16 авг. 2025 г.·8 мин
Создание веб‑приложения для управления API‑ключами, квотами и аналитикой использования
Научитесь проектировать и строить веб‑приложение, которое выдаёт API‑ключи, контролирует квоты, отслеживает использование и показывает понятные аналитические панели с безопасными рабочими потоками.
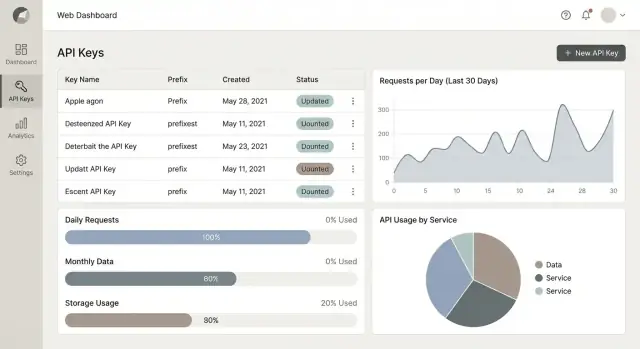
Что вы строите и для кого это нужно
Вы создаёте веб‑приложение, которое располагается между вашим API и теми, кто им пользуется. Его задача — выдавать API‑ключи, контролировать, как эти ключи используются, и объяснять, что произошло — так, чтобы это было понятно как разработчикам, так и не‑технарям.
Минимально оно отвечает на три практических вопроса:
- Кто вызывает API? (какой клиент, какое приложение, какой ключ)
- Сколько им разрешено использовать? (квоты, rate‑limits, правила плана)
- Сколько они реально использовали? (метрики и аналитика, которым можно доверять)
Если вы хотите быстро продвинуться с порталом и админ‑интерфейсом, инструменты вроде Koder.ai помогут прототипировать и быстро выпустить продакшн‑базу (React‑фронтенд + Go‑бэкенд + PostgreSQL), при этом сохраняя полный контроль через экспорт исходников, snapshot/rollback и деплой/хостинг.
Кто пользуется порталом
Приложение управления ключами нужно не только инженерам. Разные роли приходят с разными целями:
- Админы / владельцы платформы хотят создавать политики (лимиты, уровни доступа), быстро решать инциденты и сохранять контроль над множеством клиентов.
- Разработчики (ваши клиенты или внутренние команды) хотят self‑serve создание ключей, простую документацию и быстрые ответы при сбоях («Почему я получаю 429?»).
- Финансы и поддержка хотят историю использования, сводки по клиентам и данные, которые можно подкрепить счётами или кредитами — без чтения сырых логов.
Основные модули, которые вам, вероятно, понадобятся
Большинство удачных реализаций сходятся на нескольких модулях:
- Keys: создание ключей, именование/теги, области доступа, ротация, отзыв и просмотр последнего использования.
- Quotas & rate limiting: определение лимитов по ключу, по клиенту, по endpoint и их последовательное применение.
- Usage metering: сбор событий запросов (или их суммарных записей), агрегирование в суточные/месячные значения.
- Analytics: дашборды, объясняющие тренды использования, топ‑эндпоинты, ошибки и троттлинг.
- Alerts: уведомления при всплесках, близких к лимиту квот, при злоупотреблении ключами или росте ошибок.
Объём: начните просто, потом расширяйте
Сильный MVP фокусируется на выдаче ключей + базовых лимитах + понятной отчётности по использованию. Продвинутые функции — автоматические апгрейды планов, биллинговые рабочие процессы, праторация и сложные договорные условия — могут появиться позже, когда вы будете доверять своей метрологии и механизму принудительного соблюдения.
Практическая «north star» цель для первого релиза: сделать так, чтобы человек мог создать ключ, понять свои лимиты и увидеть использование без обращения в поддержку.
Чеклист требований (MVP vs позже)
Прежде чем писать код, решите, что значит «готово» для первого релиза. Такие системы быстро разрастаются: биллинг, аудиты и корпоративная безопасность появятся раньше, чем вы ожидаете. Чёткий MVP помогает регулярно выпускать релизы.
