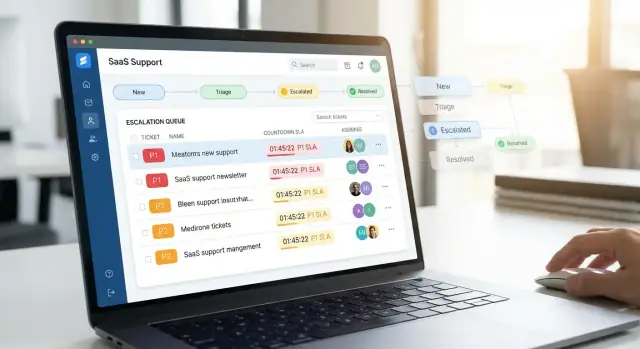
Проясните рабочий процесс эскалации и цели
Прежде чем делать экраны или писать код, решите, для чего ваше приложение и какое поведение оно должно обеспечивать. Эскалации — это не просто «сердитые клиенты»: это тикеты, требующие ускоренной обработки, повышенной видимости и плотной координации.
Что считается эскалацией?
Определите критерии эскалации простым языком, чтобы агенты и клиенты не гадали. Частые триггеры включают:
- Аутедж или серьёзное ухудшение работы
- VIP или клиент с контрактом «приоритетная поддержка»
- Надвигающееся нарушение SLA (или повторяющиеся нарушения)
- Инцидент, влияющий на безопасность, биллинг или юридические аспекты
Также определите, что не является эскалацией (например, вопросы «как пользоваться», запросы на фичи, незначительные баги) и как такие запросы должны маршрутизироваться.
Роли и ответственность
Перечислите роли, необходимые в вашем процессе, и что каждая из них может делать:
- Agent: проводит триаж и решает, обновляет тикет, следует плейбукам
- Lead: просматривает эскалации, перераспределяет задачи, утверждает изменения приоритета
- Manager: отвечает за отчётность, стандарты коммуникации с клиентом, политику эскалаций
- On-call: получает срочные оповещения и принимает немедленную ответственность в нерабочее время
- Customer admin: создаёт и отслеживает тикеты, добавляет внутренних заинтересованных лиц
Запишите, кто владеет тикетом на каждом шаге (включая передачи) и что означает «владение» (требование ответа, время следующего обновления и полномочия для эскалации).
Каналы, с которых начать
Начните с небольшого набора входов, чтобы быстрее выпустить продукт и сохранить последовательность триажа. Многие команды начинают с email + веб‑формы, затем добавляют чат, когда SLA и правила маршрутизации устоялись.
Цели и метрики успеха
Выберите измеримые показатели, которые приложение должно улучшить:
- Время до первого ответа (в целом и по эскалациям)
- Время до решения или время до смягчения последствий для инцидентов
- Частота повторного открытия и количество «pinged for update»
- Процент пропущенных SLA и время, когда тикет оставался без владельца
Эти решения станут требованиями продукта для дальнейшей разработки.
Спроектируйте модель данных для тикетов, SLA и эскалаций
Приложение для приоритетной поддержки живёт или умирает в зависимости от модели данных. Если фундамент сделать правильно, маршрутизация, отчётность и принудительное соблюдение SLA станут проще — системе будут доступны необходимые факты.
Начните с «базовых» полей тикета (что агенты должны всегда знать)
Как минимум, каждый тикет должен содержать: requester (контакт), company (аккаунт клиента), subject, description и attachments. Обращайтесь с описанием как с первоначальным изложением проблемы; позднее обновления должны храниться в комментариях, чтобы было видно, как развивалась история.
Добавьте поля, специфичные для эскалации (что делает это «приоритетным»)
Эскалации требуют большей структуры, чем обычная поддержка. Частые поля: severity (насколько серьёзна проблема), impact (сколько пользователей/какой доход затронут) и priority (насколько быстро нужно реагировать). Добавьте поле affected service (например, Billing, API, Mobile App), чтобы триаж мог быстрее маршрутизировать.
Для дедлайнов храните явные времена (например, «first response due» и «resolution/next update due»), а не просто «имя SLA». Система может вычислять эти метки времени, но агенты должны видеть точные сроки.
Смоделируйте связи для реальной работы
Практичная модель обычно включает:
- Customers → много Contacts
- Customers → много Tickets
- Tickets → много Comments (internal + public)
- Tickets → много Tasks (чек‑листы, follow‑ups)
Это держит сотрудничество понятным: разговоры в комментариях, действия в задачах, ответственность на тикете.
