20 мар. 2025 г.·8 мин
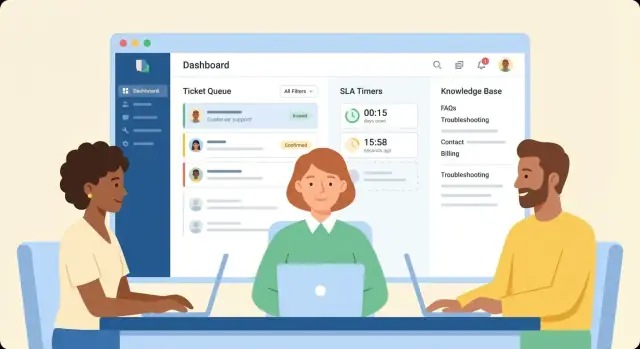
Как создать веб-приложение поддержки клиентов для тикетов и SLA
Спланируйте, спроектируйте и постройте веб-приложение поддержки клиентов с рабочими процессами тикетов, отслеживанием SLA и поисковой базой знаний — с ролями, аналитикой и интеграциями.
Определите цели, пользователей и объём
Продукт для тикетов быстро превращается в хаос, если его строят вокруг функций, а не результатов. Прежде чем проектировать поля, очереди или автоматизации, согласуйте, для кого приложение, какую боль оно решает и что означает «хорошо».
Выявите ваших пользователей (и их повседневные задачи)
Начните с перечисления ролей и того, что каждая должна успеть за обычную неделю:
- Агенты: сортируют, отвечают, решают и документируют решения быстро.
- Руководители команд: перераспределяют нагрузку, замечают застрявшие тикеты, контролируют SLA, обучают агентов.
- Администраторы: настраивают каналы, категории, автоматизации, права и шаблоны.
- Клиенты (опционально): отправляют запросы, отслеживают статус, добавляют детали, ищут ответы в портале.
Если пропустить этот шаг, вы случайно оптимизируете систему под админов, в то время как агенты будут бороться с очередью.
Пропишите проблемы, которые вы решаете
Держите формулировки конкретными и привязанными к наблюдаемому поведению:
- Пропущенные SLA: тикеты стареют без видимого прогресса; эскалации происходят слишком поздно.
- Хаотичные очереди: непонятна ответственность, дублирование работы и вопрос «куда это относится?».
- Повторяющиеся вопросы: одни и те же ответы набираются снова и снова, что замедляет решение.
Решите, где будет использоваться приложение
Будьте конкретны: это только внутренний инструмент, или вы также выпустите портал для клиентов? Порталы меняют требования (аутентификация, права, контент, брендинг, уведомления).
Выберите метрики успеха заранее
Выберите небольшое число метрик, которые будете отслеживать с первого дня:
- Время до первого ответа
- Время до решения
- Коэффициент отсеивания (вопросы решены через базу знаний, а не через тикеты)
Создайте простой statement для v1
Напишите 5–10 предложений, описывающих, что входит в v1 (обязательные рабочие процессы) и что позже (приятные дополнения, например продвинутая маршрутизация, подсказки на основе ИИ или глубокая аналитика). Это станет ориентиром, когда запросов станет много.
Спроектируйте модель тикета и его жизненный цикл
Модель тикета — это «источник правды» для всего остального: очередей, SLA, отчётности и того, что видят агенты на экране. Сделайте это правильно на раннем этапе, чтобы избежать болезненных миграций позже.
Нарисуйте жизненный цикл, который можно объяснить в одном предложении
Начните с ясного набора состояний и опишите, что каждое значит с операционной точки зрения:
- New: создан, ещё не прошёл триаж
- Assigned: закреплён за агентом или командой
- In progress: активно в работе
- Waiting: заблокирован (ответ клиента, сторонний сервис, инженерия)
- Solved: агент считает проблему решённой (часто вызывает уведомление)
- Closed: финальное состояние (заблокировано или ограничено редактирование)
Добавьте правила переходов между состояниями. Например, только тикеты в Assigned/In progress могут быть помечены как Solved, а Closed тикет не может быть вновь открыт без создания follow-up.