MVP: минимум, дающий ценность
Как минимум пользователи должны уметь:
- Создавать и отзывать API‑ключи (с именем/меткой и опциональным сроком действия)
- Задавать квоты (например, запросы/день или запросы/месяц) на ключ или проект
- Применять rate limiting (например, запросы/минута) для защиты API
- Видеть графики использования (простые суточные суммы, топ‑ключи и уровень ошибок)
- Отслеживать базовые события аудита (создание/отзыв ключа, изменение квоты) для поддержки и подотчётности
Если вы не можете безопасно выдать ключ, ограничить его и доказать, что он сделал — система не готова.
Нефункциональные требования, которые стоит решить заранее
- Производительность: какое пиковое количество запросов/сек вам нужно мерить без потерь событий?
- Надёжность: нужен ли вам «никогда не терять события», или достаточно «в итоге корректно»?
- Хранение данных: как долго хранить сырые события vs агрегаты (например, 7 дней сырых, 13 месяцев агрегированных)?
Модель арендатора: одна организация или мульти‑тенант
Выберите это рано:
- Одна организация: быстрее строить, меньше краёв ролей/разрешений.
- Мульти‑тенантный SaaS: требует изоляции арендаторов, индивидуальных квот и админ‑ролей с первого дня.
«Позже» — функции, которые стоит спланировать
Ротация, вебхуки, выгрузки для биллинга, SSO/SAML, квоты по эндпоинту, детекция аномалий и более полные журналы аудита.
Метрики успеха (сделайте их измеримыми)
- Время на выдачу ключа: например, менее 2 минут от регистрации до первого ключа
- Точность метрирования: например, <0.5% расхождения между подсчётами шлюза и агрегатами
- Нагрузка на поддержку: меньше тикетов «почему меня заблокировали?», понятные объяснения по квотам/rate limits
Высокоуровневые архитектурные варианты
Выбор архитектуры начинается с одного вопроса: где вы будете применять доступ и лимиты? Это влияет на задержки, надёжность и скорость выхода на прод.
Вариант 1: применять на API‑шлюзе
API‑шлюз (managed или self‑hosted) может валидировать ключи, применять rate limits и эмитировать события использования до того, как запрос достигнет сервисов.
Это хорошее решение при множестве бэкенд‑сервисов, при необходимости единых политик или желании держать enforcement вне кода приложений. Минус: конфигурация шлюза может превратиться в отдельный «продукт», и отладка часто требует хорошего трассирования.
Вариант 2: применять на reverse proxy
Reverse proxy (например, NGINX/Envoy) может обрабатывать проверки ключей и rate limiting через плагины или внешние auth‑хуки.
Подходит для лёгкого edge‑слоя, но моделирование бизнес‑правил (планы, квоты по арендаторам, исключения) может потребовать дополнительных сервисов.
Вариант 3: применять в middleware приложения
Размещение проверок в приложении (middleware) обычно быстрее для MVP: одна кодовая база, один деплой, проще локальное тестирование.
При росте это может усложнить ситуацию: регулярно появляются дублированные правила, поэтому планируйте вынос в общий компонент или edge‑слой.
Разделяйте ответственности с самого начала
Даже если вы начинаете просто, держите границы:
- Auth (валиден ли ключ?), quota/rate limit (разрешён ли запрос сейчас?), metering (записать, что произошло), UI аналитики (показать это).
Синхронный vs асинхронный трекинг
Для метрирования решите, что должно происходить в пределах запроса:
- Синхронно: инкрементировать счётчики перед ответом (точная блокировка, большая задержка).
- Асинхронно: эмитировать событие в очередь/лог для агрегации (быстрее, отчётность «в итоге»).
Планируйте масштаб: hot vs cold пути
Проверки rate limit — это hot path (оптимизируйте для низкой задержки, in‑memory/Redis). Отчёты и дашборды — cold path (оптимизируйте под гибкие запросы и пакетную агрегацию).
Модель данных для ключей, квот и использования
Хорошая модель разделяет три ответственности: кто владеет доступом, какие лимиты применяются и что реально произошло. Если это сделать правильно, остальное — ротация, дашборды, биллинг — упрощается.
