Что означает «распределённый SQL» (без хайпа)
«Распределённый SQL» — это база данных, которая выглядит и ощущается как традиционная реляционная СУБД — таблицы, строки, JOINы, транзакции и SQL — но спроектирована для работы как кластер на многих машинах (и часто в разных регионах), при этом ведя себя как одна логическая база данных.
Это сочетание важно, потому что система стремится одновременно дать три вещи:
- SQL и реляционную модель: знакомые схемы, ограничения и инструменты запросов.
- Горизонтальное масштабирование: добавляйте узлы для увеличения мощности, а не «покупайте более мощный сервер».
- Сильную согласованность: чтения и записи следуют понятным транзакционным правилам, даже когда данные распределены.
Между классическими RDBMS и NoSQL
Классическая RDBMS (PostgreSQL, MySQL) обычно проще в эксплуатации, когда всё живёт на одном primary-узле. Чтения можно масштабировать репликами, но масштабирование записей и выживание при региональных сбоях обычно требует дополнительной архитектуры (шардинг, ручной фейловер, сложная логика в приложении).
Многие NoSQL-системы пошли противоположным путём: сначала доступность и масштаб, иногда ценой ослабления гарантий согласованности или упрощения модели запросов.
Распределённый SQL ищет средний путь: сохранить реляционную модель и ACID‑транзакции, но автоматически распределять данные для обработки роста и сбоев.
Что он пытается решить
Распределённые SQL‑базы созданы для задач вроде:
- Глобальных приложений с пользователями в нескольких регионах, где важны и латентность, и время работы.
- Высокой доступности без сложных ручных процедур фейловера.
- Ростa со временем, когда хочется расширять мощность поэтапно, сохраняя единый интерфейс базы данных.
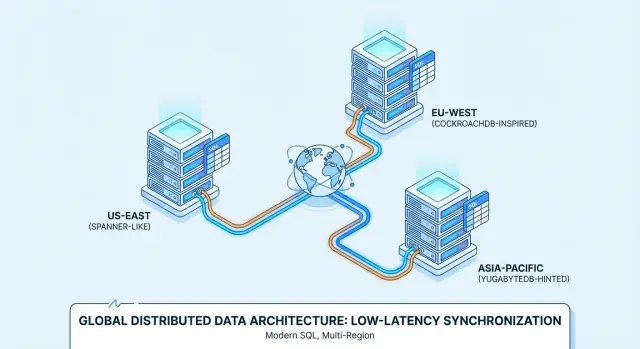
Именно поэтому такие продукты, как Google Spanner, CockroachDB и YugabyteDB, часто оценивают для мульти-региональных развертываний и всегда‑доступных сервисов.
Установите ожидания (это не по умолчанию)
Распределённый SQL не обязательно «лучше» во всех случаях. Вы принимаете больше движущихся частей и другие ограничения по производительности (сетевая задержка, консенсус, межрегиональные RTT) в обмен на устойчивость и масштаб.
Если ваша нагрузка умещается на одной хорошо управляемой базе с простой репликацией, обычная RDBMS может быть проще и дешевле. Распределённый SQL оправдывает себя, когда альтернатива — собственный шардинг, сложный фейловер или бизнес‑требования, требующие мульти-региональной согласованности и доступности.
Как устроен распределённый SQL внутри
Распределённый SQL должен ощущаться как знакомая SQL‑база, при этом хранить данные на многих машинах (и часто в нескольких регионах). Сложность в координации множества компьютеров, чтобы они вели себя как единая надёжная система.
Репликация + консенсус: как узлы приходят к согласию
Каждый кусок данных обычно копируется на несколько узлов (репликация). Если один узел падает, другая копия всё ещё может обслуживать чтения и принимать записи.
Чтобы реплики не расходились, системы распределённого SQL используют протоколы консенсуса — чаще всего Raft (CockroachDB, YugabyteDB) или Paxos (Spanner). Вкратце, консенсус означает:
- Одна реплика действует как «лидер» для группы реплик.
- Записи идут через лидера.
- Лидер подтверждает запись только после того, как большинство реплик подтвердят её.
Это «голосование большинства» и даёт вам сильную согласованность: после фиксации транзакции клиенты не увидят старую версию данных.
Шардинг/партиционирование: где живут данные
Ни одна машина не вмещает всё, поэтому таблицы разбиваются на более мелкие куски — шарды/партиции (Spanner называет их splits; CockroachDB — ranges; YugabyteDB — tablets).
