10 июл. 2025 г.·7 мин
Простые шаблоны очереди фоновых задач для писем и вебхуков
Простые паттерны очереди фоновых задач для отправки писем, генерации отчётов и доставки webhook с повторами, backoff и dead-letter, без тяжёлой инфраструктуры.
Простые паттерны очереди фоновых задач для отправки писем, генерации отчётов и доставки webhook с повторами, backoff и dead-letter, без тяжёлой инфраструктуры.
Любая работа, которая может занять больше секунды-двух, не должна выполняться внутри пользовательского запроса. Отправка писем, генерация отчётов и доставка webhook зависят от сети, внешних сервисов или медленных запросов. Иногда они приостанавливаются, падают или просто занимают больше времени, чем вы ожидаете.
Если выполнять такую работу пока пользователь ждёт, люди заметят это сразу. Страницы зависают, кнопки «Сохранить» крутятся, а запросы таймаутятся. Повторы могут происходить в неправильном месте: пользователь обновляет страницу, балансировщик нагрузки повторяет запрос, или фронтенд повторно отправляет форму — и в итоге вы получаете дублирующие письма, повторные вызовы webhook или два параллельных прогона отчёта.
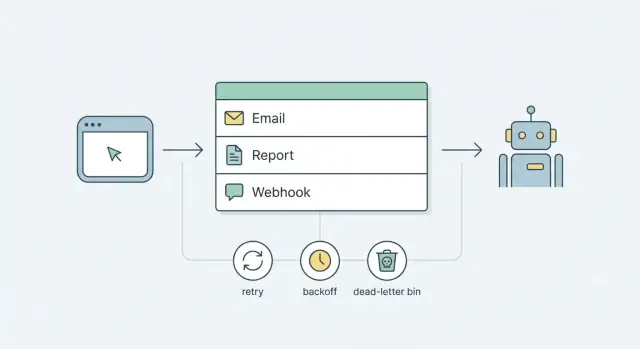
Фоновые задачи решают это, делая запросы маленькими и предсказуемыми: принять действие, записать задачу для выполнения позже, ответить быстро. Задача выполняется вне запроса, по правилам, которые вы контролируете.
Сложность — в надёжности. Когда работа выходит из пути запроса, всё равно нужно отвечать на вопросы вроде:
Многие команды отвечают «тяжёлой инфраструктурой»: брокер сообщений, отдельные пулы воркеров, дашборды, алерты и playbook'и. Эти инструменты полезны, когда они действительно нужны, но они добавляют новые движущиеся части и новые точки отказа.
Лучше стартовать с более простой цели: надёжные задачи с использованием уже имеющихся частей. Для большинства продуктов это значит очередь на базе базы данных плюс небольшой процесс-воркер. Добавьте ясную стратегию повторов и backoff и паттерн dead-letter для задач, которые постоянно падают. Вы получите предсказуемое поведение без привязки к сложной платформе с первого дня.
Даже если вы быстро разрабатываете с помощью чат-инструмента вроде Koder.ai, такое разделение всё равно важно. Пользователь должен получить быстрый ответ сейчас, а медленная, склонная к ошибкам работа должна безопасно завершиться в фоне.
Очередь — это линия ожидания для работы. Вместо того чтобы делать медленные или ненадёжные задачи в рамках пользовательского запроса (отправить письмо, собрать отчёт, вызвать webhook), вы создаёте небольшую запись в очереди и возвращаете ответ быстро. Позже отдельный процесс подхватывает эту запись и выполняет работу.
Несколько терминов, которые вы часто встретите:
Простейший поток выглядит так:
Enqueue: приложение сохраняет запись задания (тип, payload, время запуска).
Claim: воркер находит следующую доступную задачу и «блокирует» её, чтобы только один воркер её выполнял.
Run: воркер выполняет задачу (отправляет, генерирует, доставляет).
Finish: пометить как выполнено или записать ошибку и установить следующее время запуска.
