Проясните цель: что должен давать цикл обратной связи
Приложение для управления обратной связью — это не просто «место для хранения сообщений». Это система, которая помогает вашей команде надёжно перейти от входа к действию к ответу клиенту, а затем извлечь уроки из произошедшего.
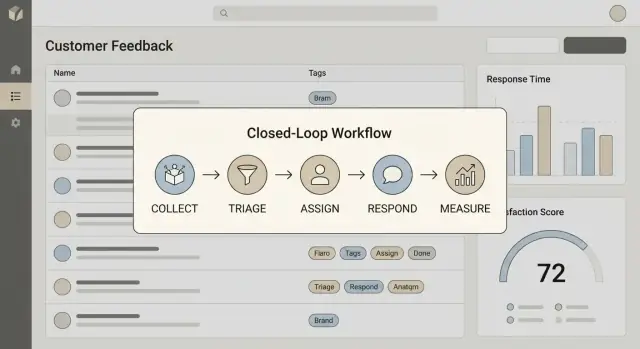
Определите, что означает «закрыть цикл»
Напишите одно‑предложение‑определение, которое команда сможет повторять. Для большинства команд закрытие цикла включает четыре шага:
- Собрать: зафиксировать обратную связь с достаточным контекстом (кто, что, откуда)
- Действовать: превратить это в работу или решение (починить, выпустить, объяснить или отклонить)
- Ответить: сообщить клиенту понятный результат и сроки (даже если это «пока нет»)
- Извлечь уроки: вернуть результаты в приоритизацию, discovery продукта и плейбуки поддержки
Если какой‑то из шагов отсутствует, ваше приложение превратится в кладбище бэклога.
Определите ключевых пользователей и их потребности
Первая версия должна обслуживать реальные повседневные роли:
- Support: быстрый триаж, прозрачность статусов, шаблоны для ответов
- Product: тренды, влияние, ссылки на работу в roadmap
- Customer success: видимость по аккаунтам, проактивные обновления
- Admins: конфигурация, чистота данных, контроль доступа
- Конечные клиенты (опционально): подтверждение получения, обновления, статус самообслуживания
Перечислите решения, которые должно поддерживать приложение
Будьте конкретны в терминах «решений на клик»:
- О чём эта обратная связь (тег/категория)?
- Кто на ней владеет и какой следующий шаг?
- Какой текущий статус и что изменилось с прошлой недели?
- Какой ответ мы отправляем и когда?
Установите измеримые результаты (чтобы понять, работает ли система)
Выберите небольшой набор метрик, отражающих скорость и качество, например время до первого ответа, коэффициент разрешения и изменение CSAT после обратной связи. Эти показатели станут вашим северным ориентиром для последующих решений по дизайну.
Схематизация пути обратной связи и модели данных
До того как проектировать экраны или выбирать базу данных, отобразите, что происходит с обратной связью с момента её создания до момента ответа. Простая карта пути выравнивает команду по тому, что значит «готово», и предотвращает создание фич, не соответствующих реальной работе.
Начните с источников, затем нормализуйте
Перечислите источники обратной связи и отметьте, какие данные каждый даёт надёжно:
- Виджет в приложении (часто содержит контекст пользователя/сессии)
- Email (письма в переписке, вложения)
- Чат (временные метки, информация об агенте)
- Веб‑форма (структурированные поля)
- Отзывы в магазинах приложений (публичный текст, рейтинг)
- Опросы (оценки плюс свободный комментарий)
Даже если входные данные различаются, приложение должно нормализовать их в согласованную «запись обратной связи», чтобы команды могли триажить всё в одном месте.
Определите основные сущности (и делайте их скучными)
Практичная первая модель обычно включает:
- Customer: человек, оставивший обратную связь
- Account: компания или организация (опционально для B2C)
- Feedback item: основная запись (сообщение, источник, метаданные)
Статусы для старта: New → Triaged → Planned → In Progress → Shipped → Closed. Пишите значения статусов, чтобы «Planned» не значил «может быть» для одной команды и «обязательное» для другой.
Решите, что значит «дубликат»
Дубликаты неизбежны. Определите правила заранее:
- Когда два элемента являются дубликатами: та же корневая проблема, тот же запрос на фичу или совпадающие ключевые слова?
- Что делает слияние: объединяет теги, сохраняет обоих клиентов, переносит ответы?