Каждая партиция реплицируется (через консенсус) и размещается на определённых узлах. Размещение не случайно: его можно задавать политиками (например, хранить записи клиентов из ЕС в регионах ЕС или держать горячие партиции на быстрых узлах). Хорошее размещение уменьшает сетевые обходы и делает производительность более предсказуемой.
Транзакции между узлами (и почему это добавляет задержку)
В однoузловой базе транзакция часто подтверждается локальной записью на диск. В распределённом SQL транзакция может затронуть несколько партиций — возможно на разных узлах.
Безопасный коммит обычно требует дополнительной координации:
- Блокировок или валидации данных на участвующих партициях
- Репликации записей через консенсус (подтверждения большинства)
- Финализации решения о фиксации, чтобы все участники согласились
Эти шаги вводят дополнительные сетевые круги, поэтому распределённые транзакции чаще добавляют задержку — особенно если данные распределены по регионам.
Мульти-региональное поведение: чтения и записи с учётом локальности
Когда развертывание охватывает регионы, системы стремятся держать операции «рядом» с пользователями:
- Чтения с учётом локальности могут обслуживаться ближайшими репликами, когда это безопасно.
- Записи с учётом локальности могут направляться к лидерам в выбранном регионе или лидеры располагаются ближе к основным писателям.
Это и есть балансировка в мульти-региональной конфигурации: можно оптимизировать локальную отзывчивость, но сильная согласованность по большим расстояниям всё равно потребует сетевых затрат.
Когда это действительно нужно (а когда нет)
Прежде чем выбирать распределённый SQL, проверьте базовые потребности. Если у вас один основной регион, предсказуемая нагрузка и небольшой операционный состав, обычная реляционная база (или управляемый Postgres/MySQL) обычно быстрее вывести фичи в продакшен. Часто одну‑региональную установку можно растянуть с помощью реплик для чтения, кэшей и аккуратной схемы/индексов.
Яркие триггеры: когда распределённый SQL оправдан
Распределённый SQL стоит серьёзно рассматривать, когда выполняется хотя бы одно (или несколько) из:
- У вас реальные пользователи в нескольких регионах, и вы хотите базу данных рядом с ними без сложного шардинга на уровне приложения.
- Требования к доступности высоки (нужно пережить сбои зоны/региона), и один регион — неприемлемый риск.
- Объёмы данных или пропускная способность записей превышают вертикальное масштабирование, и вы хотите горизонтальное масштабирование с сохранением SQL‑семантики.
- Нужна сильная согласованность между узлами/регионами для критичных транзакций (заказы, балансы, бронирования) без стыковки нескольких систем.
- Соответствие (compliance) требует географического размещения данных при сохранении единой логики работы.
Анти‑триггеры: когда обычно не стоит переходить
Распределённые системы добавляют сложность и стоимость. Будьте осторожны, если:
- Команда маленькая и нет времени изучать новые режимы отказов и операционные паттерны.
- Трафик низкий или спорадический, и вы вряд ли перерастёте однорегиональную базу.
- Бюджет задержки очень жёсткий для одиночных записей и нельзя терпеть накладные расходы консенсуса.
- Нагрузка аналитическая (большие сканы, сложные отчёты). Лучше отделить OLTP от аналитики.
Короткая чек-лист‑решение
Если на два или более пунктов вы ответите «да», распределённый SQL стоит изучить:
- Нужны ли вам мульти-региональные пользователи с согласованными данными?
- Нужен ли автоматический фейловер между зонами/регионами?
- Постоянно ли масштаб становится проблемой?
- Привёл бы шардинг к бо́льшим расходам на инженерию, чем сама база?
- Нужно ли обеспечивать размещение данных по регионам в рамках единой модели эксплуатации?
Согласованность, доступность и задержка: основные компромиссы
Распределённый SQL не даёт всего сразу — реальные системы заставляют выбирать, особенно когда регионы плохо связаны.
CAP, объяснённый для продуктовых решений
Представьте сетевой разрыв как «связь между регионами ненадёжна или пропала». В этот момент база может приоритизировать:
- Согласованность: все видят одно и то же актуальное состояние (или операция не выполняется).
- Доступность: приложение продолжает принимать чтения/записи в каждом регионе (хотя ответы могут временно расходиться).