Если объём задач умеренный и у вас уже есть база данных, очередь на базе БД часто вполне достаточна. Она понятна, её легко отлаживать и она покрывает типичные потребности вроде обработки писем и надёжной доставки webhook.
Стриминговые платформы начинают иметь смысл, когда нужен очень высокий throughput, много независимых потребителей или возможность воспроизведения больших историй событий по многим системам. Если у вас десятки сервисов и миллионы событий в час, инструменты вроде Kafka помогают. До этого момента таблица в базе плюс цикл воркера покрывают большинство реальных случаев.
Очередь на базе БД остаётся адекватной, пока у каждой записи есть быстрые ответы на три вопроса: что делать, когда пробовать снова и что случилось в прошлый раз. Сделайте это правильно — и эксплуатация станет скучной (а это хорошо).
Храните минимальный набор входных данных, нужных для выполнения работы, а не весь отрендеренный результат. Хорошие payload'ы — это ID и пара параметров, например { "user_id": 42, "template": "welcome" }.
Избегайте больших blob'ов (полных HTML-писем, больших данных отчётов, огромных тел webhook). Это быстро раздувает базу и усложняет отладку. Если задаче нужен большой документ, храните ссылку: report_id, export_id или ключ файла. Воркера может получить полный контент при выполнении.
Минимум:
job_type выбирает обработчик (send_email, generate_report, deliver_webhook). payload содержит небольшие входные данные типа ID и опций.queued, running, succeeded, failed, dead).attempt_count и max_attempts, чтобы перестать повторять, когда это бессмысленно.created_at и next_run_at (когда задача становится доступной). Добавьте started_at и finished_at для лучшей видимости медленных задач.idempotency_key, чтобы предотвратить повторные последствия, и last_error, чтобы увидеть причину неудачи без копания в логах.Идемпотентность звучит сложно, но идея простая: если та же задача запущена дважды, второй прогон должен обнаружить это и ничего опасного не сделать. Например, задача доставки webhook может использовать ключ типа webhook:order:123:event:paid, чтобы не доставлять одно и то же событие дважды при перекрывающемся повторе.
Также соберите несколько простых метрик. Не нужен большой дашборд: достаточно запросов, которые отвечают на вопросы — сколько задач в очереди, сколько падает и какой возраст самой старой задачи.
Если у вас уже есть база данных, можно начать без новой инфраструктуры. Задачи — это строки, воркер — процесс, который постоянно выбирает просроченные строки и выполняет работу.
Держите таблицу простой и предсказуемой. Достаточно полей для запуска, повторов и отладки позже.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Если вы используете Postgres (часто с бэкендом на Go), jsonb — практичный способ хранить данные задания вроде { "user_id":123,"template":"welcome" }.
Когда действие пользователя должно порождать задачу (отправить письмо, вызвать webhook), записывайте строку задания в той же транзакции, где делаете основное изменение, если это возможно. Это предотвращает состояние «пользователь создан, но задача не создана», если процесс упадёт сразу после основного записи.
Например: при регистрации пользователя вставляйте строку пользователя и задачу send_welcome_email в одной транзакции.
Воркеры повторяют цикл: найти одну доступную задачу, захватить её, обработать и пометить как выполненную или запланировать повтор.
На практике это значит:
status='queued' и next_run_at <= now().SELECT ... FOR UPDATE SKIP LOCKED).status='running', locked_at=now(), locked_by='worker-1'.done/succeeded), или записать last_error и спланировать следующую попытку.Несколько воркеров могут работать одновременно. Шаг захвата предотвращает двойной выбор.
При выключении перестаньте брать новые задачи, завершите текущую и выйдите. Если процесс умер во время выполнения, используйте простое правило: задачи, которые в состоянии running дольше заданного таймаута, считаются снова доступными для переочередки периодической задачей‑reaper.
Если вы строите на Koder.ai, этот паттерн очереди на базе БД — хороший универсальный выбор для писем, отчётов и webhook до того, как появится необходимость в специализированных службах.
