15 нояб. 2025 г.·8 мин
Создать веб‑приложение для прогнозирования запасов и планирования спроса
Спланируйте и постройте веб‑приложение для прогнозирования запасов и планирования спроса: подготовка данных, методы прогнозирования, UX, интеграции, тестирование и деплой.
Что вы строите и почему это важно
Веб‑приложение для прогнозирования запасов и планирования спроса помогает бизнесу решать что покупать, когда покупать и в каком объёме — на основе ожидаемого будущего спроса и текущего состояния запасов.
Прогнозирование запасов предсказывает продажи или потребление для каждого SKU во времени. Планирование спроса превращает эти прогнозы в решения: точки заказа, объёмы заказов и сроки, согласованные с целями сервиса и денежными ограничениями.
Проблемы, которые оно решает
Без надёжной системы команды часто полагаются на таблицы и интуицию. Это обычно приводит к двум затратным результатам:
- Stockout’ы (потерянные продажи, срочная доставка, недовольные клиенты)
- Избыточные запасы (замороженные деньги, складские расходы, уценки, устаревание)
Хорошо продуманное веб‑приложение создаёт общий источник правды по ожиданиям спроса и рекомендованным действиям — чтобы решения были последовательны по локациям, каналам и командам.
Начните просто, потом улучшайте
Доверие к прогнозам выстраивается со временем. Ваш MVP может стартовать с:
- Небольшого набора ключевых SKU
- Простого недельного прогноза
- Базовых рекомендаций по пополнению
После того как пользователи привыкнут к процессу, вы сможете постепенно улучшать точность с помощью лучших данных, сегментации, учёта промо и более умных моделей. Цель не «идеальный» прогноз, а повторяемый процесс принятия решений, который улучшается с каждым циклом.
Кто использует систему
Типичные пользователи:
- Планировщики спроса/запасов: формируют планы и просматривают исключения
- Операции и складские команды: готовят приёмы и распределение
- Закупки/поставки: размещают заказы и управляют поставщиками
- Финансы: понимают инвестиции в запасы и оборотный капитал
Что оптимизировать
Оценивайте приложение по бизнес‑результатам: меньше stockout’ов, меньше избыточных запасов, понятные решения по закупкам — всё отображается на дашборде планирования запасов, который делает следующее действие очевидным.
Определите границы MVP: решения, горизонт и гранулярность
Успех приложения зависит от ясности: какие решения оно поддерживает, для кого и с какой детализацией? Прежде чем строить модели и графики, определите минимальный набор решений, которые должен улучшить ваш MVP.
1) Начните с бизнес‑вопросов
Формулируйте их как действия, а не фичи:
- Сколько заказать для каждого товара (рекомендованное количество)
- Когда заказать (дата заказа или триггер точки заказа)
- Для каких мест/каналов (какой SKU, какая локация или канал)
Если экран не отвечает на один из этих вопросов, скорее всего он пригодится на более позднем этапе.
2) Установите горизонт планирования и ритм обновлений
Выберите горизонт, соответствующий времени выполнения и ритму закупок:
- Недели (например, 4–12) для быстрых SKU или короткого времени выполнения
- Месяцы (например, 3–6) для импортных товаров или сезонного планирования
Затем выберите частоту обновлений: ежедневно, если продажи меняются быстро; еженедельно, если закупки происходят по циклe. Частота определяет, как часто приложение запускает задачи и обновляет рекомендации.
3) Выберите гранулярность, с которой можно действовать
«Правильный» уровень — это уровень, на котором реально покупать и перемещать запасы:
- SKU‑локация (самый пригодный к действию, требует больше данных)
- Только SKU (подходит для одного склада)
- Категория или канал (полезно для раннего MVP или редких данных)
4) Определите метрики успеха
Делайте успех измеримым: уровень сервиса / частота stockout’ов, оборачиваемость запасов, и ошибка прогноза (например, MAPE или WAPE). Свяжите метрики с бизнес‑целями: предотвращение stockout’ов и снижение избыточных запасов.
5) Объём MVP vs последующие фазы
MVP: один прогноз на SKU (или SKU‑локация), расчёт точки заказа, простой workflow утверждения/экспорта.