Системы распределённого SQL обычно строятся с приоритетом на согласованность для транзакций. Это то, чего команды хотят — до тех пор, пока при разрыве операции не начнут ждать или падать.
Сильная согласованность (почему важны деньги и инвентарь)
Сильная согласованность означает: после фиксации транзакции любое последующее чтение вернёт это значение — нет «сработало в одном регионе, но не в другом». Это критично для:
- Платежей и балансов (исключает двойное списание или некорректные итоги)
- Инвентаря / бронирований (предотвращает перепродажу последнего товара)
Если обещание продукта — «когда мы подтвердили, это действительно так», сильная согласованность — не роскошь, а требование.
Read‑your‑writes и изоляция в реальных приложениях
Практически важны два поведения:
- Чтение своих записей (read‑your‑writes): после обновления профиля или оформления заказа следующий экран должен показывать новое состояние, а не старую реплику.
- Изоляция транзакций: определяет, как параллельные действия взаимодействуют. При более сильной изоляции вы избегаете тонких багов вроде двух клиентов, успешно забронировавших одно и то же место.
Стоимость задержки от межрегионального консенсуса
Сильная согласованность через регионы обычно требует консенсуса (несколько реплик должны согласиться до коммита). Если реплики рассеяны по континентам, ограничение скорости — физика: каждая межрегиональная запись может добавлять десятки — сотни миллисекунд.
Простая формула: больше географической защиты и корректности чаще означает большую задержку на запись, если вы не оптимизируете размещение данных и места фиксации транзакций.
Spanner vs CockroachDB vs YugabyteDB: практический обзор
Google Spanner — распределённая SQL‑база, предлагается преимущественно как управляемый сервис в Google Cloud. Она спроектирована для мульти‑региональных развёртываний, где нужен единый логический каталог с репликацией по узлам и регионам. Spanner поддерживает два варианта диалекта SQL — GoogleSQL (родной) и PostgreSQL‑совместимый диалект — поэтому переносимость зависит от выбранного диалекта и используемых возможностей.
CockroachDB — распределённая SQL‑база, стремящаяся к опыту команд, привыкших к PostgreSQL. Она использует PostgreSQL wire protocol и поддерживает большую часть SQL‑функционала в стиле Postgres, но не является полным битвом-заменителем (некоторые расширения и крайние поведения различаются). Можно запускать как управляемый сервис (CockroachDB Cloud) или самостоятельно в своей инфраструктуре.
YugabyteDB — распределённая СУБД с PostgreSQL‑совместимым SQL API (YSQL) и дополнительным Cassandra‑совместимым API (YCQL). Как и CockroachDB, её часто выбирают команды, желающие ergonomics Postgres при масштабировании на узлы и регионы. Доступна как self-hosted, так и managed (YugabyteDB Managed) с типичными развертываниями от однорегиональной HA до мульти-региональных конфигураций.
Managed vs self-hosted: что меняется
Управляемые сервисы снижают операционную работу (обновления, бэкапы, интеграции мониторинга), тогда как self-hosted даёт больше контроля над сетью, типами инстансов и физическим местоположением данных. Spanner чаще используется как managed в GCP; CockroachDB и YugabyteDB встречаются и в managed, и в self-hosted вариантах, включая мульти‑клауд и on‑prem.
Совместимость SQL на практике
Все три говорят на «SQL», но повседневная совместимость зависит от выбора диалекта (Spanner), покрытия возможностей Postgres (CockroachDB/YugabyteDB) и от того, полагается ли приложение на конкретные расширения, функции или семантику транзакций Postgres.
Планирование и раннее тестирование запросов, миграций и поведения ORM окупятся — не стоит предполагать полную взаимозаменяемость.
Кейc: глобальный SaaS с региональными пользователями
Практикуйте отказоустойчивость заранее
Разверните тестовую среду и проводите тренировки отказов на реалистичном трафике.
Классический сценарий для распределённого SQL — B2B SaaS с клиентами в Северной Америке, Европе и Азиатско‑Тихоокеанском регионе: инструменты поддержки, HR‑платформы, аналитические панели или маркетплейсы.
Требование бизнеса простое: пользователи хотят «локальное» отклик, а компания хочет единую логическую базу, доступную всегда.
Размещение данных и per‑tenant правила
Многие SaaS‑команды сталкиваются со смешанными требованиями:
- Клиенты из ЕС ожидают, что их данные останутся в ЕС (GDPR, договорные обязательства).
