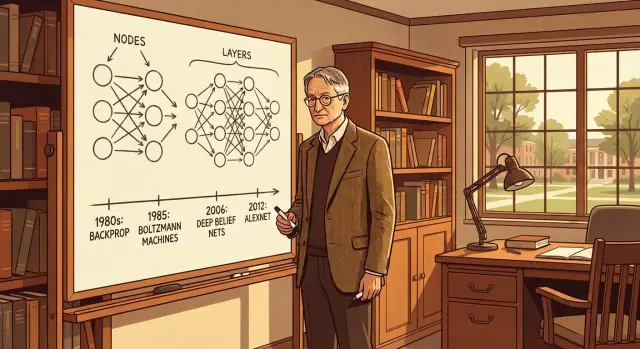
Почему Джеффри Хинтон важен
Это руководство для любознательных, не технических читателей, которые постоянно слышат, что «нейронные сети всё изменили», и хотят простого, здравого объяснения — без необходимости знать математический анализ или программирование.
Что вы узнаете
Вы получите изложение понятным языком идей, которые продвигал Джеффри Хинтон, почему они были важны в своё время и как связаны с инструментами ИИ, которые используют сейчас. Думайте об этом как о рассказе о лучших способах научить компьютеры распознавать паттерны — слова, изображения, звуки — учась на примерах.
Почему Хинтон важен (без хайпа)
Хинтон не «изобрёл ИИ», и ни один человек один не создал современное машинное обучение. Его значение в том, что он не раз помогал сделать нейронные сети рабочими на практике, когда многие считали их тупиковыми подходами. Он внес ключевые идеи, провёл важные эксперименты и сформировал культуру исследований, которая ставила в центр обучения представлений (полезных внутренних признаков) вместо ручного кодирования правил.
Краткий анонс прорывов в статье
В следующих разделах разберём:
- Обратное распространение как практический способ улучшать сеть, учась на ошибках
- Машины Больцмана и энерго-ориентированное обучение как ранний путь к изучению структуры данных
- Обучение представлений и почему «хорошие признаки» можно научиться, а не придумывать вручную
- Deep belief networks, dropout и трюки обучения, которые сделали более глубокие модели реализуемыми
- AlexNet и момент, когда нейронные сети доказали свою состоятельность в реальном масштабе
Что считать «прорывом нейронных сетей»?
В этой статье прорыв — это сдвиг, который делает нейронные сети более полезными: они надёжнее обучаются, находят лучшие признаки, лучше обобщают на новые данные или масштабируются до более сложных задач. Речь не об одном эффектном демо, а о превращении идеи в надёжный метод.
Проблема, которую пытались решить нейронные сети
Нейронные сети не были изобретены, чтобы «заменить программистов». Их первоначальная цель была точнее: создавать машины, которые могут учиться полезным внутренним представлениям из шумных реальных входов — изображений, речи и текста — без того, чтобы инженеры прописывали каждое правило вручную.
От сырых данных к смыслу
Фото — это просто миллионы значений пикселей. Запись звука — поток измерений давления. Задача — превратить эти сырые числа в понятия, которые важны людям: края, формы, фонемы, слова, объекты, намерения.
До того как нейронные сети стали практичными, многие системы опирались на вручную созданные признаки — например, детекторы краёв или дескрипторы текстуры. Это работало в узких условиях, но ломалось при изменении освещения, акцентов или при усложнении окружения.
Нейронные сети стремились решить это, автоматически обучая признаки слой за слоем из данных. Если система сама может открыть подходящие промежуточные строительные блоки, она лучше обобщает и легче адаптируется к новым задачам с меньшими затратами ручной работы.
Почему это было трудно десятилетиями
Идея привлекала, но несколько барьеров мешали долгое время:
- Вычисления: обучение требовало огромного числа вычислений. В 1980–1990‑х в большинстве лабораторий просто не было мощности для больших моделей.
- Данные: большие размеченные наборы данных, делающие обучение надёжным, появились в массовом виде лишь к 2000‑м.
- Стабильность обучения: ранние многослойные сети было трудно надёжно тренировать; прогресс зависел от алгоритмов обучения и практических приёмов, которые ещё не были зрелыми.
Упорство как стратегия
Даже когда нейронные сети были немодными — особенно в 1990‑х и начале 2000‑х — такие исследователи, как Хинтон, продолжали работать над обучением представлений. Он предлагал идеи (с середины 1980‑х) и возвращался к старым концепциям (например, энерго‑ориентированным моделям), пока железо, данные и методы не догнали теорию.
