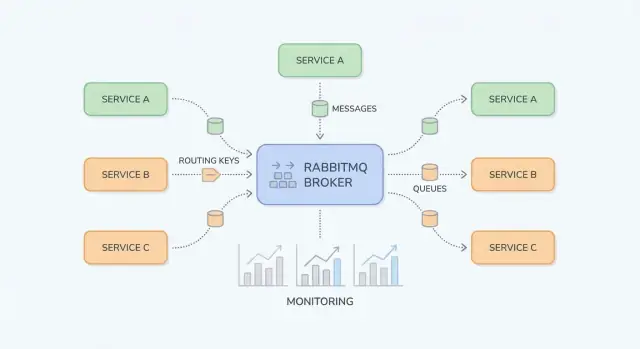
Почему RabbitMQ важен для команд приложений
RabbitMQ — это брокер сообщений: он стоит между частями вашей системы и надёжно перемещает «работу» (сообщения) от производителей к потребителям. Команды приложений обычно начинают его использовать, когда прямые синхронные вызовы (HTTP между сервисами, общие базы данных, cron) начинают создавать хрупкие зависимости, неравномерную нагрузку и сложные для отладки цепочки ошибок.
Какие проблемы решает RabbitMQ
Всплески трафика и неравномерная нагрузка. Если ваш сервис получает в 10× больше регистраций или заказов за короткое время, обработка всего сразу может перегрузить downstream. С RabbitMQ продьюсеры быстро ставят задачи в очередь, а потребители проходят по ним с контролируемой скоростью.
Тесная связность между сервисами. Когда Сервис A обязан вызвать Сервис B и ждать ответа, сбои и задержки распространяются. Месседжинг рассоединяет их: A публикует сообщение и продолжает работу; B обрабатывает его, когда доступен.
Более безопасная обработка сбоев. Не каждая ошибка должна моментально становиться видимой пользователю. RabbitMQ помогает делать фоновые повторы, изолировать «ядовитые» сообщения и не терять работу при временных отказах.
Типичные результаты для команд
Команды обычно получают плавные нагрузки (буферизация пиков), развязанные сервисы (меньше runtime-зависимостей) и контролируемые повторы (меньше ручной переработки). Также становится проще понять, где застряла работа — у продьюсера, в очереди или у потребителя.
Что охватывает это руководство (и что нет)
Руководство сосредоточено на практическом использовании RabbitMQ для команд приложений: ключевые концепции, распространённые паттерны (pub/sub, рабочие очереди, повторы и DLQ) и операционные вопросы (безопасность, масштабирование, наблюдаемость, отладка).
Оно не претендует на полный разбор спецификации AMQP или детальный разбор всех плагинов RabbitMQ. Цель — помочь вам спроектировать потоки сообщений, которые остаются поддерживаемыми в реальных системах.
Быстрый глоссарий
- Producer: компонент приложения, который отправляет сообщения.\
- Consumer: компонент приложения, который получает и обрабатывает сообщения.\
- Queue: буфер, где сообщения лежат до обработки потребителем.\
- Exchange: точка входа, которая маршрутизирует сообщения в одну или несколько очередей.\
- Routing key: метка, которую обменник использует, чтобы решить, куда направить сообщение.
Основы RabbitMQ: что это и когда его использовать
RabbitMQ — это брокер сообщений, который маршрутизирует сообщения между частями вашей системы, так что продьюсеры могут передавать работу, а потребители — обрабатывать её, когда готовы.
AMQP-месседжинг vs прямые HTTP-вызовы
При прямом HTTP-вызове Сервис A отправляет запрос Сервису B и обычно ждёт ответа. Если B медленный или упал, A либо терпит неудачу, либо зависает — и вам придётся настраивать таймауты, повторы и обратное давление в каждом вызывающем.