Дальше: мульти‑эшелонная оптимизация, ограничения по поставщикам, промоции и сценарное планирование.
Определите источники данных и требования к их качеству
Прогнозы полезны ровно настолько, насколько хороши входные данные. Прежде чем выбирать модели или экраны, проясните, какие данные у вас есть, где они хранятся и что значит "достаточно хорошо" для MVP.
Основные входы
Как минимум, прогнозирование требует последовательного вида:
- История продаж/заказов (по SKU, локации, дате)
- Запасы на руках и позиция по запасам (на руках + входящие − зарезервированные)
- Поступления и закупочные заказы (что пришло, что ожидается и когда)
- Времена выполнения (поставщик, маршрут, обработка на складе)
- Календари (праздники, промо, закрытия, индикаторы сезонности)
Где данные обычно живут
Большинство команд тянет данные из смеси систем:
- ERP для POs, поставщиков, карточки товара, стоимости
- WMS для поступлений, размещения, перемещений, корректировок запасов
- POS/eCommerce для сигналов спроса (заказы, аннуляции)
- Таблицы для «tribal knowledge» (правки, минимумы, фасовки)
Частота обновлений и поздние изменения
Решите, как часто приложение обновляется (ежечасно, ежедневно) и что делать, когда данные приходят поздно или редактируются. Практичный подход — хранить неизменяемую историю транзакций и применять корректирующие записи, а не перезаписывать вчерашние значения.
Ответственность и простой словарь данных
Назначьте владельца для каждого набора данных (например, запасы: операционная служба склада; времена выполнения: закупки). Ведите короткий словарь данных: смысл поля, единицы, часовой пояс и допустимые значения.
Типичные пробелы, к которым нужно подготовиться
Ожидайте проблемы вроде отсутствующих lead time, конверсий единиц (each vs case), возвратов и аннуляций, дубликатов SKU и несовместимых кодов локаций. Раннее выявление позволяет MVP либо исправлять, либо подставлять значения, либо исключать записи — явно и видно пользователям.
Спроектируйте модель данных для прогнозирования и учёта запасов
Успех приложения зависит от доверия к цифрам. Это доверие начинается с модели данных, которая делает «что произошло» (продажи, поступления, перемещения) однозначным и обеспечивает согласованность «что верно сейчас» (на руках, в заказе).
Начните с основных сущностей
Определите небольшой набор сущностей и придерживайтесь его во всём приложении:
- SKU и атрибуты SKU (категория, фасовка, срок годности)
- Локация (склад, магазин, 3PL‑узел)
- Поставщик (времена выполнения, минимальные объёмы заказа)
- Канал/клиент (ретейл, опт, маркетплейс)
- Время (выбранный календарь с фиксированной гранулярностью)
Выберите одну гранулярность времени и приведите всё к ней
Выберите день или неделю как каноническую гранулярность. Затем приведите все входы к ней: заказы могут иметь метки времени, учёты запасов — срезы на конец дня, счета — появляться позднее. Сделайте правило выравнивания явным (например, «продажи относятся к дате отгрузки, агрегируются по дню»).
Стандартизируйте единицы и валюты заранее
Если вы продаёте в each/case/kg, храните и оригинальную единицу, и нормализованную единицу для прогнозов (например, “each”). Если прогнозируете выручку, храните исходную валюту и нормализованную отчётную с курсом обмена.
Моделируйте запасы как события (для объяснимости)
Отслеживайте запасы как последовательность событий по SKU‑локации‑времени: моментальные снимки на руках, в заказе, поступления, перемещения и корректировки. Так легче объяснять stockout’ы и вести аудит.
Определите «единственный источник правды» для каждого поля
Для каждой ключевой метрики (продажи в единицах, на руках, lead time) решите, какая система авторитетна, и задокументируйте это в схеме. Когда две системы расходятся, модель должна показывать, какая система побеждает — и почему.
Постройте надёжный ETL‑пайплайн
UI для прогнозов полезен ровно настолько, насколько предсказуемы данные. Если числа меняются без объяснений, пользователи перестанут доверять дашборду даже при условии, что модель корректна. Ваш ETL должен делать данные предсказуемыми, отлаживаемыми и трассируемыми.