Определите статусы и держите их консистентными
Используйте небольшой, стабильный набор статусов, например: New, Triaged, In Progress, Waiting, Resolved, Closed. Избегайте «почти одинаковых» статусов — каждое лишнее состояние усложняет отчётность и автоматизацию.
Решите, что должно быть неизменяемым для аудита
Для отслеживания SLA и ответственности некоторые данные должны быть append‑only: created/updated timestamps, история изменений статуса, события старта/остановки SLA, изменения эскалаций и кто сделал каждое изменение. Предпочтительно хранить это в audit log (или в таблице событий), чтобы можно было восстановить ход событий без догадок.
Установите уровни приоритета и правила SLA
Приоритеты и правила SLA — это «контракт», который ваше приложение обеспечивает: что обрабатывается в первую очередь, как быстро и кто за это отвечает. Держите схему простой, документируйте её и усложняйте переопределения только с веской причиной.
Простая схема приоритетов (P1–P4)
Используйте четыре уровня, чтобы агенты быстро классифицировали, а менеджеры могли последовательно строить отчёты:
- P1 — Critical outage / severe impact: продукт не работает, происходит потеря данных или предположительно инцидент безопасности. Несколько пользователей или весь аккаунт клиента заблокированы.
- P2 — Major degradation: ключевые функции частично не работают, обходные пути ограничены, влияние на бизнес серьёзное, но не тотальное.
- P3 — Standard issue: затронут один пользователь или некритичная функция. Есть обходной путь. Большинство тикетов попадает сюда.
- P4 — Low urgency / requests: вопросы «как пользоваться», незначительные баги, запросы на фичи, вопросы по биллингу, не блокирующие использование.
Определяйте в UI «impact» (сколько пользователей/какой охват) и «urgency» (насколько срочно), чтобы снизить неправильную классификацию.
Определите SLA по плану, уровню клиента и приоритету
Модель данных должна позволять варьировать SLA по плану/уровню клиента (например, Free/Pro/Enterprise) и по приоритету. Обычно отслеживают минимум два таймера:
- First response SLA (время до подтверждения и начала владения)
- Resolution SLA или next‑update SLA (время до решения или до информативного обновления)
Пример: Enterprise + P1 может требовать первого ответа за 15 минут, тогда как Pro + P3 — 8 рабочих часов. Показывайте таблицу правил агентам и давайте ссылку на неё в карточке тикета.
Рабочие часы, 24/7 и календари праздников
SLA часто зависят от того, включён ли у плана круглосуточный охват.
- Для business‑hours SLA храните расписание (часовой пояс, рабочие дни, время начала/окончания).
- Для 24/7 SLA часы идут всегда.
- Добавьте holiday calendar (по регионам, если нужно), чтобы таймеры не «нарушались» в дни, когда никто не работает.
Показывайте тикетам и «SLA remaining», и расписание, по которому они считаются, чтобы агенты доверяли таймеру.
Паузы SLA, «ожидает клиента» и обработка нарушений
Реальные потоки требуют пауз. Распространённое правило: приостанавливать SLA, когда тикет в статусе Waiting on customer (или Waiting on third party), и возобновлять при ответе клиента.
Будьте явны в том, что:
- Какие статусы приостанавливают какие SLA‑таймеры
- Применяются ли паузы к response SLA, resolution SLA или к обоим
- Что происходит при нарушении (например, авто‑эскалация приоритета, пейджинг on‑call, уведомление менеджера, пометка тикета «SLA Breached»)
Избегайте «молчаливых» нарушений. Обработка breach должна создавать видимое событие в истории тикета.
Кто уведомляется до и после нарушения
Задайте как минимум два порога оповещений:
- Pre‑breach warning (например, 50% и 80% использования SLA): уведомлять владельца тикета и канал команды
- Breach alert: уведомлять on‑call (для P1/P2), тим‑лида и, опционально, customer success для аккаунтов высокого уровня
Маршрут оповещений должен зависеть от приоритета и уровня клиента, чтобы люди не получали пейджи по шумным P4. Для деталей свяжите этот раздел с вашими on‑call правилами в /blog/notifications-and-on-call-alerting.
