Определите, что такое «воздействие инцидента» и какие решения оно должно поддерживать
Прежде чем строить расчёты или дашборды, решите, что именно «воздействие» означает в вашей организации. Если пропустить этот шаг, у вас получится научно звучащий балл, который никому не помогает принимать решения.
Что считается «воздействием» (а что — нет)
Воздействие — это измеримое последствие инцидента для того, что важно бизнесу. Частые измерения включают:
- Пользователи: число пользователей, не способных залогиниться, всплески ошибок в ключевых флоу, ухудшение латентности по региону.
- Выручка: сбоев в чекауте, блокировка продлений подписок, снижение показов рекламы.
- Риск SLA/SLO: минуты простоя против целевого времени работы, скорость расходования error budget.
- Внутренние команды: объём тикетов в поддержку, нагрузка на on‑call, заблокированные деплои.
Выберите 2–4 основных измерения и определите их явно. Например: «Impact = затронутые платящие клиенты + минуты риска SLA», а не «Impact = всё, что плохо смотрится на графиках».
Кто использует приложение и что им нужно в первые 10 минут
Разные роли принимают разные решения:
- Инцидент-командир нуждается в быстром, защищаемом резюме: что сломалось, кто затронут и как меняется ситуация.
- Поддержка нужна клиентская картина: какие аккаунты, регионы или планы пострадали.
- Инженеры хотят гипотезу blast‑radius для направления отладки и смягчения.
- Руководство нуждается в кратком бизнес‑сообщении: степень, влияние на клиентов и уверенность в ETA.
Спроектируйте выводы «воздействия» так, чтобы каждая аудитория могла ответить на свой главный вопрос без перевода метрик.
Реальное время vs near‑real‑time: задайте ожидания заранее
Определите приемлемую задержку. «Реальное время» дорого и часто не нужно; near‑real‑time (например, 1–5 минут) обычно достаточно для принятия решений.
Запишите это как продуктовое требование — оно влияет на приём событий, кэширование и UI.
Решения, которые приложение должно поддерживать во время инцидента
MVP должен напрямую поддерживать действия, такие как:
- объявление уровня серьёзности и эскалации
- запуск коммуникаций с клиентами (статусная страница, макросы поддержки)
- приоритизация работ по смягчению (какой сервис/команда в первую очередь)
- решение о роллбаках, фич‑флагах или переключении трафика
- определение клиентов для проактивного оповещения
Если метрика не влияет на решение, это, вероятно, не «воздействие», а просто телеметрия.
Чеклист требований: входы, выходы и ограничения
Прежде чем проектировать экраны или выбирать базу данных, зафиксируйте, на какие вопросы «анализ воздействия» должен отвечать во время реального инцидента. Цель не в идеальной точности с первого дня — а в последовательных, объяснимых результатах, которым могут доверять респондеры.
Обязательные входы (минимум)
Начните с данных, которые необходимо принимать или ссылаться для расчёта воздействия:
- Инциденты: ID, время начала/окончания, статус, отвечающая команда, краткое описание, ссылки на канал инцидента/тикет.
- Сервисы: канонический список сервисов (имя, владелец, уровень/критичность, ссылка на runbook).
- Зависимости: какие сервисы зависят от каких (даже если первая версия грубая).
- Телеметрия/сигналы: алерты, сжигание SLO, ошибки/латентность, события деплоя — всё, что указывает на деградацию.
- Клиентские аккаунты: ID аккаунтов, план/SLA, регион, ключевые контакты, а также как аккаунты маппятся на сервисы (прямо или через ворклоады).
Опционально при запуске (планируйте, но не требуйте)
Большинство команд не имеют идеальной карты зависимостей или точного маппинга клиентов с первого дня. Решите, какие вещи люди смогут вводить вручную, чтобы приложение оставалось полезным:
- ручной выбор затронутых сервисов/клиентов при отсутствии данных
- оценка времени начала или объёма, если телеметрия задерживается
- оверрайды с указанием причины (например, «ложноположительный алерт», «влияние только внутри компании»)
Дизайн этих полей как явных полей (а не произвольных заметок) позволяет потом выполнять запросы по ним.
