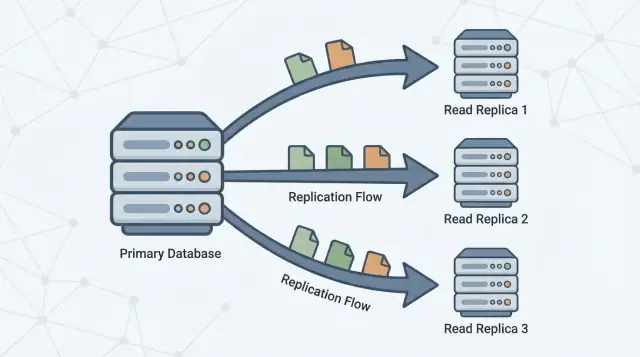
Что такое реплика для чтения (и чем она не является)
Реплика для чтения — это копия вашей основной базы данных (часто называемой primary), которая поддерживается в актуальном состоянии путём непрерывного получения изменений от неё. Ваше приложение может отправлять только читающие запросы (например, SELECT) на реплику, пока primary продолжает обрабатывать все записи (например, INSERT, UPDATE, DELETE).
Базовое обещание
Обещание простое: больше мощности для чтения, не увеличивая нагрузку на primary.
Если в приложении много «получающих» запросов — главные страницы, карточки товаров, профили пользователей, дашборды — перенос части этих чтений на одну или несколько реплик может освободить primary для записи и критичных операций чтения. Во многих случаях это можно сделать с минимальными изменениями в приложении: оставить один источник правды и добавить реплики как дополнительные места для запросов.
Чем реплика для чтения не является
Реплики полезны, но это не волшебная кнопка производительности. Они не:\n
- Не увеличивают пропускную способность записей. Все записи по-прежнему попадают на primary.\n- Не исправляют медленные запросы. Если запрос неэффективен (нет индексов, сканирование огромных таблиц, плохие соединения), он, скорее всего, будет медленным и на репликах — просто «медленно в другом месте».\n- Не заменяют хорошую схему и дизайн данных. Реплики не решают горячие точки, чрезмерно большие строки или «таблицу на всё».\n- Не устраняют необходимость мониторинга. Реплики добавляют движущиеся части: задержку, лимиты подключений и нюансы при переключении.
Ожидания от остальной части руководства
Считайте реплики инструментом для масштабирования чтения с компромиссами. Остальная часть статьи объясняет, когда они действительно помогают, как они обычно дают сбои и как такие понятия, как задержка репликации и конечная согласованность, влияют на то, что видит пользователь, когда вы начинаете читать из копии вместо primary.
Зачем существуют реплики для чтения
Один сервер primary обычно сначала кажется «достаточно большим». Он обрабатывает записи (insert, update, delete) и одновременно отвечает на все чтения (SELECT) от приложения, дашбордов и внутренних инструментов.
С ростом использования чтения обычно растут быстрее, чем записи: один просмотр страницы может вызывать несколько запросов, экраны поиска разворачивают множество обращений, а аналитические запросы сканируют много строк. Даже если объём записей умеренный, primary может стать узким местом, потому что он выполняет две задачи одновременно: безопасно и быстро принимать изменения и обслуживать растущий поток чтений с низкой задержкой.
Разделение чтений и записей
Реплики для чтения нужны, чтобы разделить эту нагрузку. Primary остаётся сосредоточенным на обработке записей и поддержании «источника правды», а одна или несколько реплик обслуживают только читающие запросы. Когда приложение может направлять часть запросов на реплики, вы снижаете нагрузку CPU, памяти и I/O на primary. Это обычно улучшает общую отзывчивость и оставляет больше резерва для всплесков записи.
Репликация в одном предложении
Репликация — это механизм, который поддерживает реплики в актуальном состоянии, копируя изменения с primary на другие серверы. Primary записывает изменения, а реплики применяют их, чтобы отвечать на запросы, используя почти те же данные.
Этот шаблон встречается во многих СУБД и управляемых сервисах (PostgreSQL, MySQL и облачные варианты). Реализация отличается, но цель одна: увеличить емкость для чтения, не заставляя primary бесконечно масштабироваться вертикально.
Как работает репликация (простой мысленный модель)
Думайте о primary как о «источнике правды». Он принимает каждую запись — создание заказов, обновление профилей, фиксацию платежей — и назначает этим изменениям определённый порядок.