- Некоторые требуют хранения внутри страны (напр., Германия, Австралия, Сингапур).
- Другие не возражают, но хотят низкую задержку.
Распределённый SQL это моделирует аккуратно через локализацию на уровне тенантов: разместите первичные данные каждого клиента в определённом регионе (или наборе регионов), сохраняя общую схему и модель запросов. Так вы избегаете раздутой архитектуры «по одной базе на регион», при этом соблюдая требования по размещению.
Минимизация задержки: региональные чтения и размещение записей
Чтобы приложение было быстрым, обычно стремятся к:
- Региональным чтениям: обслуживать читаемые, тяжёлые запросы с реплик, близких к пользователю.
- Размещению записей: ставить лидера записи в регион, откуда чаще всего происходят записи.
Это важно, потому что межрегиональные RTT доминируют в восприятии задержки пользователем. Даже при сильной согласованности грамотный дизайн локальности гарантирует, что большинство запросов не платят межконтинентальную сетевую стоимость.
Операционные реалии
Технические преимущества работают только если эксплуатация остаётся управляемой. Для глобального SaaS планируйте:
- Онлайн‑изменения схемы, которые не блокируют таблицы по регионам.
- Миграции тенантов (перемещение тенанта между регионами с минимальным простоем).
- Мониторинг и алерты для задержек репликации, горячих точек, медленных запросов и инцидентов на уровне региона.
При хорошем исполнении распределённый SQL даёт единый продуктовый опыт, который при этом ощущается локальным — без разделения команды инженеров на «EU‑стек» и «APAC‑стек».
Кейc: финансовые потоки и журналы (ledgers)
Финансовые системы — это место, где «eventually consistent» может обернуться реальными потерями денег. Если клиент оформляет заказ, авторизация платежа проходит, а баланс обновляется — все эти шаги должны соглашаться на одну истину — немедленно.
Сильная согласованность важна, потому что она предотвращает ситуацию, когда два региона или два сервиса принимают «разумные» решения, приводящие к некорректному журналу.
Почему сильная согласованность обязательна
В типовом рабочем процессе — создать заказ → зарезервировать средства → захватить платёж → обновить баланс/ledger — нужны гарантии вроде:
- Нельзя пометить заказ как «оплачен», если захват платежа не прошёл.
- Баланс не должен уйти в минус из‑за гонки двух транзакций.
- Возврат не должен примениться дважды из‑за повторов рабочих задач.
Распределённый SQL подходит потому, что обеспечивает ACID‑транзакции и ограничения между узлами (и часто регионами), так что инварианты журнала сохраняются даже при отказах.
Идемпотентность и паттерны «нет двойного списания»
Интеграции с платёжными системами часто терпят повторы: таймауты, повторные вебхуки и повторная обработка задач — это нормально. База должна помочь сделать повторы безопасными.
Практический подход — сочетать идемпотентные ключи на уровне приложения с базовыми уникальными ограничениями:
- Храните
idempotency_key для каждой попытки/платежа.
- Добавьте уникальное ограничение на
(account_id, idempotency_key).
- Оборачивайте «создать запись платежа + применить проводки в журнал» в одну транзакцию.
Тогда вторая попытка станет безвредной no-op, а не двойным списанием.
Обработка всплесков без потери корректности
События продаж и расчёты по зарплате могут создавать резкие всплески записей (авторизации, захваты, переводы). С распределённым SQL вы можете масштабировать, добавляя узлы для увеличения пропускной способности записи, сохраняя модель согласованности.
Ключ — планировать горячие ключи (например, один мерчант со всем трафиком) и использовать схемные паттерны для распределения нагрузки.
Соответствие, аудит и хранение
Финансовые потоки часто требуют неизменяемых журналов, трассируемости (кто/что/когда) и предсказуемой политики хранения. Даже без перечисления конкретных регуляций, считайте, что вам понадобятся: append-only записи журнала, метки времени, контролируемый доступ и правила ретенции/архивации, не нарушающие возможность проведения аудита.
Кейc: инвентарь, бронирования и резервации
Симулируйте конфликты инвентаря
Создайте минимальное приложение бронирования и нагрузочно протестируйте конфликты доступа, горячие ключи и поведение согласованности.
Инвентарь и бронирования кажутся простыми, пока одна и та же дефицитная единица обслуживается в нескольких регионах: последний билет, лимитированное падение товара или номер отеля на конкретную ночь.