Ключевые выходы (что приложение должно выдавать)
Первый релиз должен надежно генерировать:
- Затронутые сервисы и понятное «почему» (сигналы + зависимости)
- Список клиентов с подсчётом по планам/регионам и обзором «топ‑аккаунтов»
- Оценка серьёзности/impact score, которую можно объяснить простыми словами
- Таймлайн — когда воздействие, вероятно, началось, достигло пика и восстановилось
- Опционально: оценка стоимости (компенсации по SLA, нагрузка поддержки, риск выручки) с диапазоном уверенности
Нефункциональные ограничения (что делает систему заслуживающей доверия)
Анализ воздействия — это инструмент для принятия решений, поэтому ограничения важны:
- Задержка: дашборды должны грузиться за секунды во время инцидента
- Доступность: рассматривайте систему как критичный внутренний инструмент; задайте целевой уровень доступности
- Аудитируемость: логируйте, кто изменил оверрайд, когда и какое было предыдущее значение
- Контроль доступа: ограничивайте доступ к чувствительным данным клиентов; разделяйте права на чтение и запись
Запишите эти требования в тестируемой форме. Если вы не можете это проверить — на это нельзя полагаться в простое.
Модель данных: инциденты, сервисы, зависимости и клиенты
Модель данных — это контракт между приёмом, вычислениями и UI. Если её сделать правильно, можно менять источники данных, уточнять scoring и при этом отвечать на одни и те же вопросы: «Что сломалось?», «Кто затронут?» и «Как долго?»
Основные сущности (маленькие и с ссылками)
Минимум модель должна содержать эти первичные записи:
- Incident: контейнер повествования (заголовок, серьёзность, статус, владелец) и указатели на доказательства.
- Service: единица, для которой мапят зависимости (API, БД, очередь, сторонний провайдер).
- Dependency: направленное ребро service A → service B с метаданными (тип, критичность).
- Signal: временная наблюдаемая запись (алерт, сжигание SLO, всплеск ошибок, провал синтетики).
- Customer: аккаунт или организация, потребляющая сервисы.
- Subscription/SLA: то, на что клиент имеет право (план, SLO/SLA, правила отчётности).
Держите идентификаторы стабильными и согласованными между источниками. Если у вас уже есть каталог сервисов — используйте его как источник правды и мапьте внешние идентификаторы в него.
Модель времени (воздействие — это проблема временного окна)
Храните несколько временных меток на инциденте для отчётности и анализа:
- start_time / end_time: фактическое окно воздействия (может уточняться позже)
- detection_time: когда вы впервые узнали
- mitigation_time: когда начались исправления, уменьшившие воздействие
Также храните рассчитанные временные окна для расчёта (например, 5‑минутные бакеты). Это упрощает реплей и сравнения.
Связи, которые отвечают на «кто затронут?»
Спроектируйте два ключевых графа:
- Зависимости сервисов (blast radius)
- Использование сервисов клиентами (scope воздействия)
Простой шаблон: customer_service_usage(customer_id, service_id, weight, last_seen_at) — так вы сможете ранжировать влияние по «насколько сильно клиент зависит от сервиса».
Версионирование и история (зависимости меняются)
Зависимости эволюционируют, и расчёты воздействия должны отражать то, что было верно в момент инцидента. Добавьте датирование эффекта для ребёр:
dependency(valid_from, valid_to)
Сделайте то же для подписок клиентов и снимков использования. С историческими версиями вы сможете корректно прогонять прошлые инциденты в разборе и формировать последовательную отчётность по SLA.
Сбор и нормализация данных из инструментов
Анализ воздействия хорош ровно настолько, насколько хороши входные данные. Цель проста: вытянуть сигналы из уже используемых инструментов и превратить их в единый поток событий, с которым приложение может работать.
Что принимать (и зачем)
Начните с узкого списка источников, которые надёжно описывают «что‑то изменилось» во время инцидента:
- Мониторинговые алерты (PagerDuty, Opsgenie, CloudWatch alarms): быстрые индикаторы симптомов и серьёзности
- Логи и трейсы (ELK, Datadog, OpenTelemetry): доказательства охвата (какие эндпойнты, какие клиенты)
- Обновления статус‑страниц (Statuspage, Cachet): официальная нарративная и клиентская временная точка
- Тикетинг / инструменты инцидентов (Jira, ServiceNow): владение, метки времени и данные разборов
Не пытайтесь сразу всё поглотить. Выберите источники, покрывающие обнаружение, эскалацию и подтверждение.
