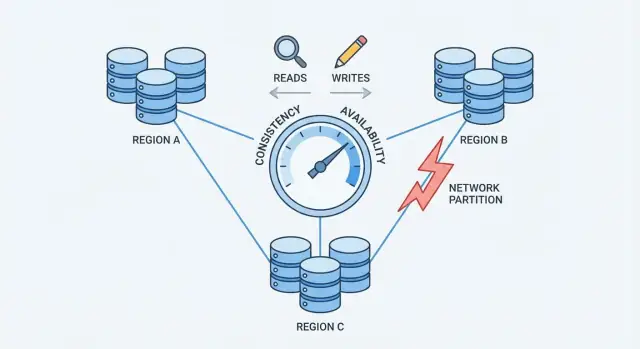
Что означают согласованность и доступность на практике
Когда база данных разделена между несколькими машинами (репликами), вы получаете скорость и устойчивость — но при этом возникают периоды, когда эти машины не полностью согласованы или не могут надёжно общаться друг с другом.
Согласованность (простое значение)
Согласованность означает: после успешной записи все дальнейшие чтения возвращают одно и то же значение. Если вы обновили email в профиле, следующее чтение — независимо от того, к какой реплике вы обратились — возвращает новый адрес.
На практике системы, которые отдают приоритет согласованности, могут задерживать или отклонять некоторые запросы во время сбоев, чтобы не возвращать конфликтующие ответы.
Доступность (простое значение)
Доступность означает: система отвечает на каждый запрос, даже если некоторые серверы упали или отключены. Вы можете не получить самые свежие данные, но вы получите ответ.
На практике системы, ориентированные на доступность, могут принимать записи и обслуживать чтения даже когда реплики рассогласованы, а затем синхронизировать различия позже.
Что означает этот компромисс для реальных приложений
«Компромисс» значит, что вы не можете одновременно максимизировать обе цели во всех сценариях сбоев. Если реплики не могут координироваться, база данных должна либо:
- Ждать/отказывать в части запросов, чтобы защитить единую согласованную правду (приоритет согласованности), или
- Продолжать отвечать пользователям, даже рискуя устаревшими или конфликтующими данными (приоритет доступности)
Простой пример: корзина покупок vs банковский перевод
- Корзина покупок: если количество товаров в корзине на другом устройстве ненадолго покажет на один товар меньше, это неприятно, но обычно допустимо. Многие команды предпочитают большую доступность и затем делают синхронизацию.
- Банковский перевод: если вы перевели $500, и баланс временно показывает два разных значения, это серьёзная проблема. Здесь более сильная согласованность часто стоит редких сообщений «повторите попытку».
Нет единственно лучшего выбора
Правильный баланс зависит от того, какие ошибки вы готовы терпеть: кратковременный простой или кратковременное неверное/устаревшее состояние. Большинство систем выбирают компромисс и явно документируют его.
Почему распределение меняет правила
База данных «распределена», когда она хранит и обслуживает данные с нескольких машин (узлов), которые координируются по сети. Для приложения это всё ещё может выглядеть как одна база — но под капотом запросы могут обслуживаться разными узлами в разных местах.
Репликация: почему команды добавляют узлы
Большинство распределённых баз реплицируют данные: одна и та же запись хранится на нескольких узлах. Это делают чтобы:
- поддерживать сервис в работе, если машина умирает
- уменьшать задержку, обслуживая пользователей с ближайшего узла
- масштабировать чтения (а иногда и записи) по большему количеству ресурсов
Репликация мощна, но сразу встает вопрос: если две ноды имеют копию одних и тех же данных, как гарантировать, что они всегда согласятся?
Частичный отказ — норма, а не исключение
На одной машине «вниз» обычно очевидно: машина либо работает, либо нет. В распределённой системе отказ часто частичный. Одна нода может быть жива, но медленна. Сетевой канал может терять пакеты. Целый стэк может потерять связь, в то время как остальная кластер продолжает работать.
Это важно, потому что узлы не могут мгновенно узнать, действительно ли другой узел упал, временно недоступен или просто задерживается. Пока они решают, что делать, им всё равно нужно принимать решение по входящим чтениям и записям.