Решите, как тикеты попадают в систему
Перечислите все пути приёма, которые вы поддерживаете сейчас (и что добавите позже): веб-форма, входящая почта, чат и API. Каждый канал должен создавать тот же объект тикета с несколькими специфичными для канала полями (например, заголовки письма или идентификатор транскрипта чата). Последовательность упрощает автоматизации и отчётность.
Выберите обязательные поля (и держите их минимальными)
Минимум — требовать:
- Тема и описание
- Запрашивающий (идентичность клиента)
- Приоритет (насколько срочно)
- Категория (какого рода проблема)
Всё остальное может быть опциональным или производным. Перегруженная форма снижает качество заполнения и замедляет агентов.
Планируйте теги и кастомные поля для реальных команд
Используйте теги для лёгкой фильтрации (например, «billing», «bug», «vip»), а кастомные поля — когда нужны структурированные данные для отчётности или маршрутизации (например, «Область продукта», «ID заказа», «Регион»). Убедитесь, что поля могут быть ограничены по команде, чтобы одна департамент не захламлял другой.
Определите взаимодействие внутри тикета
Агентам нужно безопасное место для координации:
- Внутренние заметки (не видны клиентам)
- @упоминания и списки подписчиков/СС
- Связанные тикеты (дубликаты, родитель/дочерние инциденты)
Ваш UI для агента должен делать эти элементы доступными в один клик от основной временной шкалы.
Постройте очереди тикетов и рабочие процессы назначения
Очереди и назначение — это то место, где система тикетов перестаёт быть просто совместным почтовым ящиком и становится инструментом операций. Ваша цель проста: у каждого тикета должен быть очевидный «следующий лучший шаг», и каждый агент должен знать, чем заняться прямо сейчас.
Спроектируйте очередь агента, отвечающую на вопрос «что дальше?»
Создайте представление очереди, которое по умолчанию показывает наиболее срочные задачи. Часто используемые опции сортировки, которые действительно будут применять агенты:
- Приоритет (например, P1–P4)
- Время до SLA (сначала самые срочные)
- Последнее обновление (чтобы ловить зависшие беседы)
Добавьте быстрые фильтры (команда, канал, продукт, уровень клиента) и быстрый поиск. Держите список компактным: тема, запрашивающий, приоритет, статус, обратный отсчёт SLA и назначенный агент обычно достаточно.
Правила назначения: автоматизируйте когда возможно, вручную — когда нужно
Поддержите несколько путей назначения, чтобы команды могли эволюционировать без смены инструментов:
- Ручное назначение для крайних случаев и обучающих моментов
- Round-robin для равномерного распределения нагрузки
- Маршрутизация по скиллам (язык, область продукта, billing vs technical)
- Командная маршрутизация (например, «Платежи», «Enterprise», «Возвраты»)
Делайте видимыми решения правил («Назначено по: Скиллы → Французский + Биллинг»), чтобы агенты доверяли системе.
Статусы и шаблоны, которые поддерживают прогресс работы
Статусы вроде Waiting on customer и Waiting on third party предотвращают впечатление «пассивных» тикетов, когда действие заблокировано, и делают отчётность честнее.
Чтобы ускорить ответы, включите готовые ответы и шаблоны ответов с безопасными переменными (имя, номер заказа, дата SLA). Шаблоны должны быть доступны для поиска и редактирования уполномоченными руководителями.
Предотвращение коллизий (два агента, один тикет)
Добавьте обработку коллизий: когда агент открывает тикет, ставьте короткоживущий «лок просмотра/редактирования» или баннер «в настоящее время обрабатывает». Если кто-то другой пытается ответить, предупредите и потребуйте подтверждения перед отправкой (или блокируйте отправку), чтобы избежать дублирующих или противоречивых ответов.