Методы приёма
Интеграции имеют разные паттерны:
- Вебхуки для near‑real‑time обновлений (лучше всего для алертов и статус‑страниц)
- Опрос для API без вебхуков (используйте бэкоф и лимиты)
- Пакетный импорт для исторической подгрузки (полезно для первоначальной валидации)
- Ручной ввод для «последней мили» корректировок (аналитик может добавить тег сервиса)
Практика: вебхуки для критичных сигналов + пакетные импорты для заполнения пробелов.
Нормализация в общую схему
Приведите каждый входящий объект к единой «event» форме, даже если источник называет это alert, incident или annotation. Минимум стандартизируйте:
- Timestamp(ы): occurred_at, detected_at, resolved_at (если есть)
- Идентификаторы сервисов: маппинг тегов/имён источника на канонические service_id
- Серьёзность/приоритет: перевод уровней инструментов в вашу шкалу
- Источник и raw‑payload: храните оригинальный JSON для аудита и отладки
Чистота данных: дубли, порядок, отсутствующие поля
Ожидайте грязных данных. Используйте idempotency‑ключи (source + external_id) для дедупликации, терпите события вне порядка — сортируйте по occurred_at (не по времени прихода), и применяйте безопасные значения по умолчанию, помечая их для проверки.
Небольшая очередь «несопоставленных сервисов» в UI предотвращает молчаливые ошибки и сохраняет доверие к результатам воздействия.
Маппинг зависимостей сервисов для корректного blast‑radius
Создайте страницу обзора
Создайте обзорную страницу инцидента, показывающую, что сломалось, кого это затронуло и почему.
Если карта зависимостей неверна, blast‑radius будет неверным, даже если сигналы и scoring идеальны. Цель — построить граф зависимостей, которому можно доверять во время инцидента и после него.
Начните с каталога сервисов (источник правды)
Прежде чем рисовать ребра, опишите узлы. Создайте запись каталога для каждой системы, которую вы можете упоминать в инциденте: API, background workers, хранилища данных, сторонние провайдеры и другие критичные общие компоненты.
Каждый сервис должен содержать по крайней мере: владельца/команду, уровень/критичность (например, клиентский vs внутренний), цели SLA/SLO и ссылки на runbooks и on‑call доки (например, /runbooks/payments-timeouts).
Фиксированные vs наблюдаемые зависимости
Используйте два дополняющих источника:
- Статические (задекларированные) зависимости: что команды говорят, что они зависят (из IaC, конфигов, манифестов сервисов, ADR). Стабильны и легко проверяемы.
- Наблюдаемые (learned) зависимости: что системы фактически вызывают (по трейсам, telemetry из service mesh, логам gateway, audit‑логам БД). Эти данные ловят «неизвестные неизвестные», например забытый downstream вызов.
Обозначайте эти типы ребёр отдельно, чтобы люди понимали степень уверенности: «заявлено командой» vs «наблюдалось за последние 7 дней».
Направленность и критичность важны
Зависимости должны быть направленными: Checkout → Payments не равно Payments → Checkout. Направленность управляет рассуждениями («если Payments деградирует, какие upstream‑сервисы пострадают?»).
Также моделируйте жёсткие vs мягкие зависимости:
- Жёсткие: отказ блокирует основную функциональность (сервис авторизации для логина).
- Мягкие: деградация ухудшает качество, но есть fallback (рекомендации, опциональное обогащение).
Это предотвращает завышение воздействия и помогает приоритизировать реакцию.
Снимок графа для реплея и анализа
Архитектура меняется еженедельно. Если не сохранять снимки, вы не сможете корректно анализировать инцидент двухмесячной давности.
Пersistируйте версии графа зависимостей с привязкой ко времени (ежедневно, при деплое или при изменении). При расчёте blast‑radius разрешайте временной штамп инцидента к ближайшему снимку графа, чтобы «кто был затронут» отражал реальность в тот момент, а не сегодняшнюю архитектуру.
Расчёт воздействия: от сигналов к баллам и объёму затронутых
Когда вы принимаете сигналы (алерты, сжигание SLO, синтетические проверки, тикеты пользователей), приложению нужен последовательный способ превратить грязные входные данные в ясное утверждение: что сломано, насколько плохо и кто пострадал?
Выберите подход к скорингу (начните просто)
MVP можно получить с любым из этих паттернов:
- Правила (rule‑based): «Если error rate checkout > 5% в течение 10 минут, impact = High.» Легко объяснить и отлаживать.
- Взвешенная формула: комбинируйте нормализованные метрики в единый счёт (0–100). Удобно при множестве сигналов для плавности.
