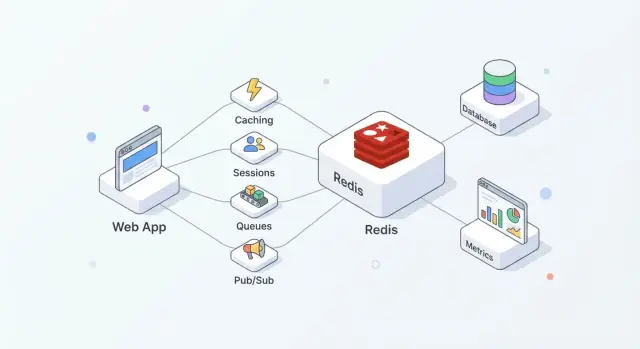
Что даёт Redis современным приложениям
Redis — это in-memory хранилище, часто используемое как общий «быстрый слой» для приложений. Командам он нравится за простоту внедрения, очень быструю обработку типичных операций и гибкость: Redis может выполнять несколько ролей (кэш, сессии, счётчики, очереди, pub/sub) без необходимости вводить отдельную систему для каждой задачи.
На практике Redis работает лучше, когда вы рассматриваете его как средство для скорости + координации, а ваша основная база данных остаётся источником правды.
Где Redis вписывается в типичную архитектуру
Обычная схема выглядит так:
- База данных: долговременные, авторитетные данные (заказы, пользователи, счета)
- Redis: быстрый доступ и общий эпемерный стейт (кэшированные страницы, токены сессий, счётчики лимитов)
- Приложение: решает, куда и когда записывать, инвалидировать или перестраивать данные
Такое разделение позволяет базе данных сосредоточиться на корректности и долговечности, а Redis поглощает высокочастотные чтения/записи, которые в противном случае увеличили бы задержки или нагрузку.
Что обычно даёт Redis
При грамотном использовании Redis приносит практические эффекты:
- Более быстрые чтения: раздача часто запрашиваемых данных из памяти вместо обращения в БД каждый раз.
- Более плавные всплески трафика: кэширование и лёгкие счётчики помогают пережить пики без того, чтобы база стала узким местом.
- Проще координировать: несколько серверов приложения могут разделять эпемерный стейт (сессии, блокировки, ключи дедупликации), вместо того чтобы реализовывать это локально в каждом инстансе.
Когда Redis — не то, что нужно
Redis не заменяет основную базу данных. Если вам нужны сложные запросы, долгосрочные гарантии хранения или аналитика, база данных остаётся правильным местом.
Также не считайте Redis «надёжным по умолчанию». Если потеря даже нескольких секунд данных недопустима, потребуется тщательная настройка персистентности — либо надо выбирать другую систему в зависимости от ваших требований восстановления.
Основы Redis, которые стоит знать перед внедрением
Redis часто называют «key-value store», но полезнее думать о нём как о очень быстром сервере, способном хранить и манипулировать небольшими фрагментами данных по имени (ключу). Такая модель поощряет предсказуемые паттерны доступа: обычно вы точно знаете, что хотите (сессию, кэшированную страницу, счётчик), и Redis способен получить или обновить это за один круг запроса.
Почему он быстрый: память прежде всего
Redis хранит данные в RAM, поэтому отвечает в микросекундах — низких миллисекундах. Цена — ограниченность и более высокая стоимость оперативной памяти по сравнению с диском.
Решите заранее, будет ли Redis:
- Только слоем производительности (чистый кэш), или
- Частью пути состояния (сессии, очереди), где важны поведение при перезапуске и настройки персистентности
Redis умеет сохранять данные на диск (RDB-снимки и/или AOF — append-only логи), но персистентность добавляет накладные записи и требует выбора между скоростью и потерей нескольких последних операций. Рассматривайте персистентность как регулятор, который вы настраиваете в зависимости от бизнес-рисков, а не как галочку, которую ставят по умолчанию.