С RabbitMQ (через AMQP) Сервис A публикует сообщение в брокер. RabbitMQ сохраняет и маршрутизирует его в нужную(ые) очередь(и), а Сервис B потребляет асинхронно. Главное отличие — вы общаетесь через устойчивый промежуточный слой, который буферизует всплески и сглаживает неравномерную нагрузку.
Когда месседжинг подходит (и когда нет)
Месседжинг хорош, когда вы:
- Хотите развязывать команды/сервисы, чтобы они могли деплоиться и масштабироваться независимо.\
- Нуждаетесь в асинхронной работе (отправка писем, генерация PDF, проверки на мошенничество) без блокировки пользовательского запроса.\
- Ожидаете взрывчатый трафик и хотите поглощать пики с помощью очередей.\
- Нуждаетесь в надежной доставке с подтверждениями, повторами и DLQ.
Месседжинг не подходит, когда вы:
- Действительно нуждаетесь в моментальном ответе для обработки запроса (например, «пароль валиден?»).\
- Делаете простые синхронные чтения, где прямой вызов чище и проще для отладки.\
- Не имеете плана по версионированию сообщений, повторным попыткам и мониторингу — вы лишь переместите сложность.
Request/response vs async workflow (простой пример)
Синхронно (HTTP):
Сервис оформления вызывает сервис выставления счетов по HTTP: «Создай счёт». Пользователь ждёт, пока выставление счета выполняется. Если выставление медленное — задержка оформления растёт; если оно недоступно — оформление падает.
Асинхронно (RabbitMQ):
Оформление публикует invoice.requested с id заказа. Пользователь получает мгновенное подтверждение о получении заказа. Сервис выставления счетов потребляет сообщение, генерирует счёт, затем публикует invoice.created, чтобы почтовый/уведомительный сервис поднял ремарку. Каждая стадия может повторяться независимо, а временные отказы не ломают весь поток.
Базовые блоки: обменники, очереди и маршрутизация
RabbitMQ проще понимать, если разделить «куда публикуют сообщения» и «где они хранятся». Продьюсеры публикуют в exchange; обменник маршрутизирует в очереди; потребители читают из очередей.
Exchanges: как RabbitMQ решает, куда отправить сообщение
Exchange не хранит сообщения. Он оценивает правила и пересылает сообщения в одну или несколько очередей.
- Direct exchange: маршрутизирует по точному совпадению routing key. Используйте, когда нужны явные назначения (например,
billing или email).\
- Topic exchange: маршрутизирует по шаблонам в routing key. Удобно для гибкого pub/sub и подписки на категории.\
- Fanout exchange: вещает в каждую привязанную очередь, игнорируя routing key. Подходит, когда каждый потребитель должен получить каждое событие (например, инвалидирование кэша).\
- Headers exchange: маршрутизирует по заголовкам сообщения вместо routing key. Полезно, когда маршрутизация зависит от нескольких атрибутов (например,
region=eu И tier=premium), но держите его для специальных случаев — его сложнее понять.
Очереди и bindings: как сообщения попадают туда, куда нужно
Queue — место, где сообщения сидят, пока потребитель их не обработает. Очередь может иметь одного потребителя или многих (конкурирующие потребители), и сообщения обычно доставляются одному потребителю за раз.
Binding связывает exchange с очередью и определяет правило маршрутизации. Думайте: «Когда сообщение попало в обменник X с routing key Y, доставить его в очередь Q». Можно привязывать несколько очередей к одному обменнику (pub/sub) или привязать одну очередь несколькими правилами.
Routing key и паттерны (topic exchange)
Для direct exchanges маршрутизация точная. Для topic exchanges routing key — слова, разделённые точкой, например:
orders.created\orders.eu.refunded
Binding-ы могут включать шаблоны:
* соответствует ровно одному слову (например, orders.* совпадает с orders.created)\# соответствует нулю или более словам (например, orders.# совпадает с orders.created и orders.eu.refunded)
Это даёт чистый способ добавлять новых потребителей без изменения продьюсеров — создайте новую очередь и привяжите её нужным паттерном.
