Что приложение должно делать (и для кого)
Приложение для продлений и расширений имеет одну задачу: помочь вашей команде увидеть риски и потенциал выручки на следующий квартал заблаговременно, чтобы успеть повлиять. Это означает прогнозирование исходов продлений (с уровнями уверенности) и выявление возможностей для расширения, пока ещё есть время на действие.
Цель: ранние и прикладные сигналы о доходе
Ваше приложение должно превращать разрозненные сигналы — даты контрактов, использование продукта, история поддержки, изменения в стейкхолдерах — в понятные выводы, которые задают следующие шаги.
Если система выдаёт только число, поведение не изменится. Если она выдаёт число и причину и действие — это работает.
Кто использует и что нужно каждому
CSM (менеджеры по успеху клиентов) нуждаются в ежедневном рабочем пространстве: аккаунты, требующие внимания, даты продлений, причины риска, следующие лучшие действия и простой способ логировать заметки и задачи.
Аккаунт‑менеджеры / отдел продаж нужны вид на расширения: квалифицированные возможности, сигналы покупки, стейкхолдеры и точки передачи, без прыжков между инструментами.
Финансы нужны надёжные сводки: прогноз по месяцам/кварталам, сценарии (best/likely/worst) и возможность аудита — что изменилось, когда и почему.
Менеджеры нужны инструменты для коучинга: покрытие (какие продления контактированы?), гигиена pipeline, нагрузка представителей и тренды по сегментам.
Основные результаты, вокруг которых строить
Минимум, что должен выдавать продукт:
- Риск продления (низкий/средний/высокий) с объяснимыми драйверами
- Вид прогнозов продлений (по дате, сумме, уверенности)
- Pipeline расширений (стадия, сумма, сроки, владелец)
- Отчёты «что изменилось с прошлой недели?»
Критерии успеха (чтобы понять, что работает)
Определите измеримые результаты заранее:
- Цель точности прогноза (например, в пределах X% за 30/60/90 дней до продления)
- Принятие: еженедельная активность по ролям и «аккаунты, обновлённые в неделю»
- Сэкономленное время: уменьшение часов на сводные таблицы и статусные презентации
- Коэффициент действий: % высоко‑рисковых продлений с зарегистрированным планом и следующим шагом
Ключевые данные: продления, аккаунты и расширения
Правильное прогнозирование продлений начинается с правильной модели данных. Если приложение не может стабильно ответить «что продлевается, когда, за какую сумму и на каких условиях?», каждый прогноз превращается в спор.
Данные по продлениям (что фактически под риском)
Запись о продлении должна быть полноценным объектом, а не просто датой на аккаунте. Минимально сохранять:
- Аккаунт (кто продлевается)
- Идентификаторы контракта/подписки (какому соглашению это относится)
- Дата продления и срок (когда и на сколько)
- Сумма (ARR/MRR или общая стоимость контракта — выберите одну основную и выведите другую)
- Продукты / план (за что платят)
Также храните практические флаги, влияющие на прогноз: авто‑реневал vs ручное, условия оплаты, окно уведомления об отмене и наличие открытых споров.
Данные по расширениям (что может вырасти)
Расширения стоит моделировать отдельно от продлений, чтобы прогнозировать «удержание» и «рост» независимо. Отслеживайте opportunity расширения с:
- Тип: upsell, cross‑sell, add‑on, увеличение мест
- Продукты или add‑on в предложении
- Изменение мест / уровня использования (частый драйвер для SaaS)
- Сумма (ожидаемый ARR) и вероятность закрытия
Связывайте расширения с аккаунтом и с продлением, когда это релевантно (многие расширения закрываются в циклах продления).
Активности и сигналы здоровья (почему продлит — или нет)
Прогнозирование улучшается, когда вы связываете исходы продлений с реальностью клиентов. Основные объекты активности: задачи, заметки, звонки/письма, QBR и плейбуки. Сопоставьте их с сигналами здоровья, такими как использование продукта, объём/серьёзность тикетов поддержки, NPS/CSAT и проблемы с биллингом.
Цель проста: каждое число прогноза должно быть объяснимо короткой цепочкой фактов, которые команда может проверить.