Гарантии меняются, когда связь не гарантирована
На одной сервере есть один источник истины: каждое чтение видит последнюю успешную запись.
На нескольких узлах «последнее» зависит от координации. Если запись прошла на узле A, но узел B недоступен, должна ли база:
- блокировать запись до подтверждения B (чтобы защитить согласованность), или
- принять запись сразу (чтобы защитить доступность)?
Это напряжение — результат ненадёжных сетей — и именно поэтому распределение меняет правила.
Сетевые разрывы: ключевая проблема
Сетевой разрыв — это нарушение связи между узлами, которые должны работать как единая база. Узлы могут продолжать быть работоспособными, но не могут надёжно обмениваться сообщениями — из-за сломанного свитча, перегруженного канала, ошибки маршрутизации, неверного правила файервола или даже «шумного» соседа в облаке.
Почему разрывы неизбежны в масштабе
Когда система распространена по множеству машин (часто по стойкам, зонам или регионам), вы уже не контролируете каждый шаг между ними. Сети теряют пакеты, добавляют задержки и иногда разрываются на «острова». На малых масштабах такие события редки; в большом масштабе они регулярны. Даже короткое нарушение важно, потому что базе нужно постоянное согласование, чтобы понять, что произошло.
Как разрывы создают конфликтующие «последние» данные
Во время разрыва обе стороны продолжают получать запросы. Если пользователи пишут на обеих сторонах, каждая может принять обновление, которое другая не увидит.
Пример: узел A обновил адрес пользователя на «Новая улица». В то же время узел B обновил его на «Старая улица, кв. 2». Каждая сторона считает свою запись самой свежей — потому что нет способа в реальном времени свериться.
Симптомы, видимые пользователю
Разрывы не появляются в виде аккуратных сообщений об ошибке; они проявляются как сбивающее с толку поведение:
- Таймауты: база ждёт подтверждения от другой ноды для записи или чтения.
- Устаревшие чтения: вы обновили страницу, а видите старые данные, потому что попали на реплику, которая пропустила обновления.
- Split-brain: разные пользователи видят разные «правды», в зависимости от того, к какой стороне они попали.
Это именно то место, где принимается решение: когда сеть не может гарантировать связь, распределённая база должна выбрать — приоритезировать согласованность или доступность.
Теорема CAP без жаргона
CAP — краткий способ описать, что происходит, когда база распространяется на множество машин.
Три термина (простыми словами)
- Согласованность (C): после записи значение, любое последующее чтение возвращает это значение.
- Доступность (A): каждый запрос получает ненулевую ошибку-ответ (то есть система отвечает), даже если некоторые серверы испытывают проблемы.
- Устойчивость к разделению сети (P): система продолжает работать, даже если сеть разделяется и узлы не могут надёжно общаться.
Главный вывод
Когда нет разрыва, многие системы выглядят и согласованными, и доступными.
Когда есть разрыв, нужно выбрать, что приоритетно:
- Выбираете согласованность: отклонять или задерживать часть запросов, пока серверы не договорятся.
- Выбираете доступность: принимать запросы на каждой стороне, даже если ответы временно расходятся.
Простой временной сценарий
- 10:00 Клиент записывает
balance = 100 на сервер A.
- 10:01 Сетевой разрыв: сервер A не может достучаться до сервера B.
- 10:02 Клиент читает с сервера B.
- Если вы приоритетите согласованность, сервер B должен отказать или ждать.
- Если вы приоритетите доступность, сервер B отвечает, но может вернуть
balance = 80.
Распространённое заблуждение
CAP не говорит «навсегда выбирай два». Он говорит: во время разрыва вы не можете одновременно обеспечить и Согласованность, и Доступность. Вне разрывов многие системы близки к обеим целям — до следующего сетевого инцидента.
Выбор согласованности: что вы получаете и что теряете
Выбирая согласованность, система отдаёт приоритет тому, чтобы «все видели одну правду», в ущерб тому, чтобы «всегда отвечать». На практике это обычно означает сильную согласованность, часто называемую линеаризуемостью: после подтверждённой записи любое последующее чтение (из любой реплики) возвращает это значение, как если бы был единственный актуальный копия.