Одна или несколько реплик затем следуют за primary, копируя эти изменения, чтобы отвечать на читающие запросы (например, «показать историю моих заказов») без дополнительной нагрузки на primary.
Базовый поток
- Primary принимает записи и сохраняет их в устойчивый журнал (названия варьируются в зависимости от СУБД).\n2. Реплики стримят или подтягивают эти записи журнала с primary.\n3. Реплики воспроизводят те же изменения в том же порядке, постепенно догоняя.
Чтения можно обслуживать с реплик, но записи по-прежнему идут на primary.
Синхронная vs асинхронная репликация (вкратце)
Репликация бывает двух типов:\n
- Синхронная: primary ждёт подтверждения от реплики (или кворума), прежде чем считать запись «зафиксированной». Это уменьшает устаревание, но может увеличить задержку записи и сделать записи чувствительными к проблемам реплики/сети.\n- Асинхронная: primary фиксирует запись сразу, а реплики догоняют позже. Это сохраняет быстрые записи и устойчивость, но реплики могут временно отставать.
Задержка репликации и «конечная согласованность»
Это отставание — реплики позади primary — называется задержкой репликации. Это не обязательно ошибка; часто это нормальный компромисс, который вы принимаете для масштабирования чтений.
Для конечных пользователей задержка проявляется как конечная согласованность: после изменения система станет согласованной повсюду, но не обязательно мгновенно.
Пример: вы обновили адрес электронной почты и обновили страницу профиля. Если страница обслуживается репликой, которая отстаёт на несколько секунд, вы кратко увидите старый email — пока реплика не применит обновление и не «догонит».
Когда реплики для чтения действительно помогают
Реплики помогают, когда primary здоров для записи, но перегружен обслуживанием чтений. Они наиболее эффективны, когда вы можете снять значимую часть SELECT нагрузки без изменения модели записи данных.
Признаки того, что проблема в чтениях (а не в записях)
Обращайте внимание на паттерны вроде:\n
- Высокая загрузка CPU на primary в пиковые моменты, при этом пропускная способность записи не необычно велика\n- Очень высокое соотношение
SELECT к INSERT/UPDATE/DELETE\n- Читающие запросы замедляются в пики, хотя записи остаются стабильными\n- Переполнение пула подключений из-за эндпойнтов с большим чтением (страницы товаров, ленты, результаты поиска)
Как подтвердить, что виноваты чтения (какие метрики смотреть)
Перед добавлением реплик проверьте несколько сигналов:\n
- CPU vs I/O: Зафиксирован ли pegged CPU на primary при всплесках задержки чтения? Или узким местом является дисковый I/O?\n- Состав запросов: Доля времени, проведённого в
SELECT (slow query log / APM).\n- p95/p99 латентность чтения: Отслеживайте отдельно латентность эндпойнтов чтения и запросов к БД.\n- Hit rate буфера/кэша: Низкий hit rate может означать, что чтения вынуждают доступ к диску.\n- Топ-запросы по суммарному времени: Один дорогой запрос может доминировать в «нагрузке чтения».
Не пропускайте более дешёвые исправления
Часто лучший первый шаг — тюнинг: добавить нужный индекс, переписать запрос, убрать N+1, закешировать горячие чтения. Эти изменения могут быть быстрее и дешевле, чем эксплуатация реплик.
Краткий чек-лист: реплики vs тюнинг
Выбирайте реплики, если:\n
- Большую часть нагрузки составляют чтения, и они уже относительно оптимизированы\n- Вы можете допустить периодические устаревшие чтения для отгружаемых запросов\n- Нужно быстро получить дополнительную ёмкость без рискованных изменений в схеме или запросах
Сначала выбирайте тюнинг, если:\n
- Пару запросов доминируют по суммарному времени\n- Очевидны отсутствующие индексы или неэффективные соединения\n- Чтения медленные даже при низком трафике (признак проблем дизайна запросов)
Лучшие случаи использования
Реплики особенно полезны, когда primary загружен обработкой записей (чекауты, регистрации, обновления), а значительная часть трафика — это чтение. В архитектуре primary–replica правильная маршрутизация запросов на реплики улучшает производительность без изменения поведения приложения.