Это упорство помогло сохранить цель: машины должны учиться правильным представлениям, а не только выдавать итоговый ответ.
Обратное распространение простыми словами
Обратное распространение (часто «backprop») — метод, который позволяет нейронной сети улучшаться, учась на ошибках. Сеть делает предсказание, мы измеряем, насколько оно неверно, и затем подстраиваем внутренние «ручки» сети (веса), чтобы в следующий раз ошибаться меньше.
Обучение через исправление ошибок
Представьте сеть, которая должна подписать фото как «кот» или «собака». Она предположила «кот», а правильный ответ — «собака». Backprop берет эту финальную ошибку и идёт назад по слоям сети, выясняя, насколько каждый вес способствовал неверному ответу.
Практическая схема:
- Прямой проход: сеть делает предположение.
- Потеря: считаем ошибку (насколько промахнулась сеть).
- Обратный проход: распределяем «вину» по слоям.
- Обновление: аккуратно двигаем веса, чтобы в следующий раз ошибка была меньше.
Эти сдвиги обычно выполняют с помощью алгоритма, называемого градиентным спуском — это просто «делать маленькие шаги вниз по поверхности ошибки».
Что дал backprop
До широкого принятия backprop многослойные сети было трудно и надёжно обучать. Backprop сделал возможным тренировать более глубокие сети, потому что дал системный, повторяемый способ настроить много слоёв одновременно — вместо того, чтобы менять только финальный слой или наугад подбирать поправки.
Это важный шаг для последующих прорывов: когда можно эффективно тренировать несколько слоёв, сеть начинает учить более богатые признаки (например: края → формы → объекты).
Распространённые недоразумения
Backprop — это не «мышление» или «понимание» сети как у человека. Это математический механизм обратной связи: способ менять параметры, чтобы лучше соответствовать примерам.
И backprop — не модель сама по себе, а метод обучения, применимый к разным типам нейронных сетей.
Если хотите более мягкое углубление в структуру сетей, смотрите /blog/neural-networks-explained.
Машины Больцмана и энерго‑ориентированное обучение
Машины Больцмана были одним из ключевых шагов Хинтона к тому, чтобы нейронные сети учились полезным внутренним представлениям, а не просто выдавали ответы.
Базовая идея: «энергия» у каждой возможности
Машина Больцмана — сеть простых единиц, которые могут быть включены/выключены (или в современных вариантах принимать непрерывные значения). Вместо прямого предсказания она присваивает энергию всей конфигурации единиц. Низкая энергия означает «эта конфигурация имеет смысл».
Полезная аналогия — стол с вмятинами и долинами. Если бросить шарик, он покатится и оседает в низине. Машины Больцмана делают нечто похожее: при частичной информации (видимые единицы, заданные данными) сеть «колеблется» внутренними единицами, пока не найдёт состояния с низкой энергией — те состояния, которые она научилась считать вероятными.
Почему это важно (даже если медленно)
Классическое обучение машин Больцмана требовало многократной выборки множества состояний, чтобы оценить, чему модель верит по сравнению с данными. Эта выборка может быть крайне медленной, особенно для крупных сетей.
Тем не менее подход был влиятельным, потому что:
- формулировал обучение как формирование распределения вероятностей, а не просто подгонку меток
- продвигал необучение с учителем (unsupervised learning)
- вдохновил практические упрощения вроде contrastive divergence и более поздних энерго‑ориентированных методов
Сравнение с современными глубокими сетями
Сегодня большинство продуктов опираются на прямые (feedforward) глубокие сети, обучаемые backprop, потому что они быстрее и проще масштабируются.
Наследие машин Больцмана скорее концептуальное, чем практическое: идея, что хорошие модели учат «предпочитаемые состояния» мира, и что обучение можно видеть как перемещение вероятностной массы к низкоэнергетическим впадинам.
Обучение представлений: ключевая идея прорывов
Нейронные сети научились не только лучше аппроксимировать функции — они научились придумывать правильные признаки. Это и есть "representation learning": вместо того чтобы человек вручную создавал, что искать, модель сама учит внутренние описания, которые упрощают задачу.
Что такое «представления»
Представление — это способ модели суммировать сырое входное сообщение. Это ещё не метка типа «кот»; это полезная структура на пути к этой метке — шаблоны, которые действительно важны. Ранние слои могут реагировать на простые сигналы, а поздние слои комбинируют их в более осмысленные концепты.