Планируйте пайплайн: extract → clean → aggregate → load → validate
Сначала пропишите «источник правды» для каждого поля (заказы, отгрузки, на руках, lead time). Затем реализуйте повторяемый поток:
- Extract из API, баз данных или файлов с неизменяемыми run ID
- Clean (типы, часовые пояса, ключи SKU/локации, конверсии единиц)
- Aggregate до нужной гранулярности (день/неделя по SKU‑локации)
- Load в аналитические таблицы для чтения задачами прогнозирования
- Validate с автоматическими проверками перед тем, как данные попадут на дашборды
Храните raw и curated таблицы (для трассируемости)
Держите два слоя:
- Raw‑таблицы: «как пришло», append‑only. Если upstream система поменяет значение, вы увидите когда и почему.
- Curated‑таблицы: стандартизованные колонки и бизнес‑логика (например, net sales, available stock).
Когда планировщик спросит: «Почему спрос за прошлую неделю изменился?», вы должны показать raw‑запись и трансформацию, которая её затронула.
Автоматические проверки, которые ловят проблемы рано
Минимум проверяйте:
- Пропущенные значения в датах, ID SKU, ID локаций
- Отрицательные запасы или невозможные перемещения
- Выбросы (внезапный 10× всплеск продаж) и дубли транзакций
Сбой выполнения должен приводить к остановке (или карантину партиции), а не к тихой публикации плохих данных.
Batch vs near‑real‑time: следуйте ритму планирования
Если закупки происходят еженедельно, обычно достаточно ежедневного батча. Near‑real‑time оправдано только когда от этого зависят оперативные решения (то же‑день пополнение, резкие изменения e‑commerce), потому что это увеличивает сложность и уровень оповещений.
Правила повторных запусков, оповещения и логи запусков
Задокументируйте, что происходит при ошибке: какие шаги перезапускаются автоматически, сколько раз и кто получает уведомление. Отправляйте оповещения при падении извлечений, резком снижении числа строк или провалах в валидации — и держите лог запусков для аудита каждого входа в прогноз.
Выбирайте методы прогнозирования, подходящие вашей реальности
Более безопасные итерации
Используйте снимки и откат, чтобы тестировать изменения моделей, не подрывая доверие планировщика.
Методы прогноза не "лучше" сами по себе — они лучше для ваших данных, SKU и ритма планирования. Хорошее приложение позволяет легко начать с простого, измерять результат и переходить на продвинутые методы там, где это окупается.
Начните с базовых моделей (и сохраняйте их навсегда)
Базовые методы быстры, объяснимы и отличны как sanity‑check. Включите хотя бы:
- Скользящая средняя (для стабильных товаров)
- Сезонный наивный (повторить прошлую неделю/месяц/сезон)
- Простое экспоненциальное сглаживание (реагирует на недавние сдвиги без переобучения)
Всегда отображайте точность прогноза относительно этих баз — если сложная модель их не превосходит, её не стоит ставить в продакшн.
Добавляйте более умные модели по мере измерений
Когда MVP стабилен, добавьте несколько «переходных» моделей:
- Prophet‑подобные модели для недельной/годовой сезонности и учёта праздников
- ARIMA, когда автокорреляция сильна и истории достаточно
- Градиентный бустинг, когда есть полезные драйверы (цена, промо, lead time, канальные сигналы)
Одна модель для всех SKU vs выбор на уровне SKU
С одним дефолтным моделем можно быстрее выпустить продукт, но лучшее качество часто даёт выбор модели на SKU (бэктест‑сравнение и выбор наилучшей семейства моделей), особенно при смешанном каталоге: стабильные, сезонные и long‑tail товары.
Не игнорируйте прерывистый спрос
Если много SKU имеют множество нулей, это отдельный кейс. Добавьте методы, приспособленные для прерывистого спроса (например, подходы в духе Croston) и оценивайте метриками, которые не штрафуют нули несправедливо.
Человек в цикле (override)
Планировщикам понадобятся правки для запусков, промо и известных сбоев. Постройте workflow для оверрайдов с указанием причины, сроком действия и аудиторским следом, чтобы ручные правки улучшали решения, не скрывая происходящее.