Однопоточный не значит медленный
Redis выполняет команды в основном в одном потоке, что звучит как ограничение, пока вы не вспомните две вещи: операции обычно маленькие, и нет накладных расходов на блокировки между рабочими потоками. Если вы избегаете тяжёлых команд и слишком больших полезных нагрузок, эта модель может быть чрезвычайно эффективной при высокой конкуренции.
Клиенты, соединения и шаблоны запросов
Приложение общается с Redis по TCP через клиентские библиотеки. Используйте пул соединений, делайте запросы небольшими и предпочитайте батчинг/пайплайнинг, когда нужно несколько операций.
Планируйте таймауты и повторные попытки: Redis быстрый, но сеть — нет, и приложение должно деградировать грациозно, когда Redis занят или временно недоступен.
Если вы создаёте новый сервис и хотите быстро стандартизировать эти базовые вещи, платформы вроде Koder.ai помогают соскелетировать приложение (React + Go + PostgreSQL) и добавить функции на базе Redis (кэширование, сессии, rate limiting) через чат‑управляемый рабочий процесс — при этом позволяя экспортировать исходники и запускать их где угодно.
Паттерны кэширования, работающие в реальных приложениях
Кэш полезен только при чёткой ответственности: кто его заполняет, кто инвалидирует и что значит «достаточная» свежесть.
Паттерн cache-aside (по умолчанию для большинства приложений)
Cache-aside означает, что логика чтений/записей контролируется приложением, а не Redis.
Типичный поток:
- Чтение: ищем элемент в Redis.
- Попадание (hit): возвращаем сразу.
- Промах (miss): получаем из первичного источника (БД, API, сервис).
- Заполнение: сохраняем результат в Redis с TTL.
- Возврат: отвечаем клиенту.
Redis — быстрый key-value; ваше приложение решает, как сериализовать, версионировать и истекать записи.
TTL: выбор срока жизни без неожиданностей
TTL — это продуктовое решение, не только техническое. Короткий TTL уменьшает устарелость, но увеличивает нагрузку на БД; длинный TTL сохраняет работу, но рискует отдавать устаревшие результаты.
Практические советы:
- Соотносите с естественной частотой обновления (например, цены и фото профиля обновляются с разной частотой).
- Используйте версионированные ключи при изменении схемы (например,
user:v3:123), чтобы старые кэши не ломали новый код.
- Обрабатывайте устаревшие данные намеренно: в некоторых представлениях допустима небольшая устарелость; в других (инвентарь, аутентификация) — нет.
Избегаем «stampede» кэша
Когда горячий ключ истекает, много запросов могут одновременно получить промах.
Обычные защиты:
- Коалесценция запросов: только один запрос перестраивает значение, остальные ждут или отдают предыдущую версию.
- Джиттер TTL: добавляйте небольшую случайность, чтобы ключи не истекали одновременно.
- Soft TTL: считайте значение «устаревшим, но годным» короткое время, пока фоновый процесс обновляет Redis.
Что кэшировать (а что нет)
Хорошие кандидаты: ответы API, дорогостоящие результаты запросов и сконструированные объекты (рекомендации, агрегаты). Кэширование полного HTML может работать, но будьте осторожны с персонализацией и правами доступа — лучше кэшировать фрагменты при пользовательской логике.
Хранение сессий и рабочие процессы аутентификации
Redis — практичное место для короткоживущего состояния логина: session ID, метаданные refresh-токенов и флаги «запомнить это устройство». Цель — сделать аутентификацию быстрой, сохранив контроль над временем жизни сессий и отзывом.
Использование Redis для сессий пользователей
Обычный паттерн: приложение выдаёт случайный sessionId, сохраняет компактную запись в Redis и возвращает ID браузеру в HTTP-only cookie. На каждом запросе вы ищете ключ сессии и прикрепляете идентичность пользователя и права в контекст запроса.
Redis удобен, потому что чтения сессий часты, а истечение встроено.
