Что освещает эта статья (и почему это важно)
Snowflake популяризировал простую, но далеко идущую идею в облачных хранилищах данных: разделять хранение данных и вычисления запросов. Такое разделение меняет две повседневные проблемы команд данных — как хранилища масштабируются и как вы за них платите.
Вместо того чтобы рассматривать хранилище как один фиксированный «ящик» (где больше пользователей, больше данных или более сложные запросы борются за одни и те же ресурсы), модель Snowflake позволяет хранить данные один раз и запускать ровно столько вычислений, сколько нужно в конкретный момент. В итоге чаще получается быстрее получать ответы, меньше узких мест в пиковой нагрузке и более прозрачный контроль над тем, за что вы платите (и когда).
Тема №1: производительность и масштабирование без классических компромиссов
Эта статья объясняет простыми словами, что означает разделение хранения и вычислений — и как это влияет на:
- Параллельность (много людей, выполняющих запросы одновременно)
- Эластичное масштабирование (увеличение/уменьшение вычислительных ресурсов)
- Поведение затрат (оплата вычислений только в момент их работы плюс постоянное хранение)
Мы также укажем, где модель не решает всё волшебным образом — потому что часть неприятных сюрпризов с производительностью и затратами возникает из того, как спроектированы рабочие нагрузки, а не из платформы сама по себе.
Тема №2: почему экосистема важна не меньше скорости
Быстрая платформа — не вся история. Для многих команд время до получения ценности зависит от того, насколько легко подключить хранилище к уже используемым инструментам — ETL/ELT, BI‑дашборды, каталоги/инструменты управления, средства безопасности и источники партнёрных данных.
Экосистема Snowflake (включая паттерны шаринга данных и стиль распространения через маркетплейс) может сократить сроки внедрения и уменьшить объём кастомной инженерии. Эта статья описывает, что на практике означает «глубина экосистемы» и как оценивать её для вашей организации.
Для кого это
Руководство написано для лидеров данных, аналитиков и неспециалистов‑решальщиков — тех, кому нужно понять компромиссы архитектуры Snowflake, масштабирования, затрат и интеграций без погружения в маркетинговый жаргон.
До разделения: почему традиционные хранилища упирались в пределы
Традиционные хранилища данных строились вокруг простой предпосылки: вы покупаете (или арендуете) фиксированное количество оборудования и запускаете всё на одном и том же кластере. Это работало, когда рабочие нагрузки были предсказуемы и рост — постепенным, но создавало структурные ограничения, когда объёмы данных и число пользователей ускорялись.
Классическая модель: фиксированные кластеры и тщательное планирование ёмкости
Локальные системы (и ранние облачные «lift‑and‑shift» деплои) обычно выглядели так:
- Один MPP‑кластер (массово параллельная обработка) обрабатывал хранение, CPU и память вместе.
- Кластер подбирали под пиковую нагрузку, потому что изменение размера было медленным, рискованным или требовало простоя.
- Планирование ёмкости превращалось в регулярный проект: прогнозирование роста, обоснование бюджета, заказ железа, установка, миграция.
Даже когда вендоры предлагали «узлы», основной паттерн оставался прежним: масштабирование обычно означало добавление больших или дополнительных узлов в общую среду.
Боли: медленное масштабирование, пустующая мощность и очереди
Такая структура порождает несколько частых проблем:
- Медленное масштабирование: если в период квартального отчёта внезапно требуется больше мощности, не всегда можно быстро её добавить. Либо ждут, либо переплачивают «на всякий случай».
- Простой мощностей: кластеры, рассчитанные на пики, большую часть времени недозагружены — но вы всё равно платите за них.
- Очереди при нагрузке: когда несколько команд запускают запросы одновременно, они конкурируют за одни и те же ресурсы. Тяжёлые задания могут блокировать интерактивные дашборды, приводя к тайм‑аутам и правилам вроде «не запускайте этот запрос в рабочие часы».
Интеграции: мощные, но часто хрупкие
Поскольку эти хранилища были тесно связаны с окружением, интеграции часто появлялись органично: кастомные ETL‑скрипты, ручные коннекторы и одноразовые пайплайны. Они работали — пока не менялась схема, не перемещался источник или не появлялся новый инструмент. Поддержка всей этой связки напоминала постоянную операцию по тушению пожаров, а не устойчивое развитие.
