12 сент. 2025 г.·7 мин
Стартовый набор наблюдаемости для продакшна: мониторинг с первого дня
Стартовый набор наблюдаемости для первого дня: минимальные логи, метрики и трассы, которые стоит добавить, и простой поток триажа для жалоб «медленно».
Стартовый набор наблюдаемости для первого дня: минимальные логи, метрики и трассы, которые стоит добавить, и простой поток триажа для жалоб «медленно».
Первым обычно ломается не всё приложение. Чаще всего это один шаг, который внезапно становится узким местом: один запрос, который в тестах был нормален, или одна зависимость, которая начала таймаутиться. Реальные пользователи добавляют реальное разнообразие: медленнее устройства, нестабильные сети, странные вводы и всплески трафика в неудобное время.
Когда кто‑то говорит «медленно», это может значить очень разное. Страница может долго грузиться, взаимодействия могут лагать, один API‑вызов может таймаутиться, фоновые задания могут накапливаться, или сторонний сервис тянет всё вниз.
Именно поэтому сигналы важнее дашбордов на первом этапе. В первый день вам не нужны идеальные графики для каждого эндпоинта. Нужны достаточные логи, метрики и трассы, чтобы быстро ответить на один вопрос: куда уходит время?
Есть и реальный риск переинструментирования. Слишком много событий создаёт шум, стоит денег и может даже замедлить приложение. Ещё хуже: команда перестаёт доверять телеметрии, потому что она кажется бардаком и непоследовательной.
Реалистичная цель на первый день проста: когда приходит жалоба «медленно», вы должны найти медленный шаг меньше чем за 15 минут. Нужно уметь сказать, является ли узким местом рендеринг на клиенте, обработчик API и его зависимости, база/кеш или фоновый воркер/внешний сервис.
Пример: новый поток оформления заказа кажется медленным. Даже без горы инструментов вы хотите иметь возможность сказать: «95% времени уходит на вызовы платёжного провайдера» или «запрос корзины сканирует слишком много строк». Если вы быстро разрабатываете приложения с помощью Koder.ai, этот базовый минимум на первый день ещё важнее: скорость релиза полезна, только если вы умеете быстро отлаживать.
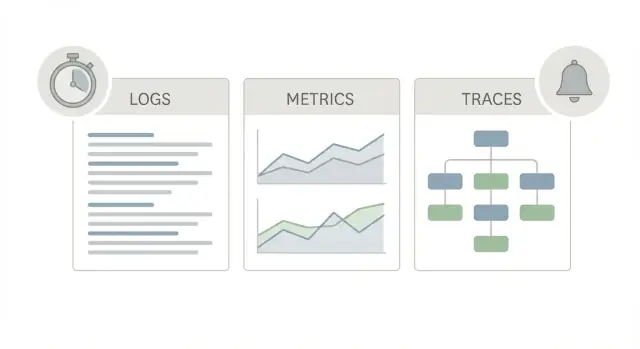
Хороший стартовый набор наблюдаемости использует три разных «вида» одной и той же системы, потому что каждый отвечает на свой вопрос.
Логи — это история. Они говорят, что произошло для одного запроса, одного пользователя или одной фоновой задачи. Строка лога может сказать «платёж не прошёл для заказа 123» или «тайм-аут БД после 2s», плюс детали: request ID, user ID и текст ошибки. Когда кто‑то жалуется на странную единичную проблему, логи часто самые быстрые для подтверждения того, что это действительно случилось и кого это затронуло.
Метрики — табло. Это числа, по которым можно смотреть тренды и ставить алерты: скорость запросов, доля ошибок, перцентильные задержки, CPU, глубина очереди. Метрики показывают, редкая это проблема или массовая, и ухудшается ли ситуация. Если задержка поднялась у всех в 10:05, метрики это покажут.
Трассы — карта. Трасса следует за одним запросом по системе (web -> API -> database -> third‑party). Она показывает, где тратится время, шаг за шагом. Это важно, потому что «медленно» почти никогда не единая большая тайна. Чаще всего это один медленный переход.
Во время инцидента практический поток такой:
Простое правило: если через несколько минут вы не можете указать одно узкое место, вам не нужно больше алертов. Вам нужны лучшие трассы и согласованные ID, которые связывают трассы и логи.
Большинство инцидентов «не можем найти» происходят не из‑за отсутствия данных, а потому что одно и то же записывают по‑разному в разных сервисах. Пара общих соглашений на первый день делает логи, метрики и трассы сопоставимыми, когда вам нужны быстрые ответы.
Начните с выбора одного имени сервиса на каждую деплойную единицу и держите его стабильным. Если «checkout-api» в одной панели становится просто «checkout» в другой, вы теряете историю и ломаете алерты. То же самое для меток среды: выберите небольшой набор, например prod и staging, и используйте их везде.