Постройте логику триажа, маршрутизации и владения
Триаж и маршрутизация — это то место, где приложение для приоритетной поддержки либо экономит время, либо создаёт хаос. Цель проста: каждый новый запрос должен быстро попадать в правильное место с явным владельцем и понятным следующим шагом.
Создайте inbox для триажа, которому агенты доверяют
Начните с отдельного ящика для unassigned или needs‑review тикетов. Сделайте его быстрым и предсказуемым:
- Сортировка по сигналам срочности (приоритет, время до SLA, уровень клиента)
- Фильтры по продуктовой области, региону/часовому поясу, каналу (email/chat/web) и «VIP» аккаунтам
- Вид «No owner / No category», который выделяет пробелы в данных
Хороший inbox минимизирует клики: агенты должны иметь возможность взять тикет в работу, перенаправить или эскалировать прямо из списка, не открывая каждую карточку.
Определите правила маршрутизации (и делайте их объяснимыми)
Маршрутизация должна быть правиломатичной, но читаемой для не‑инженеров. Частые входные данные:
- Product area (выбирается пользователем, определяется из формы или инферируется по тегам)
- Keywords в subject/body (например, «outage», «invoice», «SSO»)
- Customer tier (стандарт vs приоритет)
- Region (маршрутизация в команды по часовому поясу)
Храните «почему» для каждого решения по маршрутизации (например: “Matched keyword: SSO → Auth team”). Это облегчает разрешение споров и помогает обучению.
Ручные переопределения и пути эскалации
Даже лучшие правила нуждаются в аварийном выходе. Разрешите авторизованным пользователям переопределять маршрутизацию и запускать пути эскалации, например:
Agent → Team lead → On‑call
Переопределения должны требовать короткой причины и создавать запись в аудите. Если позже вы добавите on‑call пейджинг, свяжите действия эскалации с ним (см. /blog/notifications-and-on-call-alerting).
Дедуп и связывание связанных задач
Дублирующие тикеты тратят время SLA. Добавьте лёгкие инструменты:
- Предлагайте возможные дубликаты по клиенту + похожей теме + временно́му окну
- Позволяйте агентам link тикеты к родительскому инциденту («related to INC‑123»)
Связанные тикеты должны наследовать обновления статуса и публичные сообщения от родительского.
Правила владения: одно имя, одна очередь
Определите явные состояния владения:
- Single assignee (один ответственный человек)
- Team queue (неприсвоено внутри команды; использовать, когда передачи часты)
- Handoff (явная передача с заметками и новым SLA‑контролем, если нужно)
Показывайте владение везде: в списковом виде, в шапке тикета и в логе активности. Когда кто‑то спрашивает «Кто это держит?», приложение должно ответить мгновенно.
Создайте дашборд поддержки, которым агенты смогут пользоваться быстро
Приложение для приоритетной поддержки выигрывает или проигрывает в первые 10 секунд, которые агент в нём проводит. Дашборд должен отвечать на три вопроса сразу: что требует внимания сейчас, почему и что можно сделать дальше.
Ключевые представления, которые реально используют агенты
Начните с небольшого набора полезных представлений, а не множества вкладок:
- Queue (worklist): дефолтный вид с фильтрами по приоритету, статусу SLA, каналу, продуктовой области и назначению
- Ticket detail: открывается в один клик, с контекстом и действиями «above the fold»
- Customer profile: компактный вид уровня аккаунта, недавних эскалаций, активных инцидентов и ключевых контактов
- SLA board: тайм‑бейс‑вид, который подчёркивает, что скоро может нарушиться, а не только то, что уже просрочено
Визуальные подсказки, снижающие когнитивную нагрузку
Используйте ясные, согласованные сигналы, чтобы агентам не приходилось «читать» каждую строку:
- Priority chips (P1–P4) с доступным сочетанием цвета и текста (никогда не только цвет)
- SLA countdown (например, «45m до первого ответа») и индикатор «риска нарушения»
- Бейджи «Blocker» (Waiting on customer, Waiting on engineering, Needs approval), чтобы застрявшие задачи были видны
Держите типографику простой: один основной акцентный цвет и плотная иерархия (заголовок → клиент → статус/SLA → последнее обновление).
Быстрые действия и скорость триажа
Каждая строка тикета должна поддерживать быстрые действия без открытия полной карточки:
- Assign / reassign, escalate, change priority, request info, set blocker, add internal note.
