02 сент. 2025 г.·5 мин
Protobuf против JSON для API: скорость, размер и совместимость
Сравнение Protobuf и JSON для API: размер полезной нагрузки, скорость, читаемость, инструменты, эволюция схем и когда каждый формат подходит лучше в реальных продуктах.
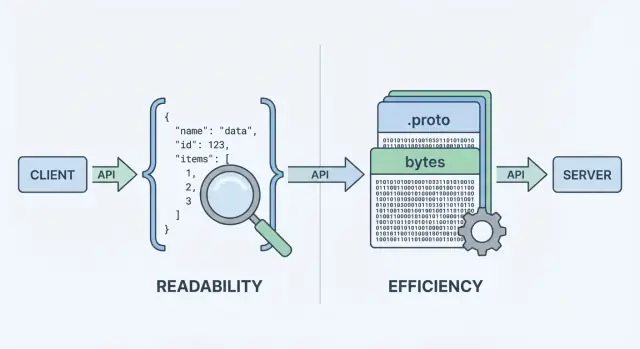
Что такое Protobuf и JSON (и почему это важно)
Когда ваш API отправляет или получает данные, ему нужен формат данных — стандартизированный способ представления информации в телах запросов и ответов. Этот формат затем сериализуется (превращается в байты) для передачи по сети и десериализуется обратно в объекты на клиенте и сервере.
Два из самых распространённых вариантов — JSON и Protocol Buffers (Protobuf). Они могут представлять одни и те же бизнес-данные (пользователи, заказы, временные метки, списки элементов), но делают разные компромиссы по производительности, размеру полезной нагрузки и рабочему процессу разработчика.
JSON: читаемый текст
JSON (JavaScript Object Notation) — текстовый формат, построенный из простых структур: объектов и массивов. Он популярен для REST API, потому что его легко читать, логировать и просматривать с помощью curl и DevTools браузера.
Одна из причин, почему JSON везде: большинство языков имеют отличную поддержку, и ответ можно визуально просмотреть и сразу понять.
Protobuf: компактный бинарный формат со схемой
Protobuf — бинарный формат сериализации, созданный Google. Вместо текста он передаёт компактное бинарное представление, определённое схемой (.proto). Схема описывает поля, их типы и числовые теги.
Благодаря бинарной природе и схеме Protobuf обычно даёт меньшие полезные нагрузки и может быть быстрее при разборе — это важно при больших объёмах запросов, мобильных сетях или сервисах с чувствительностью к задержкам (часто в gRPC, но не только).
Те же данные, другие компромиссы
Важно отличать что вы отправляете от как это кодируется. «Пользователь» с id, именем и электронной почтой можно смоделировать и в JSON, и в Protobuf. Разница — в цене, которую вы платите по:
- Размеру полезной нагрузки (текст против компактного бинарного представления)
- Времени CPU на сериализацию/десериализацию
- Отладке и наблюдаемости (читаемые логи против бинарных утилит)
- Совместимости и эволюции (неформальные соглашения JSON против принудительных схем)
Нет универсального ответа. Для многих публичных API JSON остаётся дефолтом из‑за доступности и гибкости. Для внутренних сервисов, чувствительных к производительности, или когда необходимы строгие контракты — Protobuf может быть лучшим выбором. Цель этого руководства — помочь выбрать по ограничениям, а не по идеологии.
Как данные API сериализуются и передаются
Когда API возвращает данные, он не может отправить «объекты» напрямую по сети. Их нужно сначала превратить в поток байтов. Это — сериализация — подумайте об этом как о упаковке данных в транспортируемую форму. На другой стороне клиент делает обратное (десериализацию), распаковывая байты обратно в структуры данных.
Короткий путь от сервера до клиента
Типичный поток запроса/ответа выглядит так:
- Сервер формирует ответ в своих типах в памяти (объекты/структуры/классы).
- Сериализатор кодирует этот ответ в полезную нагрузку (JSON‑текст или Protobuf‑бинар).
- Полезная нагрузка отправляется по HTTP/1.1, HTTP/2 или HTTP/3 в виде байтов.
- Клиент получает байты и декодирует их в свои типы в памяти.
Именно «шаг кодирования» определяет, какой формат важен. JSON‑кодирование даёт читаемый текст вроде {\"id\":123,\"name\":\"Ava\"} внутри curl‑вывода, а Protobuf генерирует компактные бинарные байты, непонятные человеку без инструментов.
