23 сент. 2025 г.·8 мин
ZSTD vs Brotli vs GZIP: выбор сжатия для API
Сравнение ZSTD, Brotli и GZIP для API: скорость, степень сжатия, затраты CPU и практические настройки по умолчанию для JSON и бинарных полезных нагрузок в продакшене.
Сравнение ZSTD, Brotli и GZIP для API: скорость, степень сжатия, затраты CPU и практические настройки по умолчанию для JSON и бинарных полезных нагрузок в продакшене.
Сжатие ответов API означает, что сервер кодирует тело ответа (часто JSON) в более компактный поток байтов до отправки по сети. Клиент (браузер, мобильное приложение, SDK или другой сервис) затем распаковывает его. В HTTP это оговаривается через заголовки, такие как Accept-Encoding (что поддерживает клиент) и Content-Encoding (что выбрал сервер).
Сжатие в основном приносит три вещи:
Компромисс прост: сжатие экономит трафик, но стоит CPU (сжатие/распаковка) и иногда памяти (буферы). Насколько это оправдано — зависит от вашего бутылочного горлышка.
Сжатие особенно эффективно, когда ответы:
Если вы возвращаете большие списки JSON (каталоги, результаты поиска, аналитику), сжатие часто — один из самых простых выигрышей.
Сжатие обычно не оправдано CPU, когда ответы:
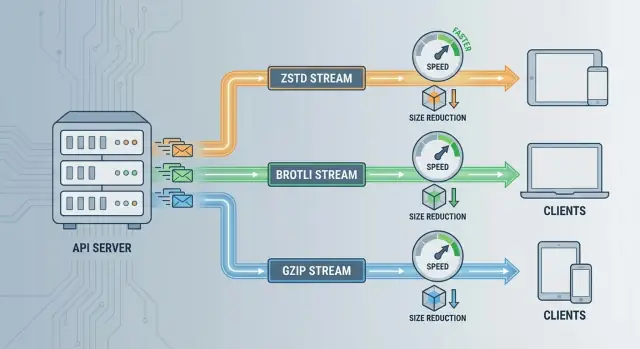
При выборе между ZSTD vs Brotli vs GZIP практическое решение обычно сводится к трём факторам:
Всё остальное в статье — про баланс этих трёх для ваших конкретных API и паттернов трафика.
Все три уменьшают размер полезной нагрузки, но оптимизируют разные параметры — скорость, степень сжатия и совместимость.
Скорость ZSTD: отлично подходит, когда API чувствительны к хвостовой задержке или сервера ограничены по CPU. Он может сжимать достаточно быстро, чтобы накладные расходы часто были несущественны по сравнению с сетевым временем — особенно для ответов среднего и большого размера.
Степень сжатия Brotli: выигрывает, когда приоритет — минимум байт (мобильные клиенты, дорогой egress, доставка через CDN) и ответы в основном текстовые. Меньшие полезные нагрузки могут оправдать более долгую компрессию.
Совместимость GZIP: подходит, когда нужна максимальная поддержка клиентов с минимальным риском переговоров (старые SDK, встраиваемые клиенты, устаревшие прокси). Это безопасная база, даже если она не лучшая по производительности.
«Уровни» сжатия — это пресеты, торгующие временем CPU за меньший выходной размер:
Распаковка обычно гораздо дешевле, чем сжатие для всех трёх форматов, но очень высокие уровни всё ещё могут увеличить нагрузку на клиент и батарею — важно для мобильных.
Сжатие часто рекламируют как «меньше байтов = быстрее API». Это верно в сетях с низкой пропускной способностью — но не автоматически. Если сжатие добавляет достаточно серверного CPU‑времени, вы можете получить более медленные ответы, несмотря на меньший объём в сети.
Полезно разделить затраты на две части:
Высокая степень сжатия может сократить время передачи, но если сжатие добавляет, скажем, 15–30 мс CPU на ответ, вы можете потерять больше времени, чем сэкономите — особенно на быстрых соединениях.
Под нагрузкой сжатие может ухудшать p95/p99 сильнее, чем p50. Когда CPU загружается, запросы встают в очередь. Очереди усиливают небольшие накладные расходы на запрос, превращая их в большие задержки — средняя задержка может выглядеть нормально, а вот самые медленные пользователи пострадают.
