SQL против NoSQL: ключевые отличия и сценарии применения
Узнайте ключевые отличия между SQL и NoSQL: модели данных, языки запросов, согласованность, масштабируемость и примеры, когда каждая база подходит лучше.
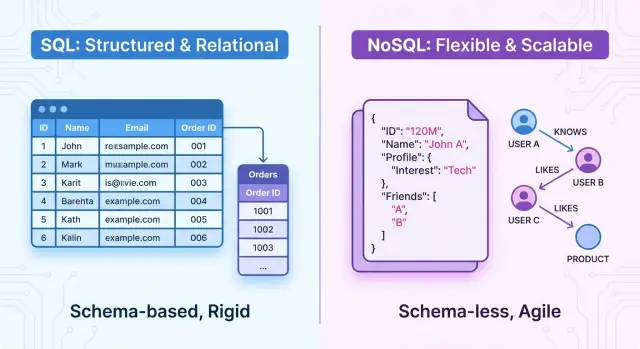
Обзор: SQL и NoSQL в двух словах
Выбор между SQL и NoSQL базами данных формирует то, как вы проектируете, строите и масштабируете приложение. Модель хранения влияет на всё: структуру данных, шаблоны запросов, производительность, надёжность и скорость эволюции продукта командой.
Вкратце, SQL‑базы данных — это реляционные системы. Данные организованы в таблицы с фиксированными схемами, строками и столбцами. Связи между сущностями явные (через внешние ключи), а для запросов используется SQL — мощный декларативный язык. Эти системы делают упор на ACID‑транзакции, строгую согласованность и предсказуемую структуру.
NoSQL‑базы данных — это нереляционные системы. Вместо единой жёсткой табличной модели они предлагают несколько моделей данных, оптимизированных под разные задачи, например:
- Key‑value хранилища
- Документные базы
- Wide‑column хранилища
- Графовые базы
То есть «NoSQL» — это не одна технология, а зонтик для множества подходов, у каждого из которых свои компромиссы по гибкости, производительности и моделированию данных. Многие NoSQL‑системы ослабляют строгие гарантии согласованности ради высокой масштабируемости, доступности или низкой задержки.
Эта статья фокусируется на разнице между SQL и NoSQL — моделях данных, языках запросов, производительности, масштабируемости и согласованности (ACID vs eventual consistency). Цель — помочь выбрать между SQL и NoSQL для конкретных проектов и понять, когда каждая категория подходит лучше.
Не обязательно выбирать только одно: современные архитектуры часто используют polyglot persistence, где SQL и NoSQL сосуществуют в одной системе, каждая обрабатывает те нагрузки, для которых она оптимальна.
Что такое SQL (реляционная) база данных?
SQL (реляционная) база данных хранит данные в структурированной табличной форме и использует Structured Query Language (SQL) для определения, запроса и изменения этих данных. Она построена вокруг математической концепции отношений, которую можно представить как хорошо организованные таблицы.
Основная структура: таблицы, строки, столбцы и схемы
Данные организованы в таблицы. Каждая таблица представляет тип сущности, например customers, orders или products.
- Строка (запись) — один экземпляр сущности, например один клиент.
- Столбец (поле) — конкретный атрибут, например
emailилиorder_date.
Каждая таблица следует фиксированной схеме: заранее заданной структуре, которая определяет
- какие столбцы существуют
- их типы данных (например,
INTEGER,VARCHAR,DATE) - ограничения (например,
NOT NULL,UNIQUE)
Схема обеспечивается базой данных, что помогает поддерживать согласованность и предсказуемость данных.
Ключи и связи
Реляционные базы отлично моделируют связи между сущностями.
- Первичный ключ однозначно идентифицирует каждую строку в таблице (например,
customer_id). - Внешний ключ — столбец, который ссылается на первичный ключ в другой таблице, связывая связанные записи.
Эти ключи позволяют задавать отношения, такие как:
- One‑to‑many (один клиент — много заказов)
- Many‑to‑many (товары в многих заказах, заказы с множеством товаров)
Транзакции и свойства ACID
Реляционные базы поддерживают транзакции — группы операций, которые выполняются как единое целое. Транзакции определяются свойствами ACID:
- Атомарность: все операции выполняются полностью или не выполняется ничего.
- Согласованность: транзакции переводят базу из одного корректного состояния в другое.
- Изолированность: параллельные транзакции не мешают друг другу.
- Долговечность: после фиксации данные надёжно сохраняются.
Эти гарантии критичны для финансовых систем, управления запасами и любых приложений, где важна корректность.