Дальше — облегчили трассировку запроса. Генерируйте request ID на краю (API gateway, веб‑сервер или первый обработчик) и передавайте его по HTTP‑вызовам, очередям сообщений и фоновым задачам. Если в тикете поддержки написано «медленно в 10:42», один ID позволяет достать точные логи и трассу без догадок.
Набор конвенций, который хорошо работает на первый день:
Согласуйте единицы времени рано. Выберите миллисекунды для API‑латентности и секунды для длинных задач и придерживайтесь этого. Смешанные единицы создают графики, которые выглядят нормально, но дают неверную картину.
Конкретный пример: если каждый API логирует duration_ms, route, status и request_id, то отчёт вроде «checkout медленный для tenant 418» становится быстрым фильтром, а не предметом дебатов, с чего начать.
Если вы сделаете только одну вещь в стартовом наборе, сделайте логи удобными для поиска. Это начинается со структурированных логов (обычно JSON) и одинаковых полей во всех сервисах. Неформатированные текстовые логи годятся для локальной разработки, но превращаются в шум при реальном трафике, ретраях и множественных инстансах.
Правило: логируйте то, что действительно будете использовать во время инцидента. Большинству команд нужно ответить: какой это был запрос? кто его сделал? где это упало? что он затронул? Если строка лога не помогает ответить на один из этих вопросов, скорее всего, её не стоит логировать.
На первый день держите небольшой, согласованный набор полей, чтобы фильтровать и объединять события по сервисам:
Когда происходит ошибка, залогируйте её один раз с контекстом. Включите тип ошибки (или код), короткое сообщение, стек‑трэйс для серверных ошибок и вовлечённую внешнюю зависимость (например: postgres, payment provider, cache). Избегайте повторного логирования одного и того же стека на каждом ретрае. Вместо этого прикрепляйте request_id, чтобы можно было проследить цепочку.
Пример: пользователь жалуется, что не может сохранить настройки. Один поиск по request_id показывает 500 на PATCH /settings, затем таймаут к Postgres с duration_ms. Не понадобились полные полезные нагрузки, только маршрут, пользователь/сессия и имя зависимости.
Конфиденциальность — это часть логирования, а не задача на потом. Не логируйте пароли, токены, заголовки авторизации, полные тела запросов или чувствительные PII. Если нужно идентифицировать пользователя, логируйте стабильный ID (или его хеш), а не email или телефон.
Если вы разрабатываете приложения на Koder.ai (React, Go, Flutter), стоит заложить эти поля в каждый сгенерированный сервис с самого начала, чтобы не приходилось «переделывать логирование» во время первого инцидента.
Хороший стартовый набор метрик — это маленький набор показателей, который быстро отвечает на один вопрос: здорова ли система сейчас, и если нет, то где болит?
Большинство проблем в проде проявляется через четыре «золотых» сигнала: задержка (latency), трафик (traffic), ошибки (errors) и насыщение (saturation). Если вы видите эти четыре сигнала для ключевых частей приложения, можно триажить большинство инцидентов без догадок.
Задержка должна быть представлена перцентилями, а не средними. Отслеживайте p50, p95 и p99, чтобы увидеть, когда небольшая группа пользователей испытывает проблемы. Для трафика начните с запросов в секунду (или задач в минуту для воркеров). Для ошибок разделяйте 4xx и 5xx: рост 4xx часто означает изменения в поведении клиента или валидации; рост 5xx указывает на проблемы в вашем приложении или его зависимостях. Насыщение — это сигнал «нам чего‑то не хватает» (CPU, память, соединения БД, очередь).
Минимальный набор, покрывающий большинство приложений:
Конкретный пример: если пользователи жалуются «медленно» и p95 API подскакивает при ровном трафике, проверьте насыщение. Если использование пула БД почти на max и растут тайм‑ауты, скорее всего, это узкое место. Если БД в порядке, но глубина очереди растёт, возможно, фоновые задачи отъедают ресурсы.
Если вы разрабатываете на Koder.ai, считайте этот чеклист частью определения готовности на первый день. Проще добавить метрики, пока приложение небольшое, чем в разгар инцидента.
Когда пользователь говорит «медленно», логи часто говорят, что случилось, а метрики — насколько часто. Трассы показывают, куда ушло время внутри одного запроса. Эта временная линия превращает смутное жалование в понятное действие.
Начните с серверной стороны. Инструментируйте входящие запросы на краю приложения (первый обработчик), чтобы каждый запрос мог породить трассу. Клиентская трассировка может подождать.
Хорошая трасса первого дня имеет спаны, соответствующие частям, которые обычно вызывают задержки:
Чтобы трассы было удобно искать и сравнивать, сохраняйте несколько ключевых атрибутов и держите их одинаковыми везде.