Сложность не в чтении доступности — а в предотвращении двух успешных заявок на один и тот же ресурс почти одновременно.
Откуда берутся конфликты
В мульти-региональной конфигурации без сильной согласованности каждый регион может временно думать, что товар доступен на основе немного устаревших данных. Если два пользователя оформляют покупку в разных регионах в этом окне, оба локально примут транзакцию и позже при согласовании возникнет конфликт.
Так происходит перепродажа: не потому что система «неправильная», а потому что ей временно позволено иметь расходящиеся истины.
Распределённый SQL часто выбирают здесь, потому что он может обеспечить единственный авторитетный результат для операций записи — «последнее место» действительно резервируется один раз, даже если запросы приходят из разных континентов.
Конкретные примеры
- Бронирование места: двое пользователей кликают одно и то же место. При сильной согласованности только одна транзакция зафиксируется; другая мгновенно упадёт и UI предложит обновление.
- Лимитированные дропы: 500 единиц поступают в продажу и тысячи пытаются оформить покупку. Нужна атомарная операция «декремент-и-выделить», а не попытка «лучшего усилия» с последующими возвратами.
- Бронирование отеля: единицей инвентаря является не просто комната, а room‑night. Перебронирование дат тяжело и дорого откатывать.
Паттерны, хорошо сочетающиеся с распределённым SQL
Hold + confirm: в транзакции размещаете временную бронь (reservation record), затем подтверждаете платёж во втором шаге.
Истечения: брони должны автоматически истекать (например, через 10 минут), чтобы инвентарь не блокировался при бросании корзины.
Транзакционный outbox: при подтверждении брони в той же транзакции записывайте строку «событие для отправки», затем асинхронно доставляйте его в почту, систему исполнения или шину сообщений — без риска «забронировано, но подтверждение не отправлено».
Вывод: если бизнес не может допустить двойного выделения в разных регионах, сильные транзакционные гарантии превращаются в фичу продукта, а не в техническую излишество.
Кейc: высокая доступность и восстановление после катастроф
Высокая доступность (HA) — хороший кейс для распределённого SQL, когда простой стоит дорого, непредсказуемые сбои недопустимы, и вы хотите, чтобы обслуживание было рутинным.
Цель — не «никогда не падать», а выполнение измеримых SLO (например, 99.9% или 99.99%) даже при падении узлов, зон или при обновлениях.
«Всегда в сети» на практике: SLO, обслуживание, отказы
Начните с перевода «всегда в сети» в измеримые ожидания: максимально допустимое ежемесячное время простоя, RTO и RPO.
Распределённые SQL‑системы могут продолжать принимать чтения/записи при многих распространённых отказах, но только если топология соответствует вашим SLO и приложение корректно обрабатывает транзиентные ошибки (повторы, идемпотентность).
Плановое обслуживание тоже важно. Rolling‑апдейты и замена инстансов проще, когда база может перемещать лидерство/реплики с затронутых узлов без остановки кластера.
Резервирование по зонам vs по регионам
Мульти‑зоновые развертывания защищают от отказа одной AZ/зоны и от многих аппаратных сбоев, при этом дают меньшие задержки и стоимость. Обычно этого достаточно, если соответствие и база пользователей преимущественно в одном регионе.
Мульти‑региональные варианты защищают от падения целого региона и поддерживают региональный фейловер. Цена — большая задержка на запись при строгой согласованности и более сложное планирование мощностей.
Ожидания по фейловеру (и тестирование game days)
Не рассчитывайте, что фейловер мгновенный и незаметный. Определите, что для вашего сервиса означает «фейловер»: краткие всплески ошибок? период только для чтения? несколько секунд повышенной задержки?
Проводите «game days», чтобы убедиться:
- Отключите узел, затем зону; проверьте метрики SLO и бюджет ошибок.
- Симулируйте сетевые разрывы и проверьте поведение лидеров/реплик.
- Практикуйте эвакуацию региона и измеряйте реальное RTO.
Репликация — не бэкап
Даже при синхронной репликации держите бэкапы и отрабатывайте восстановление. Бэкапы защищают от ошибок оператора (плохие миграции, случайные удаления), багов приложения и корупции, которая может реплицироваться.
Проверьте point‑in‑time recovery (если есть), скорость восстановления и возможность поднять чистую среду без вмешательства в продакшен.