Распространённые SQL‑СУБД
Популярные реляционные СУБД:
- MySQL и MariaDB
- PostgreSQL
- Microsoft SQL Server
- Oracle Database
Все они реализуют SQL, добавляя собственные расширения и инструменты для администрирования, настройки производительности и безопасности.
Что такое NoSQL (нереляционная) база данных?
NoSQL — это нереляционные хранилища данных, которые не используют традиционную модель таблица–строка–столбец. Они ориентированы на гибкие модели данных, горизонтальную масштабируемость и высокую доступность, часто в обмен на строгие транзакционные гарантии.
Гибкие модели данных
Многие NoSQL‑системы называют «schema‑less» или имеют гибкую схему. Вместо жёсткой схемы заранее вы можете хранить записи с разной структурой в одной коллекции или бакете.
Это особенно полезно для:
- Быстрого изменения требований приложения
- Полуструктурированных данных (логи, события, профили пользователей)
- Хранения вложенных данных в формате JSON
Поля можно добавлять или пропускать в отдельных записях, поэтому разработчики могут быстрее итеративно развивать модель без миграций для каждого изменения структуры.
Основные типы NoSQL
NoSQL — это набор разных моделей:
- Документные базы: хранят документы в формате, похожем на JSON, с вложенными полями. Примеры: MongoDB, Couchbase.
- Key–value хранилища: простые ассоциативные массивы, где ключ сопоставлен со значением — хорошо подходит для кэша и сессий. Примеры: Redis, Amazon DynamoDB (в режиме key–value).
- Column‑family хранилища: организуют данные по семействам колонок для высокой пропускной способности записей и «широких» таблиц. Примеры: Apache Cassandra, HBase.
- Графовые базы: сосредоточены на узлах и отношениях — идеальны для сильно связанных данных. Примеры: Neo4j, Amazon Neptune.
Модели согласованности
Многие NoSQL‑системы ставят в приоритет доступность и устойчивость к разделениям сети, предоставляя eventual consistency вместо строгих ACID‑транзакций по всему набору данных. Некоторые дают настраиваемые уровни согласованности или ограниченные трансакционные возможности (на уровне документа, партиции или диапазона ключей), так что можно выбирать между более жёсткими гарантиями и более высокой производительностью для конкретных операций.
Модели данных: структура, схемы и связи
Моделирование данных — то место, где SQL и NoSQL ощущаются наиболее по‑разному. Оно определяет, как вы проектируете функционал, строите запросы и эволюционируете приложение.
Структура и схемы
SQL‑базы используют строгие, предопределённые схемы. Вы проектируете таблицы и столбцы заранее, с жёсткими типами и ограничениями:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Каждая строка обязана соответствовать схеме. Изменения обычно требуют миграций (ALTER TABLE, backfilling и т.п.).
NoSQL‑базы обычно поддерживают гибкие схемы. Документное хранилище может допускать документы с разными полями:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Поля можно добавлять в отдельные документы без общей миграции. Некоторые NoSQL‑системы всё же предлагают опциональные или принудительные схемы, но в целом они мягче.
Нормализация vs денормализация
Реляционные модели поощряют нормализацию: разделение данных на связанные таблицы, чтобы избежать дублирования и поддерживать целостность. Это даёт быстрые и согласованные записи и экономию места, но чтения могут требовать множества JOIN‑ов.
NoSQL чаще склоняется к денормализации: встраивание связанных данных вместе под те запросы, которые важны. Это улучшает производительность чтения и упрощает запросы, но записи становятся сложнее — одинаковая информация может храниться в нескольких местах.
Моделирование связей
В SQL связи явны и защищены:
- One‑to‑many: внешние ключи (users → orders)
- Many‑to‑many: таблицы связей (users_roles)
В NoSQL связи моделируются через:
- Встраивание (user документ содержит массив orders) для тесно связанных данных
- Ссылки (user_id в документе заказа) для слабо связанных или больших коллекций
Выбор зависит от шаблонов доступа:
- Если вы всегда загружаете пользователя с его последними 10 заказами, встраивание может быть идеальным.
- Если заказы большие, часто обновляются или доступны независимо, ссылки и отдельные запросы предпочтительнее.
Влияние на эволюцию требований
В SQL изменения схем требуют планирования, но дают сильные гарантии и согласованность по всему набору данных: миграции, backfill‑ы, обновления ограничений. В NoSQL требования эволюционируют легче в краткосрочной перспективе: можно сразу начать записывать новые поля и постепенно обновлять старые документы. Компромисс — код приложения должен уметь работать с разными формами документов и граничными случаями.