Дизайн ключей и управление TTL
Проектируйте ключи так, чтобы их было легко сканировать и отзывать:
sess:{sessionId} → полезная нагрузка сессии (userId, issuedAt, deviceId)user:sessions:{userId} → Set активных sessionId (опционально, для «выйти на всех устройствах»)
Используйте TTL на sess:{sessionId}, соответствующий времени жизни сессии. Если вы ротация сессий (рекомендуется), создавайте новый sessionId и сразу удаляйте старый.
Осторожно с «sliding expiration» (продление TTL при каждом запросе): это может бессрочно поддерживать сессии активными у тяжёлых пользователей. Безопаснее продлевать TTL только когда до истечения осталось мало времени.
Отзыв и выход на всех устройствах
Чтобы выйти на одном устройстве — удалите sess:{sessionId}.
Чтобы выйти на всех устройствах, можно:
- удалить все sessionId из
user:sessions:{userId}, или
- хранить
user:revoked_after:{userId} — метку времени и считать любую сессию, выданную до неё, недействительной
Второй вариант избегает большого количества операций удаления.
Соображения по приватности и безопасности
Храните минимум нужного в Redis — лучше идентификаторы, а не персональные данные. Никогда не храните сырые пароли или долго действующие секреты. Если нужно хранить данные, связанные с токенами, храните их как хэши и ставьте короткие TTL.
Ограничьте, кто может подключаться к Redis, требуйте аутентификации и делайте sessionId достаточно энтропийными, чтобы предотвратить подбор.
Ограничение скорости и защита от злоупотреблений
Rate limiting — это то, где Redis особенно хорош: он быстрый, общий для всех инстансов приложения и предоставляет атомарные операции, которые сохраняют консистентность счётчиков при высокой нагрузке. Это полезно для защиты логина, дорогих поисков, сброса пароля и любых API, которые можно скрапить или подбирать.
Распространённые модели rate limiting
Фиксированное окно (Fixed window): проще всего — «100 запросов в минуту». Вы ведёте счётчик в текущем минутном бакете. Это просто, но позволяет пиковые всплески на границе окна (например, 100 запросов в 12:00:59 и ещё 100 в 12:01:00).
Скользящее окно (Sliding window) сглаживает границы, смотря на последние N секунд/минут. Это справедливее, но обычно дороже по реализации (нужны отсортированные множества или дополнительная учётность).
Token bucket отлично подходит для обработки всплесков. Пользователь «зарабатывает» токены со временем до некоторого предела; каждый запрос тратит токен. Это позволяет короткие всплески, сохраняя среднюю скорость.
Безопасные строительные блоки: INCR/EXPIRE и атомарность
Обычный паттерн фиксированного окна:
INCR key чтобы инкрементировать счётчикEXPIRE key window_seconds чтобы установить TTL
Трюк в том, чтобы делать это безопасно. Если выполнять INCR и EXPIRE разными вызовами, сбой между ними может оставить ключ без срока жизни.
Более безопасные подходы:
- Использовать Lua-скрипт, который выполняет
INCR и устанавливает EXPIRE только при первом создании счётчика.
- Или использовать
SET key 1 EX <ttl> NX для инициализации, а затем INCR (часто всё это оборачивают в скрипт для избежания гонок).
Атомарность особенно важна при всплесках: без неё два запроса могут «увидеть» одинаковую оставшуюся квоту и оба пройти.
Области применения: по пользователю, по IP, по маршруту (и всплески)
Большинству приложений нужны несколько уровней:
- По пользователю для аутентифицированных вызовов (напр.,
rl:user:{userId}:{route})
- По IP для анонимных или предварительно аутентифицированных эндпойнтов (например, попытки входа)
- По маршруту чтобы защищать горячие точки (поиск, экспорт, отчёты)
Для взрывных эндпойнтов token bucket (или щедрое фиксированное окно плюс короткое «burst» окно) поможет не наказывать легитимные пики вроде загрузок страниц или переподключений мобильных клиентов.
Когда Redis недоступен: fail-open vs fail-closed
Решите заранее, что для вас «безопасно»:
- Fail-open: разрешать запросы, если Redis недоступен. Лучше для доступности и UX, но слабее защита от злоупотреблений.