Основные сущности (на первый день)
Минимально нужны таблицы/коллекции:
- Organization: граница арендатора (владелец биллинга, участники).
- Project/App: контейнер для ключей и настроек (часто соответствует одному клиентскому приложению).
- API Key: метаданные про учётные данные (имя, статус, created_at, last_used_at).
- Plan: набор лимитов и возможностей (например Free, Pro).
- Quota: конкретные правила лимитов (например, 10k requests/day, 60 req/min).
- Usage Event: сырая запись использования (timestamp, project_id, endpoint, status code, units).
Храните метаданные отдельно от секретов
Никогда не храните raw‑токены. Храните только:
- префикс ключа (первые 6–8 символов) для отображения/поиска
- verifier для токена (обычно SHA‑256 или HMAC‑SHA‑256 с server‑side pepper поверх случайного 32–64 байтного секрета)
- Опционально: scopes, environment (prod/sandbox) и expires_at.
Это позволяет показывать «Key: ab12cd…», при этом секрет необратимо защищён.
Аудитируемость — обязательна
Заводите таблицы аудита с самого начала: KeyAudit и AdminAudit (или общая AuditLog) с полями:
- actor_id (пользователь/сервис), действие, target_type/id
- before/after (для правок квот)
- ip/user_agent, timestamp
Когда клиент спросит «кто отозвал мой ключ?», вы должны дать ответ.
Временные окна и счётчики
Модельте квоты с явными окнами: per_minute, per_hour, per_day, per_month.
Храните счётчики в отдельной таблице, например UsageCounter, с ключами (project_id, window_start, window_type, metric). Это делает сбросы предсказуемыми и ускоряет аналитические запросы.
Для порталов отображения вы можете агрегировать Usage Events в дневные роллапы и ссылаться на /blog/usage-metering для деталей.
Аутентификация, авторизация и роли
Если ваш продукт управляет API‑ключами и использованием, доступ к самому приложению должен быть строже обычной CRUD‑панели. Ясная модель ролей облегчает работу командам и предотвращает «все админы».
Проектирование ролей, соответствующих реальным командам
Начните с небольшого набора ролей на организацию (арендатора):
- Owner: полный контроль, владелец биллинга, может управлять настройками и удалять организацию.
- Admin: управляет пользователями, проектами, ключами, квотами и настройками безопасности.
- Developer: может создавать/ротацировать ключи для назначенных проектов, смотреть использование, но не менять биллинг или глобальные настройки безопасности.
- Read‑only: может просматривать ключи (замаскированные), квоты и аналитику.
- Finance: может смотреть счета/отчёты по расходам, экспортировать данные, но не управлять ключами.
Держите разрешения явными (например, keys:rotate, quotas:update), чтобы добавлять функции без переопределения ролей.
Безопасный вход для людей
Используйте username/password только при необходимости; в остальных случаях поддерживайте OAuth/OIDC. SSO — опционально, но MFA обязателен для владельцев/админов и настоятельно рекомендуется для всех.
Добавьте защиту сессий: короткоживущие access‑tokens, ротация refresh‑token, управление устройствами/сессиями.
Аутентификация для защищаемых API
Предлагайте стандартный API‑ключ в заголовке (например, Authorization: Bearer <key> или X-API-Key). Для продвинутых клиентов добавьте опциональную HMAC‑подпись (предотвращает replay/tampering) или JWT (удобен для короткоживущего, ограниченного доступа). Документируйте это в портале разработчика.
Изоляция арендаторов — безоговорочно
Применяйте org_id везде: в БД‑ограничениях, row‑level политике (если есть) и в проверках на уровне сервисов. Не полагайтесь только на фильтрацию UI — пишите тесты, пытающиеся получить доступ между арендаторами.
Жизненный цикл API‑ключа: создание, ротация, отзыв
Возьмите реализацию под контроль
Сохраняйте полный контроль, экспортируя исходный код в любой момент.
Хороший жизненный цикл делает ротацию рутиной, а не инцидентом. Проектируйте UI и API так, чтобы «happy path» был очевиден, а безопасные варианты (ротация, срок жизни) — предпочтительными.