Обычный подход — хранить один каноничный feedback item и связывать другие как дубликаты, сохраняя атрибуцию (кто спросил), без фрагментации работы.
Проектирование основных пользовательских потоков (Inbox → Triage → Action → Reply)
Приложение для обратной связи выигрывает или проигрывает в первый же день по тому, насколько быстро люди могут обработать заявки. Стремитесь к потоку «просмотреть → решить → продолжить», при этом сохраняйте контекст для последующих решений.
1) Inbox: быстрый обзор с нужными фильтрами
Inbox — это общая очередь команды. Он должен поддерживать быстрый триаж с помощью небольшого набора мощных фильтров:
- Source (in‑app, email, chat, app store, sales notes)
- Tag (billing, bugs, feature request, onboarding)
- Status (new, triaged, in progress, shipped, replied)
- Priority (low → urgent)
- Customer tier (free, pro, enterprise)
Добавьте «Сохранённые представления» рано (даже простые), потому что разные команды смотрят по‑разному: Support хочет «urgent + paying», Product — «feature requests + high ARR».
2) Просмотр детали: всё, что нужно для решения
Когда пользователь открывает элемент, он должен видеть:
- Полную историю обратной связи (оригинальный текст плюс правки, слияния и изменения статусов)
- Контекст клиента (план, ценность аккаунта, компания, последнее посещение, NPS/CSAT при наличии)
- Поток переписки, где ответы клиенту и внутренние заметки отделены
Цель — избежать переключения вкладок ради ответа на вопросы: «Кто это, что имелось в виду и отвечали ли мы уже?»
3) Действия триажа: лёгкие, но полные
Из просмотра детали триаж должен выполняться по одному клику на решение:
- Поставить тег и установить приоритет
- Назначить владельца (или очередь команды)
- Слить дубликаты (с одним «каноничным» элементом)
- Связать с фичей/issue, чтобы работа оставалась связанной с реальной клиентской потребностью
4) Ответ: определите, что внешнее, а что внутреннее
Вам, вероятно, понадобятся два режима:
- Только внутренний трекинг (большинство B2B команд): статусы и заметки приватны; клиенты получают прямые ответы при обновлении
- Публичная страница статусов: полезна для прозрачности в масштабе (публичные обновления в стиле changelog). Делайте её опциональной и тщательно курируйте
В любом варианте сделайте «ответ с контекстом» финальным шагом — чтобы закрытие цикла было частью рабочего процесса, а не послесловием.
План ролей, прав и базовой безопасности
Система обратной связи быстро становится общим источником правды: продукт хочет темы, поддержка — быстрые ответы, руководство — выгрузки. Если вы не определите, кто что может делать (и не сможете доказать, что произошло), доверие рушится.
Начните с границ мульти‑тенантности
Если вы будете обслуживать несколько компаний, рассматривайте каждое рабочее пространство как жёсткую границу с первого дня. Каждая основная запись (feedback item, customer, conversation, tags, reports) должна включать workspace_id, и каждый запрос должен быть ограничен им.
Это влияет не только на базу данных — на URL, приглашения и аналитику тоже. Безопасный дефолт: пользователи принадлежат одному или нескольким workspace, а права оцениваются по каждому workspace.
Определите роли, соответствующие реальной работе
Сделайте первую версию простой:
- Admin: управление настройками workspace, биллингом, интеграциями и ролями
- Manager: конфигурация категорий/маршрутов, массовые действия, просмотр отчётов, экспорт
- Agent: триаж, назначение, комментарии и ответы клиентам
Затем свяжите права с действиями, а не с экранами: просмотр vs редактирование обратной связи, слияние дубликатов, изменение статуса, экспорт данных и отправка ответов. Так проще добавить роль «только чтение» позже без переработки всего приложения.
Добавьте журнал аудита рано
Журнал аудита предотвращает споры «кто это поменял?». Логируйте ключевые события с актором, временной меткой и «до/после», где это полезно:
- изменения назначений
- обновления статусов и слияния
- правки тегов/категорий
- отправленные ответы клиентам
Базовая безопасность, которая не замедлит работу
Примените разумную политику паролей, защитите эндпойнты rate limiting (особенно логин и ingestion), и защитите управление сессиями.
Проектируйте с учётом SSO (SAML/OIDC), даже если внедрите позже: храните идентификатор провайдера идентификации и планируйте связывание аккаунтов. Это избавит от болезненного рефакторинга при запросах от enterprise‑клиентов.
