14 июл. 2025 г.·8 мин
Стратегии управления памятью: производительность против безопасности
Узнайте, как сборка мусора, владение и подсчёт ссылок влияют на скорость, задержки и безопасность — и как выбрать язык, подходящий под ваши цели.
Узнайте, как сборка мусора, владение и подсчёт ссылок влияют на скорость, задержки и безопасность — и как выбрать язык, подходящий под ваши цели.
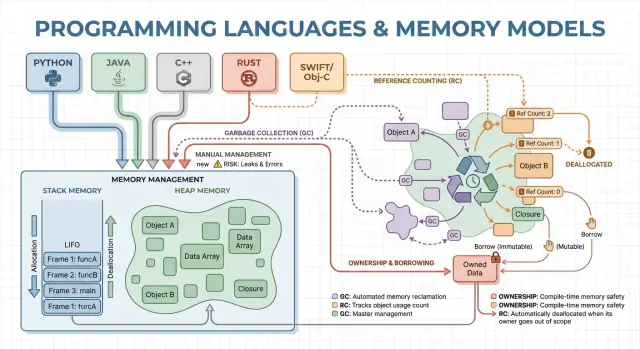
Управление памятью — это набор правил и механизмов, которые программа использует, чтобы запрашивать память, использовать её и возвращать обратно. Каждой запущенной программе нужна память для переменных, пользовательских данных, сетевых буферов, изображений и промежуточных результатов. Поскольку память ограничена и делится с ОС и другими приложениями, языки должны решить, кто отвечает за освобождение и когда это происходит.
Эти решения формируют два результата, которые волнуют большинство людей: насколько быстро ведёт себя программа и насколько надёжно она работает под нагрузкой.
Производительность — это не одно число. Управление памятью может влиять на:
Язык, который быстро выделяет объекты, но время от времени останавливается для очистки, может выглядеть хорошо в бенчмарках, но ощущаться «рваным» в интерактивных приложениях. Другая модель, избегающая пауз, может требовать более аккуратного проектирования, чтобы избежать утечек и ошибок времени жизни.
Безопасность связана с предотвращением ошибок, связанных с памятью, таких как:
Многие крупные уязвимости восходят к ошибкам управления памятью, таким как use-after-free или переполнение буфера.
Это руководство — нетехнический обзор основных моделей управления памятью в популярных языках, того, что они оптимизируют, и компромиссов, которые вы принимаете, выбирая одну из них.
Память — это место, где программа хранит данные во время выполнения. Большинство языков организуют это вокруг двух зон: стек и куча.
Представьте стек как аккуратную стопку стикеров для текущей задачи. Когда функция запускается, ей выделяется небольшой «фрейм» в стеке для локальных переменных. Когда функция заканчивает работу, весь фрейм удаляется разом.
Это быстро и предсказуемо — но работает только для значений известного размера и тех, чья жизнь заканчивается вместе с вызовом функции.
Куча похожа на склад, где можно хранить объекты сколько нужно. Она удобна для динамически растущих списков, строк или объектов, разделяемых между разными частями программы.
Поскольку объекты в куче могут переживать вызов функции, ключевой вопрос становится: кто отвечает за их освобождение и когда это происходит? Именно это и есть модель управления памятью языка.
Указатель или ссылка — способ косвенного доступа к объекту, как номер полки для коробки на складе. Если коробку выбросили, а у вас остался номер полки, вы можете прочитать мусор или упасть с исключением (классическая ошибка use-after-free).
Представьте цикл, который создаёт запись клиента, форматирует сообщение и отбрасывает его:
Некоторые языки скрывают эти детали (автоматическая очистка), другие открывают их (вы сами освобождаете память или обязаны следовать правилам владения). Остальная часть статьи исследует, как эти выборы влияют на скорость, паузы и безопасность.
Ручное управление означает, что программа (и разработчик) явно запрашивает память и позже освобождает её. На практике это выглядит как malloc/free в C или new/delete в C++. Оно всё ещё широко используется в системном программировании, где важен точный контроль, когда память выделяется и возвращается.
Обычно память выделяют, когда объект должен пережить текущий вызов функции, изменять размер (например, ресайзабельный буфер) или иметь специфическую компоновку для взаимодействия с железом, ОС или сетевыми протоколами.