Что происходит во время разрыва
Когда сеть разделяется и реплики не могут координироваться, сильно согласованная система не сможет безопасно принимать независимые обновления с обеих сторон. Чтобы защитить корректность, она обычно:
- Блокирует запросы, ожидая координации, или
- Отклоняет запросы (возвращает ошибки/таймауты), если не может достать требуемые реплики/лидера.
С точки зрения пользователя, это может выглядеть как простой, хотя некоторые машины всё ещё работают.
Что вы получаете
Главное преимущество — проще рассуждать о поведении. Код приложения может вести себя так, будто он общается с одной базой, а не с набором реплик, которые могут расходиться. Это уменьшает «странные моменты», такие как:
- чтение старых данных сразу после успешного обновления
- видение двух разных значений для одной записи в зависимости от реплики
- потеря инвариантов (например, перепродажа товара) из-за конкурентных конфликтующих записей
Также это облегчает аудит, биллинг и другие сценарии, где важна корректность с первого раза.
Что вы теряете
Согласованность имеет реальные издержки:
- Более высокая задержка: многие операции ждут координации (часто между машинами или регионами).
- Больше ошибок при сбоях: разрывы, медленные реплики или проблемы лидера могут приводить к таймаутам или «повторите позже».
Если продукт не терпит отказов запросов во время частичных сбоев, сильная согласованность может показаться дорогой — даже если она и обеспечивает корректность.
Выбор доступности: что вы получаете и что теряете
Быстро прототипируйте варианты CAP
Создайте небольшой распределённый рабочий процесс в чате и посмотрите, как выбор консистентности влияет на поведение.
Выбирая доступность, вы оптимизируете под простое обещание: система отвечает, даже когда часть инфраструктуры больна. «Высокая доступность» не означает «никаких ошибок совсем» — это значит, что большинство запросов всё ещё получают ответ во время падения нод, перегрузок или разрывов сети.
Что происходит при разрыве сети
Когда сеть разделяется, реплики не могут уверенно общаться. Система, ориентированная на доступность, обычно продолжает обслуживать трафик с той части, до которой можно достучаться:
- Чтения отвечают локально из текущих данных реплики.
- Записи принимаются локально и реплицируются/применяются позже, когда связь восстановится.
Это позволяет приложениям продолжать работу, но значит, что разные реплики могут временно принимать разные «правды».
Что вы получаете
Вы получаете лучшую доступность: пользователи всё ещё могут просматривать товары, добавлять в корзину, оставлять комментарии или записывать события, даже если регион изолирован.
Также более плавный пользовательский опыт при нагрузке. Вместо таймаутов приложение может продолжать работать («обновление сохранено») и синхронизироваться позже. Для многих потребительских и аналитических нагрузок такой компромисс оправдан.
Что вы теряете
Цена — база может возвращать устаревшие чтения. Пользователь обновил профиль на одной реплике, затем сразу прочитал с другой и не увидел изменения.
Также риск конфликтов записей. Два пользователя (или один и тот же в разных местах) могут обновить одну и ту же запись на разных сторонах разрыва. При восстановлении система должна будет разрешать расхождения. В зависимости от правил одна запись может «выиграть», поля могут слиться, либо потребуется логика приложения.
Дизайн в пользу доступности принимает временные расхождения и вкладывается в механизмы обнаружения и исправления потом.
Кворумы и голосование: средняя линия
Кворумы — практическая техника голосования, которую многие реплицированные базы используют для балансирования согласованности и доступности. Вместо того чтобы полагаться на одну реплику, система требует согласия «достаточного» числа реплик.
Идея (N, R, W)
Кворумы часто описывают тремя числами:
- N: сколько реплик хранит данные
- W: сколько реплик должны подтвердить запись, чтобы считать её успешной
- R: сколько реплик опрашивается при чтении
Общее правило: если R + W > N, то каждое чтение пересекается с последней успешной записью хотя бы на одной реплике, что снижает шанс чтения устаревших данных.