Выберите архитектуру, подходящую для первой версии
Ранний архитектурный риск — не «возможность масштабирования?», а «смогу ли я быстро менять систему, не ломая всё?» Приложение по работе с обратной связью быстро эволюционирует по мере того, как вы узнаёте, как команды фактически триажат, маршрутизируют и отвечают.
Начните просто: модульный монолит
Модульный монолит часто — лучший выбор для старта. Вы получаете одну деплой‑единицу, один набор логов и более простую отладку, при этом код остаётся организованным.
Практичное разделение на модули:
- Auth & orgs: пользователи, команды, SSO позже
- Feedback: источники, отправки, вложения, теги
- Workflow: статусы триажа, правила маршрутизации, назначения
- Messaging: исходящие ответы, шаблоны, аудиторский трек
- Analytics: отчёты, экспорт, дашборды
Думайте «разные папки и интерфейсы» до «разных сервисов». Если граница станет болезненной позже (например, увеличение объёма ingestion), её можно извлечь без драм.
Выберите стек, который команда может поддерживать
Отдавайте предпочтение фреймворкам и библиотекам, с которыми команда уверенно выпускает изменения. Скучный, проверенный стек обычно выигрывает, потому что:
- проще нанимать и вводить в команду
- обновления предсказуемее
- отладка продакшна быстрее
Новые инструменты подождут, пока не появятся реальные ограничения (высокая нагрузка ingestion, жесткие требования по задержке, сложные права). Пока что оптимизируйте ради ясности и регулярной доставки.
Хранение данных: сначала реляционная БД, поиск позже
Большинство сущностей — feedback items, customers, accounts, tags, assignments — естественно ложатся в реляционную БД. Вам нужны хорошие возможности запросов, ограничения и транзакции для изменений в workflow.
Если полномтекстовый поиск и фильтрация станут важны, добавьте отдельный поисковый индекс позже (или сначала используйте встроенные возможности БД). Избегайте двух источников правды слишком рано.
Используйте фоновые задачи там, где пользователь не должен ждать
Система быстро накапливает «сделать позже»: отправка писем, синхронизация интеграций, обработка вложений, генерация дайджестов, отправка вебхуков. Внедрите очередь/воркер с самого начала.
Это сохраняет UI отзывчивым, уменьшает таймауты и делает ошибки повторяемыми, не вынуждая вас переходить на микросервисы в день запуска.
Быстрый путь к рабочему MVP (если нужно двигаться быстрее)
Если цель — быстро проверить рабочий процесс и UI (inbox → triage → replies), рассмотрите использование платформы для быстрой генерации прототипа, чтобы получить первую версию из структурированного спецификационного чата. Это поможет поднять React‑фронтенд с Go + PostgreSQL бэкендом, итеративно тестировать в «planning mode» и затем экспортировать код, когда будете готовы перейти в классический инженерный рабочий процесс.
Реализация хранения: схема, индексы и правила хранения
Слой хранения решает, будет ли цикл обратной связи быстрым и надёжным или медленным и запутанным. Стремитесь к схеме, которую легко запросить для повседневной работы (триаж, назначение, статус), сохраняя при этом достаточно сырых данных для аудита.
Практичная стартовая модель данных
Для MVP большинство задач покрывает небольшой набор таблиц/коллекций:
Полезное правило: держите feedback лёгким (то, что вы часто запрашиваете) и выносите «всё остальное» в events и метаданные по каналам.
Храните сырые payloadы для прослеживаемости
Когда тикет приходит по email, чату или webhook, сохраняйте сырой incoming payload точно как получен (например, оригинальные заголовки письма + тело или JSON вебхука). Это помогает:
- решать проблемы парсинга («почему тема была обрезана?»)
- доказывать, что было получено при спорных ситуациях
- перепроцессить старые данные после улучшения парсера
Обычная схема: таблица ingestions с полями source, received_at, raw_payload (JSON/text/blob) и ссылкой на созданный/обновлённый feedback_id.
Индексируйте под запросы, которые реально выполняются
Большинство экранов сводится к нескольким предсказуемым фильтрам. Добавьте индексы рано для:
(workspace_id, status) для inbox/kanban представлений(workspace_id, assigned_to) для «моих задач»(workspace_id, created_at) для сортировки и фильтров по датам- теги: либо
(tag_id, feedback_id) в join‑таблице, либо отдельный индекс для поиска по тегам
Если вы поддерживаете полнотекстовый поиск, рассмотрите отдельный поисковый индекс (или встроенный текстовый поиск СУБД), а не нагружайте продакшн сложными LIKE‑запросами.