1) Дашборды и аналитика, которые не должны замедлять транзакции
Дашборды часто выполняют долгие запросы: группировки, фильтрации за большие периоды, соединения нескольких таблиц. Эти запросы конкурируют с транзакционной работой за CPU, память и кэш.
Реплика — хорошее место для:\n
- Внутренних отчётов\n- Админ-панелей\n- «Ежедневных/еженедельных» метрик
Вы оставляете primary для быстрых предсказуемых транзакций, а аналитические чтения масштабируете отдельно.
2) Страницы поиска и обзора с высокой нагрузкой чтения
Просмотры каталогов, профили пользователей и контентные ленты могут давать высокий объём похожих запросов. Когда нагрузка чтения — узкое место, реплики поглощают трафик и уменьшают всплески латентности.
Это особенно хорошо, когда чтения часто промахиваются в кэше (много уникальных запросов) или когда нельзя полагаться только на кэш в приложении.
3) Фоновые джобы, сканирующие большие объёмы данных
Экспорт, бээкфиллы, пересчёт сводных значений и «найти все записи, соответствующие X» джобы могут громить primary. Запуск таких сканов на реплике безопаснее.
Только убедитесь, что джобу устраивает конечная согласованность: из-за задержки реплика может не увидеть самые свежие изменения.
4) Чтения в мульти-регионах для снижения латентности (с оговорками по устареванию)
Если у вас глобальные пользователи, размещение реплик ближе к ним снижает RTT. Компромисс — сильнее выраженное устаревание при лаге или проблемах сети, поэтому это подходит для страниц, где «почти актуально» приемлемо (обзоры, рекомендации, публичный контент).
Где реплики могут навредить
Спланируйте архитектуру для реплик
С помощью Koder.ai набросайте план «primary‑replica» до написания кода бэкенда.
Реплики хороши, когда «достаточно близко» — это ок. Они вредят, когда продукт ожидает, что каждое чтение отражает последнюю запись.
Классический симптом: «Я только что обновил — почему не изменилось?»
Пользователь редактирует профиль, отправляет форму или меняет настройки — и следующая загрузка страницы берёт данные с реплики, отстающей на несколько секунд. Запись прошла успешно, но пользователь видит старые данные, повторяет действие, дублирует запрос или теряет доверие.
Это особенно болезненно в сценариях, где пользователь ожидает мгновенного подтверждения: смена email, переключение настроек, загрузка документа или публикация комментария с немедленным редиректом.
Экраны, которые «должны быть актуальны» (не рискуйте)
Некоторые чтения не терпят даже краткой устарелости:\n
- Корзины и итоговые суммы при оформлении\n- Балансы кошельков, баллы лояльности, остатки запасов\n- Статусы «Прошёл ли платёж?»
Если реплика отстаёт, можно показать неверную сумму, перепродать товар или отобразить старый баланс. Даже если позже система исправит ситуацию, пользовательский опыт и нагрузка на поддержку пострадают.
Админ-инструменты и операции нуждаются в самой свежей информации
Внутренние дашборды часто принимают реальные решения: проверка мошенничества, поддержка клиентов, исполнение заказов, модерация и инцидентный ответ. Если админ-инструменты читают с реплик, есть риск принять решение по неполным данным — например, вернуть деньги за уже возвращённый заказ или пропустить последнее изменение статуса.
Практическое решение: направлять «read-your-writes» на primary
Распространённый паттерн — условная маршрутизация:\n
- После записи пользователя направляйте последующие подтверждающие чтения этого пользователя на primary короткий период (секунды–минуты).\n- Ненужные фоновые, анонимные или не критичные чтения оставляйте на репликах.
Это сохраняет преимущества реплик, не делая согласованность предметом гадания.
Понимание задержки репликации и устаревших чтений
Задержка репликации — это разница во времени между фиксацией записи на primary и моментом, когда это изменение видно на реплике. Если приложение читает с реплики в это окно, результат может быть «устаревшим» — точным несколько секунд назад, но уже не актуальным.
Почему возникает задержка
Задержка нормальна и обычно растёт под нагрузкой. Частые причины:\n
- Всплески нагрузки на primary: много записей — больше данных для передачи и применения.\n- Реплика недостаточно мощная или загружена: не успевает применять поступающие изменения (CPU, диск I/O).\n- Сеть: задержки или джиттер при передаче потока репликации.\n- Большие транзакции / массовые обновления: одна большая операция требует времени для сериализации, передачи и воспроизведения.