Интуитивные примеры
Если у вас N=3 реплики:
- Одиночная реплика (R=1, W=1): быстро и очень доступно, но легко попасть на устаревшую реплику.
- Голосование большинства (R=2, W=2): запись должна дойти до 2 реплик, чтение опрашивает 2 реплики. Это увеличивает вероятность увидеть новое значение, поскольку множества чтения и записи перекрываются.
Некоторые системы требуют W=3 (всем репликам) для более сильной согласованности, но это повышает риск отказов записи при медленной или недоступной реплике.
Что кворумы делают при разрывах
Кворумы не устраняют проблему разрывов — они определяют, кто может продолжать работу. Если сеть разделилась 2–1, сторона с 2 репликами может удовлетворить R=2 и W=2, а изолированная одиночная реплика не сможет. Это уменьшает количество конфликтующих обновлений, но означает, что часть клиентов может видеть ошибки или таймауты.
Компромиссы
Кворумы обычно дают большую задержку (надо связаться с несколькими узлами), больший стоимость (межузловой трафик) и более сложное поведение при отказах (таймауты выглядят как недоступность). Зато вы получаете регулируемую среднюю линию: можно настроить R и W ближе к свежим чтениям или к успешным записям, в зависимости от приоритетов.
Отложенная согласованность и типичные аномалии
Отложенная (eventual) согласованность означает, что реплики временно могут быть не в согласии, при условии что со временем они сойдутся к одному значению.
Конкретная аналогия
Представьте сеть кофеен, обновляющих общий знак «распродано» для булочки. Один магазин пометил «распродано», но обновление добирается до других магазинов через пару минут. В промежутке другой магазин всё ещё показывает «в наличии» и может продать последний экземпляр. Система не «сломана» — просто обновления догоняют.
Общие наблюдаемые аномалии
Когда данные ещё реплицируются, клиенты могут заметить неожиданные поведения:
- Устаревшие чтения: вы читаете старые данные с реплики, которая ещё не получила запись.
- Проблемы «прочитал — значит написал» (read-your-writes): вы записали обновление, а затем сразу прочитали с другой реплики и не увидели своё изменение.
- Непоследовательность порядка: два обновления приходят в разном порядке на разных репликах, временно создавая несогласованность.
Техники, которые помогают репликам сходиться
Системы с отложенной согласованностью часто применяют фоновые механизмы:
- Read repair: если чтение обнаруживает несоответствие реплик, система обновляет отставшие реплики в фоне.
- Hinted handoff: если реплика недоступна, другая нода временно хранит «подсказку» о записи и пересылает её позже.
- Anti-entropy (синхронизация): периодическая сверка (например, через деревья Меркла) для поиска и исправления расхождений.
Когда eventual consistency подходит
Подходит, когда важнее доступность, чем абсолютная актуальность: ленты активности, счётчики просмотров, рекомендации, кеши/профили, логи/телеметрия и другие данные, где «правильно через момент» — приемлемо.
Разрешение конфликтов: как сходятся разные записи
Спланируйте архитектуру в чате
Спроектируйте модель данных, эндпоинты и правила консистентности до написания реализации.
Когда база принимает записи на нескольких репликах, могут возникать конфликты: два или более обновления одного и того же элемента, сделанные независимо на разных репликах до синхронизации.
Классический пример: пользователь меняет адрес доставки на одном устройстве и номер телефона на другом. Если каждое обновление попало на разную реплику во время разрыва, система должна решить, что считать «истиной» после обмена данными.
Last-write-wins (LWW): просто, но рискованно
Многие системы начинают с last-write-wins: обновление с самым свежим timestamp перетирает остальные.
Привлекает простотой и скоростью вычисления. Минус в том, что оно может тихо потерять данные. «Новее» побеждает, и тогда более старое, но важное изменение может быть утеряно — даже если обновления затрагивали разные поля.
Кроме того, это предполагает доверие к часам. Смещение времени между машинами (clock skew) может привести к тому, что «неправильное» обновление победит.
