки:
Первые меры:
Начните с базовой наблюдаемости, которая отражает боль пользователя:
Трейсинг добавляйте там, где запросы пересекают сервисы; не профилируйте всё подряд, пока не поймёте, за что смотреть.
«Production ready» — это набор решений, на которые вы можете указать в два часа ночи. Чёткость важнее изобретательности.
Короткий чеклист:
Если платформа поддерживает снапшоты и откат (например, Koder.ai), используйте это как обычную практику релизов, а не как трюк в аварии.
Запишите это коротким решением, чтобы все строили по одним и тем же правилам.
Это помогает потребителям не гадать, что произошло.