Реализуйте правила SLA, таймеры и эскалации
SLA работают только если все согласны, что именно измеряется, и приложение последовательно это обеспечивает. Начните с превращения «мы отвечаем быстро» в политики, которые система может вычислять.
Определите политики SLA (что вы будете измерять)
Большинство команд начинают с двух таймеров на тикет:
- Время до первого ответа: время от создания тикета до первого ответа агента (или первого неавтоматического публичного ответа).
- Время до решения: время от создания тикета до состояния «Solved/Closed».
Держите политики настраиваемыми по приоритету, каналу или уровню клиента (например: VIP — 1 час на первый ответ, Стандарт — 8 рабочих часов).
Решите, когда часы SLA стартуют и останавливаются
Запишите правила до того, как начнёте кодить, потому что варианты быстро накапливаются:
- Рабочие часы vs 24/7: определите календарь (таймзона, рабочие дни, праздники).
- Паузы: остановка часов, когда тикет в «Waiting on customer» или «Pending external vendor».
- Условия возобновления: перезапуск при ответе клиента или изменении состояния обратно в «Open/In progress».
Храните события SLA (старт, пауза, возобновление, нарушение), чтобы потом объяснить почему произошёл breach.
Сделайте статус SLA очевидным в UI
Агенты не должны открывать тикет, чтобы узнать, что он вот-вот нарушит SLA. Добавьте:
- Обратный отсчёт (оставшееся время)
- Флаги просрочки с явной градацией серьёзности (предупреждение vs нарушение)
- Опциональные оповещения (в приложении, по почте или в чате) при достижении порога
Постройте пути эскалации
Эскалация должна быть автоматической и предсказуемой:
- Уведомлять руководителя на 80% от выделенного времени
- Переадресовывать в дежурную очередь при нарушении
- Повышать приоритет или добавлять тег «Escalated»
Планируйте отчётность по SLA
Минимум — отслеживайте количество нарушений, процент нарушений и тренд во времени. Также логируйте причины нарушений (слишком долгие паузы, неверный приоритет, недокомплектованность команды), чтобы отчёты вели к действиям, а не к обвинениям.
Создайте базу знаний, уменьшающую повторяющиеся тикеты
Хорошая база знаний (KB) — это не просто папка с FAQ, это продуктовая функция, которая должна измеримо сокращать повторяющиеся вопросы и ускорять решения. Проектируйте её как часть рабочего процесса с тикетами, а не как отдельный «сайт документации».
Структура: сделайте контент лёгким для поддержки
Начните с простой модели информации, которая масштабируется:
- Категории → разделы → статьи (удобная навигация для клиентов и агентов)
- Теги для перекрёстных тем (billing, login, integrations) без дублирования статей
- Чёткая ответственность (кто отвечает за обзоры), чтобы контент оставался актуальным
Соблюдайте единый шаблон статьи: формулировка проблемы, пошаговое решение, при необходимости скриншоты и раздел «Если это не помогло…» с направлением к правильной форме тикета или каналу.
Поиск, который действительно находит ответы
Большинство провалов KB — из-за провального поиска. Реализуйте поиск с:
- Настройкой релевантности (учёт заголовков/подзаголовков, приоритет свежести)
- Синонимами (например, «invoice» ↔ «bill», «2FA» ↔ «authentication code»)
- Терпимостью к опечаткам и стеммингом (множественное/единственное число)
Также индексируйте заголовки тикетов (анонимизируя их), чтобы учесть реальные формулировки клиентов и подпитывать список синонимов.
Черновики, рецензии и публикация
Добавьте лёгкий рабочий процесс: черновик → рецензия → опубликовано, с опциональным планированием публикации. Храните историю версий и указывайте «последнее обновление». Сопоставьте роли (автор, рецензент, издатель), чтобы не каждый агент мог править публичные документы.