- Fail-closed: отклонять запросы при недоступности Redis. Надёжнее, но рискует частичной недоступностью приложения.
Частый компромисс: fail-open для низкорискованных маршрутов и fail-closed для чувствительных (логин, сброс пароля, OTP), при этом настраивая мониторинг, чтобы заметить момент остановки лимитирования.
Очереди и фоновые задания с Redis
Разрабатывайте и зарабатывайте кредиты
Получайте кредиты, делясь тем, что вы создали на Koder.ai, или приглашая коллегу.
Redis может служить для фоновых задач, когда нужен лёгкий механизм очередей для отправки писем, ресайза изображений, синхронизации данных или периодических задач. Ключ — выбрать правильную структуру данных и установить правила для retries и обработки ошибок.
Списки, отсортированные множества и стримы: что и почему
Lists — самая простая очередь: продюсеры LPUSH, воркеры BRPOP. Это просто, но потребуется дополнительная логика для «в полёте» задач, повторов и visibility timeout.
Sorted sets полезны, когда важно расписание. Используйте score как временную метку (или приоритет), и воркеры получают следующую задачу по сроку. Хорошо подходит для отложенных задач и приоритетных очередей.
Streams часто лучший дефолт для надёжного распределения работы. Они поддерживают consumer groups, хранят историю и позволяют нескольким работникам координироваться без изобретения собственного механизма "списка обработки".
Подтверждения, retries и обработка мёртвых писем
С consumer groups в Streams воркер читает сообщение и затем ACK его. Если воркер упал, сообщение остаётся в pending и может быть захвачено другим воркером.
Для повторов отслеживайте количество попыток (в полезной нагрузке сообщения или в побочном ключе) и применяйте экспоненциальную задержку (часто реализуемую через отсортированное множество как «расписание повторов»). После максимума попыток перемещайте задачу в dead-letter queue (другой stream или list) для ручной проверки.
Стратегии идемпотентности для обработчиков
Предполагается, что задача может выполниться дважды. Сделайте обработчики идемпотентными:
- Используйте идемпотентный ключ (например,
job:{id}:done) с SET ... NX перед побочными эффектами
- Проектируйте операции как upsert, а не «create blindly»
- Логируйте внешние request ID при вызове сторонних API
Держите задачи маленькими и используйте backpressure
Держите полезную нагрузку маленькой (большие данные храните в другом месте и передавайте ссылки). Добавляйте backpressure: ограничивайте длину очереди, замедляйте продюсеров при росте отставания и масштабируйте воркеров по глубине очереди и времени обработки.
Pub/Sub и распределение событий
Redis Pub/Sub — самый простой способ трансляции событий: издатель шлёт сообщение в канал, и все подключённые подписчики получают его мгновенно. Это не поллинг — лёгкая «push»-модель, хорошо подходящая для real-time обновлений.
Распространённые сценарии для Pub/Sub
Pub/Sub удобен, когда важна скорость и широкая рассылка больше, чем гарантированная доставка:
- Уведомления для пользователей ("ваш отчёт готов")
- Live‑обновления UI (presence, индикаторы набора текста, дашборды)
- Внутренний fan-out событий (одно событие вызывает несколько сервисов)
Полезная аналогия: Pub/Sub — это радиостанция. Кто настроен — услышит, но запись не сохраняется автоматически.
Ограничения, которые нужно учитывать
Pub/Sub имеет важные ограничения:
- Нет персистентности: если никто не подписан в момент отправки — сообщение потеряно.
- Надёжность подписчика: если подписчик отключился или перегружен, он может пропустить сообщения.
- Нет повторной доставки и подтверждений: нельзя требовать доставку «пока не подтверждено».
Поэтому Pub/Sub плохо подходит для критичных рабочих процессов, где каждое событие должно быть гарантированно обработано.
Когда выбирать Redis Streams
Если вам нужна долговечность, повторы, consumer groups или контроль нагрузки, обычно лучше выбирать Redis Streams. Стримы сохраняют события, поддерживают подтверждения и позволяют восстанавливаться после перезапусков — ближе к лёгкой очереди сообщений.