- Классификация по тиру: сопоставляйте системы бизнес‑тирам (Tier 0–3) и корректируйте серьёзность. Это удерживает результаты в соответствии с приоритетами бизнеса.
Какой бы подход вы ни выбрали, храните промежуточные значения (попадание в порог, веса, тир), чтобы можно было объяснить почему счёт получился таким.
Определите измерения воздействия
Не сворачивайте всё в одно число слишком рано. Отслеживайте несколько измерений отдельно, а затем выводите общую серьёзность:
- Доступность: простои, неудачные запросы, недоступные эндпойнты
- Латентность: деградация p95/p99 относительно базовой линии или SLO
- Ошибки: всплески ошибок, проваленные задания, таймауты
- Корректность данных: пропущенные/неправильные записи, задержки обработки
- Риск безопасности: подозрительные паттерны доступа, индикаторы утечки данных
Это помогает точечно коммуницировать (например, «доступен, но медленно» vs «возвращает неправильные результаты»).
Подсчёт затронутых клиентов/пользователей
Воздействие — это не только состояние сервиса, но и кто это почувствовал.
Используйте маппинг использования (тенант → сервис, план клиента → фичи, трафик пользователей → эндпойнт) и вычисляйте затронутых клиентов в временном окне, согласованном с инцидентом (start_time, mitigation_time и любые периоды бэкфилла).
Будьте явными в предположениях: выборочные логи, оценочный трафик или частичная телеметрия.
Ручные корректировки — с ответственностью
Операторам потребуется возможность оверрайдить: ложноположительный алерт, частичный релиз, известная подгруппа трафика.
Разрешайте ручные правки серьёзности, измерений и списка клиентов, но требуйте:
- кто изменил
- когда
- почему (короткий reason + опциональная ссылка на тикет/runbook)
Этот аудиторский след повышает доверие к дашборду и ускоряет разборы после инцидентов.
UX и дашборды: сделайте воздействие понятным за минуты
Спланируйте инструмент для инцидентов
Определите роли, права и требования к аудиту и логированию до начала реализации.
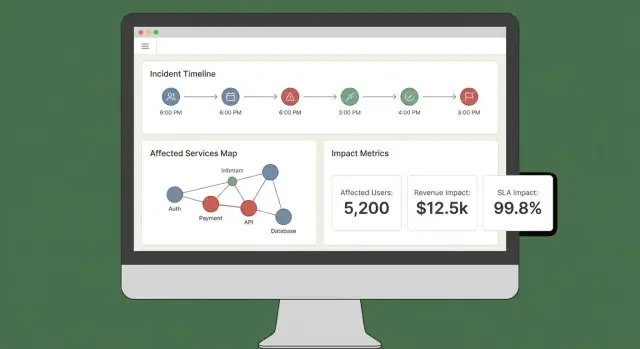
Хороший дашборд воздействия быстро отвечает на три вопроса: Что затронуто? Кто затронут? Насколько мы уверены? Если пользователям приходится открывать пять вкладок, чтобы собрать ответ, они не будут доверять результату или действовать по нему.
Основные представления для MVP
Начните с небольшого набора «всегда под рукой» видов, соответствующих реальным рабочим процессам инцидента:
- Обзор инцидента: статус, время начала, текущий impact score, топ‑затронутые сервисы/клиенты и последние доказательства.
- Затронутые сервисы: ранжированный список с серьёзностью, регионом и путём зависимости (чтобы инженеры понимали, где вмешаться).
- Затронутые клиенты: счётчики и именованные аккаунты по тиру/плану, плюс оценка затронутых пользователей если вы её считаете.
- Таймлайн: единый хронологический поток с событиями обнаружения, деплоями, алертами, мерами по смягчению и изменениями воздействия.
- Действия: предложенные следующие шаги, ответственные и ссылки на плейбуки или тикеты.
Делайте «почему» видимым
Оценки без объяснений кажутся произвольными. Каждый счёт должен восстанавливаться до входных данных и правил:
- Покажите какие сигналы внесли вклад (ошибки, латентность, health checks, объём поддержки) и их значения.
- Отобразите правила и пороги, которые применялись (например «latency p95 > 2s for 10 min = degraded»).
- Добавьте лёгкий индикатор уверенности (например «Высокая уверенность: подтверждено 3 источниками»).
Простой drawer «Объяснить влияние» или панель может это показать, не загромождая основной вид.