Хранение, удаление и «право быть забытым»
Обратная связь часто содержит персональные данные. Решите заранее:
- сколько хранить сырые payloadы (обычно меньше, чем нормализованные записи)
- как обрабатывать GDPR‑запросы на удаление (удалять или анонимизировать идентификаторы клиентов и редактировать сырые payloadы)
- что происходит при оффбординге клиента (экспорт + отложенное удаление)
Реализуйте политику хранения по workspace (например, 90/180/365 дней) и выполняйте её плановой задачей, которая сначала удаляет сырые ingestions, затем старые events/replies при необходимости.
Реализуйте ingestion: захват обратной связи из нескольких каналов
Ingestion — место, где ваш цикл обратной связи либо остаётся чистым и полезным, либо превращается в беспорядок. Стремитесь к «легко отправлять, последовательно обрабатывать». Начните с нескольких каналов, которыми уже пользуются клиенты, затем расширяйтесь.
Варианты захвата для раннего релиза
Практичный старт обычно включает:
- Виджет в приложении: небольшая форма для идей и проблем (опционально скриншот). Минимум: сообщение, категория, email.
- API‑эндпойнт: внутренние инструменты или партнёры могут отправлять обратную связь программно. Предпочитайте простой JSON‑схему и API‑ключ на workspace.
- Захват email: уникальный адрес на workspace (например, feedback+acme@...). Парсите тему/тело, сохраняйте сырое письмо для аудита.
- CSV‑импорт: полезен для миграций и исследовательских батчей. Валидируйте столбцы и показывайте предпросмотр перед импортом.
Защита от спама и контроль качества
Вам не нужна тяжёлая фильтрация с первого дня, но нужны базовые защиты:
- CAPTCHA для публичных виджетов
- Ограничения по длине текста (например, 5–5000 символов) и лимиты на размер вложений
- Индикаторы возможных дубликатов: хэш нормализованного сообщения + области продукта или обнаружение «почти дубликатов» по похожей теме. Не удаляйте автоматически; помечайте как «возможный дубликат».
Нормализуйте входы, чтобы downstream‑работа была последовательной
Нормализуйте каждое событие в единый внутренний формат с согласованными полями:
- Source (widget, API, email, CSV)
- Идентификаторы клиента (workspace, account ID, contact email, план)
- Product area (billing, onboarding, mobile и т.д.)
Сохраняйте и сырой payload, и нормализованную запись, чтобы можно было улучшать парсер без потери данных.
Авто‑подтверждение, задающее ожидания
Отправляйте мгновенное подтверждение (по email/API/widget, когда возможно): поблагодарите, опишите, что будет дальше, и не давайте обещаний. Пример: «Мы просматриваем каждое сообщение. Если нужны уточнения, мы ответим. Мы не можем ответить каждому лично, но ваша обратная связь зафиксирована.»
Создайте систему триажа и маршрутизации, которая масштабируется
Inbox полезен только пока команды могут быстро ответить на три вопросы: Что это? Кто владеет? Насколько срочно? Триаж превращает сырые сообщения в организованную работу.
Начните с контролируемой системы тегов
Свободные теги кажутся гибкими, но быстро фрагментируют («login», «log-in», «signin»). Начните с небольшой контролируемой таксономии, которая отражает, как продуктовые команды уже мыслят:
- Область продукта (Billing, Mobile, Admin)
- Тема (Bug, Feature request, UX issue)
- Влияние (Blocker, High, Normal)
Разрешайте пользователям предлагать новые теги, но требуйте владельца (например, PM/lead поддержки) для утверждения. Это сохраняет отчётность значимой.
Используйте правила автотриажа, чтобы сократить ручную сортировку
Постройте простой движок правил, который может автоматически направлять обратную связь по предсказуемым сигналам:
- Ключевое слово/намерение: «refund», «cancel», «invoice» → Billing queue
- План/уровень аккаунта: Enterprise → очередь приоритета
- Область продукта: из URL, модуля приложения или выбранной категории
Держите правила прозрачными: показывайте «Routed because: Enterprise plan + keyword 'SSO'». Люди доверяют автоматизации, когда могут её аудировать.