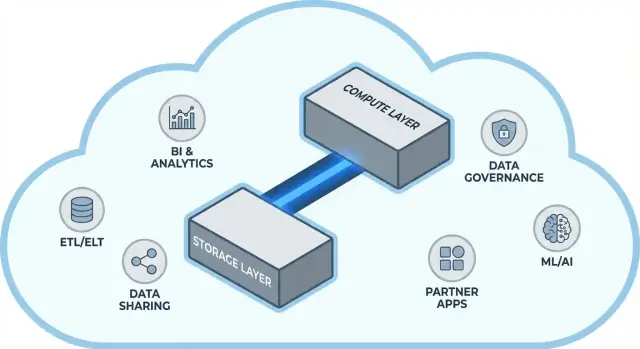
Главная идея: разделение хранения и вычислений
Традиционные хранилища часто связывают две очень разные задачи: хранение (где живут данные) и вычисления (мощность, которая читает, соединяет, агрегирует и записывает эти данные).
Хранение против вычислений (простыми словами)
Хранение похоже на кладовую: таблицы, файлы и метаданные хранятся дешёво и надёжно — данные долговечны и всегда доступны.
Вычисления — это как повара на кухне: набор CPU и памяти, который «готовит» ваши запросы — выполняет SQL, сортирует, сканирует, собирает результаты и обслуживает нескольких пользователей одновременно.
Ключевой сдвиг: масштабировать отдельно
Snowflake развязывает эти два слоя, чтобы вы могли настраивать каждый без изменения другого.
- Если растёт объём данных — вы добавляете хранение (как правило, инкрементально и предсказуемо).
- Если пик трафика отчётов — вы добавляете вычисления (изменяя размер или добавляя виртуальные склады), не копируя и не дублируя данные.
На практике это меняет повседневные операции: вам не нужно «перепокупать» вычисления только потому, что растёт хранение, и вы можете изолировать рабочие нагрузки (например, аналитики против ETL), чтобы они не мешали друг другу.
Что это не значит
Разделение мощное, но не волшебное.
- Это не «бесплатное масштабирование» — больше или крупнее склады обычно означают более высокие вычислительные расходы.
- Это не автоматическая экономия всегда — плохо написанные запросы, лишние расписания обновлений или постоянно включённые склады всё ещё тратят кредиты.
- Это не повод пренебрегать планированием — нужно выбирать размеры складов, ставить авто‑приостановку и согласовывать вычисления с бизнес‑паттернами.
Ценность — в контроле: платить за хранение и вычисления отдельно и подстраивать каждый под реальные потребности команд.
Архитектура Snowflake простыми словами
Snowflake проще всего понимать как три слоя, которые работают вместе, но масштабируются независимо.
1) Хранение: объектное облачное хранилище
Ваши таблицы в конечном счёте лежат в виде файлов данных в объектном хранилище облачного провайдера (S3, Azure Blob или GCS). Snowflake управляет форматами файлов, сжатием и организацией за вас. Вам не нужно прикреплять диски или размер томов — хранение растёт вместе с данными.
2) Вычисления: виртуальные склады
Вычисления упакованы как виртуальные склады: независимые кластеры CPU/памяти, которые исполняют запросы. Вы можете запускать несколько складов против тех же данных одновременно. Это ключевая разница с системами прошлого, где тяжёлые рабочие нагрузки боролись за общий пул ресурсов.
3) Службы облака: метаданные и координация
Отдельный слой служб отвечает за «мозг» системы: аутентификацию, парсинг и оптимизацию запросов, управление транзакциями/метаданными и координацию. Этот слой решает, как эффективно выполнить запрос до того, как вычисления начнут читать данные.
Как проходит запрос
Когда вы отправляете SQL, сервисный слой Snowflake парсит запрос, строит план выполнения и передаёт его выбранному виртуальному складу. Склад читает только необходимые файлы данных из объектного хранилища (и использует кэширование, когда это возможно), обрабатывает их и возвращает результат — без постоянного перемещения исходных данных в сам склад.
Параллельность и изоляция (без жаргона)
Если многие люди запускают запросы одновременно, вы можете:
- использовать отдельные склады для разных команд/нагрузок (изоляция);
- или включить многокластерные склады, чтобы Snowflake добавлял кластеры при пике и затем уменьшал их.
Это архитектурная база для производительности и контроля «шумных соседей» в Snowflake.