Почему это изменило практику
Раньше многие системы зависели от признаков, созданных экспертами: детекторы краёв для изображений, вручную подобранные аудио‑признаки для речи, или продуманные текстовые статистики. Такие признаки работали, но часто ломались при изменении условий.
Обучение представлений позволило моделям подстраивать признаки под сами данные, что улучшило точность и сделало системы более устойчивыми в реальных условиях.
Одна идея — много применений
- Зрение: пиксели становятся всё более структурированными визуальными концептами.
- Речь: звуковые волны превращаются в фонемоподобные паттерны, затем в слова.
- Язык: токены формируют фразы, смыслы и отношения между идеями.
Общее — иерархия: простые паттерны комбинируются в более сложные.
Простой пример: края → формы → объекты
В распознавании изображений сеть сначала может научиться шаблонам, похожим на края (переход свет/тень). Затем она комбинирует края в углы и кривые, далее — части вроде колёс или глаз, и в конце — целые объекты вроде «велосипед» или «лицо». Хинтоновские идеи помогли сделать такое многослойное построение признаков практически полезным — и именно поэтому глубокое обучение начало выигрывать на реальных задачах.
Deep belief networks и путь к глубине
Запустите без лишней настройки
Разверните и разместите приложение, когда будете готовы поделиться им.
Deep belief networks (DBN) были важной промежуточной вехой на пути к тем глубоким нейронным сетям, которые мы знаем сегодня. В общем виде DBN — это стек слоёв, где каждый слой учится представлять слой ниже — от сырых входов к всё более абстрактным концептам.
Что такое DBN (в концептуальном смысле)
Представьте обучение системе распознавать рукописные цифры. Вместо того чтобы учить всё сразу, DBN сначала усваивает простые паттерны (края и штрихи), затем их комбинации (петли, углы), и в конце — более высокоуровневые формы, похожие на части цифр.
Ключевая идея: каждый слой пытается смоделировать закономерности в своём входе без подсказки правильного ответа. После обучения стека его можно дообучить (fine‑tune) для конкретной задачи.
Почему покомпонентное предварительное обучение важно
Ранние глубокие сети часто плохо обучались при случайной инициализации. Сигналы обучения могли становиться слишком слабыми или нестабильными по мере прохождения через множество слоёв, и сеть застревала в неудачных настройках.
Покомпонентное предварительное обучение давало модели «тёплый старт»: каждый слой начинал с разумного понимания структуры данных, и полная сеть не искала решения вслепую.
Как это сделало глубину практичной
Предварительное обучение не решало все проблемы моментально, но делало глубину реализуемой в эпоху, когда данных, вычислительной мощности и обучающих приёмов было меньше, чем сейчас.
DBN показали, что обучение полезных представлений по нескольким слоям работает и что глубина — это не только теория, но и практический путь вперед.
Dropout и борьба с переобучением
Нейронные сети могут «зубрить» данные: запомнить обучающую выборку, а не понять закономерности. Это называется переобучением — модель отлично работает на знакомых примерах, но плохо на новых.
Переобучение на примере из жизни
Представьте, что вы готовитесь к вождению, заучивая точный маршрут инструктора: каждый поворот, каждая яма. Если экзамен пройдёт по тому же маршруту, вы справитесь. Но при изменении маршрута ваши навыки упадут, потому что вы не научились водить в общем, а выучили конкретный сценарий.
Dropout: простая идея, которая работает
Dropout — трюк, популяризированный Хинтоном и соавторами. В процессе обучения сеть случайно «выключает» часть своих единиц на каждом проходе по данным.
Это заставляет модель не полагаться на единую дорожку передачи информации, а распределять знания по множеству связей. Ментальная аналогия: вы готовитесь, но иногда теряете доступ к случайным страницам конспекта — вас вынуждают понять идею, а не запомнить одну формулировку.
Что улучшил dropout
Главный эффект — лучшее обобщение: модель становится надёжнее на данных, которых ранее не видела. На практике dropout позволил безопаснее увеличивать размер сетей, не давая им полностью уйти в запоминание, и стал стандартным инструментом в глубоких архитектурах.
AlexNet: момент, когда глубокое обучение вышло в мейнстрим
От спецификации к ПО
Опишите продукт на естественном языке — и Koder.ai превратит это в приложение.
Почему бенчмарки по изображениям важны
До AlexNet «распознавание изображений» было не просто красивым демо — это была измеримая задача. Бенчмарки вроде ImageNet задавали вопрос: может ли система по фото назвать, что на нём изображено?