Подтверждения сообщений: ack, nack, requeue
После доставки сообщения потребитель сообщает, что произошло:
- ack: «Успешно обработано.» RabbitMQ удаляет сообщение из очереди.\
- nack (или reject): «Ошибка.» Можно либо отбросить сообщение, либо requeue — вернуть в очередь.\
- requeue: возвращает сообщение, чтобы попробовать снова (часто сразу).
Будьте осторожны с requeue: сообщение, которое всегда падает, может зациклиться и блокировать очередь. Многие команды используют nack вместе с стратегией повторов и DLQ (см. ниже), чтобы предсказуемо обрабатывать ошибки.
Распространённые сценарии в реальных приложениях
RabbitMQ хорош, когда нужно передавать работу или уведомления между частями системы без принуждения всех ждать одного медленного шага. Ниже практичные паттерны, которые часто встречаются в продуктах.
Publish/subscribe уведомления (fanout/topic)
Когда несколько потребителей должны реагировать на одно и то же событие — без знания издателя — pub/sub — аккуратный подход.
Пример: при обновлении профиля пользователя вы можете уведомлять индексатор поиска, аналитику и синхронизацию CRM параллельно. С fanout exchange вы вещаете всем привязанным очередям; с topic exchange — маршрутизируете выборочно (например, user.updated, user.deleted). Это убирает плотную связанность сервисов и позволяет добавлять подписчиков без изменений у продьюсера.
Work queues для фоновых задач
Если задача занимает время, отправляйте её в очередь и запускайте воркеры асинхронно:
- обработка изображений/видео\
- отправка транзакционных писем\
- генерация PDF или отчётов\
- импорт/экспорт данных
Это делает веб-запросы быстрыми и позволяет масштабировать воркеры независимо. Также очереди естественно контролируют конкурентность: очередь — ваш «список дел», а количество воркеров — «ручка пропускной способности».
Событийно-ориентированная интеграция между сервисами
Многие рабочие процессы пересекают границы сервисов: order → billing → shipping — классический пример. Вместо того, чтобы один сервис блокировал следующий, каждый сервис может публиковать событие, когда завершает шаг. downstream-сервисы потребляют события и продолжают workflow.
Это повышает устойчивость (временный отказ в доставке не ломает оформление заказа) и делает ответственность явной: каждый сервис реагирует на свои события.
Буфер для медленных или ненадёжных зависимостей
RabbitMQ также служит буфером между приложением и зависимостями, которые могут быть медленными или ненадёжными (third-party API, наследуемые системы, batch-базы). Вы быстро ставите запросы в очередь, затем обрабатываете их с контролируемыми повторами. Если зависимость недоступна, работа аккумулируется и позже будет отдана — вместо таймаутов по всей системе.
Если планируете вводить очереди постепенно, небольшой «async outbox» или единая очередь фоновых задач — хороший первый шаг (см. /blog/next-steps-rollout-plan).
Проектирование потоков сообщений, которые остаются поддерживаемыми
Удобный RabbitMQ-сетап остаётся приятным в работе, когда маршруты предсказуемы, имена последовательны, а полезная нагрузка эволюционирует без слома старых потребителей. Прежде чем добавлять ещё одну очередь, убедитесь, что «история» сообщения понятна: где оно возникает, как маршрутизируется и как коллега может отладить его сквозь систему.
Выбирайте тип exchange, соответствующий нуждам маршрутизации
Правильный выбор обменника заранее уменьшает неожиданные привязки и непредвиденные фан-ауты:
- Direct exchange: когда routing key однозначно мапится на конкретную очередь (например,
billing.invoice.created).\
- Topic exchange: для гибкого pub/sub с паттернами (например,
billing.*.created, *.invoice.*). Это самый распространённый выбор для поддерживаемого event-рутинга.\
- Fanout exchange: когда каждый потребитель должен получить каждое сообщение (редко для бизнес-событий; чаще для широковещательных сигналов).