Паттерны для многоинстансных приложений
При реальном развёртывании у вас будет несколько инстансов, подписанных на каналы. Практические советы:
- Неймспейс каналов:
app:{env}:{domain}:{event} (например, shop:prod:orders:created).
- Отдельные каналы для широковещательных и таргетированных сообщений: широкое —
notifications:global, таргет — notifications:user:{id}.
- Держите полезную нагрузку небольшой и самодостаточной: включайте ID и минимальную метаинформацию; детали подтягивайте при необходимости.
Так Pub/Sub остаётся быстрым сигналом, а Streams (или другая очередь) обрабатывает события, которые нельзя потерять.
Выбор структур данных Redis
Защитите эндпоинты
Добавьте ограничение скорости запросов на основе Redis с атомарными обновлениями, чтобы защитить логины и API.
Выбор структуры данных влияет не только на работоспособность, но и на использование памяти, скорость запросов и простоту кода в будущем. Хорошее правило — выбирать структуру, соответствующую вопросам, которые вы будете к ней задавать (паттерны чтения), а не только тому, как вы сейчас храните данные.
Короткое руководство по выбору (strings, hashes, sets, sorted sets)
- Strings: для одиночных значений (JSON‑блоб, feature flag, закешированный HTML). Также отличны для атомарных счётчиков с
INCR/DECR.
- Hashes: для «объекта с полями» (поля профиля, итоги корзины). Удобны, когда часто обновляете отдельные свойства.
- Sets: для уникальности и проверок членства (например,_user уже получил купон X?). Быстрое
SISMEMBER и набор операций над множествами.
- Sorted sets (ZSETs): для ранжирования и запросов «топ N» (таблицы лидеров, приоритетные очереди, временные оценки).
Атомарные обновления, счётчики и таблицы лидеров
Операции Redis атомарны на уровне команд, поэтому безопасно инкрементировать счётчики без гонок. Просмотры страниц и счётчики rate limiting часто используют строки с INCR и истечением.
Таблицы лидеров — сильная сторона sorted sets: можно обновлять очки (ZINCRBY) и получать топ игроков (ZREVRANGE) эффективно, без полного сканирования.
Использование хэшей, чтобы сократить количество ключей
Если вы создаёте много ключей вроде user:123:name, user:123:email, user:123:plan, вы умножаете накладные расходы на ключи и усложняете управление. Хэш user:123 с полями (name, email, plan) держит связанные данные вместе и обычно экономит память. Кроме того, это упрощает частичные обновления (изменить одно поле, не перезаписывая весь JSON).
Соображения по памяти, которые влияют на расходы
- Много мелких ключей может стоить больше памяти из‑за накладных расходов на ключи.
- Hashes часто более экономичны для небольших и средних объектов, если сгруппировать их под одним ключом.
- Sorted sets мощные, но могут быть тяжелее по памяти, чем sets/strings — используйте их, когда действительно нужны ранжирование или запросы по «score».
При сомнении смоделируйте небольшой пример и измерьте использование памяти перед тем, как внедрять структуру для высоконагруженных данных.
Персистентность, репликация и безопасность данных
Redis часто называют «in-memory», но у вас есть выбор по тому, что происходит при рестарте ноды, заполнении диска или потере сервера. Правильная настройка зависит от того, сколько данных вы можете потерять и как быстро нужно восстановиться.
RDB vs AOF: что даёт каждая опция
RDB‑снимки сохраняют точечный дамп набора данных. Они компактны и быстро загружаются при старте, что делает перезапуски быстрее. Минус — можно потерять последние записи с момента последнего снимка.
AOF (append-only file) логирует операции записи по мере их выполнения. Обычно это снижает потенциальную потерю данных, потому что изменения записываются более непрерывно. AOF файлы могут вырастать, и проигрывание при старте может занять больше времени — однако Redis может переписывать/компактировать AOF.