Выбор между нормализованной SQL‑моделью и денормализованной NoSQL‑моделью — не вопрос «лучше/хуже», а выравнивания структуры данных с шаблонами запросов, объёмом записей и частотой изменения доменной модели.
Языки запросов и шаблоны доступа
SQL: декларативный и стандартизованный
SQL‑базы запрашиваются декларативным языком: вы описываете что хотите, а не как это достать. Конструкции SELECT, WHERE, JOIN, GROUP BY, ORDER BY позволяют выражать сложные вопросы по множеству таблиц в одном выражении.
Поскольку SQL стандартизован (ANSI/ISO), большинство СУБД имеют общий синтаксис ядра. Вендоры добавляют расширения, но навыки и запросы часто переносятся между PostgreSQL, MySQL, SQL Server и другими.
Эта стандартизация даёт развитую экосистему: ORM, билдоры запросов, инструменты отчётности, BI‑дашборды, фреймворки миграций и оптимизаторы запросов. Многие из этих инструментов можно подключить к любой SQL‑СУБД с минимальными изменениями, что снижает vendor lock‑in и ускоряет разработку.
NoSQL: API запросов и свои паттерны
NoSQL‑системы предоставляют разнообразные способы запросов:
- Документные хранилища (MongoDB, Couchbase) используют JSON‑подобные объекты запросов и иногда собственные языки запросов.
- Key‑value хранилища (Redis, DynamoDB) ориентированы на обращения по первичному ключу и небольшой набор вторичных индексов.
- Wide‑column системы (Cassandra, HBase) оптимизируют запросы, соответствующие заранее заданному шаблону первичного/кластерного ключа.
- Поисковые движки (Elasticsearch, Solr) используют DSL, ориентированный на полнотекстовые и релевантные запросы.
Некоторые NoSQL дают агрегирующие конвейеры или MapReduce‑подобные механизмы, но межколлекционные или межпартиционные JOIN‑ы ограничены или отсутствуют. Вместо этого связанные данные часто встраивают в один документ или денормализуют по записям.
Шаблоны доступа и продуктивность
Реляционные запросы часто полагаются на JOIN‑heavy паттерны: нормализуйте данные, затем восстанавливайте сущности при чтении с помощью JOIN‑ов. Это удобно для ad‑hoc отчётности, но сложные JOIN‑ы могут быть трудны для оптимизации.
NoSQL‑шаблоны — документно‑или ключ‑центристские: проектируйте данные вокруг наиболее частых запросов. Чтения быстрые и простые — часто одно обращение по ключу, но изменение шаблонов доступа позднее требует переработки данных.
Для обучения и продуктивности:
- Декларативная модель SQL и множество материалов делают его удобным и долговечным навыком.
- Запросы в NoSQL могут быть проще для простых, известных паттернов, но синтаксис и ограничения различаются между системами.
Команды, которым нужны богатые ad‑hoc запросы через связи, обычно выбирают SQL. Команды с устойчивыми, предсказуемыми шаблонами доступа и очень большой нагрузкой чаще находят модель NoSQL более подходящей.
Согласованность, транзакции и компромиссы CAP
ACID: строгие гарантии в SQL‑системах
Большинство SQL‑СУБД ориентированы на ACID‑транзакции:
- Атомарность: транзакция либо полностью выполняется, либо полностью отменяется.
- Согласованность: каждая зафиксированная транзакция переводит данные в корректное состояние, соблюдая ограничения.
- Изолированность: параллельные транзакции не проявляют побочных эффектов (через уровни изоляции: READ COMMITTED, REPEATABLE READ, SERIALIZABLE).
- Долговечность: после commit данные сохраняются (с помощью WAL, репликации и т.п.).
Это делает SQL подходящим, когда корректность важнее высокой пропускной способности записей.
BASE и eventual consistency в многих NoSQL
Многие NoSQL системы склонны к BASE:
- Basically Available: система стремится оставаться доступной.
- Soft state: данные могут временно отличаться между репликами.
- Eventual consistency: при отсутствии новых обновлений реплики со временем сходятся.
Записи могут быть очень быстрыми и распределёнными, но чтение может увидеть устаревшее состояние.
CAP на практике
Теорема CAP говорит, что распределённая система при сетевых разделениях должна выбирать между:
- Consistency (C): все клиенты видят одни и те же данные одновременно.
- Availability (A): каждый запрос получает ответ.
Во время partition нельзя гарантировать и C, и A одновременно.