Без сборщика, работающего в фоне, будет меньше неожиданных пауз. Выделение и освобождение можно сделать очень предсказуемым, особенно в сочетании с пользовательскими аллокаторами, пулами или буферами фиксированного размера.
Ручной контроль также уменьшает накладные расходы: нет трассировки, нет write barriers и часто меньше метаданных на объект. При аккуратном дизайне можно достигать жёстких целей по задержке и держать использование памяти в строгих рамках.
Компромисс в том, что программа может допустить ошибки, которые рантайм не предотвратит автоматически:
Эти баги вызывают сбои, порчу данных и уязвимости.
Команды снижают риск, ограничивая места, где разрешено сырьё-выделение, и опираясь на шаблоны вроде:
std::unique_ptr) для кодирования владенияРучное управление часто подходит для встроенного ПО, реального времени, компонентов ОС и производительных библиотек — там, где строгий контроль и предсказуемая задержка важнее удобства разработки.
Сборка мусора (GC) — это автоматическое очищение памяти: вместо того, чтобы вручную free-ить объекты, рантайм отслеживает их и возвращает те, до которых больше нельзя добраться. Это позволяет сосредоточиться на логике, пока система решает, когда и что освобождать.
Большинство сборщиков сначала определяют живые объекты, а потом освобождают остальные.
Трассирующий GC стартует от «корней» (переменные стека, глобальные ссылки, регистры), проходит по ссылкам, помечая всё достижимое, затем освобождает непомеченные объекты. Если к объекту нет ссылок, он становится кандидатом для сборки.
Генерационный GC основывается на наблюдении, что многие объекты «умирают молодыми». Куча делят на поколения; молодое поколение собирают чаще, что обычно дешевле и эффективнее.
Параллельный/конкуррентный GC выполняет часть работы по сборке одновременно с потоками приложения, чтобы уменьшить длительные паузы. Для этого требуется дополнительная синхронизация, чтобы поддержать согласованное представление памяти во время работы приложения.
GC обычно меняет ручной контроль на работу рантайма. Некоторые системы оптимизируют пропускную способность (много работы в секунду), но могут вводить стоп-ворлд паузы. Другие минимизируют паузы для приложений, чувствительных к задержкам, но добавляют накладные расходы в обычной работе.
GC устраняет целый класс ошибок времени жизни (особенно use-after-free), потому что объекты не освобождаются, пока до них есть ссылки. Он также снижает утечки, вызванные пропущенными деалокациями (хотя утечка всё ещё возможна, если ссылки удерживаются дольше, чем нужно). В больших кодовых базах, где владение трудно отслеживать вручную, это ускоряет итерации.
Сборщики мусора типичны в JVM (Java, Kotlin), .NET (C#, F#), Go и движках JavaScript в браузерах и Node.js.
Подсчёт ссылок — стратегия, где каждый объект отслеживает, сколько «владельцев» (ссылок) на него указывает. Когда счётчик падает до нуля, объект освобождается немедленно. Эта немедленность интуитивна: как только до объекта нельзя добраться, его память возвращается.
При копировании или сохранении ссылки счётчик увеличивается; когда ссылка уходит из области видимости, счётчик уменьшается. Достижение нуля триггерит немедленную очистку.
Это делает управление ресурсами предсказуемым: объекты часто освобождаются близко к моменту, когда вы перестаёте их использовать, что сокращает пиковое потребление памяти и избегает отложенного освобождения.
Подсчёт ссылок имеет постоянные, равномерно распределённые затраты: операции инк/дек происходят при многих присваиваниях и вызовах функций. Обычно накладные расходы малы, но они присутствуют повсеместно.
Плюс в том, что обычно нет больших стоп-ворлд пауз, как у некоторых трассирующих GC. Задержки часто более плавные, хотя всплески освобождения всё ещё возможны, когда крупные графы объектов теряют последний владелец.
Подсчёт ссылок не справится с объектами, замкнутыми в цикле. Если A ссылается на B, а B на A, их счётчики не упадут до нуля, даже если к ним больше никто не обращается — возникает утечка.
Экосистемы решают это разными способами:
Модель владения и заимствования наиболее ассоциируется с Rust. Идея проста: компилятор применяет правила, которые затрудняют появление висящих указателей, двойного освобождения и многих гонок данных — при этом без затрат на сборщик мусора.