Повторы — способ сделать очередь спокойной, когда внешний мир шумен. Без ясных правил повторы превращаются в шум, который спамит пользователей, давит на API и скрывает реальную ошибку.
Начните с решения, что стоит повторять, а что — проваливать сразу.
Повторяйте при временных проблемах: сетевые таймауты, 502/503, rate limit или кратковременные ошибки базы данных.
Проваливайте сразу, когда задача вряд ли выполнится: отсутствующий адрес электронной почты, 400 от webhook из‑за неверного payload, или запрос отчёта для удалённого аккаунта.
Backoff — это пауза между попытками. Линейный backoff (5с, 10с, 15с) прост, но всё ещё может создавать волны трафика. Экспоненциальный backoff (5с, 10с, 20с, 40с) распределяет нагрузку лучше и обычно безопаснее для webhook и внешних провайдеров. Добавьте jitter (небольшая случайная задержка), чтобы тысяча задач не попыталась повториться в одну и ту же секунду после сбоя.
Правила, которые обычно хорошо себя ведут в бою:
Максимум попыток ограничивает вред. Для многих команд 5–8 попыток достаточно. После этого — перемещайте задачу в dead-letter для ручного разбора вместо бесконечного цикла.
Таймауты предотвращают «зомби»-задачи. Для писем обычно 10–20 секунд на попытку. Для webhook чаще короче, например 5–10 секунд, потому что при недоступности приёмника хочется перейти к другим задачам. Генерация отчётов может допускать минуты, но всё равно должна иметь жёсткий лимит.
Если вы реализуете это в Koder.ai, относитесь к should_retry, next_run_at и идемпотентному ключу как к важным полям. Эти мелочи сохраняют систему спокойной при проблемах.
Состояние dead-letter — место для задач, когда повторы больше не безопасны или бесполезны. Это превращает молчаливую ошибку в то, что можно увидеть, искать и исправлять.
Сохраняйте достаточно, чтобы понять, что произошло, и при необходимости воспроизвести задачу, но аккуратно с секретами.
Храните:
Если payload содержит токены или персональные данные, редактируйте или шифруйте их перед хранением.
Когда задача попадает в dead-letter, принимайте быстрое решение: повторить, исправить или игнорировать.
Ручная повторная постановка безопаснее, когда создаётся новое задание, а старое остаётся неизменным. Пометьте dead-letter задачу тем, кто её повторно поставил, когда и почему, и затем добавьте новое задание с новым ID.
Для алертинга следите за сигналами, которые обычно означают реальные проблемы: быстро растущее число dead-letter задач, одинаковая ошибка по многим задачам и старые задачи в очереди, которые никто не берёт.
Если вы используете Koder.ai, snapshots и откаты помогают, когда плохой релиз резко увеличивает число ошибок, — можно быстро откатиться и расследовать.
Наконец, добавьте предохранители для провайдеров: лимит отправок по провайдеру и circuit breaker — если endpoint webhook сильно падает, приостаньте новые попытки на короткое окно, чтобы не топить их (и свои) сервера.
Очередь лучше всего работает, когда для каждого типа задания есть ясные правила: что считается успехом, что стоит повторять и что ни в коем случае не должно выполняться дважды.
Письма. Большинство сбоев с почтой временные: таймауты провайдера, rate limits или кратковременные падения. Обращайтесь с ними как с повторяемыми — с backoff. Главный риск — дублирующие отправки, поэтому делайте email‑задачи идемпотентными. Храните стабильный ключ дедупа, например user_id + template + event_id, и отказывайтесь от отправки, если этот ключ уже помечен как отправленный.
Стоит также хранить имя шаблона и версию (или хеш отрендеренного subject/body). Если придётся перезапустить задачу, можно выбрать — отправлять тот же контент или перегенерировать по последнему шаблону. Если провайдер вернул message ID, сохраните его для поддержки.