Хорошее правило: если вы придумываете сложную логику маршрутизации в коде, возможно, это лучше вынести в topic exchange.
Базовые принципы схемы сообщений: версионирование и обратная совместимость
Относитесь к телу сообщения как к публичному API. Используйте явное версионирование (например, верхнее поле schema_version: 2) и стремитесь к обратной совместимости:
- Добавляйте поля; не переименовывайте/не удаляйте их.\
- Предпочитайте опциональные поля с безопасными значениями по умолчанию.\
- Если неизбежен ломающий изменение — публикуйте новый тип сообщения/ routing key, а не меняйте старый молча.
Так старые потребители продолжают работать, а новые могут принять новую схему в своём темпе.
Correlation ID и trace ID для кросс-сервисной отладки
Сделайте трассировку дешёвой, стандартизовав метаданные:
correlation_id: связывает команды/события из одного бизнес-действия.\trace_id (или W3C traceparent): связывает сообщения с распределённой трассировкой по HTTP и асинхронным потокам.
Когда каждый издатель ставит эти поля последовательно, вы можете проследить одну транзакцию через несколько сервисов без догадок.
Конвенции имен, которые масштабируются
Используйте предсказуемые, удобные для поиска имена. Одна распространённая схема:
- Exchanges:
<domain>.<type> (например, billing.events)\
- Routing keys:
<domain>.<entity>.<verb> (например, billing.invoice.created)\
- Queues:
<service>.<purpose> (например, reporting.invoice_created.worker)
Последовательность важнее остроумия: будущее вы (и дежурный) скажут спасибо.
Паттерны надёжности: повторы, DLQ и идемпотентность
Вносите изменения с уверенностью
Экспериментируйте с маршрутами и быстро откатывайтесь при ошибках биндинга или обработчика.
Надёжный месседжинг — это в основном планирование сбоев: потребители падают, downstream API таймаутят, некоторые события — повреждённые. RabbitMQ даёт инструменты, но код должен им помогать.
Доставка «как минимум один раз» и что это значит для кода
Типичный сценарий — at-least-once delivery: сообщение может быть доставлено несколько раз, но не должно теряться незаметно. Такое бывает, когда потребитель получил сообщение, начал работу и упал до отправки ack — RabbitMQ перекинет и переотправит его.
Практический вывод: дубликаты — нормальны, поэтому обработчик должен быть безопасным при повторных запусках.
Стратегии идемпотентности для потребителей
Идемпотентность означает «обработка одного и того же сообщения дважды равносильна однократной обработке». Полезные подходы:
- Ключи дедупликации: включите стабильный
message_id (или бизнес-ключ вроде order_id + event_type + version) и храните его в таблице/кэше обработанных с TTL.\
- Безопасные обновления: используйте условные записи (например, обновлять только если статус
PENDING) или ограничения уникальности в БД, чтобы предотвратить дубль-создание.\
- Outbox/inbox паттерны: сначала фиксируйте приём события, затем обрабатывайте его, чтобы повторы не повторяли сайд-эффекты.
Повторы с TTL + DLX/DLQ
Повторы лучше рассматривать как отдельный поток, а не как tight-loop внутри потребителя.
Распространённый паттерн:
- При транзиентной ошибке отклонить и направить в очередь повторов с per-queue (или per-message) TTL.\
- Когда TTL истёкнет, сообщение dead-letter'ится обратно в исходную очередь через DLX.\
- Отслеживайте счётчик попыток через заголовок (или кодируйте в routing key) и останавливайте после N попыток.
Это даёт backoff, не удерживая сообщения постоянно в unacked состоянии.