Добавьте bulk actions (назначить, закрыть, применить тег, установить блокер) для быстрой очистки бэклога.
Клавиатура, доступность и «без сюрпризов»
Поддержите сочетания клавиш для продвинутых пользователей: / для поиска, j/k для навигации, e для эскалации, a для назначения, g затем q для возврата в очередь.
Для доступности обеспечьте достаточный контраст, видимые состояния фокуса, помеченные элементы управления и текст статуса, удобный для экранных читалок (например, «SLA: 12 минут осталось»). Сделайте таблицу адаптивной, чтобы тот же поток работал на маленьких экранах без скрытия критических полей.
Уведомления и on‑call пейджинг
Сотрудничайте над процессом
Привлекайте лидов и дежурных коллег для совместного просмотра путей эскалации и прав доступа.
Уведомления — это «нервная система» приложения для приоритетной поддержки: они превращают изменения в тикете в своевременные действия. Цель — не оповещать чаще, а оповещать нужных людей, в нужном канале, с достаточным контекстом.
Сопоставьте типы уведомлений
Начните с чёткого набора событий, которые вызывают сообщения. Высокосигнальные типы обычно включают:
- Assignment: тикет назначен или переназначен
- Mention: кто‑то @упомянул агента во внутренней заметке
- SLA warning: тикет приближается к цели первого ответа или решения
- SLA breach: цель пропущена (с указанием причины, если известна)
- Escalation: повышен приоритет, добавлен исполнитель/клиент высшего уровня или объявлен инцидент
Каждое сообщение должно содержать ID тикета, имя клиента, приоритет, текущего владельца, SLA‑таймеры и deep‑link на тикет.
Выбирайте каналы так, чтобы сохранить контроль
Используйте in‑app уведомления для повседневной работы и email для долговременных обновлений и передач. Для реальных on‑call сценариев добавьте SMS/push как опциональный канал, зарезервированный для срочных событий (например, P1 эскалация или неминуемое нарушение SLA).
Предотвращайте усталость от оповещений
Усталость от уведомлений убивает скорость реакции. Добавьте управление группировкой, «тихие часы» и дедупликацию:
- Группируйте повторяющиеся предупреждения по SLA в одну цепочку
- Дедупьте «смену назначения» в коротком окне времени
- Учитывайте тихие часы с возможностью перебить их для критичных инцидентов
Шаблоны и история доставки
Давайте шаблоны как для клиентских ответов, так и для внутренних заметок, чтобы тон и полнота оставались единообразными. Отслеживайте статус доставки (sent, delivered, failed) и ведите временную шкалу уведомлений в карточке тикета для аудита и последующих действий. Простая вкладка «Notifications» в деталях тикета делает это доступным.
Страница деталей тикета: сотрудничество и коммуникация
Страница с деталями — это место, где происходит работа по эскалации. Она должна помогать агентам понять контекст за секунды, координироваться с коллегами и общаться с клиентом без ошибок.
Разделяйте то, что видит клиент, и то, что остаётся внутренним
Сделайте композер явным: Customer Reply или Internal Note, с разным стилем и чётким превью. Внутренние заметки должны поддерживать быстрое форматирование, ссылки на рунибуки и приватные теги (например, «needs engineering»). Клиентские ответы должны по умолчанию подставлять дружелюбный шаблон и показывать, что именно будет отправлено.
Поток сообщений и безопасные вложения
Поддерживайте хронологическую ленту, включающую письма, транскрипты чата и системные события. Для вложений приоритет — безопасность:
- Антивирусная проверка и белый список типов файлов
- Ограничения по размеру и ссылки для скачивания с истечением
- Предупреждения о редактировании для чувствительных данных (токены, пароли)
Если вы показываете файлы, загруженные клиентом, указывайте, кто и когда их загрузил.
Макросы, quick replies и сохранённые шаги
Добавьте macros, которые вставляют заранее утверждённые ответы и чек‑листы по диагностике (например, «собрать логи», «шаги перезапуска», «формулировка для status page»). Позвольте командам поддерживать общую библиотеку макросов с историей версий, чтобы эскалации оставались последовательными и соответствующими требованиям.
Тайм‑лини события
Показывайте компактную временную шкалу ключевых событий: изменения статуса, обновления приоритета, паузы/возобновления SLA, передачи ответственных и сдвиги уровня эскалации. Это предотвращает «что изменилось?» и помогает в последующем разборе инцидента.