Фичи и крайние случаи (stockout’ы, новые SKU)
Точность часто зависит от фич: контекста помимо "продажи на прошлой неделе". Цель — не сотни сигналов, а небольшой набор, отражающий поведение бизнеса и понятный планировщикам.
Календарные и эвент‑сигналы
Спрос обычно имеет ритм. Добавьте несколько календарных фич, которые фиксируют этот ритм без переобучения:
- День недели и неделя в месяце (помогает payday‑эффектам и уик‑енд‑всплескам)
- Месяц/сезон (покрывает широкую сезонность)
- Праздники и локальные события (флаги или категория типа праздника)
- Промо (даты начала/окончания, глубина скидки, канал)
Если промо «грязные», начните с простого флага «на промо» и улучшайте позже.
Сигналы продукта и поставок
Прогнозирование запасов — это не только спрос, но и доступность. Полезные и объяснимые сигналы:
- Текущая цена и «изменение цены vs предыдущий период»
- Lead time (и изменение lead time)
- MOQ / фасовка (если влияет на поведение заказов)
- Статус запаса (в наличии, мало, бэк‑ордер)
Stockout’ы: не учите модель неверным выводам
День с нулевыми продажами из‑за stockout’а не равен нулевому спросу. Если подавать такие нули в обучение, модель решит, что спрос исчез.
Распространённые подходы:
- Помечать периоды stockout и исключать их из таргета обучения
- Импутировать «потерянные продажи» по недавнему спросу без stockout, или ограничивать по доступному запасу
- Отслеживать «дни отсутствия на складе» как фичу, чтобы модель могла корректировать ожидания
Холодный старт и замены
Новые товары не имеют истории. Ясные правила:
- Прогноз с уровня родителя (категория/бренд) и распределение по запланированному распределению
- Сопоставление с похожими товарами (заменители, предшественники) на первые недели
- Постепенный сдвиг веса от прокси к собственной истории SKU по мере накопления данных
Держите набор фич компактным и называйте фичи понятными бизнес‑терминами в приложении (например, «неделя праздника», а не «x_reg_17»), чтобы планировщики могли доверять и оспаривать логику модели.
Превратите прогнозы в рекомендации по закупкам и пополнению
Прогноз полезен только тогда, когда подсказывает конкретные действия: когда заказать, сколько заказать и какой буфер держать. Веб‑приложение должно переводить прогнозы в конкретные, подлежащие проверке закупочные действия.
От прогноза к точке заказа, safety stock и объёму заказа
Начните с трёх выходов на SKU (или SKU‑локация):
- Точка заказа (ROP): позиция запасов, при которой нужно инициировать новый заказ
- Safety stock: дополнительный запас для защиты от неопределённости спроса и времени выполнения
- Количество заказа: сколько закупить сегодня (или в следующем цикле)
Практичная структура:
- Ожидаемый спрос за время выполнения заказа (на основе прогноза)
-
- safety stock (на основе вариативности и целевого уровня сервиса)
- = точка заказа
Если можете измерить — включите вариативность lead time (не только среднее). Даже простое стандартное отклонение по поставщику заметно снижает риск stockout.
Устанавливайте уровни сервиса на основе ценности бизнеса
Не каждый товар заслуживает одинаковой защиты. Позвольте пользователям выбирать целевые уровни сервиса по ABC‑классу, марже или критичности:
- Высокая маржа/критичные SKU: высокий уровень сервиса → больше safety stock
- Long‑tail/низко‑приоритетные SKU: низкий уровень сервиса → более плоские запасы
Учитывайте реальные ограничения
Рекомендации должны быть выполнимы. Добавьте обработку ограничений:
- MOQ и фасовка (округление до коробов)
- Бюджетные лимиты (приоритизация по ожидаемому эффекту)
- Ограничения по вместимости (складские места, паллеты)
Делайте «почему» явным
Каждый предложенный заказ должен содержать краткое объяснение: прогнозный спрос за время выполнения, текущая позиция по запасам, выбранный уровень сервиса и применённые ограничения. Это формирует доверие и упрощает утверждение исключений.