Не догадывайтесь. Запустите A/B‑тест или постепенный релиз и сравните:
Тестируйте с реалистичными паттернами трафика и полезными нагрузками. «Лучший» уровень сжатия — тот, который уменьшает суммарное время, а не только байты.
Сжатие не бесплатно — оно переносит работу из сети в CPU и память на обоих концах. В API это проявляется как большее время обработки запроса, больший объём памяти и иногда замедление на стороне клиента.
Большая часть CPU уходит на сжатие ответов. Сжатие ищет повторяющиеся паттерны, строит состояния/словаря и пишет закодированный выход.
Распаковка обычно дешевле, но всё ещё важна:
Если ваш API уже нагружен по CPU (дорогие запросы, сложная аутентификация, тяжёлые вычисления), включение высокого уровня сжатия может повысить хвостовые задержки даже при уменьшении полезной нагрузки.
Сжатие может увеличить использование памяти:
В контейнеризованных окружениях большие пики памяти приводят к OOM и снижению плотности инстансов.
Сжатие добавляет CPU‑циклы на ответ, уменьшая пропускную способность на инстанс. Это может ускорить масштабирование и повысить затраты. Распространённый паттерн: трафик в байтах падает, но расход CPU растёт — поэтому правильный выбор зависит от того, какой ресурс у вас в дефиците.
На мобильных или слабых устройствах распаковка конкурирует с рендерингом, выполнением JavaScript и зарядом батареи. Формат, который экономит несколько килобайт, но дольше распаковывается, может ощущаться медленнее, особенно когда важно «время до доступных данных».
Zstandard (ZSTD) — современный формат сжатия, спроектированный так, чтобы давать хорошую степень сжатия без замедления API. Для многих JSON‑heavy API он — крепкий «дефолт»: заметно меньшие ответы, чем GZIP, при сопоставимой или меньшей задержке, плюс очень быстрая распаковка на клиентах.
ZSTD ценен, когда важен end‑to‑end time, а не только минимальный объём. Он обычно сжимает быстро и распаковывает чрезвычайно быстро — полезно там, где каждая миллисекунда CPU конкурирует с обработкой запросов.
Он также хорошо показывает себя на широком диапазоне размеров полезной нагрузки: небольшие и средние JSON получают ощутимые выигрыши, а большие ответы — ещё больше выгоды.
Для большинства API начинайте с низких уровней (обычно 1–3). Они часто дают наилучшее соотношение латентность/размер.
Повышайте уровень только когда:
Прагматичный подход — низкий глобальный дефолт и выборочное повышение уровня для «больших» endpoint'ов.
ZSTD поддерживает стриминг, что уменьшает пик памяти и позволяет начинать отправку раньше для больших ответов.
Режим словаря может дать большой выигрыш для API, возвращающих много похожих объектов (повторяющиеся ключи, стабильные схемы). Это особенно эффективно, когда:
На стороне сервера поддержка простая во многих стеках, но совместимость клиентов может быть решающим фактором. Некоторые HTTP‑клиенты, прокси и шлюзы всё ещё не объявляют или не принимают Content-Encoding: zstd по умолчанию.
Если вы обслуживаете сторонних потребителей, держите fallback (обычно GZIP) и включайте ZSTD только когда Accept-Encoding явно его включает.
Brotli создан для максимальной экономии на текстовом контенте. Для JSON, HTML и других «словесных» payload'ов он часто обгоняет GZIP по степени сжатия — особенно на высоких уровнях.
Текстовые ответы — сильная сторона Brotli. Если ваш API отправляет большие JSON‑документы (каталоги, результаты поиска, конфигурационные блобы), Brotli может заметно сократить байты, что помогает в медленных сетях и снижает расходы на egress.
Brotli также выгоден, когда вы можете сжать один раз и отдавать множество раз ( кешируемые ответы, версионированные ресурсы). В таких случаях высокие уровни Brotli окупаются, поскольку стоимость CPU амортизируется.
Для динамических ответов (генерируемых на каждый запрос) лучшие соотношения Brotli часто требуют высоких уровней, которые могут быть ресурсоёмкими и добавлять задержку. Учитывая время сжатия, реальная выгода над ZSTD (или хорошо настроенным GZIP) может быть меньше, чем кажется на бумаге.