Для входного спана запишите route (шаблон вида /orders/:id, а не полный URL), HTTP‑метод, status code и latency. Для спанов БД фиксируйте систему БД (PostgreSQL, MySQL), тип операции (select, update) и, если легко добавить, имя таблицы. Для внешних вызовов записывайте имя зависимости (payments, email, maps), целевой хост и статус.
Сэмплирование важно: иначе затраты и шум быстро вырастут. Используйте простое правило: трассируйте 100% ошибок и медленных запросов (если SDK поддерживает) и сэмплируйте небольшой процент нормального трафика (1–10%). Начинайте с более высокой доли при низком трафике, потом снижайте.
Пример «хорошей» трассы: одна трасса, где можно прочитать историю сверху вниз. Например: GET /checkout занял 2.4s, БД — 120ms, кеш — 10ms, а внешний платёжный вызов занял 2.1s с ретраем. Теперь понятно, что проблема в зависимости, а не в коде. Это основа стартового набора наблюдаемости для продакшна.
Когда говорят «медленно», самый быстрый выигрыш — превратить это ощущение в несколько конкретных вопросов. Этот поток триажа работает даже для совсем нового приложения.
Сначала сузьте проблему, затем следуйте за доказательствами по порядку. Не прыгайте сразу в базу данных.
После стабилизации сделайте одно небольшое улучшение: запишите, что случилось, и добавьте недостающий сигнал. Например, если нельзя было понять, ограничено ли замедление одним регионом, добавьте тег region в метрики задержки. Если увидели длинный спан БД без понимания, какой это запрос, аккуратно добавьте метки запросов или поле «query name».
Быстрый пример: если p95 checkout вырос с 400 ms до 3 s, а трассы показывают 2.4 s в платёжном вызове, можно перестать спорить про код и сосредоточиться на провайдере оплаты, ретраях и таймаутах.
Когда говорят «медленно», можно потратить час на выяснение смысла жалобы. Набор наблюдаемости полезен только если помогает быстро сузить проблему.
Начните с трёх уточняющих вопросов:
Потом посмотрите несколько чисел, которые обычно подсказывают, куда идти дальше. Не ищите идеальную панель — вам нужны признаки «хуже чем обычно».
Если p95 вырос, а ошибки остались на месте, откройте одну трассу для медленного маршрута в последние 15 минут. Одна трасса часто показывает, тратится ли время на БД, внешний API или ожидание блокировок.
Далее выполните поиск по логам. Если у вас есть конкретный отчёт от пользователя, ищите по request_id и читайте таймлайн. Если нет — ищите наиболее частое сообщение об ошибке в том же временном окне и смотрите, совпадает ли оно со спадом.
Наконец, решите: смягчить сейчас или копнуть глубже. Если пользователи заблокированы и наблюдается насыщение, быстрая ремедиация (масштабирование, откат или отключение необязательной фичи) может дать время. Если влияние небольшое и система стабильна — продолжайте расследование с трассами и логами медленных запросов.
Несколько часов после релиза приходят тикеты поддержки: «Оформление заказа занимает 20–30 секунд». Никто не может воспроизвести это локально, и начинается хаотичное гадание. Здесь стартовый набор наблюдаемости оправдывает себя.
Сначала идём в метрики и подтверждаем симптом. График p95 задержки для HTTP показывает явный всплеск, но только для POST /checkout. Другие маршруты в порядке, уровень ошибок стабилен. Это сужает круг с «весь сайт медленный» до «медлен один эндпоинт после релиза».
Дальше открываем трассу для медленного POST /checkout. Водопад трассы показывает очевидного виновника. Два распространённых исхода:
Проверяем логи по тому же request ID (или по trace ID, если он есть в логах). В логах для этого запроса видно повторяющиеся предупреждения вроде «payment timeout reached» или «context deadline exceeded», плюс ретраи, добавленные в новом релизе. Если виновата база, в логах могут быть сообщения о ожидании блокировок или само медленное SQL‑выражение, залогированное по порогу.
Когда все три сигнала сходятся, исправление становится очевидным:
Ключ в том, что вы не угадываете. Метрики указали эндпоинт, трассы — медленный шаг, а логи подтвердили режим отказа с точным запросом.
Большая часть времени инцидента уходит на предсказуемые пробелы: данные есть, но они шумные, рискованные или не хватает одной детали, чтобы связать симптомы с причиной. Стартовый набор полезен только если остаётся работоспособным под стрессом.
Одна ловушка — логировать слишком много, особенно сырые тела запросов. Звучит полезно, пока вы не платите за гигантское хранилище, поиск становится медленным, и вы случайно не захватываете пароли, токены или персональные данные. Предпочитайте структурированные поля (route, status code, latency, request_id) и логируйте только небольшие, явным образом разрешённые фрагменты входа.