Измеряйте то, что снижает количество тикетов
Отслеживайте не только просмотры страниц. Полезные метрики включают:
- Голосование за полезность (да/нет) и обратную связь «чего не хватило?»
- Сигналы отсеивания: поиск → статья просмотрена → отсутствие создания тикета в течение X часов
- Топ-запросов поиска без хороших результатов (пробелы в контенте)
Связывайте статьи с тикетами там, где происходит работа
Внутри окна ответа агента показывайте рекомендуемые статьи по теме тикета, тегам и обнаруженному намерению. В один клик можно вставить публичную ссылку (например, /help/account/reset-password) или внутренний фрагмент для ускорения ответов.
При грамотной реализации KB становится первой линией поддержки: клиенты решают проблемы сами, а агенты обрабатывают меньше повторяющихся тикетов с большей последовательностью.
Настройте роли, права и аудит
Быстро набросайте интерфейс агента
Создайте рабочее пространство агента, представления очередей и одно‑кликовые действия за считанные минуты.
Права доступа — это место, где инструмент для тикетов либо остаётся безопасным и предсказуемым, либо быстро превращается в хаос. Не откладывайте «заблокировать» после запуска. Смоделируйте доступ заранее, чтобы команды могли двигаться быстро, не подвергая риску конфиденциальные тикеты и не позволяя неправильным людям менять системные правила.
Разделяйте роли (и держите их простыми)
Начните с нескольких ролей и добавляйте нюансы только при реальной необходимости:
- Агент: работает с тикетами, добавляет заметки, отвечает, обновляет поля.
- Руководитель: всё, что может агент, плюс переназначение, управление очередями и инструменты коучинга.
- Админ: системные настройки, управление пользователями и конфигурация.
- Редактор контента: создаёт и публикует статьи базы знаний.
- Только для чтения: аудит, финансы, юристы или заинтересованные стороны, которым нужна видимость без прав на изменения.
Определяйте права по возможностям
Избегайте «всё или ничего». Рассматривайте крупные действия как явные права:
- Просмотр vs редактирование тикетов (включая приватные заметки)
- Управление макросами/готовыми ответами
- Редактирование правил SLA, таймеров и политик эскалации
- Публикация/снятие с публикации контента KB
Это упрощает предоставление минимально необходимых прав и поддержку роста (новые команды, регионы, подрядчики).
Доступ команд к чувствительным очередям
Некоторые очереди должны быть ограничены по умолчанию — billing, security, VIP или запросы по HR. Используйте членство в команде, чтобы контролировать:
- Какие очереди видны
- Кто может переназначать или объединять тикеты
- Будут ли поля с данными клиента замаскированы
Аудит-логи, которые вы действительно будете использовать
Логируйте ключевые действия с кем, что, когда и значениями до/после: смены назначений, удаления, правки SLA/политик, смены ролей и публикации KB. Сделайте логи доступными для поиска и экспорта, чтобы расследования не требовали прямого доступа к БД.
План мультибрендов или мультиинбоксов заранее
Если вы поддерживаете несколько брендов или инбоксов, решите, будут ли пользователи переключать контекст или доступ будет разделён. Это влияет на проверки прав и отчётность и должно быть согласовано с первого дня.
Проектируйте UX для агента и администратора
Система тикетов выигрывает или проигрывает по тому, как быстро агенты понимают ситуацию и выполняют следующий шаг. Рассматривайте рабочее пространство агента как «главный экран»: оно должно сразу отвечать на три вопроса — что произошло, кто этот клиент и что мне делать дальше.
Макет рабочего пространства агента
Начните со сплит-видa, который сохраняет контекст видимым во время работы:
- Поток беседы (email/chat/сообщения) с явными метками времени, вложениями и цитированием.
- Панель клиента с идентификацией, тарифом/типом аккаунта, организацией, прошлым тикетами и ключевыми заметками.