Создание: фиксируйте намерение, а не только строку
В потоке создания ключа просите имя (например, «Prod server», «Local dev») и scopes/permissions, чтобы ключ с первого дня был с минимально необходимыми правами.
Пригодны опции вроде allowed origins (для браузерного использования) или allowed IPs/CIDRs (для server‑to‑server). Делайте их опциональными и предупреждайте о возможных блокировках.
После создания показывайте raw‑ключ только один раз. Давайте большую кнопку «Копировать» и короткое руководство: «Храните в менеджере секретов. Мы не сможем показать его снова.» Ссылайтесь напрямую на инструкцию по настройке, например /docs/auth.
Ротация: сделайте её рутиной
Ротация должна следовать предсказуемому сценарию:
- Создать новый ключ с теми же scopes/ограничениями.
- Обновить интеграцию на новый ключ.
- Проверить, что трафик идёт.
- Откатить старый ключ.
В UI дайте действие «Rotate», которое создаёт замену и помечает предыдущий ключ как «Pending revoke» для чистки.
Отзыв и истечение: немедленное и запланированное
Отзыв должен отключать ключ немедленно и логировать кто и зачем это сделал.
Поддерживайте планируемое истечение (например, 30/60/90 дней) и вручную задаваемые «expires on» даты для подрядчиков/трид‑партов. Просроченные ключи должны падать с предсказуемой ошибкой аутентификации, чтобы разработчики знали, что исправлять.
Квоты и rate limiting: как применять ограничения
Rate limits и квоты решают разные проблемы; их смешение — частая причина путаницы в тикетах «почему меня заблокировали?».
Rate limits vs квоты
Rate limits контролируют всплески (например, «не более 50 запросов в секунду»). Они защищают инфраструктуру и предотвращают деградацию для других клиентов.
Квоты ограничивают суммарное потребление за период (например, «100000 запросов в месяц»). Они нужны для контроля планов и биллинга.
Многие продукты используют оба: месячная квота для справедливости и per‑second/per‑minute rate limit для стабильности.
Выберите алгоритм принудительного ограничения
Для real‑time rate limiting выберите алгоритм, который можно объяснить и реализовать надёжно:
- Token bucket: токены пополняются со временем; каждый запрос тратит токен. Хорош для разрешения небольших всплесков при контроле среднего уровня.
- Leaky bucket: запросы «протекают» с постоянной скоростью. Гладит трафик, но воспринимается строже.
Token bucket — обычно лучший дефолт для API, ориентированных на разработчиков, т.к. предсказуем и более снисходителен.
Выберите, где хранятся счётчики
Обычно нужны два хранилища:
- Redis (или аналог) для быстрых атомарных проверок на шлюзе/edge.
- БД для надёжной отчётности и истории биллинга.
Redis отвечает на вопрос «можно ли выполнить этот запрос прямо сейчас?», БД отвечает «сколько они использовали в этом месяце?».
Что считать использованием
Будьте явными по продукту и эндпоинтам. Частые метрики: запросы, токены, переданные байты, вес эндпоинта или время выполнения/compute.
Если используете веса эндпоинтов — публикуйте их в документации и портале.
Сделайте ответы об ошибках полезными
При блокировке возвращайте понятные ошибки:
- 429 Too Many Requests для rate limiting. Включайте
Retry-Afterи, опционально,X-RateLimit-Limit,X-RateLimit-Remaining,X-RateLimit-Reset. - 402 Payment Required (или 403) при превышении квоты у платных планов. Указывайте текущее использование периода, лимит и ссылку на /billing или /pricing.
Хорошие сообщения уменьшают churn: разработчики могут отступить, добавить retry‑логику или повысить план без догадок.
Учёт использования: сбор и агрегация событий
Метрирование — «источник истины» для квот, счетов и доверия клиента. Цель проста: считать, что произошло, согласованно, не замедляя API.
Что логировать для каждого запроса (и чего не логировать)
Для каждого запроса фиксируйте небольшой предсказуемый набор полей:
- timestamp (серверное время)
- key_id (или идентификатор токена)
- endpoint (имя маршрута, не полный URL)
- status (например, 200, 401, 429)
- units (что считать: 1 запрос, токены, байты и т.д.)