Пользовательские рабочие процессы и права доступа
Чёткие рабочие процессы поддерживают согласованность прогнозов, а права доступа — доверие к ним. Приложение должно явно показывать что происходит дальше, кто отвечает за шаг и какие изменения разрешены — без превращения процесса в бюрократию.
Рабочий процесс прогноза продления: intake → review → commit → closed
Запись о продлении обычно начинается как «intake» (создана автоматически по дате окончания контракта, импортирована из CRM или добавлена из очереди CSM). Далее:
- Intake: заполнение базовых полей (аккаунт, дата продления, текущий ARR, срок, продукты, контакт клиента). Позвольте CSM пометить начальный риск и добавить заметки.
- Review: менеджер (или renewals ops) проверяет качество: суммы, даты, вероятность и наличие понятных причин риска. Здесь недостающие данные возвращаются на доработку.
- Commit: команда соглашается включить продление в прогноз. Редактирование становится более контролируемым (см. правила владения ниже).
- Closed: продление либо завершено как продлённое, либо как churn, либо отложено. Требуется причина закрытия и итоговая сумма для корректной отчётности.
Рабочий процесс расширения: identify → qualify → propose → negotiate → won/lost
Отслеживание расширений лучше держать как лёгкий pipeline, привязанный к аккаунту:
- Identify: зафиксируйте сигнал (рост использования, новая команда, запрос функции). Удерживайте трение низким: быстрый добавление с приблизительным диапазоном суммы.
- Qualify: подтвердите бюджет, сроки и стейкхолдеров. На этом этапе сумма и целевая дата обязательны.
- Propose / Negotiate: отслеживайте предложенную сумму, дату начала и следующий шаг. Даты закрытия оставляйте редактируемыми, но видимыми в аудите.
- Won/Lost: блокируйте ключевые поля и требуйте указать результаты (причина, конкурент, сведения о скидках при релевантности).
Правила владения и уровни прав
Определите роли заранее (обычно: CSM, Sales/AE, Manager, Ops/Admin, Read‑only/Finance) и настройте права на поля:
- Суммы: редактируют AE/Manager; CSM может предлагать правки через комментарий или «request edit».
- Даты и стадии: редактируют владелец записи и Manager; переход в «Commit» или «Closed» требует одобрения Manager.
- Причины (риск/потеря): редактируются владельцем; обязательны при падении вероятности ниже порога или при закрытии.
Аудит‑трейл для изменений прогноза и риска
Каждое изменение в сумме, дате закрытия, стадии, вероятности, полях здоровья/риска и статусе commit должно создавать неизменяемое событие: кто изменил, когда, старое → новое значение и необязательная заметка. Это защищает целостность прогноза и упрощает коучинг, когда цифры меняются в конце месяца.
Информационная архитектура и раскладка экранов
Хорошая IA делает прогнозы продлений быстрыми. Пользователь всегда должен понимать:
- какие аккаунты важны сейчас,
- почему они под риском,
- что делать дальше.
Рекомендуемая навигация
Держите основную навигацию простой и ориентированной по времени:
- Accounts (поиск + сохранённые представления)
- Renewals (сначала окно по времени)
- Pipeline (expansion + upsell)
- Dashboards (по ролям)
- Settings (поля, права, интеграции)
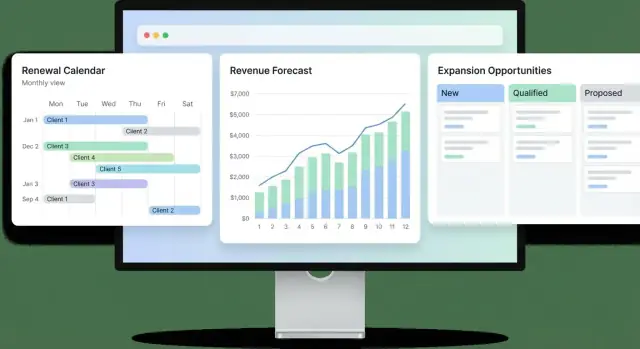
Страница аккаунта («единый источник правды»)
Сделайте страницу аккаунта такой, чтобы CSM понимал историю за 30 секунд:
- Хедер: ARR, дата продления, владелец, регион, текущая категория прогноза
- Панель здоровья: скор здоровья, ключевые драйверы (тренд использования, тикеты поддержки, NPS), время последнего обновления
- Таймлайн продлений: прошлые продления и ближайшие вехи (дата уведомления, юридическая проверка, отправлено предложение)
- Открытые возможности: расширения с стадией, суммой, вероятностью и следующим шагом
Правый блок «Следующие действия» удобен: задачи, предстоящие встречи и флаги риска.