- Поля тикета (статус, приоритет, очередь, исполнитель, теги, таймеры SLA) логично сгруппированные, а не разбросанные.
Делайте поток читаемым: отличайте сообщения клиента, агента и системные события, а внутренние заметки визуально выделяйте, чтобы их случайно не отправить.
Однокликовые действия, убирающие трение
Разместите частые действия там, где уже находится курсор — рядом с последним сообщением и вверху тикета:
- Назначить / переназначить
- Изменить статус (включая «ожидает клиента»)
- Добавить внутреннюю заметку
- Применить макрос (предзаполненный ответ + обновления полей)
Стремитесь к «один клик + опциональный комментарий». Если действие вызывает модальное окно, оно должно быть коротким и удобным для клавиатурного ввода.
Фичи скорости для команд с большим объёмом
Высоконагруженная поддержка требует предсказуемых ускорителей:
- Клавиатурные сокращения для ответа, заметки, назначить себе, закрыть и следующий тикет
- Массовые действия в списках (добавить тег, назначить, закрыть, объединить)
- Быстрая палитра команд для продвинутых пользователей
Доступность и безопасность интерфейса
Внедряйте доступность с первых дней: достаточный контраст, видимые состояния фокуса, полная навигация по табу и метки для скринридеров для контролов и таймеров. Также предотвращайте дорогостоящие ошибки: подтверждение перед безопасным удалением, явная маркировка «публичный ответ» vs «внутренняя заметка» и предпросмотр того, что будет отправлено.
UX для админов и портала клиентов
Админы нуждаются в простых, пошаговых экранах для очередей, полей, автоматизаций и шаблонов — не прячьте базовые вещи за множеством уровней настроек.
Если клиенты могут отправлять и отслеживать запросы, спроектируйте лёгкий портал: создать тикет, смотреть статус, добавлять обновления и видеть предлагаемые статьи перед отправкой. Держите его в рамках публичного бренда и свяжите с /help.
Планируйте интеграции, API и омниканальный приём
Начните с малого, масштабируйтесь позже
Постройте систему тикетов на Koder.ai и при необходимости переходите с бесплатного плана на бизнес.
Система тикетов становится полезной, когда соединяется с местами, где клиенты уже общаются — и с инструментами, которые команда использует для решения проблем.
Начните с систем, которые нужно подключить в первую очередь
Перечислите интеграции «day-one» и данные, которые нужны от каждой:
- Email (общие почтовые ящики, правила переадресации, исходящий SMTP)
- Чат (виджет на сайте, WhatsApp, инструменты типа Intercom)
- CRM (контекст аккаунта, владелец, уровень тарифа)
- Биллинг (статус подписки, инвойсы, возвраты)
- Провайдер идентификации (SSO через Google/Microsoft, SCIM для провиженинга пользователей)
Пропишите направление данных (только чтение vs запись обратно) и ответственных за каждую интеграцию внутри компании.
Проектируйте API и вебхуки заранее
Даже если интеграции выйдут позже, определите стабильные примитивы сейчас:
- API endpoints для создания, обновления и поиска тикетов, а также для комментариев/сообщений и смены статусов.
- Webhooks для ключевых событий (ticket.created, ticket.updated, message.received, sla.breached), чтобы внешние системы могли реагировать.
Сделайте аутентификацию предсказуемой (API-ключи для серверов; OAuth для приложений, устанавливаемых пользователями) и версионируйте API, чтобы не ломать интеграции.
Предотвращайте дублирование тикетов с надёжной threading для почты
Email — место, где проявляются сложные крайние случаи. Планируйте как вы будете:
- Складывать ответы в ветки по заголовкам Message-ID / In-Reply-To / References
- Корректно парсить форварды и типичные подписи
- Дедуплицировать, обнаруживая повторяющиеся входящие полезные нагрузки (особенно от провайдеров почты)
Невеликая инвестиция здесь предотвращает «каждый ответ создаёт новый тикет».