Масштабирование и параллельность: что реально меняется
Отслеживайте расходы хранилища данных
Создайте лёгкий центр учёта затрат и использования, который помогает командам выявлять причины затрат на вычисления.
Крупный практический сдвиг Snowflake в том, что вы масштабируете вычисления отдельно от данных. Вместо «склад становится больше» вы получаете возможность настраивать ресурсы на уровне рабочей нагрузки — без копирования таблиц, переразбивки дисков или простоя.
Эластичность: менять размер вычислений, не перемещая данные
В Snowflake «виртуальный склад» — это движок выполнения запросов. Его можно изменить по размеру (например, с Small на Large) за секунды — при этом данные остаются на месте в общем хранилище. Значит, настройка производительности часто сводится к простому вопросу: «Нужна ли этой нагрузке сейчас дополнительная мощность?"
Это также позволяет временные всплески: увеличьте мощности для закрытия месяца, затем верните назад после пика.
Параллельность: меньше очередей
Традиционные системы часто заставляют разные команды делить одни вычисления, что превращает часы пик в очередь у кассы.
Snowflake позволяет запускать отдельные склады для разных команд или рабочих нагрузок — например, один для аналитиков, другой для дашбордов и третий для ETL. Поскольку все они читают одни и те же базовые данные, уменьшается эффект «мой дашборд замедлил ваш отчёт», и производительность становится более предсказуемой.
Компромиссы, которые вы заметите
Эластичные вычисления — не гарантированный успех. Частые подводные камни:
- Cold starts: приостановленные склады могут немного задерживать возобновление, добавляя латентность для редких задач.
- Выбор размера: слишком большой размер — пустая трата, слишком маленький — медленные запросы и недовольство пользователей.
- Нужны подстраховки: используйте авто‑приостановку/авто‑возобновление, ресурсные мониторы и чёткие зоны ответственности, чтобы склады не работали впустую и не разрастались.
Итог: масштабирование и параллельность перестают быть инфраструктурным проектом и становятся операционной практикой.
Модель затрат: где экономия возможна (и где нет)
Как Snowflake реально выставляет счёт
У Snowflake фактически два счётчика, работающих параллельно:
- Вычисления: оплачиваются по времени работы виртуального склада (в кредитах). Если склад включён, счётчик идёт.
- Хранение: оплачивается по объёму хранимых данных (и дополнительно за функции вроде Time Travel/Fail‑safe).
Именно в этом разделении кроется потенциальная экономия: вы можете хранить много данных относительно дешёво и включать вычисления только по необходимости.
Где растут затраты
Большинство «неожиданных» трат связано не с хранением, а с поведением вычислений. Частые причины:
- Перепасованный размер складов
- Постоянно включённые склады
- Неэффективные запросы (незфильтрованные сканы, лишние джойны, тяжёлые трансформации)
- Высокая параллельность (множество маленьких дашбордов, обновляющихся постоянно)
Разделение хранения и вычислений само по себе не делает SQL эффективным — плохой код всё ещё быстро сожжёт кредиты.
Практические контрольные механизмы
Нужны не миллионы правил, а несколько рабочих инструментов:
- Auto‑suspend / auto‑resume, чтобы не платить за простой
- Resource monitors для оповещений или ограничения использования кредитов на склад/команду
- Расписания (пакетные задания в определённые окна; приостановка dev/test вне рабочего времени)
- Тестирование и правка размеров: пробуйте меньшие склады перед увеличением
При разумном использовании модель поощряет дисциплину: короткие, оптимальные вычисления вместе с предсказуемым ростом хранения.
Обмен данными и совместная работа как штатная возможность
Snowflake рассматривает шаринг как встроенную функцию, а не как допиленную сверху систему экспорта и файловых сбросов.
Шаринг без копирования (в многих сценариях)
Вместо того чтобы рассылать экстракты, Snowflake может позволить другой учётной записи запрашивать те же базовые данные через защищённый «share». Во многих случаях данные не нужно дублировать во второй склад или выгружать в объектное хранилище. Потребитель видит общую базу/таблицу как локальную, а провайдер остаётся в контроле того, что открыто.
Такой «развязанный» подход ценен: он уменьшает рассредоточение данных, ускоряет доступ и снижает количество пайплайнов, которые нужно поддерживать.