Типичные выборы:
- Многие SQL‑развёртки предпочитают строгую согласованность: это важно для платежей, учёта запасов, балансов, бронирований, где устаревшее чтение может привести к денежным потерям или нарушению правил.
- Многие NoSQL‑настройки отдают приоритет доступности и eventual consistency: подходит для аналитики, лент, каталогов продуктов, логов, кэшей, где небольшие временные рассогласования допустимы, а скорость и аптайм ценнее.
Современные системы часто смешивают режимы (например, настраиваемая согласованность на операцию), чтобы разные части приложения могли выбирать нужные гарантии.
Различия в масштабируемости и производительности
Как обычно масштабируются SQL‑базы
Традиционные реляционные СУБД проектировались для одного мощного узла.
Как правило, начинают с вертикального масштабирования: больше CPU, RAM и быстрые диски на одном сервере. Многие движки также поддерживают read replicas: дополнительные узлы для чтений, в то время как все записи идут на primary. Этот подход подходит для:
- Умеренного объёма записей
- Тяжёлых аналитических или отчётных запросов
- Нагрузок, где важна строгая согласованность
Однако вертикальное масштабирование ограничено аппаратными и ценовыми рамками, а реплики могут вносить задержку репликации для чтений.
NoSQL и горизонтальное масштабирование
NoSQL системы обычно созданы для горизонтального масштабирования: данные распределяются по всем узлам через sharding или партиционирование. Каждый шард хранит часть данных, поэтому и чтения, и записи можно распределять, повышая пропускную способность.
Такой подход подходит для:
- Массовых записей и высоких объёмов трафика
- Очень больших наборов данных, превышающих возможности одной машины
- Глобальных приложений, где данные нужно размещать ближе к пользователю
Цена — более высокая операционная сложность: выбор ключа шарда, ребалансировка и работа с кросс‑шардовыми запросами.
Шаблоны производительности и индексация
Для чит‑ориентированных нагрузок со сложными JOIN‑ами и агрегатами SQL с грамотно настроенными индексами может быть экстремально быстрым: оптимизатор использует статистику и планы выполнения.
Многие NoSQL‑системы ориентированы на простые обращения по ключу. Они отлично показывают себя при низкой задержке и высокой пропускной способности, когда запросы предсказуемы и модель данных спроектирована под них. Задержки в NoSQL‑кластерах могут быть очень низкими, но кросс‑партиционные запросы, вторичные индексы и многодокументные операции могут быть медленнее или ограничены.
Операционно масштабирование NoSQL обычно означает больше управления кластером, тогда как масштабирование SQL часто сводится к лучшему железу и тщательной индексации на меньшем числе узлов.
Когда SQL‑база обычно — лучший выбор
Нагрузки с транзакциями и бизнес‑критичные системы
Реляционные базы превосходят, когда нужны надёжные OLTP‑нагрузки:
- Финансовые системы (платежи, бухгалтерия, торговля)
- Управление заказами и запасами
- ERP, CRM и биллинговые платформы
Эти системы полагаются на ACID‑транзакции, строгую согласованность и предсказуемое поведение отката. Если перевод средств никогда не должен привести к двойному списанию, SQL обычно безопаснее.
Структурированные данные и сложные связи
Когда модель данных хорошо понятна и стабильна, а сущности сильно связаны, реляционная база часто естественный выбор. Примеры:
- Клиенты, заказы, счета, продукты и отгрузки
- Медицинские записи: пациенты, визиты, рецепты, лаборатории
Нормализованные схемы, внешние ключи и JOIN‑ы облегчают поддержание целостности без дублирования.
Аналитика по чётким схемам
Для отчётности и BI над структурированными схемами (звёздная/снежинка, data marts) SQL‑совместимые склады данных обычно предпочтительнее. Аналитики знают SQL, а существующие инструменты интегрируются напрямую.
Зрелость, навыки и соответствие требованиям
В дебатах «реляционные vs нереляционные» важно учитывать зрелость операций. SQL базы предоставляют:
- Долгопроверенную надёжность и инструменты
- Большой пул инженеров, DBA и аналитиков, владеющих SQL
- Функции для аудита, контроля доступа, шифрования и бэкапов, нужные для регуляторных рамок
Когда аудит, сертификация или юридические риски существенны, SQL часто проще защитить и обосновать.
Когда NoSQL обычно — лучший выбор
NoSQL чаще подходит, когда масштаб, гибкость и постоянная доступность важнее сложных JOIN‑ов и строгих транзакций.