Не логируйте тела запросов/ответов. По умолчанию редактируйте чувствительные заголовки (Authorization, cookies) и рассматривайте PII как «opt‑in при сильной надобности». Если нужно логировать для дебага, храните отдельно с коротким сроком хранения и строгим доступом.
Держите API быстрым с помощью event pipeline
Не агрегируйте метрики синхронно в запросе. Вместо этого:
- API записывает событие в очередь/стрим (или лёгкую append‑only таблицу).
- Воркеры потребляют события и обновляют дневные/часовые агрегаты.
Это сохраняет стабильность задержек при всплесках трафика.
Идемпотентность, ретраи и двойной подсчёт
Очереди могут доставлять сообщения более одного раза. Добавьте уникный event_id и обеспечьте дедупликацию (уникальный индекс или cache «seen» с TTL). Воркеры должны быть безопасны для повторного выполнения, чтобы сбой не испортил итоги.
Хранение: сырые данные кратко, агрегаты долго
Храните сырые события кратко (дни/недели) для аудитов и расследований. Храните агрегированные метрики намного дольше (месяцы/годы) для трендов, enforcement‑а квот и готовности к биллингу.
Дашборды аналитики, которые действительно используют
Реализуйте интерфейс жизненного цикла ключа
Создайте экраны для создания, ротации и отзыва ключей, не начиная с нуля.
Дашборд использования не должен быть «красивой картинкой». Он должен быстро отвечать на два вопроса: что изменилось? и что делать дальше? Проектируйте под принятие решений — отладка всплесков, предотвращение перерасходов и доказательство ценности клиенту.
Основные представления для релиза
Начните с четырёх панелей, которые соответствуют повседневным задачам:
- Использование во времени (запросы/день или запросы/мин) с явным сравнением с предыдущим периодом.
- Топ эндпоинтов (по объёму и по стоимости/весу, если есть взвешивание).
- Уровень ошибок (4xx vs 5xx) чтобы отделять клиентские ошибки от проблем сервиса.
- Латентность (опционально) p50/p95; включайте только если измерение надёжно.
Сделайте их действенными, а не декоративными
Каждый график должен вести к следующему шагу. Показывайте:
- Остаток квоты для текущего цикла (например, 18 200 из 50 000 осталось)
- Прогноз при текущем темпе с простым признаком «перевысит / останется в пределах»
Когда прогноз показывает возможный перерасход, давайте прямую ссылку на апгрейд: /plans (или /pricing).
Фильтрация по рабочим сценариям
Добавьте фильтры, которые упрощают расследования без сложных конструкторов запросов:
- Диапазон времени (последние 24ч, 7д, 30д, произвольно)
- API‑ключ, проект, окружение (prod/staging)
- Эндпоинт и группа статус‑кодов
Экспорт и доступ через API
Добавьте скачивание CSV для финансов и поддержки и предоставьте лёгкое metrics API, например GET /api/metrics/usage?from=...&to=...&key_id=..., чтобы клиенты могли подтянуть данные в свои BI‑инструменты.
Оповещения, уведомления и готовность к биллингу
Оповещения — это разница между «мы заметили проблему» и «клиенты заметили первыми». Делайте их вокруг вопросов, которые пользователи задают под давлением: Что произошло? Кто пострадал? Что дальше делать?
Что и когда тревожить
Начните с порогов, связанных с квотами. Простая схема, которая хорошо работает: 50% / 80% / 100% использования квоты в пределах биллингового периода.
Добавьте несколько высокосигнальных поведенческих тревог:
- Необычные всплески: использование, отклоняющееся от недавней базы арендатора (например, 3× часовой средний)
- Ошибки аутентификации: резкий рост попыток с недействительными ключами или ошибками подписи
- Нагрузка rate limiting: продолжительный троттлинг, указывающий на неправильно настроенный клиент
Делайте оповещения действенными: включайте арендатора, API‑ключ/приложение, группу эндпоинтов (если есть), интервал и ссылку на релевантный вид в портале (например, /dashboard/usage).