Инструменты сотрудничества без лишнего шума
Включите @mentions, followers и связанные задачи (инженерный тикет, документ инцидента). Упоминания должны уведомлять только нужных людей, а подписчики получать сводки при существенных изменениях, а не при каждом наборе текста.
Безопасность, приватность и разрешения
Создайте MVP быстрее
Набросайте процесс эскалации и превратите его в рабочее приложение на Koder.ai.
Безопасность — не «потом» для приложения эскалаций: в тикетах часто есть письма клиентов, скриншоты, логи и внутренние заметки. Закладывайте защиту с ранних этапов, чтобы агенты могли быстро действовать, не раскрывая лишних данных.
Ролевой доступ (RBAC), соответствующий реальной поддержке
Начните с небольшого набора ролей, которые можно объяснить одной фразой (например: Agent, Team Lead, On‑Call Engineer, Admin). Затем пропишите, что каждая роль может просматривать, редактировать, комментировать, переназначать и экспортировать.
Практичный подход — «default deny» для разрешений:
- Escalation visibility: ограничение по команде, очереди и аккаунту клиента
- Edit rights: агентам можно менять статус и добавлять заметки, но изменение SLA, переопределение приоритета и отмена эскалаций — для лидов/админов
- Чувствительные поля: PII (email, телефон), security logs и вложения — отдельные разрешения
Приватность по дизайну: принципы наименьших прав
Собирайте только те данные, которые нужны рабочему процессу. Если вам не нужны полные тела сообщений или полные IP‑адреса — не храните их. Когда храните данные клиентов, чётко помечайте, какие поля обязательны, а какие опциональны, и избегайте лишних копий данных из других систем.
Для паттернов доступа придерживайтесь принципа «агент должен видеть минимум, необходимый для решения тикета». Используйте аккаунт‑скопинг и очередь‑скопинг прежде чем добавлять сложные правила.
Защита базовых вещей: аутентификация, сессии и CSRF
Используйте проверенные решения для аутентификации (SSO/OIDC, когда возможно), требуйте надёжные пароли при их использовании и поддерживайте многофакторную аутентификацию для повышенных ролей.
Укрепите сессии:
- Secure, HttpOnly cookies; короткие сессии для админ‑действий
- Ротация при логине и при изменениях привилегий
- CSRF‑защита для операций, меняющих состояние
Секреты, аудит и доступ к чувствительной информации
Храните секреты в управляемом хранилище секретов (не в исходниках). Логируйте доступ к чувствительным данным (кто просматривал эскалацию, скачивал вложение, делал экспорт) и делайте аудит‑логи защищёнными от подделки и удобными для поиска.
Хранение и экспорты (без лишних обещаний)
Определите правила ретенции для тикетов, вложений и аудит‑логов (например, удалять вложения через N дней, хранить аудит‑логи дольше). Предоставляйте экспорт для клиентов или внутренней отчётности, но не обещайте конкретные сертификаты комплаенса, если не можете их подтвердить. Простые потоки «data export» и админская рабочая последовательность «delete request» — хорошее начало.
Выбор стека технологий и архитектуры
Ваше приложение будет эффективно только если его легко менять. Правила эскалаций, SLA и интеграции постоянно эволюционируют, поэтому отдавайте приоритет стеку, который ваша команда сможет поддерживать и под который можно нанять разработчиков.
Выбирайте стек, подходящий вашей команде
Выбирайте знакомые инструменты вместо «идеальных». Несколько распространённых комбинаций:
- React + Node.js (Express/NestJS): хорошо для интерактивного дашборда и реального времени в UI
- Django (Python): сильные админ‑инструменты, быстрое CRUD‑развитие, отлично для workflow‑heavy приложений
- Rails (Ruby): хорошие соглашения для быстрого создания продуктов в стиле тикетной системы
Если у вас уже есть монолит в другом стеке, совпадение экосистем часто снижает время онбординга и операционную сложность.
Если хотите двигаться быстрее без большого инжинирингового старта, можно прототипировать рабочий процесс на платформе для кодинга вроде Koder.ai — особенно для стандартных частей: React‑панель агента, бэкенд на Go/PostgreSQL и логика SLA/уведомлений.
Хранение данных: сначала реляционные, поиск — там, где нужен
Для основных сущностей — тикетов, клиентов, SLA, событий эскалаций, назначений — используйте реляционную базу (Postgres — распространённый выбор). Она даёт транзакции, ограничения и удобство для отчётов.