Высокая нагрузка и огромные системы
Если ожидается гигантский объём записей, всплески трафика или данные в терабайтах и больше, NoSQL (key‑value, wide‑column) легче масштабировать по горизонтали. Шардинг и репликация обычно встроены, и вы просто добавляете узлы.
Типичные сценарии:
- Высоконагруженные веб‑ и мобильные приложения
- Бэкенды игр и real‑time лидерборды
- Ad‑tech, рекомендательные движки, персонализация
Гибкость данных при быстрой итерации продукта
Когда модель данных часто меняется, гибкая или schema‑less модель полезна. Документные базы позволяют вводить новые поля без миграций.
Хорошо подходит для:
- CMS и каталогов товаров
- Профилей пользователей и предпочтений
- Лент активности и событий, где постоянно появляются новые типы событий
IoT, кэширование и временные ряды
NoSQL силён в нагрузках с большим количеством вставок и упорядоченных по времени данных:
- IoT‑телеметрия и сенсорные данные
- Метрики, логирование и мониторинг
- Кэширование (сессии, токены, feature flags)
Key‑value и time‑series базы оптимизированы для быстрых записей и простых чтений.
Глобальное распределение и always‑on
Многие NoSQL платформы делают ставку на гео‑репликацию и запись в нескольких регионах, обеспечивая низкую задержку для пользователей по всему миру. Это полезно, когда:
- Приложение должно работать при региональных сбоях
- Пользователи в разных континентах требуют локальной скорости отклика
Цена — часто eventual consistency вместо строгого ACID между регионами.
Ограничения и компромиссы
Выбирая NoSQL, часто отказываются от привычных возможностей SQL:
- Слабее или настраиваемая согласованность; чтения могут быть устаревшими
- Ограниченная ad‑hoc аналитика и JOIN‑ы; нужно проектировать доступы заранее
- Больше ответственности приложения за обеспечение целостности данных
Когда эти компромиссы принимаемы, NoSQL даёт лучшую масштабируемость, гибкость и глобальную доступность.
Гибридные паттерны и polyglot persistence
Polyglot persistence — сознательное использование нескольких технологий хранения в одной системе, выбирая лучший инструмент для каждой задачи.
Типичный гибрид
Обычный подход:
- SQL для критичных данных: заказы, платежи, профили пользователей, конфигурации — там нужна сильная согласованность и транзакции.
- NoSQL для сессий и кэша: key‑value (Redis‑стиль) для сессий, лимитов, feature flags; документное хранилище для предпочтений и лент.
Так «система записи» остаётся в реляционной базе, а быстро меняющиеся или тяжёлые для чтения нагрузки выносятся в NoSQL.
Комбинация разных NoSQL типов
Можно комбинировать NoSQL решения:
- Key‑value для кэша и сессий
- Документная для контента и данных пользователей с гибкой схемой
- Wide‑column / time‑series для метрик и логов
- Поисковый движок для полнотекстового поиска и аналитики
Цель — выровнять каждое хранилище под конкретный шаблон доступа: быстрые lookup‑ы, агрегаты, поиск или чтения по времени.
Интеграция и операционные затраты
Гибридные архитектуры опираются на интеграцию:
- ETL или стриминг для синхронизации данных между хранилищами
- Event streaming для распространения изменений (например, из SQL в кэш или аналитические хранилища)
- API, скрывающие, где хранятся данные, чтобы сервисы не зависели от конкретного хранилища
Компромисс — операционная нагрузка: больше технологий изучать, мониторить, защищать, бэкапить и отлаживать. Polyglot persistence оправдана, когда каждое дополнительное хранилище решает реальную измеримую проблему.
Как выбирать между SQL и NoSQL для проекта
Выбор — это сопоставление ваших данных и шаблонов доступа с подходящим инструментом, а не следование моде.
1. Начните с данных и связей
Спросите:
- Естественно ли мои данные табличны с явными сущностями (пользователи, заказы, счёта)?
- Много ли у меня JOIN‑ов и сложных связей (1‑to‑many, many‑to‑many)?
Если «да», реляционная SQL‑база обычно по умолчанию. Если данные документоподобны, вложены или сильно различаются по записям, документная или другая NoSQL‑модель может подойти лучше.
2. Уточните требования по согласованности и транзакциям
- Нужны ли мне мульти‑строчные/мульти‑табличные ACID‑транзакции (платежи, запасы)?
- Приемлемы ли для меня частично устаревшие чтения?
Строгая согласованность и сложные транзакции обычно говорят в пользу SQL. Высокая нагрузка с ослабленной согласованностью — в пользу NoSQL.