Как устаревшие чтения проявляются в продукте
Задержка влияет не только на «свежесть», но и на корректность с точки зрения пользователя:\n
- Пользователь обновил профиль, а при обновлении страницы видит старое значение.\n- Счётчики «непрочитанных сообщений» или бейджи уведомлений отстают.\n- Админ/отчёты не видят последних заказов, возвратов или изменений статуса.
Практические способы работы с этим
Сначала решите, что терпит ваша фича:\n
- Добавьте окно терпимости: «Данные могут быть устаревшими до 30 секунд» подходит для многих дашбордов.\n- Маршрутизация read-after-write на primary: после записи читайте этот объект с primary в течение короткого времени.\n- Подсказки в UI: ставьте ожидания («Обновление…», «Может появиться через несколько секунд»).\n- Логика повторных попыток: если критическое чтение не находит только что записанную запись, повторите запрос к primary или через небольшой таймаут.
Что мониторить и на что оповещать
Отслеживайте задержку реплик (в секундах/байтах), скорость применения репликации, ошибки репликации и загрузку CPU/диска реплики. Оповещайте, когда лаг превышает согласованный максимум (например, 5с, 30с, 2м) или когда лаг постоянно растёт (признак того, что реплика никогда не догонит без вмешательства).
Масштабирование чтения vs масштабирование записи (ключевые компромиссы)
Вносите изменения с уверенностью
Безопасно тестируйте миграции и откаты, пока прорабатываете компромиссы репликации.
Реплики — инструмент для масштабирования чтения: добавления мест для обслуживания SELECT. Они не предназначены для масштабирования записи: увеличения числа INSERT/UPDATE/DELETE операций, которые система может принять.
Масштабирование чтения: для чего годятся реплики
Добавляя реплики, вы увеличиваете ёмкость чтения. Если приложение ограничено эндпойнтами с чтением (страницы товаров, ленты, lookup'и), вы можете распределить эти запросы по нескольким машинам.
Это обычно улучшает:\n
- Латентность запросов под нагрузкой (меньше конкуренции на primary)\n- Пропускную способность чтений (больше CPU/памяти/I/O для
SELECT)\n- Изоляцию тяжёлых чтений, чтобы отчёты не мешали транзакциям
Масштабирование записи: что реплики не делают
Распространённое заблуждение — «больше реплик = больше пропускной способности записи». В типичной primary–replica схеме все записи идут на primary. Более того, больше реплик может немного увеличить работу primary, потому что ему надо генерировать и отправлять данные репликации всем репликам.
Если у вас проблема с пропускной способностью записи, реплики её не решат. Обычно нужны другие подходы: тюнинг запросов/индексов, батчинг, партицирование/шардинг или изменение модели данных.
Лимиты подключений и пуллинг: скрытое узкое место
Даже если реплики дают больше CPU для чтения, вы можете упереться в лимиты подключений. Каждый узел базы имеет максимум одновременных подключений, и добавление реплик умножает число мест, к которым ваше приложение может подключаться — без уменьшения общего спроса.
Практическое правило: используйте пул подключений (или pooler) и держите количество подключений на сервис преднамеренным. Иначе реплики просто станут «еще базами, которые можно перегрузить».
Стоимость: ёмкость не бесплатна
Реплики имеют реальные расходы:\n
- Доп. узлы (вычислительные затраты)\n- Доп. хранилище (каждая реплика хранит полную копию)\n- Доп. усилия по операциям (мониторинг, бэкапы, миграции схем, реакция на инциденты)
Компромисс прост: реплики дают вам запас для чтения и изоляцию, но добавляют сложность и не повышают потолок записи.
Высокая доступность и переключение (failover): что могут реплики
Реплики могут улучшить доступность чтения: если primary перегружен или временно недоступен, вы всё ещё сможете обслуживать часть читающего трафика с реплик. Это помогает поддерживать отзывчивость пользовательских страниц (для контента, терпимого к устареванию) и уменьшает радиус поражения при инциденте primary.
Но реплики сами по себе не дают полного плана высокой доступности. Реплика обычно не готова автоматически принимать записи, и «есть читаемая копия» ≠ «система может безопасно и быстро снова принимать записи».
Продвижение и переключение (в общем виде)
Failover обычно означает: обнаружить падение primary → выбрать реплику → поднять её до роли primary → перенаправить записи (и обычно чтения) на новый primary.