Ядовитые сообщения: карантин и воспроизведение
Некоторые сообщения никогда не пройдут (сломанная схема, отсутствующие ссылки, баг в коде). Обнаруживают их по:
- достижению максимума попыток\
- повторяющимся ошибкам с одинаковой подписью
Направьте такие сообщения в DLQ для карантина. Рассматривайте DLQ как операционный входящий ящик: исследуйте полезную нагрузку, исправляйте причину, затем вручную воспроизводите выбранные сообщения (лучше через контролируемый инструмент/скрипт), а не массово перекладывайте всё обратно.
Производительность и масштабирование: практические настройки
Производительность RabbitMQ обычно ограничивается несколькими практическими факторами: как вы управляете подключениями, насколько быстро потребители безопасно обрабатывают работу и используются ли очереди как «хранилище». Цель — стабильная пропускная способность без растущего бэклога.
Подключения vs каналы (reuse и лимиты)
Распространённая ошибка — открывать новое TCP-подключение для каждого издателя или потребителя. Подключения тяжелее, чем кажется (handshakes, heartbeats, TLS), поэтому держите их долгоживущими и переиспользуйте.
Используйте каналы для мультиплексирования работы поверх меньшего числа подключений. Правило большого пальца: мало подключений, много каналов. Но не создавайте тысячи каналов бездумно — у каждого канала есть оверхед, и в клиентской библиотеке могут быть свои лимиты. Предпочтительнее небольшой пул каналов на сервис и их повторное использование для публикаций.
Prefetch и конкурентность (пропускная способность без перегрузки)
Если потребители тянут слишком много сообщений одновременно, вы увидите скачки памяти, долгие времена обработки и неравномерную задержку. Установите prefetch (QoS), чтобы каждый потребитель держал контролируемое число unacked сообщений.
Практические рекомендации:
- Для долгих задач (вызовы API, обработка файлов) начните с prefetch 1–10 на потребителя.\
- Для быстрых лёгких обработчиков постепенно увеличивайте prefetch, наблюдая за скоростью ack и ресурсами узла.\
- Масштабируйтесь, добавляя больше инстансов потребителей (или потоков), прежде чем значительно повышать prefetch.
Размер сообщений: держите полезную нагрузку компактной
Большие сообщения уменьшают пропускную способность и увеличивают память (у издателей, брокера и потребителей). Если полезная нагрузка большая (документы, изображения, большие JSON), храните их в объектном хранилище или базе и отправляйте через RabbitMQ только ID + метаданные.
Хорошая эвристика: держите сообщения в KB-диапазоне, а не MB.
Обратное давление: предотвращение «бесконечного роста очереди»
Рост очередей — симптом, а не стратегия. Введите обратное давление, чтобы продьюсеры замедлялись, когда потребители не успевают:
- Ограничьте работу потребителей: капайте конкурентность и настраивайте prefetch, чтобы in-flight работа была предсказуемой.\
- Детектируйте и реагируйте на рост: алертьте по глубине очередей и соотношению publish rate vs ack rate.\
- Шединг нагрузки: для некритичных событий отбрасывайте или сэмплируйте сообщения на этапе публикации во время пиков.
При сомнении меняйте один параметр за раз и измеряйте: скорость публикаций, скорость ack-ов, длину очереди и сквозную задержку.
Чеклист безопасности для развёртываний RabbitMQ
Стандартизируйте повторные попытки и DLQ
Создайте готовую к редактированию настройку повторов и dead-letter с едиными соглашениями по именованию.
Безопасность RabbitMQ — это в основном ужесточение «краёв»: как клиенты подключаются, кто что может делать и как не дать учёткам попасть не туда. Используйте этот чеклист как базу и адаптируйте под требования соответствия.
Шифруйте соединения TLS
- Включите TLS для всех клиентских подключений (AMQP-over-TLS на 5671 или выбранном порту) и отдавайте предпочтение современным версиям TLS и шифрам.\
- Используйте сертификаты, соответствующие hostname брокера, к которому подключаются клиенты.\
- Планируйте ротацию сертификатов: отслеживайте сроки истечения, автоматизируйте обновления, репетируйте процедуры перезагрузки, чтобы ротация не превратилась в outage.\
- По возможности валидируйте клиентов через mTLS для внутренних сервисов, работающих с чувствительными данными.