Суть в масштабе: миллионы изображений и тысячи категорий. Такой объём отделял методы, работавшие в мелких экспериментах, от тех, что держались в реальных условиях.
Результаты обычно росли постепенно. Затем пришёл AlexNet (Алекс Кризевский, Илья Сутскевер и Джеффри Хинтон) и дал скачок, который почувствовался как качественный рубеж.
Что показал AlexNet
AlexNet продемонстрировал, что глубокая сверточная сеть может превзойти лучшие традиционные конвейеры компьютерного зрения, когда совпадают три ингредиента:
- Свертки (слои, использующие структуру изображений)
- GPU (для обучения большой модели в разумное время)
- Большие размеченные данные (масштаб ImageNet)
Это был практический рецепт обучения глубоких сетей на реальных задачах.
Свертки, объяснённые без математики
Представьте, что выдвигаете маленькое окошко по фотографии, как почтовую марку. Внутри окна сеть ищет простой паттерн: край, угол или полосу. Этот же «проверяльщик паттернов» используется по всему изображению, поэтому он найдёт «подобное» независимо от позиции.
Накопите такие слои — и получите иерархию: края → текстуры → части → объекты.
Почему это переключило внимание индустрии
AlexNet показал, что глубокое обучение надёжно работает на сложных публичных бенчмарках. Значит, оно может улучшать продукты — поиск, автотегирование фото, функции камер, инструменты доступности и многое другое. Это перевело нейронные сети из «перспективных исследований» в очевидное направление для коммерческих команд.
Что изменилось: данные, вычисления и практичное обучение
Глубокое обучение не появилось из ниоткуда. Оно стало выглядеть драматично, когда несколько ингредиентов наконец сошлись — после многих лет работы, показывающей потенциал, но трудности масштабирования.
Три фактора, которые всё запустили
Больше данных. Веб, смартфоны и крупные размеченные наборы (ImageNet) позволили учиться на миллионах примеров вместо тысяч. При малых данных большие модели склонны к запоминанию.
Больше вычислений (особенно GPU). Обучение глубоких сетей — это повторение одних и тех же матожиданий миллиарды раз. GPU сделали это достаточно быстрым и доступным, чтобы можно было итеративно экспериментировать.
Лучшие приёмы тренировки. Практические улучшения снизили случайность «обучается/не обучается»:
- лучшая инициализация и оптимизация
- нормализация и аккуратные пайплайны ввода
- регуляризация вроде dropout
- улучшенные функции активации и архитектурные шаблоны
Ни одно из этих изменений не изменило основную идею нейронных сетей — они повысили надёжность их обучения.
Почему прогресс казался внезапным
Как только данные и вычисления достигли порога, улучшения начали складываться: лучшие результаты привлекали инвестиции, которые давали больше данных и мощностей, что позволяло получить ещё лучшие результаты. Со стороны это выглядело как резкий скачок; изнутри — как компаундирование улучшений.
Компромиссы: большие модели — большие затраты
Масштабирование приносит реальные издержки: больше энергии, более дорогие тренировки и сложность развёртывания. Это увеличивает разрыв между экспериментами маленьких команд и тренировками, доступными лишь ресурсам крупных лабораторий.
Как эти идеи проявляются в привычных продуктах
Ключевые идеи Хинтона — учить полезные представления, надёжно тренировать глубокие сети и бороться с переобучением — не "функции", которые можно ткнуть в приложении. Это фундамент того, почему многие повседневные функции стали быстрее, точнее и менее раздражающими.
Поиск и рекомендации
Современные системы поиска не просто сопоставляют ключевые слова. Они учат представления запросов и контента, поэтому «лучшие наушники с шумоподавлением» могут показать страницы, где не повторяется точная фраза. То же обучение представлений помогает рекомендательным лентам понимать, что два товара «похоже» даже при разных описаниях.
Перевод и текстовые инструменты
Машинный перевод резко улучшился, когда модели научились многослойным паттернам (от символов к словам к смыслу). Даже если тип модели эволюционировал, методы обучения — большие данные, аккуратная оптимизация и регуляризация — остаются ключевыми.
Голос и распознавание речи
Голосовые ассистенты и диктовка полагаются на сети, которые переводят шумный аудио‑поток в текст. Обратное распространение — это "рабочая лошадка", которая настраивает такие модели, а приёмы вроде dropout помогают не заучивать особенности одного диктора или микрофона.