Делайте SLA видимыми, а не скрытыми
Добавьте таймеры SLA в каждый элемент и очередь:
- Время до первого ответа (как быстро вы подтверждаете)
- Время до закрытия (как быстро вы разрешаете или приходите к выводу)
Показывайте состояние SLA в списке («осталось 2ч») и в карточке детали, чтобы срочность была общей, а не в голове одного человека.
Добавьте эскалации и напоминания в рабочий процесс
Создайте понятный путь, когда элементы застревают: очередь просроченных, ежедневные дайджесты владельцам и лёгкая лестница эскалации (Support → Team lead → On‑call/Manager). Цель — не давление, а предотвращение тихого пропадания важной обратной связи.
Закрытие цикла: связывайте работу с ответами клиентам
Закрытие цикла — момент, когда система перестаёт быть «ящиком для сбора» и становится инструментом построения доверия. Цель проста: каждую обратную связь можно связать с реальной работой, и клиенты, которые просили, получают информацию о результате — без ручных таблиц.
Связывайте обратную связь с внутренней работой
Начните с того, что один feedback item может указывать на один или несколько внутренних рабочих объектов (bug, task, feature). Не пытайтесь зеркалить весь issue‑трекер — храните лёгкие ссылки:
work_type (например, issue/task/feature)external_system (например, jira, linear, github)external_id и опционально external_url
Это сохраняет модель данных стабильной даже при смене инструментов позже. Также позволяет делать виды «покажи всю клиентскую обратную связь, связанную с этим релизом» без скрейпинга других систем.
Определите workflow «Shipped», который уведомляет всех
Когда связанная работа переходит в Shipped (или Done/Released), ваше приложение должно уведомить всех клиентов, привязанных к соответствующим элементам обратной связи.
Используйте шаблонное сообщение с безопасными плейсхолдерами (имя, область продукта, краткое описание, ссылка на релиз‑ноты). Оставьте сообщение редактируемым перед отправкой, чтобы избежать неловкой формулировки. Если у вас есть публичные заметки, ссылайтесь на них относительно через /releases.
Каналы ответов и трекинг
Поддерживайте ответы через те каналы, от которых вы надёжно можете отправлять:
- Email
- In‑app уведомление
- Webhook в вашу систему сообщений
Что бы вы ни выбрали, фиксируйте ответы по каждому feedback item с аудиторным таймлайном: sent_at, channel, author, template_id и статус доставки. Если клиент отвечает обратно, сохраняйте входящие сообщения с временными метками, чтобы команда могла доказать, что цикл действительно закрыт — а не просто помечен как «shipped».
Добавьте отчётность, которая помогает командам принимать решения
Отчёты полезны, только если они меняют поведение команд. Стремитесь к нескольким представлениям, которые люди проверяют ежедневно, а затем расширяйте, когда уверены, что исходные данные — статус, теги, владельцы, временные метки — консистентны.
Дашборды, отвечающие на вопрос «что требует внимания?»
Начните с операционных дашбордов, которые поддерживают маршрутизацию и follow‑up:
- Объём по источникам (email, in‑app, соцсети, звонки): замечайте сдвиги каналов и потребности в кадрах
- Топ тегов/категорий: какие темы растут на этой неделе
- Бэклог по статусу (new, triaged, in progress, waiting on customer, closed): где застряла работа
- Соответствие SLA: время до первого ответа и время до закрытия по целям
Держите графики простыми и кликабельными, чтобы менеджер мог углубиться в конкретные элементы, стоящие за всплеском.
Вид на уровне клиента для более содержательных диалогов
Добавьте страницу «customer 360», которая помогает поддержке и success‑командам отвечать с контекстом:
- Вся обратная связь от этого клиента по всем каналам
- Последний контакт и кто отвечал
- Открытые элементы и текущий статус/владелец
- Место для лёгких заметок о настроении (например, «расстроен из‑за биллинга; предпочитает email») — не как черный ящик с баллом
Этот вид уменьшает повторные вопросы и делает follow‑up более целенаправленным.
Экспорт без подрыва доверия
Команды попросят экспорт рано. Дайте:
- CSV‑экспорт, который уважает те же фильтры, что и UI
- Read‑only API‑эндпойнты для отчётности/BI
Сделайте фильтрацию консистентной везде (те же имена тегов, диапазоны дат, определения статусов). Это предотвращает «две версии правды».
Избегайте показательных метрик
Не делайте дашборды, которые меряют только активность (создано тикетов, добавлено тегов). Предпочитайте метрики результата, связанные с действием и ответом: время до первого ответа, % элементов, достигших решения, и повторяющиеся проблемы, которые были реально решены.