Каналы уведомлений
Email — базис, потому что у всех он есть. Добавьте webhooks для интеграции в системы клиентов. Slack — опционально, делайте настройку лёгкой.
Практическое правило: предоставляйте политику уведомлений на уровне арендатора — кто получает какие оповещения и при какой серьёзности.
Простые отчёты об использовании, которые читают
Предлагайте ежедневные/еженедельные сводки с общими запросами, топ‑эндпоинтами, ошибками, троттлингом и «изменение vs предыдущий период». Руководители хотят трендов, а не сырых логов.
Подготовленность к биллингу без прямой реализации биллинга
Даже если биллинг — «потом», храните:
- Историю планов (каким планом пользовался арендатор и когда)
- Даты вступления в силу цен (чтобы пересчёты были консистентны)
Это позволит откатно выставлять счета или пред‑просмотры без переписывания модели данных.
Шаблон понятного сообщения
Каждое сообщение должно отвечать: что произошло, какой эффект, следующий шаг (ротация ключа, апгрейд плана, расследование клиента или обращение в поддержку через /support).
Безопасность и соответствие требованиям
Обеспечьте аудитируемость
Настройте журналы аудита для действий с ключами и изменений квот на раннем этапе, чтобы служба поддержки имела ответы.
Безопасность для приложения управления API‑ключами — это не про сложные фичи, а про осторожные настройки по‑умолчанию. Рассматривайте каждый ключ как учётные данные и предполагайте, что со временем он попадёт не туда.
Защита API‑ключей
Никогда не храните ключи в открытом виде. Храните верификатор производного от секрета (обычно SHA‑256 или HMAC‑SHA‑256 с server‑side pepper) и показывайте пользователю полный секрет только при создании.
В UI и логах отображайте ненебезопасный префикс (например, ak_live_9F3K…), чтобы люди могли идентифицировать ключ без раскрытия секрета.
Давайте практические советы по сканированию секретов: напомните не коммитить ключи в Git и дайте ссылку на инструменты (например, GitHub secret scanning) в портале /docs.
Защиты для административных функций
Атакующие любят админ‑эндпоинты, потому что там можно генерировать ключи, повышать квоты или отключать лимиты. Применяйте rate limiting к админ‑API, и подумайте об опции IP allowlist для админского доступа (полезно внутри команды).
Используйте принцип наименьших привилегий: разделяйте роли (viewer vs admin) и ограничивайте, кто может менять квоты или ротацировать ключи.
Журналы аудита и хранение
Фиксируйте события аудита для создания/ротации/отзыва ключей, попыток входа и изменений квот. Держите логи tamper‑resistant (append‑only, ограниченный доступ на запись и регулярные бэкапы).
Примите базовые требования соответствия: минимизация данных (храните только необходимое), четкие правила ретенции (авто‑удаление старых логов) и документированные правила доступа.
Сценарии угроз, которые стоит продумать
Утечка ключей, replay‑атаки, скрейпинг портала и «шумные» арендаторы, потребляющие общие ресурсы. Проектируйте смягчающие меры (хеши/верификаторы, короткоживущие токены, rate limits и квоты по арендаторам) вокруг этих реалий.
UX для админов и разработчиков
Отличный портал делает «безопасный путь» самым простым: админы быстро уменьшают риски, разработчики получают рабочий ключ и успешный тест‑запрос без писем в поддержку.
UX для админов: скорость, контроль и уверенность
Админы приходят с срочными задачами («отозвать этот ключ сейчас», «кто создал?» , «почему usage взлетел?»). Проектируйте для быстрого сканирования и решительных действий.
Используйте быстрый поиск, который работает по префиксам ID ключа, именам приложений, пользователям и воркспейсам. Сопровождайте его понятными статусами (Active, Expired, Revoked, Compromised, Rotating) и метками времени «last used», «created by». Эти поля сокращают случайные отозвы.
Для массовых операций добавьте bulk actions с safety‑механизмами: массовый отзыв, массовая ротация, массовая смена уровня квоты. Всегда показывайте подтверждение с количеством и сводкой влияния («38 ключей будут отозваны; 12 использовались в последние 24ч»).