Хранение истории: векторы версий и подобные идеи
Более безопасная обработка конфликтов обычно требует отслеживания причинно-следственной истории.
Концептуально векторы версий (version vectors) добавляют небольшой фрагмент метаданных к каждой записи, который резюмирует «какая реплика видела какие обновления». При обмене версиями база может определить, одна версия включает другую (нет конфликта), или они разошлись (нужна резолюция).
Некоторые системы применяют логические метки времени (например, часы Лампорта) или гибридные логические часы, чтобы меньше полагаться на wall-clock, но всё ещё иметь подсказку порядка.
Слияние вместо перезаписи
Когда конфликт обнаружен, есть варианты:
- Слияния на уровне приложения: приложение решает, как объединять поля, спрашивает пользователя или сохраняет обе версии для проверки.
- CRDT (Conflict-Free Replicated Data Types): структуры данных, спроектированные так, чтобы автоматически и детерминированно сливаться (полезно для счётчиков, множеств, совместного редактирования текста и т.д.). Они позволяют избегать «победителя забирает всё» и остаются высокодоступными.
Лучший подход зависит от того, что значит «правильно» для ваших данных — иногда потеря записи допустима, а иногда это критическая ошибка.
Как выбирать для вашего случая использования
Выбор позы согласованности/доступности — это не философский спор, а продуктовый выбор. Начните с вопроса: какова цена ошибки на мгновение, и какова цена ответа «повторите позже»?
Соотнесите бизнес-риски с потребностями согласованности
Некоторые домены требуют единого авторитетного ответа при записи, потому что «почти правильно» — всё ещё неправильно:
- Деньги и биллинг: двойные списания, овердрафты и возвраты обычно требуют сильной согласованности.
- Идентификация и права доступа: логин, сброс пароля, управление ролями должны избегать поведения split-brain.
- Инвентарь и ёмкость: если недопустимо перепродать (билеты, ограниченные запасы), склоняйтесь к согласованности или проектируйте явные резервации.
Если влияние временного рассогласования невелико или обратимо, можно чаще отдавать приоритет доступности.
Решите, сколько устаревших данных вы готовы терпеть
Многие пользовательские сценарии нормально работают со слегка устаревшими чтениями:
- Ленты и таймлайны: пост, появившийся через пару секунд — обычно нормально.
- Аналитика и дашборды: пакетные и отложенные числа ожидаемы.
- Кеши и поисковые индексы: пользователи мирятся с «ещё не обновлено», если это быстро и стабильно.
Будьте конкретны: сколько устаревания допустимо — секунды, минуты или часы. Этот бюджет времени определяет ваши выборы репликации и кворума.
Выберите режим отказа, который пользователи будут терпеть меньше всего
Когда реплики не могут договориться, обычно получается один из трёх UX-исходов:
- Загрузка / ожидание (приоритет корректности — может казаться медленно)
- Ошибка / повтор (честно, но разрушительно)
- Устаревший результат (плавно, но иногда удивляет)
Выбирайте наименее вредный вариант для каждой функции, а не глобально для всей системы.
Быстрый чек-лист
Склоняйтесь к C (согласованности) если: неправильный результат создаёт финансовый/юридический риск, угрозу безопасности или необратимые действия.
Склоняйтесь к A (доступности) если: пользователи ценят отзывчивость, устаревшие данные допустимы, и конфликты можно безопасно разрешить позже.
Если не уверены, раздельте систему: храните критичные записи с сильной согласованностью, а производные представления (фиды, кеши, аналитика) оптимизируйте под доступность.
Шаблоны проектирования, снижающие боль от компромисса
Проверьте длительные рабочие процессы
Прототипируйте saga-воркфлоу с компенсационными действиями, чтобы аккуратно обрабатывать частичные отказы.
Вам редко нужно выбирать одну «настройку согласованности» для всей системы. Многие современные распределённые базы позволяют выбирать уровень согласованности на операцию — и умные приложения используют это, чтобы сохранить UX без иллюзии о том, что компромисса не существует.