Список продлений (рабочая очередь)
Сделайте Renewals настоящей очередью, а не статичным отчётом. По умолчанию — следующие 90 дней; добавьте фильтры по окну по датам, CSM, региону, риску и ARR. Включите быстрые inline‑действия: обновить риск, поставить следующий шаг, назначить задачу.
Вид pipeline (для продаж простой)
Используйте представление по стадиям (Kanban или таблица) с суммами, вероятностями, датами закрытия и следующими шагами. Избегайте скрытой логики — показывайте, что влияет на вероятность.
Дашборд менеджера (сводки «покрыто ли всё?»)
Дайте лидерам покрытие и исключения:
- Сводный прогноз по месяцам/кварталам
- Суммы под риском и главные драйверы
- Покрытие по владельцам/командам и прогноз vs цель
Сделайте drill‑down в один клик к Renewal или Account view.
Логика прогнозирования и скоринга (просто и объяснимо)
Прогноз полезен только если люди ему доверяют. Для приложения по продлениям и расширениям это означает скоринг, который легко понять, оспорить и применять одинаково по всем аккаунтам.
Скор риска продления: простые факторы и понятные веса
Начните с риска, собранного из небольшого набора входных данных, о которых команда уже говорит на QBR и звонках по продлениям. Держите расчёт намеренно «скучным»:
- Тренд использования (рост/стабильно/падение)
- Сигналы поддержки (открытые эскалации, время до решения)
- Сила стейкхолдеров (есть чемпион, вовлечён ли спонсор на уровне exec)
- Коммерческие факторы (ожидаемое повышение цен, сложность контракта)
- Сентимент (заметки CSM, NPS/CSAT при наличии)
Показывайте скор с точными факторами и весами для каждого аккаунта. Например:
Renewal Risk Score (0–100) =
30% Usage Trend + 25% Support Risk + 25% Stakeholder Risk + 20% Commercial Risk
Переводите скор в понятные категории (Low/Medium/High) и показывайте «почему» в одной фразе: «Usage down 18% and escalation open 12 days.»
Прогнозирование расширений: вероятность, ожидаемая стоимость, уверенность
Для каждой возможности расширения храните:
- Probability (0–100%)
- Expected value (Probability × expansion amount)
- Confidence level (High/Medium/Low) на основе доказательств (например, подтверждённый проект vs «может добавить места»)
Уверенность — это не вероятность. Это флаг доверия, который помогает лидерам понять, что подкреплено реальными сигналами.
Ручные переопределения с ответственностью
Позвольте CSM и менеджерам переопределять вероятность продления или расширения — но требуйте короткую причину (выпадающий список + свободный текст). Показывайте аудит‑трейл изменений, чтобы команда могла учиться на том, что было точным, а что — нет.
Прозрачность повышает принятие
Избегайте «мистической математики». Всегда показывайте входные данные, время последнего обновления и кто что менял. Цель — не идеальный прогноз, а последовательные, объяснимые прогнозы, которыми команда будет реально пользоваться.
Интеграции: CRM, биллинг и использование продукта
Прототипируйте очередь продлений
Создайте очередь продлений с причинами риска и следующими шагами для ежедневной итерации.
Интеграции определяют, доверяют ли прогнозу. Для MVP упростите: подключите три системы, которые «знают правду» о клиентах — CRM, платформу биллинга и источник аналитики/использования продукта.
Минимум интеграций для поддержки продлений + расширений
CRM должна отдавать аккаунты, контакты, открытые opportunities, назначение владельцев и историю стадий. Здесь живёт контекст клиента (стейкхолдеры, заметки, следующие шаги).