Он также менее полезен для payload'ов, которые плохо сжимаются (уже сжатые данные, многие бинарные форматы). В таких случаях вы просто тратите CPU.
Браузеры обычно хорошо поддерживают Brotli по HTTPS, поэтому он популярен для веб‑трафика. Для небраузерных API клиентов (мобильные SDK, IoT, старые HTTP‑стэки) поддержка может быть непостоянной — поэтому корректно оговаривайте через Accept-Encoding и держите fallback (обычно GZIP).
GZIP остаётся стандартным ответом для сжатия API, потому что это самый универсальный вариант. Практически каждый HTTP‑клиент, браузер, прокси и шлюз понимает Content-Encoding: gzip, и эта предсказуемость важна, когда вы не полностью контролируете промежуточные звенья.
Преимущество не в том, что GZIP «лучший», а в том, что он редко оказывается неправильным выбором. Многие команды имеют годы операций с ним, чувствительные дефолты в веб‑серверах и меньше сюрпризов с промежуточными устройствами, которые могут некорректно обращаться с новыми кодеками.
Для API‑полезных нагрузок (часто JSON) средние‑низкие уровни — золотая середина. Уровни 1–6 обычно дают большую часть уменьшения размера при разумном CPU‑потреблении.
Очень высокие уровни (8–9) могут выжать немного больше, но затраты CPU редко оправдывают это для динамичного трафика, где важна задержка.
На современном железе GZIP обычно медленнее, чем ZSTD при сопоставимом уровне сжатия, и часто не может дотянуться до лучших показателей Brotli на текстовых payload'ах. На практике это означает:
Если нужно поддержать старые клиенты, встраиваемые устройства, корпоративные прокси или легаси‑шлюзы, GZIP — самый безопасный выбор. Некоторые промежуточные устройства будут удалять неизвестные кодировки, ломать переговоры или не пропускать их — чего гораздо меньше с GZIP.
Если среда у вас смешанная, лучше начать с GZIP и добавить ZSTD/Brotli там, где вы контролируете полный путь.
Выигрыш от сжатия зависит не только от алгоритма, но и от типа данных. Некоторые payload'ы резко уменьшаются с ZSTD/Brotli/GZIP; другие едва меняются и просто сжигают CPU.
Текстовые ответы обычно очень хорошо сжимаются из‑за повторяющихся ключей, пробелов и предсказуемых паттернов.
Чем больше повторяемости и структуры — тем лучше степень сжатия.
Бинарные форматы вроде Protocol Buffers и MessagePack компактнее JSON, но не случайны. Они могут содержать повторяющиеся теги, похожие макеты записей и предсказуемые последовательности.
Это значит, что они часто всё ещё сжимаются, особенно для больших ответов или endpoint'ов со списками. Единственный надёжный ответ — тестировать с реальным трафиком: тот же endpoint, те же данные, сжатие вкл/выкл и сравнить и размер, и задержку.
Многие форматы уже используют внутреннее сжатие. Применение HTTP‑сжатия сверху даёт малую экономию и может увеличить время ответа.
Для них обычно отключают сжатие по типу контента.
Простой подход — сжимать только когда ответы превышают минимальный размер:
Content-Encoding.Это позволяет CPU работать там, где сжатие действительно снижает трафик и улучшает end‑to‑end производительность.
Сжатие работает плавно, когда клиент и сервер соглашаются на кодировку. Это делается через Accept-Encoding (от клиента) и Content-Encoding (от сервера).
Клиент объявляет, что он может декодировать:
GET /v1/orders HTTP/1.1
Host: api.example
Accept-Encoding: zstd, br, gzip
Сервер выбирает одну и указывает, что использовал:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Encoding: zstd
Если клиент отправил Accept-Encoding: gzip, а вы ответили Content-Encoding: br, этот клиент может не распарсить тело. Если клиент не отправляет Accept-Encoding, безопасный дефолт — не сжимать.
Практический порядок для API часто такой:
zstd сначалаbrgzipДругими словами: zstd > br > gzip.
Не делайте это догмой: если ваш трафик в основном — браузеры, br может иметь более высокий приоритет; если у вас старые мобильные клиенты, gzip может быть самым надёжным выбором.