Ещё одна потеря времени — метрики, которые детализированы, но их невозможно агрегировать. Метки с высокой кардинальностью вроде полных user ID, email или уникальных номеров заказов взрывают количество временных рядов и делают дашборды ненадёжными. Используйте грубые метки (имя маршрута, HTTP‑метод, класс статуса, имя зависимости) и держите пользовательскую информацию в логах.
Ошибки, которые регулярно мешают быстрой диагностике:
Небольшой практичный пример: если p95 для checkout вырос с 800ms до 4s, вы хотите ответить за минуты: началось ли это сразу после деплоя, и тратится ли время в вашем коде или во внешней зависимости? С перцентилями, меткой релиза и трассами с именами маршрутов и зависимостей это легко. Без них вы сжигаете окно инцидента на споры и догадки.
Реальный выигрыш — в согласованности. Стартовый набор помогает только если каждый новый сервис отправляется с одинаковыми базовыми вещами, названными одинаково и легко доступными при сбое.
Превратите ваши решения первого дня в короткий шаблон, который команда будет переиспользовать. Держите его маленьким, но конкретным.
Создайте одну «домашнюю» панель, которую может открыть любой во время инцидента. Один экран должен показывать запросы в минуту, уровень ошибок, p95 задержку и ваш главный показатель насыщения, с фильтром по среде и версии.
Держите алерты минимальными сначала. Два алерта покрывают многое: всплеск ошибок на ключевом маршруте и всплеск p95 задержки на том же маршруте. Если добавляете больше, у каждого должен быть чёткий план действий.
Наконец, назначьте ежемесячный обзор. Удаляйте шумные алерты, уточняйте имена и добавляйте один отсутствующий сигнал, который сэкономил бы время в последнем инциденте.
Чтобы встроить это в процесс сборки, добавьте «ворота наблюдаемости» в чеклист релиза: нельзя деплоить без request_id, меток версии, домашней панели и двух базовых алертов. Если вы работаете с Koder.ai, вы можете определять эти сигналы в режиме планирования до деплоя, а затем безопасно итератировать с помощью снимков и отката, когда нужно быстро подстраиваться.
Начните с той части, куда попадают пользователи в первую очередь: веб-сервер, API-шлюз или первый обработчик.
request_id и передавайте его через все внутренние вызовы.route, method, status и duration_ms для каждого запроса.Этого обычно достаточно, чтобы быстро перейти к конкретному эндпоинту и временному окну.
Цель по умолчанию: вы можете определить медленный шаг меньше чем за 15 минут.
Вам не нужны идеальные дашборды в первый день. Нужен достаточный сигнал, чтобы ответить:
Используйте их вместе — каждый отвечает на разный вопрос:
Во время инцидента: подтвердите воздействие метриками, найдите узкое место в трассах, объясните его логами.
Выберите небольшой набор соглашений и применяйте их везде:
По умолчанию используйте структурированные логи (часто JSON) с одинаковыми ключами везде.
Минимальные поля, которые окупают себя сразу:
Начните с четырех «золотых» сигналов по ключевой части системы:
Потом добавьте небольшой чеклист по компонентам:
Инструментируйте серверную сторону в первую очередь, чтобы каждый входящий запрос мог породить трассу.
Полезная трасса на день один содержит спаны, соответствующие частям, которые обычно тормозят:
Делайте спаны поисковыми: шаблон маршрута (например ), код статуса и понятное имя зависимости (payments, postgres, cache).
Простой и безопасный дефолт:
Начните с более высокого процента при низком трафике и снижайте по мере роста. Цель — сохранить полезность трасс без взрывного роста затрат.
Используйте повторяемый поток, который следует за доказательствами:
Запишите один отсутствующий сигнал, который ускорил бы диагностику, и добавьте его потом.
Эти ошибки отнимают время (и иногда деньги):
Держите все просто: стабильные ID, перцентили, понятные имена зависимостей и теги версии везде.
service_name, environment (например prod/staging) и versionrequest_id, сгенерированный на краю и передаваемый в вызовах и задачахroute, method, status_code и tenant_id (если multi-tenant)duration_ms)Цель — чтобы один фильтр работал по всем сервисам вместо того, чтобы каждый раз начинать заново.
timestamp, level, service_name, environment, versionrequest_id (и trace_id, если есть)route, method, status_code, duration_msuser_id или session_id (стабильный идентификатор, не email)Логируйте ошибки один раз с контекстом (тип/код ошибки + сообщение + имя зависимости). Избегайте повторов одного и того же стек-трейса при каждой попытке.
/orders/:id