Давайте панель деталей для каждого ключа: scopes, связанное приложение, allowed IPs (если есть), tier квоты и недавние ошибки.
UX для разработчиков: успешный старт тут и сейчас
Разработчики хотят copy→paste→go. Размещайте чёткую документацию рядом с потоком создания ключа, а не где‑то в глубине. Предлагайте копируемые curl‑примеры и переключатель языков (curl, JS, Python), если возможно.
Показывайте ключ один раз с кнопкой «Копировать» и кратким напоминанием о хранении. Затем направляйте на шаг «Тестовый вызов», который выполняет реальный запрос к sandbox или безопасному endpoint. Если тест падает, давайте пояснения ошибок простым языком и распространённые исправления:
- “Invalid key” → проверьте имя заголовка и пробелы
- “Forbidden” → отсутствует scope/право
- “Rate limited” → как посмотреть квоты и Retry‑After
Self‑serve onboarding за минуты
Простой путь работает лучше: Создать ключ → выполнить тестовый вызов → увидеть использование. Даже крошечный график использования («последние 15 минут») укрепляет доверие к метрированию.
Ссылайтесь напрямую на релевантные страницы с относительными маршрутами: /docs, /keys, /usage.
Доступность и понятность
Используйте простые метки («Запросов в минуту», «Месячные запросы») и держите единицы постоянными по всем страницам. Добавьте тултипы для терминов вроде «scope» и «burst». Обеспечьте навигацию с клавиатуры, видимые состояния фокуса и достаточный контраст — особенно для бейджей статуса и баннеров ошибок.
Деплой, мониторинг и тестирование
Запуск такой системы в прод — это дисциплина: предсказуемые деплои, видимость при проблемах и тесты, сосредоточенные на «hot paths» (аутентификация, проверки лимитов, метрирование).
Настройка деплоя (секреты, env vars, миграции)
Держите конфигурацию явной. Храните не‑секретные настройки в переменных окружения (например, дефолтные лимиты, имена очередей, окна ретенции) и секреты в управляемом хранилище (AWS Secrets Manager, GCP Secret Manager, Vault). Избегайте встраивания секретов в образы.
Выполняйте миграции как первый шаг в пайплайне. Предпочитайте стратегию «migrate then deploy» для обратносуместимых изменений и планируйте безопасные откаты (feature flags помогают). В мульти‑тенантной среде добавляйте проверки, чтобы миграции случайно не просканировали таблицы всех арендаторов.
Если вы строите систему на Koder.ai, snapshot/rollback может быть практичным страховочным сетом на ранних итерациях.
Observability, отвечающая на реальные вопросы
Нужны три сигнала: логи, метрики и трассы. Инструментируйте rate limiting и enforcement квот метриками типа:
- Разрешённые vs отклонённые запросы (по API‑ключу, эндпоинту и арендатору)
- «Коды причины» отклонений (rate limit, quota exceeded, invalid key)
- Задержка пайплайна метрирования (ingest события → агрегация)
Соберите дашборд специально по отказам из‑за rate limit, чтобы поддержка могла отвечать «почему мой трафик падает?» без догадок. Трейсинг помогает найти медленные зависимости на критическом пути (поиски статуса ключа в БД, промахи кэша и т.п.).
Бэкапы и приоритеты восстановления
Приоритизируйте конфигурационные данные (ключи, квоты, роли) как критичные и события использования как высокообъёмные. Бэкапьте конфигурацию часто с возможностью восстановления по точке во времени.
Для usage‑данных ориентируйтесь на надёжность и возможность переиграть: write‑ahead лог/очередь + повторная агрегация часто практичнее частых полных бэкапов.
Тестирование и план выпуска
Юнит‑тестируйте логику лимитов (граничные случаи: границы окна, конкурентные запросы, ротация ключей). Нагрузочно тестируйте горячие пути: валидация ключа + обновление счётчика.
Делайте поэтапный релиз: внутренние пользователи → ограниченная бета (избранные арендаторы) → GA, с «kill switch» для отключения enforcement при необходимости.