Billing должен быть источником дат начала/окончания контрактов, текущего ARR/MRR, плана, скидок и инвойсов. Если CRM и биллинг расходятся — доверяйте биллингу по деньгам и датам.
Product usage должен отвечать: внедряют ли продукт? Отслеживайте несколько стабильных сигналов (активные пользователи, ключевые события, количество мест vs куплено). На ранних стадиях избегайте десятков метрик — выберите 3–5, которые коррелируют с продлениями.
Синхронизация данных: webhooks сначала, расписание потом
Используйте webhooks, где доступны (обновления в CRM, оплата счёта, изменение подписки), чтобы CSM видели изменения быстро.
Для систем без надёжных webhooks выполняйте плановую синхронизацию (например, почасово для usage, один раз в сутки для истории биллинга). Показывайте статус синка в UI: «Last updated 12 min ago.»
Сопоставление идентичностей, которое можно защитить
Решите, как «клиент» определяется между инструментами:
- Предпочитайте стабильные ID (CRM Account ID ↔ Billing Customer ID)
- Используйте сопоставление по домену как запасной вариант, с ручным подтверждением
- Тщательно сопоставляйте контакты (обычно email)
Добавьте экран администратора для разрешения дубликатов и несоответствий вместо молчаливых догадок.
Проектируйте под частично доступные данные (и делайте пробелы действенными)
Системы неидеальны. Когда данные отсутствуют, не блокируйте рабочий процесс — показывайте это:
- Показывайте бейдж «Missing data» на аккаунтах (например, нет даты окончания контракта)
- Объясняйте влияние («Уверенность прогноза снижена»)
- Предлагайте путь исправления: «Link billing customer» или «Select account domain»
Если нужен референс‑реализация, держите настройку интеграций отдельно от экранов прогнозирования и ссылкуйте на неё из /settings/integrations.
Дизайн базы данных для отслеживания продлений и расширений
Приложение для продлений и расширений живёт или умирает от чистоты модели данных. Цель — не построить совершенную enterprise‑схему, а сделать прогнозы объяснимыми, изменения — отслеживаемыми, а интеграции — предсказуемыми.
Основные таблицы (минимальный набор)
Начните с небольшой, хорошо связанной «скелетной» модели:
- accounts: запись компании (владелец, сегмент, статус, день продления, таймзона)
- contacts: люди, привязанные к аккаунту (роль, влияние, email)
- contracts: коммерческие условия (план, места/единицы, биллинг‑каденс)
- renewals: предстоящее событие продления для контракта (дата, ожидаемая сумма, риск)
- opportunities: движения расширения (upsell, cross‑sell, add‑on) привязанные к аккаунту и, опционально, контракту
- activities: человеческая работа (звонки, письма, заметки) с опциональными ссылками на renewals/opportunities
- events: системные события (провал оплаты, падение использования, изменение контракта) для таймлайнов и автоматизации
Модельируйте renewals как первоклассные записи, а не просто дату окончания контракта. Это даёт место для хранения категории прогноза, причин, следующих шагов и «что изменилось с прошлой недели».
Храните деньги безопасно
Избегайте чисел с плавающей точкой для валюты. Храните суммы в минорных единицах (например, в центах) плюс код валюты. Делайте финансовые входы явными:
- list amount vs net amount
- значение скидки и тип (процент/фиксированная)
- пророция (фактор или пророцированная сумма) с явными датами начала/окончания
Это предотвращает «мистическую математику» при сверке с биллингом и делает прогнозы дохода последовательными.
Моделируйте историю для трендов
Для графиков движения прогноза добавьте таблицу forecast_snapshots (еженедельно/ежемесячно). Каждый снимок фиксирует стадию продления/возможности, ожидаемую сумму и вероятность на момент времени. Снапшоты должны быть append‑only, чтобы отчёты могли ответить «во что мы верили 1 октября?»
Тэги и кастомные поля без ломки схемы
Используйте тэги для лёгкой маркировки (many‑to‑many). Для гибких атрибутов добавьте custom_fields (определения) и custom_field_values (значения по сущности). Это позволяет командам отслеживать «причину продления» или «уровень продукта» без миграций при каждой новой метке.
