Почему ранние решения Джо Беды для Kubernetes до сих пор важны
Джо Беда был одним из ключевых людей, формировавших ранний дизайн Kubernetes — вместе с другими основателями, которые вынесли опыт из внутренних систем Google в открытую платформу. Его влияние заключалось не в погоне за модными фичами, а в выборе простых примитивов, которые выдержат реальный продакшен‑хаос и останутся понятными для обычных команд.
Эти ранние выборы — причина, по которой Kubernetes стал не просто «инструментом для контейнеров». Он превратился в переиспользуемое ядро современных платформ для приложений.
Оркестрация контейнеров, простыми словами
«Оркестрация контейнеров» — это набор правил и автоматизации, который поддерживает приложение в рабочем состоянии при падениях машин, всплесках трафика или деплоях. Вместо того, чтобы человек присматривал за серверами, система планирует контейнеры на компьютеры, перезапускает их при крашах, распределяет для устойчивости и настраивает сеть, чтобы пользователи могли к ним добраться.
Хаос до Kubernetes
До повсеместного распространения Kubernetes команды часто склеивали решения скриптами и самописными инструментами, чтобы ответить на базовые вопросы:
- Где сейчас должен запуститься этот контейнер?
- Что случится, если узел умрёт в 2 часа ночи?
- Как безопасно деплоить без даунтайма?
- Как сервисы находят друг друга, если IP постоянно меняются?
Такие DIY‑системы работали — пока не переставали. Каждое новое приложение или команда добавляли ещё один одноразовый кусок логики, и достичь операционной консистентности было сложно.
Что рассматривает эта статья
Здесь мы пройдёмся по ранним дизайнерским решениям Kubernetes («форме» Kubernetes) и почему они по‑прежнему влияют на современные платформы: декларативная модель, контроллеры, Pod'ы, метки, Service, сильный API, согласованное состояние кластера, подключаемое планирование и расширяемость. Даже если вы прямо не запускаете Kubernetes, вероятно, вы используете платформу, построенную на этих идеях — или сталкиваетесь с теми же проблемами.
Проблема, которую Kubernetes решил
До Kubernetes «запуск контейнеров» часто означал запуск нескольких контейнеров. Команды клеили bash‑скрипты, cron‑задачи, golden‑образы и набор ad‑hoc‑инструментов для деплоя. Когда что‑то ломалось, починка часто жила в чьей‑то голове или в README, которому никто не доверял. Операции сводились к серии одноразовых вмешательств: перезапуск процессов, перенаправление балансировщиков, чистка диска и угадывание, на какую машину безопасно лезть.
Масштаб вскрыл новые режимы отказов
Контейнеры упростили упаковку, но не убрали сложные стороны продакшена. В масштабе система отказывает чаще и по‑разному: узлы пропадают, сети разъединяются, образы выкатываются непоследовательно, а рабочие нагрузки уходят от того, что вы думаете запущено. «Простой» деплой может превратиться в каскад: часть инстансов обновлена, часть нет, одни застряли, другие здоровы, но недоступны.
Настоящая проблема — не запуск контейнеров, а поддержание правильных контейнеров в правильной форме несмотря на постоянный дрейф.
Единая модель для разных инфраструктур
Команды также балансировали между разными окружениями: on‑prem, виртуальные машины, ранние облачные провайдеры и разные сетевые/сторедж‑настройки. Каждая платформа имела свой словарь и свои паттерны отказов. Без общей модели каждая миграция означала переписывание оперативных инструментов и переобучение людей.
Kubernetes предлагал единый и последовательный способ описать приложения и их операционные потребности, независимо от местонахождения машин.
Ожидания от «платформы»
Разработчики хотели самообслуживание: деплоить без тикетов, масштабировать без просьб о ресурсах и откатывать без драмы. Операторы хотели предсказуемости: стандартизированные health checks, повторяемые деплои и ясный источник правды о том, что должно работать.
Kubernetes не пытался быть просто красивым планировщиком. Он стремился стать фундаментом надёжной платформы для приложений — системой, превращающей грязную реальность в пространство, в котором можно рассуждать.
Решение 1: декларативная модель желаемого состояния
Один из самых влиятельных ранних выборов — сделать Kubernetes декларативным: вы описываете, чего хотите, а система делает так, чтобы реальность соответствовала этому описанию.