Отчёты. Ошибки отчётов другие. Они могут выполняться минуты, натыкаться на ограничения пагинации или заканчиваться по памяти, если всё делать за один проход. Разбивайте работу на куски. Общий паттерн: один job "report request" создаёт много job'ов "page" или "chunk", каждый обрабатывает свою часть данных.
Храните результаты для последующей загрузки, а не держите пользователя в ожидании. Это может быть таблица в базе, привязанная к report_run_id, или ссылка на файл с метаданными (status, row count, created_at). Добавьте поля прогресса, чтобы UI мог показывать "processing" vs "ready" без догадок.
Webhooks. Webhook — это про надёжную доставку, а не скорость. Подписывайте каждый запрос (например, HMAC с общим секретом) и добавляйте метку времени, чтобы предотвратить повторную отправку. Повторять только когда приёмник может восстановиться.
Простые правила:
Порядок и приоритет. Большинство задач не требуют строгого глобального порядка. Когда порядок важен, обычно он важен по ключу (по пользователю, счёту, endpoint'у webhook). Добавьте group_key и не запускайте параллельно больше одной задачи для ключа.
Для приоритета отделяйте срочное от медленного. Большая очередь отчётов не должна задерживать письма для сброса пароля.
Пример: после покупки вы ставите в очередь (1) письмо с подтверждением заказа, (2) webhook партнёру и (3) обновление отчёта. Письмо ретраится быстро, webhook — дольше с backoff, отчёт запускается позже с низким приоритетом.
Пользователь регистрируется в приложении. Нужно сделать три вещи, но ни одна из них не должна замедлять страницу регистрации: отправить приветственное письмо, уведомить CRM через webhook и включить пользователя в ночной отчёт активности.
Сразу после создания записи пользователя запишите три строки в таблицу очереди. Каждая строка содержит тип, payload (например, user_id), статус, счётчик попыток и next_run_at.
Типичный жизненный цикл:
queued: создана и ждёт воркераrunning: воркер захватил и выполняетsucceeded: выполнено, работы больше нетfailed: упало, запланировано или исчерпаны попыткиdead: слишком много ошибок, нужна ручная проверкаЗадача приветственного письма содержит идемпотентный ключ вроде welcome_email:user:123. Перед отправкой воркер проверяет таблицу выполненных идемпотентных ключей (или уникальное ограничение). Если задача выполнится второй раз из‑за краша, второй прогон увидит ключ и пропустит отправку — никаких двойных писем.
CRM endpoint упал. Задача webhook умирает с таймаутом. Воркеры планируют повторы с backoff (например: 1 мин, 5 мин, 30 мин, 2 часа) плюс небольшой jitter, чтобы многие задачи не повторились одновременно.
После исчерпания попыток задача становится dead. Пользователь всё равно зарегистрирован, получил приветственное письмо, ночной отчёт может выполниться как обычно. Застрявшее уведомление в CRM видно отдельно.
Утром support или ответственный человек делают простые шаги:
webhook.crm).Если вы строите приложения на платформе вроде Koder.ai, тот же паттерн применим: держите пользовательский поток быстрым, выносите сайд‑эффекты в задания и делайте ошибки легко наблюдаемыми и перезапускаемыми.
Самый быстрый путь сломать очередь — считать её опцией. Команды часто начинают с "в этот один раз отправлю письмо в запросе", потому что так проще. Потом это распространяется: сброс пароля, квитанции, webhook, экспорт отчётов. Приложение медлеет, таймауты растут, и любой сбой внешнего сервиса становится вашей проблемой.
Другой распространённый промах — пропуск идемпотентности. Если задача может выполниться дважды, она не должна давать два результата. Без идемпотентности повторы превращаются в дубли писем, повторные события webhook и хуже.
Третья проблема — видимость. Если вы узнаёте о падениях только из тикетов поддержки, очередь уже вредит пользователям. Даже простое внутреннее представление с счётчиками задач по статусу и поиском по last_error экономит часы.