Аутентификация и авторизация
Права RabbitMQ мощны при их консистентном использовании.
- Создавайте отдельные пользователи для каждого приложения (избегайте общих «app» аккаунтов).\
- Используйте vhosts для разделения тенантов или систем (например, один vhost на продукт/команду).\
- Применяйте принцип наименьших привилегий для vhost: Configure (создавать/изменять ресурсы), Write (публиковать), Read (потреблять).
Разделите dev/staging/prod безопасно
- Запускайте отдельные кластеры для окружений, когда возможно. Если инфраструктура общая — изолируйте через vhost и отдельные креды.\
- Никогда не направляйте dev-приложение на prod-брокер «для теста». Сделайте это невозможным через сетевые политики и DNS-названия.
Правильная работа с секретами в приложениях
- Не храните креды в коде, в конфиге, залитом в git, или в образах контейнеров.\
- Впрыскивайте секреты в рантайме через платформу (Kubernetes Secrets, менеджер секретов или зашифрованные переменные CI).\
- Ротируйте креды регулярно и удаляйте неиспользуемых пользователей.
Для операционного ужесточения (порты, фаерволы, аудит) держите короткий внутренний ранбук и ссылайтесь на него из /docs/security.
Мониторинг и наблюдаемость: что измерять
Когда RabbitMQ ведёт себя плохо, симптомы обычно появляются сначала в приложении: медленные endpoints, таймауты, пропавшие обновления или задачи, которые «никогда не завершаются». Хорошая наблюдаемость позволяет подтвердить, является ли брокер причиной, найти узкое место (издатель, брокер или потребитель) и действовать прежде, чем пользователи заметят.
Основные метрики брокера для отслеживания
Начните с небольшого набора сигналов, которые показывают, идут ли сообщения:
- Глубина очереди (messages ready + unacked): растущая глубина указывает, что потребители не успевают или зависли.\
- Publish rate и ack rate: публикации растут, а acks плоские = бэклог. Внезапный провал acks = ошибки потребителей или таймауты.\
- Загрузка потребителей: простаивают ли потребители, насыщены ли они или часто перезапускаются? Сопоставьте это с prefetch и concurrency.\
- Redeliveries / requeues: сильный индикатор ошибок обработки, плохой политики повторов или ядовитых сообщений.
Сигналы для алертов, которые ловят инциденты рано
Алертьте по трендам, а не только по жёстким порогам.
- Растущий бэклог в течение N минут: постоянный рост глубины более полезен, чем «depth > X».\
- Повторные requeues/redeliveries: указывает на петлю ошибок, которая нагружает CPU и блокирует очередь.\
- Частые переподключения connections/channels: могут сигнализировать об авариях приложений, сетевых проблемах или неверных heartbeats.\
- Долгие unacked: говорят о том, что потребители зависают или обрабатывают слишком долго.
Логи и трассировка сообщений при инцидентах
Логи брокера помогут отличить «RabbitMQ упал» от «клиенты пользуются им неправильно». Ищите ошибки аутентификации, blocked connections (ресурсные алармы) и частые ошибки каналов.
Со стороны приложения логируйте каждую попытку обработки с correlation_id, именем очереди и результатом (acked, rejected, retried).
Если используете распределённую трассировку — прокидывайте trace-заголовки в свойства сообщений, чтобы связать «HTTP-запрос → опубликованное сообщение → работа потребителя».
Дашборды и внутренние ранбуки
Сделайте дашборд по критичному потоку: publish rate, ack rate, depth, unacked, requeues и число потребителей. Добавьте в дашборд ссылку на внутренний ранбук, например /docs/monitoring, и чеклист «что проверить сначала» для дежурных.