Почему формат меняет производительность и рабочие процессы
Потому что каждый ответ нужно упаковать и распаковать, формат влияет на:
- Пропускную способность (размер полезной нагрузки): меньшие полезные нагрузки снижают затраты на передачу, что важно в мобильных сетях и при большом трафике.
- Задержку: меньше данных для передачи может дать более быстрые ответы; более быстрые кодирование/декодирование уменьшает CPU‑латентность.
- Рабочий процесс разработчика: JSON легко смотреть в DevTools и логах; для Protobuf обычно нужны сгенерированные типы и специфичное декодирование.
Стиль API может склонить выбор
Ваш стиль API часто подталкивает выбор:
- REST‑стиль JSON API обычно используют JSON из‑за широкой поддержки, простоты тестирования с
curlи лёгкости логирования. - gRPC по умолчанию строится вокруг Protobuf: HTTP/2 и генерация кода хорошо сочетаются с типизированными Protobuf‑сообщениями.
Вы можете использовать JSON с gRPC (через транс‑кодирование) или брать Protobuf поверх обычного HTTP, но дефолтная эргономика стека — фреймворков, шлюзов, клиентских библиотек и привычек отладки — часто определяет, что проще поддерживать в повседневной работе.
Размеры полезной нагрузки и скорость: что обычно выигрываете или теряете
Когда люди сравнивают protobuf vs json, они обычно смотрят на два показателя: насколько велика полезная нагрузка и сколько времени занимает кодирование/декодирование. Суть проста: JSON — текст и обычно многословен; Protobuf — бинарный и компактнее.
Размер полезной нагрузки: компактный бинар против читаемого текста
JSON повторяет имена полей и использует текстовое представление чисел, boolean и структуры, поэтому часто передаёт больше байтов. Protobuf заменяет имена полей числовыми тегами и упаковывает значения эффективно, поэтому обычно даёт заметно меньшие полезные нагрузки — особенно для больших объектов, повторяющихся полей и глубоко вложенных структур.
Тем не менее сжатие сокращает разрыв: с gzip или brotli повторяющиеся ключи JSON очень хорошо сжимаются, так что разница между JSON и Protobuf в реальных развертываниях может уменьшиться. Protobuf тоже можно сжимать, но относительный выигрыш часто меньше.
Затраты CPU: разбор текста против декодирования бинарного
Парсеры JSON должны токенизировать и валидировать текст, преобразовывать строки в числа и учитывать краевые случаи (экранирование, пробелы, unicode). Декодирование Protobuf более прямолинейно: читать тег → читать типизированное значение. Во многих сервисах Protobuf снижает нагрузку CPU и количество мусора в куче, что улучшает хвостовую задержку при нагрузке.
Сетевой эффект: мобильные и высоколатентные соединения
В мобильных сетях или при высокой задержке меньше байтов обычно означает более быстрые передачи и меньшее время радио‑модуля (что также экономит батарею). Но если ответы уже малы, накладные расходы рукопожатия, TLS и обработка на сервере могут доминировать — и выбор формата будет менее заметен.
Как бенчмарить в вашей системе
Измеряйте на реальных полезных нагрузках:
- Выберите репрезентативные запросы/ответы (малые, типовые, худший случай).
- Сравните: сырой размер, сжатый размер (gzip/brotli), время кодирования/декодирования и end‑to‑end задержку.
- Запускайте тесты при реалистичной конкуренции и фиксируйте p50/p95/p99.
Это переводит дебаты «сериализация API» в данные, которым вы сможете доверять для вашего API.
Опыт разработчика: читаемость, отладка и логирование
По опыту разработчиков JSON часто выигрывает по умолчанию. Вы можете инспектировать JSON‑запрос или ответ почти везде: в DevTools браузера, curl‑выводе, Postman, обратных прокси и текстовых логах. Когда что‑то ломается, «что мы на самом деле отправили?» обычно можно быстро вставить в консоль.
Protobuf отличается: он компактен и строг, но не читаем человеком. Если вы логируете «сырые» байты Protobuf, вы увидите base64‑строки или нечитаемый бинарник. Чтобы понять полезную нагрузку, нужны правильная .proto‑схема и декодер (напр., protoc, язык‑специфичные утилиты или сгенерированные типы сервиса).