Желанное состояние, объяснённое на примере термостата
Термостат — полезный повседневный пример. Вы не вручную включаете и выключаете отопление каждые несколько минут. Вы ставите желаемую температуру — скажем, 21°C — и термостат периодически проверяет комнату и управляет нагревом, чтобы оставаться близко к целевому значению.
Kubernetes работает аналогично. Вместо того чтобы по шагам говорить кластеру «запусти этот контейнер на той машине, затем перезапусти его при падении», вы объявляете результат: «хочу 3 копии этого приложения». Kubernetes постоянно сверяет текущее состояние с желаемым и исправляет отклонения.
Меньше ручных шагов, меньше сюрпризов
Декларативная конфигурация уменьшает скрытые «ops‑чек‑листы», которые обычно живут в чьей‑то голове или в наполовину обновлённом runbook'е. Вы применяете конфиг, и Kubernetes берет на себя механику — размещение, перезапуски и согласование изменений.
Это также делает обзоры изменений проще: изменение видно как diff в конфигурации, а не как серия ad‑hoc команд.
Повторяемость между окружениями
Поскольку желаемое состояние записано, вы можете переиспользовать один и тот же подход в dev, staging и production. Окружение может отличаться, но намерение остаётся согласованным, что делает деплои предсказуемее и проще для аудита.
Компромиссы
Декларативные системы имеют кривую обучения: нужно думать в терминах «что должно быть верно», а не «что мне сделать дальше». Они также сильно зависят от хороших дефолтов и ясных конвенций — без этого команды могут создавать конфиги, которые формально работают, но их трудно понять и сопровождать.
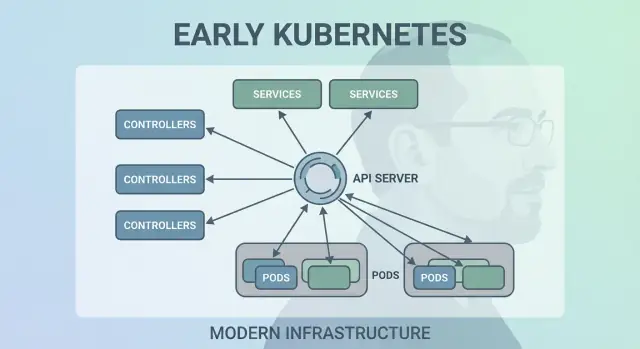
Решение 2: контрольные петли (контроллеры) как движок
Kubernetes преуспел не потому, что умел один раз запустить контейнеры, а потому что мог поддерживать их корректную работу со временем. Большой архитектурный ход — сделать «контрольные петли» (controllers) ядром системы.
Что такое контроллер
Контроллер — это простая петля:
- Посмотреть текущее состояние (что реально запущено)
- Сравнить с желаемым состоянием (что вы запросили)
- Выполнить действия до тех пор, пока они не совпадут
Это похоже на автопилот. Вы не присматриваете за рабочими нагрузками; вы декларируете желаемое, а контроллеры постоянно подправляют кластер в нужную сторону.
Обработка падений, потери узлов и дрейфа
Этот паттерн объясняет устойчивость Kubernetes при реальных проблемах:
- Краш контейнера: контроллер замечает, что реплик стало меньше, и создаёт замену.
- Потеря узла: контроллеры пересаживают Pod'ы на другие узлы, чтобы восстановить нужное количество.
- Дрейф конфигурации: если кто‑то изменил или удалил ресурсы, контроллеры восстанавливают ожидаемое состояние.
Вместо того чтобы рассматривать отказы как особые случаи, контроллеры трактуют их как обычное «несоответствие состояний» и исправляют одинаковым образом каждый раз.
Почему это масштабируется лучше, чем скрипты
Традиционные скрипты часто предполагают стабильную среду: выполните шаг A, затем B, затем C. В распределённых системах эти предположения постоянно ломаются. Контроллеры масштабируются лучше, потому что они идемпотентны (безопасно выполнять много раз) и в конечном итоге консистентны (они продолжают пробовать, пока цель не достигнута).
Повседневные примеры: Deployment и ReplicaSet
Если вы использовали Deployment, вы уже полагаетесь на контрольные петли. Внутри Kubernetes ReplicaSet‑контроллер следит за количеством Pod'ов, а Deployment‑контроллер управляет безопасными rolling updates и откатами.