3. Поймите масштаб и производительность
- Какой объём чтений/записей сейчас и через 2–3 года?
- Нужна ли низкая задержка в нескольких регионах?
Многие проекты можно масштабировать на SQL при грамотной индексации и железе. Если ожидается очень большой рост с простыми паттернами доступа, некоторые NoSQL‑решения будут экономичнее.
4. Шаблоны запросов и отчётность
- Нужны ли ad‑hoc аналитика, JOIN‑ы и гибкие отчёты?
- Кто будет делать запросы: только инженеры или аналитики/бизнес‑пользователи?
SQL превосходит для сложных запросов, BI‑инструментов и ad‑hoc исследования. NoSQL лучше для заранее известных путей доступа и может затруднять новые типы запросов.
5. Навыки команды, инструменты и хостинг
- Чем команда уже владеет: SQL‑проектированием или конкретными NoSQL‑системами?
- Что доступно в хостинге (managed PostgreSQL/MySQL, managed MongoDB, DynamoDB)?
- Какие библиотеки, драйверы и мониторинг лучше интегрируются с нашим стеком?
Отдавайте предпочтение технологиям, которые команда умеет эксплуатировать, особенно для прод‑траблов и миграций.
6. Стоимость и операционная сложность
- Можем ли мы позволить себе управлять распределёнными NoSQL‑кластерами, или managed SQL‑инстанс закроет потребности?\
- Как соотносятся стоимости хранения и операций для ожидаемой нагрузки?
Один управляемый SQL‑экземпляр часто дешевле и проще, пока вы явно не перерастёте его.
7. Всегда тестируйте на реалистичных нагрузках
Перед финальным решением:
- Смоделируйте небольшой набор данных в SQL‑схеме и в кандидатной NoSQL‑модели.\
- Реализуйте ключевые запросы и операции записи.\
- Запустите нагрузочные тесты с реалистичными объёмами и трафиком.\
- Измерьте задержки, пропускную способность, ошибки и операционные затраты.
Опирайтесь на измерения, а не на предположения. Для многих проектов старт с SQL — самый безопасный путь с возможностью добавления NoSQL для отдельных задач позже.
Распространённые мифы о SQL и NoSQL
Миф 1: NoSQL вытеснит SQL
NoSQL не пришёл «убить» реляционные базы; он дополнил их.
Реляционные базы по‑прежнему доминируют как системы записи: финансы, HR, ERP, инвентари. NoSQL полезен там, где важны гибкие схемы, высокая пропускная способность или глобальное распределение.
Большинство организаций в итоге используют оба подхода.
Миф 2: SQL не умеет масштабироваться горизонтально
Раньше реляционные СУБД масштабировались в основном вверх, но современные движки поддерживают:
- Read replicas
- Шардинг/партиционирование
- Distributed SQL (NewSQL)
Горизонтальный рост реляционных систем возможен, но требует проектирования и инструментов.
Миф 3: NoSQL не имеет схем и правил
«Schema‑less» означает, что схема контролируется приложением, а не базой данных.
Документные, key‑value и wide‑column хранилища всё равно имеют структуру; она просто более гибкая. Без контрактов и валидации данные быстро становятся непоследовательными.
Миф 4: Один тип всегда быстрее
Производительность зависит от моделирования данных, индексов и шаблонов запросов, а не просто от категории SQL/NoSQL.
Плохо индексированная NoSQL‑коллекция будет медленнее, чем правильно настроенная реляционная таблица для многих запросов. И наоборот, плохая реляционная схема уступит хорошо продуманной NoSQL‑модели для специфичных запросов.
Миф 5: SQL всегда безопаснее и надёжнее
Многие NoSQL решения поддерживают надёжность, шифрование, аудит и контроль доступа. И наоборот, неправильно настроенная реляционная база может быть небезопасной и хрупкой.
Надёжность и безопасность зависят от конкретного продукта, развертывания, конфигурации и уровеня операционной зрелости — а не только от ярлыка «SQL» или «NoSQL».
Стратегии миграции и совместного использования
Команды обычно переходят между SQL и NoSQL по двум причинам: масштаб и гибкость. Часто сохраняют реляционную базу как систему записи и добавляют NoSQL для чтений в масштабе или для новых функций с гибкой схемой.
Паттерны миграции
Риск большой‑банг миграции велик. Более безопасные варианты:
- Инкрементальная миграция: выделите bounded context (каталог товаров) и перенесите только его в NoSQL.\
- Dual writes: в течение переходного периода писать и в старую, и в новую базу.\
- Sync pipelines: одна БД остаётся первичной, а изменения стримятся в другую через CDC, очереди или ETL.