Некоторые управляемые БД автоматизируют это, но суть остаётся: меняется узел, принимающий записи.
Ключевые риски, которые нужно планировать
- Устаревшие данные на реплике: реплика может отставать; при её повышении до primary вы можете потерять последние записи, которые не успели распространиться.\n- Split-brain (разделённый мозг): нужно предотвратить ситуацию, где два узла одновременно принимают записи. Поэтому повышение обычно контролируется единым авторитетом (управляемая панель, кворум или строгие операционные процедуры).\n- Маршрутизация и кэши: приложению нужен надежный способ переключения целей — строки подключения, DNS, прокси или роутер БД. Убедитесь, что записи не продолжают случайно идти на старый primary.
Тестируйте переключение как фичу
Относитесь к failover как к тому, что нужно практиковать. Проводите игровые упражнения в staging (и аккуратно в prod в низко-рисковые окна): симулируйте потерю primary, измеряйте время восстановления, проверяйте маршрутизацию и уверяйтесь, что приложение корректно обрабатывает readonly периоды и переподключения.
Практические паттерны маршрутизации (разделение чтения/записи)
Реплики полезны только если трафик действительно до них доходит. “Read/write splitting” — набор правил, который отправляет записи на primary и подходящие чтения на реплики, не нарушая корректности.
Паттерн 1: разделение в приложении
Самый простой подход — явная маршрутизация в слое доступа к данным:\n
- Все записи (
INSERT/UPDATE/DELETE, изменение схемы) идут на primary.\n- Только выбранные чтения могут использовать реплику.
Это просто для понимания и отката. Здесь же можно кодировать бизнес-правила, например: «после оформления заказа читать статус заказа с primary некоторое время».
Паттерн 2: разделение через прокси или драйвер
Некоторые команды предпочитают прокси БД или «умный» драйвер, который понимает endpoint’ы primary vs replica и маршрутизирует по типу запроса или настройкам соединения. Это сокращает правки в коде, но будьте осторожны: прокси не всегда может понять, какие чтения безопасны с точки зрения продукта.
Как выбирать, какие запросы безопасно отправлять на реплики
Хорошие кандидаты:\n
- Аналитика, отчёты, бэкап-джобы\n- Страницы поиска/обзора, где допустимо небольшое устаревание\n- Фоновые задания, которые повторяются и не требуют самых свежих данных
Избегайте отправки на реплики чтений, которые сразу следуют за записью (например, «обновить профиль → перезагрузить профиль»), если у вас нет стратегии согласованности.
Транзакции и согласованность сессии
Внутри транзакции держите все чтения на primary.
Вне транзакций рассмотрите «read-your-writes» сессии: после записи закрепляйте пользователя/сессию на primary на короткий TTL или направляйте конкретные последующие запросы на primary.
Начинайте с малого и измеряйте
Добавьте одну реплику, направьте на неё ограниченный набор эндпойнтов/запросов и сравните до/после:\n
- CPU и дисковые IOPS primary\n- Использование реплики\n- Ошибки и перцентиль латентности\n- Инциденты, связанные с устаревшими чтениями
Расширяйте маршрутизацию только когда влияние очевидно и безопасно.
Мониторинг и основы эксплуатации
Сохраняйте полный контроль над кодом
Экспортируйте исходники в любой момент, чтобы настраивать запросы, индексы и маршрутизацию в своём рабочем процессе.
Реплики — это не «поставил и забыл». Это дополнительные серверы БД со своими пределами производительности, режимами отказа и операционными задачами. Немного дисциплины мониторинга часто решает, приведут ли реплики к улучшению или к путанице.
Что отслеживать (несколько ключевых метрик)
Сосредоточьтесь на индикаторах, которые объясняют симптомы, видимые пользователям:\n
- Задержка реплики: насколько реплика отстаёт от primary (в секундах, байтах или по позиции WAL/LSN).\n- Ошибки репликации: разрывы соединения, проблемы авторизации, полный диск, слоты репликации. Рассматривайте их как инциденты, а не «шум».\n- Латентность запросов (p50/p95) на реплике vs primary: реплики могут быть медленнее из-за другого состояния кэша или различного железа.\n- Hit rate кэша: реплика, которая постоянно промахивается, может показывать более высокую латентность после рестарта или при смене трафика.