Решение 3: Pod'ы как атомарная единица размещения
Kubernetes мог бы планировать «просто контейнеры», но команда Джо Беды ввела Pod'ы как наименьшую единицу размещения. Главное: многие реальные приложения — это не одиночный процесс. Это небольшая группа тесно связанных процессов, которым нужно жить вместе.
Почему Pod'ы вместо отдельных контейнеров?
Pod — это оболочка вокруг одного или нескольких контейнеров, которые разделяют судьбу: они стартуют вместе, работают на одном узле и масштабируются вместе. Это делает паттерны вроде sidecar естественными — лог‑шиппер, прокси, релоадер конфигурации или агент безопасности, который всегда должен сопровождать главное приложение.
Вместо того чтобы заставлять каждое приложение интегрировать такие помощники, Kubernetes позволяет упаковать их как отдельные контейнеры внутри Pod'а, которые тем не менее ведут себя как единое целое.
Что Pod'ы дали для сети и стораджа
Pod'ы сделали практичными два важных предположения:
- Сеть: контейнеры в Pod'е разделяют сетевую идентичность (один IP и пространство портов). Главное приложение может обращаться к sidecar'у по
localhost — просто и быстро.
- Хранилище: контейнеры в Pod'е могут разделять тома. Помощник пишет файлы, которые читает главное приложение, без лишних внешних прыжков.
Эти решения уменьшили потребность в кастомном «склейке», оставив изоляцию на уровне процессов.
Где Pod'ы путают новичков
Новые пользователи часто ожидают «один контейнер = одно приложение», а затем спотыкаются о концепции Pod'а: рестарты, IP‑адреса и масштабирование. Многие платформы скрывают это за опинионированными шаблонами (например, «веб‑сервис», «воркер» или «job»), которые генерируют Pod'ы за кулисами — чтобы команды получали преимущества sidecar'ов и совместных ресурсов, не думая о механике Pod'ов каждый день.
Решение 4: метки и селекторы для слабой связанности
Сделайте его настоящим продуктом
Привяжите приложение к собственному домену, когда оно готово для команды или пользователей.
Тихо мощный ранний выбор — признать метки первоклассной метаданных и селекторы — основным способом «находить» объекты. Вместо жёсткой привязки (например, «эти точные три машины запускают моё приложение») Kubernetes поощряет описывать группы через общие атрибуты.
Метки: гибкие теги на всём
Метка — это простая пара ключ/значение, которую можно прикрепить к ресурсам — Pod'ам, Deployment'ам, Node'ам, Namespace и др. Они действуют как консистентные, доступные для запроса теги:
app=checkoutenv=prodtier=frontend
Поскольку метки лёгкие и пользовательские, вы моделируете реальность организации: команды, центры затрат, зоны соответствия, каналы релизов или всё, что важно для вашей операции.
Селекторы: отношения без жёсткой зависимости
Селекторы — это запросы по меткам (например, «все Pod'ы, где app=checkout и env=prod»). Это лучше фиксированных списков хостов, потому что система адаптируется по мере рескейлов, масштабирования или замен во время релизов. Ваша конфигурация остаётся стабильной, даже когда подлежащие экземпляры постоянно меняются.
Динамическое группирование в масштабе
Такой дизайн упрощает операционную работу: вы не управляете тысячами идентичностей инстансов — вы управляете несколькими значимыми наборами меток. В этом суть слабой связанности: компоненты подключаются к группам, членство в которых можно безопасно менять.
Метки дают больше, чем группировку
Как только метки появились, они становятся общим словарём по платформе. Их используют для маршрутизации трафика (Service), границ политик (NetworkPolicy), фильтрации в наблюдаемости (метрики/логи) и даже расчёта затрат. Одна простая идея — помечать ресурсы последовательно — открывает целый набор автоматизаций.
Решение 5: Service для стабильной сети
Kubernetes нужно было сделать сеть предсказуемой, даже если контейнеры — неустойчивы. Pod'ы заменяют, пересаживают и масштабируют — их IP и машины меняются. Суть Service проста: дать стабильную «фасадную» точку доступа к меняющемуся набору Pod'ов.
Стабильный доступ к меняющимся Pod'ам
Service даёт постоянный виртуальный IP и DNS‑имя (например, payments). За этим именем Kubernetes непрерывно следит за Pod'ами, которые соответствуют селектору, и маршрутизирует трафик. Если Pod умирает и появляется новый, Service всё ещё указывает в нужное место, и вам не нужно трогать настройки приложений.