Подводные камни моделей и схем
При переносе таблиц в NoSQL соблазн копировать таблицы в документы или key‑value часто приводит к:
- чрезмерной нормализации в NoSQL и множеству join‑ов на уровне приложения
- неограниченному росту документов
Проектируйте NoSQL‑схему вокруг реальных шаблонов доступа, а не зеркально переносите таблицы.
Сосуществование и страховочные механизмы
Частый паттерн: SQL как authoritative data, NoSQL для read‑heavy views (ленты, поиск, кэш). В любом сценарии вкладывайтесь в:
- повторимые backfill‑ы и процедуры отката
- валидацию данных между хранилищами
- нагрузочные тесты, отражающие реальные шаблоны запросов
Это делает миграции контролируемыми, а не болезненными однонаправленными переходами.
Резюме и практические рекомендации
SQL и NoSQL различаются главным образом в четырёх областях:
- Модель данных — SQL: таблицы и строгие схемы; NoSQL: документы, key‑value, wide‑column или графы с более гибкой структурой.
- Запросы — SQL предлагает единый выразительный язык; NoSQL чаще использует специфичные API/синтаксис.
- Согласованность и транзакции — SQL ориентирован на ACID и строгую согласованность; многие NoSQL‑системы жертвуют частичными гарантиями ради доступности, масштаба или латентности.
- Масштабирование — SQL традиционно масштабируется вверх (и всё чаще наружу через кластеры); NoSQL обычно проектируется для шардинга и репликации по множеству узлов.
Ни одна категория не универсально лучше. «Правильный» выбор зависит от ваших реальных требований, а не от трендов.
Как выбирать на практике
-
Опишите ваши потребности:
- Структура данных и связи
- Шаблоны запросов и отчётность
- Ожидания по согласованности vs доступности
- Пиковый трафик, объём данных, целевые задержки
- Навыки команды и доступные инструменты
-
По умолчанию разумно:
- Предпочитайте SQL для транзакционных систем, аналитики и структурированных бизнес‑данных.
- Рассмотрите NoSQL для больших объёмов записей, гибкой/полуструктурированной информации или очень больших масштабов.
-
Начните с малого и измеряйте:
- Постройте небольшой proof‑of‑concept.
- Собирайте метрики: задержки запросов, throughput, ошибки, усилия по эксплуатации.
- Итеративно улучшайте схемы, индексы и партиционирование на основе реального использования.
-
Будьте открыты к гибридам:
- Используйте несколько БД, если части системы имеют разные требования.\
- Документируйте решения, компромиссы и паттерны в внутренней базе знаний (например, в
/docs/architecture/datastoresи в/blog).
Для детального погружения дополните этот обзор внутренними стандартами, чек‑листами миграции и материалами в инженерном справочнике или блоге.
FAQ
В чем основная разница между SQL и NoSQL базами данных?
SQL (реляционные) базы данных:
- Используют таблицы с строками и столбцами.
- Принуждают к фиксированной схеме (определённые столбцы, типы, ограничения).
- Запросы выполняются на SQL — стандартизованном языке.
- Делают упор на ACID‑транзакции и строгую согласованность.
NoSQL (нереляционные) базы данных:
- Используют гибкие модели (документы, key‑value, wide‑column, графы).
- Часто допускают схему‑flexible или schema‑less.
- Предоставляют специфичные для БД API или DSL для запросов.
- Часто жертвуют частью гарантии согласованности ради масштабируемости и доступности.
Когда обычно лучше выбирать SQL базу данных?
Используйте SQL, когда:
- Данные хорошо структурированы и реляционны (пользователи, заказы, счета).
- Нужны ACID‑транзакции, охватывающие несколько строк/таблиц.
- Корректность и согласованность важнее сырой пропускной способности.
- Ожидаются частые ad‑hoc запросы, JOIN‑ы и отчётность.
- Важны соответствие требованиям, аудит и долгосрочная поддерживаемость.
Для большинства новых систем учёта и «системы записи» SQL — разумный выбор по умолчанию.
Когда обычно лучше выбирать NoSQL базу данных?
NoSQL подходит, когда:
- Нужно масштабировать запись и хранение по горизонтали.
- Данные полуструктурированные, вложенные или часто меняют форму.
- Шаблоны доступа известны заранее и могут быть спроектированы под ключ/документ.
- Допускаются временные рассогласования (ленты, логи, аналитические представления).