Бэкенд‑сервисы и дизайн API
Сохраняйте полный контроль над кодом
Когда будете готовы, экспортируйте исходный код и продолжайте развивать проект на своих условиях.
Бэкенд — место, где данные продлений и расширений становятся согласованными, отслеживаемыми и безопасными для автоматизации. Хорошая архитектура держит UI быстрым и одновременно применяет правила, делающие прогнозы надёжными.
Основные сервисы (маленькие и сфокусированные)
Чаще всего достаточно нескольких чётких сервисов/модулей:
- Accounts service: кто клиент, владение, сегментация и ключевые даты
- Renewals service: запись продления, сумма, дата, стадия, причины риска и категория прогноза
- Opportunities service (expansion): элементы upsell/cross‑sell, сумма, стадия и ожидаемая дата закрытия
- Activities service: заметки, звонки, письма, задачи и результаты встреч, связанные с аккаунтом/продлением
- Reporting service: предварительно агрегированные метрики и экспорты для дэшбордов
Основные API‑эндпойнты
Держите эндпойнты предсказуемыми и единообразными:
GET/POST /accounts, GET/PATCH /accounts/{id}GET/POST /renewals, GET/PATCH /renewals/{id}GET/POST /opportunities, GET/PATCH /opportunities/{id}GET/POST /activities, GET /reports/forecast, GET /reports/expansion
Поддерживайте фильтрацию, соответствующую реальным рабочим процессам (владелец, диапазон дат, стадия, уровень риска), и добавьте пагинацию.
Правила и валидация (защита целостности прогноза)
Определяйте правила в бэкенде, чтобы все интеграционные и UI‑пути вели себя одинаково:
- Обязательные поля (например, дата продления, сумма, владелец, стадия)
- Переходы стадий (разрешены только определённые перемещения; сохраняется история)
- Ограничения дат закрытия (не позволять «вечное» открытие расширений; ограничивать максимальные сдвиги)
Возвращайте понятные сообщения об ошибках, чтобы пользователи знали, что исправлять.
Background jobs, на которых вы будете полагаться
Используйте асинхронные задачи для всего медленного или повторяющегося:
- CRM/billing/product‑usage sync
- Обновления скоринга здоровья и роллапы прогноза
- Уведомления (оповещения о риске, приближающиеся продления)
- Генерация отчётов для тяжёлых экспортов
Безопасность интеграций: rate limits и retries
Внешние системы падают. Ваш бэкенд должен уметь:
- Обрабатывать лимиты по каждому коннектору (ставить в очередь вызовы, делать back off автоматически)
- Повторять с idempotency‑ключами, чтобы избежать дубликатов
- Иметь dead‑letter очереди и алерты, когда синки зависают
Такая структура держит прогнозы надёжными по мере роста источников данных и команд.
Безопасность, контроль доступа и приватность данных
Безопасность — это фича продукта, а не список проверок, прикрученных позже. Прогнозы часто содержат чувствительные данные — суммы контрактов, скидки, заметки о рисках и контакты executive — поэтому нужны явные правила, кто что может видеть, и журнал изменений.
RBAC (ролевая модель доступа)
Начните с малого набора ролей, соответствующих реальной работе команд:
- CSM: управляют здоровьем, датами продлений, рисками и плейбуками; ограниченный доступ к ценовым деталям при необходимости
- Sales: видят контекст продлений, логируют возможности расширения, обновляют поля, связанные с pipeline
- Admin: управляют пользователями, правами, интеграциями и мэппингом данных
- Read‑only finance: просматривают итоги, сводки прогнозов и условия контрактов без редактирования операционных заметок
Делайте разрешения полевыми там, где важно (например, «просмотр ARR» vs «редактирование риска»), а не только экранными. Это предотвращает ситуацию, когда всем нужен admin.
Основы приватности данных, которые окупаются быстро
Применяйте принцип минимально необходимого доступа по умолчанию: новые пользователи видят только аккаунты, за которые они отвечают (или их команду), доступ расширяется намеренно.
Добавьте аудит‑логирование для ключевых действий: изменения суммы/даты продления, стадии, переопределения вероятности и обновления прав. Когда прогнозы расходятся, аудит‑лог — самый быстрый путь к разбору.