Отладка распространённых проблем RabbitMQ
Когда что-то «просто перестаёт двигаться», не спешите с перезапуском. Большинство проблем становится очевидным после проверки (1) bindings и маршрутизации, (2) здоровья потребителей и (3) ресурсных алармов.
Сообщения не потребляются
Если издатели говорят «отправлено успешно», но очереди пусты (или заполняется не та очередь), проверьте маршрутизацию до кода.
Начните с Management UI:
- Проверьте тип exchange и что очередь имеет ожидаемый binding.\
- Убедитесь, что routing key продьюсера совпадает с паттерном binding (особенно для
topic).\
- Проверьте, что вы публикуете в правильный vhost.
Если в очереди есть сообщения, но никто не потребляет, проверьте:
- Подключён ли потребитель и подписан ли он на нужную очередь.\
- Не завис ли потребитель из-за prefetch (слишком мало/много) или ожидания медленной внешней работы.\
- Происходят ли ack (растущий unacked обычно означает, что потребитель не подтверждает или перегружен).
Дубликаты и нарушение порядка
Дубликаты обычно связаны с повторами (потребитель упал после обработки и до ack), сетевыми перерывами или ручным requeue. Смягчайте эффект идемпотентностью (например, дедупликация по message ID в БД).
Нарушение порядка — ожидаемо при множественных потребителях или requeue. Если порядок важен, используйте одного потребителя для этой очереди или партиционируйте по ключу в несколько очередей.
Аварии памяти/диска
Алармы означают, что RabbitMQ защищается:
- Disk alarm: освободите диск, переместите логи или расширьте том; затем убедитесь, что тревога снята.\
- Memory alarm: уменьшите in-flight сообщения (понизьте prefetch, ограничьте конкуренцию), и проверьте на предмет слишком больших сообщений.
Безопасный реплей из DLQ
Перед реплеем исправьте корневую причину и предотвратите петли «ядовитых сообщений». Реплейте малыми партиями, добавьте кап повторов и помечайте ошибки метаданными (attempt count, last error). Рассмотрите отправку реплея в отдельную очередь сначала, чтобы можно было быстро остановиться при повторении той же ошибки.
RabbitMQ против альтернатив: как выбрать инструмент
Начните с безопасных настроек по умолчанию
Задайте TLS, пользователей, vhosts и доступ по принципу наименьших привилегий в плане сборки.
Выбор месседжинг-инструмента зависит от паттерна трафика, требований к отказоустойчивости и операционного уровня комфорта.
Когда RabbitMQ — подходящий выбор
RabbitMQ хорош, когда вам нужна надёжная доставка сообщений и гибкая маршрутизация между компонентами приложения. Это сильный вариант для классических асинхронных рабочих потоков — команды, фоновые задачи, fan-out уведомления и request/response паттерны — особенно когда вы хотите:
- Подтверждения по сообщению и обратное давление (медленные потребители не теряют работу).\
- Богатую маршрутизацию (topics, headers, direct) без дополнительной реализации.\
- Операционно простое масштабирование для многих команд (добавляйте потребителей, настраивайте prefetch, управляйте очередями).
Если цель — перемещение работы, а не хранение долгой истории событий, RabbitMQ часто — удобный выбор.
RabbitMQ vs Kafka-подобные стриминг-системы
Kafka и похожие системы рассчитаны на высокопроизводительный стриминг и долговременные журналы событий. Выбирайте Kafka-подобную систему, когда вам важно:
- Возможность реплея (потребители могут заново обработать историю).\
- Очень высокая пропускная способность с масштабированием по партициям.\
- Единый «источник правды» событий для аналитики и сервисов.
Торговая плата: Kafka может требовать большего операционного усилия и подталкивать к архитектуре, ориентированной на throughput (батчи, стратегия партиционирования). RabbitMQ проще для низко- и средне-нагруженных сценариев с низкой сквозной задержкой и сложной маршрутизацией.