Рабочие процессы отладки на практике
С JSON воспроизвести проблему просто: возьмите записанную полезную нагрузку, удалите секреты, воспроизведите curl‑командой — и вы близки к минимальному тестовому случаю.
С Protobuf обычно отлаживают так:
- захватывают бинарную полезную нагрузку (часто base64),
- декодируют её с правильной версией схемы,
- перекодируют для повторной отправки.
Этот дополнительный шаг управляем — если у команды есть повторяемый рабочий процесс.
Советы, чтобы упростить отладку Protobuf (и JSON)
Структурированное логирование помогает в обоих случаях. Логируйте request‑id, имя метода, идентификаторы пользователя/аккаунта и ключевые поля вместо целых тел.
Для Protobuf конкретно:
- Логируйте декодированное, отредактированное «debug view» (например, JSON‑представление) рядом с бинарной полезной нагрузкой, если это безопасно.
- Храните версию схемы или тип сообщения в логах, чтобы не гадать «какая
.protoиспользовалась?».\n- Добавьте маленький внутренний скрипт (или make‑задачу), который «декодирует эту base64‑полезную нагрузку с нужной схемой» для on‑call.
Для JSON рассмотрите логирование канонизированного JSON (стабильный порядок ключей), чтобы облегчить диффы и анализ инцидентов.
Схемы и типобезопасность: гибкость против ограждений
Контролируйте сгенерированный код
Экспортируйте полный исходный код, чтобы контракт API и сгенерированные типы хранились в вашем репозитории.
API не только переносят данные — они передают значение. Крупнейшая разница между JSON и Protobuf — насколько ясно это значение определено и обеспечено.
JSON: гибкая структура, гибкие интерпретации
JSON по умолчанию «без схемы»: можно отправлять любой объект с любыми полями, и многие клиенты примут его, если он «выглядит» разумно.
Эта гибкость удобна на ранних этапах, но может скрывать ошибки. Частые проблемы:
- Несогласованные поля:
userIdв одном ответе,user_idв другом, или отсутствующие поля в зависимости от пути исполнения. - «Stringly‑typed» данные: числа, boolean или даты как строки вроде
"42","true"или"2025-12-23"— легко произвести, легко неправильно истолковать. - Неоднозначные null:
nullможет означать «неизвестно», «не задано» или «намеренно пусто», и клиенты трактуют это по‑разному.
Вы можете добавить JSON Schema или OpenAPI, но сам JSON не заставляет потребителей следовать им.
Protobuf: явный контракт через .proto
Protobuf требует схемы в .proto. Схема — это общий контракт, который указывает:
- какие поля существуют,
- какие у них типы (string, integer, enum, message и т.д.),
- и какой номер поля идентифицирует его в проводе.
Этот контракт помогает избежать случайных изменений — например, замены числа на строку — потому что сгенерированный код ожидает конкретные типы.
Детали типобезопасности, которые важны
С Protobuf числа остаются числами, enum ограничены известными значениями, а временные метки обычно моделируются с помощью встроенных типов, а не произвольных строк. «Не задано» тоже яснее: в proto3 отсутствие поля отличается от значения по умолчанию, если использовать optional поля или wrapper‑типы.
Если вашему API нужны точные типы и предсказуемый разбор по разным командам и языкам, Protobuf даёт ограждения, которых JSON обычно достигает только дисциплиной и тестами.
Версионирование и эволюция схемы без поломки клиентов
Сохраняйте удобство JSON-интерфейсов
Создавайте REST-эндпоинты, которые легко просматривать в логах, DevTools и простых тестах.
API эволюционируют: вы добавляете поля, меняете поведение и выводите старое. Цель — изменять контракт, не удивляя потребителей.
Обратная и прямая совместимость простыми словами
- Обратная совместимость: новые серверы могут работать со старыми клиентами. Старые клиенты игнорируют незнакомое и продолжают работать.
- Прямая совместимость: новые клиенты могут работать со старыми серверами. Новые клиенты умеют обрабатывать отсутствие полей и использовать значения по умолчанию.
Стратегия эволюции стремится к обеим, но минимум — обратная совместимость.
Protobuf: номера полей — это настоящая идентичность
В Protobuf у каждого поля есть номер (например, email = 3). Именно номер, а не имя, отправляется по проводу. Имена служат людям и сгенерированному коду.