Кейc: размещение данных и архитектуры, продиктованные соответствием
Требования размещения данных возникают, когда регуляции, контракты или внутренние политики диктуют, что определённые записи должны храниться (и иногда обрабатываться) внутри страны или региона.
Это может касаться персональных данных, медицинской информации, платёжных данных, государственных рабочих нагрузок или наборов данных, где контракт клиента определяет географию хранения.
Распределённый SQL часто рассматривают потому, что он может сохранить единую логическую базу, при этом физически размещая данные в разных регионах — без необходимости запускать отдельный стек приложения для каждой географии.
Почему правила размещения меняют дизайн БД
Если регулятор или клиент требует «данные остаются в регионе», недостаточно просто близких реплик. Возможно, нужно гарантировать, что:
- Первичная копия (или все копии) конкретных данных хранится только в разрешённых регионах
- Бэкапы и снимки также соответствуют правилам
- Операторы и сервисы вне региона не имеют доступа к сырому контенту
Это толкает команды к архитектурам, где местоположение — первоклассная забота, а не допущение.
Размещение по клиентам и контроль доступа (в общих чертах)
Популярный паттерн для SaaS — размещение по тенанту. Например: данные клиентов из ЕС закреплены за регионами ЕС, данные США — за регионами США.
В высокой абстракции это обычно сочетание:
- Правил размещения данных (куда можно помещать данные тенанта)
- Идентификации и контроля доступа (какие сервисы и люди могут читать)
- Шифрования и управления ключами (иногда с регионально ограниченными ключами)
Цель — сделать риск нарушения правил через оперативный доступ, восстановление из бэкапа или межрегиональную репликацию минимальным.
Юридические требования различаются — привлекайте юристов
Правила размещения и соответствия сильно варьируются по странам, отраслям и контрактам. Они меняются со временем.
Рассматривайте топологию базы как часть программы соответствия и валидируйте предположения с квалифицированным юрисконсультом (и, при необходимости, с аудиторами).
Как мульти-региональная топология влияет на отчётность и аналитику
Топологии, ориентированные на соблюдение размещения, усложняют «глобальные виды» бизнеса. Если данные клиентов заранее разделены по регионам, аналитика и отчётность могут:
- Нуждаться в региональных аналитических пайплайнах (вычисления выполняются там, где лежат данные)
- Использовать агрегированные экспорты (только разрешённые метрики покидают регион)
- Смириться с большей задержкой для глобальных дашбордов, поскольку глобальные запросы либо охватывают регионы, либо опираются на реплицированные/выведенные наборы данных
На практике многие команды отделяют операционные рабочие нагрузки (строго согласованные, с учётом размещения) от аналитики (региональные хранилища или строго управляемые агрегаты), чтобы упростить соблюдение требований, не замедляя повседневную отчётность.
Планирование затрат и производительности для распределённого SQL
Спланируйте топологию
Спланируйте регионы, тенантов и правила размещения данных прежде чем писать миграции.
Распределённый SQL может спасти вас от болезненных простоев и региональных ограничений, но по умолчанию он редко экономит деньги. Планирование заранее помогает избежать оплаты страховки, которая вам не нужна.
Основные драйверы затрат
Большинство бюджетов делится на четыре блока:
- Узлы (вычисления): платите за поддержание нескольких реплик онлайн — часто 3+ на регион — плюс запас для фейловера. Мульти-региональные дизайны обычно требуют больше свободных мощностей, чем однорегиональный Postgres.
- Хранение: репликация умножает объём данных. Датасет 2 ТБ при трёх репликах ≈ 6 ТБ до учёта бэкапов, индексов и служебных накладных расходов.
- Межрегиональный трафик: репликация между регионами, чтения и клиентский трафик могут стать заметной строчкой в счёте. Обычно это первая «сюрпризная» статья расходов при переходе в active‑active.
- Операции: даже управляемые предложения требуют работы: настройка схем и запросов, реагирование на инциденты, планирование ёмкости, тестирование обновлений и управление соответствием (особенно по размещению данных).
Оценка влияния задержки на реальные пользовательские сценарии
Распределённые SQL-системы добавляют координацию — особенно для сильных записей, которые требуют подтверждения кворумом.
Практический способ оценить влияние:
- Выберите 2–3 ключевых пути (чекаут, бронирование, «сохранить изменения").
- Посчитайте количество записывающих транзакций и шагов «чтение-после-записи» в критическом пути.