Храните секреты безопасно. API‑ключи и креды БД должны быть в управляемом хранилище секретов (не в репозитории кода или общих таблицах) и ротироваться по графику.
Мульти‑тенантность
Если приложение обслуживает несколько бизнес‑юнитов или внешних клиентов, решите заранее, нужна ли вам мульти‑тенантность. Как минимум — разделяйте данные по tenant_id и принудительно фильтруйте на уровне запросов. Даже внутренние «тенанты» (регионы, дочерние компании) выигрывают от чистого разделения и упрощённой отчётности.
Соответствие требованиям: что проверить
На раннем этапе согласуйте с безопасностью/юридическим отделом требования, которые могут применяться: SOC 2, GDPR/CCPA права субъектов данных, SSO/SAML, политики хранения и vendor risk review. Документируйте, что вы будете (и не будете) хранить — особенно свободноформатные заметки — и ссылку на это в внутренних документах (например, /security).
Уведомления, задачи и плейбуки
Уведомления полезны, когда они постоянно ведут к следующему правильному действию. Для приложения прогнозов продлений и расширений рассматривайте уведомления как «слой сигналов», а задачи/плейбуки — как «слой действий».
Оповещения, которые побуждают к действию
Фокусируйтесь на событиях, меняющих исход, а не на любых изменениях данных. Типичные триггеры:
- Приближающиеся даты продлений (90/60/30 дней)
- Рост риска (падение скорa здоровья, открытая эскалация, пропуск ключевой метрики использования)
- Застрявшие расширения (нет активности N дней, прошла дата решения)
Каждое предупреждение должно включать: аккаунт, что изменилось, почему это важно и одно‑кликовое следующее действие (создать задачу, открыть плейбук, добавить заметку).
Очереди задач, соответствующие рабочим привычкам
Вместо того чтобы заставлять людей искать аккаунты, предоставьте личную очередь задач, сортируемую по срочности и влиянию (сумма продления, уровень риска, дата закрытия). Делайте задачи простыми: владелец, срок, статус и понятное «definition of done».
Используйте задачи для мостов между системами: когда представитель помечает «звонок по продлению завершён», приложение может предложить обновить стадию в CRM или добавить заметку прогноза.
Плейбуки для повторяемых действий
Плейбуки превращают лучшие практики в чек‑листы, которыми люди реально пользуются. Примеры:
- «30‑дневный план спасения продления»: подтвердить чемпиона, проверить использование, согласовать результаты, назначить встречу с руководством
- «Discovery для расширения»: картирование стейкхолдеров, идентификация триггера, определение критериев успеха пилота
Плейбуки редактируются админами и ссылаются на внутренние страницы вроде /playbooks и /accounts/:id.
Дайджесты и управление шумом
Шлите еженедельный дайджест (email/Slack) со сводками: продления под риском, крупнейшие изменения, новые возможности расширения и просроченные задачи.
Предотвратите усталость от оповещений настройками пользователя (например, уведомлять только при росте риска на 2+ пункта), дедупликацией (группируйте похожие оповещения) и «тихими часами», чтобы уведомления приходили, когда люди могут действовать.
Отчётность и метрики, которые важны
Превратите схему в приложение
Сгенерируйте React UI с бэкендом на Go и PostgreSQL по вашим экранам и сущностям.
Приложение для продлений и расширений заслуживает доверия, когда быстро отвечает на два вопроса: «Какую выручку мы удержим?» и «Откуда придёт рост?» Слой отчётности должен быть выстроен вокруг небольшого набора совместных KPI с достаточным drill‑down, чтобы объяснить, почему цифры двигаются.
Ядро KPI (и как их читать)
Начните с метрик, по которым согласованы финансы и customer success:
- Renewal rate: % контрактов, выставленных на продление, которые были продлены
- Expansion rate: % аккаунтов (или продлений), которые увеличили ARR
- Gross retention / net retention: сохранённый доход vs сохранённый + расширение
- Forecast accuracy: отклонение между прогнозом и фактом (по месяцам/кварталам)
Убедитесь, что у каждой метрики есть ясное определение в приложении (подсказка или панель «Definitions»), чтобы команды не спорили о формулах.