Распространённые паттерны совместной работы
Партнёрский и клиентский шаринг: вендор может публиковать курируемые наборы данных для клиентов (например, аналитика использования или справочные данные) с чёткими границами — только разрешённые схемы, таблицы или вью.
Внутренний шаринг доменов: центральные команды могут открывать сертифицированные наборы данных для продукта, финансов и операций без необходимости, чтобы каждая команда делала собственную копию. Это поддерживает культуру «единых цифр», при этом команды всё ещё выполняют свои вычисления.
Управляемое сотрудничество: совместные проекты (например, с агентством, поставщиком или дочерней компанией) могут работать с общими данными, сохраняя маскирование чувствительных колонок и логирование доступа.
Ограничения, которые нужно учесть
Шаринг — это не «поставил и забыл». Требуется:
- Говернанс: чёткая ответственность, ревью доступа и политики по PII/регулируемым данным
- Договорённости: кто платит за вычисления, SLA, ретеншен и что происходит при изменении определений
- Обнаружимость: без каталога и понятных наименований люди не найдут и не будут доверять нужным данным. Сопроводите шаринги документацией и записями в каталоге, если он у вас есть.
Почему экосистема важна не меньше производительности
Спланируйте пилот Snowflake
Составьте план пилота на 2–4 недели и реализуйте его пошагово в режиме планирования.
Быстрое хранилище ценно, но сама скорость редко решает, выполнится ли проект в срок. Чаще всего разницу делает экосистема вокруг платформы: готовые подключения, инструменты и экспертиза, которые уменьшают объём кастомной работы.
Что значит «экосистема» для платформы данных
На практике экосистема включает:
- Коннекторы к источникам и приёмникам данных (SaaS, БД, стриминг)
- Партнёрские инструменты для ингерста, трансформации, BI, качества данных и наблюдаемости
- Нативные интеграции и приложения, которые работают близко к данным
- Шаблоны и референс‑архитектуры (общие модели, паттерны, руководства по деплою)
- Сообщество: примеры, форумы, митапы и наличие специалистов на рынке
Почему экосистема ускоряет поставку больше, чем бенчмарки
Бенчмарки измеряют узкий срез производительности в контролируемых условиях. Реальные проекты тратят время на:
- Надёжный и инкрементальный приём данных
- Моделирование, тестирование и документирование наборов данных
- Операционные задачи (мониторинг, оповещения, контроль затрат)
- Проверки безопасности, контроль доступа и аудиты
Если у платформы зрелые интеграции для этих шагов, вам не придётся писать и поддерживать клей‑код. Обычно это сокращает сроки внедрения, повышает надёжность и упрощает смену команд или вендоров.
Простая линза оценки: покрытие, качество, поддерживаемость
Оценивайте экосистему по трём признакам:
- Покрытие: поддерживает ли она ваши ключевые источники, BI‑инструменты, оркестрацию и требования по говернансу?
- Качество: активно ли поддерживаются коннекторы, есть ли документация и доказанная работа в вашем масштабе?
- Поддерживаемость: сколько людей потребуется для обновлений, отладки и сопровождения?
Производительность даёт возможность; экосистема часто определяет, как быстро вы превратите её в бизнес‑результат.
Экосистема интеграций: как данные заходят, выходят и используются
Snowflake может быстро выполнять запросы, но ценность проявляется, когда данные надёжно проходят через стек: от источников в Snowflake и обратно в инструменты, которыми пользуются люди. «Последняя миля» часто определяет, кажется ли платформа надёжной или постоянно хрупкой.
Основные категории интеграций
Большинству команд нужен набор из:
- ELT/ETL для инжеста из БД, SaaS, файлов и объектного хранилища
- BI и аналитика для дашбордов, self‑serve и семантических слоёв
- Reverse ETL для отправки курированных данных обратно в CRM, маркетинг и support‑системы
- Оркестрация для расписаний, зависимостей, бэфилов и продвижения окружений
- Стриминг для почти реального времени и CDC
- ML‑инструменты для пайплайнов признаков, обучения и мониторинга моделей
Вопросы при выборе коннекторов
Не все инструменты «совместимые со Snowflake» ведут себя одинаково. При оценке смотрите на практические детали:
- Сертифицирован ли коннектор/поддерживается ли он (и кем)? Какой путь эскалации при проблемах?
- Может ли он корректно обрабатывать инкрементальные загрузки (CDC, метки времени, high‑water marks)?