Архитектура веб‑приложения: UI, API, задания и хранилище
Преобразуйте решения в экраны
Генерируйте React UI, Go API и схему PostgreSQL на основе вашего рабочего процесса планирования.
Прогнозное приложение проще поддерживать, разделив его на два продукта: интерфейс для людей и движок прогнозов в фоне. Такое разделение делает UI быстрым, избегает тайм‑аута и обеспечивает воспроизводимость результатов.
Простой масштабируемый базовый стек
Начните с четырёх блоков:
- Web UI для загрузки данных, настройки прогонов, просмотра прогнозов и утверждений
- API (backend‑сервис), который валидирует запросы, читает/пишет данные и запускает задания
- База данных для транзакций (запуски, настройки, пользователи, утверждения) и места для больших артефактов
- Фоновые задания для тяжёлой работы: генерация фич, обучение моделей, прогнозы и расчёт рекомендаций
Ключевое правило: прогоны прогнозов не должны выполняться внутри UI‑запроса. Ставьте их в очередь (или по расписанию), возвращайте run ID и стримьте прогресс в UI.
Если хотите ускорить сборку MVP, платформа для быстрой прототипировки, типа Koder.ai, может подойти: с её помощью можно прототипировать React‑UI, Go‑API с PostgreSQL и workflow фоновых задач из единого чат‑ориентированного цикла — затем экспортировать код при готовности к жёсткой доработке или самостоятельному хостингу.
Хранение: что где хранить
Держите «system of record» таблицы (тенанты, SKU, локации, конфиги прогона, статус прогона, утверждения) в основной базе. Результаты в объёме — ежедневные прогнозы, диагностические данные, экспорты — храните в таблицах, оптимизированных для аналитики, или в объектном хранилище, а по run ID ссыльтесь на них из основной БД.
Мульти‑тенантность с первых дней (даже для MVP)
Если вы обслуживаете несколько бизнес‑единиц или клиентов, обеспечьте границы по тенантам в API и схеме базы данных. Простое решение — tenant_id в каждой таблице плюс ролевой доступ в UI. Даже single‑tenant MVP выигрывает от этого — вы избежите случайного перемешивания данных позже.
Минимальные API
Стремитесь к небольшому и понятному набору конечных точек:
POST /data/upload(или коннекторы),GET /data/validationPOST /forecast-runs(запуск),GET /forecast-runs/:id(статус)GET /forecasts?run_id=...иGET /recommendations?run_id=...POST /approvals(принять/переопределить),GET /audit-logs
Контроль затрат
Прогнозы могут быть дорогими. Ограничьте тяжёлые переобучения кэшированием фич, переиспользованием моделей при неизменных конфигурациях и планированием полных переобучений (например, еженедельно), одновременно выполняя лёгкие ежедневные обновления. Это держит UI отзывчивым и бюджет предсказуемым.
UX и дашборды: делайте прогнозы пригодными к действию
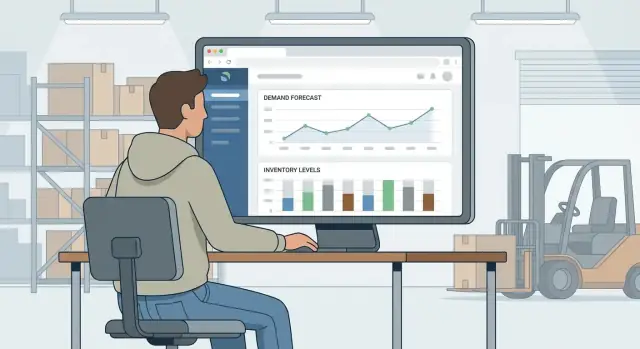
Модель ценна только тогда, когда планировщик может быстро и уверенно принять решение. Хороший UX превращает "числа в таблице" в понятные действия: что купить, когда купить и что требует внимания сейчас.