У каждого значения есть ровно один «владелец» в любой момент. Когда владелец выходит из области видимости, значение очищается немедленно и предсказуемо. Это даёт детерминированное управление ресурсами (память, файловые дескрипторы, сокеты), похожее на ручное, но с меньшим шансом ошибиться.
Владение может «перемещаться»: присваивание или передача в функцию передаёт ответственность. После перемещения старое связывание нельзя использовать — это предотвращает use-after-free на уровне дизайна.
Заимствование позволяет использовать значение, не становясь его владельцем.
Разделяемое заимствование даёт доступ только для чтения и может копироваться свободно.
Мутируемое заимствование даёт возможность модификации, но должно быть эксклюзивным: пока оно существует, никто другой не может читать или писать это же значение. Правило «один писатель или много читателей» проверяется на этапе компиляции.
Поскольку времена жизни отслеживаются, компилятор может отклонять код, который будет ссылаться на данные после их жизни, устраняя многие висячие ссылки. Те же правила уменьшают количество гонок данных в конкурентном коде.
Цена — кривая обучения и некоторые ограничения в дизайне. Возможно, придётся перестроить потоки данных, ввести чёткие границы владения или использовать специальные типы для совместно используемого изменяемого состояния.
Она отлично подходит системному коду — сервисам, встроенным системам, сетевым компонентам и производительным частям, где нужна предсказуемая очистка и низкая задержка без пауз GC.
Когда вы создаёте много краткоживущих объектов (узлы AST в парсере, сущности в игровом кадре, временные данные в обработке запроса), накладные расходы на выделение и освобождение по одному объекту могут доминировать во времени выполнения. Арены (регионы) и пулы меняют тонкое освобождение на быстрое массовое управление.
Арена — это память/зона, в которой вы выделяете множество объектов, а затем освобождаете всё сразу, сбрасывая арену.
Вместо отслеживания жизни каждого объекта по‑отдельности, вы привязываете их к явной границе: «всё, что выделено для этого запроса» или «всё, что выделено при компиляции этой функции».
Аренa часто быстры, потому что они:
Это повышает пропускную способность и уменьшает пики задержек от частых free или конкуренции за аллокатор.
Арены и пулы встречаются в:
Главное правило: не позволяйте ссылкам «убежать» за пределы региона, который владеет памятью. Если то, что выделено в арене, сохраняется глобально или возвращается за пределы жизни арены, вы рискуете use-after-free.
Языки и библиотеки по-разному решают это: некоторые полагаются на дисциплину и API, другие кодируют границы региона в типах.
Арены и пулы не являются заменой GC или владению — они часто дополняют их. GC‑языки используют пулы для горячих путей; языки с владением применяют арены, чтобы сгруппировать аллокации и явно задать времена жизни. При осторожном применении они дают «быстро по умолчанию» выделение без потери ясности по моменту освобождения.
Модель памяти языка — лишь часть истории производительности и безопасности. Современные компиляторы и рантаймы перераписывают ваш код так, чтобы выделять меньше, освобождать быстрее и избегать лишней бухгалтерии. Поэтому типичные утверждения вроде «GC медленный» или «ручное управление — самое быстрое» часто оказываются неверными в реальных приложениях.
Многие выделения существуют только для передачи данных между функциями. С помощью escape‑анализа компилятор может доказать, что объект не выживает за пределы текущей области, и разместить его в стеке вместо кучи.
Это убирает обращение к куче, сопутствующие затраты (трекер GC, накладные на подсчёт ссылок, блокировки аллокатора). В управляемых языках это одна из причин, почему мелкие объекты могут быть дешевле, чем кажется.
Когда компилятор инлайнит функцию (заменяет вызов телом), он может «увидеть» сквозь уровни абстракции. Это даёт оптимизации:
Хорошо спроектированные API могут становиться «без стоимости» после оптимизаций, даже если в исходнике они выглядят как интенсивные аллокации.
JIT рантайм оптимизирует по реальным данным продакшена: какие пути горячие, типичные размеры объектов и паттерны выделений. Это часто повышает пропускную способность, но добавляет время прогрева и иногда паузы на рекомпиляцию или GC.
AOT компиляторы вынуждены догадываться заранее, но дают предсказуемый старт и более ровную задержку.