Используйте уровни согласованности на уровне операции
Относитесь к согласованности как к регулятору, который вы настраиваете в зависимости от действия пользователя:
- Критичные обновления (платежи, уменьшение инвентаря, смена пароля): используйте более сильную согласованность (например, кворум/линеаризуемые записи).
- Некритичные чтения (ленты, дашборды, «последний визит»): разрешайте слабые чтения (локальные/одна реплика/отложенные) ради скорости и устойчивости.
Так вы не платите высокой ценой согласованности за всё подряд, но защищаете важные операции.
Смешивайте сильное и слабое в одном потоке
Обычный паттерн: сильные записи, слабые чтения:
- Записывайте с жёстким уровнем, чтобы иметь авторитетную запись.
- Читайте с более слабым уровнем, и если вы обнаружите несоответствие (пропавший элемент, устаревший счётчик), делайте повторное чтение с сильным уровнем или показывайте отметку «ещё обновляется».
Иногда наоборот: быстрые записи (очередные/отложенные) + сильные чтения при подтверждении результата ("Заказ оформлен?").
Проектируйте для повторов: идемпотентность
Когда сети шатаются, клиенты повторяют запросы. Делайте повторы безопасными с помощью idempotency keys, чтобы «отправить заказ» дважды не создало два заказа. Храните и повторно используйте первый результат, когда видите тот же ключ.
Длинные рабочие процессы: саги и компенсации
Для многозадачных действий через сервисы используйте сагу: каждый шаг имеет соответствующее компенсирующее действие (возврат денег, освобождение резерва, отмена доставки). Это делает систему восстанавливаемой, даже когда части временно рассогласованы или падают.
Тестирование и наблюдаемость для баланса согласованности и доступности
Вы не сможете управлять компромиссом, если не видите его. Проблемы в продакшене часто выглядят как «случайные отказы», пока вы не добавите нужные метрики и тесты.
Что измерять (и зачем)
Начните с небольшой группы метрик, которые напрямую отражают влияние на пользователя:
- Задержка (p50/p95/p99): следите за всплесками во время переключений лидера, кворумных повторов или отказов.
- Процент ошибок: разделяйте «жёсткие» ошибки (таймауты, 5xx) и «мягкие» ошибки (ответ из fallback, частичные результаты).
- Доля устаревших чтений: процент чтений, возвращающих данные старше вашего целевого окна (например, старше 2 секунд).
- Частота конфликтов: как часто конкурентные записи требуют разрешения (включая перезаписи LWW).
Если возможно, тэгируйте метрики по режиму согласованности (кворум vs локал) и по региону/зоне, чтобы заметить, где поведение расходится.
Тестируйте разрывы намеренно
Не ждите реального сбоя. В стейджинге проводите хаос-эксперименты, симулируя:
- потерю пакетов и высокие задержки между репликами
- недоступность одного региона
- частичные разделения, где только некоторые ноды могут общаться
Проверяйте не просто «система остаётся в сети», а какие гарантии сохраняются: остаются ли чтения свежими, блокируются ли записи, получают ли клиенты понятные ошибки?
Алерты, которые ловят компромисс рано
Добавьте оповещения для:
- репликационной задержки, превышающей допустимое окно устаревания
- сбоев кворума (недостаточно реплик) и роста числа повторов
- увеличения числа конфликтов или накопления бэклога на reconciler
Наконец, делайте гарантии явными: документируйте, что ваша система обещает в норме и при разрывах, и обучайте команды продукта и поддержки, что пользователи могут увидеть и как реагировать.
Быстрая проверка вариантов CAP без полной переделки
Если вы исследуете эти компромиссы в новом продукте, полезно валидировать предположения рано — особенно про режимы отказа, поведение повторов и как выглядит «устаревшее» в UI.
Практический подход — прототипировать небольшой вариант рабочего процесса (путь записи, путь чтения, повторы/идемпотентность и джоб по согласованию) до полной архитектуры. С помощью инструментов для быстрой разработки команд могут быстро собрать веб-приложение и бэкенд, пробовать разные паттерны согласованности (например, строгие записи + ослабленные чтения) и оценить UX без больших затрат. Когда прототип соответствует нужному поведению, его можно развивать в продакшн.