Основные экраны, соответствующие рабочему потоку
Начните с нескольких экранов, соответствующих ежедневным задачам:
- Обзор: KPI (уровень сервиса, риск stockout, недели покрытия), главные исключения и рекомендованные действия на сегодня
- Детали SKU: все данные по товару — история, прогноз, на руках, входящие, lead time и итоговая рекомендация по точке заказа
- Исключения: очередь «нужна проверка» (риск отсутствия, избыток, всплеск ошибки прогноза, задержки у поставщика)
- Предложения по заказам: черновики PO с количествами, ожидаемыми датами прибытия и суммарным бюджетом
Согласованная навигация позволяет быстро прыгать от исключения к деталям SKU и обратно, не теряя контекст.
Быстрые фильтры и производительность
Планировщики постоянно дробят данные. Сделайте фильтрацию мгновенной и предсказуемой по диапазону дат, локации, поставщику и категории. Используйте разумные дефолты (последние 13 недель, основной склад) и запоминайте последние выборы пользователя.
Объяснимость, понятная людям
Стройте доверие, показывая, почему прогноз изменился:
- Главные драйверы спроса (промо, смена каналов, цена)
- Простая сезонность (недельный паттерн, праздники)
- Флаги недавних аномалий (одноразовый крупный заказ, пропуски в данных)
Избегайте тяжёлой математики в UI; делайте упор на простые подсказки и понятные тултипы.
Коллаборация и ответственность
Добавьте лёгкие инструменты совместной работы: inline‑заметки, шаг утверждения для крупных заказов и история изменений (кто изменил оверрайд прогноза, когда и почему). Это поддерживает аудит без торможения рутинных решений.
Экспорт и печатные представления заказов
Современные команды всё ещё обмениваются файлами. Предоставьте чистые CSV‑экспорты и печатный summary заказа (товары, количества, поставщик, итоги, требуемая дата доставки), чтобы закупки могли исполнить заказ без дополнительного форматирования.
Интеграции, права доступа и аудит
Создайте MVP быстрее
Прототипируйте MVP прогнозирования запасов в Koder.ai с чат-управляемым циклом разработки.
Прогнозы полезны только тогда, когда системы, которые они обновляют, и люди, которые им доверяют, доступны. Планируйте интеграции, контроль доступа и аудиторский след, чтобы приложение стало «операционным», а не просто «интересным».
Интеграция с ERP/WMS (оперативная правда)
Начните с основных объектов, влияющих на решения по запасам:
- Карточка товара (SKU, UOM, дефолты lead time, поставщик, статус)
- Закупочные заказы (open/closed, количества, обещанные даты)
- Поступления (что и когда пришло, куда)
- Перемещения (межскладские перемещения, товары в пути)
Будьте явными в том, какая система источник правды для каждого поля. Например: статус SKU и UOM — из ERP, а оверрайды прогноза — из вашего приложения.
Поддержка нескольких вариантов импорта
Большинству команд нужен путь «сейчас работает» и путь «масштабируется позже»:
- API‑интеграция для near‑real‑time синхронизации
- SFTP‑сбросы для поставщиков/старых ERP, которые выгружают файлы ночью
- Плановый CSV‑загрузчик для MVP с шаблонами и валидацией
Сохраняйте логи импорта (число строк, ошибки, метки времени), чтобы пользователи могли диагностировать пропавшие данные без помощи инженеров.
Идентификация, роли и утверждения
Определите права доступа, соответствующие процессам бизнеса — обычно по локациям и/или департаментам. Типичные роли: Viewer, Planner, Approver, Admin. Убедитесь, что чувствительные действия (редактирование параметров, утверждение PO) требуют нужной роли.
Надёжный аудиторский след
Записывайте кто что изменил, когда и почему: оверрайды прогноза, правки точек заказа, изменения lead time и решения по утверждению. Храните диффы, комментарии и ссылки на затронутые рекомендации.
Если публикуете KPI по прогнозам, давайте определения в приложении (или ссылку на /blog/forecast-accuracy-metrics). Для планирования развёртывания простая градация доступа может быть синхронизирована с /pricing.
Тестирование, бэктестинг и измерение качества прогноза
Приложение полезно только если можно доказать, что оно работает — и если можно заметить, когда оно перестало работать. Тестирование — это не только «код работает», но и «прогнозы и рекомендации улучшают результаты».