Рантаймы с GC открывают параметры: размер кучи, цели по времени пауз, пороги поколений. Меняйте их только когда у вас есть измерения (например, всплески задержки или давление по памяти), а не заранее.
Две реализации «того же» алгоритма могут отличаться по числу скрытых аллокаций, временам жизни временных объектов и числу переходов по указателям. Эти различия взаимодействуют с оптимизациями, аллокатором и кэш‑поведением — поэтому для сравнения нужна профилировка, а не догадки.
Выбор модели управления памятью не только меняет стиль написания кода, но и когда выполняется работа, сколько памяти нужно держать и насколько стабильно приложение ощущается пользователем.
Пропускная способность — «сколько работы за единицу времени». Подумайте о пакетной задаче, обрабатывающей 10 млн записей: если GC или подсчёт ссылок добавляют небольшую накладную, но ускоряют разработку, вы всё равно можете закончить быстрее в сумме.
Задержка — «сколько времени занимает одна операция». Для веб‑запроса единичный медленный ответ ухудшает UX, даже если средняя пропускная способность высока. Рантайм, который иногда останавливается для сборки мусора, может быть нормален для пакетной обработки, но заметен в интерактивных службах.
Большой memory footprint повышает затраты в облаке и может замедлять программу. Когда рабочий набор не помещается в кэш процессора, CPU чаще ждёт данные из RAM. Некоторые стратегии жертвуют памятью ради скорости (например, держать объекты в пуле), другие уменьшают память, но добавляют учёт.
Фрагментация возникает, когда свободная память разбросана мелкими дырками — как попытка припарковать фургон на площадке с множеством маленьких мест. Аллокатору приходится дольше искать место, и память может расти, хотя «достаточно» свободного места есть.
Кэш‑локальность означает, что связанные данные находятся рядом. Пулы/арены часто улучшают локальность (объекты, выделенные вместе, лежат рядом), в то время как долгоживущие кучи с разными размерами объектов могут деградировать в плане кэш‑дружественности.
Если нужны стабильные времена отклика — игры, аудио, торговые системы, встроенные контроллеры — «в основном быстро, но иногда медленно» хуже, чем «слегка медленнее, но стабильно». Тут важны предсказуемые паттерны деалокации и жёсткий контроль над аллокациями.
Ошибки с памятью — это не только «ошибки программиста». Во многих системах они превращаются в проблемы безопасности: аварии (DoS), случайный утечка данных (чтение освобождённой или неинициализированной памяти) или условия, когда атакующий заставляет программу выполнить нежелательный код.
Разные стратегии управления памятью склонны к разным видам ошибок:
Конкуренция меняет модель угроз: память может быть безопасна в одном потоке и опасна, когда другой поток освобождает или мутирует её. Модели, которые явно ограничивают шаринг или требуют синхронизации, снижают шанс гонок, приводящих к повреждению состояния, утечкам и случайным авариям.
Ни одна модель памяти не снимает все риски — логические баги (ошибки аутентификации, небезопасные настройки, неверная валидация) остаются. Сильные команды накладывают дополнительные слои: санитайзеры в тестах, безопасные стандартные библиотеки, тщательные ревью, фуззинг и строгие зоны с небезопасным/FFI кодом. Памятная безопасность значительно сокращает поверхность атаки, но не гарантирует её отсутствие.
Проблемы с памятью легче исправлять, когда вы ловите их близко к моменту внесения изменения. Ключ — сначала измерять, затем сузить проблему подходящим инструментом.
Определитесь, гонитесь ли вы за быстродействием или за ростом памяти.
Для производительности меряйте wall‑clock, CPU time, скорость выделений (байт/сек) и время в GC или аллокаторе. Для памяти отслеживайте пик RSS, устойчивый RSS и счётчики объектов со временем. Запускайте одинаковые нагрузки с одинаковыми вводами; мелкие вариации могут скрыть шум аллокаций.
Признаки: один запрос выделяет намного больше, чем ожидалось, или память растёт с нагрузкой, хотя пропускная способность стабильна. Исправления часто включают повторное использование буферов, переход на арену/пул для краткоживущих объектов и упрощение графов объектов, чтобы меньше объектов переживало цикл сборки.