Обнаружение сервисов, упрощающее конфигурацию
Этот подход убрал много ручной проводки. Вместо того чтобы вшивать IP в конфиги, приложения могут опираться на имена. Вы деплоите приложение, создаёте Service, и другие компоненты находят его через DNS — без кастомного реестра и без жёстких эндпоинтов.
Встроенная балансировка для надёжности
Service также предлагает базовую балансировку нагрузки по здоровым эндпоинтам. Это значит, что команды не строят собственные балансировщики для каждого внутреннего микросервиса. Распределение трафика уменьшает радиус поражения при падении отдельного Pod'а и делает rolling updates менее рискованными.
Ограничения — и как Ingress/Gateway это дополняют
Service отлично подходит для L4 (TCP/UDP) трафика, но не моделирует HTTP‑правила, TLS‑терминацию или политики на краю. Здесь появляются Ingress и, всё чаще, Gateway API: они строят поверх Service, чтобы управлять хостами, путями и внешними точками входа более гибко.
Решение 6: API как поверхность продукта
Один из тихо‑радикальных ранних выборов — трактовать Kubernetes как API, на которое строятся интеграции, а не как монолитный инструмент. Такой подход «API‑первый» сделал Kubernetes платформой, которую можно расширять, скриптовать и управлять программно.
Почему API‑первый изменил построение платформ
Когда API — это поверхность продукта, команды платформы могут стандартизировать как описываются и управляются приложения, независимо от того, какой UI, пайплайн или внутренний портал поверх этого лежит. «Деплой сервиса» превращается в «создание и обновление объектов API» (Deployment, Service, ConfigMap), что даёт чистый контракт между командами приложений и платформой.
Инструменты, UI и автоматизация без специальных прав
Поскольку всё идёт через единый API, новым инструментам не нужны привилегированные обходные пути. Дашборды, GitOps‑контроллеры, движки политик и CI/CD могут быть обычными клиентами API с чётко ограниченными правами.
Эта симметрия важна: одинаковые правила, аутентификация, аудит и admission применимы независимо от того, пришёл ли запрос от человека, скрипта или внутреннего UI.
Версионирование и совместимость для долгоработающих кластеров
Версионирование API позволило эволюционировать Kubernetes без моментального ломания всех кластеров и инструментов. Депрекации можно планировать, совместимость тестировать, апгрейды планировать. Для организаций, эксплуатирующих кластеры годами, это разница между «мы можем апгрейдиться» и «мы застряли».
Что на самом деле представляет kubectl
kubectl — это не Kubernetes, а клиент. Эта мысль помогает проектировать рабочие процессы в терминах API: kubectl можно заменить автоматизацией, веб‑UI или кастомным порталом, и система остаётся согласованной, потому что контракт — это API.
Решение 7: централизованное состояние кластера (etcd) и согласованность
Растяните бюджет на разработку
Зарабатывайте кредиты, делясь тем, что вы создали на Koder.ai, или приглашая коллег.
Kubernetes нуждался в едином «источнике правды»: какие Pod'ы существуют, какие узлы здоровы, куда указывают Service и какие объекты обновляются. Эту роль выполняет etcd.
Что делает etcd, простыми словами
etcd — это база данных для control plane. Когда вы создаёте Deployment, масштабируете ReplicaSet или обновляете Service, желаемая конфигурация записывается в etcd. Контроллеры и другие компоненты следят за сохранённым состоянием и приводят реальность в соответствие с ним.
Почему согласованность важна, когда всё реагирует одновременно
Кластер Kubernetes полон движущихся частей: шедулеры, контроллеры, kubelet'ы, автоскейлеры и admission‑проверки могут реагировать одновременно. Если они читают разные версии «правды», появляются гонки — например, два компонента принимают конфликтующие решения по одному и тому же Pod'у.
Сильная согласованность etcd обеспечивает, что когда control plane говорит «это текущее состояние», все с ним согласны. Это делает контрольные петли предсказуемыми, а не хаотичными.
Как это влияет на бэкапы, апгрейды и восстановление
Поскольку etcd хранит конфигурацию кластера и историю изменений, его защищают при:
- бэкапах: без снимка etcd вы не сможете достоверно восстановить объекты кластера
- апгрейдах: здоровье etcd и снимки снижают риск во время обновлений
- восстановлении после катастроф: восстановление etcd часто самый быстрый путь вернуть control plane с прежним намерением
Практический совет
Относитесь к состоянию control plane как к критическим данным. Делайте регулярные etcd snapshots, тестируйте восстановление и храните бэкапы вне кластера. В управляемом Kubernetes выясните, что именно бэкапит провайдер, а что вам нужно бэкапить самостоятельно (например, PV и данные приложений).