- Для каждого шага предположите межрегиональный RTT, где требуется координация. Если межрегиональный RTT 80–120 мс, два последовательных записи добавят 160–240 мс к времени отклика.
Это не значит «не делайте так», но означает: проектируйте пути, чтобы уменьшить последовательные записи (батчинг, идемпотентные повторы, менее разговорчивые транзакции).
Сложность vs более простые альтернативы
Если пользователи в основном в одном регионе, однорегиональный Postgres с репликами для чтения, хорошими бэкапами и протестированным планом фейловера может быть дешевле и проще — и быстр.
Распределённый SQL окупается, когда вам действительно нужны мульти-региональные записи, строгие RPO/RTO или размещение данных по регионам.
Простая ROI‑рамка
Считайте расходы как компромисс:
- Риск, который избегаете: меньше простоев, меньше потерь данных, меньше «глобальных» инцидентов по выходным.
- Защищённый доход: выше конверсия из‑за меньшей задержки для региональных пользователей, более серьёзное корпоративное предложение (SLA, соответствие).
- Расход: базовый кластер + накладные репликации + трафик + время инженеров.
Если избегаемые потери (простои + отток + риски соответствия) превышают премию затрат, мульти-региональный дизайн оправдан. Если нет — начните проще и оставьте путь для эволюции.
Чек-лист принятия и следующие шаги
Переход на распределённый SQL — это не просто «перенести» базу, а доказать, что именно ваша нагрузка ведёт себя предсказуемо, когда данные и консенсус распределены по узлам (и, возможно, регионам). Лёгкий план поможет избежать сюрпризов.
Фокусированный PoC
Выберите одно рабочее»»» нагрузочное»»»», представляющее реальную боль: например, checkout/booking, создание аккаунта или запись в ledger.
Определите метрики успеха заранее:
- Корректность: нет двойных бронирований, нет потерянных обновлений, предсказуемое поведение транзакций
- Latency SLOs: p50/p95 для трёх ключевых запросов (включая межрегиональные цели, если нужно)
- Пропускная способность: устойчивый QPS на пике + запас (обычно 2–3×)
- Устойчивость: поведение при падении узла и (если актуально) при потере региона
- Операционные затраты: время обнаружения, диагностики и восстановления при симулированном инциденте
Чтобы ускорить PoC, полезно сделать небольшой «реалистичный» интерфейс (API + UI), а не только синтетические бенчмарки. Команды иногда используют инструменты-стартеры, чтобы быстро поднять React + Go + PostgreSQL и затем поменять слой БД на CockroachDB/YugabyteDB или подключиться к Spanner — чтобы тестировать паттерны транзакций, повторы и поведение при отказах end‑to‑end. Главное — сократить цикл от «идеи» до «нагрузки, которую можно измерить».
Дизайн‑чеклист (проблемы, бьющие по расписанию)
- Схема: выбирайте PK, которые распределяют записи; избегайте последовательных «горячих» ключей
- Индексы: держите только необходимые; учитывайте амплификацию записей из‑за вторичных индексов
- Партиционирование/размещение: выбирайте ключи партиционирования и правила гео/зонального размещения по паттернам доступа
- Горячие точки: выявляйте «celebrity rows» (глобальные счётчики, таблицы одного тенанта) и переразрабатывайте заранее
- Миграции: планируйте онлайн‑изменения схем и бэкфиллы; тестируйте пути отката
Операционные базовые вещи на первый день
Мониторинг и runbook’ы не менее важны, чем SQL:
- Дашборды по задержкам, повторам, конкуренции, состоянию репликации/консенсуса, диску и компакции
- Руководства на инциденты: медленные запросы, рестарты узлов, падающие реплики, неравномерная нагрузка
- Нагрузочное тестирование, имитирующее прод (смесь чтений/записей, всплески, длинные транзакции)
- Бэкапы + упражнения по восстановлению (включая point‑in‑time, если поддерживается)
Следующие шаги
Начните с PoC‑спринта, затем выделите время на оценку готовности к продакшену и постепенный cutover (dual‑writes или shadow‑reads, где возможно).
Если нужно помочь с оценкой затрат или уровней, смотрите /pricing. Для практических руководств и паттернов миграции — /blog.
Если вы документируете результаты PoC, компромиссы архитектуры или уроки миграции — поделитесь ими с командой (и публично, если возможно): некоторые платформы даже предлагают кредиты за создание обучающего контента или рекомендации, что может частично компенсировать затраты на эксперименты.