Выбирайте метрики, соответствующие бизнес‑решениям
Начните с небольшого набора понятных метрик:
- MAE (средняя абсолютная ошибка) — «на сколько в штуках промахиваемся»
- MAPE/WMAPE — «насколько промах относительно объёмов продаж» (WMAPE обычно стабильнее по SKU)
- Bias — чтобы понять систематическое завышение или занижение прогноза
- Влияние на уровень сервиса (fill rate, частота stockout) — связывает точность с опытом клиента и выручкой
Отчётность делайте по SKU, категории, локации и горизонту прогноза (следующая неделя и следующий месяц часто ведут себя по‑разному).
Бэктесты с реалистичным разбиением во времени
Бэктестинг должен имитировать работу в продакшне:
- Обучение на историческом окне и тест на следующих неделях/месяцах (без случайного перемешивания)
- Повторение по скользящим окнам, чтобы избежать «удачных» временных интервалов
- Сравнение с простыми базовыми моделями (прошлая неделя, скользящая средняя). Если не бьёте их стабильно — не выпускайте сложность.
Ограждения и мониторинг
Добавьте оповещения при резком падении точности или при подозрительных входах (пропали продажи, дубли заказов, необычные всплески). Небольшая панель мониторинга в /admin поможет предотвратить недели плохих закупочных решений.
Пилот и обратная связь
Перед полным запуском запустите пилот с небольшой группой планировщиков/закупщиков. Отслеживайте, приняты ли рекомендации, и причины отклонений. Эти данные обратной связи становятся обучающими данными для настройки правил, исключений и дефолтов.
Безопасность, приватность и готовность к эксплуатации
Приложение часто содержит самые чувствительные части бизнеса: историю продаж, цены поставщиков, позиции запасов и будущие планы закупок. Рассматривайте безопасность и эксплуатационную готовность как продуктовые фичи — одна утечка экспорта или сломанная ночная задача могут подорвать месяцы доверия.
Контроль доступа: делайте права строже и простыми
Защитите данные принципом наименьших привилегий. Начните с ролей Viewer, Planner, Approver и Admin, затем ограничьте действия (не только страницы): просмотр цен, редактирование параметров, утверждение рекомендаций, экспорт данных.
Если интегрируетесь с провайдером идентификации (SSO), маппьте группы на роли, чтобы offboarding проходил автоматически.
Шифрование и управление секретами
Шифруйте данные в транзите и, по возможности, в покое. Используйте HTTPS везде, ротацию API‑ключей и храните секреты в управляемом тайнике (vault), а не в файлах окружения на серверах. Для баз данных включите шифрование at‑rest и ограничьте сетевой доступ только для приложения и раннеров задач.
Аудит: делайте «кто что сделал» легкоотвечаемым
Логируйте доступ и критические действия (экспорт, правки, утверждения). Храните структурированные логи по:
- Импортам данных и исходным файлам
- Прогонам прогнозов (метод, параметры, версия кода)
- Редактированию рекомендаций/оверайдам и решениям по утверждению
Это не бюрократия, а способ разобраться в неожиданностях на дашборде планирования запасов.
Сохранение, бэкапы и план реагирования на инциденты
Определите правила хранения для загрузок и исторических прогонов. Многие команды хранят raw‑загрузки недолго (например, 30–90 дней) и агрегации дольше для анализа трендов.
Подготовьте план реагирования: кто на дежурстве, как лишить доступа, как восстановить базу. Тестируйте восстановления по расписанию и документируйте RTO для API, заданий и хранилища, чтобы софт для планирования спроса оставался надёжным в стрессовых ситуациях.
FAQ
Что нужно определить в первую очередь при создании веб‑приложения для прогнозирования запасов и планирования спроса?
Начните с определения решений, которые приложение должно улучшить: сколько заказать, когда заказать и для каких мест/каналов (SKU, локация, канал). Затем выберите практичный горизонт планирования (например, 4–12 недель) и единую гранулярность времени (день или неделя), которая соответствует ритму закупок и пополнений в бизнесе.
Что должно быть включено в MVP для веб‑приложения по прогнозированию запасов?