Если ответ может быть отдан в нескольких кодировках, добавляйте:
Vary: Accept-Encoding
Без этого CDN или прокси может закешировать gzip‑версию и неправильно отдать её клиенту, который не просил (или не умеет) эту кодировку.
Некоторые клиенты заявляют поддержку, но имеют баги в декодерах. Чтобы быть устойчивым:
zstd, временно откатывайтесь на gzip.Переговоры — это скорее про отсутствие поломок клиентов, чем про экономию каждого байта.
Сжатие API не существует в вакууме. Ваш транспортный протокол, накладные расходы TLS и любые CDN/шлюзы между ними могут изменить реальный результат — или даже поломать поведение при неверной конфигурации.
В HTTP/2 несколько запросов разделяют одно TCP‑соединение. Это уменьшает накладные расходы на установку соединения, но потеря пакета может остановить все потоки из‑за TCP head‑of‑line blocking. Сжатие помогает, уменьшая объём ответов, снижая количество данных, «заблокированных» за событием потери пакета.
HTTP/3 работает поверх QUIC (UDP) и избегает TCP‑уровневого head‑of‑line между потоками. Размер полезной нагрузки всё ещё важен, но штраф за потерю пакета на поток обычно меньше. На практике сжатие остаётся полезным — ожидайте выгоды в виде экономии пропускной способности и более быстрой «time to last byte», чем драматических падений латентности.
TLS уже потребляет CPU (хендшейки, шифрование/дешифрование). Добавление сжатия (особенно на высоких уровнях) может вывести вас за пределы CPU при всплесках. Поэтому «быстрое сжатие с хорошим соотношением» часто превосходит «максимальную степень сжатия» в продакшне.
Некоторые CDN/шлюзы автоматически сжимают определённые MIME‑типы, другие пропускают то, что приходит от origin. Некоторые могут нормализовать или даже убрать Content-Encoding, если настроены неверно.
Проверьте поведение для каждого маршрута и убедитесь, что Vary: Accept-Encoding сохраняется, чтобы кэши не отдали сжатый вариант клиенту, который этого не просил.
Если вы кешируете на краю, рассмотрите хранение отдельных вариантов для каждой кодировки (gzip/br/zstd), вместо перекомпрессии при каждом хите. Если кеш на origin, вы всё равно можете захотеть, чтобы edge договаривался и кешировал несколько кодировок.
Ключ — согласованность: корректный Content-Encoding, правильный Vary и чёткое разграничение, где происходит сжатие.
Для API, ориентированных на браузеры, предпочитайте Brotli, если клиент объявляет его (Accept-Encoding: br). Браузеры эффективно декодируют Brotli, и он чаще даёт лучшую экономию на текстовых ответах.
Для внутренних сервисов (service‑to‑service) используйте ZSTD, когда обе стороны под вашим контролем. Он обычно быстрее при схожих или лучших соотношениях, чем GZIP, и переговоры просты.
Для публичных API, используемых разными SDK, держите GZIP как универсальный базовый вариант и опционно добавляйте ZSTD как опцию для клиентов, которые явно её поддерживают. Это избегает ломки старых HTTP‑стэков.
Начните с уровней, которые легко измерить и которые вряд ли удивят вас:
Если вам нужна сильнее степень сжатия, валидируйте на выборке продакшен‑payload'ов и отслеживайте p95/p99 перед повышением уровней.
Сжатие крошечных ответов может стоить больше CPU, чем экономит в сети. Практическая стартовая точка:
Настраивайте, сравнивая: (1) сохранённые байты, (2) добавленное серверное время, (3) изменение end‑to‑end latency.
Разворачивайте сжатие за feature flag, затем добавьте пер‑маршрутную конфигурацию (включать для /v1/search, отключать для уже маленьких endpoint'ов). Предоставьте опцию отключения на клиенте через Accept-Encoding: identity для отладки и слабых клиентов. Всегда включайте Vary: Accept-Encoding, чтобы кэши оставались корректными.
Если вы быстро генерируете API (например, фронтенды на React с бэкендом на Go + PostgreSQL), сжатие становится той самой «маленькой настройкой с большим эффектом». На Koder.ai команды часто доходят до этого раньше, потому что быстро прототипируют и деплоят полные приложения, затем точечно настраивают поведение в продакшене (включая сжатие ответов и заголовки кэша). Вывод: относитесь к сжатию как к фиче производительности, релизьте за флагом и меряйте p95/p99.