Срезы, которые действительно меняют решения
Верхнеуровневый дашборд полезен, но решения принимаются в срезах. Давайте стандартные фильтры и сохранённые представления: план, регион, индустрия, уровень клиента, CSM.
Это помогает лидерам находить паттерны (например, определённый сегмент недорабатывает) и даёт менеджерам данные для коучинга вместо анекдотов.
Сводки прогноза: commit, best‑case, pipeline
Отчёт по продлениям должен складываться в три суммы — commit, best‑case и pipeline — с возможностью drill‑down до аккаунтов и строк. Цель — чтобы при клике по «commit упал на $120k» можно было увидеть точные продления, которые вызвали разницу, и заявленные причины.
Экспорты и расписанные отчёты
Финансы и руководство будут просить офлайн‑снапшоты. Поддерживайте CSV export и запланированные отчёты (email/Slack) для еженедельных продлений, ежемесячного прогноза и квартального закрытия. Включайте отметку «as of», чтобы все знали, какие данные отражены в отчёте.
Объём MVP, тестирование и план запуска
MVP для прогнозирования продлений должен доказать одно: ваша команда может видеть, что продлевается, почему это под риском и какое число фиксировать — без борьбы с инструментом. Начните с малого, выпустите и итеративно улучшайте по реальным рабочим процессам.
Объём MVP (недели 1–4)
Сфокусируйтесь на четырёх основных экранах и минимуме правил:
- Renewals list: фильтрация по диапазону дат, владельцу, уровню риска и «нуждается во внимании»
- Account view: детали контракта, ключевые контакты, последняя активность, история продлений и секция заметок/таймлайн
- Базовый скоринг: простой объяснимый скор здоровья (например, тренд использования + нагрузка поддержки + статус оплаты)
- Ручной прогноз: по каждому продлению категория прогноза (Likely / At Risk / Commit) с суммой и датой, плюс поле причины
Сделайте первую версию прощаюшей: разрешите ручные переопределения и показывайте факторы, повлиявшие на скор, чтобы CSM могли доверять или исправлять его.
Если хотите быстро прототипировать внутренний инструмент, workflow типа vibe‑coding поможет быстрее выйти на работоспособный UI и backend, чем традиционная разработка. Например, Koder.ai позволяет генерировать React‑приложение с Go‑бэкендом и PostgreSQL, описав экраны, сущности и рабочие процессы в чате — затем итерации в режиме планирования, снимков и отката. Это практичный способ проверить очереди продлений, страницы аккаунтов и аудит‑трейлы с реальными пользователями, прежде чем вкладываться в кастомную инфраструктуру.
Добавьте расширения следующим этапом (недели 5–8)
Когда продления надёжны, расширьте ту же страницу аккаунта:
- Возможности расширения: тип (места, апгрейд плана, add‑on), ожидаемая сумма, стадия и целевая дата
- Отчётность pipeline: простой вид, который складывает продления + расширения в общий прогноз выручки
План тестирования
Приоритизируйте тесты, которые не позволят «молчаливым» ошибкам в доходе:
- Unit‑тесты для скоринга: крайние случаи (отсутствие usage, отрицательные тренды, переопределения)
- Integration‑тесты для синка: импорты CRM/billing, дедупинг и идемпотентные перезапуски
- UX‑тестирование: 5–8 CSM проходят сценарии «обновить прогноз», «залогировать риск», «найти следующие действия» с таймингом
Чек‑лист перед запуском
- Миграция данных: валидация дат продления, сумм и владения аккаунтами перед go‑live
- Обучение: одна короткая сессия + одностраничный шит
- Документация: «как мы определяем категории прогноза» и «как работает скоринг»
- План итераций: еженедельный разбор несоответствий (прогноз vs факт) и небольшой бэклог улучшений по точности и удобству
При запуске предусмотрите деплой и хостинг как часть MVP — не как опцию. Независимо от того, строите вы традиционно или используете платформу вроде Koder.ai (которая может обеспечить деплой, хостинг, кастомные домены и экспорт кода), операционная цель одна: упростить доставку изменений безопасно и обеспечить постоянную доступность системы прогнозирования для команды.