Планирование ёмкости: сколько реплик нужно
Начните с одной реплики, если цель — снять чтения. Добавляйте, когда появляется явное ограничение:\n
- Пропускная способность чтения: одна реплика не справится с пиковым QPS или тяжёлыми аналитическими запросами.\n- Изоляция: выделите реплику под отчёты, чтобы дашборды не забирать ресурсы у пользовательского трафика.\n- География: реплика в каждом регионе снижает задержку, но увеличивает операционную нагрузку.
Практическое правило: масштабируйте реплики только после подтверждения, что чтения — узкое место (а не индексы, медленные запросы или кэш).
Частые операционные задачи
- Бэкапы: решите, где делать бэкапы. Снятие бэкапов с реплики может снизить нагрузку на primary, но убедитесь в требованиях консистентности и здоровье реплики.\n- Изменения схемы: тестируйте миграции с учётом репликации (долгие DDL могут увеличить лаг). Координируйте откладки, чтобы приложение и схема оставались совместимыми во время распространения.\n- Окна техобслуживания: патчи или рестарты реплик временно уменьшают ёмкость чтения. Планируйте ротацию, чтобы не опустить запас ниже требуемого.
Чек-лист при проблеме «реплики медленные»
- Проверьте задержку реплики: если высокая, пользователи могут повторять операции или видеть устаревшие данные.\n2. Сравните slow query logs на реплике и primary: часто там всплывают отчётные запросы.\n3. Проверьте CPU, память, диск I/O и сеть на хосте реплики.\n4. Ищите блокировки или долгие транзакции на primary, которые задерживают репликацию.\n5. Убедитесь, что маршрутизация чтения не перегружает одну реплику (неравномерный баланс нагрузки).\n6. Проверьте, что на репликах есть нужные индексы (они должны зеркалить primary) и что статистика актуальна.
Альтернативы и простой фреймворк принятия решения
Реплики — один из инструментов для масштабирования чтения, но редко первый. Прежде чем добавлять операционную сложность, проверьте, не даст ли более простое решение тот же результат.
Альтернативы, которые стоит попробовать в первую очередь
Кеширование может убрать целые классы запросов из базы. Для страниц с преобладающим чтением (карточки товаров, публичные профили, конфигурация) кеш или CDN могут сократить нагрузку серьёзно — без проблем с задержкой репликации.
Индексация и оптимизация запросов часто превосходят реплики: несколько дорогих запросов, потребляющих CPU, решаются добавлением индексов, уменьшением проекции столбцов, устранением N+1 и исправлением плохих JOIN.
Материализованные представления / предагрегация подходят, когда нагрузка по своей природе тяжёлая (аналитика, дашборды). Вместо повторного выполнения сложных запросов храните вычисленные результаты и обновляйте по расписанию.
Когда стоит подумать о шардировании/партиционировании
Если записи — узкое место (горячие строки, блокировки, лимиты write IOPS), реплики мало помогут. Тогда партиционирование таблиц по времени/тенанту или шардирование по customer_id может распределить нагрузку записи и снизить конкуренцию. Это более крупный архитектурный шаг, но он решает реальный узкий место.
Простой фреймворк принятия решения
Задайте четыре вопроса:\n
- Какая цель? Снизить латентность чтения, снять отчётные нагрузки или улучшить доступность?\n2. Насколько свежими должны быть данные? Если нельзя допустить устаревших чтений, реплики могут привести к проблемам.\n3. Какой бюджет? Реплики добавляют инфраструктурные и операционные расходы.\n4. Сколько сложности вы готовы принять? Разделение чтения/записи, обработка конечной согласованности и тестирование failover непросты.
Если вы прототипируете продукт или быстро поднимаете сервис, полезно заложить эти ограничения в архитектуру с самого начала. Например, команды, строящие приложения на Koder.ai (платформа, генерирующая React-приложения с бэкендом на Go + PostgreSQL из чат-интерфейса), часто начинают с одного primary для простоты, затем переходят на реплики, как только дашборды, ленты или внутренние отчёты начинают конкурировать с транзакционной нагрузкой. Планы и проектирование заранее помогают определить, какие эндпойнты могут терпеть конечную согласованность, а какие должны читать «свою запись» с primary.
Если хотите помощи с выбором пути, смотрите /pricing или просмотрите сопутствующие руководства в /blog.