Обрабатывайте вложения безопасно
Поддерживайте вложения, но с ограничениями: допустимые типы/размеры файлов, безопасное хранение и интеграция со сканированием на вирусы (или сторонним сервисом). Рассмотрите удаление опасных форматов и никогда не рендерьте недоверенный HTML inline.
Документируйте настройку как продуктовую функцию
Создайте короткое руководство по интеграциям: необходимые учётные данные, пошаговая конфигурация, отладка и тестовые шаги. Если вы ведёте документацию, свяжите её в интеграционном хабе на /docs, чтобы админам не нужен был инженер для подключения систем.
Добавьте аналитику и отчётность по работе поддержки
Аналитика превращает систему тикетов из «места работы» в «инструмент улучшения». Важно сохранять правильные события, вычислять несколько согласованных метрик и представлять их разным аудиториям, не раскрывая при этом чувствительные данные.
Начните с трека событий (а не только текущего состояния тикета)
Фиксируйте моменты, которые объясняют, почему тикет выглядит так, а не иначе. Минимум — отслеживайте: смены статусов, ответы клиента и агента, назначения и переназначения, обновления приоритета/категории и события таймеров SLA (старт/стоп, паузы и нарушения). Это позволит ответить на вопросы типа «Мы нарушили SLA из-за недокомплектованности или потому что ждали клиента?».
По возможности делайте события append-only; это повышает доверие к аудиту и отчётности.
Дашборды для руководителей команд
Руководители обычно нуждаются в оперативных рабочих видах, на которые можно сразу повлиять:
- Бэклог по очередям, приоритетам и категориям
- Устаревшие тикеты (например, самые старые открытые, самые старые ожидающие клиента)
- Риск SLA (тикеты, которые могут нарушить SLA в ближайшие X часов)
- Нагрузка агентов (количество назначений, активные задачи и время с последнего обновления)
Сделайте дашборды фильтруемыми по диапазонам времени, каналам и командам — без необходимости выгружать всё в таблицы.
Отчёты для руководства
Руководство меньше заботит детализация тикетов и больше — тренды:
- Объёмы по категориям/каналам, включая пиковые дни и часы
- Тренды времени до первого ответа и времени до решения (медиана и 90-й перцентиль)
- Тренды CSAT (и процент ответивших, чтобы оценки не вводили в заблуждение)
Если связать исходы с категориями, можно обосновать найм, обучение или продуктовые изменения.
Фильтры, экспорты и контроль доступа
Добавьте экспорт CSV для типичных представлений, но ограничьте доступ правами (и, по возможности, контролируйте отдельные поля), чтобы не допустить утечек почт, текстов сообщений или идентификаторов клиентов. Логируйте, кто и когда делал экспорт.
Сроки хранения данных без рискованных обещаний
Определите, как долго храните события тикетов, содержимое сообщений, вложения и агрегированную аналитику. Предпочтительнее настраиваемые политики хранения и чёткое документирование того, что фактически удаляется, а что анонимизируется, чтобы не давать гарантий, которые вы не можете проверить.
Выберите практичную архитектуру и стек технологий
Продукт для тикетов не требует сложной архитектуры, чтобы быть эффективным. Для большинства команд простой подход быстрее в разработке, легче в поддержке и при этом хорошо масштабируется.
Начните с понятной схемы системы
Практический базис выглядит так:
- Веб-фронтенд: UI для агентов/админов и портал для клиентов
- Бэкенд API: бизнес-логика для тикетов, SLA, пользователей и KB
- База данных: источник правды для тикетов, пользователей, событий и настроек
- Фоновые задания: всё, что зависит от времени или долго выполняется
Подход «модульный монолит» (один бэкенд с чёткими модулями) делает v1 управляемым и оставляет пространство для выделения сервисов позже.