- Обрабатываются IoT‑телеметрия, временные ряды, кэширование или массовый пользовательский контент.
Как схемы и моделирование данных различаются между SQL и NoSQL?
SQL базы данных:
- Используют предопределённые схемы; каждая строка должна соответствовать определению таблицы.
- Поощряют нормализацию для уменьшения дублирования и обеспечения целостности.
- Управляют отношениями через внешние ключи и ограничения.
NoSQL базы данных:
- Разрешают документы/записи с разными полями в одной коллекции.
- Часто поощряют денормализацию и встраивание связанных данных.
- Больше полагаются на приложение для поддержания правил целостности данных.
Итог: контроль схемы перемещается из базы данных (SQL) в приложение (NoSQL).
Как SQL и NoSQL отличаются в вопросах согласованности и транзакций?
SQL базы данных:
- Сосредоточены на ACID‑транзакциях со строгой согласованностью.
- Подходят, когда каждый чтение должно видеть актуальное, корректное состояние.
Многие NoSQL системы:
- Делают ставку на доступность и устойчивость к разделениям сети.
- Следуют принципам BASE и eventual consistency: реплики со временем сходятся.
- Могут предлагать настраиваемую согласованность для отдельных операций или диапазонов ключей.
Выбирайте SQL, когда устаревшие чтения недопустимы; NoSQL — когда кратковременная несогласованность приемлема ради масштабируемости и доступности.
Как SQL и NoSQL базы данных обычно масштабируются?
SQL базы обычно:
- Масштабируются вертикально (мощнее серверы).
- Используют реплики для масштабирования чтений.
- Иногда применяют шардинг или распределённые SQL решения для горизонтального роста.
NoSQL базы обычно:
- Проектируются для горизонтального масштабирования изначально.
- Шардируют/партиционируют данные по множеству узлов.
- Позволяют добавлять ёмкость, добавляя узлы на кластер.
Компромисс: NoSQL‑кластеры сложнее в эксплуатации, а SQL‑решения могут раньше упереться в пределы одного узла.
Можно ли использовать SQL и NoSQL вместе в одной системе?
Да. Полиглотное хранение (polyglot persistence) — обычная практика:
- SQL как «источник истины» (платежи, аккаунты, ключевые сущности).
- NoSQL для сессий, кэша, лент, логов или поиска.
Шаблоны интеграции:
- Change Data Capture или стриминг изменений из SQL в NoSQL.
- Периодические ETL‑процессы для построения read‑optimized представлений.
- Сервисы/API, скрывающие, где именно хранятся данные.
Важно добавлять каждое хранилище только тогда, когда оно решает конкретную задачу.
Как подходить к миграции между SQL и NoSQL?
Переход безопаснее проводить поэтапно:
- Выделите ограниченный контекст (например, каталог товаров) для миграции.
- Проектируйте данные вокруг новых шаблонов доступа, а не «таблица→документ».\
- Используйте двойную запись или CDC, чтобы временно держать оба хранилища синхронизированными.\
- Валидируйте данные между хранилищами и планируйте многократные backfill‑процедуры.\
- Перенаправляйте трафик поэтапно и имейте план отката.
Избегайте «большого взрыва» — предпочитайте инкрементальные, хорошо промониторенные шаги.
Какие факторы следует оценивать при выборе между SQL и NoSQL?
Оценивайте:
- Структуру данных: табличные с явными связями или гибкие документы/события.
- Потребности в согласованности: строгие ACID‑требования или допустима устарелость.
- Масштаб и задержки: ожидаемый объём записей, размер данных, глобальные пользователи.\
- Шаблоны запросов: ad‑hoc аналитика и JOIN‑ы или предсказуемые ключевые/документные обращения.\
- Навыки команды и доступный стек: что команда умеет эксплуатировать.\
- Стоимость и операционную сложность: managed vs собственные кластеры.
Рекомендуется прототипировать критические потоки и измерять задержки, throughput и сложность, прежде чем принимать окончательное решение.
Какие распространённые мифы существуют про SQL и NoSQL?
Распространённые мифы:
- «NoSQL заменит SQL» — на практике они дополняют друг друга.
- «SQL не масштабируется горизонтально» — современные реляционные системы поддерживают реплики, шардинг и распределённый SQL.\
- «NoSQL не имеет схем» — схемы существуют, но их часто обеспечивает приложение или валидация.\
- «Один тип всегда быстрее» — производительность зависит от моделирования данных, индексов и шаблонов запросов.
Оценивайте конкретные продукты и архитектуры, а не опирайтесь на обобщённые мифы.