Интегрируйтесь с инструментами, где уже работают команды
Цикл обратной связи работает только если он живёт там, где люди проводят время. Интеграции уменьшают копипаст, сохраняют контекст рядом с работой и превращают «закрытие цикла» в привычку, а не в отдельный проект.
Начните с интеграций, которые разблокируют повседневную работу
Приоритет отдавайте системам, в которых команда общается, строит и отслеживает клиентов:
- Slack / Microsoft Teams: уведомлять нужный канал о высоко‑импактной обратной связи, назначении владельца или отправке ответа клиенту
- Jira / Linear: связывать обратную связь с issue (или создавать её), чтобы инженерная работа оставалась прослеживаемой
- Синхронизация CRM (Salesforce/HubSpot): прикреплять обратную связь к аккаунтам/контактам, чтобы support и success имели полный контекст
Первую версию держите простой: односторонние уведомления + deep links обратно в ваше приложение, затем добавляйте действия записи (например, «Назначить владельца» из Slack) позже.
Добавьте вебхуки для расширяемости
Даже если вы выпустите только несколько нативных интеграций, вебхуки позволяют клиентам и внутренним системам подключать всё остальное.
Предлагайте небольшой стабильный набор событий:
feedback.createdfeedback.updatedfeedback.closed
Включайте idempotency key, временные метки, tenant/workspace id и минимальный payload плюс URL для получения полного объекта. Это помогает не ломать потребителей при эволюции модели данных.
Делайте ошибки видимыми и восстанавливаемыми
Интеграции падают по обычным причинам: отозванные токены, лимиты, сетевые ошибки, несовпадение схем. Проектируйте на это заранее:
- Ретраи с экспоненциальной задержкой для временных ошибок
- Dead‑letter queue для повторяющихся сбоев
- Простая страница состояния интеграций (последний успех, последняя ошибка, следующая попытка)
- Действующие состояния ошибок в UI (например, «Reconnect Slack» или «Permission missing in Jira")
Если вы упаковываете это как продукт, интеграции — важный триггер покупки. Добавьте понятные шаги из приложения (и маркетингового сайта) на /pricing и /contact для команд, которые хотят демо или помощи с подключением стека.
Выпустите MVP, затем улучшайте по реальным данным использования
Эффективное приложение для обратной связи не «завершено» после релиза — оно формируется тем, как команды триажат, действуют и отвечают. Цель первого релиза проста: подтвердить рабочий процесс, сократить ручную работу и собрать чистые данные, которым можно доверять.
Определите MVP, который мал, но завершён
Держите объём узким, чтобы быстро выпустить и учиться. Практичный MVP обычно включает:
- Одно рабочее пространство (без сложности мульти‑орг)
- Основной inbox с поиском и базовыми фильтрами
- Тегирование/категоризация и простое назначение
- Базовый поток ответов (даже если сначала это простые email‑шаблоны)
Если фича не помогает команде обработать обратную связь end‑to‑end, она может подождать.
Тестируйте то, что подрывает доверие
Ранние пользователи простят отсутствие фич, но не потерянную обратную связь или некорректную маршрутизацию. Сосредоточьтесь на тестах там, где ошибка дорога:
- Unit‑тесты для правил маршрутизации, логики тегирования и проверок прав
- Integration‑тесты для источников ingestion и вебхуков (включая ретраи и дублирующие события)
Стремитесь к уверенности в рабочем процессе, а не к идеальному покрытию.
Планируйте эксплуатационную реальность
Даже MVP нуждается в нескольких «скучных» вещах:
- Мониторинг для ошибок ingestion и очередей фоновых задач
- Резервные копии и процесс восстановления, который вы уже проверяли
- Трекинг ошибок с контекстом, достаточным для воспроизведения
- Лёгкие инструменты админа (пропустить событие, переназначить элементы, поправить плохие теги)
Релизуйте как продуктный эксперимент
Начните с пилота: одна команда, ограниченный набор каналов и чёткая метрика успеха (например, «ответить на 90% high‑priority обратной связи в течение 2 дней»). Собирайте проблемные точки еженедельно и итеративно улучшайте рабочий процесс перед расширением на другие команды.
Трактуйте данные использования как роадмап: где кликают, где бросают, какие теги не используются и какие «хак‑обходы» раскрывают реальные требования.