Если нужно ускорить v1 без полного переписывания пайплайна доставки, платформа вроде Koder.ai может помочь прототипировать панель агента, жизненный цикл тикета и экраны админа через чат — с возможностью экспортировать исходники, когда будете готовы взять полный контроль.
Знайте, что должно работать в фоне
Система тикетов ощущается как реального времени, но много работы асинхронно. Планируйте фоновые задания заранее для:
- Таймеров SLA и эскалаций (например, «первый ответ через 30 минут»)
- Уведомлений (email, in-app, вебхуки)
- Индексации поиска (тикеты и статьи KB)
- Обработки входящей почты (парсинг, вложения, объединение в ветки)
Если фоновая обработка — второстепенная мысль, SLA станут ненадёжными, и агенты потеряют доверие.
Храните данные для корректности, индексируйте для скорости
Используйте реляционную БД (PostgreSQL/MySQL) для основных записей: тикеты, комментарии, статусы, назначения, политики SLA и таблицу аудита/событий.
Для быстрого поиска и релевантности держите отдельный поисковый индекс (Elasticsearch/OpenSearch или управляемый эквивалент). Не пытайтесь заставить реляционную БД выполнять полнотекстовый поиск на масштабе, если продукт от этого зависит.
Решение — строить или покупать (и почему)
Три области часто экономят месяцы при покупке:
- Аутентификация: используйте проверенного провайдера (SSO, MFA, политики паролей)
- Доставка почты: сервисы для транзакционных писем с хорошей доставляемостью и обработкой bounce
- Поиск: управляемый поиск, если нет экспертизы в команде
Стройте то, что отличает вас: правила воркфлоу, поведение SLA, логика маршрутизации и опыт агента.
Планируйте вехи с ясным списком v1
Оценивайте работу по вехам, а не по отдельным функциям. Надёжный список вех для v1: CRUD тикетов + комментарии, базовое назначение, ядро таймеров SLA, email-уведомления, минимальная отчётность. Держите «приятные дополнения» (сложные автоматизации, детальные роли, глубокая аналитика) вне объёма до того, как v1 покажет, что действительно важно.
Обеспечьте основы безопасности, приватности и надёжности
Итерации без сбоев в работе
Безопасно тестируйте правила SLA и маршрутизацию с помощью снимков и быстрого отката во время пилотов.
Решения по безопасности и надёжности проще и дешевле внедрять с самого начала. Приложение поддержки обрабатывает конфиденциальные переписки, вложения и данные аккаунтов — обращайтесь к нему как к критическому сервису, а не как к побочному инструменту.
Защищайте данные клиентов по умолчанию
Начните с шифрования при передаче (HTTPS/TLS) везде, включая внутренние сервисные вызовы при наличии нескольких сервисов. Для данных в покое шифруйте базы и объектное хранилище (вложения), храните секреты в управляемом хранилище секретов.
Используйте принцип наименьших привилегий: агенты видят только разрешённые им тикеты, админы получают повышенные права по необходимости. Добавьте логи доступа, чтобы можно было ответить «кто и когда посмотрел/экспортировал что» без догадок.
Выбирайте аутентификацию, соответствующую вашей аудитории
Аутентификация не универсальна. Для маленьких команд достаточно email + пароль. Для продажи крупным организациям SSO (SAML/OIDC) может быть обязательным. Для лёгких клиентских порталов магическая ссылка снижает трение.
Что бы вы ни выбрали, обеспечьте безопасность сессий (короткоживущие токены, стратегия обновления, защищённые cookie) и добавьте MFA для админов.
Предотвращайте распространённые атаки заранее
Поставьте rate limiting на логин, создание тикетов и поиск, чтобы замедлить брутфорс и спам. Валидируйте и санитизируйте ввод, чтобы избежать инъекций и небезопасного HTML в комментариях.
Если используете cookie, добавьте защиту от CSRF. Для API задайте строгие правила CORS. Для загрузок файлов — сканирование на вредоносное ПО и ограничения по типам и размерам.