Многие команды запускают оба: снимки для быстрого старта и AOF для лучшей записи долговечности.
Как персистентность влияет на задержки и рестарты
Персистентность не бесплатна. Дисковые записи, политики fsync для AOF и фоновые операции переписывания могут давать скачки задержек на медленном или заполненном хранилище. С другой стороны, персистентность делает рестарты менее пугающими: без неё непредвиденный рестарт означает пустой Redis.
Репликация и цели failover
Репликация держит копию(и) данных на репликах, чтобы вы могли переключиться при падении primary. Цель обычно — доступность, а не идеальная согласованность. При отказе реплики могут отставать, и при failover вы можете потерять последние подтверждённые записи в некоторых сценариях.
Определите допустимую потерю данных и время восстановления
Прежде чем ковырять настройки, запишите два числа:
- Допустимая потеря данных (RPO): «Мы можем потерять до X секунд/минут данных».
- Время восстановления (RTO): «Мы должны быть снова в рабочем состоянии за Y секунд/минут».
Используйте эти цели, чтобы выбирать частоту RDB, политику AOF и нужен ли вам реплики/автоматический failover для каждой роли Redis — кэш, хранилище сессий, очередь или первичное хранилище.
Масштабирование Redis: от одной ноды к кластеру
Одна нода Redis может очень долго вас обслуживать: проста в эксплуатации, предсказуема и часто достаточно быстра для многих кэш-, сессий- или очередных нагрузок.
Масштабирование становится необходимым при достижении жёстких лимитов — обычно потолка памяти, насыщения CPU или невозможности принять единую ноду как SPOF (single point of failure).
Когда переходить от одной ноды к нескольким
Рассмотрите добавление нод, когда:
- Датасет больше не помещается в RAM с безопасным запасом.
- На пике наблюдаются скачки задержки из‑за CPU‑нагрузки ноды.
- Нужна более высокая доступность, чем «перезапустись и восстановись».
- Есть конкурирующие рабочие нагрузки (кэш + очереди) и нужна их изоляция.
Практичный первый шаг — разделить нагрузки (запустить два независимых инстанса Redis) перед тем, как прыгать в кластер.
Шардинг и Redis Cluster простыми словами
Шардинг — это разделение ключей по нескольким нодам, так что каждая нода хранит лишь часть данных. Redis Cluster — встроенный механизм для этого: ключевое пространство делится на слоты, и каждая нода владеет набором слотов.
Плюсы: больше общей памяти и пропускной способности. Минусы: сложность, ограничения на мульти‑ключевые операции (ключи должны быть на одной шард‑нуде) и более сложное отлаживание.
Горячие ключи и неравномерное распределение трафика
Даже при «равном» шардинге реальный трафик может быть несбалансированным. Один популярный ключ может перегружать одну ноду, в то время как остальные простаивают.
Митигаторы: короткие TTL с джиттером, разбиение значения на несколько ключей (key hashing) или переработка паттернов доступа, чтобы чтения распределялись.
Клиентские моменты: драйверы, понимающие кластер и маршрутизацию
Redis Cluster требует клиент, который умеет обнаруживать топологию, направлять запросы на нужную ноду и следовать редиректам при переносе слотов.
Перед миграцией убедитесь, что:
- Драйвер для вашего языка полностью поддерживает Redis Cluster.
- Стратегия пуллинга соединений работает с несколькими нодами.
- Код избегает мульти‑ключевых команд через разные шарды (или использует hash tags, чтобы связать ключи).
Масштабирование лучше планировать: валидируйте через нагрузочные тесты, инструментируйте задержки по ключам и мигрируйте трафик постепенно, а не выключая всё разом.
Основы безопасности при развёртывании Redis
Сгенерируйте стек
Сгенерируйте проект на React + Go + PostgreSQL и добавьте кэширование за считанные минуты.
Redis часто считают «внутренней трубопроводной» частью, и именно поэтому он частая цель: один открытый порт — и может случиться утечка данных или управление кэшем злоумышленником. Считайте Redis чувствительной инфраструктурой, даже если вы храните только «временные» данные.