Фильтры и drilldown по реальным вопросам
Дайте возможность быстро резать данные по сервису, региону, тирам клиентов и временным диапазонам. Разрешите клик по любой точке графика или строке, чтобы спуститься до сырых доказательств (точные мониторы, логи или события, которые вызвали изменение).
Шеринг и экспорт
Во время активного инцидента нужны переносимые обновления. Включите:
- Делимые ссылки на вид инцидента (с учётом прав доступа)
- CSV‑экспорт списков сервисов/клиентов
- PDF‑экспорт для статусных апдейтов и пост‑инцидентных отчётов
Если у вас уже есть статус‑страница, ссылаться на неё можно относительным роутом, например /status, чтобы команды коммуникаций могли быстро свериться.
Безопасность, права и аудит
Владейте кодовой базой
Экспортируйте исходный код, когда команда подтвердит, что UX и система оценивания соответствуют реальности.
Анализ воздействия полезен только при доверии — а значит нужно контролировать, кто что видит, и поддерживать явную историю изменений.
Роли и права (начните просто)
Определите небольшой набор ролей, соответствующих тому, как протекают инциденты:
- Viewer: доступ только для чтения к сводкам инцидентов и высокоуровневому воздействию.
- Responder: может добавлять заметки, подтверждать затронутые сервисы и обновлять операционные поля.
- Incident commander: может одобрять оверрайды воздействия, задавать статус для клиентов и закрывать инциденты.
- Admin: управляет интеграциями, назначениями ролей и политиками хранения данных.
Привязывайте права к действиям, а не к должностям. Например, «can export customer impact report» — это отдельное право, которое можно давать командирам и выбранным администраторам.
Защита чувствительных данных клиентов
Анализ воздействия часто затрагивает идентификаторы клиентов, условия контрактов и контакты. Применяйте принцип наименьших привилегий:
- Маскируйте чувствительные поля (например показывайте последние 4 символа ID), если у пользователя нет явного доступа.
- Разделяйте «кто затронут» и «что сломалось». Многие пользователи нуждаются только в уровне сервиса, а не в списке клиентов.
- Защищайте экспорты: наносите водяной знак на PDF/CSV, указывайте запрашивающего пользователя и ограничивайте экспорт по ролям. Предпочитайте краткоживущие подписанные ссылки для скачивания.
Аудит‑логи, которые отвечают на «кто что изменил?»
Логируйте ключевые действия с достаточным контекстом:
- ручные правки входных данных (затронутые сервисы/клиенты)
- оверрайды impact score (старое значение, новое, причина)
- подтверждения и переходы статуса
- генерация отчётов и экспортов
Храните логи в режиме append‑only с метками времени и идентификацией акторов. Делайте их поисковыми по инциденту, чтобы они были полезны при пост‑инцидентном разборе.
План для требований по комплаенсу (без пустых обещаний)
Документируйте, что вы поддерживаете сейчас — периоды хранения, контроль доступа, шифрование и покрытие аудита — и что в планах. Короткая страница «Security & Audit» в приложении (например, /security) помогает задать ожидания и снижает количество срочных вопросов во время инцидента.
Рабочие процессы и уведомления во время активного инцидента
Анализ воздействия важен только тогда, когда он двигает к действию. Приложение должно быть «копилотом» для канала инцидента: превращать входящие сигналы в понятные обновления и подсказывать людям, когда значение воздействия существенно меняется.
Интеграция с чатами и каналами инцидентов
Подключайтесь к месту, где уже работают респондеры (обычно Slack, Microsoft Teams или специализированный инструмент инцидентов). Цель — не заменить канал, а публиковать контекстные обновления и сохранять общий журнал.
Практичный паттерн — рассматривать канал как вход и выход:
- Вход: респондеры тегают приложение (например, «/impact summarize», «/impact add affected customer Acme»), чтобы скорректировать или уточнить охват.
- Выход: приложение публикует краткие, последовательные обновления (текущий impact score, затронутые сервисы/клиенты, тренд относительно предыдущего апдейта).
Если прототипируете быстро, сначала реализуйте полный workflow end‑to‑end (вид инцидента → summarize → notify), а затем улучшайте скоринг. Платформы вроде Koder.ai полезны для итерации: можно быстро прототипировать React‑дашборд и Go/PostgreSQL бэкенд через чат‑управляемый workflow и экспортировать код, когда UX устраивает команду.