Для быстрого поиска по темам, текстам разговоров и именам клиентов подумайте о добавлении поискового индекса (Elasticsearch/OpenSearch). Начните с Postgres full‑text, и переходите к отдельному поиску, если перерастёте его.
Фоновые задания — необходимо
Приложения эскалаций зависят от таймеров и интеграций, которые не должны выполняться в веб‑запросе:
- Таймеры SLA и проверки нарушений
- Уведомления (email/SMS/push)
- Пейджинг on‑call
- Синхронизация сообщений из email/chat/CRM
Используйте очередь заданий (например, Celery, Sidekiq, BullMQ) и делайте задания идемпотентными, чтобы повторы не создавали дубликатов оповещений.
Определите API рано и держите их консистентными
REST или GraphQL — заранее продумайте границы ресурсов: tickets, comments, events, customers, users. Консистентный стиль API ускоряет интеграции и UI. Планируйте webhook‑эндпойнты с самого начала (подписи, повторы, rate limits).
Хостинг и окружения
Поддерживайте минимум dev/staging/prod. Стейджинг должен зеркалить прод (провайдеры электронной почты, очереди, webhooks) с безопасными тестовыми учётными данными. Документируйте деплой и шаги отката, храните конфигурацию в переменных окружения, а не в коде.
Интеграции: Email, Chat, CRM и Webhooks
Интеграции превращают ваше приложение из «ещё одного места для проверки» в систему, в которой команда действительно работает. Начните с каналов, которые используют ваши клиенты, затем добавьте хуки, чтобы другие инструменты могли реагировать на события эскалации.
Email: парсинг входящей почты, отправка, нитевание
Email обычно даёт наибольший эффект. Поддерживайте входящую пересылку (например, support@) и парсите:
- From/To/Cc, subject, body (предпочитайте plain‑text fallback) и вложения
- Message‑ID и In‑Reply‑To для нитевания
- Домен клиента и подсказки подписи для поиска контакта
Для исходящих писем отправляйте из тикета (reply/forward) и сохраняйте заголовки нитевания, чтобы ответы попадали в тот же тикет. Храните чистую хронологию: показывайте то, что видел клиент, а не только внутренние заметки.
Чат: конвертация сообщений в тикеты
Для чата (Slack/Teams/виджеты) делайте просто: конвертируйте разговор в тикет с явным транскриптом и участниками. Не синхронизируйте все сообщения по умолчанию — предложите кнопку «Attach last 20 messages», чтобы агенты контролировали шум.
Синхронизация с CRM/каталогом клиентов: определение уровня и контактов
CRM‑синхрон — это то, как вы делаете «приоритетную поддержку» автоматической. Подтягивайте компанию, план/уровень, ответственного аккаунт‑овнера и ключевые контакты. Сопоставляйте CRM‑аккаунты с вашей моделью клиентов, чтобы новые тикеты наследовали правила приоритета автоматически.
Webhooks для ключевых событий
Предоставляйте webhooks для событий ticket.escalated, ticket.resolved, sla.breached и т. п. Включайте стабильный payload (ticket ID, timestamps, severity, customer ID) и подписывайте запросы, чтобы получатели могли проверять подлинность.
Документируйте и упростите настройку
Добавьте небольшой админ‑флоу с тестовыми кнопками («Send test email», «Verify webhook»). Держите документацию в одном месте (например, /docs/integrations) и указывайте распространённые шаги устранения неполадок: проблемы SPF/DKIM, отсутствие заголовков нитевания, маппинг полей CRM.
Тестирование, мониторинг и надёжность
Планируйте SLA и ответственность
Используйте режим планирования, чтобы смоделировать роли, статусы и правила SLA до генерации кода.
Приложение для приоритетной поддержки становится «источником истины» в напряжённые моменты. Если таймеры SLA дрейфуют, маршруты ломаются или права дают доступ к данным — доверие быстро исчезает. Рассматривайте надёжность как фичу: тестируйте важное, измеряйте происходящее и планируйте на случай отказа.