Аутентификация и контроль доступа
Сначала включите аутентификацию и используйте ACLs (Redis 6+). ACL позволяют:
- создавать отдельных пользователей для приложений, воркеров и админов
- ограничивать команды (напр., разрешить GET/SET, но запретить CONFIG)
- ограничивать ключи по префиксу (полезно для многопользовательских установок)
Не используйте единый пароль для всех компонентов. Выпускайте креденшалы для каждого сервиса и держите права минимальными.
Сетевой изоляция и TLS
Самый эффективный контроль — это недоступность. Привязывайте Redis к приватному интерфейсу, запускайте в приватной подсети и ограничивайте входящие подключения с помощью security groups/фаервола только для необходимых сервисов.
Используйте TLS, когда трафик Redis пересекает границы хостов, которые вы не полностью контролируете (multi‑AZ, общие сети, Kubernetes ноды или гибридные среды). TLS предотвращает перехват и кражу креденшалов — это стоит небольшой накладной нагрузки для данных сессий или любых пользовательских данных.
Опасные команды и неверная конфигурация
Закройте команды, которые могут нанести большой вред при злоупотреблении. Частые кандидаты для блокировки или ограничения через ACL: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG и EVAL (или по крайней мере контролируйте использование скриптов). Подмена команд через rename-command возможна, но ACL обычно понятнее и проще для аудита.
Управление секретами и их ротация
Храните креденшалы Redis в менеджере секретов (не в коде и не в образах контейнеров) и планируйте ротацию. Ротация проще, когда клиенты умеют подхватывать новые креденшалы без релиза, или когда вы поддерживаете два валидных набора в переходный период.
Если нужен практический чеклист, держите его в ранбуке рядом с вашими заметками /blog/monitoring-troubleshooting-redis.
Мониторинг, отладка и операционная гигиена
Redis часто «кажется в порядке»… пока трафик не сдвинется, память не начнёт ползти или медленная команда не заблокирует всё. Лёгкий набор мониторинга и чёткий инцидентный чеклист предотвратят большинство сюрпризов.
Метрики, которые действительно важны
Начните с небольшого набора, понятного всей команде:
- Память использована vs maxmemory: смотрите тренды, а не только текущее значение.
- Hit rate кэша (если вы кэшируете): низкий процент указывает на плохую схему ключей, короткие TTL или обход кэша.
- Задержки: отслеживайте p95/p99 — всплески важнее средних.
- Evictions: постоянные вытеснения означают недостаток ресурсов или неверные TTL.
- Replication lag (если есть реплики): рост лагов подрывает масштабирование чтений и уверенность в failover.
Быстрая отладка: slowlog и статистика команд
Когда что‑то «медленно», проверьте встроенные инструменты Redis:
- SLOWLOG помогает выявить дорогие команды (часто большие диапазонные запросы, выборки больших значений или случайные полносканирования).
- Command stats (через INFO) показывают, какие команды доминируют. Внезапный рост
KEYS, SMEMBERS или больших LRANGE — обычный красный флаг.
Если задержки растут при нормальном CPU, смотрите на сеть, большие полезные нагрузки или блокированные клиенты.
Планирование ёмкости и запас мощности
Планируйте рост, удерживая запас (обычно 20–30% свободной памяти) и пересматривайте предположения после релизов или включения фич. Считайте «постоянные evictions» за аварию, а не за предупреждение.
Простой инцидентный ранбук
Во время инцидента проверьте (в порядке): память/evictions, задержки, соединения клиентов, slowlog, replication lag и недавние деплои. Записывайте повторяющиеся причины и устраняйте их навсегда — одних алертов недостаточно.
Если команда быстро итеративно развивает продукт, полезно включить эти операционные ожидания в рабочий процесс разработки. Например, с Koder.ai вы можете прототипировать функции на базе Redis (кэширование, rate limiting), тестировать их под нагрузкой и безопасно откатывать — при этом сохраняя реализацию в кодовой базе через экспорт исходников.