Резервные копии, восстановление и измеримые цели
Определите RPO/RTO (сколько данных можно потерять и за какое время нужно восстановиться). Автоматизируйте бэкапы баз и файлового хранилища и — что важно — регулярно тестируйте восстановление. Бэкап, который нельзя восстановить, не является бэкапом.
Основы приватности, о которых спросят пользователи
Системы поддержки часто подпадают под запросы в рамках приватности. Предоставьте возможность экспортировать и удалять данные клиента и документируйте, что именно удаляется, а что сохраняется по юридическим/аудиторским причинам. Держите доступные админам логи аудита и доступа (см. /security), чтобы быстро расследовать инциденты.
Тестируйте, запускайте и улучшайте вместе с реальными командами поддержки
Выпуск веб-приложения поддержки — это не финиш, а начало обучения тому, как агенты работают под реальной нагрузкой. Цель тестирования и развёртывания — защитить повседневную поддержку, пока вы проверяете, что система тикетов и управление SLA работают корректно.
Опишите end-to-end сценарии, отражающие реальную работу
Кроме unit-тестов, оформите (и автоматизируйте, где возможно) небольшой набор end-to-end сценариев, отражающих ваши наиболее рискованные потоки:
- Создание тикета: приём через email/веб/API создаёт тикет с нужными полями, идентичностью клиента и первоначальным статусом.
- Ответы и threading: ответы клиента прикрепляются к правильному тикету, ответы агента уведомляют клиента, внутренние заметки остаются приватными.
- Нарушения SLA: таймеры стартуют/останавливаются корректно (например, пауза в «ожидает клиента»), нарушения вызывают правильные эскалации, а аудит-логи фиксируют события.
- Поиск в базе знаний: агенты быстро находят релевантные статьи из вида тикета, клиенты видят полезные подсказки перед отправкой.
Если есть staging, наполните его реалистичными данными (клиенты, теги, очереди, рабочие часы), чтобы тесты не срабатывали «в теории» только.
Запустите пилот и собирайте обратную связь еженедельно
Начните с небольшой группы поддержки (или одной очереди) на 2–4 недели. Установите еженедельный рутин — 30 минут для обсуждения, что тормозит, что сбивает с толку клиентов и какие правила вызвали сюрпризы.
Структурируйте обратную связь: “Какая задача?”, “Что ожидалось?”, “Что произошло?”, “Как часто это случается?” — это поможет приоритизировать исправления, влияющие на пропускную способность и соблюдение SLA.
Создайте чеклист онбординга для админов и агентов
Сделайте онбординг повторяемым, чтобы запуск не зависел от одного человека.
Включите базовые вещи: вход в систему, виды очередей, ответ vs внутренняя заметка, назначение/упоминание, смена статуса, использование макросов, чтение индикаторов SLA и поиск/создание статей KB. Для админов: управление ролями, рабочими часами, тегами, автоматизациями и базовые отчёты.
Планируйте поэтапный rollout (с возможностью отката)
Выводите по командам, каналам или типам тикетов. Заранее определите путь отката: как временно вернуть приём, какие данные потребуют ресинхронизации и кто принимает решение.
Команды, использующие Koder.ai, часто опираются на снапшоты и откаты в ранних пилотах, чтобы безопасно итерационно менять воркфлоу (очереди, SLA и формы портала) без нарушения живых операций.
Сформируйте дорожную карту итераций
Когда пилот стабилизируется, планируйте улучшения волнами:
- Умные автоматизации (макросы, триггеры, авто-тегирование)
- Продвинутая маршрутизация (skills-based, балансировка нагрузки)
- Улучшенные воркфлоу KB (рецензии статей, обратная связь, метрики отсеивания)
Относитесь к каждой волне как к маленькому релизу: тестируйте, пилотьте, измеряйте и затем расширяйте.