Хорошее MVP обычно включает в себя:
- Один прогноз на SKU (или SKU‑локация) с недельной или дневной гранулярностью
- Базовые рекомендации по пополнению (точка заказа, safety stock, количество заказа)
- Список исключений (риск отсутствия на складе, риск избыточных запасов)
- Процесс утверждения/экспорта (CSV или черновик заказа)
Оставьте такие вещи, как промоакции, сценарное планирование и мульти‑эшелонную оптимизацию, для следующих этапов.
Какие данные нужны для получения полезных прогнозов и рекомендаций по пополнению?
Минимально вам нужны:
- История продаж/заказов по SKU, локации и дате
- Позиция по запасам (на руках + входящие − зарезервированные)
- Заказы и поступления (ожидаемые vs фактические даты прибытия)
- Время выполнения (и, по возможности, его вариативность)
Как справляться с проблемами качества данных, не убивая проект?
Создайте словарь данных и добейтесь консистентности в ключевых вещах:
- ID SKU и локаций (без дубликатов, стабильные ключи)
- Выравнивание по времени (к какой дате относится продажа)
- Единицы измерения (each vs case vs kg) с нормализацией
- Правила по возвратам/аннуляциям (net vs gross)
В пайплайне добавьте автоматические проверки на пропущенные ключи, отрицательные остатки, дубликаты и выбросы — и карантиньте проблемные партиции вместо того, чтобы публиковать их.
Как моделировать данные по запасам, чтобы пользователи доверяли цифрам?
Представляйте запасы как набор событий и снимков:
- Транзакции: продажи, поступления, перемещения, корректировки
- Состояние: снимки на руках, количества в заказе, зарезервированные единицы
Так проще объяснять «что произошло» и поддерживать согласованное «что сейчас верно». Это облегчает объяснение stockout’ов и сверку данных между ERP, WMS и POS/eCommerce.
Какие методы прогнозирования стоит использовать вначале?
Начните с простых и объяснимых базовых методов и храните их навсегда:
- Скользящая средняя
- Сезонный наивный (повторить прошлую неделю/месяц)
- Экспоненциальное сглаживание
Используйте бэктесты, чтобы доказать, что более сложная модель стабильно превосходит эти базовые. Добавляйте сложные методы только тогда, когда можно измерить улучшение и когда есть достаточно чистой истории и драйверов.
Как избежать ошибок в прогнозах, вызванных отсутствием товара на складе?
Не подавайте нули из дней stockout’ов прямо в таргет обучения. Обычно применяют:
- Флагирование и исключение периодов отсутствия запасов из тренировочной выборки
- Импутация потерянных продаж на основе недавнего спроса без stockout
- Отслеживание дней отсутствия на складе как фичи
Главная цель — не научить модель думать, что спрос исчез из‑за отсутствия товара.
Как прогнозировать спрос для новых SKU с малой историей?
Для новых SKU используйте явные правила холодного старта:
- Делайте прогноз на родительском уровне (категория/бренд) и распределяйте вниз
- Сопоставляйте с похожими SKU или предыдущими версиями для начальных недель
- Постепенно смещайте вес от прокси‑сигналов к собственной истории SKU по мере накопления данных
Показывайте в интерфейсе, что прогноз основан на прокси, а не на реальной истории.
Как переводить прогнозы в точки заказа и количества покупок?
Переведите прогнозы в три действующих вывода:
- Ожидаемый спрос за время выполнения заказа
- Safety stock (на основе вариативности и целевого сервиса)
- Точка заказа и предложенное количество для заказа
Затем примените реальные ограничения: MOQ и фасовки (округление), бюджетные лимиты (приоритизация) и ограничения по вместимости. Всегда показывайте «почему» за каждой рекомендацией.
Какая архитектура лучше всего подходит для веб‑приложения по прогнозированию (UI, API, задания, хранилище)?
Отделяйте UI от движка прогнозов:
- UI и API отвечают за настройку, валидацию, утверждения и получение результатов
- Фоновые задачи делают генерацию фич, обучение, прогнозирование и расчёт рекомендаций
Никогда не запускайте прогноз в контексте UI‑запроса — используйте очередь или планировщик, возвращайте run ID и показывайте статус/прогресс в приложении. Храните большие выводы (прогнозы, диагностику) в аналитическом хранилище и ссылайтесь на них по run ID.