Фото: автотегирование, группировка и поиск по изображению
Фото‑приложения могут распознавать лица, группировать похожие сцены и искать «пляж» без ручной разметки. Это обучение представлений в действии: система учит визуальные признаки (края → текстуры → объекты), что делает теги и поиск масштабируемыми.
Где команды всё ещё применяют эти идеи
Даже если вы не тренируете модели с нуля, принципы проявляются в работе с продуктом: начните с хороших представлений (часто — pretrained моделей), стабилизируйте обучение и оценку, используйте регуляризацию, когда система начинает запоминать тестовые наборы.
Именно поэтому современные инструменты «vibe‑coding» кажутся такими эффективными. Платформы вроде Koder.ai работают поверх современных LLM и агентных рабочих процессов, помогая командам превращать тексты на естественном языке в рабочие веб‑, бэкенд‑ или мобильные приложения быстрее, чем традиционные пайплайны, при этом давая возможность экспортировать исходный код и развёртывать как обычная инженерная команда.
Если хотите интуитивное руководство по тренировке, смотрите /blog/backpropagation-explained.
Распространённые мифы о Хинтоне и нейронных сетях
Итерации с подстраховкой
Создавайте снимки и безопасно откатывайтесь при экспериментах с изменениями.
Крупные прорывы часто упрощают до запоминающихся историй — но это создаёт мифы, которые скрывают настоящую суть событий.
Миф: «Один человек изобрёл современный ИИ»
Хинтон — ключевая фигура, но современное глубокое обучение — результат десятилетий работы многих групп: исследователей оптимизации, создателей наборов данных, инженеров, сделавших GPU практичными, и команд, доказавших идеи в масштабе. Внутри «работ Хинтона» его студенты и соавторы сыграли огромную роль. Реальная история — цепочка вкладов, которые сошлись во времени.
Миф: «Нейронные сети — это нечто новое»
Нейронные сети изучаются с середины XX века, с волнами энтузиазма и разочарований. Изменилось не само существование идеи, а способность надёжно тренировать большие модели и показывать явные выигрыши на реальных задачах. Эпоха "deep learning" — скорее возрождение, чем внезапное изобретение.
Миф: «Больше слоёв всегда лучше»
Более глубокие модели могут помочь, но это не магия. Время обучения, стоимость, качество данных и убывающая отдача — реальные ограничения. Иногда меньшая модель побеждает, потому что её легче настроить, она устойчивее к шуму или лучше соответствует задаче.
Миф: «Backprop — это как человеческое обучение»
Backprop — практический способ корректировать параметры по ошибкам с метками. Люди учатся на куда меньшем числе примеров, используют богатые априорные знания и не полагаются на такие же сигналы ошибки. Нейронные сети могут быть вдохновлены биологией, но не являются точной копией мозга.
Выводы и практические уроки
История Хинтона — не просто набор изобретений. Это паттерн: сохранять простую идею обучения, тестировать её настойчиво и обновлять сопутствующие ингредиенты (данные, вычисления, приёмы обучения), пока она не заработает в масштабе.
Что сегодняшним разработчикам стоит перенять
Самые полезные привычки практичны:
- Итерации короткими циклами. Каждому прогону относитесь как к небольшому эксперименту: изменили одну вещь, зафиксировали результат, повторили.
- Измеряйте важное. Отслеживайте чёткую метрику (точность, ошибка, задержка, стоимость запроса) и сравнивайте с базой. «Лучше» должно измеряться.
- Упрощайте объяснения. Если вы не можете объяснить цель системы, входы и режимы отказа нетехническому коллеге, скорее всего вы не готовы безопасно выпускать продукт.
Что не стоит копировать
Соблазн — думать, что «большие модели всегда лучше». Это неполный вывод.
Погоня за размером без ясной цели часто приводит к:
- росту затрат без видимых улучшений для пользователей
- усложнению отладки при ошибках
- оптимизации бенчмарков в ущерб продуктовым целям
Лучший подход: начните с малого, докажите ценность, затем масштабируйте — и масштабируйте только то, что действительно ограничивает производительность.
Куда дальше читать
Если хотите применять уроки в работе, полезны следующие материалы:
- /blog/ai-model-evaluation
- /blog/how-to-reduce-overfitting
- /blog/representation-learning-explained
Главная сюжетная линия для запоминания
От правила обучения через backprop, к представлениям, которые захватывают смысл, к практическим приёмам вроде dropout и демонстрации масштаба в AlexNet — арка последовательна: учите полезные признаки из данных, стабильно тренируйте модели и проверяйте прогресс на реальных результатах.
Именно такой подход стоит сохранить.