Несколько проблем проявляются рано, даже в простых очередях:
Backoff предотвращает самодельные аварии. Даже базовый график вроде 1 мин, 5 мин, 30 мин, 2 часа делает падения безопаснее. Также ставьте лимит попыток, чтобы поломанная задача останавливалась и становилась видимой.
Если вы строите на платформе вроде Koder.ai, полезно сразу внедрить эти базовые подходы вместе с функционалом, а не откладывать на потом.
Прежде чем добавлять новые инструменты, убедитесь, что базовые вещи на месте. Очередь на базе БД работает хорошо, когда каждую задачу легко захватить, повторить и просмотреть.
Короткий чек‑лист надёжности:
Дальше выберите первые три типа задач и пропишите для них правила. Пример: письмо для сброса пароля (быстрые повторы, короткий максимум), ночной отчёт (мало попыток, большие таймауты), доставка webhook (больше попыток, длинный backoff, останов на постоянный 4xx).
Если не уверены, когда очередь на базе БД перестаёт быть достаточной, следите за сигналами: блокировки на уровне строк при большом числе воркеров, строгий порядок между многими типами задач, большой fan‑out (событие порождает тысячи задач) или потребление событий разными сервисами.
Если хотите быстрый прототип, можно накидать поток в Koder.ai (koder.ai) в режиме планирования, сгенерировать таблицу jobs и цикл воркера, и итеративно проверять с помощью snapshots и rollback перед деплоем.
Если задача может занять больше секунды-двух или зависит от сетевого вызова (поставщик почты, конечная точка webhook, медленный запрос), перемещайте её в фоновую задачу.
Держите запрос пользователя простым: проверка входных данных, запись основного изменения в базу, добавление записи в очередь и быстрый ответ.
Начните с очереди на базе базы данных, когда:
Добавляйте брокер/стриминговый инструмент позже, когда понадобятся очень высокий пропуск или независимые потребители и возможность воспроизводить события между сервисами.
Отслеживайте минимум, чтобы ответить на вопросы: что делать, когда пробовать снова и что случилось в последний раз.
Практический минимум:
Храните входные данные, а не большие выходы.
Хорошие полезные данные:
user_id, template, report_id)Избегайте:
Ключевой шаг — атомарная операция «захвата», чтобы два воркера не взяли одно и то же задание.
Обычно в Postgres это делается так:
FOR UPDATE SKIP LOCKED)running и записывают locked_at/locked_byТогда воркеры масштабируются горизонтально без двойной обработки одной строки.
Предполагая, что задача может выполниться дважды (при краше, таймауте, повторной отправке), сделайте побочный эффект безопасным.
Простые паттерны:
idempotency_key, например welcome_email:user:123Это особенно важно для писем и webhook, чтобы избежать дублирования.
Используйте ясную и простую политику по умолчанию:
Быстро проваливать при постоянных ошибках (отсутствие адреса, неверный payload, большинство 4xx для webhook).
Dead-letter — это состояние «перестать повторять и сделать видимым». Используйте его, когда:
max_attemptsХраните достаточно контекста:
Решайте «зависшие running» задачи двумя правилами:
running задачи старше порога и переотправляет их (или помечает как failed)Это позволяет восстанавливаться после крашей воркеров без ручной чистки.
Разделяйте, чтобы медленная работа не блокировала срочные задачи:
Если важен порядок, он обычно локален (по пользователю, по webhook-эндпоинту). Добавьте group_key и разрешайте только одну выполняемую задачу на ключ, чтобы сохранять локальный порядок без глобального упорядочивания.
job_type, payloadstatus (queued, running, succeeded, failed, dead)attempts, max_attemptsnext_run_at, плюс created_atlocked_at, locked_bylast_erroridempotency_key (или другой механизм дедупа)Если задаче нужны большие данные, храните ссылку (например, report_run_id или ключ файла) и получайте содержимое при запуске воркера.
last_error и последний код статуса (для webhook)При повторном запуске создавайте новое задание, оставляя dead-letter неизменным.