Отсюда:
-
Безопасные изменения (обычно)
- Добавляйте новые опциональные поля с новыми, раньше не использовавшимися номерами.
- Добавляйте новые значения в enum (желательно без переупорядочивания существующих).
- Деактивируйте поле (перестаньте его использовать), оставив номер зарезервированным.
-
Рисковые изменения (часто ломают)
- Повторное использование номера поля для другого смысла или типа.
- Несовместимая смена типа поля (например, string → int).
- Удаление поля без резервирования номера (повторное использование приведёт к коррупции смысла).
- Переименование «безопасно на проводе», но может ломать сгенерированный код и ожидания downstream.
Лучшие практики: используйте reserved для старых номеров/имен и ведите changelog.
JSON: версионирование через соглашения и дисциплину
JSON не имеет встроенной схемы, поэтому совместимость зависит от ваших паттернов:
- Предпочитайте аддитивные изменения: добавляйте новые поля, а не меняйте существующие.
- Считайте неизвестные поля игнорируемыми, а отсутствие поля — как «используйте разумный дефолт».
- Избегайте смены типов (например, число → строка). Если нужно, вводите новое имя поля.
Депрекации и ясная политика
Документируйте депрекации заранее: когда поле будет помечено устаревшим, как долго будет поддерживаться и чем его заменяют. Опубликуйте простую политику версионирования (например: «аддитивные изменения — не ломают; удаления требуют новой мажорной версии») и придерживайтесь её.
Поддержка инструментов и экосистема по платформам
Выбор между JSON и Protobuf часто сводится к тому, где ваш API должен работать и что команда готова поддерживать.
Браузеры vs серверы: «дефолтное» преимущество JSON
JSON практически универсален: любой браузер и бэкенд‑рантайм могут его распарсить без дополнительных зависимостей. В веб‑приложении fetch() + JSON.parse() — обычный путь, а прокси, API‑шлюзы и инструменты наблюдаемости чаще «понимают» JSON из коробки.
Protobuf можно запускать в браузере, но это не бесплатно: обычно добавляют библиотеку Protobuf (или сгенерированный JS/TS), учитывают размер бандла и решают, отправлять ли Protobuf по HTTP‑эндпоинтам, которые легко инспектировать.
Мобильные и backend SDK: где Protobuf сильнее
Для iOS/Android и бэкенд‑языков (Go, Java, Kotlin, C#, Python и т.д.) поддержка Protobuf зрелая. Главное отличие: Protobuf предполагает использование библиотек на каждой платформе и обычно генерацию кода из .proto.
Генерация кода даёт реальные преимущества:
- Типизированные модели и enum, с ранними ошибками при рассогласованиях контракта
- Быстрые библиотеки сериализации и единообразные формы данных между сервисами
Но есть издержки:
- Шаги в сборке (генерация кода в CI, синхронизация артефактов)
- Сложность репозитория/процессов (публикация общих
.proto, фиксация версий)
gRPC: сильная экосистема и ограничивающее влияние
Protobuf тесно связана с gRPC, который даёт полный набор инструментов: описание сервисов, клиентские стабы, стриминг и перехватчики. Если рассматриваете gRPC, Protobuf — естественный выбор.
Если вы строите традиционный JSON REST API, экосистема JSON (DevTools браузера, совместимость с curl, универсальные шлюзы) остаётся проще — особенно для публичных API и быстрых интеграций.
Прототипирование обоих вариантов без преждевременных обязательств
Если вы всё ещё исследуете поверхность API, полезно прототипировать оба стиля. Например, команды, использующие Koder.ai, часто поднимают JSON REST API для широкой совместимости и внутренний gRPC/Protobuf сервис для эффективности, а затем бенчмарят реальные полезные нагрузки перед окончательным выбором. Поскольку Koder.ai может генерировать full‑stack приложения (React для веба, Go + PostgreSQL на бэке, Flutter для мобильных) и поддерживает режим планирования, снапшоты/откат, это практично для итерации контрактов без масштабных рефакторов.
FAQ
В чём практическая разница между JSON и Protobuf в API?
JSON — это текстовый формат, который легко читать, логировать и тестировать с помощью обычных инструментов. Protobuf — это компактный бинарный формат, описываемый схемой в .proto, часто дающий меньшие полезные нагрузки и более быструю парсинг.