FAQ
Какой минимальный набор функций нужен для портала управления API-ключами?
Сфокусируйтесь на трёх результатах:
- Выпуск и отзыв ключей безопасно (показывать секрет один раз, поддерживать срок действия).
- Применять базовые ограничения (rate limits + простая дневная/месячная квота).
- Объяснять использование и блокировки (небольшая панель и понятные сообщения при 429/перерасходе квоты).
Если пользователи могут создать ключ, понять свои лимиты и проверить использование без обращения в поддержку — ваш MVP выполняет свою задачу.
Где лучше контролировать API-ключи и лимиты — в шлюзе, reverse proxy или в middleware приложения?
- API‑шлюз: оптимален для множества сервисов и централизованных политик; сложнее отлаживать без хорошего трассирования.
- Обратный прокси: лёгкий слой на краю, но сложные бизнес‑правила потребуют дополнительных сервисов.
- Middleware в приложении: самый быстрый путь для MVP (одна база кода), но следите за дублированием логики при росте.
Частая стратегия: начать с middleware, затем вынести в общий edge-слой по мере роста системы.
Как безопасно хранить API-ключи в базе данных?
Храните метаданные отдельно от секрета:
- Сохраняйте префикс (первые 6–8 символов) для отображения/поиска.
- Сохраняйте хеш для проверки (никогда — сам токен).
- Отслеживайте поля жизненного цикла:
created_at, , , .
В чём разница между rate limits и квотами, и нужны ли оба?
Они решают разные задачи:
- Rate limits ограничивают всплески (например, 60 req/min) для защиты надёжности.
- Quotas ограничивают общее потребление за период (например, 100k/месяц) для планов и биллинга.
Часто используют оба: месячная квота для планов и per-second/per-minute rate limit для стабильности.
Как учитывать использование API, не замедляя обработку запросов?
Используйте конвейер, который не замедляет обработку запроса:
- Для каждого запроса сохраняйте лёгкое событие использования (timestamp, id ключа, endpoint, статус, единицы).
- Записывайте его в очередь/стрим (или append-only лог).
- Рабочие потребляют события и агрегируют в часовые/суточные/месячные итоги.
Это избегает медленных подсчётов в обработчике запроса и даёт готовые роллапы для биллинга.
Как предотвратить двойной подсчёт в пайплайне событий использования?
Предположите возможность повторной доставки сообщений и проектируйте под повторные попытки:
- Добавьте уникальный
event_idдля каждого запроса. - Дедуплицируйте на стороне потребителя (уникальное ограничение в БД или cache «seen IDs» с TTL).
- Сделайте агрегирующие обновления идемпотентными, чтобы авария воркера не испортила итоги.
Это критично, если вы собираетесь использовать данные для квот, выставления счетов или кредитов.
Что включать в аудиторские логи для системы управления ключами и квотами?
Фиксируйте кто, что и когда сделал:
- Жизненный цикл ключа: создание, ротация, отзыв, истечение.
- Изменения политик: правки квот/лимитов (храните до/после).
- Действия по аутентификации/админские: логины, смена ролей, подозрительные всплески.
Всегда включайте актёра, цель, метку времени и IP/user-agent — тогда на вопрос «кто отозвал ключ?» у вас будет однозначный ответ.
Как проектировать роли и права для мульти‑тенантного портала API?
Используйте небольшую и явную модель ролей и детализированные разрешения:
- Роли: Owner, Admin, Developer, Read-only, Finance.
- Разрешения: например , — чтобы добавлять функции без перекроения ролей.
Как долго хранить сырые события использования и агрегированные метрики?
Практический подход — сырые события коротко, агрегаты долго:
- Храните сырые события несколько дней/недель для расследований.
- Храните агрегаты (суммы по дням/месяцам) месяцами/годами для трендов и подготовки биллинга.
Решите это заранее, чтобы расходы на хранение, политика приватности и ожидания отчётности были предсказуемы.
Что должен возвращать API, когда запрос блокируется, чтобы это было полезно для отладки?
Делайте блокировки простыми для отладки:
- При rate limiting возвращайте 429 с
Retry-Afterи (опционально) заголовками .