- Как он справляется со schema drift — новыми колонками, изменением типов, удалением полей?
- Какие гарантии по ретраям, дедупликации и exactly‑once vs at‑least‑once?
Не пренебрегайте операциями
Интеграции требуют готовности «после запуска»: мониторинг и оповещения, хук‑линия для линейности/каталога, и процедуры инцидент‑менеджмента (тикеты, on‑call, плейбуки). Сильная экосистема — это не только логотипы, это меньше сюрпризов ночью.
Управление, безопасность и доверие в масштабе
Оптимизируйте размер с ограничениями
Разверните быстрый админ‑инструмент для решений по размеру хранилища и правил изоляции нагрузок.
По мере роста команд самая трудная часть аналитики часто — не скорость, а обеспечить, чтобы правильные люди имели доступ к правильным данным с доказуемыми контролями. Фичи говернанса Snowflake заточены под эту реальность: много пользователей, много продуктов данных и частые шаринги.
Базовые принципы говернанса, которые работают
Начните с чётких ролей и принципа минимальных привилегий. Вместо выдачи доступа индивидуумам, определите роли вроде ANALYST_FINANCE или ETL_MARKETING, затем дайте этим ролям доступ к конкретным базам/схемам/таблицам/вью.
Для чувствительных полей (PII, финансовые идентификаторы) используйте masking policies, чтобы люди могли выполнять запросы без доступа к исходным значениям, если роль не разрешает. Сопровождайте это аудитом: фиксируйте, кто что запрашивал и когда, чтобы команды безопасности и комплайенс могли быстро отвечать на запросы.
Как говернанс меняет шаринг и self‑service
Хороший говернанс делает шаринг безопасным и масштабируемым. Когда модель шаринга базируется на ролях, политиках и аудируемом доступе, вы можете уверенно расширять self‑service (больше пользователей исследует данные), не рискуя случайной утечкой.
Это также уменьшает трение при проверках комплаенса: политики становятся повторяемыми контролями, а не разовыми исключениями. Это важно, когда наборы данных переиспользуются между проектами, департаментами или внешними партнёрами.
Практические советы, которые предотвращают будущие боли
- Нейминг: стандартизируйте имена баз/схем так, чтобы они сигнализировали цель и чувствительность (например,
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Последовательность ускоряет ревью и снижает ошибки.
- Разделение окружений: логически разделяйте DEV/TEST/PROD, с жёсткими контролями в PROD. Обращайтесь с продовыми данными как с исключением, а не правилом.
- Ревью доступа: установите периодичность (ежемесячно для высокорискованных данных, квартально — для остальных). Проверяйте состав ролей, неактивных пользователей и привилегированные роли.
Доверие в масштабе — это не одна «идеальная» мера, а система небольших, надёжных практик, которые держат доступ осознанным и прослеживаемым.
Рабочие нагрузки и практические паттерны
Snowflake особенно хорошо показывает себя, когда много людей и инструментов опрашивают одни и те же данные по разным причинам. Поскольку вычисления упакованы в независимые склады, вы можете сопоставить каждую рабочую нагрузку с формой и расписанием, которые ей подходят.
Частое сопоставление рабочих нагрузок
Аналитика и дашборды: выделяйте BI‑инструментам отдельный склад, рассчитанный на стабильный, предсказуемый объём запросов. Это не даст интерактивным запросам замедлять обновления дашбордов.
Ad hoc анализ: дайте аналитикам отдельный склад (обычно меньше), с авто‑приостановкой. Получаете быструю итерацию без оплаты простоя.
Data science и эксперименты: используйте склад, рассчитанный на тяжёлые сканы и временные всплески. Если эксперименты дают пики, временно увеличьте мощность этого склада, не затрагивая BI‑пользователей.
Данные приложения и встраиваемая аналитика: относитесь к трафику приложений как к продовой службе — отдельный склад, консервативные таймауты и ресурсные мониторы, чтобы избежать неожиданных расходов.
Если вы строите лёгкие внутренние приложения (например, ops‑портал, который запрашивает Snowflake и показывает KPI), быстрый путь — сгенерировать рабочую заготовку React + API и итерировать с пользователями. Платформы вроде Koder.ai (платформа для «vibe‑coding», создающая web/server/mobile приложения через чат) помогают быстро прототипировать такие приложения и экспортировать исходники, когда придёт время вывести их в прод.