Выбирайте в зависимости от ограничений: доступность и удобство отладки (JSON) против эффективности и строгих контрактов (Protobuf).
Что означают «сериализация» и «десериализация» в потоке запрос/ответ?
API передают байты, а не объекты в памяти. Сериализация кодирует объекты сервера в полезную нагрузку (текст JSON или бинарный Protobuf) для передачи; десериализация декодирует эти байты обратно в объекты на клиенте/сервере.
Выбор формата влияет на пропускную способность, задержки и CPU, затрачиваемый на (де)серилизацию.
Всегда ли Protobuf меньше JSON на проволоке?
Чаще всего да, особенно для больших и вложенных объектов и повторяющихся полей: Protobuf использует числовые теги и эффективное бинарное кодирование.
Однако если включить gzip/brotli, повторяющиеся ключи JSON хорошо сжимаются, и реальная разница в размере может сократиться. Измеряйте как сырой, так и сжатый размеры.
Protobuf быстрее JSON по кодированию/декодированию и задержке?
Может. Парсинг JSON требует токенизации текста, обработки экранирования/Unicode и преобразования строк в числа. Декодирование Protobuf более прямое: тег → типизированное значение, что часто снижает затраты CPU и количество аллокаций.
Тем не менее, если полезные нагрузки очень малы, общая задержка может доминироваться TLS, сетевыми RTT и работой приложения, а не сериализацией.
Почему с Protobuf сложнее отлаживать и логировать, чем с JSON?
По умолчанию — да. JSON человекочитаем и легко просматривать в DevTools, логах, curl и Postman. Protobuf — бинарный, поэтому обычно требуется соответствующая .proto схема и инструменты для декодирования.
Хорошая практика: логировать декодированное, редактированное представление (например, JSON) параллельно с бинарной полезной нагрузкой, когда это безопасно.
Как отличаются схемы и типобезопасность в JSON и Protobuf?
JSON гибок и по умолчанию «без схемы», если не применять JSON Schema/OpenAPI. Эта гибкость может приводить к несогласованным полям, «stringly-typed» значениям и неоднозначности null.
Protobuf задаёт типы через .proto контракт, генерирует строго типизированный код и упрощает эволюцию контрактов — особенно при работе нескольких команд и языков.
Как эволюционировать API, не ломая клиентов, для JSON и Protobuf?
В Protobuf совместимость строится вокруг номеров полей (тегов). Безопасные изменения — обычно добавление новых опциональных полей с новыми номерами. Разрушающие изменения: повторное использование номера для другого смысла или несовместимое изменение типа.
Практики: помечайте старые номера/имена как reserved и ведите changelog. В JSON предпочитайте аддитивные изменения, вводите новые поля вместо изменения типов и рассматривайте неизвестные поля как игнорируемые.
Можно ли поддерживать одновременно JSON и Protobuf в одном API?
Да. Используйте соглашение о контенте:
- Клиент отправляет
Accept: application/jsonилиAccept: application/x-protobuf - Сервер отвечает соответствующим
Content-Type - Устанавливайте
Vary: Accept, чтобы кэши не смешивали форматы
Если у инструментов трудности с переговорами, временно можно открыть отдельный эндпоинт или версию (например, ).
Какие ограничения платформ/тулчейна влияют на выбор?
Зависит от окружения:
- Браузеры/публичные API: JSON даёт минимальное трение и лучшее стандартное инструментирование.
- Мобильные/бэкенд/внутренние сервисы: Protobuf имеет зрелые библиотеки и выигрывает от генерации кода.
- gRPC: Protobuf — естественный выбор с богатым набором инструментов.
Учтите издержки поддержки codegen и версионирования общих схем при выборе Protobuf.
Улучшается ли безопасность/надёжность при выборе Protobuf вместо JSON?
Ни один формат сам по себе не заменяет безопасность. Protobuf кажется «менее читаемым», но это не защита. Обязательные меры:
- Устанавливайте максимальный размер запроса/сообщения (включая распакованный размер при компрессии)
- Используйте таймауты и отмены
- Валидируйте бизнес-правила (типы сами по себе недостаточны)
- Не логируйте секреты; применяйте редактирование
Следите за обновлениями парсеров/библиотек, чтобы снизить риск уязвимостей парсинга.