Тестируйте правила, которые управляют срочностью
Сконцентрируйтесь на автоматизированных тестах для логики, меняющей исходы:
- SLA‑вычисления: условия старта/остановки, рабочие часы, паузы, пороги нарушений и «next due» метки
- Маршрутизация и владение: правила триажа, round‑robin/skill‑based назначение, триггеры эскалации
- Разрешения: RBAC для очередей, деталей тикета, внутренних заметок и клиентских сообщений
Добавьте набор end‑to‑end тестов, имитирующих поток агента (create ticket → triage → escalate → resolve), чтобы ловить расхождения между UI и бэкендом.
Данные для сидирования и реалистичные сценарии
Генерируйте сид‑данные, полезные не только для демо: несколько клиентов, разные уровни (стандарт vs приоритет), разнообразные приоритеты и тикеты в разных состояниях. Включите сложные кейсы: повторно открытые тикеты, «waiting on customer», множественные назначенные. Это делает практику триажа содержательной и помогает QA быстро воспроизводить краевые случаи.
Наблюдаемость: знать раньше, чем скажут клиенты
Инструментируйте приложение так, чтобы отвечать на вопрос: «Что упало, у кого и почему?»
- Трек ошибок для исключений в job‑логике SLA/маршрутизации
- Структурированные логи с ticket ID, rule ID и correlation ID
- Мониторинг производительности для критичных страниц и бэкграунд‑воркеров
Нагрузочное тестирование и безопасное восстановление
Проводите нагрузочные тесты для высоконагруженных представлений: queues, search, dashboards — особенно в моменты смены смены.
И, наконец, подготовьте собственную плей‑книгу инцидента: feature flags для новых правил, шаги отката миграций БД и чёткая процедура отключения автоматизаций при сохранении работоспособности агентов.
План запуска, отчётность и итерации
Приложение для приоритетной поддержки «готово» только тогда, когда агенты доверяют ему в стрессовых ситуациях. Лучший способ добиться этого — запускать маленькими порциями, измерять реальные эффекты и итеративно улучшать.
Начните с MVP, который докажет процесс
Удерживайте импульс и не пытайтесь выпустить всё сразу. Первый релиз должен покрывать кратчайший путь от «новая эскалация» до «решено с ответственностью»:
- Триаж‑очередь с понятной сортировкой (приоритет, время до SLA, уровень клиента)
- Страница тикета с быстрыми обновлениями и внутренними заметками
- Видимые таймеры SLA (first response и resolution/next update, если применимо)
- Базовые оповещения о надвигающихся нарушениях и изменениях статуса
Если вы используете Koder.ai, эта форма MVP хорошо ложится на его дефолты (React UI, Go сервисы, PostgreSQL), а возможность делать snapshot и откат пригодится, пока вы настраиваете расчёт SLA, правила маршрутизации и границы разрешений.
Пилот с небольшой командой и еженедельный обзор
Запустите пилот для небольшой группы (один регион, одна продуктовая линия или одна ротация on‑call) и проводите еженедельный обзор обратной связи. Держите формат структурированным: что замедляло агентов, каких данных не хватало, какие оповещения были шумными и где управление эскалациями давало сбои (передачи, неопределённое владение, неправильная маршрутизация).
Практичный приём: ведите лёгкий changelog внутри приложения, чтобы агенты видели улучшения и чувствовали свою вовлечённость.
Добавьте отчётность, которая даёт действие, а не тщеславие
Когда использование устаканится, вводите отчёты, которые отвечают операционным вопросам:
- Соблюдение SLA: процент нарушений по приоритету, уровню клиента и каналу
- Объём эскалаций: тренды во времени и всплески после релизов
- Основные драйверы: теги/причины, коррелирующие с эскалациями
- Нагрузка на агентов: открытые тикеты на агента и время до первого касания
Эти отчёты должны быть просты для экспорта и понятны нетехническим заинтересованным сторонам.
Итерации правил и макросов на основе реальных результатов
Правила маршрутизации и триажа будут неверны поначалу — это нормально. Настраивайте правила по ошибочным маршрутам, времени решения и обратной связи on‑call. То же самое для макросов: убирайте те, которые не сокращают время, и совершенствуйте те, что улучшают коммуникацию при инцидентах.
Публикуйте простой roadmap и справочные материалы
Держите roadmap коротким и видимым в продукте («Next 30 days»). Даёте ссылки на справку и FAQ, чтобы обучение не превратилось в «племенное знание». Если поддерживаете публичную документацию, делайте её доступной через внутренние ссылки вроде /pricing или /blog, чтобы команды могли самообслуживаться и находить лучшие практики.