Решение 8: подключаемое планирование и осведомлённость о ресурсах
Kubernetes не считал «куда запускать ворклоад» тривиальным. С самого начала шедулер был отдельным компонентом с ясной задачей: сопоставить Pod'ы с узлами, которые действительно способны их запустить, учитывая состояние кластера и требования Pod'а.
Как шедулер сопоставляет ворклоады с узлами
В высоком уровне планирование проходит в два этапа:
- Фильтрация: убрать узлы, не удовлетворяющие жёстким ограничениям (нехватка CPU/памяти, отсутствующие метки, несовместимые taint'ы, занятые порты и т.д.).
- Оценка: ранжировать оставшиеся узлы по предпочтениям (распределение по зонам, укладывание для эффективности, избегание «шумных» соседей, уважение правил affinity).
Такая структура позволила эволюционировать планирование без переписывания всего механизма.
Разделение ответственности: шедулер vs runtime vs сеть
Ключевой выбор — чистые ответственности:
- шедулер решает размещение;
- runtime и kubelet выполняют запуск на выбранном узле;
- сетевой слой обеспечивает связность после запуска.
Благодаря этому улучшения в одной области (например, новый CNI‑плагин) не требуют новой модели планирования.
Ограничения и приоритеты развивались естественно
Осведомлённость о ресурсах началась с requests и limits, давая шедулеру реальные сигналы. Затем добавились более богатые механизмы — node affinity/anti‑affinity, pod affinity, priorities and preemption, taints and tolerations и топологически‑осознанное распределение — все на одной основе.
Современное воздействие: мульти‑тенантность и экономичное размещение
Такой подход позволяет совместно использовать кластеры: команды изолируют критические сервисы через приоритеты и taint'ы, а остальные получают выгоду от большей утилизации. С помощью бин‑пэкинга и топологического контроля платформы размещают нагрузку дешевле, не теряя надёжности.
Решение 9: расширяемость вместо «одного встроенного пути»
Пропустите настройку и начните писать код
Сократите рутину с YAML: сгенерируйте начальный сервис из чата и затем дорабатывайте по шагам.
Kubernetes мог бы выйти с полностью опинионированным PaaS — со сборками, правилами маршрутизации, фоновыми задачами, конвенциями конфигов и т.д. Вместо этого команда Джо Беды сузила ядро: запускать и восстанавливать ворклоады, делать их доступными и предоставлять согласованный API для автоматизации.
Почему Kubernetes не стал полным PaaS
Полный PaaS навязывал бы один рабочий процесс и один набор компромиссов всем. Kubernetes целился в более широкое основание, которое могло бы поддерживать разные стили платформ: похожие на Heroku простые developer‑workflow, корпоративное управление, пайплайны для batch/ML или низкоуровневый контроль — без жёсткой привязки к одному продукт‑философии.
Как расширения безопасно добавляют фичи
Механизмы расширяемости Kubernetes дают контролируемый путь роста функциональности:
- CRD позволяют добавлять новые типы API (например,
Certificate или Database), которые выглядят нативно;
- контроллеры/операторы приводят эти новые ресурсы в желаемое состояние используя тот же паттерн;
- admission controller'ы / webhook'и навязывают политику и подставляют дефолты на границе API.
Это означает, что внутренние команды или вендоры могут добавлять фичи как плагины, при этом используя стандартные примитивы Kubernetes (RBAC, namespaces, аудит).
Преимущества — и главный риск
Для вендоров это даёт возможность дифференцироваться без форка Kubernetes. Для внутренних команд — строить платформу на Kubernetes под свои нужды.
Риск в разрастании экосистемы: слишком много CRD, пересекающихся инструментов и непоследовательных соглашений. Управление — стандарты, владение, версии и правила депрекации — становится частью работы платформы.
Как эти решения сформировали современные платформы приложений
Ранние решения Kubernetes создали не просто планировщик контейнеров, а переиспользуемое ядро платформы. Поэтому многие современные внутренние developer platform (IDP) по сути «Kubernetes + опинионированные workflow'ы». Декларативная модель, контроллеры и единый API позволили строить более высокоуровневые продукты без повторного изобретения деплоя, согласования и обнаружения сервисов.