Когда достаточно простой очереди задач
Если у вас один продьюсер и один потребитель/пул воркеров — и вас устраивают простые семантики — очередь на Redis или управляемый таск-сервис может быть достаточен. Команды обычно перерастают это, когда нужны более строгие гарантии доставки, dead-lettering, множественные шаблоны маршрутизации или чёткое разделение продьюсеров и потребителей.
Соображения при миграции, если требования изменятся
Проектируйте контракты сообщений так, будто вы можете позже сменить систему:
- Держите схемы сообщений версионированными и обратно совместимыми.\
- Избегайте broker-специфичных фич в теле сообщений (помещайте маршрутизацию в заголовки/метаданные, не в тело).\
- Делайте продьюсеров/потребителей способными работать параллельно во время миграции.
Если затем потребуется поток с возможностью реплея, можно организовать мост из событий RabbitMQ в лог-ориентированную систему, сохранив RabbitMQ для оперативных рабочих потоков. Для практического плана развертывания см. /blog/rabbitmq-rollout-plan-and-checklist.
Следующие шаги: план развёртывания и чеклист для команды
Роллаут RabbitMQ проходит легче, если рассматривать его как продукт: начните с малого, определите владение и подтвердите надёжность, прежде чем расширять использование на больше сервисов.
Стартовый чеклист (адаптация для одного сервиса)
Выберите один рабочий процесс, который выигрывает от асинхронной обработки (например, отправка писем, генерация отчётов, синк с третьей стороной).
- Определите контракт сообщения: обязательные поля, версия и что означает «успех».\
- Создайте один exchange + одну очередь с понятной схемой именования.\
- Задайте лимиты конкурентности потребителя и prefetch, чтобы не перегружать downstream.\
- Добавьте повторы (с backoff) и DLQ с первого дня.\
- Сделайте обработчики идемпотентными (безопасными при повторной обработке).\
- Задокументируйте операционные шаги «остановить кровотечение» (поставить потребителя на паузу, осушить очередь, воспроизвести из DLQ).
Если нужен шаблон имен, политик повторов и базовой конфигурации — держите его централизовано в /docs.
Как вы внедряете эти паттерны, подумайте о стандартизации каркаса по командам. Например, команды, использующие Koder.ai, часто генерируют шаблон сервиса producer/consumer из чат-промпта (включая соглашения об именах, wiring retry/DLQ и trace/correlation заголовки), затем экспортируют код для ревью и итераций в «планировочном режиме» перед развёртыванием.
Операционная ответственность (сделайте её явной)
RabbitMQ успешен, когда «кто-то владеет очередью». Решите это до выхода в прод:
- Кто мониторит: обычно платформа/SRE команда отвечает за здоровье брокера; команды сервисов — за свои очереди и поведение потребителей.\
- Кто работает с DLQ: команда сервиса на дежурстве (с явным путём эскалации).\
- Runbooks: один runbook на уровень брокера и один runbook на сервис для каждой критичной очереди.
Если вы формализуете поддержку или управляемый хостинг, согласуйте ожидания заранее (см. /pricing) и укажите контакт для инцидентов и онбординга на /contact.
Следующие эксперименты (подтвердите до масштабирования)
Проведите небольшие эксперименты в ограниченном времени, чтобы набрать уверенность:
- Нагрузочное тестирование: проверьте throughput, конкурентность потребителей и задержки при пиковых условиях.\
- Учения по отказам: убивайте потребителей, симулируйте перезапуски брокера, искусственно повышайте сетевую латентность, проверьте поведение повторов и DLQ.\
- Версионирование схем: выпустите v2-схему, пока v1-потребители ещё работают; убедитесь в совместимости и порядке раскатки.
Когда один сервис стабилен несколько недель, повторяйте шаблоны — не придумывайте заново для каждой команды.