Воспроизведите минимальным входом, включите строгие проверки рантайма (санитайзеры/верификацию GC), затем соберите:
Считайте первое исправление экспериментом; прогоняйте измерения снова, чтобы подтвердить, что изменение снизило аллокации или стабилизировало память — без смещения проблемы в другое место. Для интерпретации компромиссов см. /blog/performance-trade-offs-throughput-latency-memory-use.
Выбор языка — это не только синтаксис или экосистема: модель управления памятью формирует повседневную скорость разработки, операционный риск и предсказуемость производительности под реальной нагрузкой.
Сопоставьте требования продукта с стратегией памяти, ответив на практические вопросы:
При смене модели планируйте трение: вызовы в существующие библиотеки (FFI), смешанные соглашения по памяти, инструменты и рынок найма. Прототипы помогают обнаружить скрытые затраты (пауз, рост памяти, накладные CPU) раньше.
Практический подход — прототипировать одну и ту же фичу в рассматриваемых средах и сравнивать скорость выделений, хвостовую задержку и пик памяти под репрезентативной нагрузкой. Команды иногда делают такие «яблоки к яблокам» эксперименты (например, быстро скелетируют фронт React + бэкенд на Go + PostgreSQL), чтобы понять поведение GC‑сервиса в реальном трафике и экспортировать исходники, когда готовы развиваться дальше.
Определите 3–5 верхнеприоритетных ограничений, соберите тонкий прототип и измерьте использование памяти, хвостовую задержку и режимы отказов.
| Модель | Безопасность по умолчанию | Предсказуемость задержки | Скорость разработки | Типичные ловушки |
|---|---|---|---|---|
| Ручное | Низкая–Средняя | Высокая | Средняя | утечки, use-after-free |
| GC | Высокая | Средняя | Высокая | паузы, рост кучи |
| RC | Средне–Высокая | Высокая | Средняя | циклы, накладные расходы |
| Владение | Высокая | Высокая | Средняя | кривая обучения |
Управление памятью — это то, как программа выделяет память для данных (объекты, строки, буферы) и затем освобождает её, когда она больше не нужна.
Это влияет на:
Стек — быстрый, автоматический и привязанный к вызовам функций: когда функция возвращается, её фрейм в стеке удаляется целиком.
Куча (heap) нужна для гибких или более длительных объектов, но требуется стратегия—кто и когда освобождает такую память.
Правило практичности: стек хорош для короткоживущих локальных значений фиксированного размера; куча — когда размеры или времена жизни непредсказуемы.
Ссылка/указатель даёт косвенный доступ к объекту. Опасность в том, что память объекта может быть освобождена, а ссылка на неё всё ещё используется.
Это может привести к:
Вы явно выделяете и освобождаете память (например, malloc/free, new/delete).
Это полезно, когда нужно:
Цена — повышенный риск ошибок, если владение и времена жизни не соблюдаются.
Ручное управление может давать предсказуемую задержку если код грамотно спроектирован, поскольку нет фонового сборщика, который может внезапно остановить выполнение.
Его можно оптимизировать через:
Но легко получить дорогие паттерны (фрагментация, конкуренция в аллокаторе, много мелких alloc/free).
Сборщик мусора автоматически находит объекты, до которых программа больше не может добраться, и возвращает их память.
Большинство трассирующих GC работает так:
Это повышает безопасность (меньше ошибок типа use-after-free), но добавляет работу во время выполнения и может вызывать паузы в зависимости от дизайна сборщика.
Подсчёт ссылок освобождает объект, когда его счётчик ссылок падает до нуля.
Плюсы:
Минусы:
Владение и заимствование (в модели Rust) — это правила, проверяемые на этапе компиляции, которые предотвращают многие ошибки времени жизни.
Основные идеи:
Это даёт предсказуемое освобождение без пауз GC, но часто требует перестроить потоки данных и чётче задать границы владения.
Аренa/регион/пул выделяет много объектов в «зоне», а затем освобождает их всеми сразу, сбросив или уничтожив арену.
Это эффективно, когда есть ясная граница времени жизни, например:
Главное правило безопасности: не позволяйте ссылкам выходить за пределы жизни арены.
Начните с измерений в реалистичной нагрузке:
Затем используйте целевые инструменты:
Многие экосистемы используют weak references или дополнение в виде детектора циклов, чтобы смягчить проблему циклов.
Тюнингу параметров рантайма (например, GC) предшествует измерение и подтверждение проблемы.