Kubernetes как общий control plane
Поскольку API — это поверхность продукта, вендоры и команды платформы стандартизируют один контрольный плоскость и строят разные UX поверх него: GitOps, мульти‑кластерный менеджмент, политики, каталог сервисов и автоматизацию деплоя. Это большая причина, почему Kubernetes стал общим знаменателем для cloud‑native платформ: интеграции ориентируются на API, а не на конкретный UI.
Что осталось сложным (Day‑2 реалии)
Даже при чистых абстракциях самая тяжёлая работа остаётся операционной:
- безопасность: идентичность, сетевые политики, секреты и доверие в цепочке поставок
- апгрейды: версии Kubernetes, CRD и аддоны, движущиеся с разной скоростью
- надёжность: отладка контроллеров, неверные конфиги и «шумные» соседи
Как оценивать платформу на базе Kubernetes
Задавайте вопросы, которые выявляют зрелость операций:
- Как обрабатываются апгрейды и какая история откатов?
- Что — стандартный Kubernetes, а что — проприетарные расширения?
- Какие guardrail'ы (политики, дефолты, шаблоны) предотвращают фатальные ошибки?
- Насколько наблюдаема система (события, логи, трейлы аудита) и кто отвечает за инциденты?
Хорошая платформа снижает когнитивную нагрузку без сокрытия control plane или затруднения escape hatches.
Одна практическая линза: помогает ли платформа командам перейти от «идея → рабочий сервис», не требуя от всех стать экспертами по Kubernetes с первого дня? Инструменты в категории «vibe‑coding» — например, Koder.ai — помогают, генерируя реальные приложения из чата (веб на React, бэкенд на Go с PostgreSQL, мобильные на Flutter) и позволяя быстро итеративно работать с возможностями вроде planning mode, snapshot'ов и откатов. Независимо от того, используете ли вы что‑то подобное или строите собственный портал, цель одна: сохранить сильные примитивы Kubernetes и снизить накладные расходы рабочих процессов вокруг них.
Основные выводы и практические уроки
Kubernetes может казаться сложным, но большая часть этой «странности» — сознательный выбор: набор небольших примитивов, которые можно комбинировать в разные типы платформ.
Развенчание двух распространённых заблуждений
Первое: «Kubernetes — это просто оркестрация Docker». Kubernetes не только про запуск контейнеров. Он про постоянное согласование желаемого состояния (чего вы хотите) с фактическим (что реально происходит) через падения, релизы и изменяющийся спрос.
Второе: «Если мы берём Kubernetes, то всё станет микросервисами». Kubernetes поддерживает микросервисы, но также подходит для монолитов, batch‑задач и внутренних платформ. Примитивы (Pod, Service, метки, контроллеры и API) нейтральны — архитектурный выбор остаётся за вами.
Откуда действительно растёт сложность
Трудности обычно связаны не с YAML или Pod'ами, а с сетью, безопасностью и много‑командным использованием: идентичность и доступ, управление секретами, политики, ingress, наблюдаемость, контроль цепочки поставок и создание guardrail'ов, чтобы команды могли безопасно релизить, не мешая друг другу.
Выводы на уровне решений, которые можно применить
При планировании опирайтесь на изначальные архитектурные допущения:
- отдавайте предпочтение декларативным рабочим потокам и автоматизации, которые умеют исправлять дрейф;
- используйте метки/селекторы, чтобы снижать связанность между командами и компонентами;
- рассматривайте API как продукт: версионирование, конвенции и явная ответственность важны.
Практический следующий шаг
Сопоставьте ваши реальные требования с примитивами Kubernetes и слоями платформы:
-
Ворклоады → Pod/Deployment/Job
-
Связность → Service/Ingress
-
Операции → контроллеры, политики и наблюдаемость
Если вы оцениваете или стандартизируете, запишите эту карту и обсудите её со стейкхолдерами — затем стройте платформу инкрементально, закрывая реальные пробелы, а не поддаваясь трендам.
Если вам важно ускорить стадию «build» (а не только «run»), подумайте, как ваш delivery‑workflow превращает намерение в деплойемые сервисы. Для некоторых команд это набор кураторских шаблонов; для других — AI‑помощник вроде Koder.ai, который генерирует рабочую заготовку и даёт код для дальнейшей кастомизации — при этом платформа всё ещё использует базовые архитектурные решения Kubernetes внизу.