Изменения в сжатии легко выкатывать и удивительно легко ошибиться. Обращайтесь к этому как к продакшен‑фиче: запускайте поэтапно, измеряйте влияние и держите простой откат.
Начните с канарки: включите новый Content-Encoding (например, zstd) для небольшой части трафика или одного внутреннего клиента.
Затем плавно наращивайте (1% → 5% → 25% → 50% → 100%), останавливаясь при отрицательной динамике ключевых метрик.
Держите простой откат:
gzip)Отслеживайте сжатие как изменение производительности и надёжности:
Когда что‑то ломается, обычные причины:
Content-Encoding указан, но тело не сжато (или наоборот)Accept-Encoding, или возвращается кодировка, которую клиент не объявлялContent-Length или вмешательство прокси/CDNОпишите поддерживаемые кодировки в документации, с примерами:
Accept-Encoding: zstd, br, gzipContent-Encoding: zstd (или fallback)Если вы поставляете SDK, добавьте короткие примеры декодирования и укажите минимальные версии, которые поддерживают Brotli или Zstandard.
Используйте сжатие ответов, когда ответы богаты текстом (JSON/GraphQL/XML/HTML), средние или большие по размеру, и ваши пользователи находятся в медленных/дорогих сетях или вы платите значимые затраты на исходящий трафик. Пропускайте (или ставьте высокий порог) для крошечных ответов, уже сжатых медиа (JPEG/MP4/ZIP/PDF) и CPU‑ограниченных сервисов, где дополнительная работа на запрос ухудшит p95/p99.
Потому что это обменивает пропускную способность на CPU (и иногда память). Время на сжатие может отложить момент начала отправки байтов (TTFB), а под нагрузкой добавочная нагрузка CPU вызывает очереди—это часто ухудшает хвостовые задержки даже если средняя задержка уменьшается. Лучшие настройки — те, которые минимизируют конечное время запроса, а не только размер полезной нагрузки.
Практический приоритет для многих API:
zstd сначала (быстро, хорошее соотношение)br (часто наиболее компактно для текста, может требовать больше CPU)gzip (наибольшая совместимость)Всегда опирайтесь на то, что клиент объявляет в , и держите безопасный запасной вариант (обычно или ).
Начинайте с низких уровней и измеряйте.
Используйте порог минимального размера ответа, чтобы не тратить CPU на крошечные полезные нагрузки.
Тонкая настройка на уровне endpoint: сравнивайте сэкономленные байты против добавленного серверного времени и влияния на p50/p95/p99.
Сосредоточьтесь на типах контента, которые структурированы и повторяются:
Сжатие должно следовать HTTP‑переговору:
Accept-Encoding (например, zstd, br, gzip)Content-EncodingЕсли клиент не отправляет , самым безопасным ответом обычно является . Никогда не возвращайте , которого клиент не объявлял, иначе клиент может не распарсить тело.
Добавьте заголовок:
Vary: Accept-EncodingЭто предотвращает ситуацию, когда CDN/прокси кэширует, например, gzip‑версию и ошибочно отдает её клиенту, который не запросил или не умеет декодировать gzip (или zstd/br). Если вы поддерживаете несколько кодировок, этот заголовок обязателен для корректного кэширования.
Частые ошибки:
Разворачивайте как фичу производительности:
Content-Encoding (например, zstd) для небольшой доли трафикаДержите быстрый откат (фича‑флаг или конфиг gateway), и мониторьте:
Accept-EncodinggzipidentityБолее высокие уровни обычно дают убывающую отдачу по размеру, но могут резко повысить CPU и ухудшить p95/p99.
Обычный подход — включать сжатие только для текстоподобных Content-Type и отключать для известных уже сжатых форматов.
Accept-EncodingContent-EncodingContent-Encoding говорит gzip, а тело не gzip)Accept-Encoding)Content-Length при стриминге/сжатииПри отладке захватывайте необработанные заголовки ответа и проверяйте декомпрессию известным рабочим клиентом/инструментом.
Если хвостовые задержки растут под нагрузкой — понижайте уровень, повышайте порог или переключайтесь на более быстрый кодек (часто ZSTD).